

A Model-Assisted Federated Reinforcement Learning Method for Multi-UAV Path Planning
-
摘要: 针对多无人机在环境监测传感器网络、灾害应急通信节点等设备位置部分未知场景下的数据收集需求,该文提出一种模型辅助的联邦强化学习多无人机路径规划方法。在联邦学习框架下,通过结合最大熵强化学习与单调价值函数分解机制,引入动态熵温度参数和注意力机制,优化了多无人机协作的探索效率与策略稳定性。此外,设计了一种基于信道建模与位置估计的混合模拟环境构建方法,利用改进的粒子群算法快速估计未知设备位置,显著降低了真实环境交互成本。仿真结果表明,所提算法能够实现高效数据收集,相较于传统多智能体强化学习方法,数据收集率提升5.2%,路径长度减少7.7%,验证了所提算法的有效性和优越性。Abstract:
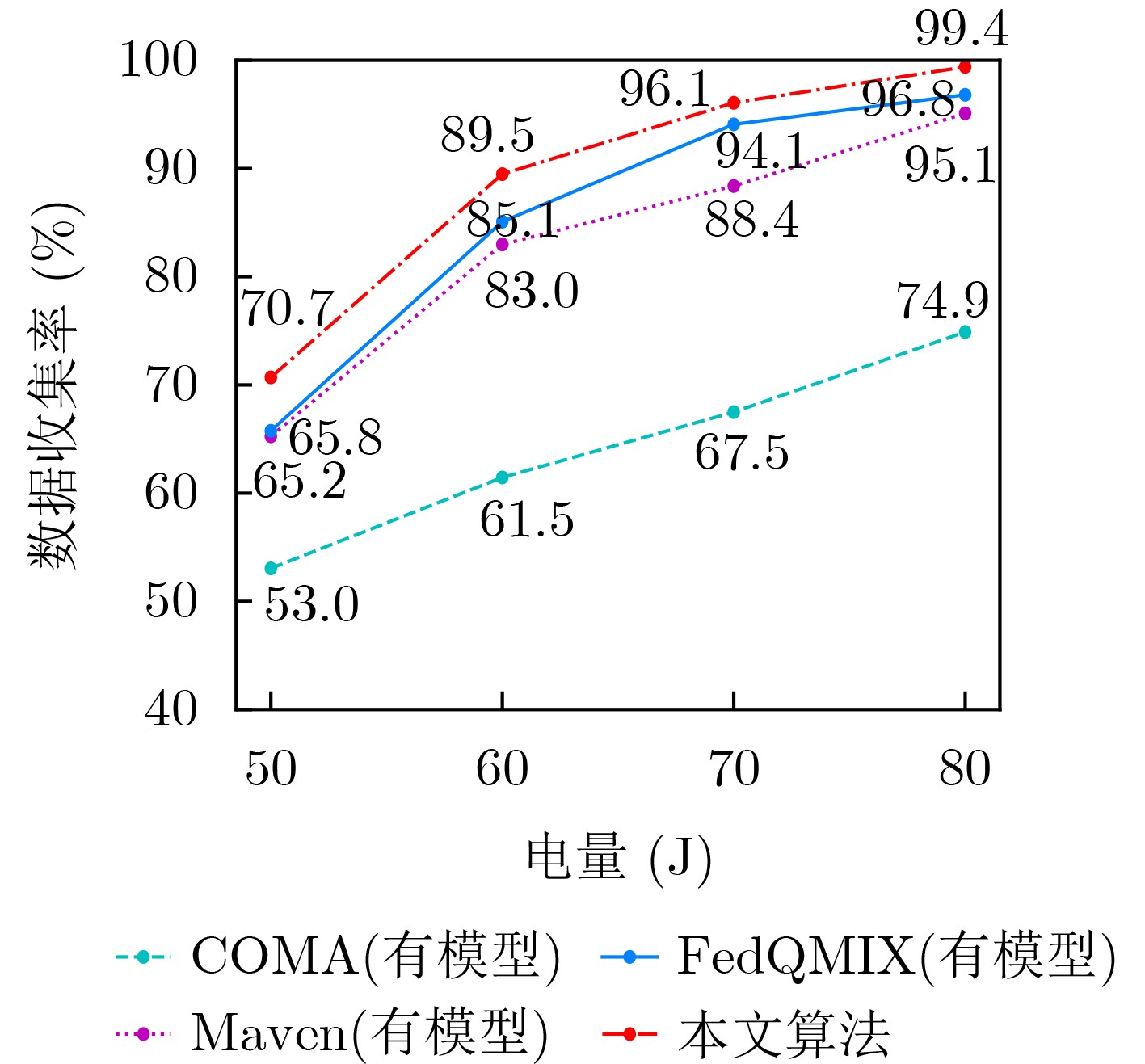
Objective The rapid advancement of low-altitude Internet of Things (IoT) applications has increased the demand for efficient sensor data acquisition. Unmanned Aerial Vehicles (UAVs) have emerged as a viable solution due to their high mobility and deployment flexibility. However, existing multi-UAV path planning algorithms show limited adaptability and coordination efficiency in dynamic and complex environments. To overcome these limitations, this study develops a model-assisted approach that constructs a hybrid simulated environment by integrating channel modeling with position estimation. This strategy reduces the interaction cost between UAVs and the real world. Building on this, a federated reinforcement learning-based algorithm is proposed, which incorporates a maximum entropy strategy, monotonic value function decomposition, and a federated learning framework. The method is designed to optimize two objectives: maximizing the data collection rate and minimizing the flight path length. The proposed algorithm provides a scalable and efficient solution for cooperative multi-UAV path planning under dynamic and uncertain conditions. Methods This study formulates the multi-UAV path planning problem as a multi-objective optimization task and models it using a Decentralized Partially Observable Markov Decision Process (Dec-POMDP) to address dynamic environments with partially unknown device positions. To improve credit assignment and exploration efficiency, enhanced reinforcement learning algorithms are developed. The exploration capacity of individual agents is increased using a maximum entropy strategy, and a dynamic entropy regularization mechanism is incorporated to avoid premature convergence. To ensure global optimality of the cooperative strategy, the method integrates monotonic value function decomposition based on the QMIX algorithm. A multi-dimensional reward function is designed to guide UAVs in balancing competing objectives, including data collection, path length, and device exploration. To reduce interaction costs in real environments, a model-assisted training framework is established. This framework combines known information with neural networks to learn channel characteristics and applies an improved particle swarm algorithm to estimate unknown device locations. To enhance generalization, federated learning is employed to aggregate local experiences from multiple UAVs into a global model through periodic updates. In addition, an attention mechanism is introduced to optimize inter-agent information aggregation, improving the accuracy of collaborative decision-making. Results and Discussions Simulation results demonstrate that the proposed algorithm converges more rapidly and with reduced volatility (red curves in Fig. 3 andFig. 4 ), due to a 70% reduction in interactions with the real environment achieved by the model-assisted framework. The federated learning mechanism further enhances policy generalization through global model aggregation. Under test conditions with an initial energy of 50~80 J, the data collection rate increases by 2.1~7.4%, and the flight path length decreases by 6.9~14.4% relative to the baseline model (Fig. 6 andFig. 7 ), confirming the effectiveness of the reward function and exploration strategy (Fig. 5 ). The attention mechanism allows UAVs to identify dependencies among sensing targets and cooperative agents, improving coordination. As shown inFig. 2 , the UAVs dynamically partition the environment to cover undiscovered devices, reducing path overlap and significantly improving collaborative efficiency.Conclusions This study proposes a model-assisted multi-UAV path planning method that integrates maximum entropy reinforcement learning, the QMIX algorithm, and federated learning to address the multi-objective data collection problem in complex environments. By incorporating modeling, dynamic entropy adjustment, and an attention mechanism within the Dec-POMDP framework, the approach effectively balances exploration and exploitation while resolving collaborative credit assignment in partially observable settings. The use of federated learning for distributed training and model sharing reduces communication overhead and enhances system scalability. Simulation results demonstrate that the proposed algorithm achieves superior performance in data collection efficiency, path optimization, and training stability compared with conventional methods. Future work will focus on coordination of heterogeneous UAV clusters and robustness under uncertain communication conditions to further support efficient data collection for low-altitude IoT applications. -
Key words:
- UAV /
- Path planning /
- Reinforcement learning /
- Federated Learning (FL) /
- Model-assisted
-
1 模型辅助的联邦最大熵强化学习算法
(1) 初始化M架无人机集合,重放缓冲区$ {\mathcal{D}}^{m} $,QMIX参数θ,本地QMIX参数θm=0,目标网络参数$ {\widehat{\theta }}^{m}={\theta }^{m} $,目标网络更新周期Ntarget,
聚合周期Nfreq(2) for e=0,1,···, Emax-1 do (3) (a)现实世界数据收集 (4) for 每个无人机m∈M do (5) t=0,初始化状态s0 (6) while $ {E}_{t}^{m}\ge 0 $ do (7) 采样动作$ {\mathit{a}}_{t}^{m}~{\pi }_{\theta }\left({\mathit{a}}_{t}^{m}\right|{s}_{t}^{m}) $ (8) 使用批评网络计算Q值$ Q({s}_{t}^{m},{\mathit{a}}_{t}^{m}) $ (9) 根据安全控制器执行$ {\mathit{a}}_{t}^{m} $,观察新状态$ {s}_{t+1}^{m} $和奖励$ {r}_{t}^{m} $ (10) 将$ \left({{s}_{t}^{m},\mathit{a}}_{t}^{m},{r}_{t}^{m},{s}_{t+1}^{m}\right) $存储在$ {\mathcal{D}}^{m} $中 (11) t=t+1 (12) end while (13) end for (14) (b)学习信道模型并估计未知设备位置,建立模拟环境 (15) (c)模拟环境训练 (16) for episode=0,1,···,N-1 do (17) for 每个并行的无人机m∈M do (18) t=0,初始化状态s0 (19) while $ {E}_{t}^{m}\ge 0,\forall j=\mathrm{1,2},\cdots ,M $ do (20) for 每个模拟代理$ j=\mathrm{1,2},\cdots ,M $ do (21) $ {\tau }_{t}^{j}={\tau }_{t-1}^{j}\cup \{{o}_{t}^{j},{\mathit{a}}_{t-1}^{j}\} $ (22) 使用SAC策略选择动作$ {\mathit{a}}_{t}^{j}~{\pi }_{\theta }\left({\mathit{a}}_{t}^{j}\right|{s}_{t}^{j}) $ (23) 使用评价网络计算Q值$ Q({s}_{t}^{j},{\mathit{a}}_{t}^{j}) $,并更新策略 (24) end for (25) 采取联合动作$ {\times }_{j}{\mathit{a}}_{t}^{j} $,观察$ {\times }_{j}{o}_{t+1}^{j} $,获得奖励rt和下一个状态st+1 (26) 将$ \left({s}_{t},{\times }_{j}{o}_{t}^{j},{\times }_{j}{\mathit{a}}_{t}^{j},{r}_{t},{s}_{t+1},{{\times }_{j}o}_{t+1}^{j}\right) $存储在$ {\mathcal{D}}^{m} $中 (27) t=t+1 (28) end while (29) end for (30) 从$ {\mathcal{D}}^{m} $中随机采样一批B片段,计算Qtot,并使用目标网络$ {\widehat{\theta }}^{m} $计算目标Qtot (31) 更新评价网络参数,最大化期望奖励并正则化熵 (32) $ {\theta }^{m}\leftarrow {\theta }^{m}-\alpha \nabla \mathcal{L}\left({\theta }^{m}\right) $ (33) if mod (episode,Ntarget)=0 then (34) 重置$ {\widehat{\theta }}^{m}={\theta }^{m} $ (35) end if (36) end for (37) if mod (episode,Nfreq)=0 then (38) 更新$ \theta =\sum _{m=1}^{M}{w}_{m}{\theta }_{m} $并设置$ {\theta }^{m}\leftarrow \theta ,\forall m\in M $ (39) end if (40)end for  下载: 导出CSV
下载: 导出CSV
表 1 训练超参数
训练参数 数值 折扣因子γ 0.99 软更新率τ 0.005 经验池大小$ \mathcal{D} $ 5000 批量样本数B 32 网络学习率lr 0.0003 演员网络学习率lactor 0.0003 温度参数学习率lα 0.0002 目标熵值 0.3 注意力头数n 4 优化器 Adam
下载: 导出CSV
-
[1] WEI Zhiqing, ZHU Mingyue, ZHANG Ning, et al. UAV-assisted data collection for Internet of Things: A survey[J]. IEEE Internet of Things Journal, 2022, 9(17): 15460–15483. doi: 10.1109/JIOT.2022.3176903. [2] CHENG Zhekun, ZHAO Liangyu, and SHI Zhongjiao. Decentralized multi-UAV path planning based on two-layer coordinative framework for formation rendezvous[J]. IEEE Access, 2022, 10: 45695–45708. doi: 10.1109/ACCESS.2022.3170583. [3] ZHENG Jibin, DING Minghui, SUN Lu, et al. Distributed stochastic algorithm based on enhanced genetic algorithm for path planning of multi-UAV cooperative area search[J]. IEEE Transactions on Intelligent Transportation Systems, 2023, 24(8): 8290–8303. doi: 10.1109/TITS.2023.3258482. [4] LIU Zhihong, WANG Xiangke, SHEN Lincheng, et al. Mission-oriented miniature fixed-wing UAV swarms: A multilayered and distributed architecture[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2022, 52(3): 1588–1602. doi: 10.1109/TSMC.2020.3033935. [5] VELICHKO N A. Distributed multi-agent reinforcement learning based on feudal networks[C]. 2024 6th International Youth Conference on Radio Electronics, Electrical and Power Engineering (REEPE), Moscow, Russian Federation, 2024: 1–5. doi: 10.1109/REEPE60449.2024.10479775. [6] LIN Mengting, LI Bin, ZHOU Bin, et al. Distributed stochastic model predictive control for heterogeneous UAV swarm[J]. IEEE Transactions on Industrial Electronics, 2024: 1–11. doi: 10.1109/TIE.2024.3508055. [7] WANG Xu, WANG Sen, LIANG Xingxing, et al. Deep reinforcement learning: A survey[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(4): 5064–5078. doi: 10.1109/TNNLS.2022.3207346. [8] WESTHEIDER J, RÜCKIN J, and POPOVIĆ M. Multi-UAV adaptive path planning using deep reinforcement learning[C]. 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, USA, 2023: 649–656. doi: 10.1109/IROS55552.2023.10342516. [9] PUENTE-CASTRO A, RIVERO D, PEDROSA E, et al. Q-learning based system for path planning with unmanned aerial vehicles swarms in obstacle environments[J]. Expert Systems with Applications, 2024, 235: 121240. doi: 10.1016/j.eswa.2023.121240. [10] HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]. The 35th International Conference on Machine Learning, Stockholm, Sweden, 2018: 1861–1870. [11] LOWE R, WU Yi, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6382–6393. [12] FOERSTER J N, FARQUHAR G, AFOURAS T, et al. Counterfactual multi-agent policy gradients[C]. The 32nd AAAI Conference on Artificial Intelligence, New Orleans, USA, 2018: 363. doi: 10.1609/aaai.v32i1.11794. [13] MAHAJAN A, RASHID T, SAMVELYAN M, et al. MAVEN: Multi-agent variational exploration[C]. The 33rd International Conference on Neural Information Processing Systems, 2019: 684. [14] RASHID T, SAMVELYAN M, DE WITT C S, et al. Monotonic value function factorisation for deep multi-agent reinforcement learning[J]. The Journal of Machine Learning Research, 2020, 21(1): 178. [15] LYU Lingjuan, YU Han, MA Xingjun, et al. Privacy and robustness in federated learning: Attacks and defenses[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(7): 8726–8746. doi: 10.1109/TNNLS.2022.3216981. [16] WANG Tianshun, HUANG Xumin, WU Yuan, et al. UAV swarm-assisted two-tier hierarchical federated learning[J]. IEEE Transactions on Network Science and Engineering, 2024, 11(1): 943–956. doi: 10.1109/TNSE.2023.3311024. [17] HU Chen, REN Hanchi, DENG Jingjing, et al. Distributed learning for UAV swarms[J]. arXiv preprint arXiv: 2410.15882, 2024. doi: 10.48550/arXiv.2410.15882. [18] TONG Ziheng, WANG Jingjing, HOU Xiangwang, et al. Blockchain-based trustworthy and efficient hierarchical federated learning for UAV-enabled IoT networks[J]. IEEE Internet of Things Journal, 2024, 11(21): 34270–34282. doi: 10.1109/JIOT.2024.3370964. [19] FIROUZJAEI H M, MOGHADDAM J Z, and ARDEBILIPOUR M. Delay optimization of a federated learning-based UAV-aided IoT network[J]. arXiv preprint arXiv: 2502.06284, 2025. doi: 10.48550/arXiv.2502.06284. [20] WANG Pengfei, YANG Hao, HAN Guangjie, et al. Decentralized navigation with heterogeneous federated reinforcement learning for UAV-enabled mobile edge computing[J]. IEEE Transactions on Mobile Computing, 2024, 23(12): 13621–13638. doi: 10.1109/TMC.2024.3439696. [21] ESRAFILIAN O, BAYERLEIN H, and GESBERT D. Model-aided deep reinforcement learning for sample-efficient UAV trajectory design in IoT networks[C]. 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 2021: 1–6. doi: 10.1109/GLOBECOM46510.2021.9685774. [22] CHEN Jichao, ESRAFILIAN O, BAYERLEIN H, et al. Model-aided federated reinforcement learning for multi-UAV trajectory planning in IoT networks[C]. 2023 IEEE Globecom Workshops (GC Wkshps), Kuala Lumpur, Malaysia, 2023: 818–823. doi: 10.1109/GCWkshps58843.2023.10465088. [23] YAN Yan, ZHANG Baoxian, LI Cheng, et al. A novel model-assisted decentralized multi-agent reinforcement learning for joint optimization of hybrid beamforming in massive MIMO mmWave systems[J]. IEEE Transactions on Vehicular Technology, 2023, 72(11): 14743–14755. doi: 10.1109/TVT.2023.3280910. [24] ZHANG Tuo, FENG Tiantian, ALAM S, et al. GPT-FL: Generative pre-trained model-assisted federated learning[J]. arXiv Preprint arXiv: 2306.02210, 2023. doi: 10.48550/arXiv.2306.02210. [25] BAYERLEIN H, THEILE M, CACCAMO M, et al. Multi-UAV path planning for wireless data harvesting with deep reinforcement learning[J]. IEEE Open Journal of the Communications Society, 2021, 2: 1171–1187. doi: 10.1109/OJCOMS.2021.3081996. [26] OLIEHOEK F A and AMATO C. A Concise Introduction to Decentralized POMDPs[M]. Cham, Switzerland: Springer, 2016. doi: 10.1007/978-3-319-28929-8. [27] ZENG Yong, XU Jie, and ZHANG Rui. Energy minimization for wireless communication with rotary-wing UAV[J]. IEEE Transactions on Wireless Communications, 2019, 18(4): 2329–2345. doi: 10.1109/TWC.2019.2902559. -


 下载:
下载:







图(7) / 表(2)
计量
- 文章访问数: 1911
- HTML全文浏览量: 1531
- PDF下载量: 231
- 被引次数: 0
