

Adaptively Sparse Federated Learning Optimization Algorithm Based on Edge-assisted Server
-
摘要: 联邦学习中,高模型贡献率的无线网络设备通常由于算力不足、能量有限成为掉队者,进而增加模型聚合时延并影响全局模型精度。针对此问题,该文设计了联合边缘服务器辅助训练和模型自适应稀疏联邦学习架构,并提出了基于边缘辅助训练的自适应稀疏联邦学习优化算法。首先,引入边缘服务器为算力不足或能量受限的设备提供辅助训练。构建了辅助训练和通信、计算资源分配的优化模型,并采用多种深度强化学习方法求解优化的辅助训练决策。其次,基于辅助训练决策,在每个通信轮次自适应地对全局模型进行非结构化剪枝,进一步降低设备的时延和能耗开销。实验结果表明,所提算法极大地减少了掉队设备,其模型测试精度优于经典联邦学习的测试精度;利用深度确定性策略梯度(DDPG)优化辅助资源分配的算法有效地减少了系统训练时延,提升了模型训练效率。Abstract:
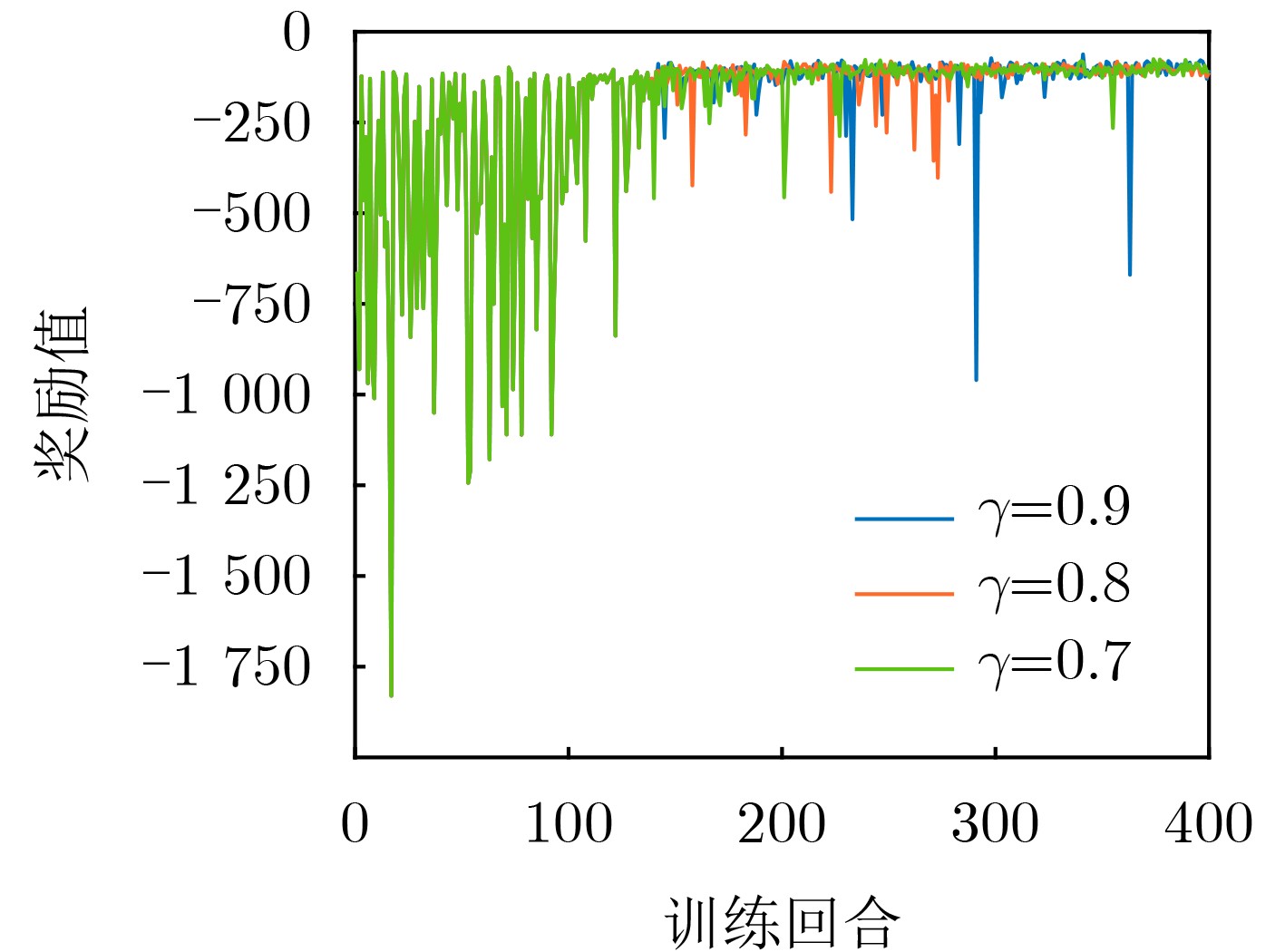
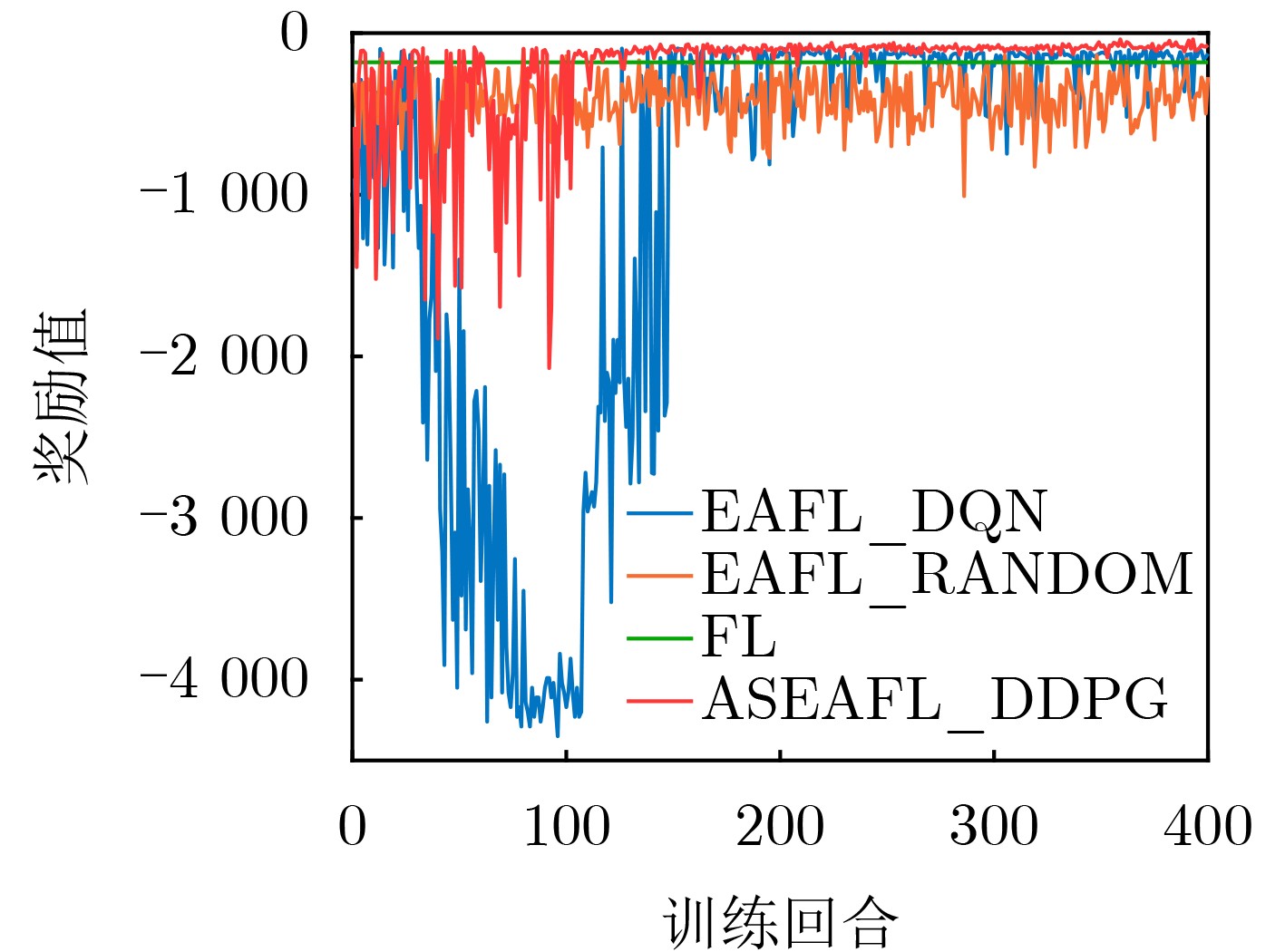
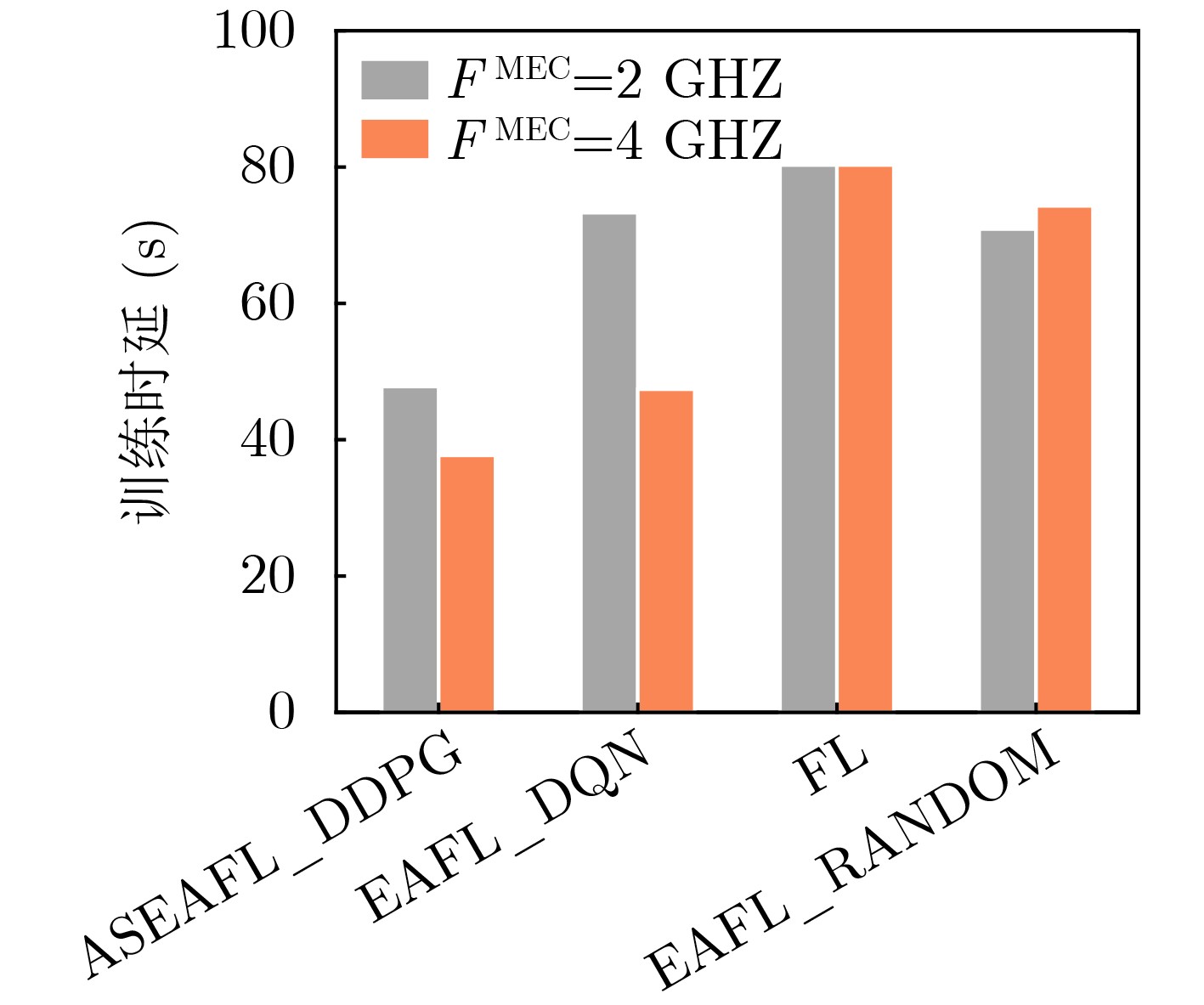
Objective Federated Learning (FL) represents a distributed learning framework with significant potential, allowing users to collaboratively train a shared model while retaining data on their devices. However, the substantial differences in computing, storage, and communication capacities across FL devices within complex networks result in notable disparities in model training and transmission latency. As communication rounds increase, a growing number of heterogeneous devices become stragglers due to constraints such as limited energy and computing power, changes in user intentions, and dynamic channel fluctuations, adversely affecting system convergence performance. This study addresses these challenges by jointly incorporating assistance mechanisms and reducing device overhead to mitigate the impact of stragglers on model accuracy and training latency. Methods This paper designs an FL architecture integrating joint edge-assisted training and adaptive sparsity and proposes an adaptively sparse FL optimization algorithm based on edge-assisted training. First, an edge server is introduced to provide auxiliary training for devices with limited computing power or energy. This reduces the training delay of the FL system, enables stragglers to continue participating in the training process, and helps maintain model accuracy. Specifically, an optimization model for auxiliary training, communication, and computing resource allocation is constructed. Several deep reinforcement learning methods are then applied to obtain the optimized auxiliary training decision. Second, based on the auxiliary training decision, unstructured pruning is adaptively performed on the global model during each communication round to further reduce device delay and energy consumption. Results and Discussions The proposed framework and algorithm are evaluated through extensive simulations. The results demonstrate the effectiveness and efficiency of the proposed method in terms of model accuracy and training delay.The proposed algorithm achieves an accuracy rate approximately 5% higher than that of the FL algorithm on both the MNIST and CIFAR-10 datasets. This improvement results from low-computing-power and low-energy devices failing to transmit their local models to the central server during multiple communication rounds, reducing the global model’s accuracy ( Table 3 ).The proposed algorithm achieves an accuracy rate 18% higher than that of the FL algorithm on the MNIST-10 dataset when the data on each device follow a non-IID distribution. Statistical heterogeneity exacerbates model degradation caused by stragglers, whereas the proposed algorithm significantly improves model accuracy under such conditions (Table 4 ).The reward curves of different algorithms are presented (Fig. 7 ). The reward of FL remains constant, while the reward of EAFL_RANDOM fluctuates randomly. ASEAFL_DDPG shows a more stable reward curve once training episodes exceed 120 due to the strong learning and decision-making capabilities of DDPG and DQN. In contrast, EAFL_DQN converges more slowly and maintains a lower reward than the proposed algorithm, mainly due to more precise decision-making in the continuous action space and an exploration mechanism that expands action selection (Fig. 7 ).When the computing power of the edge server increases, the training delay of the FL algorithm remains constant since it does not involve auxiliary training. The training delay of EAFL_RANDOM fluctuates randomly, while the delays of ASEAFL_DDPG and EAFL_DQN decrease. However, ASEAFL_DDPG consistently achieves a lower system training delay than EAFL_DQN under the same MEC computing power conditions (Fig. 9 ).When the communication bandwidth between the edge server and devices increases, the training delay of the FL algorithm remains unchanged as it does not involve auxiliary training. The training delay of EAFL_RANDOM fluctuates randomly, while the delays of ASEAFL_DDPG and EAFL_DQN decrease. ASEAFL_DDPG consistently achieves lower system training delay than EAFL_DQN under the same bandwidth conditions (Fig. 10 ).Conclusions The proposed sparse-adaptive FL architecture based on an edge-assisted server mitigates the straggler problem caused by system heterogeneity from two perspectives. By reducing the number of stragglers, the proposed algorithm achieves higher model accuracy compared with the traditional FL algorithm, effectively decreases system training delay, and improves model training efficiency. This framework holds practical value, particularly for FL deployments where aggregation devices are selected based on statistical characteristics, such as model contribution rates. Straggler issues are common in such FL scenarios, and the proposed architecture effectively reduces their occurrence. Simultaneously, devices with high model contribution rates can continue participating in multiple rounds of federated training, lowering the central server’s frequent device selection overhead. Additionally, in resource-constrained FL environments, edge servers can perform more diverse and flexible tasks, such as partial auxiliary training and partitioned model training. -
表 1 主要符号描述表
符号 含义 符号 含义 Z, N 边缘服务器个数,每个边缘服务器范围内被选中参与
聚合的设备数$ {p}_{z,n} $ 边缘服务器z范围下设备n的传输功率 M 联邦学习的总通信轮次 $ k $ 由芯片结构决定的有效开关电容 $ {D}_{n} $ 每个轮次的本地训练样本数据量 $ {t}_{m,z,n}^{\mathrm{u}\mathrm{p}\_\mathrm{z}} $ 第m个通信轮次内设备n上传样本数据到边缘服务器z的时延 $ {D}_{\omega } $ 联邦学习模型参数数据量 $ {t}_{z,n}^{\mathrm{I}\mathrm{O}\mathrm{T}} $ 边缘服务器z范围下设备n的本地训练时延 r 处理单位比特数据所需的CPU周期数 $ {t}_{m,z,n}^{\mathrm{M}\mathrm{E}\mathrm{C}} $ 第m个通信轮次内边缘服务器z训练设备n上传的样本数据的时延 $ {s}_{m} $ 第m个通信轮次的模型稀疏率 $ {t}_{m,z,n}^{\mathrm{u}\mathrm{p}\_\mathrm{c}} $ 第m个通信轮次内边缘服务器z范围下设备n上传模型到聚合服务器的时延 $ {\alpha }_{m,z,n} $ 第m个通信轮次内边缘服务器z范围下设备n是否
接受辅助训练$ {e}_{m,z,n}^{\mathrm{u}\mathrm{p}\_\mathrm{z}} $ 第m个通信轮次内设备n上传样本数据到边缘服务器z的能耗 $ {r}_{m,z,n}^{\mathrm{u}\mathrm{p}\_\mathrm{z}} $ 第m个通信轮次内设备n到边缘服务器z的数据传输速率 $ {e}_{z,n}^{\mathrm{I}\mathrm{O}\mathrm{T}} $ 边缘服务器z范围下设备n的本地训练能耗 $ {r}_{m,z,n}^{\mathrm{u}\mathrm{p}\_\mathrm{c}} $ 第m个通信轮次内边缘服务器z范围下设备n到聚合服务器
的数据传输速率$ {e}_{m,z,n}^{\mathrm{u}\mathrm{p}\_\mathrm{c}} $ 第m个通信轮次内边缘服务器z范围下设备n上传模型到聚合服务器的能耗 $ {B}_{m,z,n} $ 第m个通信轮次内边缘服务器z范围下设备n分配到的
单位带宽数目$ {E}_{z,n}^{\mathrm{s}\mathrm{t}\mathrm{a}\mathrm{r}\mathrm{t}} $ 边缘服务器z范围下设备n的初始能量 $ {B}_{z} $ 辅助训练系统带宽 $ {E}_{m,z,n} $ 边缘服务器z范围下设备n在第m个通信轮次的总能耗 $ {b}_{z} $ 辅助训练系统的单位带宽数目 $ {F}_{m,z,n} $ 第m个通信轮次内边缘服务器z用于设备n上样本训练的计算频率 $ {h}_{z,n} $ 设备n与边缘服务器z之间的传输信道增益 $ {f}_{z,n}^{\mathrm{I}\mathrm{O}\mathrm{T}} $ 边缘服务器z范围下设备n的计算频率 $ {\delta }^{2} $ 噪声功率 $ {F}_{z}^{\mathrm{M}\mathrm{E}\mathrm{C}} $ 边缘服务器z的计算频率  下载: 导出CSV
下载: 导出CSV
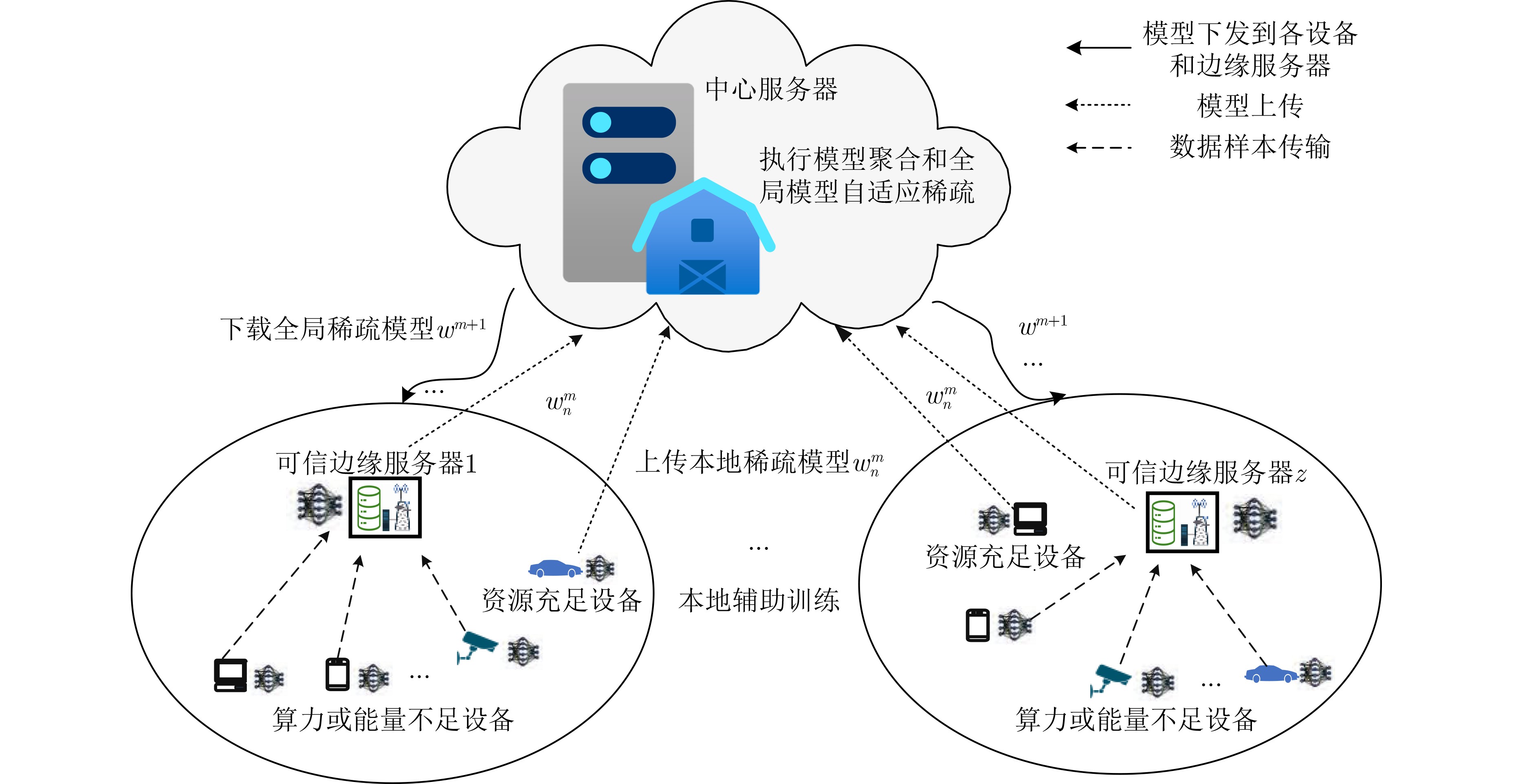
1 基于边缘辅助训练的自适应稀疏联邦学习
输入:初始稀疏比例$ {s}_{0} $,最终的稀疏比例$ {s}_{M} $,稀疏频率$ U $,稀
疏速率控制指数c,开始稀疏的轮次$ {m}_{0} $,初始掩码矩阵$ {\mathit{X}}^{{m}_{0}} $,
边缘服务器z下参与聚合的设备集合$ {\varPsi }_{z} $,当前设备选择下总的通
信轮次M,初始模型$ \omega $,各设备的初始能量$ {E}_{{z},n}^{\mathrm{s}\mathrm{t}\mathrm{a}\mathrm{r}\mathrm{t}} $、计算频率
$ {f}_{z,n}^{\mathrm{I}\mathrm{O}\mathrm{T}} $,传输功率$ {p}_{{z},n} $,边缘服务器的计算频率$ {F}_{{z}}^{\mathrm{M}\mathrm{E}\mathrm{C}} $、边缘服务
器和设备间的通信带宽$ {B}_{{z}} $,每轮训练数据量$ {D}_{n} $,由芯片结构
决定的有效开关电容$ k $输出:联邦学习模型$ {\omega }^{M} $ (1) 在边缘服务器z上部署深度强化学习智能体,智能体收集联邦
学习在当前设备选择下的总通信轮次M、其覆盖范围内所有参与
模型聚合的设备的状态信息并初始化策略网络和价值网络,智能
体的奖励函数为式(14),通过不断地与环境交互,智能体将学习
到最佳的辅助训练决策(2) 智能体下发M个通信轮次的辅助训练决策,包括辅助训练标
记$ {\alpha }_{m,z,n} $、传输带宽$ {B}_{m,{z},n} $和CPU频率$ {F}_{m,{z},n} $(3) For m=1 to M do For n=1 to N do (并行) IF $ {\alpha }_{m,z,n}==1 $ 设备n依据传输带宽$ {B}_{m,{z},n} $上传样本数据到边缘服务 器,边缘服务器依据分配到的算力$ {F}_{m,{z},n} $完成辅助训
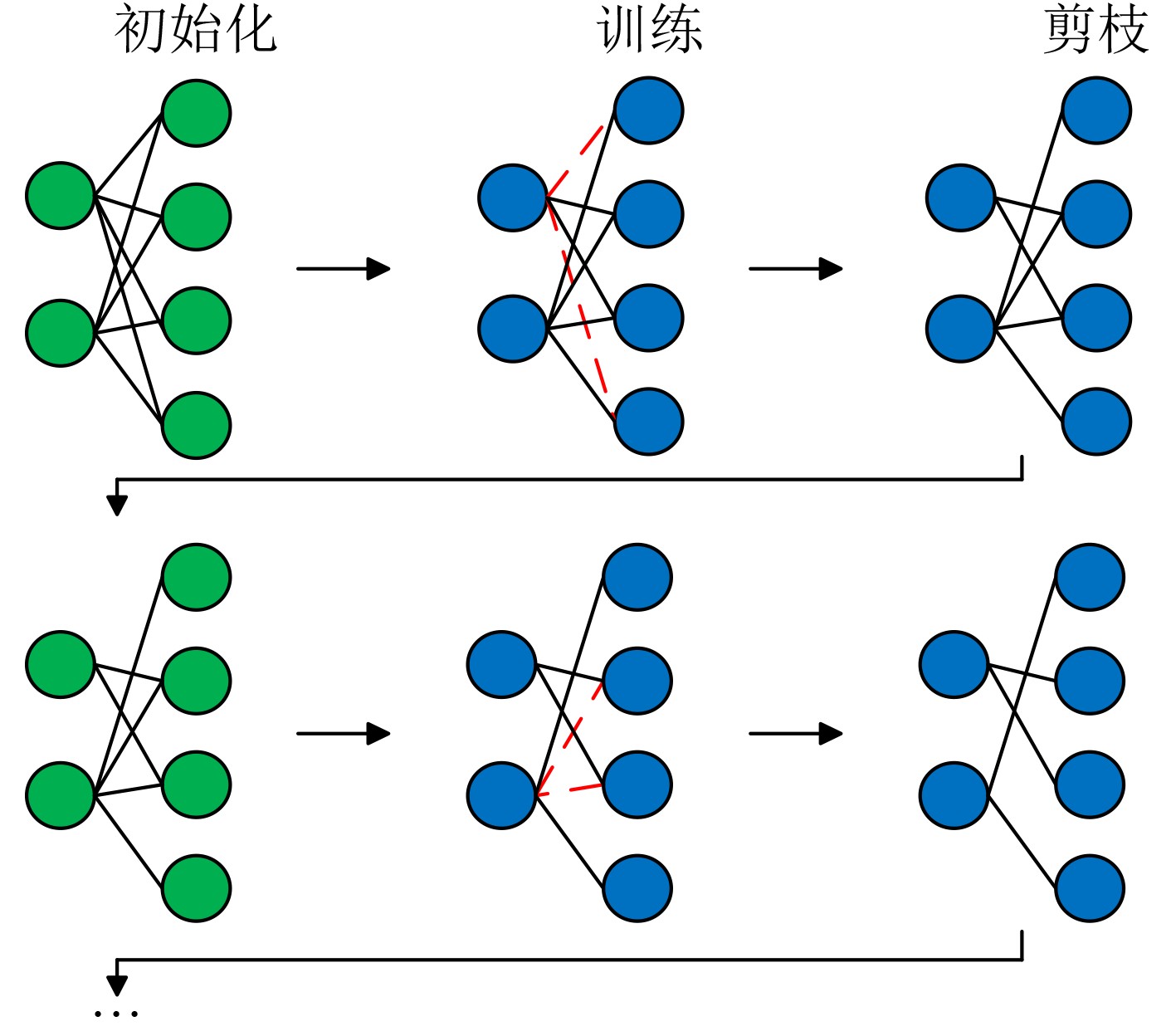
练,模型训练更新依据式(21)边缘服务器上传辅助训练模型$ {\omega }_{n} $到聚合服务器 ELSE 设备n完成本地训练,模型更新依据式(21) 设备n上传本地训练模型$ {\omega }_{n} $到聚合服务器 End For (4) 执行全局模型聚合$ {\omega }^{m+1}=\displaystyle\sum\nolimits _{n=1}^{N}\dfrac{{D}_{n}}{D}{\omega }_{n}^{m} $ (5) 依据式(20)计算全局模型稀疏度$ {s}_{m} $,然后根据稀疏度$ {s}_{m} $计
算全局模型的掩码矩阵$ {\mathit{X}}^{m} $(6) 全局模型和掩码矩阵进行哈达玛积运算${\omega }^{m + } = {\omega }^{m + 1} $$ \odot{\mathit{X}}^{m} $,
获得非结构化剪枝模型$ {\omega }^{m+1} $作为新的全局模型(7) 将全局稀疏模型$ {\omega }^{m+1} $和掩码矩阵$ {\mathit{X}}^{m} $下发给参与训练的设
备和边缘服务器End For
下载: 导出CSV
表 2 各参数取值表
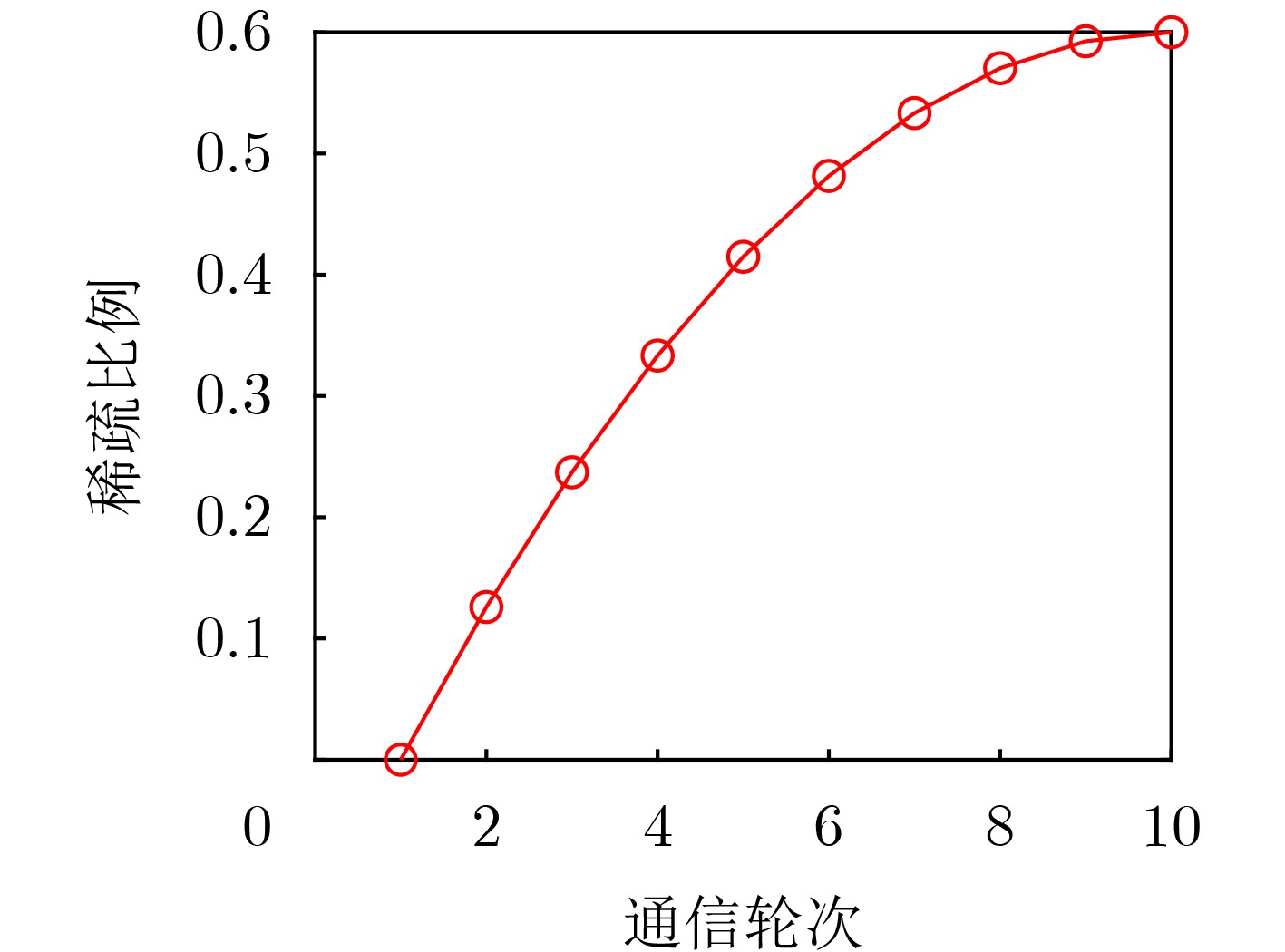
参数 取值 边缘服务器z下参与聚合的设备数N 5 系统单位带宽数目$ {b}_{z} $ 8 处理单位比特数据所需CPU圈数r 1 000 距离1 m时的参考信道增益h –30 dB 上行链路传输功率$ {p}_{z,n} $ 0.1 W 噪声功率$ {\delta }^{2} $ –100 dBm 由芯片结构决定的有效开关电容$ k $ $ {10}^{-25} $ 边缘服务器z计算频率$ {F}_{z}^{\mathrm{M}\mathrm{E}\mathrm{C}} $ 4 GHz 模型初始稀疏系数$ {S}_{0} $ 0 模型最终稀疏系数$ {S}_{M} $ 0.6 稀疏频率$ U $ 1 初始稀疏轮次$ {m}_{0} $ 1 当前设备选择下总的通信轮次M 10 稀疏速率控制指数$ c $ 2 MNIST数据集上的学习率Lr_mnist 0.001 CIFAR10数据集上的学习率Lr_cifar 0.01 MNIST数据集的批量大小Bs_mnist 32 CIFAR10数据集的批量大小Bs_cifar 64 本地更新批数Local_eps 4
下载: 导出CSV
表 3 不同算法模型测试精度对比(%)
算法 数据集 通信轮次 1 2 3 4 5 6 7 8 9 10 FL MNIST 62.65 73.41 75.24 76.18 77.00 77.45 78.52 79.18 79.78 80.38 CIFAR10 15.03 47.06 55.79 58.75 59.65 61.1 61.21 62.05 61.83 62.39 ASEAFL_DDPG MNIST 62.65 73.13 77.51 80.04 82.2 82.73 84.17 84.71 85.27 85.65 CIFAR10 15.03 41.01 55.90 60.75 63.23 64.60 65.80 66.33 67.10 67.26
下载: 导出CSV
表 4 Non-IID设置下MNIST数据集上的模型测试精度(%)
算法 通信轮次 1 2 3 4 5 6 7 8 9 10 FL 16.25 15.97 19.53 21.76 26.33 32.98 37.62 40.18 42.69 45.84 ASEAFL_DDPG 16.25 25.72 35.02 42.51 48.81 54.31 57.32 60.17 62.75 63.97
下载: 导出CSV
-
[1] CHENG Nan, WU Shen, WANG Xiucheng, et al. AI for UAV-assisted IoT applications: A comprehensive review[J]. IEEE Internet of Things Journal, 2023, 10(16): 14438–14461. doi: 10.1109/JIOT.2023.3268316. [2] ALSELEK M, ALCARAZ-CALERO J M, and WANG Qi. Dynamic AI-IoT: Enabling updatable AI models in ultralow-power 5G IoT devices[J]. IEEE Internet of Things Journal, 2024, 11(8): 14192–14205. doi: 10.1109/JIOT.2023.3340858. [3] KALAKOTI R, BAHSI H, and NÕMM S. Improving IoT security with explainable AI: Quantitative evaluation of explainability for IoT botnet detection[J]. IEEE Internet of Things Journal, 2024, 11(10): 18237–18254. doi: 10.1109/JIOT.2024.3360626. [4] KUMAR R, JAVEED D, ALJUHANI A, et al. Blockchain-based authentication and explainable AI for securing consumer IoT applications[J]. IEEE Transactions on Consumer Electronics, 2024, 70(1): 1145–1154. doi: 10.1109/TCE.2023.3320157. [5] MCMAHAN B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data[C]. The 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, USA, 2017: 1273–1282. [6] LI Xingyu, QU Zhe, TANG Bo, et al. Stragglers are not disasters: A hybrid federated learning framework with delayed gradients[C]. The 21st IEEE International Conference on Machine Learning and Applications (ICMLA), Nassau, Bahamas, 2022: 727–732. doi: 10.1109/ICMLA55696.2022.00121. [7] LIANG Kai and WU Youlong. Two-layer coded gradient aggregation with straggling communication links[C]. 2020 IEEE Information Theory Workshop (ITW), Riva del Garda, Italy, 2021: 1–5. doi: 10.1109/ITW46852.2021.9457626. [8] LANG N, COHEN A, and SHLEZINGER N. Stragglers-aware low-latency synchronous federated learning via layer-wise model updates[J]. arXiv: 2403.18375, 2024. doi: 10.48550/arXiv.2403.18375. [9] MHAISEN N, ABDELLATIF A A, MOHAMED A, et al. Optimal user-edge assignment in hierarchical federated learning based on statistical properties and network topology constraints[J]. IEEE Transactions on Network Science and Engineering, 2022, 9(1): 55–66. doi: 10.1109/TNSE.2021.3053588. [10] FENG Chenyuan, YANG H H, HU Deshun, et al. Mobility-aware cluster federated learning in hierarchical wireless networks[J]. IEEE Transactions on Wireless Communications, 2022, 21(10): 8441–8458. doi: 10.1109/TWC.2022.3166386. [11] LIM W Y B, NG J S, XIONG Zehui, et al. Decentralized edge intelligence: A dynamic resource allocation framework for hierarchical federated learning[J]. IEEE Transactions on Parallel and Distributed Systems, 2022, 33(3): 536–550. doi: 10.1109/TPDS.2021.3096076. [12] KONG J M and SOUSA E. Adaptive ratio-based-threshold gradient sparsification scheme for federated learning[C]. 2023 International Symposium on Networks, Computers and Communications (ISNCC), Doha, Qatar, 2023: 1–5. doi: 10.1109/ISNCC58260.2023.10323644. [13] SU Junshen, WANG Xijun, CHEN Xiang, et al. Joint sparsification and quantization for wireless federated learning under communication constraints[C]. 2023 IEEE 24th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Shanghai, China, 2023: 401–405. doi: 10.1109/SPAWC53906.2023.10304559. [14] PARK S and CHOI W. Regulated subspace projection based local model update compression for communication-efficient federated learning[J]. IEEE Journal on Selected Areas in Communications, 2023, 41(4): 964–976. doi: 10.1109/JSAC.2023.3242722. [15] DHAKAL S, PRAKASH S, YONA Y, et al. Coded federated learning[C]. 2019 IEEE Globecom Workshops (GC Wkshps), Waikoloa, USA, 2019: 1–6. doi: 10.1109/GCWkshps45667.2019.9024521. [16] PRAKASH S, DHAKAL S, AKDENIZ M R, et al. Coded computing for low-latency federated learning over wireless edge networks[J]. IEEE Journal on Selected Areas in Communications, 2021, 39(1): 233–250. doi: 10.1109/JSAC.2020.3036961. [17] SUN Yuchang, SHAO Jiawei, MAO Yuyi, et al. Stochastic coded federated learning: Theoretical analysis and incentive mechanism design[J]. IEEE Transactions on Wireless Communications, 2024, 23(6): 6623–6638. doi: 10.1109/TWC.2023.3334732. [18] BANERJEE S, VU X S, and BHUYAN M. Optimized and adaptive federated learning for straggler-resilient device selection[C]. 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 2022: 1–9. doi: 10.1109/IJCNN55064.2022.9892777. [19] HUANG Peishan, LI Dong, and YAN Zhigang. Wireless federated learning with asynchronous and quantized updates[J]. IEEE Communications Letters, 2023, 27(9): 2393–2397. doi: 10.1109/LCOMM.2023.3294606. [20] YAN Xinru, MIAO Yinbin, LI Xinghua, et al. Privacy-preserving asynchronous federated learning framework in distributed IoT[J]. IEEE Internet of Things Journal, 2023, 10(15): 13281–13291. doi: 10.1109/JIOT.2023.3262546. [21] YANG Zhigang, ZHANG Xuhua, WU Dapeng, et al. Efficient asynchronous federated learning research in the internet of vehicles[J]. IEEE Internet of Things Journal, 2023, 10(9): 7737–7748. doi: 10.1109/JIOT.2022.3230412. [22] DIAO E, DING Jie, and TAROKH V. HeteroFL: Computation and communication efficient federated learning for heterogeneous clients[C]. 9th International Conference on Learning Representations, 2021. [23] AL-ABIAD M S, HASSAN M Z, and HOSSAIN M J. Energy-efficient resource allocation for federated learning in NOMA-enabled and relay-assisted internet of things networks[J]. IEEE Internet of Things Journal, 2022, 9(24): 24736–24753. doi: 10.1109/JIOT.2022.3194546. [24] TANG Jianhang, NIE Jiangtian, ZHANG Yang, et al. Multi-UAV-assisted federated learning for energy-aware distributed edge training[J]. IEEE Transactions on Network and Service Management, 2024, 21(1): 280–294. doi: 10.1109/TNSM.2023.3298220. [25] LI Yuchen, LIANG Weifa, LI Jing, et al. Energy-aware, device-to-device assisted federated learning in edge computing[J]. IEEE Transactions on Parallel and Distributed Systems, 2023, 34(7): 2138–2154. doi: 10.1109/TPDS.2023.3277423. [26] 高晗, 田育龙, 许封元, 等. 深度学习模型压缩与加速综述[J]. 软件学报, 2021, 32(1): 68–92. doi: 10.13328/j.cnki.jos.006096.GAO Han, TIAN Yulong, XU Fengyuan, et al. Survey of deep learning model compression and acceleration[J]. Journal of Software, 2021, 32(1): 68–92. doi: 10.13328/j.cnki.jos.006096. [27] STRIPELIS D, GUPTA U, VER STEEG G, et al. Federated progressive sparsification (purge, merge, tune)+[J]. arXiv: 2204.12430, 2022. doi: 10.48550/arXiv.2204.12430. -

 下载:
下载:




图(10) / 表(5)
计量
- 文章访问数: 1289
- HTML全文浏览量: 581
- PDF下载量: 153
- 被引次数: 0
