

A Detection Method of Small Target in Sea Clutter Environment Based on Feature Temporal Sequence
-
摘要: 特征检测作为海杂波环境下小目标检测的有效手段,受到了广泛关注与深入研究。过去对特征的研究大多关注于当前帧,近年来使用帧间时序信息融合当前帧特征的方法也被提出并在检测方面取得一定效果。但该方法不能很好地适应具有时变性的海杂波数据,且仅采用静态加权算法融合特征,对历史帧信息的利用不够充分。针对上述问题,该文提出基于模型稳定的修正Burg方法进行特征自回归(AR)建模与一步预测,使模型能够自适应调整极点分布,提高了海杂波特征预测的准确性,并基于求解多变量极值问题提出了一种动态加权算法得到了最小方差的融合特征。该文结合IPIX数据集和海军航空大学共享数据集进行实验,利用相对平均幅度(RAA)、相对多普勒峰高(RDPH)、频域峰均值比(FPAR)3特征构建凸包检测器验证了所提方法的有效性。Abstract:
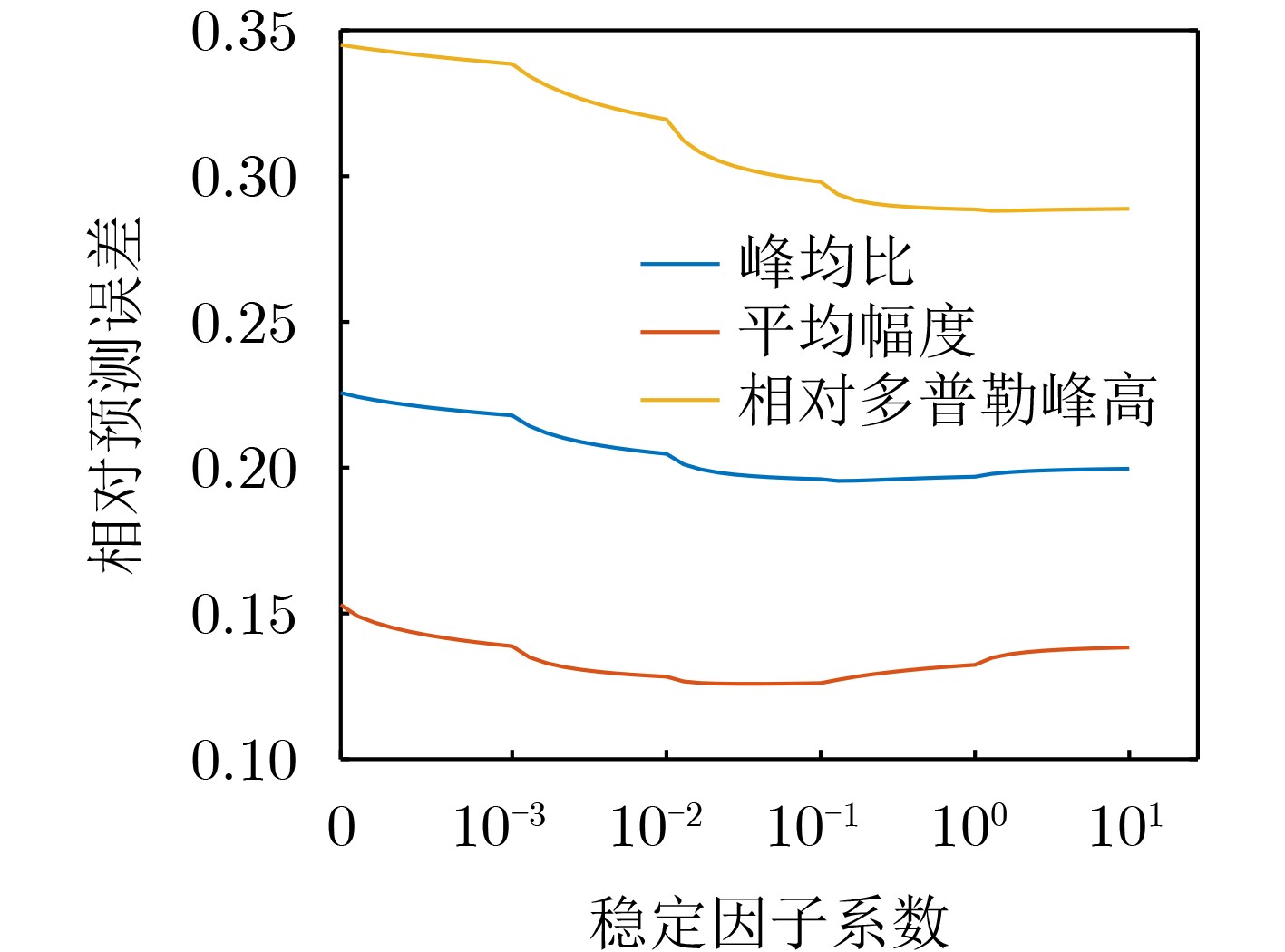
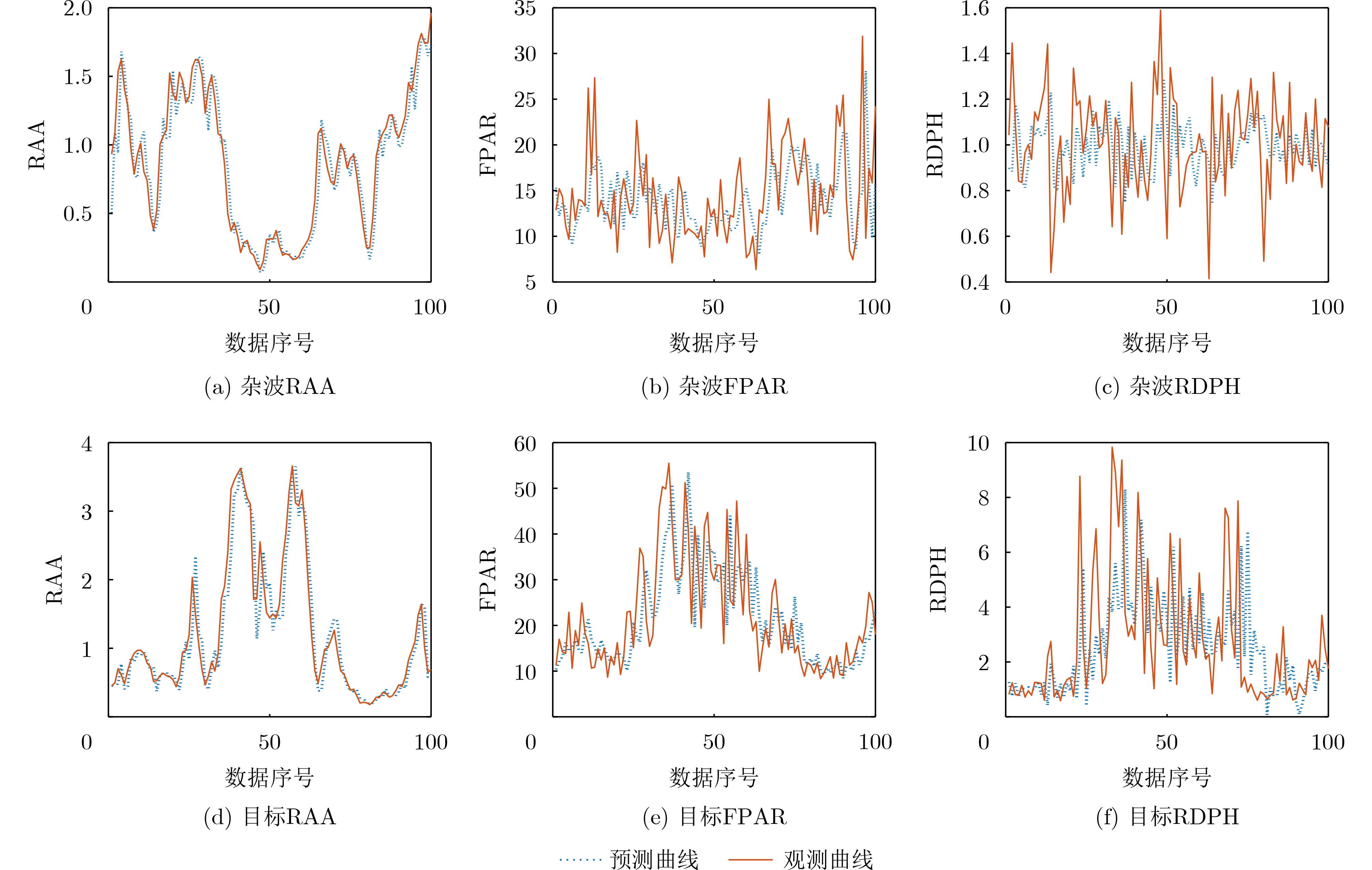
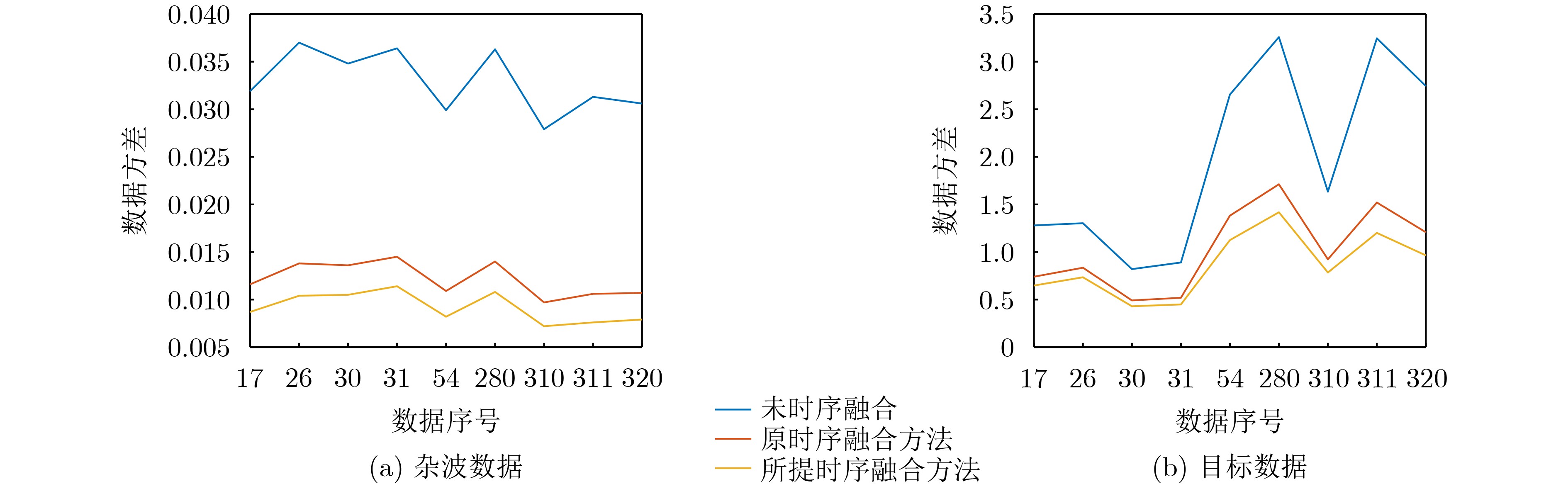
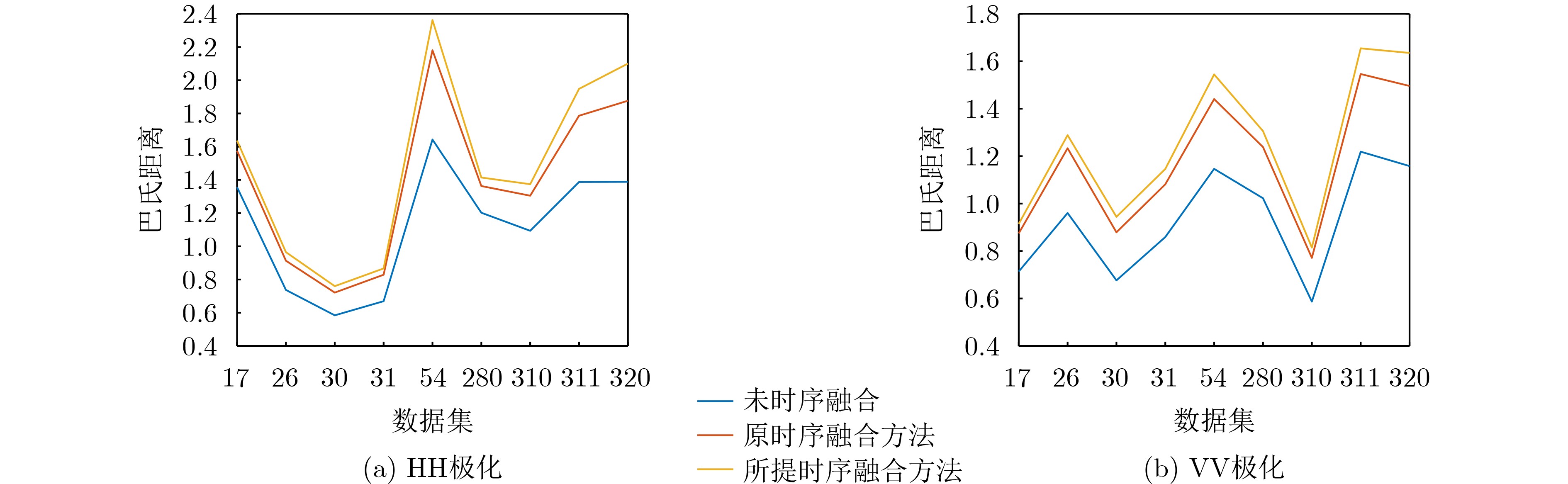
Objective Feature detection has become an effective approach for detecting small targets in sea clutter environments, attracting significant attention and research. Previous studies primarily focused on extracting differential features between targets and clutter from the current pulse frame for detection. Recent methods have integrated temporal information from multiple frames with current frame features, demonstrating improved detection performance. However, these methods rely on fixed-order Auto Regressive (AR) models, which do not effectively adapt to the time-varying nature of sea clutter. Moreover, the use of static weighting algorithms for feature fusion fails to account for clutter characteristics in the current scene, leading to suboptimal utilization of temporal information. To address these issues, this study proposes a feature AR modeling and one-step prediction method based on a model-stable modified Burg algorithm, enabling adaptive pole distribution adjustment and enhancing the accuracy of sea clutter feature prediction. Additionally, a dynamic weighting algorithm is developed by solving multivariable extreme value problems to obtain minimum variance fused features, fully leveraging historical frame temporal information and improving radar target detection performance. Methods This study employs a modified Burg method to predict sea clutter, incorporating a stability factor in the derivation of reflection coefficients to constrain the model’s poles within the unit circle. This enhances model stability, improving its adaptability to the time-varying nature of sea clutter and increasing the accuracy of feature prediction. A dynamic weighting algorithm is introduced to adaptively adjust fusion weights based on data volatility around the current frame by solving a multivariable extremum problem, thereby minimizing the local variance of fused features. Temporal fusion is performed using the features Relative Average Amplitude (RAA), Frequency Peak to Average Ratio (FPAR), and Relative Doppler Peak Height (RDPH) to generate a fused feature. The fused clutter features are then used to construct a three-dimensional convex hull decision region, where target presence is determined by assessing whether the detection unit’s feature point lies within this region. Detection results are compared with commonly used feature detection methods. Additionally, the study evaluates the boundary performance of the proposed method and contrasts it with the traditional energy-domain CFAR method, providing a comprehensive analysis of its usability and effectiveness. Results and Discussions The proposed method achieves the following results: (1) For clutter data, the temporal fusion algorithm reduces data variance by an average of 0.024 5 compared to no temporal fusion and by 0.003 5 compared to the original temporal fusion algorithm. For target data, it reduces data variance by an average of 1.126 6 compared to no temporal fusion and by 0.179 compared to the original temporal fusion algorithm. (2) The Bhattacharyya distance of the proposed temporal fusion algorithm improves by an average of 0.237 3 compared to no temporal fusion and by 0.109 3 compared to the original temporal fusion algorithm. Under VV polarization, the Bhattacharyya distance improves by an average of 0.219 9 compared to no temporal fusion and by 0.090 8 compared to the original temporal fusion algorithm. (3) The proposed method outperforms other feature detectors in detection performance by effectively utilizing temporal information from historical frames, thereby enhancing the echo information used. Compared to energy-domain CFAR methods, it maintains a strong competitive advantage. Conclusions This study presents innovative solutions to two key challenges in existing sea clutter feature modeling and fusion methods. First, to address the time-varying nature of sea clutter features, a model-stable modified Burg method is proposed for Autoregressive (AR) feature modeling. This approach enables adaptive adjustment of model pole distribution, improving the accuracy of one-step sea clutter feature predictions and simplifying model order estimation. Second, to enhance the utilization of inter-frame temporal information during feature fusion, a dynamic weighted fusion algorithm is introduced to integrate predicted and observed features. This method reduces the variance of fused features and fully exploits historical temporal information. Validation using the IPIX dataset and the shared dataset from the Naval Aeronautical University demonstrates that the fused features obtained through these methods exhibit improved separability compared to the original features, significantly enhancing detector performance. -
Key words:
- Small target detection /
- Sea clutter /
- Temporal feature information /
- Modified burg /
- Dynamic weighting
-
表 1 IPIX数据集信息
文件序号 采样数 浪高 风力 目标影响单元
目标所在单元总距离 最大(m) 一般(m) 风向(°) 风速(m/s) 单元个数 17 131 072 3.1 2.1 301 10 8:11 9 14 26 131 072 1.56 1.03 211 9 6:9 7 14 30 131 072 1.25 0.89 210 19 6:8 7 14 31 131 072 1.28 0.89 206 15 6:9 7 14 54 131 072 0.97 0.66 308 20 7:10 8 14 280 131 072 2.4 1.44 216 11 7:10 8 14 310 131 072 1.38 0.9 313 33 6:9 7 14 311 131 072 1.38 0.9 310 33 6:9 7 14 320 131 072 1.34 0.91 317 27 6:9 7 14  下载: 导出CSV
下载: 导出CSV
表 3 不同预测方法下杂波特征的平均相对预测误差
AR预测方法 不同特征的平均相对预测误差 RAA FPAR RDPH 本文所提方法 0.128 3 0.204 7 0.319 4 未修正Burg方法 0.153 0 0.225 6 0.345 0 文献[10]方法 0.198 3 0.260 3 0.338 4 LSTM 0.263 2 0.198 5 0.296 0
下载: 导出CSV
表 4 不同预测方法下目标特征的平均相对预测误差
AR预测方法 不同特征的平均相对预测误差 RAA FPAR RDPH 本文方法 0.112 6 0.183 1 0.285 8 未修正Burg方法 0.126 9 0.199 9 0.315 8 文献[10]方法 0.198 3 0.260 3 0.338 4 LSTM 0.152 7 0.183 2 0.310 7
下载: 导出CSV
表 5 IPIX数据检测结果
检测器 使用脉冲数 不同极化方式下的平均检测概率 平均检测概率 HH HV VH VV 原3特征
检测器64 0.245 9 0.349 1 0.339 3 0.177 2 0.277 9 128 0.437 2 0.574 3 0.569 9 0.368 7 0.487 5 256 0.569 4 0.699 6 0.696 7 0.496 2 0.615 5 文献[10]检测器 64 0.348 1 0.472 8 0.456 1 0.276 4 0.388 4 128 0.629 2 0.743 9 0.735 4 0.535 6 0.661 0 256 0.709 9 0.813 9 0.809 3 0.642 0 0.743 8 本文检测器 64 0.417 7 0.543 2 0.537 3 0.347 4 0.461 4 128 0.692 1 0.794 1 0.792 6 0.630 0 0.727 2 256 0.776 3 0.856 3 0.854 4 0.732 1 0.804 8
下载: 导出CSV
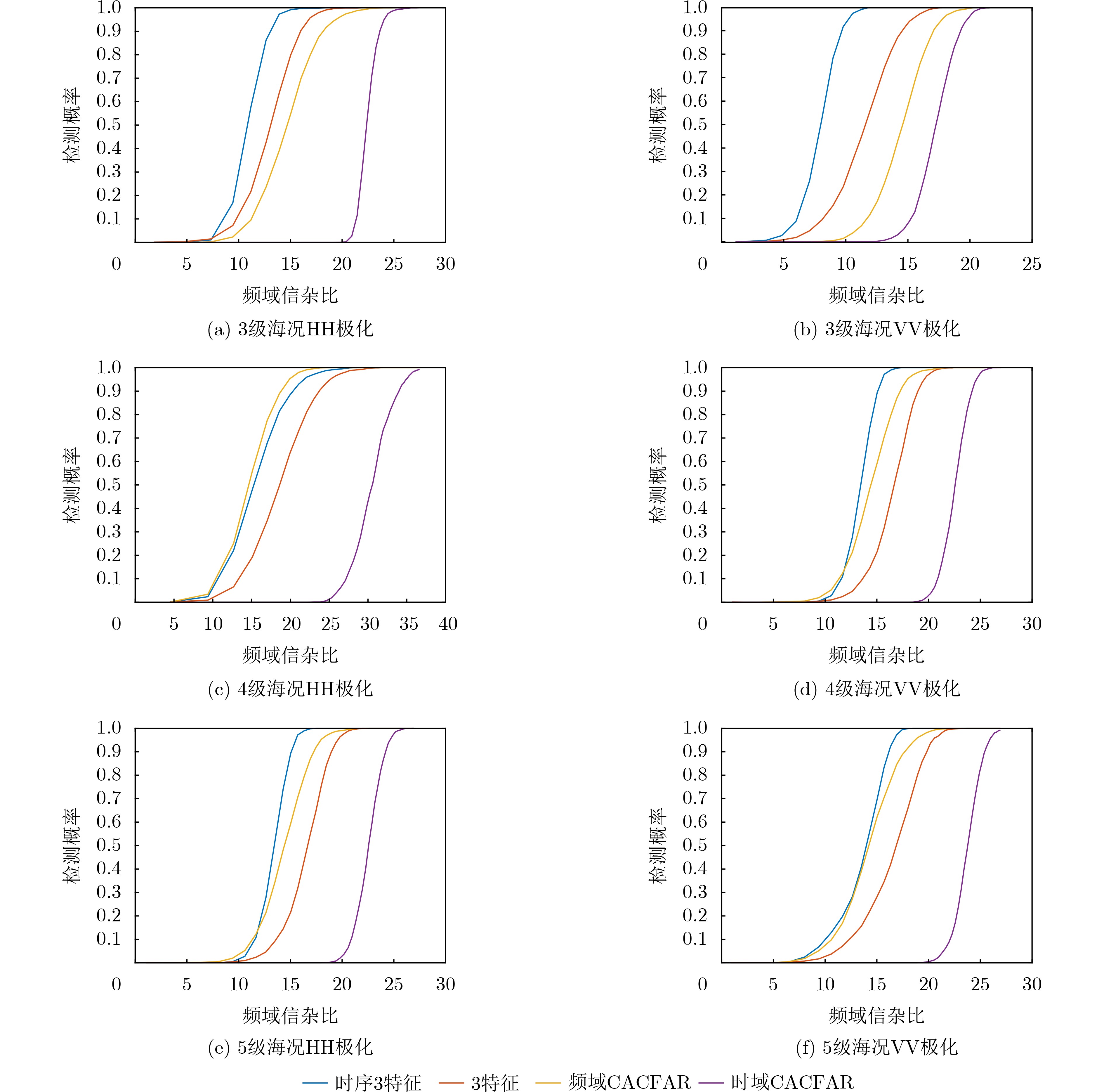
表 6 海军航空大学共享数据集检测结果
检测器 使用脉冲数 检测概率 平均检测概率 4级HH 4级VV 5级HH 5级VV 原3特征
检测器64 0.305 5 0.682 0 0.218 2 0.155 8 0.340 4 128 0.456 7 0.808 4 0.453 1 0.334 8 0.513 2 256 0.632 7 0.907 1 0.647 5 0.459 4 0.661 7 文献[10]检测器 64 0.400 7 0.718 6 0.334 7 0.208 9 0.415 7 128 0.592 3 0.886 5 0.644 5 0.443 3 0.641 7 256 0.753 3 0.959 1 0.820 8 0.534 6 0.767 0 本文检测器 64 0.442 4 0.778 5 0.434 1 0.255 6 0.477 7 128 0.647 1 0.922 5 0.727 6 0.497 5 0.698 7 256 0.803 1 0.976 6 0.866 4 0.597 9 0.811 0
下载: 导出CSV
-
[1] 关键. 雷达海上目标特性综述[J]. 雷达学报, 2020, 9(4): 674–683. doi: 10.12000/JR20114.GUAN Jian. Summary of marine radar target characteristics[J]. Journal of Radars, 2020, 9(4): 674–683. doi: 10.12000/JR20114. [2] BI Xiaowen, GUO Shenglong, YANG Yunxiu, et al. Adaptive target extraction method in sea clutter based on fractional Fourier filtering[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5115609. doi: 10.1109/TGRS.2022.3192893. [3] SHI Sainan and SHUI Penglang. Sea-surface floating small target detection by one-class classifier in time-frequency feature space[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(11): 6395–6411. doi: 10.1109/ TGRS.2018.2838260. doi: 10.1109/TGRS.2018.2838260. [4] XU Shuwen, ZHENG Jibin, PU Jia, et al. Sea-surface floating small target detection based on polarization features[J]. IEEE Geoscience and Remote Sensing Letters, 2018, 15(10): 1505–1509. doi: 10.1109/LGRS.2018.2852560. [5] 陈世超, 高鹤婷, 罗丰. 基于极化联合特征的海面目标检测方法[J]. 雷达学报, 2020, 9(4): 664–673. doi: 10.12000/ JR20072. doi: 10.12000/JR20072.CHEN Shichao, GAO Heting, and LUO Feng. Target detection in sea clutter based on combined characteristics of polarization[J]. Journal of Radars, 2020, 9(4): 664–673. doi: 10.12000/JR20072. [6] LO T, LEUNG H, LITVA J, et al. Fractal characterisation of sea-scattered signals and detection of sea-surface targets[J]. IEE Proceedings F: Radar and Signal Processing, 1993, 140(4): 243–250. doi: 10.1049/ip-f-2.1993.0034. [7] FAN Yifei, TAO Mingliang, and SU Jia. Multifractal correlation analysis of autoregressive spectrum-based feature learning for target detection within sea clutter[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5108811. doi: 10.1109/TGRS.2021.3137466. [8] 关键, 伍僖杰, 丁昊, 等. 基于对角积分双谱的海面慢速小目标检测方法[J]. 电子与信息学报, 2022, 44(7): 2449–2460. doi: 10.11999/JEIT210408.GUAN Jian, WU Xijie, DING Hao, et al. A method for detecting small slow targets in sea surface based on diagonal integrated bispectrum[J]. Journal of Electronics & Information Technology, 2022, 44(7): 2449–2460. doi: 10.11999/JEIT210408. [9] 关键, 姜星宇, 刘宁波, 等. 海杂波背景下的双极化最大特征值目标检测[J]. 系统工程与电子技术, 2024, 46(11): 3715–3725. doi: 10.12305/j.issn.1001-506X.2024.11.13.GUAN Jian, JIANG Xingyu, LIU Ningbo, et al. Target detection using dual-polarization maximum eigenvalue in sea clutter background[J]. Systems Engineering and Electronics, 2024, 46(11): 3715–3725. doi: 10.12305/j.issn.1001-506X.2024.11.13. [10] 董云龙, 张兆祥, 丁昊, 等. 基于三特征预测的海杂波中小目标检测方法[J]. 雷达学报, 2023, 12(4): 762–775. doi: 10.12000/JR23037.DONG Yunlong, ZHANG Zhaoxiang, DING Hao, et al. Target detection in sea clutter using a three-feature prediction-based method[J]. Journal of Radars, 2023, 12(4): 762–775. doi: 10.12000/JR23037. [11] SHUI Penglang, LI Dongchen, and XU Shuwen. Tri-feature-based detection of floating small targets in sea clutter[J]. IEEE Transactions on Aerospace and Electronic Systems, 2014, 50(2): 1416–1430. doi: 10.1109/TAES.2014.120657. [12] IPIX Radar. The IPIX radar database[EB/OL]. http://soma.ece.mcmaster.ca/ipix/, 2021. [13] 关键, 刘宁波, 王国庆, 等. 雷达对海探测试验与目标特性数据获取——海上目标双极化多海况散射特性数据集[J]. 雷达学报, 2023, 12(2): 456–469. doi: 10.12000/JR23029.GUAN Jian, LIU Ningbo, WANG Guoqing, et al. Sea-detecting radar experiment and target feature data acquisition for dual polarization multistate scattering dataset of marine targets[J]. Journal of Radars, 2023, 12(2): 456–469. doi: 10.12000/JR23029. [14] BARBARESCO F. Algorithme de burg regularise fsds (fonctionnelle stabilisatrice de douceur spectrale) Comparaison avec l'algorithme de burg mfe (Minimum free energy)[C]. Quinzieme Colloque Gretsi - Juan-Les-Pins, 1995: 29–32. [15] LI Yuzhou, XIE Pengcheng, TANG Zeshen, et al. SVM-based sea-surface small target detection: A false-alarm-rate-controllable approach[J]. IEEE Geoscience and Remote Sensing Letters, 2019, 16(8): 1225–1229. doi: 10.1109/LGRS.2019.2894385. [16] 王鑫, 吴际, 刘超, 等. 基于LSTM循环神经网络的故障时间序列预测[J]. 北京航空航天大学学报, 2018, 44(4): 772–784. doi: 10.13700/j.bh.1001-5965.2017.0285.WANG Xin, WU Ji, LIU Chao, et al. Exploring LSTM based recurrent neural network for failure time series prediction[J]. Journal of Beijing University of Aeronautics and Astronautics, 2018, 44(4): 772–784. doi: 10.13700/j.bh.1001-5965.2017.0285. [17] 胡学骏, 罗中良. 基于统计理论的多传感器信息融合方法[J]. 传感器技术, 2002(8): 38–39,43. doi: 10.13873/j.1000-97872002.08.013.HU Xuejun and LUO Zhongliang. Method of multi-sensor information fusion based on statistics theory[J]. Transducer and Microsystem Technologies, 2002(8): 38–39,43. doi: 10.13873/j.1000-97872002.08.013. -


 下载:
下载:










图(14) / 表(6)
计量
- 文章访问数: 1166
- HTML全文浏览量: 643
- PDF下载量: 145
- 被引次数: 0
