

Optimized Design of Non-Transparent Bridge for Heterogeneous Interconnects in Hyper-converged Infrastructure
-
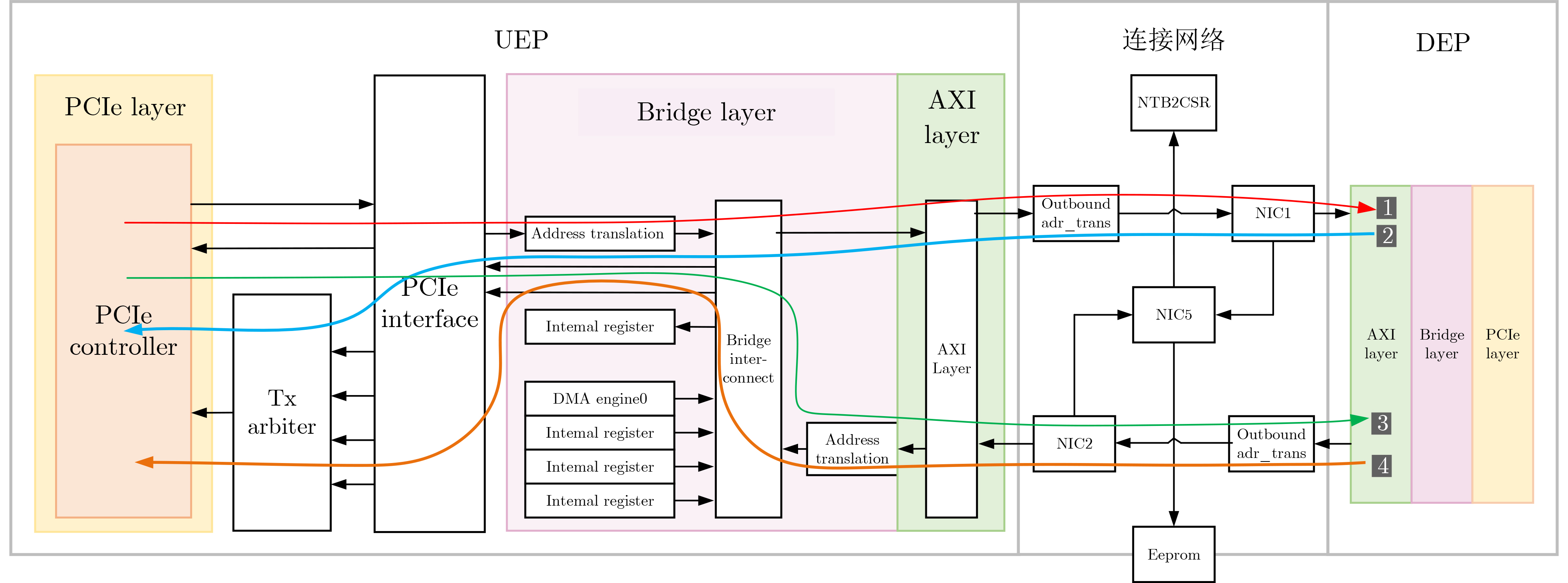
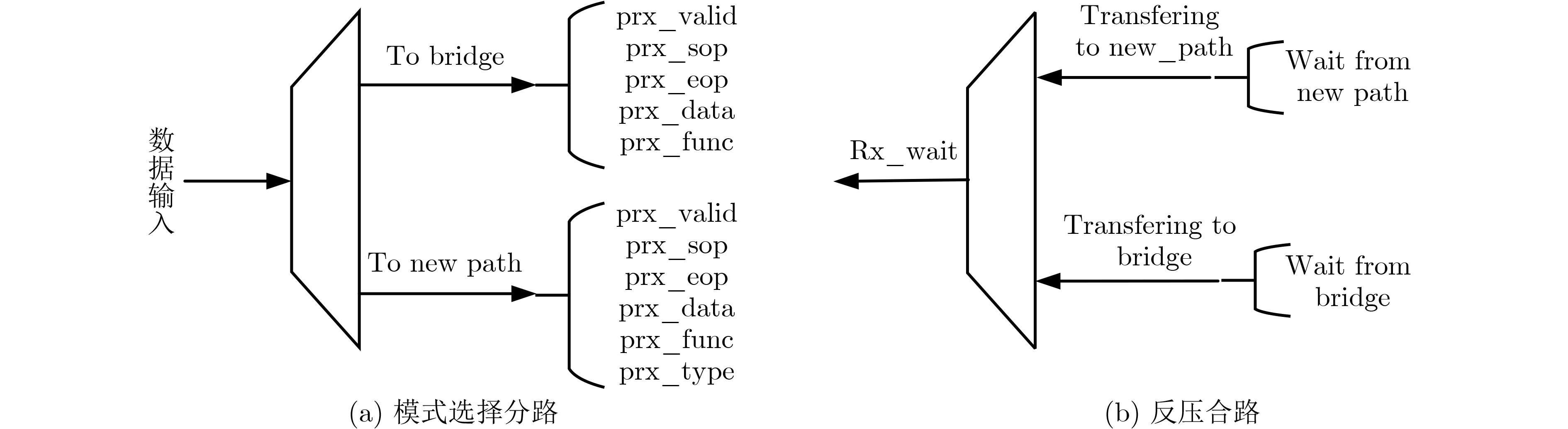
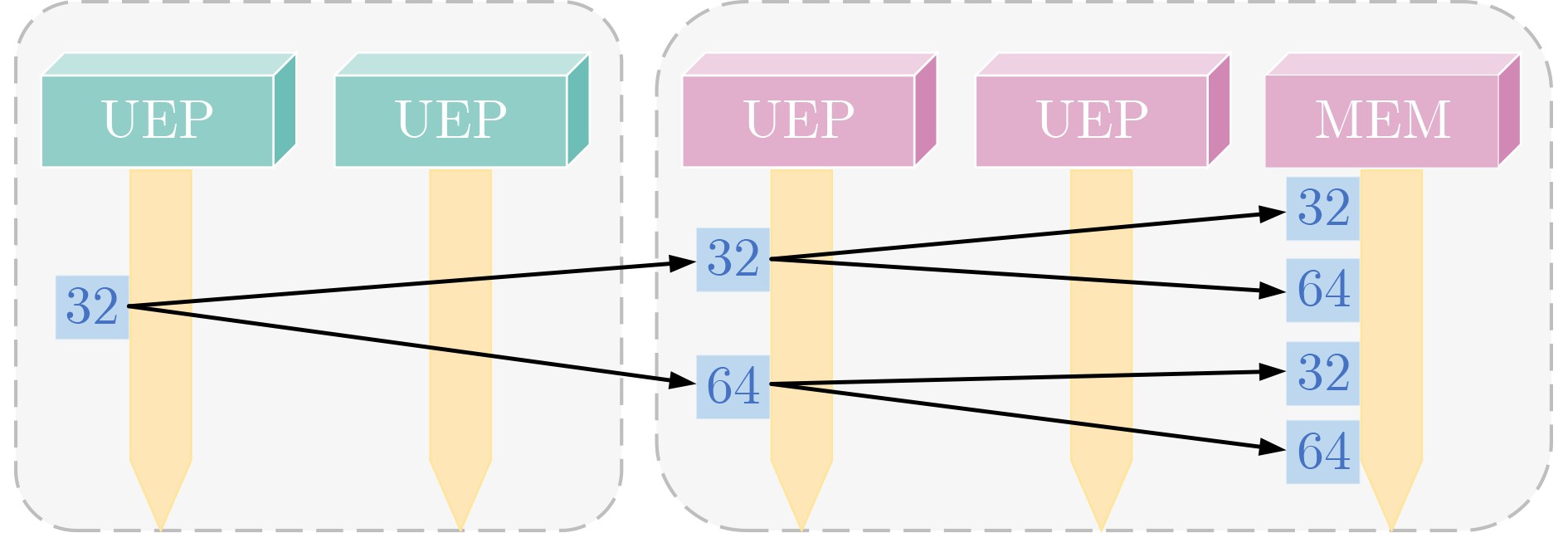
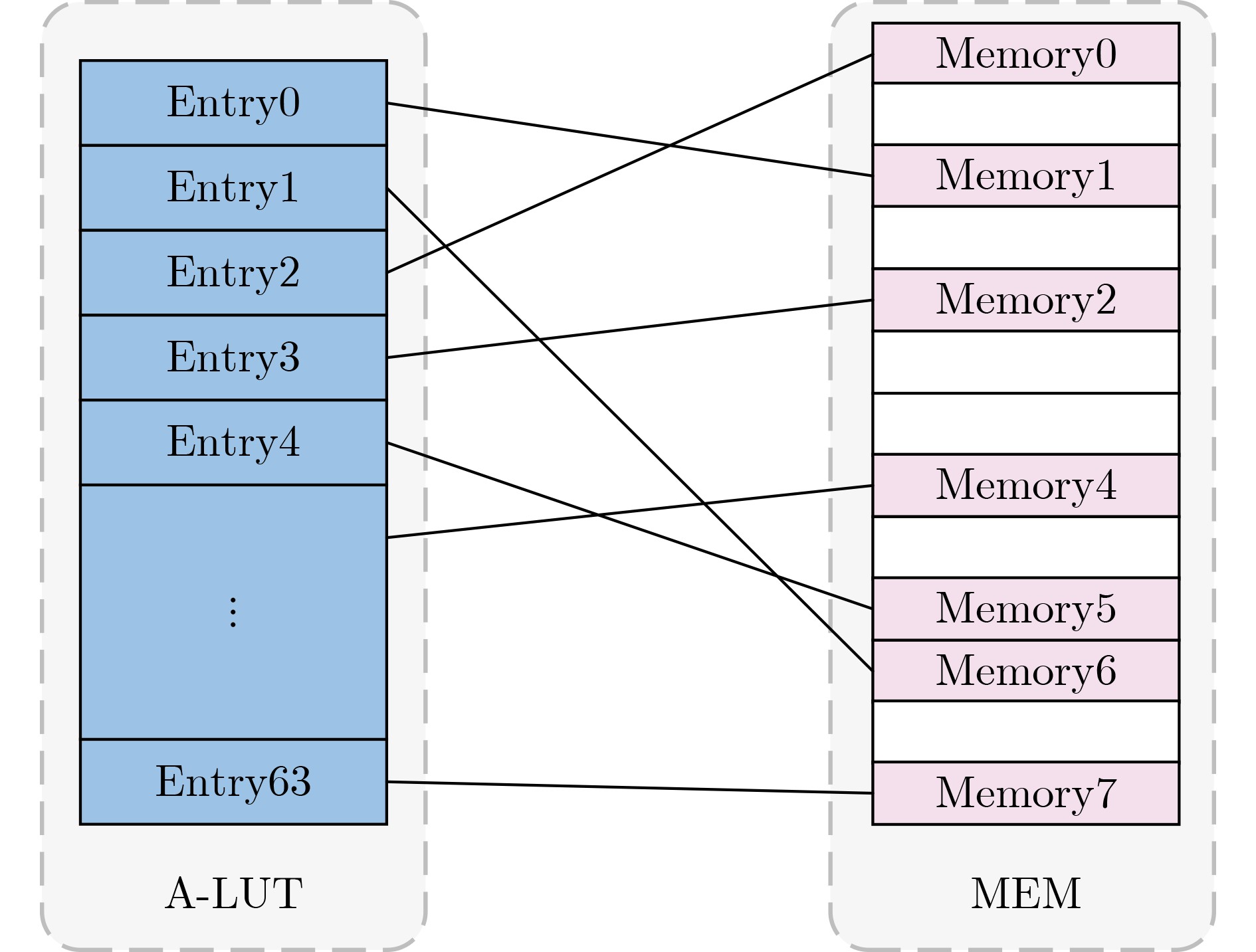
摘要: 为提升超融合(HCI)系统内异构域跨域的传输性能和稳定性,该文提出一种支持双传输模式的非透明桥(NTB)数据通路架构(D-MNTBA)。通过融合所提旁路架构下的快速传输模式和传统架构(TDPA)下的稳定传输模式,NTB能够结合HCI数据特性与跨域需求进行分流传输报文。通过对地址转换和ID转换进行硬件级优化,NTB中地址转换可支持更复杂的转换方案,并最大限度地压缩了ID转换时间。实验结果表明,在所构建的HCI环境中,D-MNTBA的最大带宽及吞吐量分别可达
1500 MB/s和1.36 GB/s,ID转换时间降低至71 ns。相较于以太网卡,其带宽及吞吐量分别提升了约19.0%和40.2%。对比PEX8748,其ID转换时间缩短了约34.9%,带宽及吞吐量分别提升了约27.1%和51.1%,且系统稳定性更强,可有效支撑HCI中异构域的跨域传输。Abstract:Objective The integration of heterogeneous computing resource clusters into modern Hyper-Converged Infrastructure (HCI) systems imposes stricter performance requirements in latency, bandwidth, throughput, and cross-domain transmission stability. Traditional HCI systems primarily rely on the Ethernet TCP/IP protocol, which exhibits inherent limitations, including low bandwidth efficiency, high latency, and limited throughput. Existing PCIe Switch products typically employ Non-Transparent Bridges (NTBs) for conventional dual-system connections or intra-server communication; however, they do not meet the performance demands of heterogeneous cross-domain transmission within HCI environments. To address this limitation, a novel Dual-Mode Non-Transparent Bridge Architecture (D-MNTBA) is proposed to support dual transmission modes. D-MNTBA combines a fast transmission mode via a bypass mechanism with a stable transmission mode derived from the Traditional Data Path Architecture (TDPA), thereby aligning with the data characteristics and cross-domain streaming demands of HCI systems. Hardware-level enhancements in address and ID translation schemes enable D-MNTBA to support more complex mappings while minimizing translation latency. These improvements increase system stability and effectively support the cross-domain transmission of heterogeneous data in HCI systems. Methods To overcome the limitations of traditional single-pass architectures and the bypass optimizations of the TDPA, the proposed D-MNTBA incorporates both a fast transmission path and a stable transmission path. This dual-mode design enables the NTB to leverage the data characteristics of HCI systems for telegram-based streaming, thereby reducing dependence on intermediate protocols and data format conversions. The stable transmission mode ensures reliable message delivery, while the fast transmission mode—enhanced through hardware-level optimizations in address and ID translation—supports high-real-time cross-domain communication. This combination improves overall transmission performance by reducing both latency and system overhead. To meet the low-latency demands of the bypass transmission path, the architecture implements hardware-level enhancements to the address and ID conversion modules. The address translation module is expanded with a larger lookup table, allowing for more complex and flexible mapping schemes. This enhancement enables efficient utilization of non-contiguous and fragmented address spaces without compromising performance. Simultaneously, the ID conversion module is optimized through multiple conversion strategies and streamlined logic, significantly reducing the time required for ID translation. Results and Discussions Address translation in the proposed D-MNTBA is validated through emulation within a constructed HCI environment. The simulation log for indirect address translation shows no errors or deadlocks, and successful hits are observed on BAR2/3. During dual-host disk access, packet header addresses and payload content remain consistent, with no packet loss detected ( Fig. 14 ), indicating that indirect address translation is accurately executed under D-MNTBA. ID conversion performance is evaluated by comparing the proposed architecture with the TDPA implemented in the PEX8748 chip. The switch based on D-MNTBA exhibits significantly shorter ID conversion times. A maximum reduction of approximately 34.9% is recorded, with an ID conversion time of 71 ns for a 512-Byte payload (Fig. 15 ). These findings suggest that the ID function mapping method adopted in D-MNTBA effectively reduces conversion latency and enhances system performance. Throughput stability is assessed under sustained heavy traffic with payloads ranging from 256 to 2 048 Bytes. The maximum throughputs of D-MNTBA, the Ethernet card, and PEX8748 are measured at 1.36 GB/s, 0.97 GB/s, and 0.9 GB/s, respectively (Fig. 16 ). Compared to PEX8748 and the Ethernet architecture, D-MNTBA improves throughput by approximately 51.1% and 40.2%, respectively, and shows the slowest degradation trend, reflecting superior stability in heterogeneous cross-domain transmission. Bandwidth comparison reveals that D-MNTBA outperforms TDPA and the Ethernet card, with bandwidth improvements of approximately 27.1% and 19.0%, respectively (Fig. 17 ). These results highlight the significant enhancement in cross-domain transmission performance achieved by the proposed architecture in heterogeneous environments.Conclusions This study proposes a Dual-Mode D-MNTBA to address the challenges of heterogeneous interconnection in HCI systems. By integrating a fast transmission path enabled by a bypass architecture with the stable transmission path of the TDPA, D-MNTBA accommodates the specific data characteristics of cross-domain transmission in heterogeneous environments and enables efficient message routing. D-MNTBA enhances transmission stability while improving system-wide performance, offering robust support for high-real-time cross-domain transmission in HCI. It also reduces latency and overhead, thereby improving overall transmission efficiency. Compared with existing transmission schemes, D-MNTBA achieves notable gains in performance, making it a suitable solution for the demands of heterogeneous domain interconnects in HCI systems. However, the architectural enhancements, particularly the bypass design and associated optimizations, increase logic resource utilization and power consumption. Future work should focus on refining hardware design, layout, and wiring strategies to reduce logic complexity and resource consumption without compromising performance. -
表 1 path_select模块路选规则
报文类型 规则 传输模式 MWr/MRd 命中Bar0,Bar0/1 稳定传输 MWr/MRd 命中Bar2, Bar3, Bar4, Bar5, Bar4/5且path_mux=1 快速传输 MRd 命中Expansion ROM 稳定传输 MWr 命中Expansion ROM 丢弃 CPL/CPLD DMA使能且path_mux=1 快速传输 Credit(信用值) 原有数据通路信用量缺失 快速传输  下载: 导出CSV
下载: 导出CSV
表 2 ID转换模式控制方式
寄存器模式 条目格式 Lut_format=0
(不支持function num检查)[15:8]bus num [7:3]device num [2]reserved [1]no snoop ctrl(1:清除;0:不清除) [0]entry en [15:8]bus num Lut_format=1
(支持function num检查)[7:3]device num [2:0]function num No snoop ctrl保证每一比特与每个entry一一对应
下载: 导出CSV
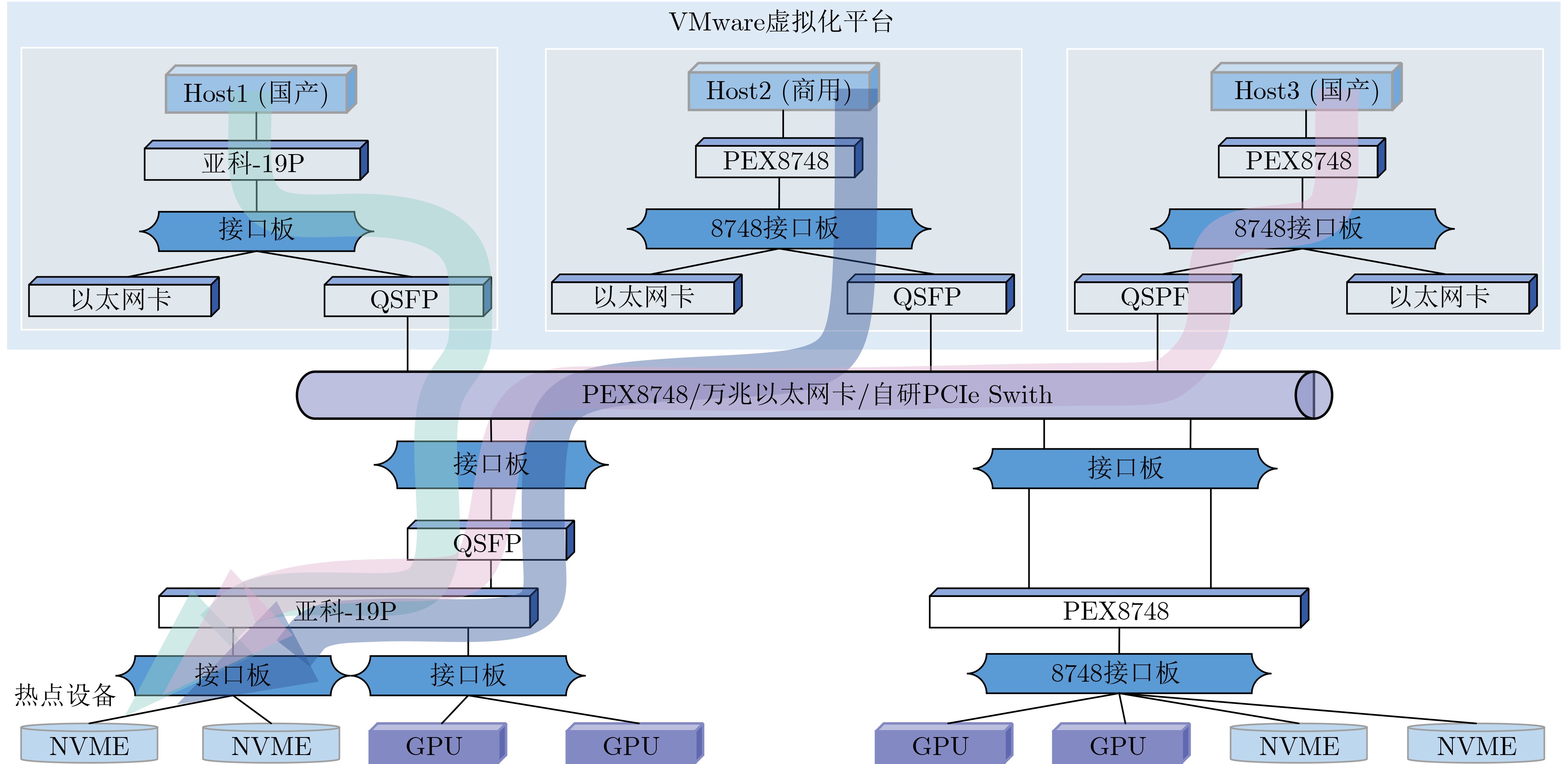
表 3 HCI异构互连场景资源部署情况
编号 资源名称 型号 数量 1 处理器 Intel i9-13900K 1 2 处理器 飞腾嵌入式:2000-4 1 3 处理器 龙芯2K30000 1 4 GPU显卡 NVIDIA-T1000 1 5 GPU显卡 华为升腾310B 1 6 GPU显卡 景嘉微JM930 1 7 GPU显卡 天数智芯智凯100 1 8 FPGA板卡 亚科19p 3 板卡 PEX8748 3 9 万兆以太网卡 Intelx520 3 10 NVMe SSD盘 联想SL7000-M 1 11 NVMe SSD盘 致钛TiPlus7100-M.2-1TB 1 12 NVMe SSD盘 Intel P4510-U.2-1TB 1 13 NVMe SSD盘 致钛PC005 Active-M.2-1TB 1 14 操作系统 Ubuntu 20.04.6 1 15 操作系统 Windows11 1
下载: 导出CSV
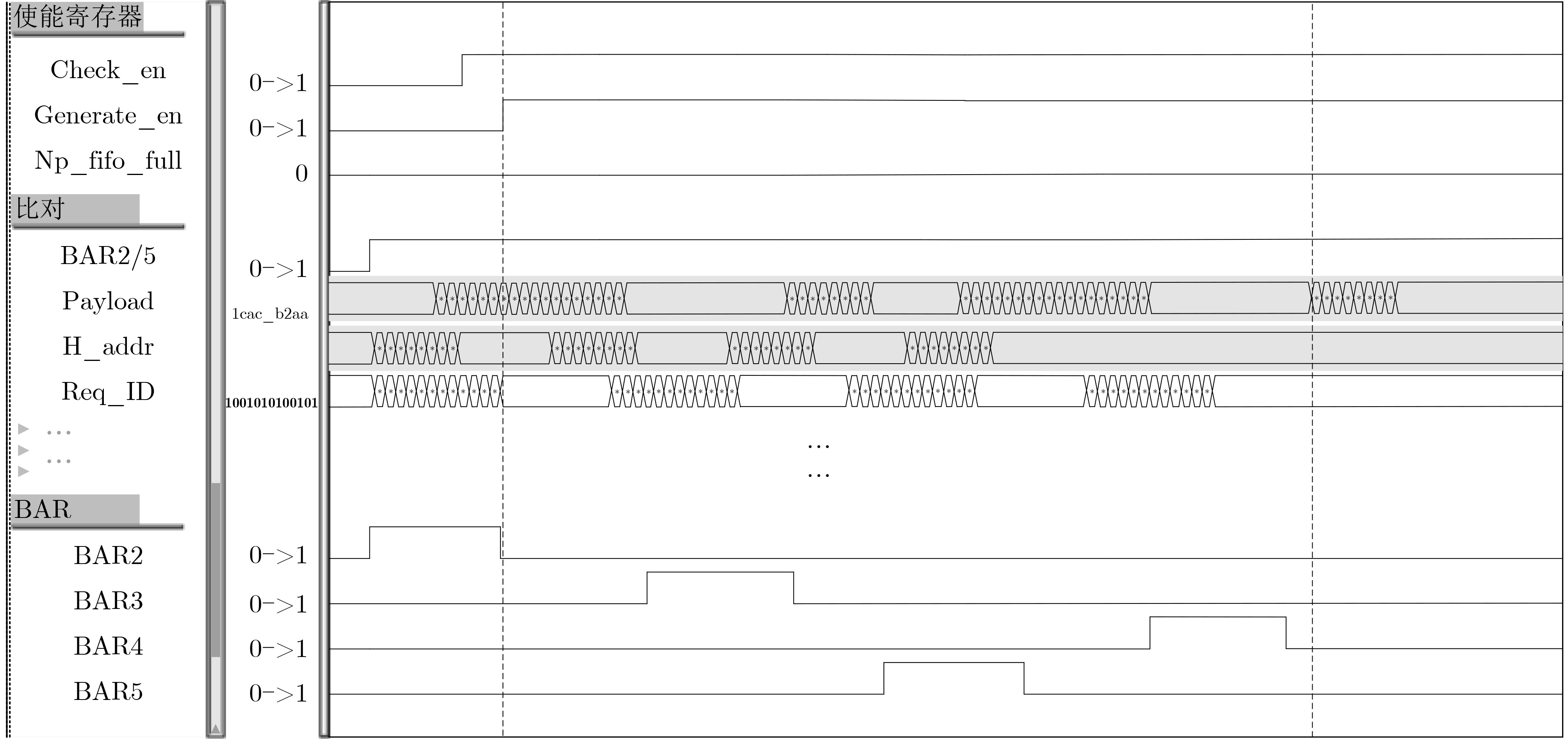
表 4 32 bit-64 bit间接地址转换测试用例描述
用例描述 通过准则 命中BAR2进行32-64
间接地址转换;
报文类型、地址长度
随机;(1)验证环境对比地址转换通过、包头地址、payload比对通过;
(2)验证环境监视过程中np_fifo未满,
无死锁;
(3)验证环境进行包计数的预期;
(4)用例仿真log,打印关键信息。
下载: 导出CSV
1 AA模式主备倒换测试
输入:定义初始默认角色为active, global_role = “active”;
倒换时间failover_start = 6;恢复时间failover_step2 = $(expr
$failover_start + 3);重启时间failover_step3 = $(expr
$failover_start + 4)输出:主备倒换完成指示信号 (1) /*AA模式接管方操作,等待接管完成*/ (2) aa_passive_failover_strart() (3) echo_trace“passive start failover”;//客户端需要重启,
等待接管完成(4) aa_stop_client; (5) aa_passive_failover_step2()//主备恢复 (6) 交换端口角色; (7) 使能NT端口; (8) aa_passive_failover_step2(); (9) 重启主机域; (10) /*AA模式被接管方*/ (11) aa_active_failover_start() (12) 关闭程序; (13) 断开心跳; (14) 重启恢复+通信;
下载: 导出CSV
表 5 热点设备场景性能测试结果
测试对象 吞吐量(Gbit/(s·Hz)) 时延(ns) 丢包率(%) D-MNTBA 1 217.21 108 0.71 PEX8748 965.06 172 5.10 以太网卡 1 081.75 164 3.70
下载: 导出CSV
表 6 主要设计指标对比
对比方案 改进措施 带宽大小(MB/s) 吞吐量(GB/s) ID转换耗时(ns) 性能稳定性 协议类型及支持场景 PEX8748中的TDPA - 1 180 0.9(有效负载256 Byte
时峰值)256(峰值)
109(最低)弱 PCIe Gen3传统超融合 文献[17] 环形队列管理
地址空间1 215(帧大小为2 MB时
的峰值)未明确 未明确 弱 PCIe Gen3双机互连 文献[18] NT端口大小优化 1 200(NT端口大小为
32 kB时的峰值)未明确 未明确 弱 PCIe Gen3双机互连 以太网卡 - 1 260 0.71(有效负载256 Byte
时峰值)- 较弱 PCIe Gen4传统超融合 D-MNTBA 双传输模式架构 1 500 1.36(有效负载256 Byte
时峰值)221(峰值)
71(最低)强 PCIe Gen4超融合异构
互连注1:以太网卡不涉及ID转换概念,主要处理MAC地址而非设备ID。
注2:文献[17]和文献[18]只适应用于双机互连,其单通路架构面对异构互连易达到性能饱和,架构稳定性弱。
下载: 导出CSV
-
[1] 张桉齐, 张利彬. 基于跨机内存映射的高速互联机制[J]. 指挥控制与仿真, 2025, 47(3): 109–115. doi: 10.3969/j.issn.1673-3819.2025.03.015.ZHANG Anqi and ZHANG Libin. A high-speed interconnection mechanism based on multi-hosts memory mapping[J]. Command Control & Simulation, 2025, 47(3): 109–115. doi: 10.3969/j.issn.1673-3819.2025.03.015. [2] 王浩, 王勇, 冯长磊, 等. Chiplet互联技术综述[J/OL]. 计算机研究与发展, 1–13. https://link.cnki.net/urlid/11.1777.TP.20250304.1704.002, 2025.WANG Hao, WANG Yong, FENG Changlei, et al. Review of Chiplet interconnection technology[J/OL]. Journal of Computer Research and Development, 1–13. http://kns.cnki.net/kcms/detail/11.1777.TP.2040.20304.1704.002.html, 2025. [3] DASARRAJU V K. Implementing and managing hyper-converged infrastructure with VMware vSAN and azure stack HCI[J]. Journal of Artificial Intelligence, Machine Learning and Data Science, 2024, 2(2): 666–670. doi: 10.51219/JAIMLD/reddy-davu/170. [4] YANG Yang, JIA Junjun, and LV Hua. Resources optimization research of service oriented architecture based on hyper converged infrastructure cloud computing platform[M]. CHEN Chihua, SCAPELLATO A, BARBIERO A, et al. Applied Mathematics, Modeling and Computer Simulation. Amsterdam: IOS Press, 2023: 78–84. doi: 10.3233/ATDE230942. [5] SILVA-ATENCIO G and UMAÑA-RAMÍREZ M. The evolution and trends of hyperconvergence in the telecommunications sector: A competitive intelligence review[J]. Dyna, 2023, 90(227): 126–132. doi: 10.15446/dyna.v90n227.107360. [6] USHAKOV Y, USHAKOVA M, and LEGASHEV L. Research of a virtual infrastructure network with hybrid software-defined switching[J]. Engineering Proceedings, 2023, 33(1): 52. doi: 10.3390/engproc2023033052. [7] 谭政源, 钟佳卿, 陈娟. 等. AI+HPC: “智能+”驱动下的超算系统软件及应用技术发展综述[J]. 计算机科学, 2025, 52(5): 1–10. doi: 10.11896/jsjkx.241100177.TAN Zhengyuan, ZHONG Jiaqing, CHEN Juan, et al. AI+HPC: An overview of supercomputing system software and application technology development driven by “AI+”[J]. Computer Science, 2025, 52(5): 1–10. doi: 10.11896/jsjkx.241100177. [8] TSUNG C K, LIU J C, LIU S H, et al. Performance analysis in HyperFlex and vSAN hyper convergence platforms for online course consideration[J]. IEEE Access, 2022, 10: 124464–124474. doi: 10.1109/ACCESS.2022.3224435. [9] NISA N, KHAN A S, AHMAD Z, et al. TPAAD: Two‐phase authentication system for denial of service attack detection and mitigation using machine learning in software‐defined network[J]. International Journal of Network Management, 2024, 34(3): e2258. doi: 10.1002/nem.2258. [10] MA Xiaohan, WANG Ying, WANG Yuji, et al. Survey on chiplets: Interface, interconnect and integration methodology[J]. CCF Transactions on High Performance Computing, 2022, 4(1): 43–52. doi: 10.1007/s42514-022-00093-0. [11] NOAMAN M, KHAN M S, ABRAR M F, et al. Challenges in integration of heterogeneous internet of things[J]. Scientific Programming, 2022, 2022(1): 8626882. doi: 10.1155/2022/8626882. [12] LAU J H. Recent advances and trends in multiple system and heterogeneous integration with TSV-less interposers[J]. IEEE Transactions on Components, Packaging and Manufacturing Technology, 2022, 12(8): 1271–1281. doi: 10.1109/TCPMT.2022.3194374. [13] YIN Jinyong, WANG Honghui, and XU Zhenpeng. A reconfigurable rack-scale interconnect architecture based on PCIe fabric[C]. 2022 IEEE 2nd International Conference on Data Science and Computer Application (ICDSCA), Dalian, China, 2022: 306–310. doi: 10.1109/ICDSCA56264.2022.9988411. [14] HOSSEINABADY M, ZAINOL M A B, and NUNEZ-YANEZ J. Heterogeneous FPGA+GPU embedded systems: Challenges and opportunities[EB/OL]. https://arxiv.org/abs/1901.06331, 2019. [15] ZHAO Xujie and ZHI Xiaoli. A PCIe-based inter-processor messaging architecture[C]. 2024 4th International Conference on Electronic Information Engineering and Computer (EIECT), IEEE, Shenzhen, China, 2024: 548–553. doi: 10.1109/EIECT64462.2024.10866443. [16] HUANG Yibo, HUANG Yukai, YAN Ming, et al. An ultra-low latency and compatible PCIe interconnect for rack-scale communication[C]. The 18th International Conference on emerging Networking EXperiments and Technologies, Roma, Italy, 2022: 232–244. doi: 10.1145/3555050.3569128. [17] 刘佳兴, 胡怀湘. 非透明桥在国产化平台上的应用[J]. 信息技术, 2020, 44(11): 103–107. doi: 10.13274/j.cnki.hdzj.2020.11.020.LIU Jiaxing and HU Huaixiang. Application of non-transparent bridge on localized platform[J]. Information Technology, 2020, 44(11): 103–107. doi: 10.13274/j.cnki.hdzj.2020.11.020. [18] 徐健, 张建泉, 张健. 基于PCIE非透明桥的嵌入式异构平台设计[J]. 微电子学与计算机, 2018, 35(1): 26–30. doi: 10.19304/j.cnki.issn1000-7180.2018.01.006.XU Jian, ZHANG Jianquan and ZHANG Jian. An application of PCIE non-transparent bridge on a heterogeneous platform[J]. Microelectronics & Computer, 2018, 35(1): 26–30. doi: 10.19304/j.cnki.issn1000-7180.2018.01.006. [19] 李沛杰, 刘勤让, 陈艇, 等. 异构集成互连接口研究综述[J]. 集成电路与嵌入式系统, 2024, 24(2): 31–40.LI Peijie, LIU Qinrang, CHEN Ting, et al. Research on the heterogeneous integrated interconnect interface[J]. Integrated Circuits and Embedded Systems, 2024, 24(2): 31–40. [20] HOU Wentao, ZHANG Jie, WANG Zeke, et al. Understanding routable PCIe performance for composable infrastructures[C]. The 21st USENIX Symposium on Networked Systems Design and Implementation. Santa Clara, USA, 2024: 271–312. [21] LIM S H and CHA K. Shared memory model over a switchless PCIe NTB interconnect network[J]. Journal of Information Processing Systems, 2022, 18(1): 159–172. doi: 10.3745/JIPS.01.0085. [22] 任晓旭, 谭靖超, 邓辉, 等. 基于端边云超融合的算力网络架构[J]. 计算机应用, 2022, 42(S1): 195–200. doi: 10.11772/j.issn.1001-9081.2021081491.REN Xiaoxu, TAN Jingchao, DENG Hui, et al. Arithmetic network architecture based on end-side cloud hyperconvergence[J]. Journal of Computer Application, 2022, 42(S1): 195–200. doi: 10.11772/j.issn.1001-9081.2021081491. [23] NABLI H, BEN DJEMAA R, and AMOUS BEN AMOR I. Description, discovery, and recommendation of Cloud services: A survey[J]. Service Oriented Computing and Applications, 2022, 16(3): 147–166. doi: 10.1007/s11761-022-00343-7. [24] 卢宇彤, 陈志广. 基于超算的多模式计算融合支撑系统[J]. 中山大学学报(自然科学版中英文), 2024, 63(6): 150–160. doi: 10.13471/j.cnki.acta.snus.ZR20240293.LU Yutong and CHEN Zhiguang. The convergent computing based on supercomputer[J]. Acta Scientiarum Naturalium Universitatis Sunyatseni, 2024, 63(6): 150–160. doi: 10.13471/j.cnki.acta.snus.ZR20240293. -


 下载:
下载:












图(17) / 表(7)
计量
- 文章访问数: 1241
- HTML全文浏览量: 893
- PDF下载量: 80
- 被引次数: 0
