

A Short-time Window ElectroEncephaloGram Auditory Attention Decoding Network Based on Multi-dimensional Characteristics of Temporal-spatial-frequency
-
摘要: 在鸡尾酒会场景中,听力正常的人有能力选择性地注意特定的说话者语音,但听力障碍者在这种场景中面临困难。听觉注意力解码(AAD)的目的是通过分析听者的脑电信号(EEG)响应特征来推断听者关注的是哪个说话者。现有的AAD模型只考虑脑电信号的时域或频域单个特征或二者的组合(如时频特征),而忽略了时-空-频域特征之间的互补性,这在一定程度上限制了模型的分类能力,进而影响了模型在决策窗口上的解码精度。同时,已有AAD模型大多在长时决策窗口(1~5 s)中有较高的解码精度。该文提出一种基于时-空-频多维特征的短时窗口脑电信号听觉注意解码网络(TSF-AADNet),用于提高短时决策窗口(0.1~1 s)的解码精度。该模型由两个并行的时空、频空特征提取分支以及特征融合和分类模块组成,其中,时空特征提取分支由时空卷积块和高阶特征交互模块组成,频空特征提取分支采用基于频空注意力的3维卷积模块(FSA-3DCNN),最后将双分支网络提取的时空和频空特征进行融合,得到最终的听觉注意力二分类解码结果。实验结果表明,TSF-AADNet模型在听觉注意检测数据集KULeuven(KUL)和听觉注意检测的脑电和音频数据集(DTU)的0.1 s决策窗口下,解码精度分别为91.8%和81.1%,与最新的AAD模型一种基于时频融合的双分支并行网络(DBPNet)相比,分别提高了5.40%和7.99%。TSF-AADNet作为一种新的短时决策窗口的AAD模型,可为听力障碍诊断以及神经导向助听器研发提供有效参考。Abstract:
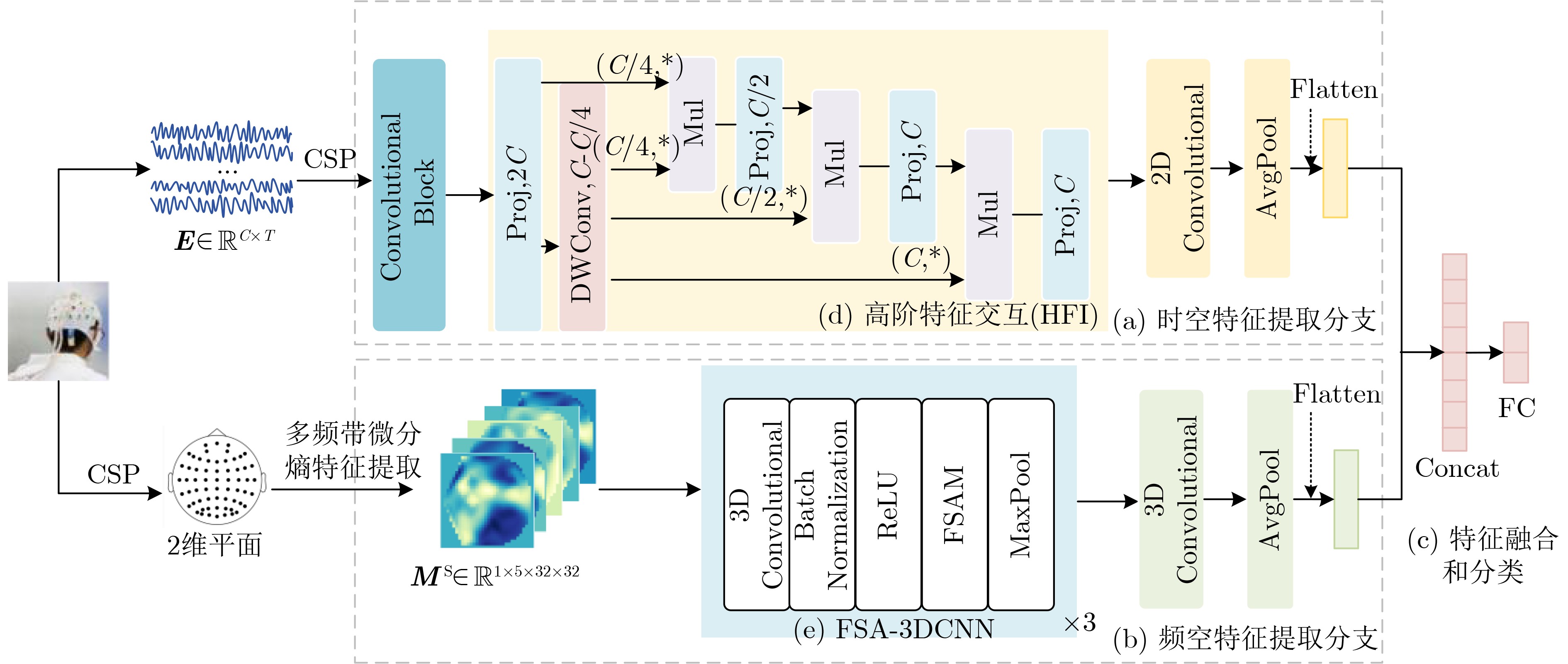
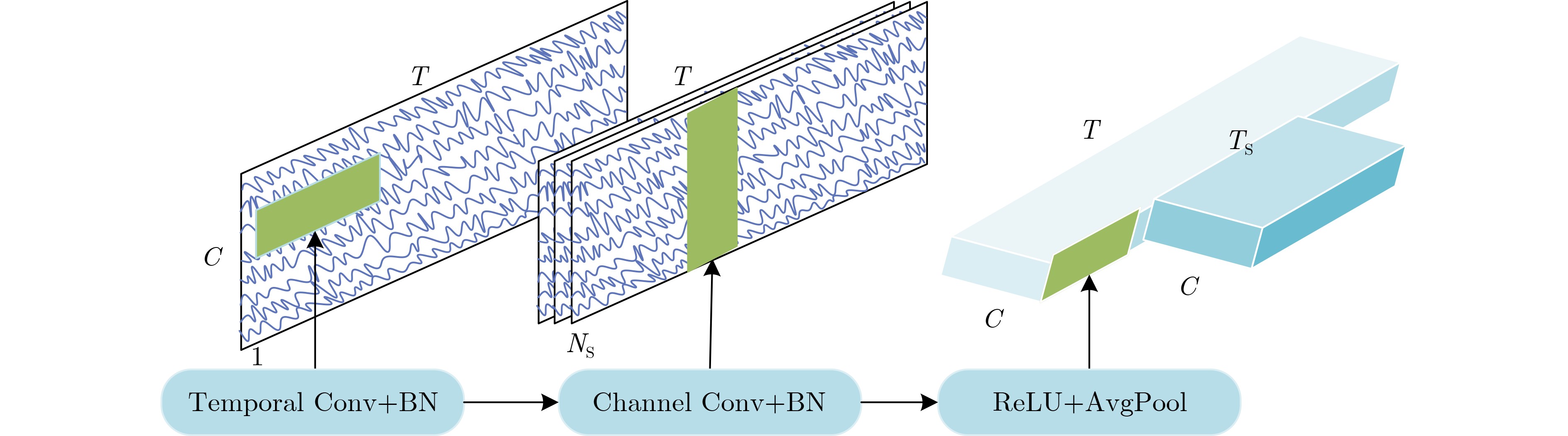
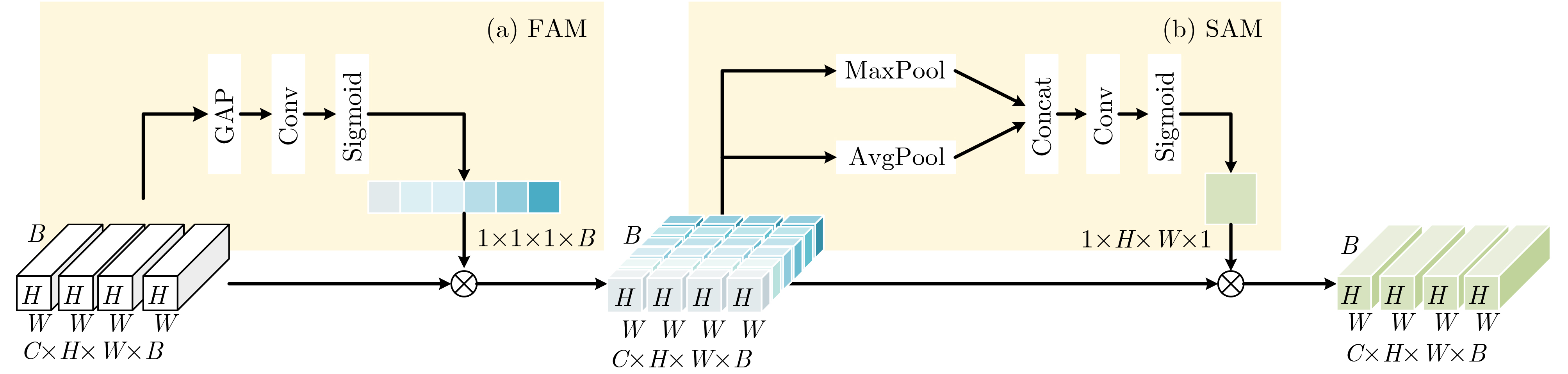
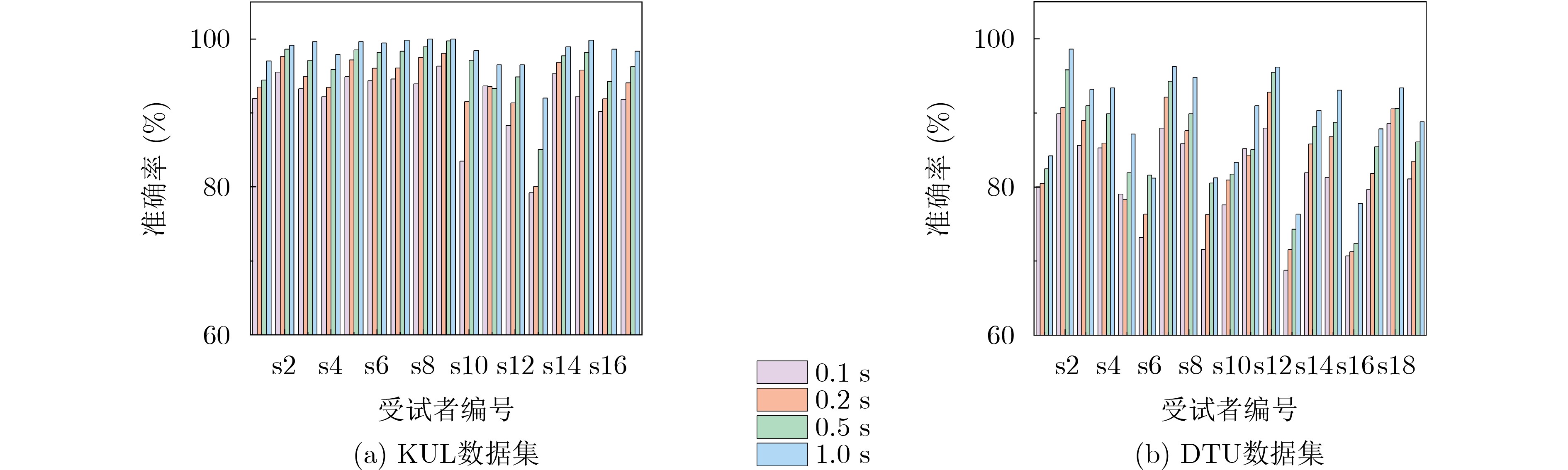
Objective In cocktail party scenarios, individuals with normal hearing can selectively focus on specific speakers, whereas individuals with hearing impairments often struggle in such environments. Auditory Attention Decoding (AAD) aims to infer the speaker that a listener is attending to by analyzing their brain’s electrical response, recorded through ElectroEncephaloGram (EEG). Existing AAD models typically focus on a single feature of EEG signals in the time domain, frequency domain, or time-frequency domain, often overlooking the complementary characteristics across the time-space-frequency domain. This limitation constrains the model’s classification ability, ultimately affecting decoding accuracy within a decision window. Moreover, while many current AAD models exhibit high accuracy over long-term decision windows (1~5 s), real-time AAD in practical applications necessitates a more robust approach to short-term EEG signals. Methods This paper proposes a short-window EEG auditory attention decoding network, Temporal-Spatial-Frequency Features-AADNet (TSF-AADNet), designed to enhance decoding accuracy in short decision windows (0.1~1 s). TSF-AADNet decodes the focus of auditory attention from EEG signals, eliminating the need for speech separation. The model consists of two parallel branches: one for spatiotemporal feature extraction, and another for frequency-space feature extraction, followed by feature fusion and classification. The spatiotemporal feature extraction branch includes a spatiotemporal convolution block, a high-order feature interaction module, a two-dimensional convolution layer, an adaptive average pooling layer, and a Fully Connected (FC) layer. The spatiotemporal convolution block can effectively extract EEG features across both time and space dimensions, capturing the correlation between signals at different time points and electrode positions. The high-order feature interaction module further enhances feature interactions at different levels, improving the model’s feature representation ability. The frequency-space feature extraction branch is composed of an FSA-3DCNN module, a 3D convolutional layer, and an adaptive average pooling layer, all based on frequency-space attention. The FSA-3DCNN module highlights key information in the EEG signals’ frequency and spatial dimensions, strengthening the model’s ability to extract features specific to certain frequencies and spatial positions. The spatiotemporal features from the spatiotemporal attention branch and the frequency-space features from the frequency-space attention branch are fused, fully utilizing the complementarity between the spatiotemporal and frequency domains of EEG signals. This fusion enables the final binary decoding of auditory attention and significantly improves decoding performance within the short decision window. Results and Discussions The TSF-AADNet model proposed in this paper is evaluated on four types of short-time decision windows using the KUL and DTU datasets. The decision window durations range from very short to relatively short, covering various real-world scenarios such as instantaneous information capture in real-time communication and rapid auditory response situations. The experimental results are presented in Figure 4 . Under the short decision window conditions, the TSF-AADNet model demonstrates excellent performance on both the KUL and DTU datasets. In testing with the KUL dataset, the model’s decoding accuracy increases steadily and significantly as the decision window duration extends from the shortest time. This indicates that the model effectively adapts to decision windows of varying lengths, accurately extracting key information from complex EEG signals to achieve precise decoding. Similarly, for the DTU dataset, the decoding accuracy of the TSF-AADNet model improves as the decision window lengthens. This result aligns with prior studies in the field, further confirming the robustness and effectiveness of TSF-AADNet in short-time decision window decoding tasks. Additionally, to evaluate the specific contributions of each module in the TSF-AADNet model, ablation experiments are conducted on various modules. Ablation of two single-branch networks, without feature fusion, highlights the importance of integrating time-space-frequency features simultaneously. The contributions of the frequency attention and spatial attention mechanisms in the FSA-3DCNN module are also verified by removing key modules and comparing the model’s performance before and after each removal. (Figure 7 ) Accuracy of the TSF-AADNet model for decoding auditory attention of all subjects on the KUL and DTU datasets with short decision windows; Average AAD accuracy of various models with four types of short decision windows on KUL and DTU datasets are shown. (Table 3 )Conclusions To evaluate the performance of the proposed AAD model, TSF-AADNet is compared with five other AAD classification models across four short-time decision windows using the KUL and DTU datasets. The experimental results demonstrate that the decoding accuracy of the TSF-AADNet model is 91.8% for the KUL dataset and 81.1% for the DTU dataset under the 0.1 s decision window, exceeding the latest AAD model, DBPNet, by 5.4% and 7.99%, respectively. Therefore, TSF-AADNet, as a novel model for short-time decision window AAD, provides an effective reference for the diagnosis of hearing disorders and the development of neuro-oriented hearing aids. -
表 1 时空、频空特征提取分支和特征融合与分类层中各层的输出值
分支 层 输入特征维度 输出特征维度 时空特征提取分支(TSAnet) 卷积块(Convolutional Block) $1 \times 64 \times 128$ $64 \times 1 \times 64$ 高阶特征交互模块(HFI) $64 \times 1 \times 64$ $64 \times 1 \times 64$ 2维卷积层 $64 \times 1 \times 64$ $4 \times 1 \times 64$ 自适应平均池化层 $4 \times 1 \times 64$ $4 \times 1 \times 1$ 全连接层 $4 \times 1 \times 1$ $4$ 频空特征提取分支(FSAnet) FSA-3DCNN $1 \times 5 \times 32 \times 32$ $128 \times 5 \times 4 \times 4$ 3维卷积层 $128 \times 5 \times 4 \times 4$ $4 \times 5 \times 4 \times 4$ 自适应平均池化层 $4 \times 5 \times 4 \times 4$ $4 \times 1 \times 1 \times 1$ 全连接层 $4 \times 1 \times 1 \times 1$ $4$ 特征融合与分类层 拼接(Concat) 8 8 全连接层 8 2  下载: 导出CSV
下载: 导出CSV
表 2 实验中使用的脑电图数据集KUL, DTU的详细信息
数据集 受试者个数 刺激语言 每个受试者的试验持续时间(min) 总时长(h) KUL 16 佛兰德语 48 12.8 DTU 18 丹麦语 50 15.0
下载: 导出CSV
表 3 KUL, DTU数据集上4种短决策窗口的各种模型的平均AAD准确率(%)
数据集 模型 样本时长(s) 0.1 0.2 0.5 1.0 KUL CNN[14] 74.3 78.2 80.6 84.1 STAnet[17] 80.8 84.3 87.2 90.1 RGCnet[29] 87.6 88.9 90.1 91.4 mRFInet[30] 87.4 89.7 90.8 92.5 DBPNet[31] 87.1 89.9 92.9 95.0 TSF-AADNet(本文) 91.8 94.1 96.3 98.3 DTU CNN[14] 56.7 58.4 61.7 63.3 STAnet[17] 65.7 68.1 70.8 71.9 RGCnet[29] 66.4 68.4 72.1 76.9 mRFInet[30] 65.4 68.7 72.3 75.1 DBPNet[31] 75.1 78.9 81.9 83.9 TSF-AADNet(本文) 81.1 83.5 86.1 88.8
下载: 导出CSV
-
[1] CHERRY E C. Some experiments on the recognition of speech, with one and with two ears[J]. The Journal of the Acoustical Society of America, 1953, 25(5): 975–979. doi: 10.1121/1.1907229. [2] WANG Deliang. Deep learning reinvents the hearing aid[J]. IEEE Spectrum, 2017, 54(3): 32–37. doi: 10.1109/MSPEC.2017.7864754. [3] ZHANG Malu, WU Jibin, CHUA Yansong, et al. MPD-AL: An efficient membrane potential driven aggregate-label learning algorithm for spiking neurons[C]. The 33rd AAAI Conference on Artificial Intelligence, Hawaii, USA, 2019: 1327–1334. doi: 10.1609/aaai.v33i01.33011327. [4] MESGARANI N and CHANG E F. Selective cortical representation of attended speaker in multi-talker speech perception[J]. Nature, 2012, 485(7397): 233–236. doi: 10.1038/nature11020. [5] DING Nai and SIMON J Z. Emergence of neural encoding of auditory objects while listening to competing speakers[J]. Proceedings of the National Academy of Sciences of the United States of America, 2012, 109(29): 11854–11859. doi: 10.1073/pnas.1205381109. [6] O'SULLIVAN J A, POWER A J, MESGARANI N, et al. Attentional selection in a cocktail party environment can be decoded from single-trial EEG[J]. Cerebral Cortex, 2015, 25(7): 1697–1706. doi: 10.1093/cercor/bht355. [7] CASARES A P. The brain of the future and the viability democratic governance: The role of artificial intelligence, cognitive machines, and viable systems[J]. Futrues, 2018, 103(OCT.): 5–16. doi: 10.1016/j.futures.2018.05.002. [8] CICCARELLI G, NOLAN M, PERRICONE J, et al. Comparison of two-talker attention decoding from EEG with nonlinear neural networks and linear methods[J]. Scientific Reports, 2019, 9(1): 11538. doi: 10.1038/s41598-019-47795-0. [9] FUGLSANG S A, DAU T, and HJORTKJÆR J. Noise-robust cortical tracking of attended speech in real-world acoustic scenes[J]. NeuroImage, 2017, 156: 435–444. doi: 10.1016/j.neuroimage.2017.04.026. [10] WONG D D E, FUGLSANG S A, HJORTKJÆR J, et al. A comparison of regularization methods in forward and backward models for auditory attention decoding[J]. Frontiers in Neuroscience, 2018, 12: 531. doi: 10.3389/fnins.2018.00531. [11] DE CHEVEIGNÉ A, WONG D D E, DI LIBERTO G M, et al. Decoding the auditory brain with canonical component analysis[J]. NeuroImage, 2018, 172: 206–216. doi: 10.1016/j.neuroimage.2018.01.033. [12] DE CHEVEIGNÉ A, DI LIBERTO G M, ARZOUNIAN D, et al. Multiway canonical correlation analysis of brain data[J]. NeuroImage, 2019, 186: 728–740. doi: 10.1016/j.neuroimage.2018.11.026. [13] ZWICKE E and FASTL H. Psychoacoustics: Facts and Models[M]. 2nd ed. New York: Springer, 1999. [14] VANDECAPPELLE S, DECKERS L, DAS N, et al. EEG-based detection of the locus of auditory attention with convolutional neural networks[J]. eLife, 2021, 10: e56481. doi: 10.7554/eLife.56481. [15] CAI Siqi, SU Enze, SONG Yonghao, et al. Low latency auditory attention detection with common spatial pattern analysis of EEG signals[C]. The INTERSPEECH 2020, Shanghai, China, 2020: 2772–2776. doi: 10.21437/Interspeech.2020-2496. [16] CAI Siqi, SU Enze, XIE Longhan, et al. EEG-based auditory attention detection via frequency and channel neural attention[J]. IEEE Transactions on Human-Machine Systems, 2022, 52(2): 256–266. doi: 10.1109/THMS.2021.3125283. [17] SU Enze, CAI Siqi, XIE Longhan, et al. STAnet: A spatiotemporal attention network for decoding auditory spatial attention from EEG[J]. IEEE Transactions on Biomedical Engineering, 2022, 69(7): 2233–2242. doi: 10.1109/TBME.2022.3140246. [18] JIANG Yifan, CHEN Ning, and JIN Jing. Detecting the locus of auditory attention based on the spectro-spatial-temporal analysis of EEG[J]. Journal of Neural Engineering, 2022, 19(5): 056035. doi: 10.1088/1741-2552/ac975c. [19] CAI Siqi, SCHULTZ T, and LI Haizhou. Brain topology modeling with EEG-graphs for auditory spatial attention detection[J]. IEEE Transactions on Biomedical Engineering, 2024, 71(1): 171–182. doi: 10.1109/TBME.2023.3294242. [20] XU Xiran, WANG Bo, YAN Yujie, et al. A DenseNet-based method for decoding auditory spatial attention with EEG[C]. The ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing, Seoul, Korea, Republic of, 2024: 1946–1950. doi: 10.1109/ICASSP48485.2024.10448013. [21] GEIRNAERT S, FRANCART T, and BERTRAND A. Fast EEG-based decoding of the directional focus of auditory attention using common spatial patterns[J]. IEEE Transactions on Biomedical Engineering, 2021, 68(5): 1557–1568. doi: 10.1109/TBME.2020.3033446. [22] SCHIRRMEISTER R T, SPRINGENBERG J T, FIEDERER L D J, et al. Deep learning with convolutional neural networks for EEG decoding and visualization[J]. Human Brain Mapping, 2017, 38(11): 5391–5420. doi: 10.1002/hbm.23730. [23] LAWHERN V J, SOLON A J, WAYTOWICH N R, et al. EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces[J]. Journal of Neural Engineering, 2018, 15(5): 056013. doi: 10.1088/1741-2552/aace8c. [24] RAO Yongming, ZHAO Wenliang, TANG Yansong, et al. HorNet: Efficient high-order spatial interactions with recursive gated convolutions[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 752. [25] LIU Yongjin, YU Minjing, ZHAO Guozhen, et al. Real-time movie-induced discrete emotion recognition from EEG signals[J]. IEEE Transactions on Affective Computing, 2018, 9(4): 550–562. doi: 10.1109/TAFFC.2017.2660485. [26] CAI Siqi, SUN Pengcheng, SCHULTZ T, et al. Low-latency auditory spatial attention detection based on spectro-spatial features from EEG[C]. 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society, Mexico, Mexico, 2021: 5812–5815. doi: 10.1109/EMBC46164.2021.9630902. [27] DAS N, FRANCAR T, and BERTRAND A. Auditory attention detection dataset KULeuven (OLD VERSION)[J]. Zenodo, 2019. doi: 10.5281/zenodo.3997352. [28] FUGLSANG S A, WONG D D E, and HJORTKJÆR J. EEG and audio dataset for auditory attention decoding[J]. Zenodo, 2018. doi: 10.5281/zenodo.1199011. [29] CAI Siqi, LI Jia, YANG Hongmeng, et al. RGCnet: An efficient recursive gated convolutional network for EEG-based auditory attention detection[C]. The 2023 45th Annual International Conference of the IEEE Engineering in Medicine & Biology Society, Sydney, Australia, 2023: 1–4. doi: 10.1109/EMBC40787.2023. 10340432. [30] LI Jia, ZHANG Ran, and CAI Siqi. Multi-scale recursive feature interaction for auditory attention detection using EEG signals[C]. 2024 IEEE International Symposium on Biomedical Imaging, Athens, Greece, 2024: 1–5. doi: 10.1109/ISBI56570.2024.10635751. [31] NI Qinke, ZHANG Hongyu, FAN Cunhang, et al. DBPNet: Dual-Branch Parallel Network with Temporal-Frequency Fusion for Auditory Attention Detection[C]. Proceedings of the International Joint Conference on Artificial Intelligence, Jeju, South Korea, 2024: 3115–3123. doi: 10.24963/ijcai.2024/345. -

 下载:
下载:
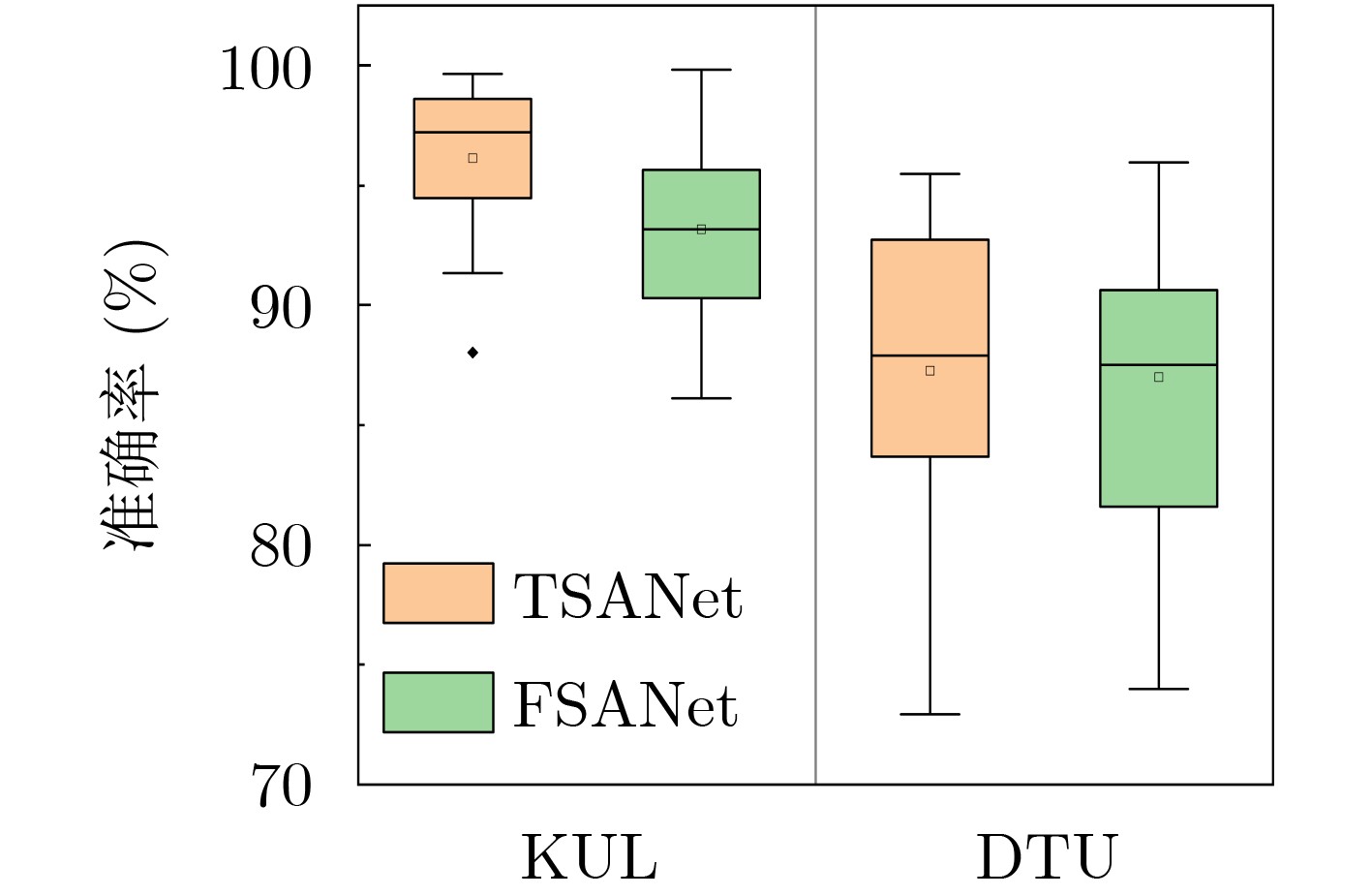
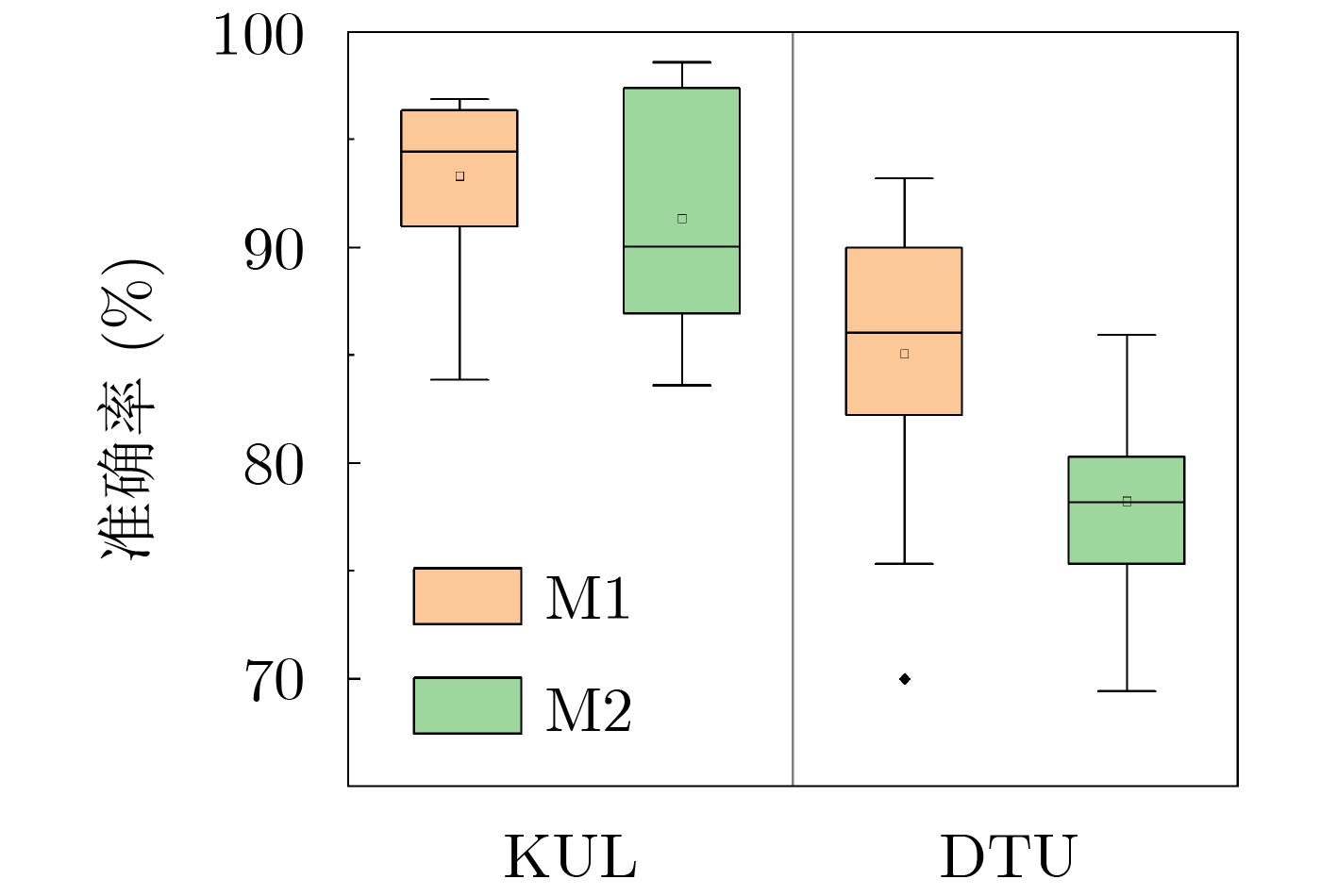
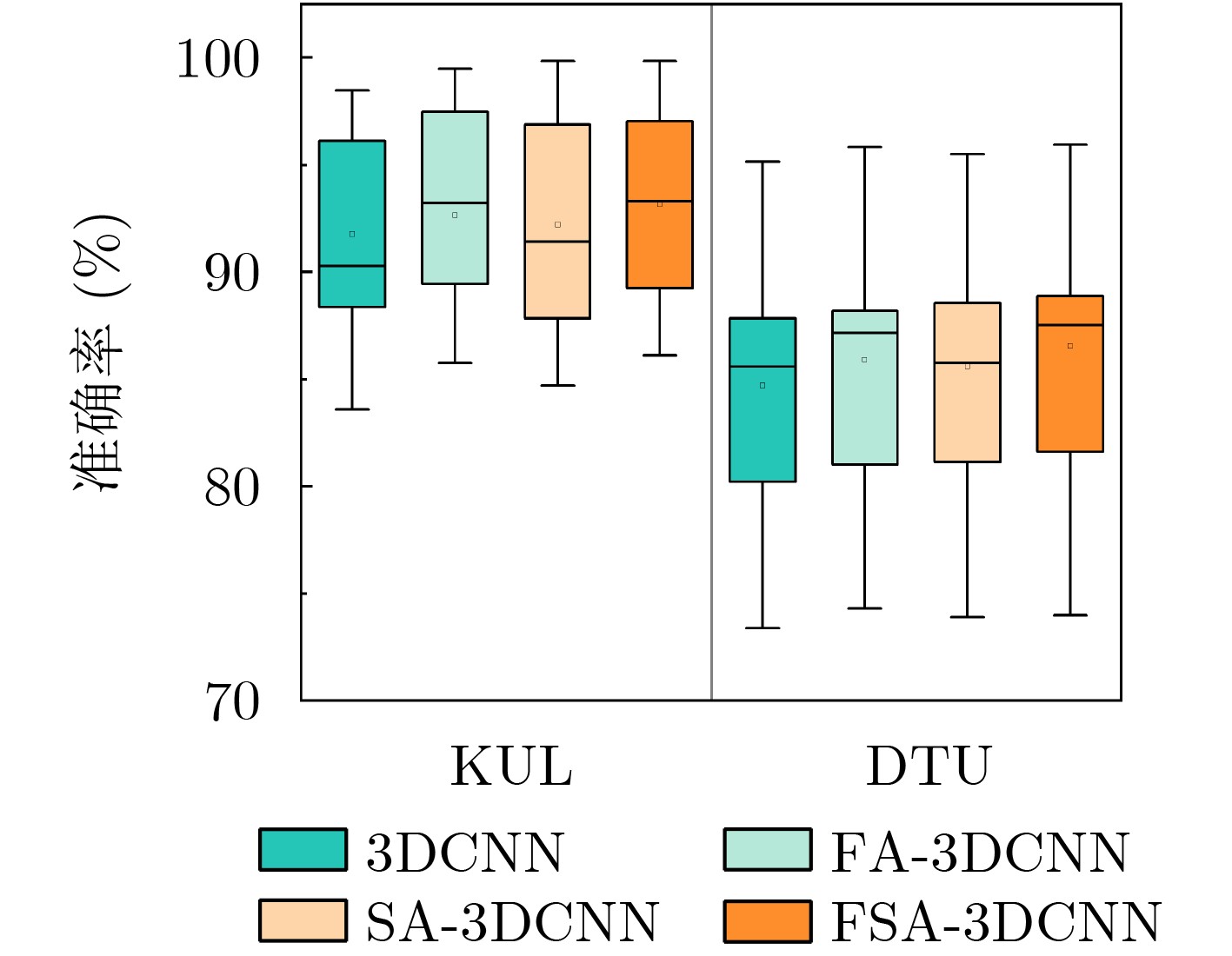


图(7) / 表(3)
计量
- 文章访问数: 1018
- HTML全文浏览量: 751
- PDF下载量: 120
- 被引次数: 0
