

Scene Text Detection Based on High Resolution Extended Pyramid
-
摘要: 文本检测作为计算机视觉领域一项重要分支,在文字翻译、自动驾驶和票据信息处理等方面具有重要的应用价值。当前文本检测算法仍无法解决实际拍摄图像的部分文本分辨率低、尺度变化大和有效特征不足的问题。针对上述待解决的问题,该文提出一种基于高分辨扩展金字塔的场景文本检测方法(HREPNet)。首先,构造一种改进型特征金字塔,引入高分辨扩展层和超分辨特征模块,有效增强文本分辨率特征,解决部分文本分辨率低的问题;同时,在主干网络传递特征过程中引入多尺度特征提取模块,通过多分支空洞卷积结构与注意力机制,充分获取文本多尺度特征,解决文本尺度变化大的问题;最后,提出高效特征融合模块,选择性融合高分辨特征和多尺度特征,从而减少模型的空间信息的丢失,解决有效特征不足的问题。实验结果表明,HREPNet在公开数据集ICDAR2015, CTW1500和Total-Text上综合指标F值分别提高了7.6%, 5.5%和3.0%,在准确率召回率上都得到显著提升;此外,HREPNet对不同尺度和分辨率的文本检测效果均有明显提升,对小尺度和低分辨率文本提升尤为显著。Abstract:
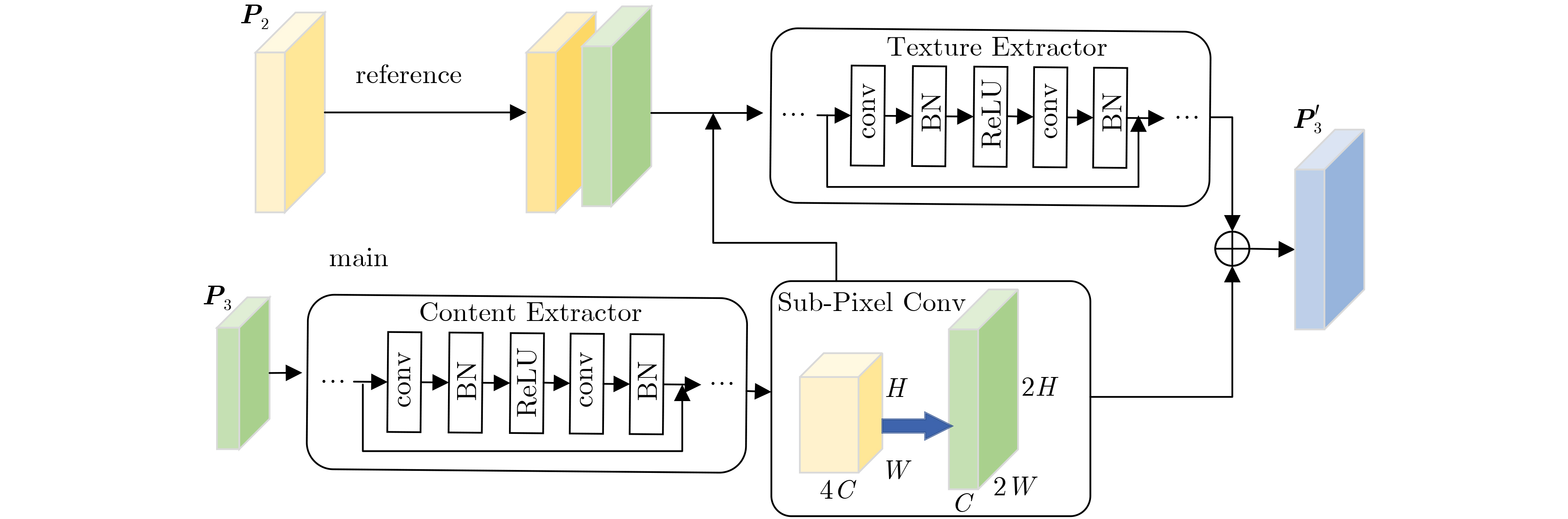
Objective Text detection, a critical branch of computer vision, has significant applications in text translation, autonomous driving, and hill information processing. Although existing text detection methods have improved detection performance, several challenges remain in complex natural scenes. Scene text exhibits substantial scale variations, making multi-scale text detection difficult. Additionally, inadequate feature utilization hampers the detection of small-scale text. Furthermore, increasing the receptive field often necessitates reducing image resolution, which results in severe spatial information loss and diminished feature saliency. To address these challenges, this study proposes the High-Resolution Extended Pyramid Network (HREPNet), a scene text detection method based on a high-resolution extended pyramid structure. Methods First, an improved feature pyramid was constructed by incorporating a high-resolution extension layer and a super-resolution feature module to enhance text resolution features and address the issue of low-resolution text. Additionally, a multi-scale feature extraction module was integrated into the backbone network to facilitate feature transfer. By leveraging a multi-branch dilated convolution structure and an attention mechanism, the model effectively captured multi-scale text features, mitigating the challenge posed by significant variations in text scale. Finally, an efficient feature fusion module was proposed to selectively integrate high-resolution and multi-scale features, thereby minimizing spatial information loss and addressing the problem of insufficient effective features. Results and Discussions Ablation experiments demonstrated that the simultaneous application of HREP, Multi-scale Feature Extraction Module (MFEM) and Efficient Feature Fusion Module (EFFM) significantly enhanced the model’s text detection performance. Compared with the baseline, the proposed method improved accuracy and recall by 6.3% and 8.9%, respectively, while increasing the F-measure by 7.6%. These improvements can be attributed to MFEM, which enhances multi-scale text detection, facilitates efficient feature transmission from the top to the bottom of the high-resolution extended pyramid, and supports the extraction of text features at different scales. This process enables HRFP to generate high-resolution features, thereby substantially improving the detection of low-resolution and small-scale text. Moreover, the large number of feature maps generated by HREP and MFEM are refined through EFFM, which effectively suppresses spatial redundancy and enhances feature expression. The proposed method demonstrated significant improvements in detecting text across different scales, with a more pronounced effect on small-scale text compared to large-scale text. Visualization results illustrate that, for small-scale text images (384 pixel), the detected text box area of the proposed method aligns more closely with the actual text area than that of the baseline method. Experimental results confirm that HREPNet significantly improves the accuracy of small-scale text detection. Additionally, for large-scale text images (2,048 pixel), the number of correctly detected text boxes increased considerably, demonstrating a substantial improvement in recall for large-scale text detection. Comparative experiments on public datasets further validated the effectiveness of HREPNet. The F-measure improved by 7.6% on ICDAR2015, 5.5% on CTW1500, and 3.0% on Total-Text, with significant enhancements in both precision and recall. Conclusions To address challenges related to large-scale variation, low resolution, and insufficient effective features in natural scene text detection, this study proposes a text detection network based on a High-Resolution Extended Pyramid. The High-Resolution Extended Pyramid is designed with the MFEM and the EFFM. Ablation experiments demonstrate that each proposed improvement enhances text detection performance compared with the baseline model, with the modules complementing each other to further optimize model performance. Comparative experiments on text images of different scales show that HREPNet improves text detection across various scales, with a more pronounced enhancement for small-scale text. Furthermore, experiments on natural scene and curved text demonstrate that HREPNet outperforms other advanced algorithms across multiple evaluation metrics, exhibiting strong performance in both natural scene and curved text detection. The method also demonstrates robustness and generalization capabilities. However, despite its robustness, the model has a relatively large number of parameters, which leads to slow inference speed. Future research will focus on optimizing the network to reduce the number of parameters and improve inference speed while maintaining accuracy, recall, and F-measure. -
表 1 各个创新点的影响实验结果
HREP MFEM EFFM EFFM* P R F 83.6 74.0 78.5 √ 85.4 75.6 80.2 √ 87.4 74.4 80.4 √ 85.7 80.1 82.8 √ √ 88.7 80.3 84.3 √ √ 88.2 77.1 82.3 √ √ √ 88.9 80.6 84.5 √ √ √ 88.5 79.9 84.0 注:EFFM*表示不进行交叉重构  下载: 导出CSV
下载: 导出CSV
表 2 MFEM模块中膨胀系数的选择对模型检测效果的影响
膨胀系数 ICDAR2015 CTW1500 P R F P R F (1,2) 87.3 79.6 83.3 85.4 79.3 82.2 (1,4) 88.4 80.3 84.2 86.2 78.6 82.2 (1,2,4) 88.9 80.6 84.5 87.1 80.7 83.8 (1,2,6) 88.1 79.8 83.7 86.3 78.9 82.4 (1,2,4,6) 87.9 78.2 82.8 86.5 78.4 82.3
下载: 导出CSV
表 3 公开数据集上本文方法与其它方法的比较结果
方法 Exit CTW1500 Total-Text ICDAR2015 P R F P R F P R F PSENet (2019) [11] × 80.6 75.6 78.0 81.8 75.1 78.3 81.5 79.7 80.6 PAN (2019) [32] √ 86.4 81.2 83.7 88.0 79.4 83.5 82.9 77.8 80.3 TextField (2019) [33] √ 83.0 79.8 81.4 81.2 79.9 80.6 84.3 80.5 82.4 DBNet (2022) [12] √ 84.3 79.1 81.6 87.1 82.5 84.7 86.5 80.2 83.2 FCENet (2021) [15] × 85.7 80.7 83.1 87.4 79.8 83.4 85.1 84.2 84.6 PCR (2021) [14] × 85.3 79.8 82.4 86.1 80.2 83.1 - - - CM-Net (2022) [31] × 86.0 82.2 84.1 88.5 81.4 84.8 86.7 81.3 83.9 Wang et al. (2023) [30] × 84.6 77.7 81.0 88.7 79.9 84.1 88.1 78.8 83.2 baseline × 82.6 76.4 79.4 87.3 77.9 82.3 83.6 74.0 78.5 本文方法 × 87.1 80.7 83.8 88.8 81.2 84.8 88.9 80.6 84.5
下载: 导出CSV
-
[1] WANG Xiaofeng, HE Zhihuang, WANG Kai, et al. A survey of text detection and recognition algorithms based on deep learning technology[J]. Neurocomputing, 2023, 556: 126702. doi: 10.1016/j.neucom.2023.126702. [2] NAIEMI F, GHODS V, and KHALESI H. Scene text detection and recognition: A survey[J]. Multimedia Tools and Applications, 2022, 81(14): 20255–20290. doi: 10.1007/s11042-022-12693-7. [3] 连哲, 殷雁君, 智敏, 等. 自然场景文本检测中可微分二值化技术综述[J]. 计算机科学与探索, 2024, 18(9): 2239–2260. doi: 10.3778/j.issn.1673-9418.2311105.LIAN Zhe, YIN Yanjun, ZHI Min, et al. Review of differentiable binarization techniques for text detection in natural scenes[J]. Journal of Frontiers of Computer Science and Technology, 2024, 18(9): 2239–2260. doi: 10.3778/j.issn.1673-9418.2311105. [4] EPSHTEIN B, OFEK E, and WEXLER Y. Detecting text in natural scenes with stroke width transform[C]. 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, USA, 2010: 2963–2970. doi: 10.1109/CVPR.2010.5540041. [5] LI Qian, PENG Hao, LI Jianxin, et al. A survey on text classification: From traditional to deep learning[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2022, 13(2): 31. doi: 10.1145/3495162. [6] KIM K I, JUNG K, and KIM J H. Texture-based approach for text detection in images using support vector machines and continuously adaptive mean shift algorithm[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(12): 1631–1639. doi: 10.1109/TPAMI.2003.1251157. [7] TIAN Zhi, HUANG Weilin, HE Tong, et al. Detecting text in natural image with connectionist text proposal network[C]. The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 56–72. doi: 10.1007/978-3-319-46484-8_4. [8] BAEK Y, LEE B, HAN D, et al. Character region awareness for text detection[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 9365–9374. doi: 10.1109/CVPR.2019.00959. [9] HE Minghang, LIAO Minghui, YANG Zhibo, et al. MOST: A multi-oriented scene text detector with localization refinement[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 8813–8822. doi: 10.1109/CVPR46437.2021.00870. [10] DENG Dan, LIU Haifeng, LI Xuelong, et al. PixelLink: Detecting scene text via instance segmentation[C]. The 32nd AAAI Conference on Artificial Intelligence, New Orleans, USA, 2018. doi: 10.1609/aaai.v32i1.12269. [11] WANG Wenhai, XIE Enze, LI Xiang, et al. Shape robust text detection with progressive scale expansion network[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 9336–9345. doi: 10.1109/CVPR.2019.00956. [12] LIAO Minghui, ZOU Zhisheng, WAN Zhaoyi, et al. Real-time scene text detection with differentiable binarization and adaptive scale fusion[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(1): 919–931. doi: 10.1109/TPAMI.2022.3155612. [13] ZHANG Chengquan, LIANG Borong, HUANG Zuming, et al. Look more than once: An accurate detector for text of arbitrary shapes[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 10552–10561. doi: 10.1109/CVPR.2019.01080. [14] DAI Pengwen, ZHANG Sanyi, ZHANG Hua, et al. Progressive contour regression for arbitrary-shape scene text detection[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 7393–7402. doi: 10.1109/CVPR46437.2021.00731. [15] ZHU Yiqin, CHEN Jianyong, LIANG Lingyu, et al. Fourier contour embedding for arbitrary-shaped text detection[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 3123–3131. doi: 10.1109/CVPR46437.2021.00314. [16] ZHANG Shixue, YANG Chun, ZHU Xiaobin, et al. Arbitrary shape text detection via boundary transformer[J]. IEEE Transactions on Multimedia, 2024, 26: 1747–1760. doi: 10.1109/TMM.2023.3286657. [17] YE Maoyuan, ZHANG Jing, ZHAO Shanshan, et al. DPText-DETR: Towards better scene text detection with dynamic points in transformer[C]. The 37th AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 3241–3249. doi: 10.1609/aaai.v37i3.25430. [18] YU Wenwen, LIU Yuliang, HUA Wei, et al. Turning a CLIP model into a scene text detector[C].2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 6978–6988. doi: 10.1109/CVPR52729.2023.00674. [19] YE Maoyuan, ZHANG Jing, ZHAO Shanshan, et al. DeepSolo: Let transformer decoder with explicit points solo for text spotting[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 19348–19357. doi: 10.1109/CVPR52729.2023.01854. [20] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, SUA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [21] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2117–2125. doi: 10.1109/CVPR.2017.106. [22] DENG Chunfang, WANG Mengmeng, LIU Liang, et al. Extended feature pyramid network for small object detection[J]. IEEE Transactions on Multimedia, 2022, 24: 1968–1979. doi: 10.1109/TMM.2021.3074273. [23] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834–848. doi: 10.1109/TPAMI.2017.2699184. [24] ZHANG Qiulin, JIANG Zhuqing, LU Qishuo, et al. Split to be slim: An overlooked redundancy in vanilla convolution[C]. The 29th International Joint Conference on Artificial Intelligence, 2021: 3195–3201. doi: 10.24963/ijcai.2020/442. [25] WU Yuxin and HE Kaiming. Group normalization[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 3–19. doi: 10.1007/978-3-030-01261-8_1. [26] LI Jiafeng, WEN Ying, and HE Lianghua. SCConv: Spatial and channel reconstruction convolution for feature redundancy[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 6153–6162. doi: 10.1109/CVPR52729.2023.00596. [27] KARATZAS D, GOMEZ-BIGORDA L, NICOLAOU A, et al. ICDAR 2015 competition on robust reading[C]. 2015 13th International Conference on Document Analysis and Recognition, Tunis, Tunisia, 2015: 1156–1160. doi: 10.1109/ICDAR.2015.7333942. [28] LIU Yuliang and JIN Lianwen. Deep matching prior network: Toward tighter multi-oriented text detection[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 1962–1969. doi: 10.1109/CVPR.2017.368. [29] CH'NG C K and CHAN C S. Total-text: A comprehensive dataset for scene text detection and recognition[C]. 2017 14th IAPR International Conference on Document Analysis and Recognition, Kyoto, Japan, 2017, 1: 935–942. doi: 10.1109/ICDAR.2017.157. [30] WANG Fangfang, XU Xiaogang, CHEN Yifeng, et al. Fuzzy semantics for arbitrary-shaped scene text detection[J]. IEEE Transactions on Image Processing, 2023, 32: 1–12. doi: 10.1109/TIP.2022.3201467. [31] YANG Chuang, CHEN Mulin, XIONG Zhitong, et al. CM-Net: Concentric mask based arbitrary-shaped text detection[J]. IEEE Transactions on Image Processing, 2022, 31: 2864–2877. doi: 10.1109/TIP.2022.3141844. [32] WANG Wenhai, XIE Enze, SONG Xiaoge, et al. Efficient and accurate arbitrary-shaped text detection with pixel aggregation network[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 8440–8449. doi: 10.1109/ICCV.2019.00853. [33] XU Yongchao, WANG Yukang, ZHOU Wei, et al. TextField: Learning a deep direction field for irregular scene text detection[J]. IEEE Transactions on Image Processing, 2019, 28(11): 5566–5579. doi: 10.1109/TIP.2019.2900589. [34] PENG Jingchao, ZHAO Haitao, ZHAO Kaijie, et al. CourtNet: Dynamically balance the precision and recall rates in infrared small target detection[J]. Expert Systems with Applications, 2023, 233: 120996. doi: 10.1016/j.eswa.2023.120996. -


 下载:
下载:








图(8) / 表(3)
计量
- 文章访问数: 1067
- HTML全文浏览量: 550
- PDF下载量: 109
- 被引次数: 0
