

Deep Active Time-series Clustering Based on Constraint Transitivity
-
摘要: 已有的深度主动聚类方法未能通过标注样本推理生成必须链接(ML)约束或不能链接(CL)约束,标注成本较高。为此该文提出一种基于约束传递的深度主动时序聚类方法。该方法设置了标注类簇集合(ACS)及相应的辅助标注集合(AAS)。通过预训练时序自编码器得到时序样本的表示向量。在深度聚类的每个训练轮次过程中,采样并标注表示空间中离类簇中心最近的样本存入ACS,使每个ACS内的样本属同一类别而ACS集合间的样本属于不同类别,然后从包含样本数最小的ACS集合中随机选取时序样本,采样并标注与该样本不属于同一类簇且距其所在类簇中心最近的时序样本存入AAS,使ACS与相应的AAS中的样本为不同类别,由ACS及对应的AAS中的样本推理生成ML和CL约束。由基于t-分布的类簇分布与其生成的辅助分布间的KL散度以及使满足ML及CL约束的时序样本在表示空间距离分别变小和变大的约束损失更新时序自编码器中编码网络参数和聚类中心。在18个公开数据集上的实验结果表明,该方法聚类效果在较低标注预算下平均RI值比已有的典型基线模型均提升5%以上。Abstract:
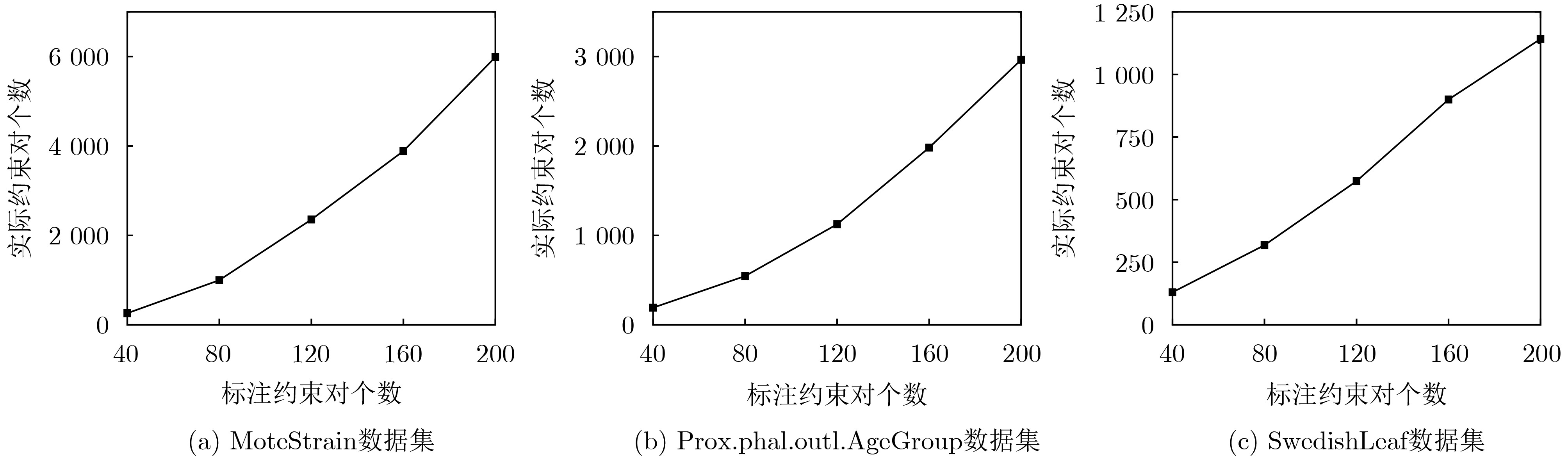
Objective The rapid advancement of the Internet of Things and sensor technology has led to the accumulation of vast amounts of unlabeled time-series data, making deep time-series clustering a key analytical approach. However, existing deep clustering methods lack supervised constraint information and label guidance, making them susceptible to noise and outliers. Deep semi-supervised clustering methods rely on predefined Must-Link (ML) and Cannot-Link (CL) constraints, limiting improvements in clustering performance. Existing active clustering approaches sample only within clusters in the representation space, overlooking pairwise annotations from different clusters. This results in lower-quality ML and CL constraints and prevents further extrapolation from manually annotated pairs, increasing annotation costs. To address these limitations, this paper proposes Deep Active Time-series Clustering based on Constraint Transitivity (DATC-CT), which improves clustering performance while reducing annotation costs. Methods DATC-CT defines an Annotation Cluster Set (ACS) and an Auxiliary Annotation Set (AAS) and obtains the representation vector of time-series samples using a pre-trained autoencoder. In each clustering epoch, samples closest to cluster centers in the representation space are selected, labeled, and stored in ACS. This ensures that all samples within an ACS belong to the same category, while those in different ACSs belong to different categories. Next, a time-series sample is randomly chosen from the ACS with the fewest samples. Another sample, which does not belong to the same cluster but is nearest to the selected sample’s center, is then sampled, labeled, and stored in either AAS or ACS. Samples in ACS and AAS belong to different categories. ML and CL constraints are inferred from these samples. The encoder’s network parameters and cluster centers are updated using KL divergence between the cluster distribution (modeled by a t-distribution) and an auxiliary distribution generated from it. Additionally, a constraint loss function is applied to increase the distance between ML-constrained samples while reducing the distance between CL-constrained samples in the representation space. Results and Discussions Experimental results on 18 public datasets show that the proposed method improves the average Rand Index (RI) by more than 5% compared to existing deep time-series clustering methods ( Table 2 ). With the same labeling budget, it achieves an RI improvement of over 7% compared to existing active clustering methods (Table 3 ). These findings confirm the effectiveness of the active sampling strategy and constraint reasoning mechanism. Additionally, the method infers a large number of ML and CL constraints from a small set of manually annotated constraints (Fig. 4 ), significantly reducing annotation costs.Conclusions This paper proposes a deep active time-series clustering model based on constraint transitivity, incorporating a two-phase active sampling strategy: exploration and consolidation. In the exploration phase, the model selects the sample closest to each cluster center in the representation space and stores it in ACS. During consolidation, a sample is randomly chosen from the ACS with the fewest samples. Another sample, which does not belong to the same cluster but is nearest to the selected sample’s center, is then sampled, labeled, and stored in either AAS or ACS. The number of ACS and AAS matches the number of clusters. ML and CL constraints are inferred from ACS and AAS samples. Experiments on public datasets demonstrate that inferring new clustering constraints reduces annotation costs and improves deep time-series clustering performance. -
Key words:
- Deep time series clustering /
- Active learning /
- Constraint transitivity
-
1 探索阶段采样标注过程
输入:已标注次数$b$,类簇$\left\{ {{\pi _g}} \right\}_{g = 1}^G$,类簇中心$\left\{ {{{\boldsymbol{\mu }}_g}} \right\}_{g = 1}^G$,
ACS集合$\left\{ {{S_g}} \right\}_{g = 1}^G$输出:更新后的ACS集合$\left\{ {{S_g}} \right\}_{g = 1}^G$ (1) for $ i =1 $ to $G$ do: (2) 从${\pi _i}$中选择尚未被选择且表示向量与${{\boldsymbol{\mu }}_i}$距离最小的样本${{\boldsymbol{x}}_p}$ (3) for $ j =1 $ to $G$ do: (4) if ${S_j} = \varnothing $ then$ : $ (5) 将样本${{\boldsymbol{x}}_p}$放入集合${S_j}$ (6) break (7) else: (8) 从${S_j}$中随机选择一个样本${{\boldsymbol{x}}_q}$,标注样本${{\boldsymbol{x}}_p}$与${{\boldsymbol{x}}_q}$的关
系,$ b= b+1 $(9) if 样本${{\boldsymbol{x}}_p}$与${{\boldsymbol{x}}_q}$为ML约束 then: (10) 将样本${{\boldsymbol{x}}_p}$放入集合${S_j}$ (11) break (12) end if (13) end if (14) end for (15) end for  下载: 导出CSV
下载: 导出CSV
2 巩固阶段采样标注过程
输入:已标注次数$b$,类簇$\left\{ {{\pi _g}} \right\}_{g = 1}^G$,类簇中心$\left\{ {{{\boldsymbol{\mu }}_g}} \right\}_{g = 1}^G$,
ACS集合$\left\{ {{S_g}} \right\}_{g = 1}^G$,AAS集合$\left\{ {{S_g}} \right\}_{g = 1}^G$输出:更新后的ACS集合$\left\{ {{S_g}} \right\}_{g = 1}^G$与AAS集合$\left\{ {{{\bar S}_g}} \right\}_{g = 1}^G$ (1) 从样本数量最少的集合${S_g}$中随机选择样本${{\boldsymbol{x}}_p}$,从样本${{\boldsymbol{x}}_p}$所
属类簇${\pi _g}$之外选择表示向量与${{\boldsymbol{\mu }}_g}$距离最小的样本${{\boldsymbol{x}}_q}$(2) 标注样本${{\boldsymbol{x}}_p}$与${{\boldsymbol{x}}_q}$的关系,$b = b + 1$ (3) if 样本${{\boldsymbol{x}}_p}$与${{\boldsymbol{x}}_q}$为ML约束关系 then: (4) 将样本${{\boldsymbol{x}}_q}$放入集合${S_g}$ (5) end if (6) if 样本${{\boldsymbol{x}}_p}$与${{\boldsymbol{x}}_q}$为CL约束关系 then: (7) 将样本${{\boldsymbol{x}}_q}$放入集合${\bar S_g}$ (8) end if
下载: 导出CSV
3 生成ML约束集合$M$和CL约束集合$C$
输入:ACS集合$\left\{ {{S_g}} \right\}_{g = 1}^G$与AAS集合$\left\{ {{{\bar S}_g}} \right\}_{g = 1}^G$ 输出:ML约束集合$M$,CL约束集合$C$ (1) 初始化集合$M$=$\varnothing $, $C$=$\varnothing $ (2) for $g{\text{ = }}1$ to $G$ do (3) for ${{\boldsymbol{x}}_i},{{\boldsymbol{x}}_j} \in {S_g}$ do (4) 将样本对(${{\boldsymbol{x}}_i},{{\boldsymbol{x}}_j}$)添加至集合$M$ (5) end for (6) for ${{\boldsymbol{x}}_i} \in {S_g}$, ${{\boldsymbol{x}}_j} \in {\bar S_g}$ do (7) 将样本对(${{\boldsymbol{x}}_i},{{\boldsymbol{x}}_j}$)添加至集合$C$ (8) end for (9) for $k = g + 1$ to $ G $ do (10) for ${{\boldsymbol{x}}_i} \in {S_g}$, $ {{\boldsymbol{x}}}_{j}\in {S}_{k} $ do (11) 将样本对(${{\boldsymbol{x}}_i},{{\boldsymbol{x}}_j}$)添加至集合$C$ (12) end for (13) end for (14) end for
下载: 导出CSV
4 DATC-CT算法过程
输入:数据集$X$,总预算$B$,当前预算$b$,训练轮次$T$,ACS集
合$\left\{ {{S_g}} \right\}_{g = 1}^G$与AAS集合$\left\{ {{{\bar S}_g}} \right\}_{g = 1}^G$,主动采样阶段标志SFlag输出:类簇中心$\left\{ {{{\boldsymbol{\mu }}_g}} \right\}_{g = 1}^G$ (1) 使用K-means方法对样本${{\boldsymbol{x}}_1},{{\boldsymbol{x}}_2} \cdots ,{{\boldsymbol{x}}_N}$的表示向量
${{\boldsymbol{z}}_1},{{\boldsymbol{z}}_2} \cdots ,{{\boldsymbol{z}}_N}$聚类,得到初始类簇中心${{\boldsymbol{\mu }}_1},{{\boldsymbol{\mu }}_2}, \cdots ,{{\boldsymbol{\mu }}_G}$(2) 初始化${S_1},{S_2}, \cdots ,{S_G} = \varnothing $, ${\bar S_1},{\bar S_2}, \cdots ,{\bar S_G} = \varnothing $,
SFlag=True, $b = 0$(3) for $ t =1\dots T $ do (4) 使用TAE编码器获取样本${{\boldsymbol{x}}_1},{{\boldsymbol{x}}_2}, \cdots ,{{\boldsymbol{x}}_N}$嵌入
${{\boldsymbol{z}}_1},{{\boldsymbol{z}}_2}, \cdots ,{{\boldsymbol{z}}_N}$(5) 使用式(2)计算样本类簇分布形成类簇${\pi _1},{\pi _2}, \cdots ,{\pi _G}$ (6) if $b < B$ then: (7) if SFlag then: (8) 使用算法1更新${S_1},{S_2}, \cdots ,{S_G}$ (9) else: (10) 使用算法2更新${S_1},{S_2}, \cdots ,{S_G}$与${\bar S_1},{\bar S_2}, \cdots ,{\bar S_G}$ (11) end if (12) if ACS集合${S_1},{S_2}, \cdots ,{S_G}$中均至少包含1个样本
then:(13) SFlag=False (14) end if (15) 使用算法3生成约束集合$M$与约束集合$C$ (16) 使用式(6)计算模型损失${L_3}$ (17) 使用${L_3}$更新TAE编码器参数与类簇中心${{\boldsymbol{\mu }}_1},{{\boldsymbol{\mu }}_2}, \cdots ,{{\boldsymbol{\mu }}_G}$ (18) end for
下载: 导出CSV
表 1 实验数据集描述
数据集 样本总数 类别数 序列长度 ChlorineConcentration 4307 3 166 Dist.Phal.Outl.AgeGroup 539 3 80 Dist.Phal.Outl.Correct 876 2 80 ECG200 200 2 96 ECGFiveDays 884 2 136 GunPoint 200 2 150 Ham 214 2 431 Herring 128 2 512 MoteStrain 1272 2 84 OSULeaf 442 6 427 Plane 210 7 144 Prox.phal.outl.AgeGroup 605 3 80 Prox.Phal.TW 605 6 80 SonyAIBORobotSurface1 621 2 70 SonyAIBORobotSurface2 980 2 65 SwedishLeaf 1125 15 128 ToeSegmentation1 268 2 277 TwoLeadECG 166 2 343
下载: 导出CSV
表 2 与相关深度时序聚类方法对比结果
数据集 DEC DTC DTCR DATC-CT ChlorineConcentration 0.4994 0.5353 0.5357 0.5370 Dist.Phal.Outl.AgeGroup 0.7321 0.7812 0.7825 0.7918 Dist.Phal.Outl.Correct 0.4998 0.5010 0.6075 0.5824 ECG200 0.6308 0.6018 0.6648 0.7345 ECGFiveDays 0.5002 0.5016 0.9638 1.0000 GunPoint 0.4975 0.5400 0.6398 0.8219 Ham 0.4987 0.5648 0.5362 0.5841 Herring 0.4971 0.5045 0.5759 0.5153 MoteStrain 0.7621 0.5062 0.7686 0.9228 OSULeaf 0.7283 0.7329 0.7739 0.7742 Plane 0.9283 0.9040 0.9549 0.9921 Prox.phal.outl.AgeGroup 0.3893 0.7430 0.8091 0.8140 Prox.Phal.TW 0.5151 0.8380 0.9023 0.8568 SonyAIBORobotSurface1 0.8988 0.5563 0.8769 0.9967 SonyAIBORobotSurface2 0.6509 0.7012 0.8354 0.8562 SwedishLeaf 0.8837 0.8871 0.9223 0.9241 ToeSegmentation1 0.4995 0.5077 0.5659 0.5158 TwoLeadECG 0.5001 0.5116 0.7114 1.0000 最优个数 0 0 4 14 平均RI 0.6173 0.6343 0.7459 0.7900
下载: 导出CSV
表 3 与已有主动选择策略对比结果
数据集 Rand ADC DATC-CT ChlorineConcentration 0.5294 0.5342 0.5370 Dist.Phal.Outl.AgeGroup 0.7313 0.7218 0.7918 Dist.Phal.Outl.Correct 0.5019 0.5059 0.5824 ECG200 0.6882 0.6699 0.7345 ECGFiveDays 0.6747 0.8311 1.0000 GunPoint 0.5754 0.5348 0.8219 Ham 0.5302 0.5173 0.5841 Herring 0.5062 0.5022 0.5153 MoteStrain 0.8300 0.8915 0.9228 OSULeaf 0.7443 0.7257 0.7742 Plane 0.9506 0.9819 0.9921 Prox.phal.outl.AgeGroup 0.7656 0.8047 0.8140 Prox.Phal.TW 0.8315 0.8566 0.8568 SonyAIBORobotSurface1 0.9526 0.9744 0.9967 SonyAIBORobotSurface2 0.8033 0.7588 0.8562 SwedishLeaf 0.9051 0.9128 0.9241 ToeSegmentation1 0.4982 0.5029 0.5158 TwoLeadECG 0.5011 0.9982 1.0000 最优个数 0 0 18 平均RI 0.6955 0.7347 0.7900
下载: 导出CSV
-
[1] AIGNER W, MIKSCH S, SCHUMANN H, et al. Visualization of Time-Oriented Data[M]. London: Springer, 2011: 153–196. [2] LEE S, CHOI C, and SON Y. Deep time-series clustering via latent representation alignment[J]. Knowledge-Based Systems, 2024, 303: 112434. doi: 10.1016/j.knosys.2024.112434. [3] CAI Jinyu, FAN Jicong, GUO Wenzhong, et al. Efficient deep embedded subspace clustering[C]. The 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, USA, 2022: 21–30. doi: 10.1109/cvpr52688.2022.00012. [4] ZHONG Ying, HUANG Dong, and WANG Changdong. Deep temporal contrastive clustering[J]. Neural Processing Letters, 2023, 55(6): 7869–7885. doi: 10.1007/s11063-023-11287-0. [5] ROS F, RIAD R, and GUILLAUME S. Deep clustering framework review using multicriteria evaluation[J]. Knowledge-Based Systems, 2024, 285: 111315. doi: 10.1016/j.knosys.2023.111315. [6] XIE Junyuan, GIRSHICK R, and FARHADI A. Unsupervised deep embedding for clustering analysis[C]. The 33rd International Conference on International Conference on Machine Learning, New York, USA, 2016: 478–487. [7] MADIRAJU N S. Deep temporal clustering: Fully unsupervised learning of time-domain features[D]. [Ph. D. dissertation], Arizona State University, 2018. [8] MA Qianli, ZHENG Jiawei, LI Sen, et al. Learning representations for time series clustering[C]. The 33rd International Conference on Neural Information Processing Systems, Red Hook, USA, 2019: 3781–3791. [9] PENG Furong, LUO Jiachen, LU Xuan, et al. Cross-domain contrastive learning for time series clustering[C]. The AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2024: 8921–8929. doi: 10.1609/aaai.v38i8.28740. [10] LI Xiaosheng, XI Wenjie, and LIN J. Randomnet: Clustering time series using untrained deep neural networks[J]. Data Mining and Knowledge Discovery, 2024, 38(6): 3473–3502. doi: 10.1007/s10618-024-01048-5. [11] SUN Bicheng, ZHOU Peng, DU Liang, et al. Active deep image clustering[J]. Knowledge-Based Systems, 2022, 252: 109346. doi: 10.1016/j.knosys.2022.109346. [12] REN Yazhou, HU Kangrong, DAI Xinyi, et al. Semi-supervised deep embedded clustering[J]. Neurocomputing, 2019, 325: 121–130. doi: 10.1016/j.neucom.2018.10.016. [13] REN Pengzhen, XIAO Yun, CHANG Xiaojun, et al. A survey of deep active learning[J]. ACM Computing Surveys (CSUR), 2022, 54(9): 180. doi: 10.1145/3472291. [14] DENG Xun, LIU Junlong, ZHONG Han, et al. A3S: A general active clustering method with pairwise constraints[C]. The 41st International Conference on Machine Learning, Vienna, Austria, 2024: 10488–10505. [15] 李海林, 张丽萍. 时间序列数据挖掘中的聚类研究综述[J]. 电子科技大学学报, 2022, 51(3): 416–424. doi: 10.12178/1001-0548.2022055.LI Hailin and ZHANG Liping. Summary of clustering research in time series data mining[J]. Journal of University of Electronic Science and Technology of China, 2022, 51(3): 416–424. doi: 10.12178/1001-0548.2022055. [16] PETITJEAN F, KETTERLIN A, and GANÇARSKI P. A global averaging method for dynamic time warping, with applications to clustering[J]. Pattern Recognition, 2011, 44(3): 678–693. doi: 10.1016/j.patcog.2010.09.013. [17] PAPARRIZOS J and GRAVANO L. Fast and accurate time-series clustering[J]. ACM Transactions on Database Systems (TODS), 2017, 42(2): 8. doi: 10.1145/3044711. [18] ZAKARIA J, MUEEN A, and KEOGH E. Clustering time series using unsupervised-shapelets[C]. 2012 IEEE 12th International Conference on Data Mining, Brussels, Belgium, 2012: 785–794. doi: 10.1109/icdm.2012.26. [19] 余思琴, 闫秋艳, 闫欣鸣. 基于最佳u-shapelets的时间序列聚类算法[J]. 计算机应用, 2017, 37(8): 2349–2356. doi: 10.11772/j.issn.1001-9081.2017.08.2349.YU Siqin, YAN Qiuyan, and YAN Xinming. Clustering algorithm of time series with optimal u-shapelets[J]. Journal of Computer Applications, 2017, 37(8): 2349–2356. doi: 10.11772/j.issn.1001-9081.2017.08.2349. [20] MACQUEEN J B. Some methods for classification and analysis of multivariate observations[C]. The 5th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, USA, 1967: 281–297. [21] JOHNSON S C. Hierarchical clustering schemes[J]. Psychometrika, 1967, 32(3): 241–254. doi: 10.1007/bf02289588. [22] NG A Y, JORDAN M I, and WEISS Y. On spectral clustering: Analysis and an algorithm[C]. The 15th International Conference on Neural Information Processing Systems: Natural and Synthetic, Cambridge, USA, 2001: 849–856. [23] CHANG Shiyu, ZHANG Yang, HAN Wei, et al. Dilated recurrent neural networks[C]. The 31st International Conference on Neural Information Processing Systems, Red Hook, USA, 2017: 76–86. [24] BASU S, BANERJEE A, and MOONEY R J. Active semi-supervision for pairwise constrained clustering[C]. The 2004 SIAM International Conference on Data Mining, Lake Buena Vista, USA, 2004: 333–344. doi: 10.1137/1.9781611972740.31. [25] DAU H A, BAGNALL A, KAMGAR K, et al. The UCR time series archive[J]. IEEE/CAA Journal of Automatica Sinica, 2019, 6(6): 1293–1305. doi: 10.1109/jas.2019.1911747. -


 下载:
下载:



图(4) / 表(7)
计量
- 文章访问数: 584
- HTML全文浏览量: 564
- PDF下载量: 57
- 被引次数: 0
