

A Few-Shot Land Cover Classification Model for Remote Sensing Images Based on Multimodality
-
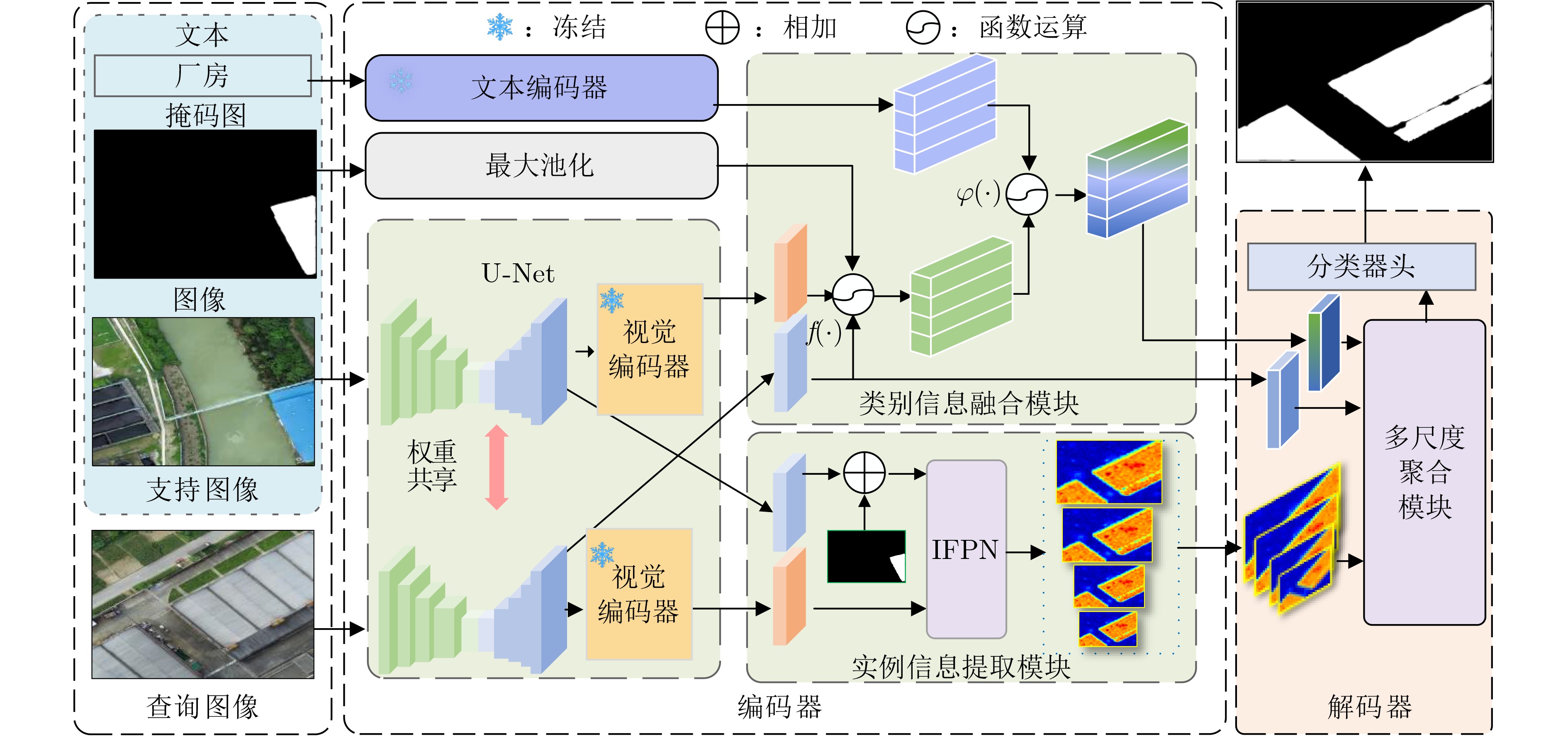
摘要: 针对遥感影像覆盖范围大、标注困难、类别融合适配度弱的问题,该文提出一种基于图像-文本多模态融合的小样本语义分割网络模型(FSSNet),采用编解码结构,编码器提取、语义对齐图像-文本多模态特征,并引入类别信息融合模块、实例信息提取模块。其中利用相关性原理设计基于对比语言-图像预训练(CLIP)模型的类别信息融合模块以增强查询图像与支持图像、文本间类别的适配;利用支持图像的实例目标区域作为先验提示,设计基于改进金字塔特征网络(IFPN)的实例信息提取模块,以提高查询图像目标区域分割的完整性。解码器引入多尺度特征融合的语义聚合模块,聚合类别信息、多尺度实例位置信息和查询图像特征,准确识别地物语义类别。在小样本语义分割数据集PASCAL-5i,公共遥感影像地物分类数据集LoveDA, Postdam和Vaihingen进行实验,该文FSSNet模型在PASCAL-5i数据集上的1-shot, 5-shot的平均交并比(mIoU)精度超越多信息聚合网络(MIANet),优于最佳水平(SOTA)模型分别为2.29%, 1.96%;在数据集LoveDA, Postdam和Vaihingen上的mIoU精度,优于SOTA模型分别为2.1%, 1.4%, 1.9%。在水利工程实际场景构建数据集HERSD,并进行实验,该文FSSNet模型的mIoU精度高于SOTA模型1.89%。结果表明该文FSSNet模型在遥感影像小样本地物分类、水利实际场景具有更高的分类识别精度。Abstract:
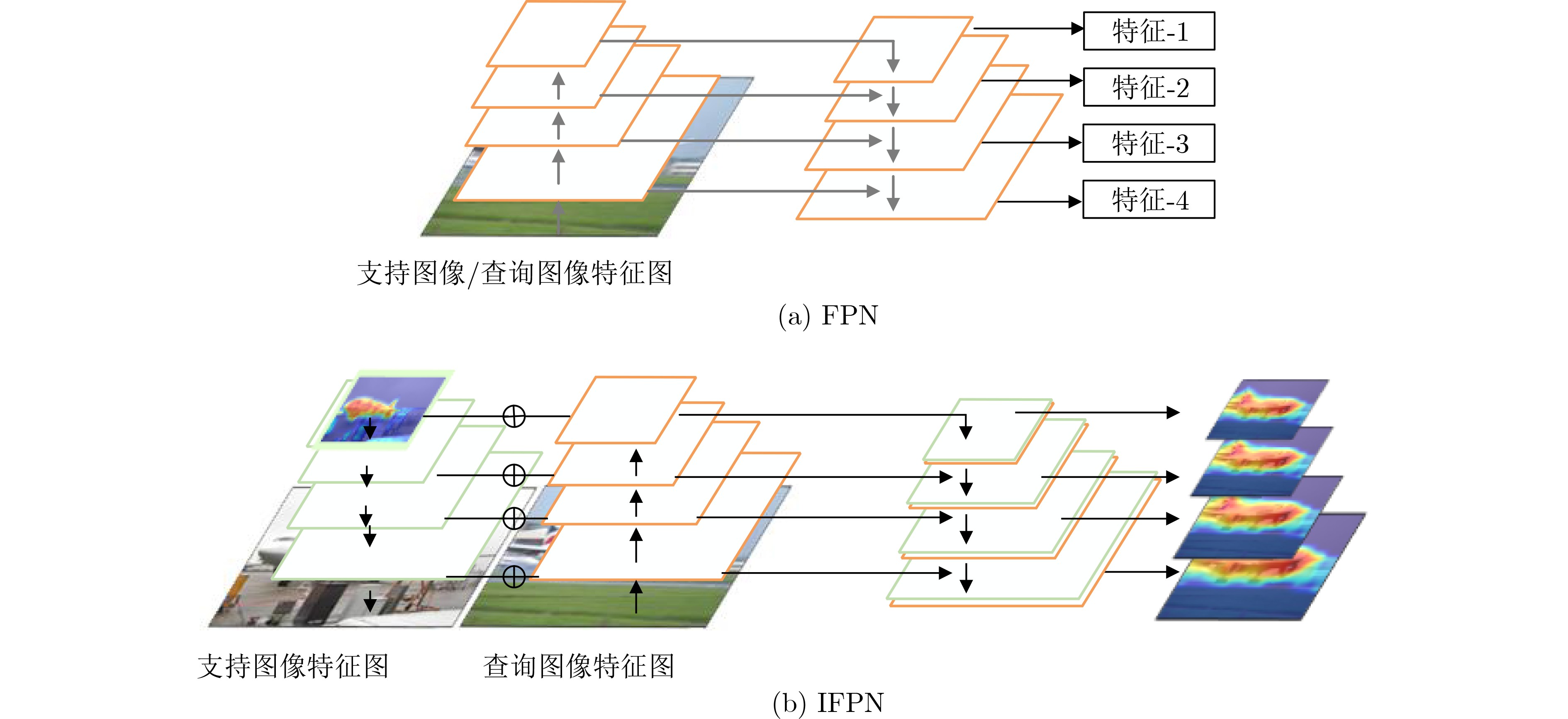
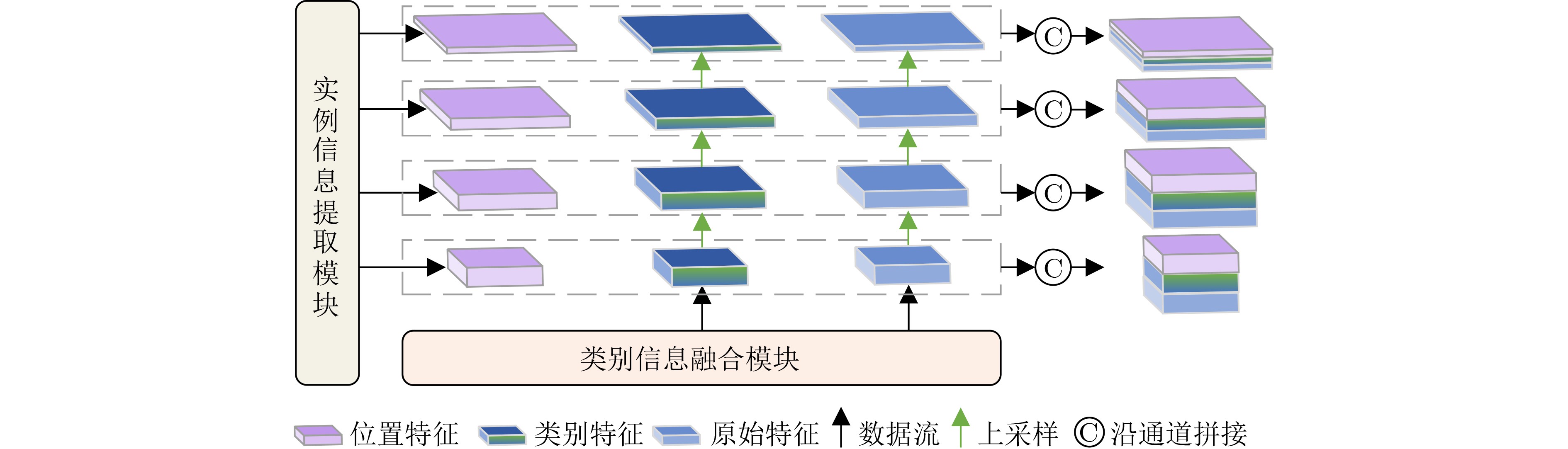
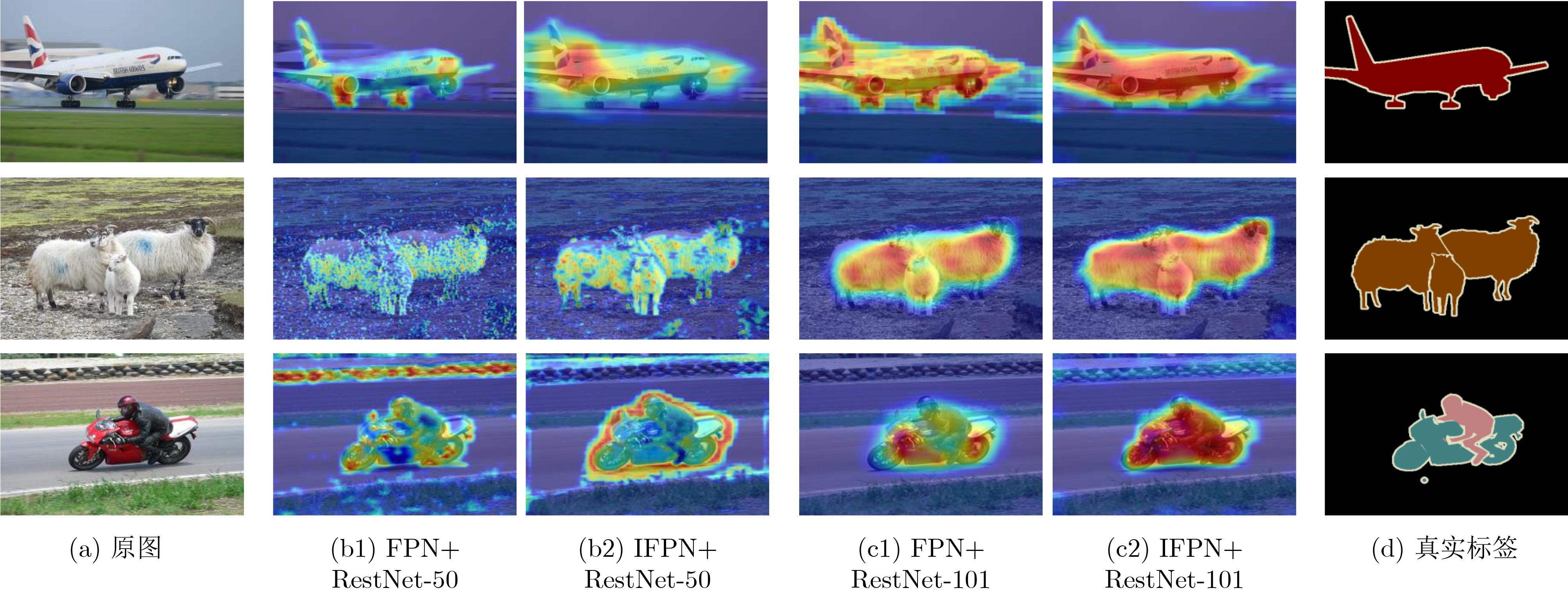
Objective To address the challenges of broad coverage, limited sample annotation, and poor adaptability in category fusion for remote sensing images, this paper proposes a few-shot semantic segmentation model based on image-text multimodal fusion, termed the Few-shot Semantic Segmentation Network (FSSNet). FSSNet is designed to effectively utilize multimodal information to improve generalization and segmentation accuracy under data-scarce conditions. Methods The proposed model, FSSNet, adopts a classic encoder-decoder architecture. The encoder serves as the central component, extracting features from both remote sensing images and associated text. An interaction mechanism is introduced to semantically align and fuse these multimodal features, generating enriched semantic representations. Within the encoder, two modules are incorporated: a class information fusion module and an instance information extraction module. The class information fusion module is developed based on the CLIP model and leverages correlation principles to enhance the adaptation between support and query image-text pairs. Simultaneously, inspired by the pyramid feature structure, an improved version, referred to as IFPN, is constructed. The instance information extraction module, built upon IFPN, captures detailed regional features of target instances from support images. These instance areas serve as prior prompts to guide the recognition and segmentation of corresponding regions in query images. The IFPN further provides semantic context and fine-grained spatial details, enhancing the completeness and boundary precision of object detection and segmentation in query images. The decoder integrates class-level information, multi-scale instance features, and query image features through a semantic aggregation module operating at multiple scales. This module outputs four levels of aggregated features by concentrating inputs at different resolutions. Large-scale features, with higher resolution, improve the detection of small target regions, whereas small-scale features, with lower resolution and broader receptive fields, are better suited for identifying large targets. The integration of multi-scale features improves segmentation accuracy across varying object sizes. This framework enables few-shot classification and segmentation of land cover in remote sensing images by leveraging image–text multimodality. Results and Discussions To evaluate the performance of the proposed FSSNet model, extensive experiments are conducted on multiple representative datasets. On the standard few-shot semantic segmentation benchmark PASCAL-5i, FSSNet is compared with several mainstream models, including the Multi-Information Aggregation Network (MIANet). Under both 1-shot and 5-shot settings, FSSNet achieves higher mean Intersection over Union (mIoU) scores, exceeding State-Of-The-Art (SOTA) models by 2.29% and 1.96%, respectively. Further evaluation on three public remote sensing datasets—LoveDA, Postdam, and Vaihingen—demonstrates model generalization across domains. FSSNet outperforms existing methods, with mIoU improvements of 2.1%, 1.4%, and 1.9%, respectively. For practical applicability, a custom dataset (HERSD) is constructed for hydraulic engineering, comprising various types of hydraulic infrastructure and land cover. On HERSD, FSSNet maintains robust performance, exceeding SOTA models by 1.89% in mIoU accuracy. Overall, the results indicate that FSSNet provides effective and robust performance in both standard benchmarks and real-world remote sensing tasks under few-shot learning conditions. Conclusions This paper presents a novel FSSNet for remote sensing images, FSSNet, which demonstrates strong performance in data-constrained scenarios through the integration of image–text multimodal information and three specifically designed modules. Experimental results on multiple public and custom datasets confirm the effectiveness and robustness of the proposed approach, particularly in few-shot and small-sample object classification tasks, as well as in practical land cover classification applications. The proposed framework offers new perspectives and practical solutions for few-shot learning and cross-modal information fusion in remote sensing, facilitating broader adoption of remote sensing image analysis in real-world settings. Future work will focus on extending the model to zero-shot land cover classification by exploring additional multimodal data sources and more efficient feature fusion strategies. -
Key words:
- Remote sensing image /
- Land cover classification /
- Few-shot learning /
- Multimodality
-
表 1 遥感影像语义分割数据集的详细信息
数据集 数量 类别数量 原始尺寸 LoveDA 6 017 7 1 024×1 024 Postdam 44 6 3 000×6 000 Vaihingen 39 6 2 494×2 064  下载: 导出CSV
下载: 导出CSV
表 5 在数据集PASCAL-5i上不同模块mIoU性能的消融合实验(%)
类别信息CIM 实例信息IIM 特征聚合MAM Fold-0 Fold-1 Fold-2 Fold-3 mIoU 63.21 68.76 61.20 54.27 61.86 √ 65.45 70.12 62.85 56.42 63.71 √ 66.89 71.42 64.32 59.90 65.63 √ 64.78 69.48 63.10 55.36 63.18 √ √ 68.71 72.89 65.44 62.16 67.30↑5.44 √ √ 67.54 71.29 64.67 59.82 65.83↑3.97 √ √ 68.92 73.05 66.23 62.84 67.76↑5.90 √ √ √ 74.52 75.63 71.88 65.45 71.87↑10.01
下载: 导出CSV
表 6 本文FSSNet模型与主流小样本分割模型在PASCAL-5i$ \text{PASCAL-}{\text{5}}^{\text{i}} $数据集上的对比实验结果(%)
方法 1-shot 5-shot Fold-0 Fold-1 Fold-2 Fold-3 mIoU Fold-0 Fold-1 Fold-2 Fold-3 mIoU PFENET(IEEE’20)[40] 61.70 69.50 55.40 56.30 60.80 63.10 70.70 55.80 57.90 61.90 HSNet(arXiv’23)[41] 64.30 70.70 60.30 60.50 64.00 70.30 73.20 67.40 67.10 69.50 DPCN(CVPR’22)[42] 65.70 71.60 69.10 60.60 66.70 70.00 73.20 70.90 65.50 69.90 BAM(CVPR’22)[43] 68.97 73.59 67.55 61.13 67.81 70.59 75.05 70.79 67.20 70.91 NTRENet(CVPR’22)[44] 65.40 72.30 59.40 59.80 64.20 66.20 72.80 61.70 62.20 65.70 MIANet(CVPR’23)[17] 68.51 75.76 67.46 63.15 68.72 70.20 77.38 70.02 68.77 71.59 PMNet(IEEE/CVE’24)[45] 72.00 72.00 62.40 59.90 65.40 73.60 74.60 69.90 67.20 71.30 Baseline 63.21 68.76 61.20 54.27 61.86 66.64 69.78 64.28 63.17 65.97 FSSNet(本文) 73.63 74.59 70.55 65.28 71.01 73.52 73.84 75.36 71.47 73.55
下载: 导出CSV
表 7 在LoveDA, Potsdam和Vaihingen遥感数据集的对比结果(%)
方法 mIoU LoveDA Postdam Vaihingen UNet++(Springer’18)[3] 批量样本 48.2 83.9 75.8 DeepLabV3+(ECCV’18)[35] 47.6 83.4 81.3 SwinUperNet(CVPR’21)[36] 50.0 85.8 78.6 DC-Swin(IEEE’22)[37] 50.6 84.4 80.4 UNetFormer(ISPRS’22)[38] 52.4 86.8 82.7 Hi-ResNet(arXiv’23)[39] 52.5 86.1 79.8 GeoRSCLIP(TGRS’24)[46] Zero-shot 30.8 38.0 22.3 SegEarth-OV(IEEE’24)[47] 36.9 47.1 29.1 MIANet(CVPR’23)[17] 1-shot 51.2 85.5 81.0 FSSNet(本文) 54.6 88.2 84.6
下载: 导出CSV
表 8 HERSD数据集的详细信息
空间分辨率 切分尺寸 切分方式 图像数量 10 cm 1 024×1 024 均分网格 5 850 滑动窗口 5 850 中心膨胀缩小 17 550
下载: 导出CSV
表 10 HERSD数据集测试结果(%)
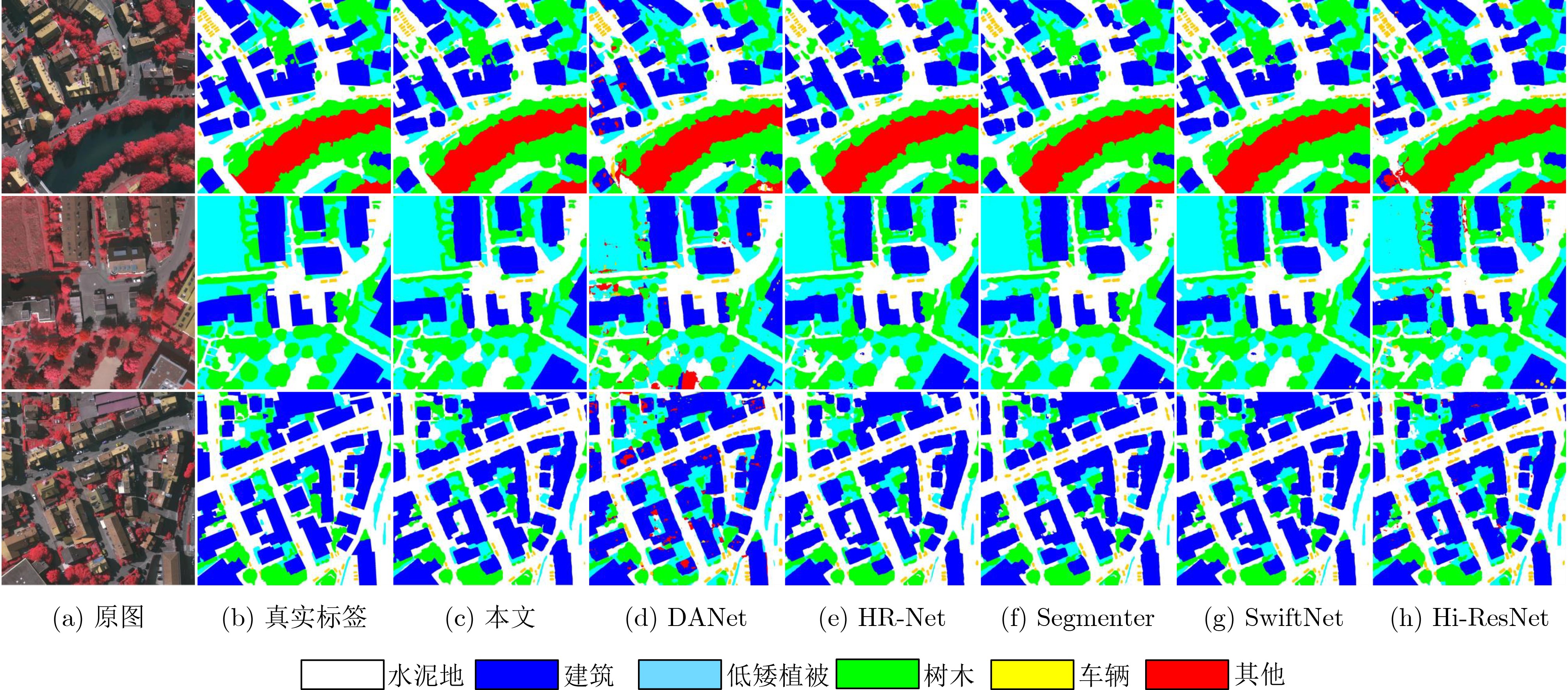
模型 植被 裸土地 水泥地 旱地 棚房 混泥土房 加固斜坡 水域 大坝 mIoU UNet++(Springer’18)[3] 76.4 77.1 82.6 81.5 69.3 64.9 58.0 74.8 77.7 73.37 HRNet(IEEE’20)[49] 78.6 81.4 83.9 83.6 79.1 72.1 61.3 80.9 86.2 78.36 SwinUperNet(CVPR’21)[36] 81.2 85.5 80.2 83.8 79.8 71.1 63.4 81.2 85.0 79.21 DC-Swin(IEEE’22)[37] 85.0 82.2 85.3 85.5 88.7 69.4 59.1 86.2 88.4 81.50 UNetFormer(ISPRS’22)[38] 79.7 85.0 86.8 76.5 82.9 74.7 64.7 82.4 86.2 79.45 Hi-ResNet(arXiv’23)[39] 83.7 83.1 82.3 80.5 87.8 76.2 67.9 86.9 84.1 82.04 FSSNet(本文) 86.9 85.3 87.1 86.4 86.2 77.4 67.4 85.7 88.6 83.93
下载: 导出CSV
-
[1] 谢雯, 王若男, 羊鑫, 等. 融合深度可分离卷积的多尺度残差UNet在PolSAR地物分类中的研究[J]. 电子与信息学报, 2023, 45(8): 2975–2985. doi: 10.11999/JEIT220867.XIE Wen, WANG Ruonan, YANG Xin, et al. Research on multi-scale residual UNet fused with depthwise separable convolution in PolSAR terrain classification[J]. Journal of Electronics & Information Technology, 2023, 45(8): 2975–2985. doi: 10.11999/JEIT220867. [2] LONG J, SHELHAMER E, and DARRELL T. Fully convolutional networks for semantic segmentation[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015. doi: 10.1109/CVPR.2015.7298965. [3] ZHOU Zongwei, RAHMAN SIDDIQUEE M, TAJBAKHSH N, et al. UNet++: A nested U-Net architecture for medical image segmentation[C]. The 4th International Workshop Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Granada, Spain, 2018. doi: 10.1007/978-3-030-00889-5_1. [4] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834–848. doi: 10.1109/TPAMI.2017.2699184. [5] SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]. The 3rd International Conference on Learning Representations, San Diego, USA, 2015. [6] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016. doi: 10.1109/CVPR.2016.90. [7] XU Zhiyong, ZHANG Weicun, ZHANG Tianxiang, et al. Efficient transformer for remote sensing image segmentation[J]. Remote Sensing, 2021, 13(18): 3585. doi: 10.3390/rs13183585. [8] MA Xianping, ZHANG Xiaokang, PUN M O, et al. A multilevel multimodal fusion transformer for remote sensing semantic segmentation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5403215. doi: 10.1109/TGRS.2024.3373033. [9] CRESWELL A, WHITE T, DUMOULIN V, et al. Generative adversarial networks: An overview[J]. IEEE Signal Processing Magazine, 2018, 35(1): 53–65. doi: 10.1109/MSP.2017.2765202. [10] PAN S J and YANG Qiang. A survey on transfer learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345–1359. doi: 10.1109/TKDE.2009.191. [11] 陈龙, 张建林, 彭昊, 等. 多尺度注意力与领域自适应的小样本图像识别[J]. 光电工程, 2023, 50(4): 220232. doi: 10.12086/oee.2023.220232.CHEN Long, ZHANG Jianlin, PENG Hao, et al. Few-shot image classification via multi-scale attention and domain adaptation[J]. Opto-Electronic Engineering, 2023, 50(4): 220232. doi: 10.12086/oee.2023.220232. [12] RAKELLY K, SHELHAMER E, DARRELL T, et al. Few-shot segmentation propagation with guided networks[J]. arXiv preprint arXiv: 1806.07373, 2018. [13] ZHANG Chi, LIN Guosheng, LIU Fayao, et al. CANet: Class-agnostic segmentation networks with iterative refinement and attentive few-shot learning[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019. doi: 10.1109/CVPR.2019.00536. [14] 刘晓敏, 余梦君, 乔振壮, 等. 面向多源遥感数据分类的尺度自适应融合网络[J]. 电子与信息学报, 2024, 46(9): 3693–3702. doi: 10.11999/JEIT240178.LIU Xiaomin, YU Mengjun, QIAO Zhenzhuang, et al. Scale adaptive fusion network for multimodal remote sensing data classification[J]. Journal of Electronics & Information Technology, 2024, 46(9): 3693–3702. doi: 10.11999/JEIT240178. [15] LI Boyi, WEINBERGER K Q, BELONGIE S J, et al. Language-driven semantic segmentation[C]. The 10th International Conference on Learning Representations, 2022. [16] XU Mengde, ZHANG Zheng, WEI Fangyun, et al. A simple baseline for open-vocabulary semantic segmentation with pre-trained vision-language model[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022. doi: 10.1007/978-3-031-19818-2_42. [17] YANG Yong, CHEN Qiong, FENG Yuan, et al. MIANet: Aggregating unbiased instance and general information for few-shot semantic segmentation[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023. doi: 10.1109/CVPR52729.2023.00689. [18] RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]. The 38th International Conference on Machine Learning, 2021. [19] LIN Bingqian, ZHU Yi, CHEN Zicong, et al. ADAPT: Vision-language navigation with modality-aligned action prompts[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022. doi: 10.1109/CVPR52688.2022.01496. [20] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017. doi: 10.1109/CVPR.2017.106. [21] EVERINGHAM M, VAN GOOL L, WILLIAMS C K I, et al. The PASCAL visual object classes (VOC) challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303–338. doi: 10.1007/s11263-009-0275-4. [22] WANG Junjue, ZHENG Zhuo, MA Ailong, et al. LoveDA: A remote sensing land-cover dataset for domain adaptive semantic segmentation[C]. The 1st Neural Information Processing Systems Track on Datasets and Benchmarks, 2021. [23] KRIZHEVSKY A. Convolutional deep belief networks on cifar-10[J]. Unpublished Manuscript, 2010, 40(7): 1–9. [24] HENDRYCKS D and DIETTERICH T G. Benchmarking neural network robustness to common corruptions and perturbations[C]. The 7th International Conference on Learning Representations, New Orleans, USA, 2019. [25] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C]. The 9th International Conference on Learning Representations, 2021. [26] OQUAB M, DARCET T, MOUTAKANNI T, et al. DINOv2: Learning robust visual features without supervision[J]. Transactions on Machine Learning Research Journal, 2024. [27] GESMUNDO A and DEAN J. An evolutionary approach to dynamic introduction of tasks in large-scale multitask learning systems[J]. arXiv preprint arXiv: 2205.12755, 2022. [28] YUAN Kun, GUO Shaopeng, LIU Ziwei, et al. Incorporating convolution designs into visual transformers[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021. doi: 10.1109/ICCV48922.2021.00062. [29] DAGLI R. Astroformer: More Data Might not be all you need for Classification[J]. arXiv preprint arXiv: 2304.05350, 2023. [30] LEE M, KIM D, and SHIM H. Threshold matters in WSSS: Manipulating the activation for the robust and accurate segmentation model against thresholds[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022. doi: 10.1109/CVPR52688.2022.00429. [31] RONG Shenghai, TU Bohai, WANG Zilei, et al. Boundary-enhanced Co-training for weakly supervised semantic segmentation[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023. doi: 10.1109/CVPR52729.2023.01875. [32] CHEN Zhaozheng and SUN Qianru. Extracting class activation maps from non-discriminative features as well[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023. doi: 10.1109/CVPR52729.2023.00306. [33] HAN W, KANG S, CHOO K, et al. CoBra: Complementary branch fusing class and semantic knowledge for robust weakly supervised semantic segmentation[J]. arXiv preprint arXiv: 2403.08801, 2024. [34] SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: Visual explanations from deep networks via gradient-based localization[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017. doi: 10.1109/ICCV.2017.74. [35] CHEN L C, ZHU Yukun, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018. doi: 10.1007/978-3-030-01234-2_49. [36] LIU Ze, LIN Yutong, CAO Yue, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021. doi: 10.1109/ICCV48922.2021.00986. [37] WANG Libo, LI Rui, DUAN Chenxi, et al. A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images[J]. IEEE Geoscience and Remote Sensing Letters, 2022, 19: 6506105. doi: 10.1109/LGRS.2022.3143368. [38] WANG Libo, LI Rui, ZHANG Ce, et al. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 190: 196–214. doi: 10.1016/j.isprsjprs.2022.06.008. [39] CHEN Yuxia, FANG Pengcheng, YU Jianhui, et al. Hi-ResNet: Edge detail enhancement for high-resolution remote sensing segmentation[J]. arXiv preprint arXiv: 2305.12691, 2023. [40] TIAN Zhuotao, ZHAO Hengshuang, SHU M, et al. Prior guided feature enrichment network for few-shot segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(2): 1050–1065. doi: 10.1109/TPAMI.2020.3013717. [41] WANG Haohan, LIU Liang, ZHANG Wuhao, et al. Iterative few-shot semantic segmentation from image label text[C]. The 31st International Joint Conference on Artificial Intelligence, Vienna, Austria, 2022. doi: 10.24963/ijcai.2022/193. [42] LIU Jie, BAO Yanqi, XIE Guosen, et al. Dynamic prototype convolution network for few-shot semantic segmentation[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022. doi: 10.1109/CVPR52688.2022.01126. [43] LANG Chunbo, CHENG Gong, TU Binfei, et al. Learning what not to segment: A new perspective on few-shot segmentation[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022. doi: 10.1109/CVPR52688.2022.00789. [44] LIU Yuanwei, LIU Nian, CAO Qinglong, et al. Learning non-target knowledge for few-shot semantic segmentation[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022. doi: 10.1109/CVPR52688.2022.01128. [45] CHEN Hao, DONG Yonghan, LU Zheming, et al. Pixel matching network for cross-domain few-shot segmentation[C]. 2024 IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2024. doi: 10.1109/WACV57701.2024.00102. [46] ZHANG Zilun, ZHAO Tiancheng, GUO Yulong, et al. RS5M and GeoRSCLIP: A large-scale vision- language dataset and a large vision-language model for remote sensing[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5642123. doi: 10.1109/TGRS.2024.3449154. [47] LI Kaiyu, LIU Ruixun, CAO Xiangyong, et al. SegEarth-OV: Towards training-free open-vocabulary segmentation for remote sensing images[J]. arXiv preprint arXiv: 2410.01768, 2024. [48] 方秀秀, 黄旻, 王德志, 等. 基于高程和地物光谱约束的多光谱图像预处理算法[J]. 半导体光电, 2020, 41(2): 264–267, 272. doi: 10.16818/j.issn1001-5868.2020.02.023.FANG Xiuxiu, HUANG Min, WANG Dezhi, et al. Multispectral image preprocessing based on elevation and surface feature spectrum constraints[J]. Semiconductor Optoelectronics, 2020, 41(2): 264–267, 272. doi: 10.16818/j.issn1001-5868.2020.02.023. [49] WANG Jingdong, SUN Ke, CHENG Tianheng, et al. Deep high-resolution representation learning for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(10): 3349–3364. doi: 10.1109/TPAMI.2020.2983686. -

 下载:
下载:











图(14) / 表(10)
计量
- 文章访问数: 1283
- HTML全文浏览量: 793
- PDF下载量: 108
- 被引次数: 0
