

Skeleton-based Action Recognition with Selective Multi-scale Graph Convolutional Network
-
摘要: 针对目前骨架行为识别方法忽视骨架关节点多尺度依赖关系和无法合理利用卷积核进行时间建模的问题,该文提出了一种可选择多尺度图卷积网络(SMS-GCN)的行为识别模型。首先,介绍了人体骨架图的构建原理和通道拓扑细化图卷积网络的结构;其次,构建成对关节邻接矩阵和多关节邻接矩阵以生成多尺度通道拓扑细化邻接矩阵,并引入图卷积网络,进一步提出多尺度图卷积(MS-GC)模块,以期实现对骨架关节点的多尺度依赖关系的建模;然后,基于多尺度时序卷积和可选择大核网络,提出可选择多尺度时序卷积(SMS-TC)模块,以期实现对有用的时间上下文特征的充分提取,同时结合MS-GC和SMS-TC模块,进而提出可选择多尺度图卷积网络模型并在多支流数据输入下进行训练;最后,在NTU-RGB+D和NTU-RGB+D 120数据集上进行大量实验,实验结果表明,该模型能够捕获更多的关节特征和学习有用的时间信息,具有优异的准确率和泛化能力。
-
关键词:
- 骨架行为识别 /
- 图卷积网络 /
- 多尺度通道拓扑细化邻接矩阵 /
- 可选择多尺度时序卷积 /
- 可选择多尺度图卷积网络
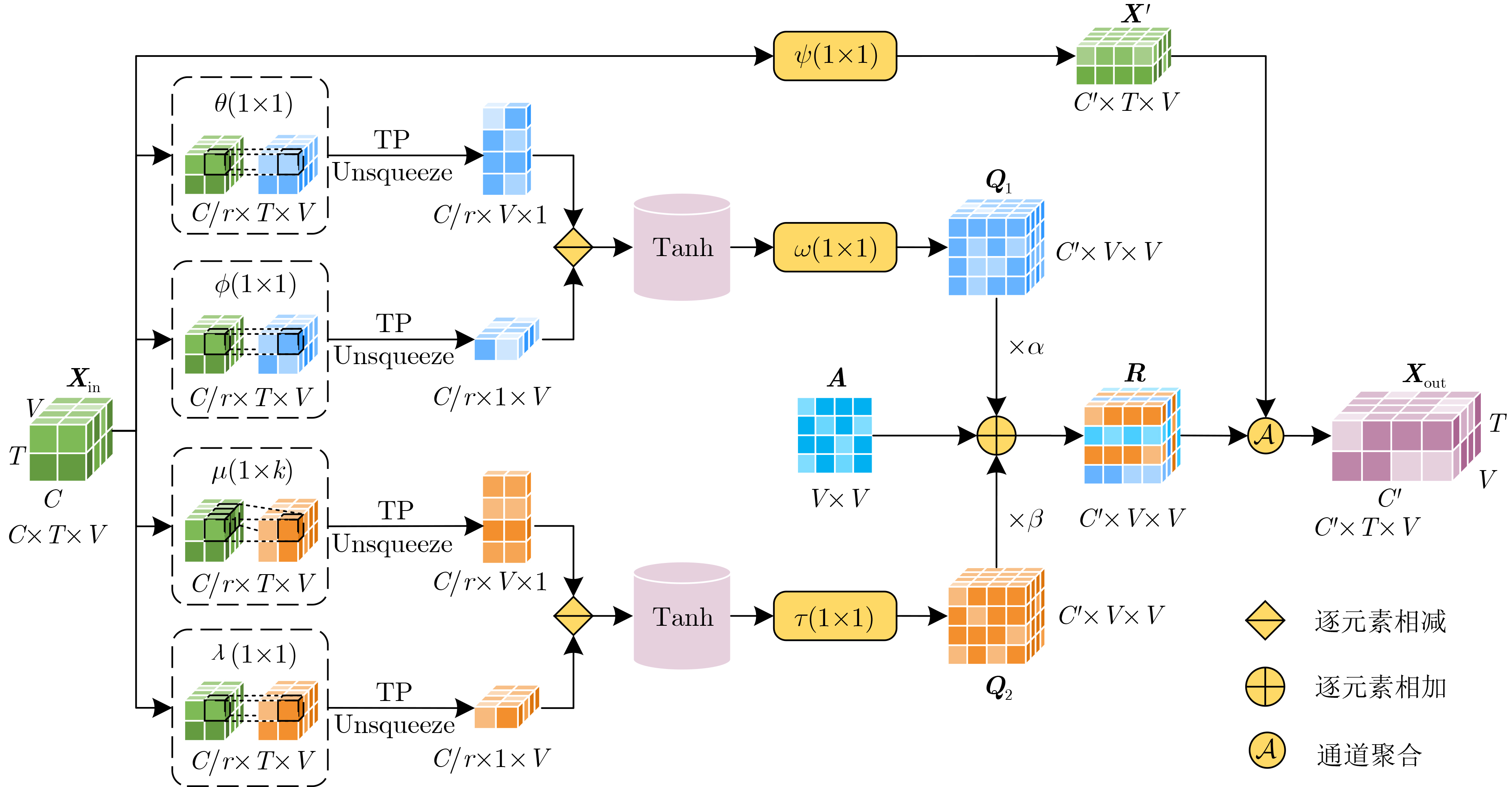
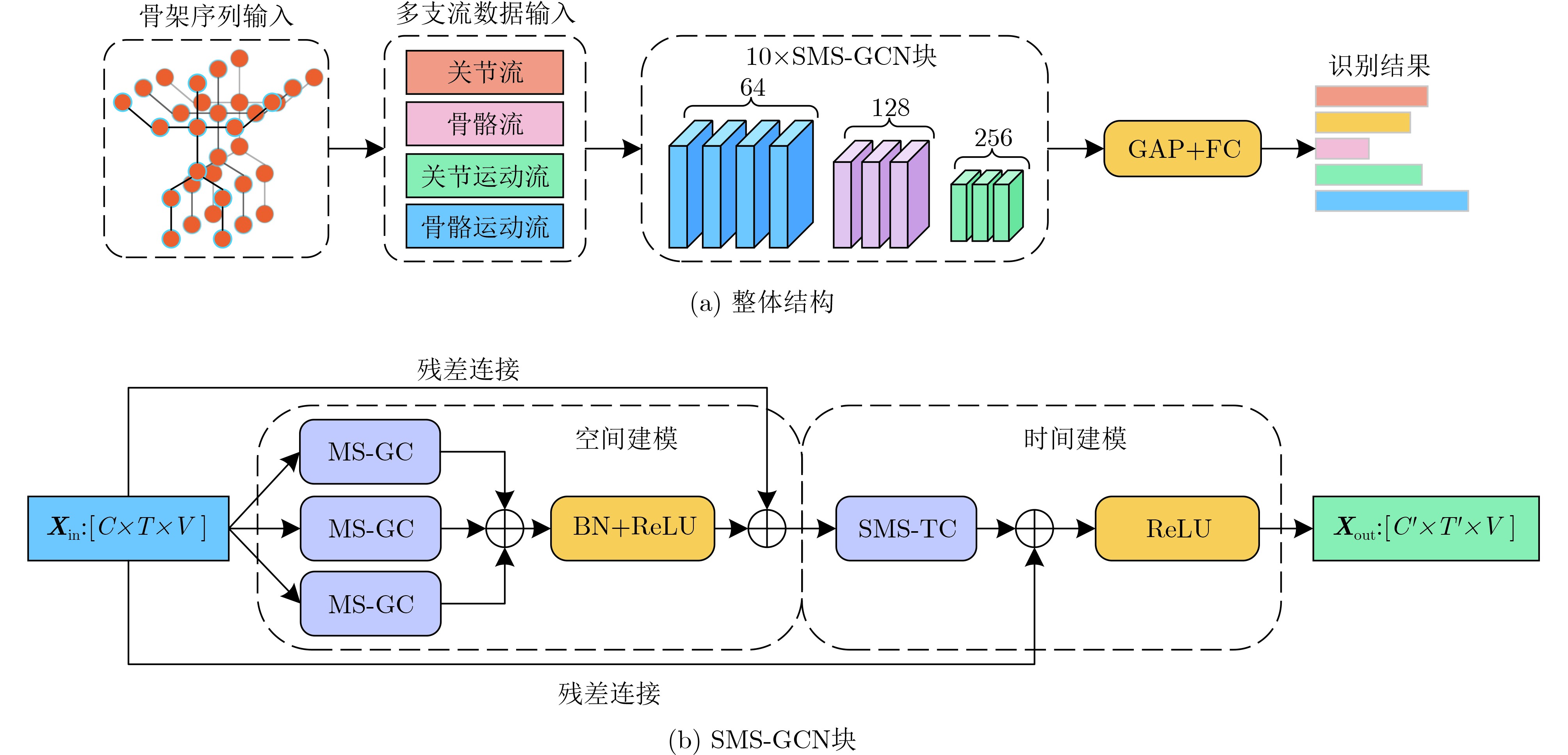
Abstract:Objective Human action recognition plays a key role in computer vision and has gained significant attention due to its broad range of applications. Skeleton data, derived from human action samples, is particularly robust to variations in camera viewpoint, illumination, and background occlusion, offering advantages over depth image and video data. Recent advancements in skeleton-based action recognition using Graph Convolutional Networks (GCNs) have demonstrated effective extraction of the topological relationships within skeleton data. However, limitations remain in some current approaches employing GCNs: (1) Many methods focus on the discriminative dependencies between pairs of joints, failing to effectively capture the multi-scale discriminative dependencies across the entire skeleton. (2) Some temporal modeling methods use dilated convolutions for simple feature fusion, but do not employ convolutional kernels in a manner suitable for effective temporal modeling. To address these challenges, a selective multi-scale GCN is proposed for action recognition, designed to capture more joint features and learn valuable temporal information. Methods The proposed model consists of two key modules: a multi-scale graph convolution module and a selective multi-scale temporal convolution module. First, the multi-scale graph convolution module serves as the primary spatial modeling component. It generates a multi-scale, channel-wise topology refinement adjacency matrix to enhance the model’s ability to learn multi-scale discriminative dependencies of skeleton joints, thereby capturing more joint features. Specifically, the pairwise joint adjacency matrix is used to capture the interactive relationships between joint pairs, enabling the extraction of local motion details. Additionally, the multi-joint adjacency matrix emphasizes the overall action feature changes, improving the model’s spatial representation of the skeleton data. Second, the selective multi-scale temporal convolution module is designed to capture valuable temporal contextual information. This module comprises three stages: feature extraction, temporal selection, and feature fusion. In the feature extraction stage, convolution and max-pooling operations are applied to obtain temporal features at different scales. Once the multi-scale temporal features are extracted, the temporal selection stage uses global max and average pooling to select salient features while preserving key details. This results in the generation of temporal selection masks without directly fusing temporal features across scales, thus reducing redundancy. In the feature fusion stage, the output temporal feature is obtained by weighted fusion of the temporal features and the selection masks. Finally, by combining the multi-scale graph convolution module with the selective multi-scale temporal convolution module, the proposed model extracts multi-stream data from skeleton data, generating various prediction scores. These scores are then fused through weighted summation to produce the final prediction outcome. Results and Discussions Extensive experiments are conducted on two large-scale datasets: NTU-RGB+D and NTU-RGB+D 120, demonstrating the effectiveness and strong generalization performance of the proposed model. When the convolution kernel size in the multi-scale graph convolution module is set to 3, the model performs optimally, capturing more representative joint features ( Table 1 ). The results (Table 4 ) show that the temporal selection stage is critical within the selective multi-scale temporal convolution module, significantly enhancing the model’s ability to extract temporal contextual information. Additionally, ablation studies (Table 5 ) confirm the effectiveness of each component in the proposed model, highlighting their contributions to improving recognition performance. The results (Tables 6 and7 ) demonstrate that the proposed model outperforms state-of-the-art methods, achieving superior recognition accuracy and strong generalization capabilities.Conclusions This study presents a selective multi-scale GCN model for skeleton-based action recognition. The multi-scale graph convolution module effectively captures the multi-scale discriminative dependencies of skeleton joints, enabling the model to fully extract more joint features. By selecting appropriate temporal convolution kernels, the selective multi-scale temporal convolution module extracts and fuses temporal contextual information, thereby emphasizing useful temporal features. Experimental results on the NTU-RGB+D and NTU-RGB+D 120 datasets demonstrate that the proposed model achieves excellent accuracy and robust generalization performance. -
表 1 不同卷积核尺寸的模型准确率对比(%)
模型 Top-1 Top-5 SMS-GCN(k=3) 95.09 99.41 SMS-GCN(k=5) 95.00 99.43 SMS-GCN(k=7) 94.99 99.40 SMS-GCN(k=9) 94.93 99.36  下载: 导出CSV
下载: 导出CSV
表 2 不同卷积核尺寸的准确率对比
模型 (k1, k2) (d1, d2) Top-1(%) 参数量(M) 时间(s) 模型 (k1, k2) (d1, d2) Top-1(%) 参数量(M) 时间(s) 1 (1, 3) (1, 1) 94.58 1.77 277 9 (3, 11) (1, 1) 94.87 1.93 277 2 (1, 5) (1, 1) 94.79 1.80 275 10 (5, 7) (1, 1) 94.69 1.90 278 3 (1, 7) (1, 1) 94.92 1.83 277 11 (5, 9) (1, 1) 94.82 1.93 277 4 (1, 9) (1, 1) 94.78 1.87 282 12 (5, 11) (1, 1) 94.89 1.97 277 5 (1, 11) (1, 1) 95.04 1.90 276 13 (7, 9) (1, 1) 94.84 1.97 270 6 (3, 5) (1, 1) 94.92 1.83 287 14 (7, 11) (1, 1) 94.83 2.00 285 7 (3, 7) (1, 1) 94.74 1.87 281 15 (9, 11) (1, 1) 95.03 2.03 272 8 (3, 9) (1, 1) 94.91 1.90 271
下载: 导出CSV
表 3 不同卷积核尺寸和膨胀系数的准确率对比
模型 (k1, k2) (d1, d2) Top-1(%) 参数量(M) 时间(s) 模型 (k1, k2) (d1, d2) Top-1(%) 参数量(M) 时间(s) 1 (1, 1) (1, 2) 92.95 1.74 747 7 (9, 9) (1, 3) 95.07 2.00 761 2 (3, 3) (1, 2) 94.69 1.80 886 8 (9, 9) (1, 4) 95.09 2.00 1000 3 (5, 5) (1, 2) 94.89 1.87 865 9 (9, 9) (2, 3) 94.98 2.00 1466 4 (7, 7) (1, 2) 94.66 1.93 854 10 (9, 9) (2, 4) 94.96 2.00 1490 5 (9, 9) (1, 2) 95.09 2.00 735 11 (9, 9) (3, 4) 94.85 2.00 1479 6 (11, 11) (1, 2) 94.97 2.06 767
下载: 导出CSV
表 4 不同结构的模型准确率对比
模型 参数量(M) Top-1(%) SMS-GCN 2.00 95.09 SMS-GCN(无SMS-TC) 3.76 94.46 SMS-GCN(无S) 1.96 94.97 SMS-GCN(无GMP) 2.00 94.90 SMS-GCN(无GAP) 2.00 94.93
下载: 导出CSV
表 5 添加不同模块的模型准确率对比(%)
模型 关节流 骨骼流 双流 CTR-GCN 94.74 94.70 96.07 CTR-GCN + MS-GC 94.91 94.90 96.30 CTR-GCN + SMS-TC 94.86 94.90 96.29 SMS-GCN 95.09 94.96 96.52
下载: 导出CSV
-
[1] IODICE F, DE MOMI E, and AJOUDANI A. HRI30: An action recognition dataset for industrial human-robot interaction[C]. Proceedings of the 26th International Conference on Pattern Recognition, Montreal, Canada, 2022: 4941–4947. doi: 10.1109/ICPR56361.2022.9956300. [2] SARDARI S, SHARIFZADEH S, DANESHKHAH A, et al. Artificial intelligence for skeleton-based physical rehabilitation action evaluation: A systematic review[J]. Computers in Biology and Medicine, 2023, 158: 106835. doi: 10.1016/j.compbiomed.2023.106835. [3] SUN Zehua, KE Qiuhong, RAHMANI H, et al. Human action recognition from various data modalities: A review[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(3): 3200–3225. doi: 10.1109/TPAMI.2022.3183112. [4] 曹毅, 吴伟官, 张小勇, 等. 基于自校准机制的时空采样图卷积行为识别模型[J]. 工程科学学报, 2024, 46(3): 480–490. doi: 10.13374/j.issn2095-9389.2022.12.25.002.CAO Yi, WU Weiguan, ZHANG Xiaoyong, et al. Action recognition model based on the spatiotemporal sampling graph convolutional network and self-calibration mechanism[J]. Chinese Journal of Engineering, 2024, 46(3): 480–490. doi: 10.13374/j.issn2095-9389.2022.12.25.002. [5] SHEN Xiangpei and DING Yanrui. Human skeleton representation for 3D action recognition based on complex network coding and LSTM[J]. Journal of Visual Communication and Image Representation, 2022, 82: 103386. doi: 10.1016/j.jvcir.2021.103386. [6] LIU Jun, WANG Gang, HU Ping, et al. Global context-aware attention LSTM networks for 3D action recognition[C]. Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, USA, 2017: 3671–3680. doi: 10.1109/CVPR.2017.391. [7] XIA Rongjie, LI Yanshan, and LUO Wenhan. LAGA-Net: Local-and-global attention network for skeleton based action recognition[J]. IEEE Transactions on Multimedia, 2022, 24: 2648–2661. doi: 10.1109/TMM.2021.3086758. [8] ZHANG Pengfei, LAN Cuiling, ZENG Wenjun, et al. Semantics-guided neural networks for efficient skeleton-based human action recognition[C]. Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 1109–1118. doi: 10.1109/CVPR42600.2020.00119. [9] SHI Lei, ZHANG Yifan, CHENG Jian, et al. Two-stream adaptive graph convolutional networks for skeleton-based action recognition[C]. Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA, 2019: 12018–12027. doi: 10.1109/CVPR.2019.01230. [10] CHEN Yuxin, ZHANG Ziqi, YUAN Chunfeng, et al. Channel-wise topology refinement graph convolution for skeleton-based action recognition[C]. Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, Canada, 2021: 13339–13348. doi: 10.1109/ICCV48922.2021.01311. [11] 曹毅, 吴伟官, 李平, 等. 基于时空特征增强图卷积网络的骨架行为识别[J]. 电子与信息学报, 2023, 45(8): 3022–3031. doi: 10.11999/JEIT220749.CAO Yi, WU Weiguan, LI Ping, et al. Skeleton action recognition based on spatio-temporal feature enhanced graph convolutional network[J]. Journal of Electronics & Information Technology, 2023, 45(8): 3022–3031. doi: 10.11999/JEIT220749. [12] ZHU Yisheng, SHUAI Hui, LIU Guangcan, et al. Multilevel spatial-temporal excited graph network for skeleton-based action recognition[J]. IEEE Transactions on Image Processing, 2023, 32: 496–508. doi: 10.1109/TIP.2022.3230249. [13] ZHOU Huanyu, LIU Qingjie, and WANG Yunhong. Learning discriminative representations for skeleton based action recognition[C]. Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, Canada, 2023: 10608–10617. doi: 10.1109/CVPR52729.2023.01022. [14] WANG Kaixuan, DENG Hongmin, and ZHU Qilin. Lightweight channel-topology based adaptive graph convolutional network for skeleton-based action recognition[J]. Neurocomputing, 2023, 560: 126830. doi: 10.1016/j.neucom.2023.126830. [15] YAN Sijie, XIONG Yuanjun, and LIN Dahua. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]. Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, USA, 2018: 7444–7452. doi: 10.1609/aaai.v32i1.12328. [16] GEDAMU K, JI Yanli, GAO Lingling, et al. Relation-mining self-attention network for skeleton-based human action recognition[J]. Pattern Recognition, 2023, 139: 109455. doi: 10.1016/j.patcog.2023.109455. [17] LIU Ziyu, ZHANG Hongwen, CHEN Zhenghao, et al. Disentangling and unifying graph convolutions for skeleton-based action recognition[C]. Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 140–149. doi: 10.1109/CVPR42600.2020.00022. [18] LI Yuxuan, HOU Qibin, ZHENG Zhaohui, et al. Large selective kernel network for remote sensing object detection[C]. Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2023: 16748–16759. doi: 10.1109/ICCV51070.2023.01540. [19] XIA Yu, GAO Qingyuan, WU Weiguan, et al. Skeleton-based action recognition based on multidimensional adaptive dynamic temporal graph convolutional network[J]. Engineering Applications of Artificial Intelligence, 2024, 127: 107210. doi: 10.1016/j.engappai.2023.107210. [20] AMIR S, LIU Jun, NG T T, et al. NTU RGB+D: A large scale dataset for 3D human activity analysis[C]. Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA: IEEE, 2016: 1010–1019. doi: 10.1109/CVPR.2016.115. [21] LIU Jun, SHAHROUDY A, PEREZ M, et al. NTU RGB+D 120: A large-scale benchmark for 3D human activity understanding[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(10): 2684–2701. doi: 10.1109/TPAMI.2019.2916873. [22] PAN Qingzhe, ZHAO Zhifu, XIE Xuemei, et al. View-normalized and subject-independent skeleton generation for action recognition[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(12): 7398–7412. doi: 10.1109/TCSVT.2022.3219864. [23] 曹毅, 刘晨, 盛永健, 等. 基于三维图卷积与注意力增强的行为识别模型[J]. 电子与信息学报, 2021, 43(7): 2071–2078. doi: 10.11999/JEIT200448.CAO Yi, LIU Chen, SHENG Yongjian, et al. Action recognition model based on 3D graph convolution and attention enhanced[J]. Journal of Electronics & Information Technology, 2021, 43(7): 2071–2078. doi: 10.11999/JEIT200448. -

 下载:
下载:



图(3) / 表(7)
计量
- 文章访问数: 991
- HTML全文浏览量: 727
- PDF下载量: 102
- 被引次数: 0
