

Multi-Hop UAV Ad Hoc Network Access Control Protocol: Deep Reinforcement Learning-Based Time Slot Allocation Method
-
摘要: 无人机自组织网络中,各个节点的流量不均衡,容易导致网络拥塞和时隙资源利用率低的问题。该文研究了无人机自组网中饱和节点和不饱和节点共存的场景下的接入控制问题,旨在让更多的节点共享不饱和节点的空闲时隙,提升网络的吞吐量。针对无人机多跳自组织网络接入控制问题,该文提出一种基于深度强化学习的多跳无人机自组织网络MAC协议(DQL-MHTDMA),将饱和节点联合为一个大智能体,学习网络拓扑信息和时隙占用规律,选择最优的接入动作,实现每个时隙上的最大吞吐量或最佳能效。仿真结果表明,所提DQL-MHTDMA协议能够学习时隙的占用规律,并且可以感知多跳拓扑,在多种不饱和流量到达规律下获得最优的吞吐量或最佳的能量效率。Abstract:
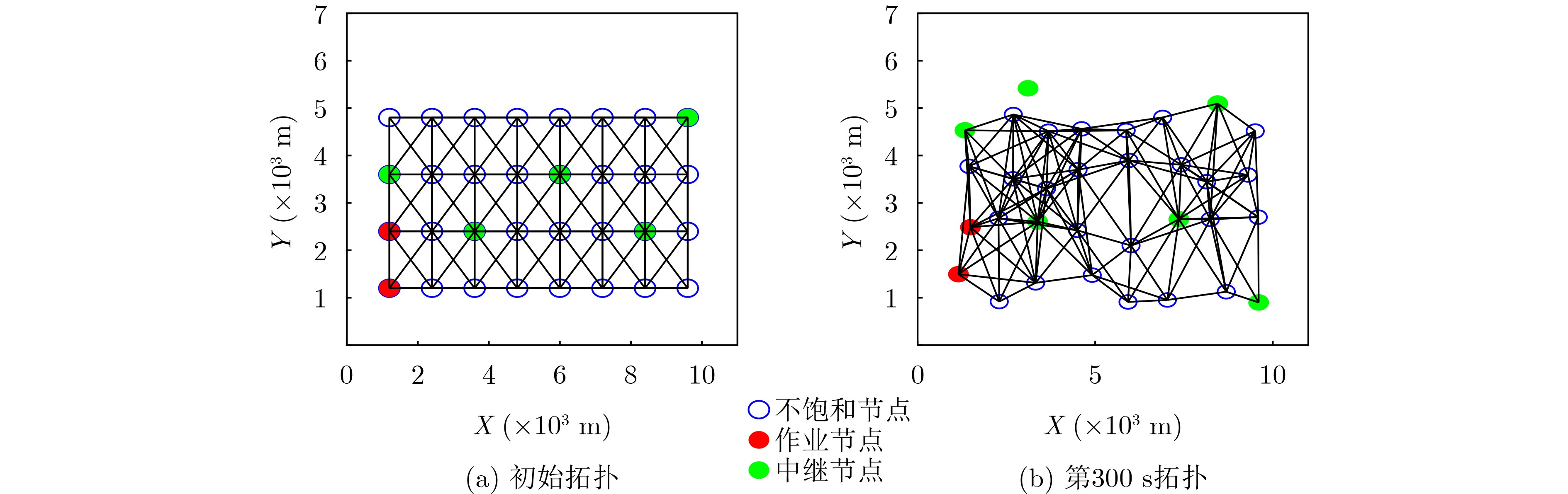
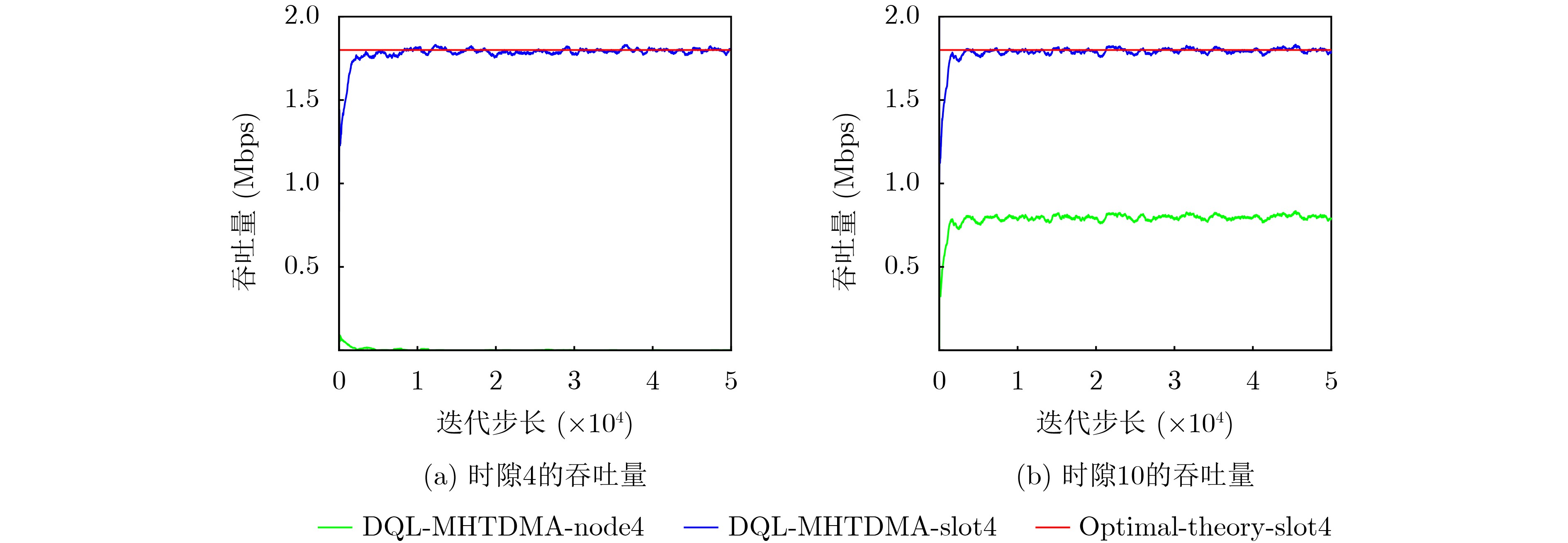
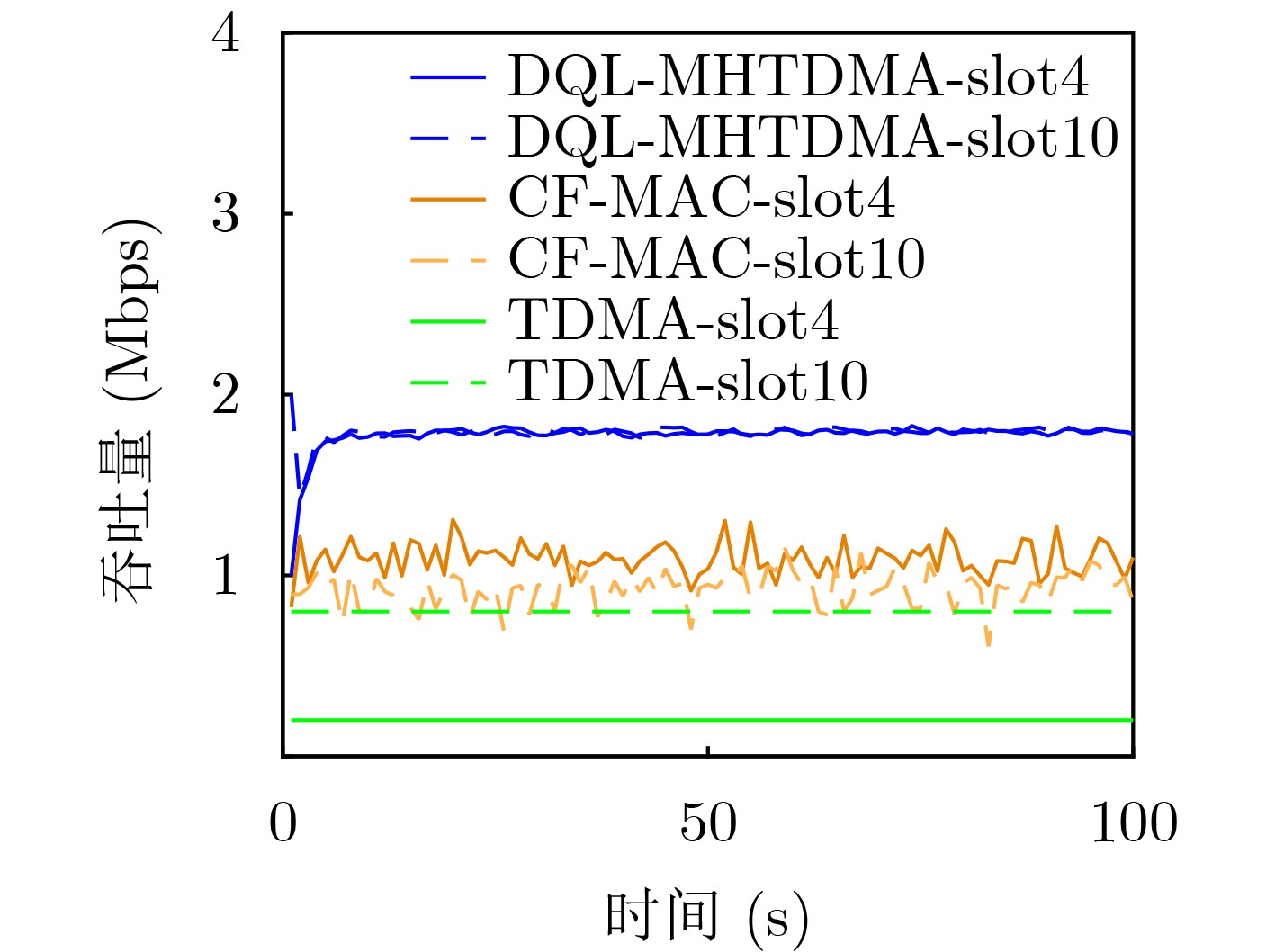
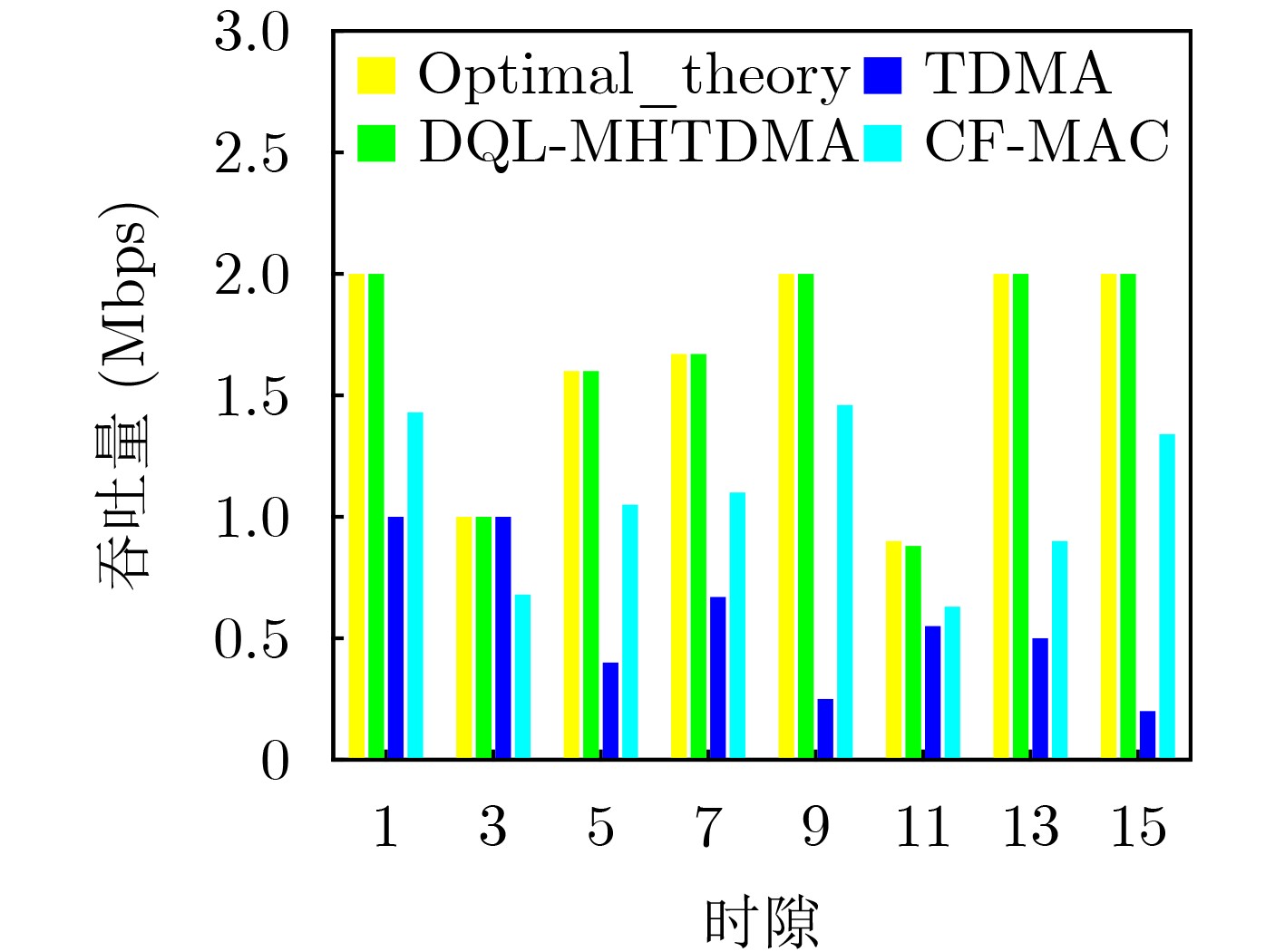
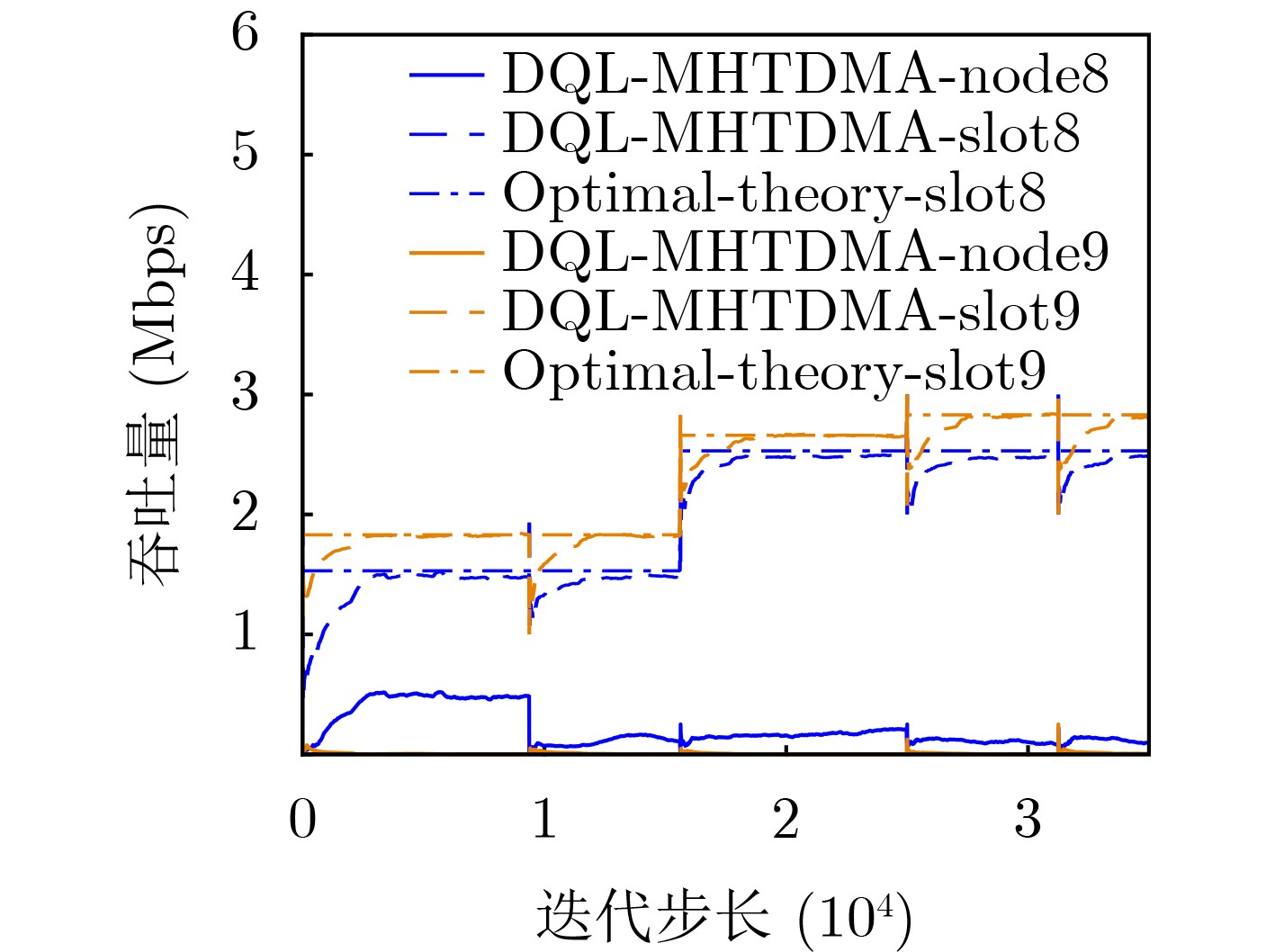
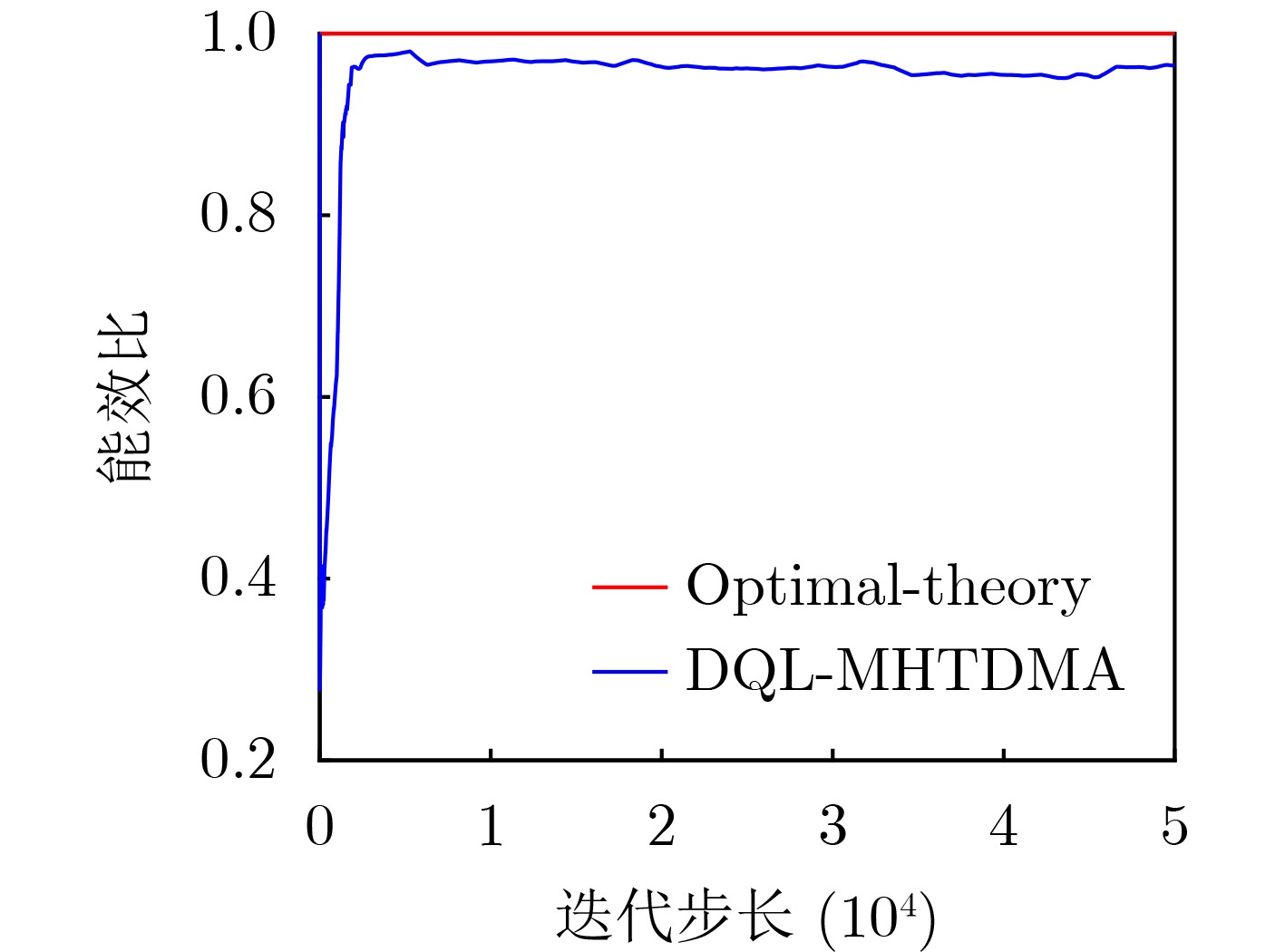
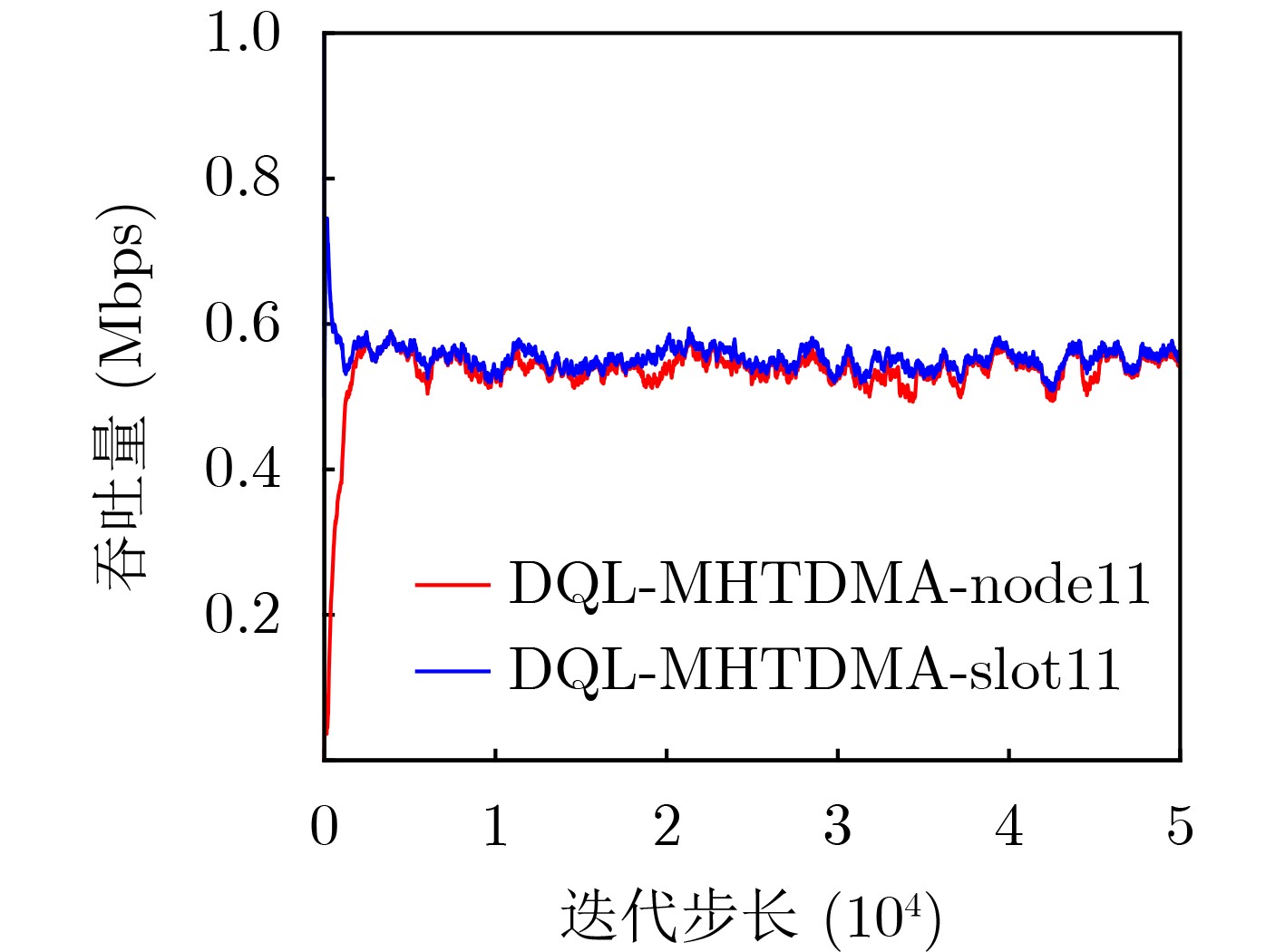
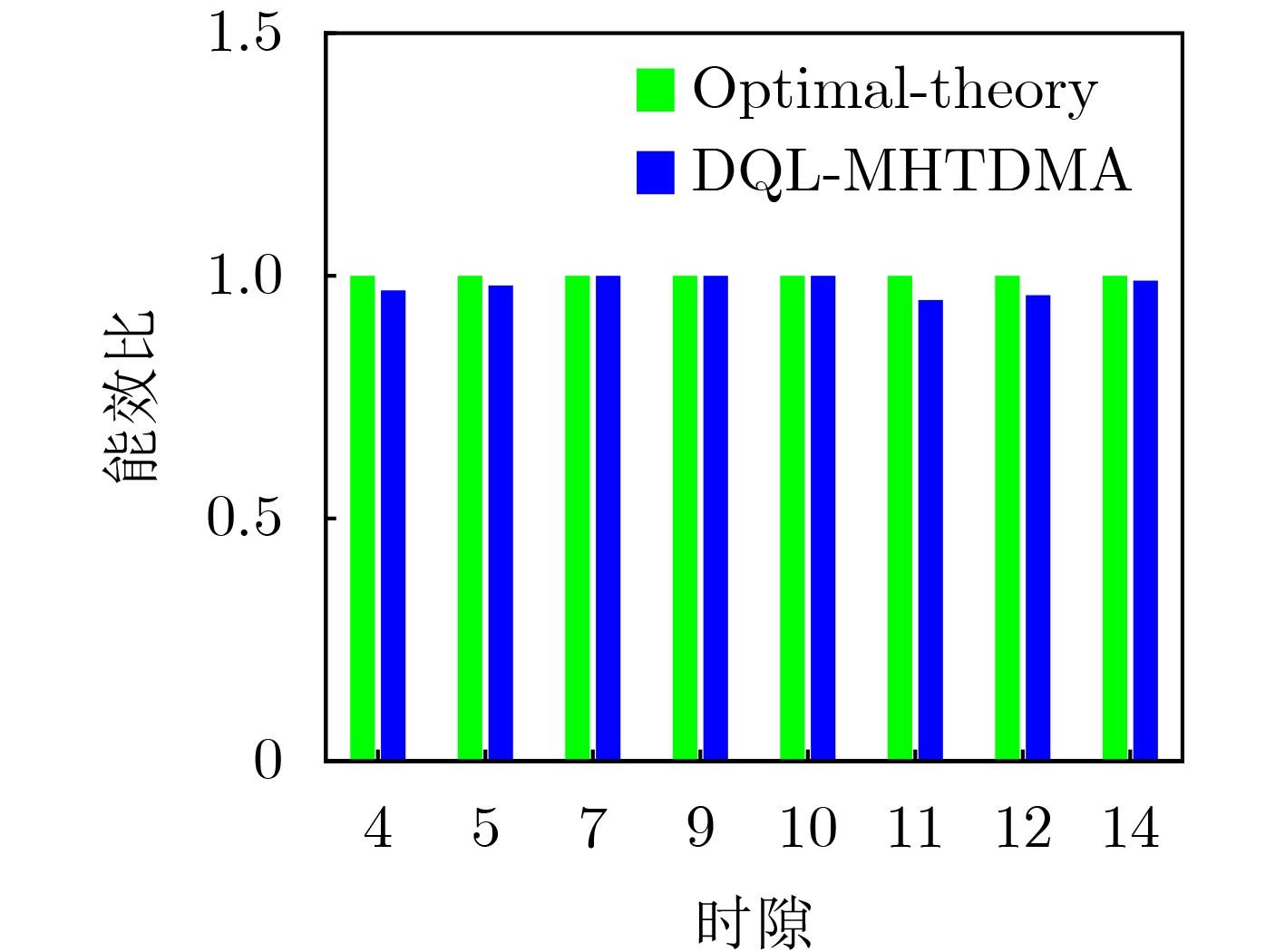
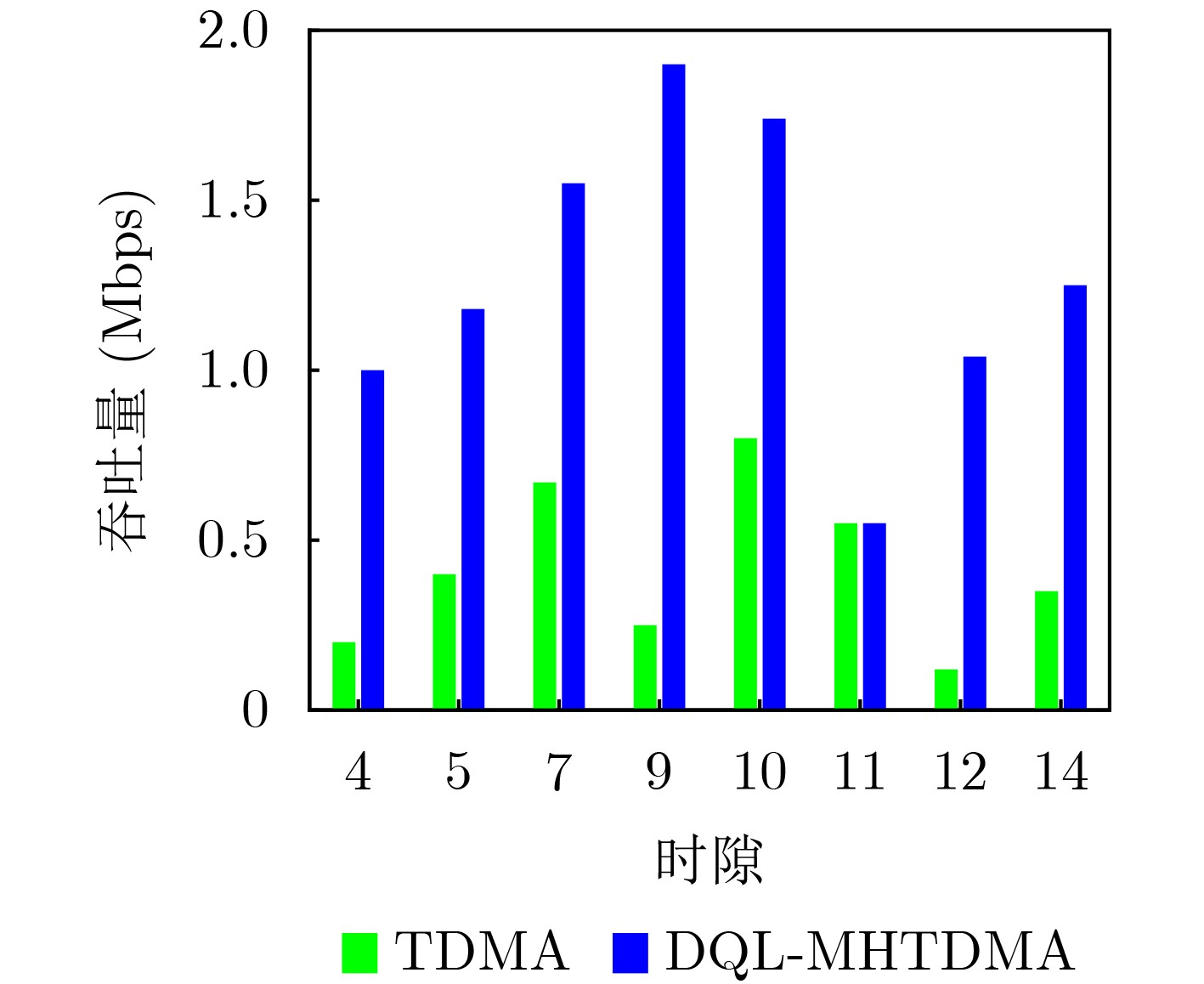
Objective Unmanned Aerial Vehicle (UAV) ad hoc networks have gained prominence in emergency and military operations due to their decentralized architecture and rapid deployment capabilities. However, the coexistence of saturated and unsaturated nodes in dynamic multi-hop topologies often results in inefficient time-slot utilization and network congestion. Existing Time Division Multiple Access (TDMA) protocols show limited adaptability to dynamic network conditions, while conventional Reinforcement Learning (RL)-based approaches primarily target single-hop or static scenarios, failing to address scalability challenges in multi-hop UAV networks. This study explores dynamic access control strategies that allow idle time slots of unsaturated nodes to be efficiently shared by saturated nodes, thereby improving overall network throughput. Methods A Deep Q-Learning-based Multi-Hop TDMA (DQL-MHTDMA) protocol is developed for UAV ad hoc networks. First, a backbone selection algorithm classifies nodes into saturated (high-traffic) and unsaturated (low-traffic) groups. The saturated nodes are then aggregated into a joint intelligent agent coordinated through UAV control links. Second, a distributed Deep Q-Learning (DQL) framework is implemented in each TDMA slot to dynamically select optimal transmission node sets from the saturated group. Two reward strategies are defined: (1) throughput maximization and (2) energy efficiency optimization. Third, the joint agent autonomously learns network topology and the traffic patterns of unsaturated nodes, adaptively adjusting transmission probabilities to meet the targeted objectives. Upon detecting topological changes, the agent initiates reconfiguration and retraining cycles to reconverge to optimal operational states. Results and Discussions Experiments conducted in static (16-node) and mobile (32-node) scenarios demonstrate the protocol’s effectiveness. As the number of iterations increases, the throughput gradually converges towards the theoretical optimum, reaching its maximum after approximately 2,000 iterations ( Fig. 5 ). In Slot 4, the total throughput achieves the theoretical optimum of 1.8, while the throughput of Node 4 remains nearly zero. This occurs because the agent selects transmission sets {1, 8} or {2, 8} to share the channel, with transmissions from Node 1 preempting Node 4’s sending opportunities. Similarly, the total throughput of Slot 10 also attains the theoretical optimum of 1.8, resulting from the algorithm’s selection of conflict-free transmission sets {1} or {2} to share the channel simultaneously. The throughput of the DQL-MHTDMA algorithm is compared with that of other algorithms and the theoretical optimal value in odd-numbered time slots under Scenario 1. Across all time slots, the proposed algorithm achieves or closely approximates the theoretical optimum, significantly outperforming the traditional fixed-slot TDMA algorithm and the CF-MAC algorithm. Notably, the intelligent agent operates without prior knowledge of traffic patterns in each time slot or the topology of nodes beyond its own, demonstrating the algorithm’s ability to learn both slot occupancy patterns and network topology. This enables it to intelligently select the optimal transmission set to maximize throughput in each time slot. In the mobile (32-node) scenario, when the relay selection algorithm detects significant topological changes, the protocol is triggered to reselect actions. After each change, the algorithm rapidly converges to optimal action selection schemes and adaptively achieves near-theoretical-optimum maximum throughput across varying topologies (Fig. 9 ). Under the optimal energy efficiency objective policy, energy efficiency in time slot 11 converges after 2,000 iterations, reaching a value close to the theoretical optimum (Fig. 10 ). Compared to the throughput-oriented algorithm, energy efficiency improves from 0.35 to 1. This occurs because the throughput-optimized algorithm preferentially selects transmission sets {1, 8} or {2, 8} to maximize throughput. However, as Node 11 lies within the 2-hop neighborhood of both Nodes 1 and 8, concurrent channel occupancy induces collisions, significantly degrading energy efficiency. In contrast, the energy-efficiency-optimized algorithm preferentially selects an empty transmission set (i.e., no scheduled transmissions), thereby maximizing energy efficiency while maintaining moderate throughput levels. The paper presents statistical comparisons of energy efficiency against theoretical optima across eight distinct time slots in the static (16-node) scenario. As demonstrated in multi-hop network environments, the proposed algorithm achieves or closely approaches theoretical optimum energy efficiency values in all slots. Furthermore, while maintaining energy efficiency guarantees, the algorithm delivers significantly higher throughput compared to conventional TDMA protocols.Conclusions This paper addresses the access control problem in multi-hop UAV ad hoc networks, where saturated and non-saturated nodes coexist. A DQL-MHTDMA is proposed. By consolidating saturated nodes into a single large agent, the protocol learns network topology and time-slot occupation patterns to select optimal access actions, thereby maximizing throughput or energy efficiency in each time slot. Simulation results demonstrate that the algorithm exhibits fast convergence, stable performance, and achieves the theoretically optimal values for both throughput and energy efficiency objectives. -
Key words:
- UAV /
- Multiple access protocol /
- Ad hoc network /
- Deep Reinforcement Learning (DRL)
-
1 DQL-MHTDMA(目标:最大吞吐量或者最佳能效)
(1) 运行中继选择算法,选出中继节点 (2) 确定智能体成员集合$ {N_{\mathrm{S}}} $ (3) 初始化参数:初始状态$ {s_0} $,贪心策略中的探索概率$ \varepsilon $,折扣
因子$ \gamma $,调整步进$ \rho $,最小样本数量$ {N_{\mathrm{E}}} $,更新周期$ F $(4) 初始化经验池$ {\mathrm{EM}} $ (5) 初始化QNN的参数$ \theta $ (6) 初始化目标QNN的参数$ {\theta ^ - } $ (7) for t=0,1,2, ···, do 向QNN输入$ {s_t} $,输出$ Q = \left\{ {q\left( {{s_t},a,\theta } \right)\left| {a \in {A_{{s_t}}}} \right.} \right\} $ 采用$ \varepsilon $-贪婪算法从$ Q $中选择动作$ {a_t} $ 执行动作$ {a_t} $,获得$ {z_t} $和$ {r_{t + 1}} $,得到$ {s_{t + 1}} $ 存储$ \left( {{s_t},{a_t},{r_{t + 1}},{s_{t + 1}}} \right) $经验池$ {\mathrm{EM}} $ 训练QNN网络: 从经验池中随机选择$ {N_{\mathrm{E}}} $个样本 for 每一个样本中的经验$ e = \left( {s,a,r,s'} \right) $,do 计算$ y_{r,s'}^{{\mathrm{QNN}}} = r + \gamma \mathop {\max }\limits_{a'} q\left( {s',a';{\theta ^ - }} \right) $ end for 执行梯度下降,在QNN中更新$ \theta $ 如果$ \left( {t/F = = 0} \right) $,更新目标网络$ {\theta ^ - } = \theta $ end 训练 end for  下载: 导出CSV
下载: 导出CSV
表 1 不饱和节点的时隙占用规律(场景1)
节点
编号发送概率 说明 节点
编号发送概率 说明 4 0.2 随机 12 0.12 随机 5 0.4 随机 13 0.50 周期 7 0.67 随机 14 0.35 随机 9 0.25 周期 15 0.20 周期 10 0.8 随机 16 0.9 随机 11 0.55 随机
下载: 导出CSV
表 2 不饱和节点的时隙占用规律(场景2)
节点
编号发送
概率节点
编号发送
概率节点
编号发送
概率3 0.79 13 0.6 23 0.55 4 0.31 14 0.18 24 0 5 0 15 0.23 25 0.45 6 0.2 16 0.26 26 0.65 7 0.23 17 0.65 27 0.63 8 0.53 18 0.24 28 0.08 9 0.17 19 0.19 29 0 10 0.67 20 0.69 30 0.23 11 0.11 21 0.75 31 0 12 0 22 0.28 32 0.91
下载: 导出CSV
表 3 超参数设置
参数名称 参数值 历史状态长度$ M $ 20 折扣因子$ \gamma $ 0.9 贪心策略中的探索概率$ \varepsilon $ 0.005~0.010 学习率 1 目标网络的更新频率$ F $ 100 最小样本数量$ {N_E} $ 64 经验池大小 1000 鼓励参数$ \beta $ 12
下载: 导出CSV
-
[1] KHAN M A, KUMAR N, MOHSAN S A H, et al. Swarm of UAVs for network management in 6G: A technical review[J]. IEEE Transactions on Network and Service Management, 2023, 20(1): 741–761. doi: 10.1109/TNSM.2022.3213370. [2] ZENG Yong, ZHANG Rui, and LIM T J. Wireless communications with unmanned aerial vehicles: Opportunities and challenges[J]. IEEE Communications Magazine, 2016, 54(5): 36–42. doi: 10.1109/MCOM.2016.7470933. [3] MOZAFFARI M, SAAD W, BENNIS M, et al. A tutorial on UAVs for wireless networks: Applications, challenges, and open problems[J]. IEEE Communications Surveys & Tutorials, 2019, 21(3): 2334–2360. doi: 10.1109/COMST.2019.2902862. [4] ARSALAAN A S, FIDA M R, and NGUYEN H X. UAVs relay in emergency communications with strict requirements on quality of information[J]. IEEE Transactions on Vehicular Technology, 2025, 74(3): 4877–4892. doi: 10.1109/TVT.2024.3493206. [5] CHEN Jiaxin, CHEN Ping, WU Qihui, et al. A game-theoretic perspective on resource management for large-scale UAV communication networks[J]. China Communications, 2021, 18(1): 70–87. doi: 10.23919/JCC.2021.01.007. [6] QI Fei, ZHU Xuetian, MANG Ge, et al. UAV network and IoT in the sky for future smart cities[J]. IEEE Network, 2019, 33(2): 96–101. doi: 10.1109/MNET.2019.1800250. [7] NATKANIEC M, KOSEK-SZOTT K, SZOTT S, et al. A survey of medium access mechanisms for providing QoS in Ad-hoc networks[J]. IEEE Communications Surveys & Tutorials, 2013, 15(2): 592–620. doi: 10.1109/SURV.2012.060912.00004. [8] BORGONOVO F, CAPONE A, CESANA M, et al. ADHOC MAC: New MAC architecture for Ad hoc networks providing efficient and reliable point-to-point and broadcast services[J]. Wireless Networks, 2004, 10(4): 359–366. doi: 10.1023/B:WINE.0000028540.96160.8a. [9] OMAR H A, ZHUANG Weihua, and LI Li. VeMAC: A TDMA-based MAC protocol for reliable broadcast in VANETs[J]. IEEE Transactions on Mobile Computing, 2013, 12(9): 1724–1736. doi: 10.1109/TMC.2012.142. [10] NGUYEN V, DANG D N M, JANG S, et al. E-VeMAC: An enhanced vehicular MAC protocol to mitigate the exposed terminal problem[C]. The 16th Asia-Pacific Network Operations and Management Symposium, Hsinchu, China, 2014: 1–4. doi: 10.1109/APNOMS.2014.6996561. [11] ZOU Rui, LIU Zishan, ZHANG Lin, et al. A near collision free reservation based MAC protocol for VANETs[C]. 2014 IEEE Wireless Communications and Networking Conference (WCNC), Istanbul, Turkey, 2014: 1538–1543. doi: 10.1109/WCNC.2014.6952438. [12] JIANG Anzhou, MI Zhichao, DONG Chao, et al. CF-MAC: A collision-free MAC protocol for UAVs Ad-hoc networks[C]. 2016 IEEE Wireless Communications and Networking Conference, Doha, Qatar, 2016: 1–6. doi: 10.1109/WCNC.2016.7564844. [13] CHUA M Y K, YU F R, LI Jun, et al. Medium access control for Unmanned Aerial Vehicle (UAV) Ad-hoc networks with full-duplex radios and multipacket reception capability[J]. IEEE Transactions on Vehicular Technology, 2013, 62(1): 390–394. doi: 10.1109/TVT.2012.2211905. [14] MAO Qian, HU Fei, and HAO Qi. Deep learning for intelligent wireless networks: A comprehensive survey[J]. IEEE Communications Surveys & Tutorials, 2018, 20(4): 2595–2621. doi: 10.1109/COMST.2018.2846401. [15] LIU Xin, SUN Can, YAU K L A, et al. Joint collaborative big spectrum data sensing and reinforcement learning based dynamic spectrum access for cognitive internet of vehicles[J]. IEEE Transactions on Intelligent Transportation Systems, 2024, 25(1): 805–815. doi: 10.1109/TITS.2022.3175570. [16] ZHANG Xiaohui, CHEN Ze, ZHANG Yinghui, et al. Deep-reinforcement-learning-based distributed dynamic spectrum access in multiuser multichannel cognitive radio internet of things networks[J]. IEEE Internet of Things Journal, 2024, 11(10): 17495–17509. doi: 10.1109/JIOT.2024.3359277. [17] 邓炳光, 徐成义, 张泰, 等. 基于多智能体深度强化学习的D2D通信资源联合分配方法[J]. 电子与信息学报, 2023, 45(4): 1173–1182. doi: 10.11999/JEIT220231.DENG Bingguang, XU Chengyi, ZHANG Tai, et al. A joint resource allocation method of D2D communication resources based on multi-agent deep reinforcement learning[J]. Journal of Electronics & Information Technology, 2023, 45(4): 1173–1182. doi: 10.11999/JEIT220231. [18] NISIOTI E and THOMOS N. Fast Q-learning for improved finite length performance of irregular repetition slotted ALOHA[J]. IEEE Transactions on Cognitive Communications and Networking, 2020, 6(2): 844–857. doi: 10.1109/TCCN.2019.2957224. [19] NAPARSTEK O and COHEN K. Deep multi-user reinforcement learning for distributed dynamic spectrum access[J]. IEEE Transactions on Wireless Communications, 2019, 18(1): 310–323. doi: 10.1109/TWC.2018.2879433. [20] YU Yiding, WANG Taotao, and LIEW S C. Deep-reinforcement learning multiple access for heterogeneous wireless networks[J]. IEEE Journal on Selected Areas in Communications, 2019, 37(6): 1277–1290. doi: 10.1109/JSAC.2019.2904329. [21] WANG Shangxing, LIU Hanpeng, GOMES P H, et al. Deep reinforcement learning for dynamic multichannel access in wireless networks[J]. IEEE Transactions on Cognitive Communications and Networking, 2018, 4(2): 257–265. doi: 10.1109/TCCN.2018.2809722. [22] CUI Qimei, ZHANG Ziyuan, SHI Yanpeng, et al. Dynamic multichannel access based on deep reinforcement learning in distributed wireless networks[J]. IEEE Systems Journal, 2022, 16(4): 5831–5834. doi: 10.1109/JSYST.2021.3134820. [23] ZHANG Shuying, NI Zuyao, KUANG Linling, et al. Load-aware distributed resource allocation for MF-TDMA Ad hoc networks: A multi-agent DRL approach[J]. IEEE Transactions on Network Science and Engineering, 2022, 9(6): 4426–4443. doi: 10.1109/TNSE.2022.3201121. [24] SOHAIB M, JEONG J, and JEON S W. Dynamic multichannel access via multi-agent reinforcement learning: Throughput and fairness guarantees[J]. IEEE Transactions on Wireless Communications, 2022, 21(6): 3994–4008. doi: 10.1109/TWC.2021.3126112. [25] LIU Xiaoyu, XU Chi, YU Haibin, et al. Deep reinforcement learning-based multichannel access for industrial wireless networks with dynamic multiuser priority[J]. IEEE Transactions on Industrial Informatics, 2022, 18(10): 7048–7058. doi: 10.1109/TII.2021.3139349. [26] NAEEM F, ADAM N, KADDOUM G, et al. Learning MAC protocols in HetNets: A cooperative multi-agent deep reinforcement learning approach[C]. 2024 IEEE Wireless Communications and Networking Conference (WCNC), Dubai, United Arab Emirates, 2024: 1–6. doi: 10.1109/WCNC57260.2024.10571321. [27] MIUCCIO L, RIOLO S, BENNIS M, et al. Design of a feasible wireless MAC communication protocol via multi-agent reinforcement learning[C]. 2024 IEEE International Conference on Machine Learning for Communication and Networking (ICMLCN), Stockholm, Sweden, 2024: 94–100. doi: 10.1109/ICMLCN59089.2024.10624759. [28] ZOU Yifei, ZHANG Zuyuan, ZHANG Congwei, et al. A distributed abstract MAC layer for cooperative learning on internet of vehicles[J]. IEEE Transactions on Intelligent Transportation Systems, 2024, 25(8): 8972–8983. doi: 10.1109/TITS.2024.3362909. [29] 唐龙, 王峰. 基于UCDS的战术网络拓扑构建研究[J]. 通信技术, 2015, 48(9): 1037–1043. doi: 10.3969/j.issn.1002-0802.2015.09.011.TANG Long and WANG Feng. Tactical network topology construction based on UCDS[J]. Communications Technology, 2015, 48(9): 1037–1043. doi: 10.3969/j.issn.1002-0802.2015.09.011. [30] 王聪, 赵几航, 吴霞, 等. 面向FANET的N-UCDS虚拟骨干网构建方法[J]. 陆军工程大学学报, 2023, 2(1): 55–62. doi: 10.12018/j.issn.2097-0730.20220117001.WANG Cong, ZHAO Jihang, WU Xia, et al. FANET-oriented construction method of N-UCDS virtual backbone network[J]. Journal of Army Engineering University of PLA, 2023, 2(1): 55–62. doi: 10.12018/j.issn.2097-0730.20220117001. -


 下载:
下载:





图(13) / 表(4)
计量
- 文章访问数: 1289
- HTML全文浏览量: 758
- PDF下载量: 153
- 被引次数: 0
