

Fuzzy C-Means Clustering Algorithm Based on Mixed Noise-aware under Local Differential Privacy
-
摘要: 在大数据和物联网应用中,本地差分隐私(LDP)技术用于保护聚类分析中的用户隐私,但现有方法要么在LDP下交互式地进行聚类,需要消耗大量隐私预算,要么没有同时考虑到聚类数据中蕴含的表示数据质量的高斯噪音以及为满足LDP保护的拉普拉斯噪音,致使聚类精度低下。同时,对于衡量用户提交数据和簇心之间的距离选择较为武断,没有充分利用到用户提交的噪音数据中蕴含的噪音模式。为此,该文创新性地提出一种满足LDP的混合噪音感知的模糊C均值聚类算法(mnFCM),该算法的主要思想是同时建模用户上传数据中蕴含的表示用户质量的高斯噪音以及为保护用户数据注入的拉普拉斯噪音,进而设计出混合噪音感知的距离替代传统的欧式距离,来衡量样本数据与簇心间的相似性。特别地,在mnFCM中,该文首先设计了混合噪音感知的距离计算方法,在此基础上给出算法新的目标函数,并基于拉格朗日乘子法设计了求解方法,最后理论上分析了求解算法的收敛性。该文进一步理论分析了mnFCM的隐私、效用和复杂度,分析结果表明所提算法严格满足LDP、相对于对比算法更接近非隐私下的簇心以及和非隐私算法具有接近的复杂度。在两个真实数据集上的实验结果表明,mnFCM在满足LDP下,聚类精度提高了10%~15%。Abstract:
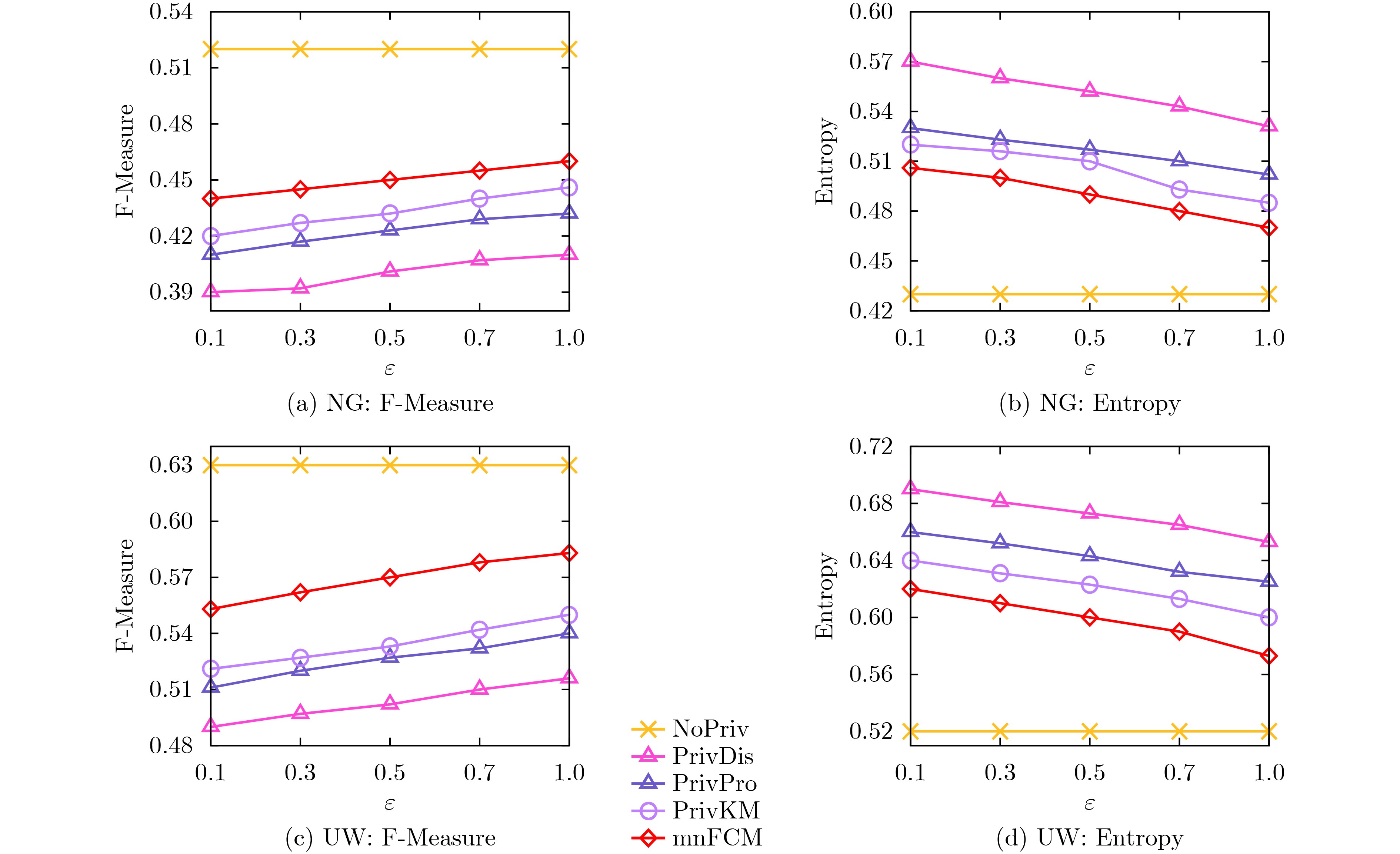
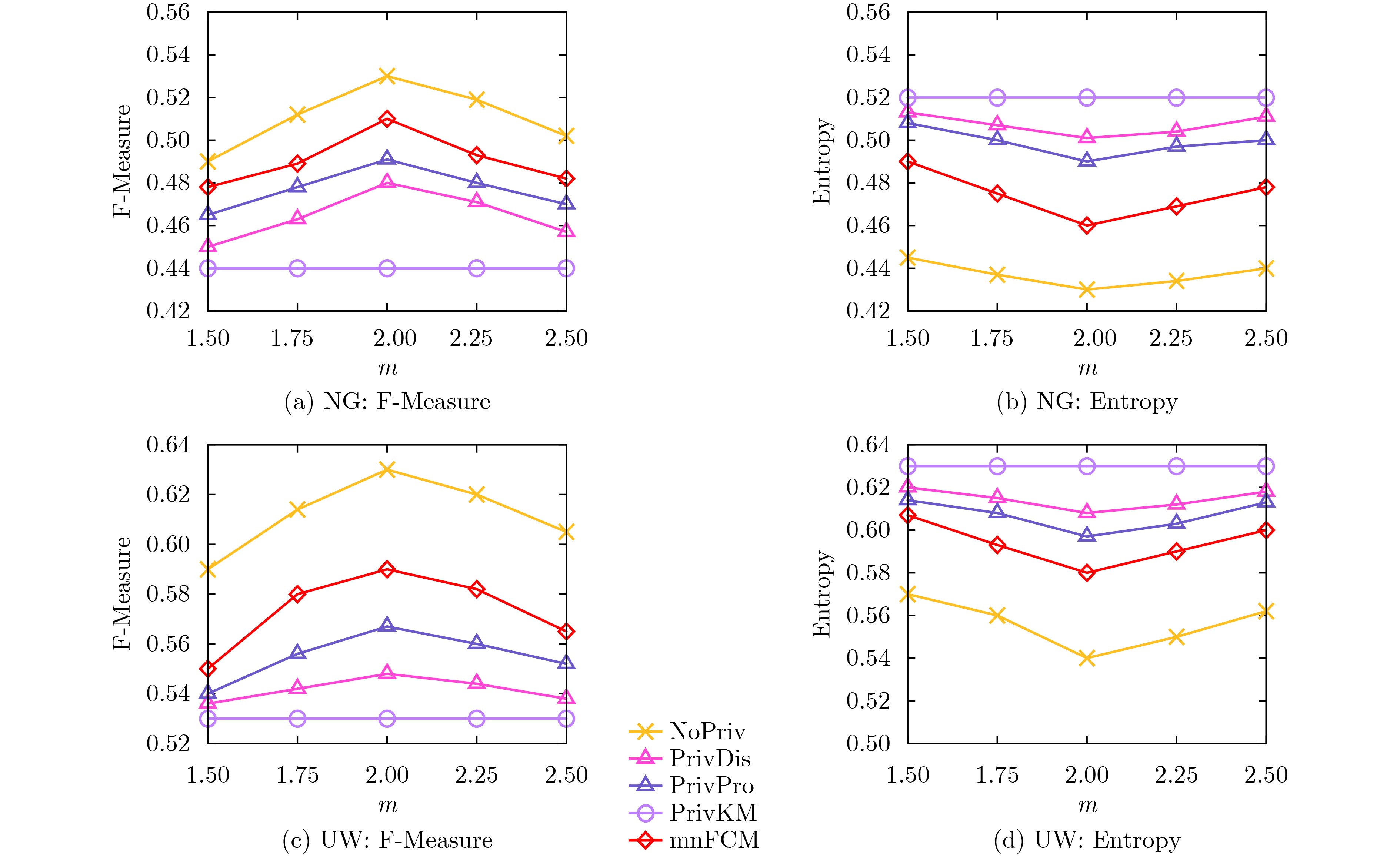
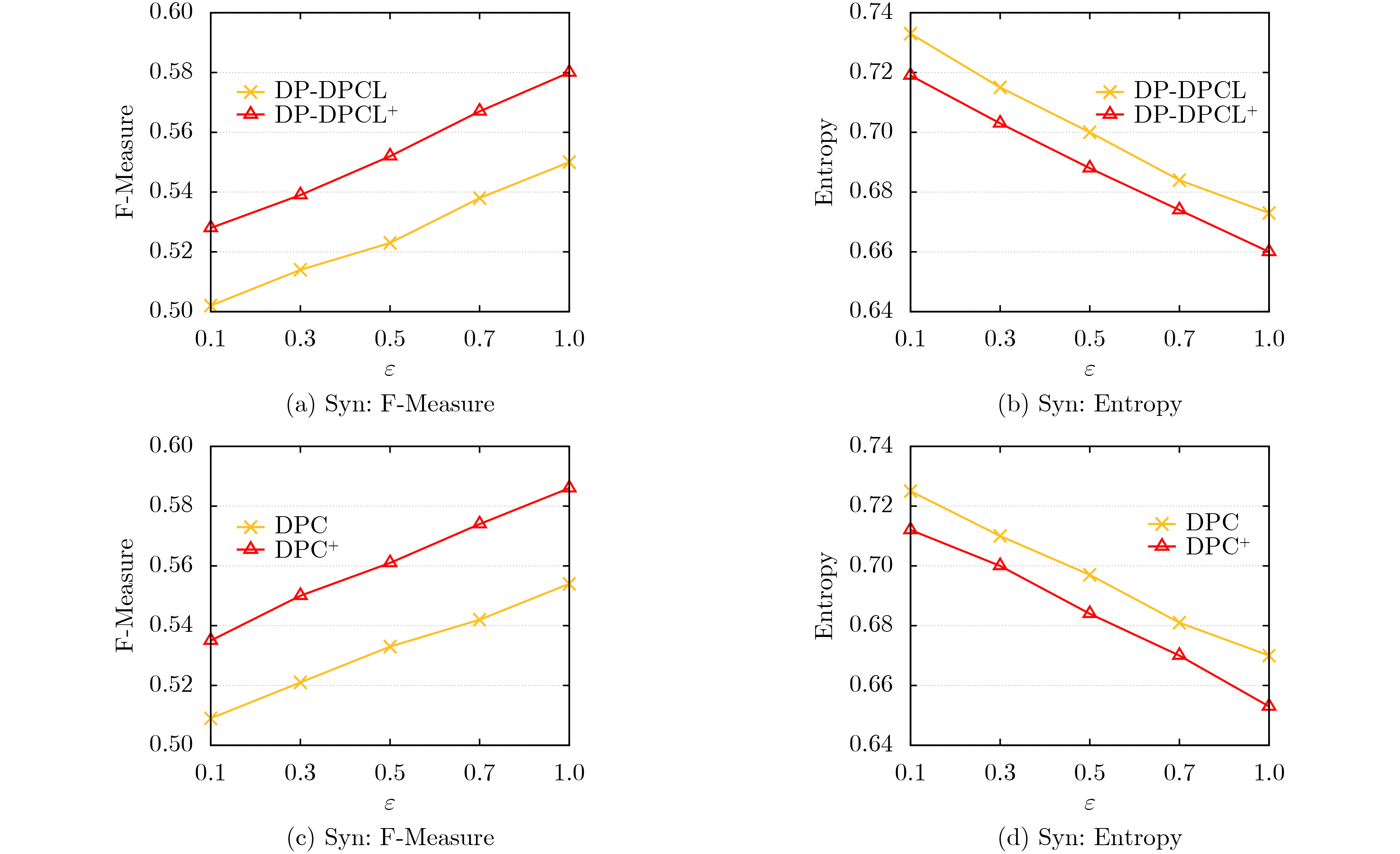
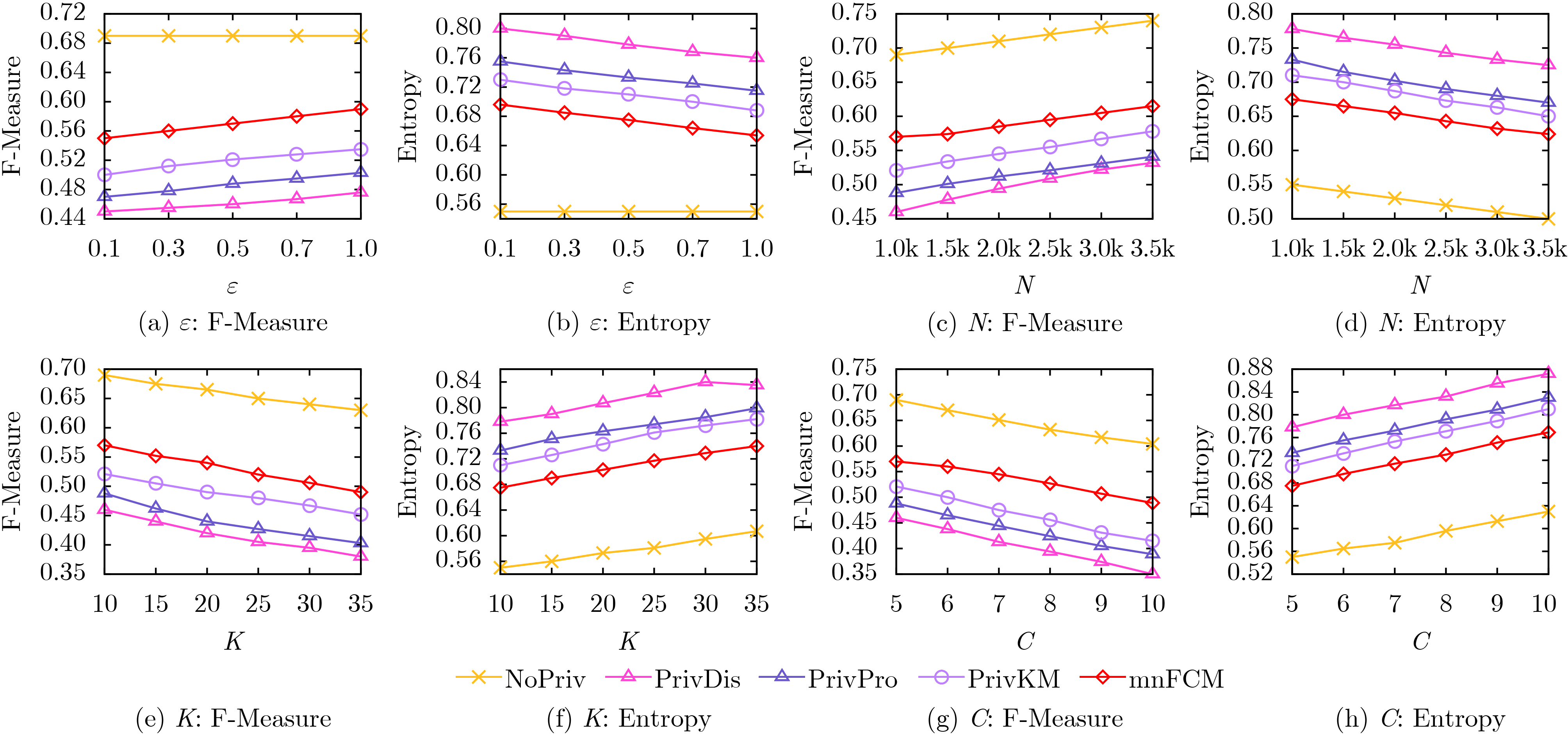
Objective In big data and Internet of Things (IoT) applications, clustering analysis of collected data is crucial for enhancing user experience. To mitigate privacy risks from using raw data directly, Local Differential Privacy (LDP) techniques are often employed. However, existing LDP clustering studies either require interactive execution, consuming significant privacy budgets, or fail to balance Gaussian noise in clustering data with Laplacian noise for LDP protection, resulting in low clustering accuracy. Moreover, distance metrics for similarity measurement are chosen arbitrarily without fully utilizing the noise characteristics of user-submitted noisy data. This study designs a hybrid noise-aware distance calculation method integrated into the fuzzy C-means clustering algorithm, effectively reducing noise impact on clustering results while protecting data privacy, ensuring both privacy security and clustering quality. It provides a robust solution for sensitive information processing in high-dimensional data environments. Methods This paper innovatively proposes a mixed noise-aware Fuzzy C-Means clustering algorithm (mnFCM) under LDP. The core idea is to model both Gaussian noise (representing data quality) and Laplacian noise (for data protection) in uploaded user data by constructing a more accurate mixed distribution model, and design a mixed noise-aware distance to replace Euclidean distance for measuring similarity between samples and cluster centers. Specifically, in mnFCM, this paper first designs a mixed noise-aware distance calculation method. On this basis, a new objective function for the algorithm is proposed, and a solution method is designed based on the Lagrange multiplier method. Finally, the convergence of the solution algorithm is theoretically analyzed. Results and Discussions The experimental results show that as the privacy budget ε increases, the performance of various clustering algorithms generally improves. Notably, mnFCM achieves at least a 8.5% improvement in accuracy compared to the state-of-the-art PrivPro algorithm ( Fig.1 ). This is because mnFCM innovatively considers both Gaussian noise (reflecting data quality) and Laplacian noise (for LDP protection), designing a hybrid noise-aware distance metric to enhance sample similarity measurement, thereby effectively protecting privacy while balancing clustering performance. Experiments on the fuzziness parameter m reveal that when m=2, all algorithms reach peak F-Measure values and lowest Entropy values (Fig.2 ), strongly validating m=2 as the optimal balance point for clustering effectiveness. Additionally, running time of mnFCM is 1.0 to 1.4 times that of the non-privacy-preserving Nopriv algorithm (Table 2 ), due to its refined noise processing mechanism. Ablation experiments demonstrate that the MixDis scheme achieves the best clustering performance on both NG and UW datasets (Fig.4 ), as it considers both Laplacian and Gaussian noise, making the clustered data more robust. Comparative analysis on the synthetic dataset Syn with other privacy-preserving clustering algorithms shows that DP-DPCL+ consistently outperforms DP-DPCL, and DPC+ consistently outperforms DPC (Fig.5 ). In addition, by varying the values of the four adjustable parameters—privacy budget ε, sample size N, dimension K, and cluster number C—it is evident that the mnFCM method outperforms other privacy protection schemes (Fig. 6 ).Conclusions This paper addresses the privacy protection issue in fuzzy clustering algorithms by simultaneously considering Gaussian noise (reflecting data quality) and Laplacian noise (for LDP protection), and innovatively proposes a mixed noise-aware fuzzy C-means clustering algorithm, mnFCM, satisfying LDP to balance privacy security and clustering quality. It designs a mixed noise-aware distance calculation method, formulates a new objective function, and solves it using the Lagrange multiplier method, while theoretically analyzing the algorithm’s convergence. Theoretical analysis shows that the algorithm strictly satisfies LDP, is closer to non-private cluster centroids compared to baseline algorithms, and has similar complexity to non-private algorithms. Experiments demonstrate that the algorithm improves clustering accuracy by 10%~15% on real datasets compared to baseline privacy-preserving algorithms. However, a limitation of this study is that the privacy budget calculation for Laplacian noise in the mixed noise setting may be influenced by Gaussian noise. In future research, the adaptive noise proportion allocation strategies, such as dynamically adjusting the weights of Gaussian/Laplacian noise, will be further explored to optimize the privacy-utility trade-off. -
表 1 常用符号列表
符号 符号含义 ε 隐私预算 C, N, K 簇、样本数据以及样本属性的个数 uci 样本数据的划分隶属度 Dci 样本数据与簇心间的混合噪音感知的距离 $ {x_i} $, pc 样本数据i、簇c的质心 $ {{\hat {\boldsymbol x}}_i} $ 加噪后的样本数据i m, γ 模糊度参数、收敛终止参数 $\tau $ 迭代阈值  下载: 导出CSV
下载: 导出CSV
1 mnFCM算法
输入:样本数据集X={x1,x2, ···, xN},模糊度参数m,收敛终止
参数γ,最大迭代次数τmax;输出:样本划分隶属度uci,簇心pc /*本地端*/ for i=1, 2, ··· , N do 调用Laplace机制对样本数据进行加噪; 用户将加噪后的样本数据$ {\hat {\boldsymbol x}}_i$上传给服务器; end for /*服务器端*/ 设置初始迭代次数:τ =0; 随机初始化uci使其满足0≤uci≤1; 迭代开始: 根据式(22)更新pc; 根据式(12)更新Dci; 根据式(18)更新uci; 更新迭代次数τ= τ+1; 迭代终止条件 max|uci(τ)–uci(τ–1)|≤γ或者τ =τmax。 return uci, pc;
下载: 导出CSV
表 2 算法运行时间对比
对比算法 NG (min) UW(s) NoPriv 5 8.33 PrivDis 19 23.67 PrivPro 26 44.36 PrivKM 24 34.63 mnFCM 7 8.42
下载: 导出CSV
-
[1] MISTRY H K, MAVANI C, GOSWAMI A, et al. The impact of cloud computing and AI on industry dynamics and competition[J]. Educational Administration: Theory and Practice, 2024, 30(7): 797–804. doi: 10.53555/kuey.v30i7.6851. [2] 常璐瑶, 牛新征, 罗涛, 等. 基于子博弈完美均衡的启发式聚类算法[J]. 电子学报, 2024, 52(3): 740–750. doi: 10.12263/DZXB.20221206.CHANG Luyao, NIU Xinzheng, LUO Tao, et al. Heuristic clustering algorithm based on sub-game perfect equilibrium[J]. Acta Electronica Sinica, 2024, 52(3): 740–750. doi: 10.12263/DZXB.20221206. [3] 黄鹤, 李文龙, 杨澜, 等. 跳跃跟踪SSA交叉迭代AP聚类算法[J]. 电子学报, 2024, 52(3): 977–990. doi: 10.12263/DZXB.20220209.HUANG He, LI Wenlong, YANG Lan, et al. Jump tracking SSA hybrid iterative AP clustering algorithm[J]. Acta Electronica Sinica, 2024, 52(3): 977–990. doi: 10.12263/DZXB.20220209. [4] 张强, 叶阿勇, 叶帼华, 等. 最优聚类的k-匿名数据隐私保护机制[J]. 计算机研究与发展, 2022, 59(7): 1625–1635. doi: 10.7544/issn1000-1239.20210117.ZHANG Qiang, YE Ayong, YE Guohua, et al. k-Anonymous data privacy protection mechanism based on optimal clustering[J]. Journal of Computer Research and Development, 2022, 59(7): 1625–1635. doi: 10.7544/issn1000-1239.20210117. [5] LIN Wanyu, LI Baochun, and WANG Cong. Towards private learning on decentralized graphs with local differential privacy[J]. IEEE Transactions on Information Forensics and Security, 2022, 17: 2936–2946. doi: 10.1109/TIFS.2022.3198283. [6] 傅培旺, 丁红发, 刘海, 等. 基于本地差分隐私的分布式图统计采集算法[J]. 计算机研究与发展, 2024, 61(7): 1643–1669. doi: 10.7544/issn1000-1239.202330628.FU Peiwang, DING Hongfa, LIU Hai, et al. Statistics collecting algorithms of distributed graph via local differential privacy[J]. Journal of Computer Research and Development, 2024, 61(7): 1643–1669. doi: 10.7544/issn1000-1239.202330628. [7] 李宗维, 孔德潮, 牛媛争, 等. 基于人工智能和区块链融合的隐私保护技术研究综述[J]. 信息安全研究, 2023, 9(6): 557–565. doi: 10.12379/j.issn.2096-1057.2023.06.08.LI Zongwei, KONG Dechao, NIU Yuanzheng, et al. Towards a privacy-preserving research for AI and blockchain integration[J]. Journal of Information Security Research, 2023, 9(6): 557–565. doi: 10.12379/j.issn.2096-1057.2023.06.08. [8] LUO Yuling, WANG Zhangrui, ZHANG Shunsheng, et al. Efficient-secure k-means clustering guaranteeing personalized local differential privacy[C]. 22nd International Conference on Algorithms and Architectures for Parallel Processing, Copenhagen, Denmark, 2023: 660–675. doi: 10.1007/978-3-031-22677-9_35. [9] 张少波, 原刘杰, 毛新军, 等. 基于本地差分隐私的K-modes聚类数据隐私保护方法[J]. 电子学报, 2022, 50(9): 2181–2188. doi: 10.12263/DZXB.20201374.ZHANG Shaobo, YUAN Liujie, MAO Xinjun, et al. Privacy protection method for K-modes clustering data with local differential privacy[J]. Acta Electronica Sinica, 2022, 50(9): 2181–2188. doi: 10.12263/DZXB.20201374. [10] XIA Chang, HUA Jingyu, TONG Wei, et al. Distributed K-Means clustering guaranteeing local differential privacy[J]. Computers & Security, 2020, 90: 101699. doi: 10.1016/j.cose.2019.101699. [11] LIN Aixin and MA Xuebin. PU_Bpub: High-dimensional data release mechanism based on spectral clustering with local differential privacy[C]. 17th International Conference on Wireless Algorithms, Systems, and Applications, Dalian, China, 2022: 572–581. doi: 10.1007/978-3-031-19214-2_48. [12] 张国鹏, 陈学斌, 王豪石, 等. 面向本地差分隐私的K-Prototypes聚类方法[J]. 计算机应用, 2022, 42(12): 3813–3821. doi: 10.11772/j.issn.1001-9081.2021101724.ZHANG Guopeng, CHEN Xuebin, WANG Haoshi, et al. K-Prototypes clustering method for local differential privacy[J]. Journal of Computer Applications, 2022, 42(12): 3813–3821. doi: 10.11772/j.issn.1001-9081.2021101724. [13] LI Weiqing, CHEN Hongyu, ZHAO Ruifeng, et al. A federated recommendation system based on local differential privacy clustering[C]. 2021 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/IOP/SCI), Atlanta, USA, 2021: 364–369. doi: 10.1109/SWC50871.2021.00056. [14] LI Yong, SONG Xiao, TU Yuchun, et al. GAPBAS: Genetic algorithm-based privacy budget allocation strategy in differential privacy K-means clustering algorithm[J]. Computers & Security, 2024, 139: 103697. doi: 10.1016/j.cose.2023.103697. [15] LIU Chao, ZHI Zhaolong, ZHAO Weinan, et al. Research on local fingerprint image differential privacy protection method based on clustering algorithm and regression algorithm segmentation image[J]. IEEE Access, 2024, 12: 27127–27146. doi: 10.1109/ACCESS.2024.3363494. [16] 石江南, 彭长根, 谭伟杰. Spark框架下支持差分隐私保护的K-means++聚类方法[J]. 信息安全研究, 2024, 10(8): 712–718. doi: 10.12379/j.issn.2096-1057.2024.08.04.SHI Jiangnan, PENG Changgen, and TAN Weijie. K-means++ clustering method supporting differential privacy protection in spark framework[J]. Journal of Information Security Research, 2024, 10(8): 712–718. doi: 10.12379/j.issn.2096-1057.2024.08.04. [17] WU Fuyu, DU Mingjing, and ZHI Qiang. Density-based clustering with differential privacy[J]. Information Sciences, 2024, 681: 121211. doi: 10.1016/j.ins.2024.121211. [18] FANG Shuhui, WAN Xuejun, WANG Jun, et al. HiDS Data clustering algorithm based on differential privacy[C]. 2024 International Conference on Networking and Network Applications (NaNA), Yinchuan, China, 2024: 131–136. doi: 10.1109/NaNA63151.2024.00029. [19] DIAA A, HUMPHRIES T, and KERSCHBAUM F. FastLloyd: Federated, accurate, secure, and tunable k-means clustering with differential privacy[EB/OL]. https://arxiv.org/abs/2405.02437, 2024. [20] SONG Haina, HAN Xinyu, LV Jie, et al. MPLDS: An integration of CP-ABE and local differential privacy for achieving multiple privacy levels data sharing[J]. Peer-to-Peer Networking and Applications, 2022, 15(1): 369–385. doi: 10.1007/s12083-021-01238-8. [21] YANG Wenjun and AL-MASRI E. ULDP: A user-centric local differential privacy optimization method[C]. 2024 IEEE World AI IoT Congress (AIIoT), Seattle, USA, 2024: 0316–0322. doi: 10.1109/AIIoT61789.2024.10579023. [22] 曾卓, 汪成亮, 马飞. 基于差分隐私的活动模式保护与时空轨迹发布方法[J]. 电子学报, 2023, 51(3): 552–563. doi: 10.12263/DZXB.20210631.ZENG Zhuo, WANG Chengliang, MA Fei. Differentially private activity pattern and spatial-temporal trajectory publication[J]. Acta Electronica Sinica, 2023, 51(3): 552–563. doi: 10.12263/DZXB.20210631. [23] HERNANDEZ-MATAMOROS A and KIKUCHI H. Comparative analysis of local differential privacy schemes in healthcare datasets[J]. Applied Sciences, 2024, 14(7): 2864. doi: 10.3390/app14072864. [24] DU Minxin, YUE Xiang, CHOW S S M, et al. Sanitizing sentence embeddings (and labels) for local differential privacy[C]. Proceedings of the ACM Web Conference 2023, New York, USA, 2023: 2349–2359. doi: 10.1145/3543507.3583512. [25] YANG Mengmeng, GUO Taolin, ZHU Tianqing, et al. Local differential privacy and its applications: A comprehensive survey[J]. Computer Standards & Interfaces, 2024, 89: 103827. doi: 10.1016/j.csi.2023.103827. [26] KRASNOV D, DAVIS D, MALOTT K, et al. Fuzzy C-means clustering: A review of applications in breast cancer detection[J]. Entropy, 2023, 25(7): 1021. doi: 10.3390/e25071021. [27] ALI N A, EL ABBASSI A, and BOUATTANE O. Performance evaluation of spatial fuzzy C-means clustering algorithm on GPU for image segmentation[J]. Multimedia Tools and Applications, 2023, 82(5): 6787–6805. doi: 10.1007/s11042-022-13635-z. [28] 徐久成, 侯钦臣, 瞿康林, 等. 面向时间序列的鲁棒性半监督模糊C均值聚类[J]. 计算机工程与应用, 2023, 59(8): 73–80. doi: 10.3778/j.issn.1002-8331.2207-0445.XU Jiucheng, HOU Qinchen, QU Kanglin, et al. Robust semi-supervised fuzzy C-means clustering for time series[J]. Computer Engineering and Applications, 2023, 59(8): 73–80. doi: 10.3778/j.issn.1002-8331.2207-0445. [29] ARORA J, TUSHIR M, and DADHWAL S K. A new suppression-based possibilistic fuzzy c-means clustering algorithm[J]. EAI Endorsed Transactions on Scalable Information Systems, 2023, 10(3): e3. doi: 10.4108/eetsis.v10i3.2057. [30] FANG Siguo, HUANG Dong, CAI Xiaosha, et al. Efficient multi-view clustering via unified and discrete bipartite graph learning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(8): 11436–11447. doi: 10.1109/TNNLS.2023.3261460. [31] JAEGER A and BANKS D. Cluster analysis: A modern statistical review[J]. WIREs Computational Statistics, 2023, 15(3): e1597. doi: 10.1002/wics.1597. [32] BESHARATNIA F, TALEBPOUR A, and ALIAKBARY S. An improved grey wolves optimization algorithm for dynamic community detection and data clustering[J]. Applied Artificial Intelligence, 2022, 36(1): 2012000. doi: 10.1080/08839514.2021.2012000. [33] ALEMAZKOOR N, TOOTKABONI M, NATEGHI R, et al. Smart-meter big data for load forecasting: An alternative approach to clustering[J]. IEEE Access, 2022, 10: 8377–8387. doi: 10.1109/ACCESS.2022.3142680. [34] ZHAO Wenhao, MA Jin, LIU Qiyuan, et al. Comparison and application of SOFM, fuzzy c-means and k-means clustering algorithms for natural soil environment regionalization in China[J]. Environmental Research, 2023, 216: 114519. doi: 10.1016/j.envres.2022.114519. [35] 葛丽娜, 陈圆圆, 王捷, 等. 改进的密度峰值聚类算法的差分隐私保护方案[J]. 郑州大学学报: 工学版, 2023, 44(6): 19–24. doi: 10.13705/j.issn.1671-6833.2023.03.010.GE Lina, CHEN Yuanyuan, WANG Jie, et al. Differential privacy protection scheme of adaptive clustering by fast search and find of density peaks[J]. Journal of Zhengzhou University: Engineering Science, 2023, 44(6): 19–24. doi: 10.13705/j.issn.1671-6833.2023.03.010. [36] CHEN Hua, ZHOU Yuan, MEI Kehui, et al. A new density peak clustering algorithm with adaptive clustering center based on differential privacy[J]. IEEE Access, 2023, 11: 1418–1431. doi: 10.1109/ACCESS.2022.3233196. -

 下载:
下载:



图(6) / 表(3)
计量
- 文章访问数: 865
- HTML全文浏览量: 559
- PDF下载量: 64
- 被引次数: 0
