

FCSNet: A Frequency-Domain Aware Cross-Feature Fusion Network for Smoke Segmentation
-
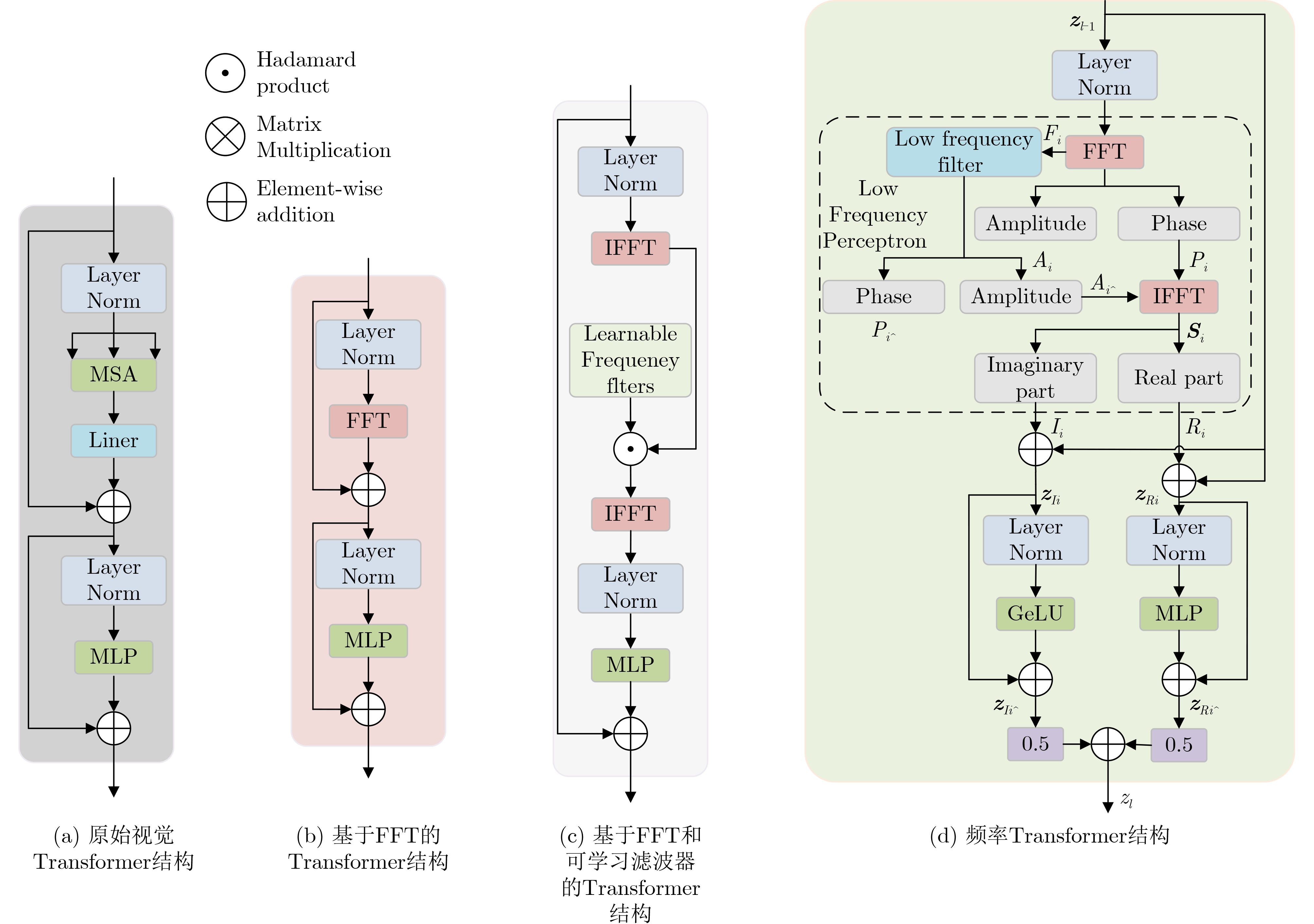
摘要: 由于烟雾具有非刚性结构、半透明性以及形态多变等特点,烟雾的语义分割相较于其他物体具有更大的挑战性。为此,该文设计了频域感知的跨特征融合烟雾分割网络(FCSNet),用于应对真实场景中的烟雾分割任务。该网络由Transformer分支、卷积神经网络分支、特征融合分支以及多级高频感知分支组成。为了在获取全局上下文信息的同时降低Transformer分支的计算复杂度,提出频率Transformer分支,该分支基于傅里叶变换来获取全局特征,并使用频域中的低频幅值来代表大规模的语义结构。此外,还提出域间交互模块(DIM),该模块通过加权融合操作和坐标注意力机制,促进了来自不同特征源信息的协同学习和整合,有效地融合全局和局部信息。为了充分利用边缘信息的固有分割能力来解决混淆区域的不准确分割问题,提出多级高频感知模块(MHFM),以获取准确的高频边缘信息。考虑到烟雾的非刚性特征,设计多向交叉注意力模块(MHCA),该模块计算边缘特征图和解码器特征图之间的相似性,从而指导混淆区域的分割结果。实验结果表明,该网络在真实场景烟雾分割数据集中的两个测试数据集上分别达到了58.95%和63.92%的平均交并比,在SMOKE5K数据集上达到了78.94%的平均交并比。与其他方法相比,该网络能够获得准确的烟雾定位和更精细的烟雾边缘。
-
关键词:
- 烟雾语义分割 /
- 频率Transformer /
- 域间交互 /
- 多级高频感知 /
- 多向交叉注意力
Abstract:Objective Vision-based smoke segmentation enables pixel-level classification of smoke regions, providing more spatially detailed information than traditional bounding-box-based detection approaches. Existing segmentation models based on Deep Convolutional Neural Networks (DCNNs) demonstrate reasonable performance but remain constrained by a limited receptive field due to their local inductive bias and two-dimensional neighborhood structure. This constraint reduces their capacity to model multi-scale features, particularly in complex visual scenes with diverse contextual elements. Transformer-based architectures address long-range dependencies but exhibit reduced effectiveness in capturing local structure. Moreover, the limited availability of real-world smoke segmentation datasets and the underutilization of edge information reduce the generalization ability and accuracy of current models. To address these limitations, this study proposes a Frequency-domain aware Cross-feature fusion Network for Smoke segmentation (FCSNet), which integrates frequency-domain and spatial-domain representations to enhance multi-scale feature extraction and edge information retention. A dataset featuring various smoke types and complex backgrounds is also constructed to support model training and evaluation under realistic conditions. Methods To address the challenges of smoke semantic segmentation in real-world scenarios, this study proposes FCSNet, a frequency-domain aware cross-feature fusion network. Given the high computational cost associated with Transformer-based models, a Frequency Transformer is designed to reduce complexity while retaining global representation capability. To overcome the limited contextual modeling of DCNNs and the insufficient local feature extraction of Transformers, a Domain Interaction Module (DIM) is introduced to facilitate effective fusion of global and local information. Within the network architecture, the Frequency Transformer branch extracts low-frequency components to capture large-scale semantic structures, thereby improving global scene comprehension. In parallel, a Multi-level High-Frequency perception Module (MHFM) is combined with Multi-Head Cross Attention (MHCA). MHFM processes multi-layer encoder features to capture high-frequency edge details at full resolution using a shallow structure. MHCA then computes directional global similarity maps to guide the decoder in aggregating contextual information more effectively. Results and Discussions The effectiveness of FCSNet is evaluated through comparative experiments against state-of-the-art methods using the RealSmoke and SMOKE5K datasets. On the RealSmoke dataset, FCSNet achieves the highest segmentation accuracy, with mean Intersection over Union (mIoU) values of 58.59% on RealSmoke-1 and 63.92% on RealSmoke-2, outperforming all baseline models ( Table 4 ). Although its FLOPs are slightly higher than those of TransFuse, FCSNet demonstrates a favorable trade-off between accuracy and computational complexity. Qualitative results further highlight its advantages under challenging conditions. In scenes affected by clouds, fog, or building occlusion, FCSNet distinguishes smoke boundaries more clearly and reduces both false positives and missed detections (Fig. 8 ). Notably, in RealSmoke-2, which contains fine and sparse smoke patterns, FCSNet exhibits superior performance in smoke localization and edge detail segmentation compared to other methods (Fig. 9 ). On the SMOKE5K dataset, FCSNet achieves an mIoU of 78.94%, showing a clear advantage over competing algorithms (Table 5 ). Visual comparisons also indicate that FCSNet generates more accurate and refined smoke boundaries (Fig. 10 ). These results confirm that FCSNet maintains strong segmentation accuracy and robustness across diverse real-world scenes, supporting its generalizability and practical utility in smoke detection tasks.Conclusions To address the challenges of smoke semantic segmentation in real-world environments, this study proposes FCSNet, a network that integrates frequency- and spatial-domain information. A Frequency Transformer is introduced to reduce computational cost while enhancing global semantic modeling through low-frequency feature extraction. To compensate for the limited receptive field of DCNNs and the local feature insensitivity of Transformers, a DIM is designed to fuse global and local representations. An MHFM is employed to extract edge features, improving segmentation performance in ambiguous regions. Additionally, an MHCA mechanism aligns high-frequency edge features with decoder representations to guide segmentation in visually confusing areas. By jointly leveraging low-frequency semantics and high-frequency detail, FCSNet achieves effective fusion of contextual and structural information. Extensive quantitative and qualitative evaluations confirm that FCSNet performs robustly under complex interference conditions, including clouds, fog, and occlusions, enabling accurate smoke localization and fine-grained segmentation. -
表 1 频率Transformer的消融实验
方法 mIoU (%) 参数量 (M) FLOPs (G) fps RealSmoke-1 RealSmoke-2 Model1 58.81 64.89 23.67 11.95 28.34 Model2 56.12 58.37 19.16 (19.05%) 11.11 (7.03%) 30.93 Model3 57.74 61.74 20.29 (14.28%) 11.11 (7.03%) 30.15 本文FCSNet 58.59(0.22) 63.92(0.97) 19.72 (16.69%) 11.11 (7.03%) 30.49  下载: 导出CSV
下载: 导出CSV
表 2 DIM的消融实验
方法 mIoU (%) RealSmoke-1 RealSmoke-2 Model1 53.78 51.23 Model2 54.73 52.81 Model3 58.15 55.31 本文FCSNet 58.59 63.92
下载: 导出CSV
表 3 MHFM和MHCA的消融实验
方法 mIoU (%) RealSmoke-1 RealSmoke-2 Model1 53.51 54.32 Model2 55.87 58.69 Model3 56.53 57.53 Model4 58.21 59.19 本文FCSNet 58.59 63.92
下载: 导出CSV
表 4 在RealSmoke数据集上的烟雾分割性能
方法 mIoU (%) 参数量 (M) FLOPs (G) RealSmoke-1 RealSmoke-2 FCN8s 52.47 54.32 14.42 19.69 W-Net 56.63 57.53 31.75 12.50 DMAENet 56.86 58.37 32.61 44.08 Trans-BVM 58.17 63.24 51.62 / DSS 50.46 52.32 28.80 21.62 TransUnet 54.56 61.32 75.65 22.23 TransFuse 53.71 61.56 25.02 8.44 本文FCSNet 58.59 63.92 19.72 11.11
下载: 导出CSV
表 5 在SMOKE5K数据集上的分割性能
方法 mIoU (%) FCN8s 71.39 W-Net 74.65 Trans-BVM 77.69 DSS 68.87 TransFuse 75.87 DMAENet 76.06 本文FCSNet 78.94
下载: 导出CSV
-
[1] 王开正, 周顺珍, 王健, 等. 基于多尺度时空特征深度融合神经网络的输电线路火点判识方法[J]. 高电压技术, 2025, 51(3): 1145–1157. doi: 10.13336/j.1003-6520.hve.20240086.WANG Kaizheng, ZHOU Shunzhen, WANG Jian, et al. Wildfire identification method for transmission lines based on deep fusion neural network with multi-scale spatio-temporal features[J]. High Voltage Engineering, 2025, 51(3): 1145–1157. doi: 10.13336/j.1003-6520.hve.20240086. [2] 杜辰, 王兴, 董增寿, 等. 改进YOLOv5s的地下车库火焰烟雾检测方法[J]. 计算机工程与应用, 2024, 60(11): 298–308. doi: 10.3778/j.issn.1002-8331.2307-0003.DU Chen, WANG Xing, DONG Zengshou, et al. Improved YOLOv5s flame and smoke detection method for underground garage[J]. Computer Engineering and Applications, 2024, 60(11): 298–308. doi: 10.3778/j.issn.1002-8331.2307-0003. [3] 张欣雨, 梁煜, 张为. 融合全局和局部信息的实时烟雾分割算法[J]. 西安电子科技大学学报, 2024, 51(1): 147–156. doi: 10.19665/j.issn1001-2400.20230405.ZHANG Xinyu, LIANG Yu, and ZHANG Wei. Real-time smoke segmentation algorithm combining global and local information[J]. Journal of Xidian University, 2024, 51(1): 147–156. doi: 10.19665/j.issn1001-2400.20230405. [4] CAO Hu, WANG Yueyue, CHEN J, et al. Swin-unet: Unet-like pure transformer for medical image segmentation[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 205–218. doi: 10.1007/978-3-031-25066-8_9. [5] JIANG Huiyan, DIAO Zhaoshuo, SHI Tianyu, et al. A review of deep learning-based multiple-lesion recognition from medical images: Classification, detection and segmentation[J]. Computers in Biology and Medicine, 2023, 157: 106726. doi: 10.1016/j.compbiomed.2023.106726. [6] MIAH M S U, KABIR M M, SARWAR T B, et al. A multimodal approach to cross-lingual sentiment analysis with ensemble of transformer and LLM[J]. Scientific Reports, 2024, 14(1): 9603. doi: 10.1038/s41598-024-60210-7. [7] TANG M C S, TING K C, and RASHIDI N H. DenseNet201-based waste material classification using transfer learning approach[J]. Applied Mathematics and Computational Intelligence, 2024, 13(2): 113–120. doi: 10.58915/amci.v13i2.555. [8] MIN Hai, ZHANG Yemao, ZHAO Yang, et al. Hybrid feature enhancement network for few-shot semantic segmentation[J]. Pattern Recognition, 2023, 137: 109291. doi: 10.1016/j.patcog.2022.109291. [9] CHENG Huixian, HAN Xianfeng, and XIAO Guoqiang. TransRVNet: LiDAR semantic segmentation with transformer[J]. IEEE Transactions on Intelligent Transportation Systems, 2023, 24(6): 5895–5907. doi: 10.1109/TITS.2023.3248117. [10] GROSSBERG S. Recurrent neural networks[J]. Scholarpedia, 2013, 8(2): 1888. doi: 10.4249/scholarpedia.1888. [11] ZAGORUYKO S and KOMODAKIS N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer[C]. 5th International Conference on Learning Representations, Toulon, France, 2017. [12] KHAN S, MUHAMMAD K, HUSSAIN T, et al. DeepSmoke: Deep learning model for smoke detection and segmentation in outdoor environments[J]. Expert Systems with Applications, 2021, 182: 115125. doi: 10.1016/j.eswa.2021.115125. [13] HUANG Yonghao, CHEN Leiting, ZHOU Chuan, et al. Model long-range dependencies for multi-modality and multi-view retinopathy diagnosis through transformers[J]. Knowledge-Based Systems, 2023, 271: 110544. doi: 10.1016/j.knosys.2023.110544. [14] HUTCHINS D, SCHLAG I, WU Yuhuai, et al. Block-recurrent transformers[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 2409. [15] GAO Mingyu, QI Dawei, MU Hongbo, et al. A transfer residual neural network based on ResNet-34 for detection of wood knot defects[J]. Forests, 2021, 12(2): 212. doi: 10.3390/f12020212. [16] LI Xiuqing, CHEN Zhenxue, WU Q M J, et al. 3D parallel fully convolutional networks for real-time video wildfire smoke detection[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2020, 30(1): 89–103. doi: 10.1109/TCSVT.2018.2889193. [17] 张俊鹏, 刘辉, 李清荣. 基于FCN-LSTM的工业烟尘图像分割[J]. 计算机工程与科学, 2021, 43(5): 907–916. doi: 10.3969/j.issn.1007-130X.2021.05.018.ZHANG Junpeng, LIU Hui, and LI Qingrong. An industrial smoke image segmentation method based on FCN-LSTM[J]. Computer Engineering & Science, 2021, 43(5): 907–916. doi: 10.3969/j.issn.1007-130X.2021.05.018. [18] YUAN Feiniu, ZHANG Lin, XIA Xue, et al. Deep smoke segmentation[J]. Neurocomputing, 2019, 357: 248–260. doi: 10.1016/j.neucom.2019.05.011. [19] YUAN Feiniu, ZHANG Lin, XIA Xue, et al. A wave-shaped deep neural network for smoke density estimation[J]. IEEE Transactions on Image Processing, 2020, 29: 2301–2313. doi: 10.1109/TIP.2019.2946126. [20] TAO Huanjie and DUAN Qianyue. Learning discriminative feature representation for estimating smoke density of smoky vehicle rear[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(12): 23136–23147. doi: 10.1109/TITS.2022.3198047. [21] YAN Siyuan, ZHANG Jing, and BARNES N. Transmission-guided Bayesian generative model for smoke segmentation[C]. Proceedings of the 36th AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2022: 3009–3017. doi: 10.1609/aaai.v36i3.20207. [22] HE Qiqi, YANG Qiuju, and XIE Minghao. HCTNet: A hybrid CNN-transformer network for breast ultrasound image segmentation[J]. Computers in Biology and Medicine, 2023, 155: 106629. doi: 10.1016/j.compbiomed.2023.106629. [23] CHEN Jieneng, LU Yongyi, YU Qihang, et al. TransUNet: Transformers make strong encoders for medical image segmentation[J]. arXiv preprint arXiv, 2021: 2102.04306. doi: 10.48550/arXiv.2102.04306. [24] GHOSH R and BOVOLO F. An FFT-based CNN-transformer encoder for semantic segmentation of radar sounder signal[C]. Proceedings of SPIE 12267, Image and Signal Processing for Remote Sensing XXVIII, Berlin, Germany, 2022: 122670R. doi: 10.1117/12.2636693. [25] LABBIHI I, EL MESLOUHI O, BENADDY M, et al. Combining frequency transformer and CNNs for medical image segmentation[J]. Multimedia Tools and Applications, 2024, 83(7): 21197–21212. doi: 10.1007/s11042-023-16279-9. [26] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[C]. The 9th International Conference on Learning Representations, 2021. [27] ZHENG Sixiao, LU Jiachen, ZHAO Hengshuang, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 6877–6886. doi: 10.1109/CVPR46437.2021.00681. [28] SUN Yu, ZHI Xiyang, JIANG Shikai, et al. Image fusion for the novelty rotating synthetic aperture system based on vision transformer[J]. Information Fusion, 2024, 104: 102163. doi: 10.1016/j.inffus.2023.102163. [29] HUANG Zilong, WANG Xinggang, HUANG Lichao, et al. CCNet: Criss-cross attention for semantic segmentation[C]. The IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 603–612. doi: 10.1109/ICCV.2019.00069. [30] WANG Xiaolong, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7794–7803. doi: 10.1109/CVPR.2018.00813. [31] LONG J, SHELHAMER E, and DARRELL T. Fully convolutional networks for semantic segmentation[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 3431–3440. doi: 10.1109/CVPR.2015.7298965. [32] WEN Gang, ZHOU Fangrong, MA Yutang, et al. A dense multi-scale context and asymmetric pooling embedding network for smoke segmentation[J]. IET Computer Vision, 2024, 18(2): 236–246. doi: 10.1049/cvi2.12246. [33] ZHANG Yundong, LIU Huiye, and HU Qiang. TransFuse: Fusing transformers and CNNs for medical image segmentation[C]. The 24th International Conference on Medical Image Computing and Computer Assisted Intervention, Strasbourg, France, 2021: 14–24. doi: 10.1007/978-3-030-87193-2_2. -


 下载:
下载:










图(10) / 表(5)
计量
- 文章访问数: 773
- HTML全文浏览量: 379
- PDF下载量: 56
- 被引次数: 0
