

Deep Reinforcement Learning Based Beamforming Algorithm for IRS Assisted Cognitive Radio System
-
摘要: 为进一步提升多用户无线通信系统的频谱利用率,该文提出了一种基于深度强化学习的智能反射面(IRS)辅助认知无线电网络次用户和速率最大化算法。首先在考虑次基站最大发射功率约束、次基站对主用户的干扰容限约束以及IRS相移矩阵单位模量约束的情况下,建立一个联合优化次基站波束成形和IRS相移矩阵的资源分配模型;然后提出了一种基于深度确定性策略梯度的主被动波束成形算法,联合进行变量优化以最大化次用户和速率。仿真结果表明,所提算法相对于传统优化算法在和速率性能接近的情况下具有更低的时间复杂度。Abstract:
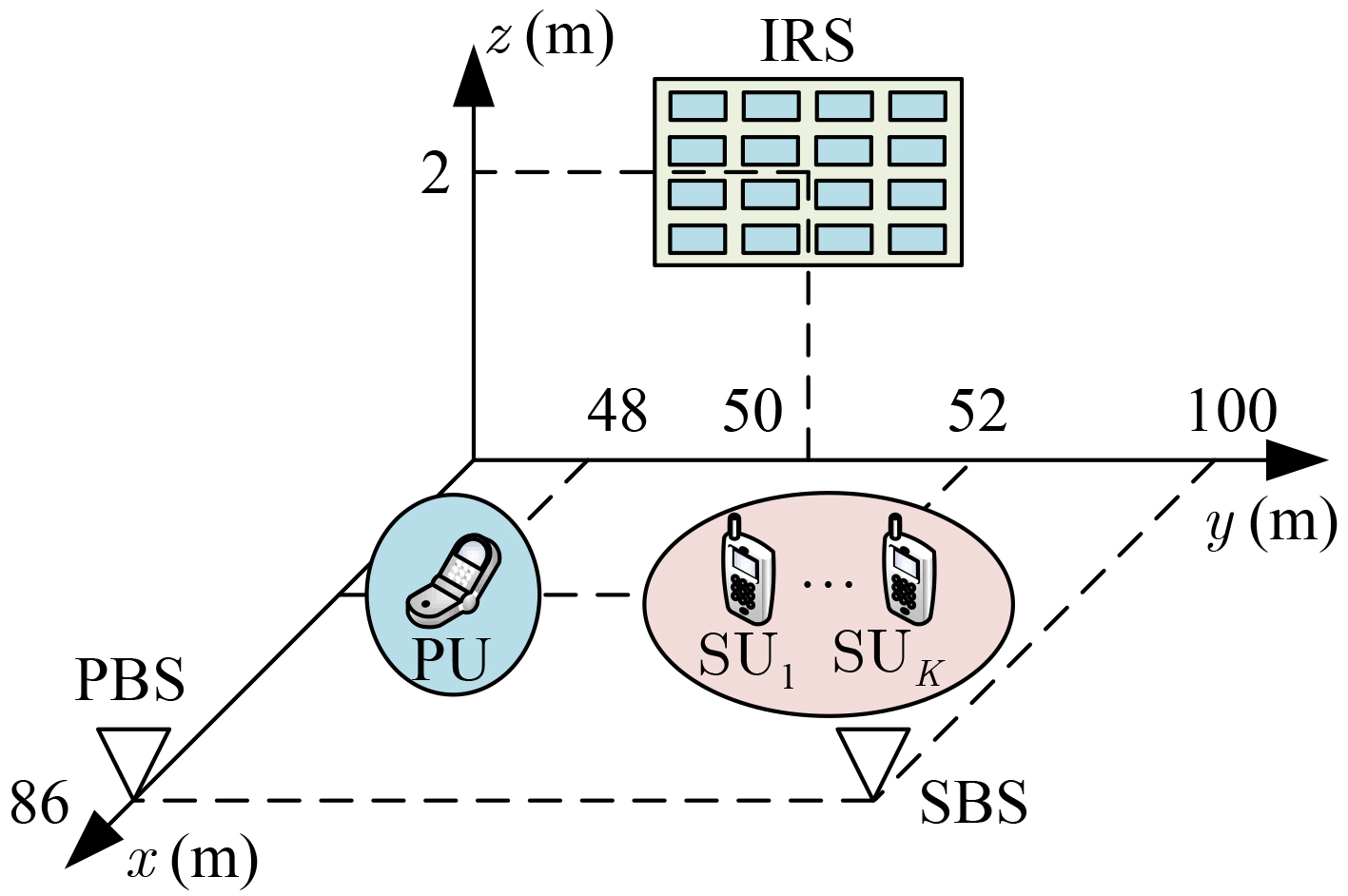
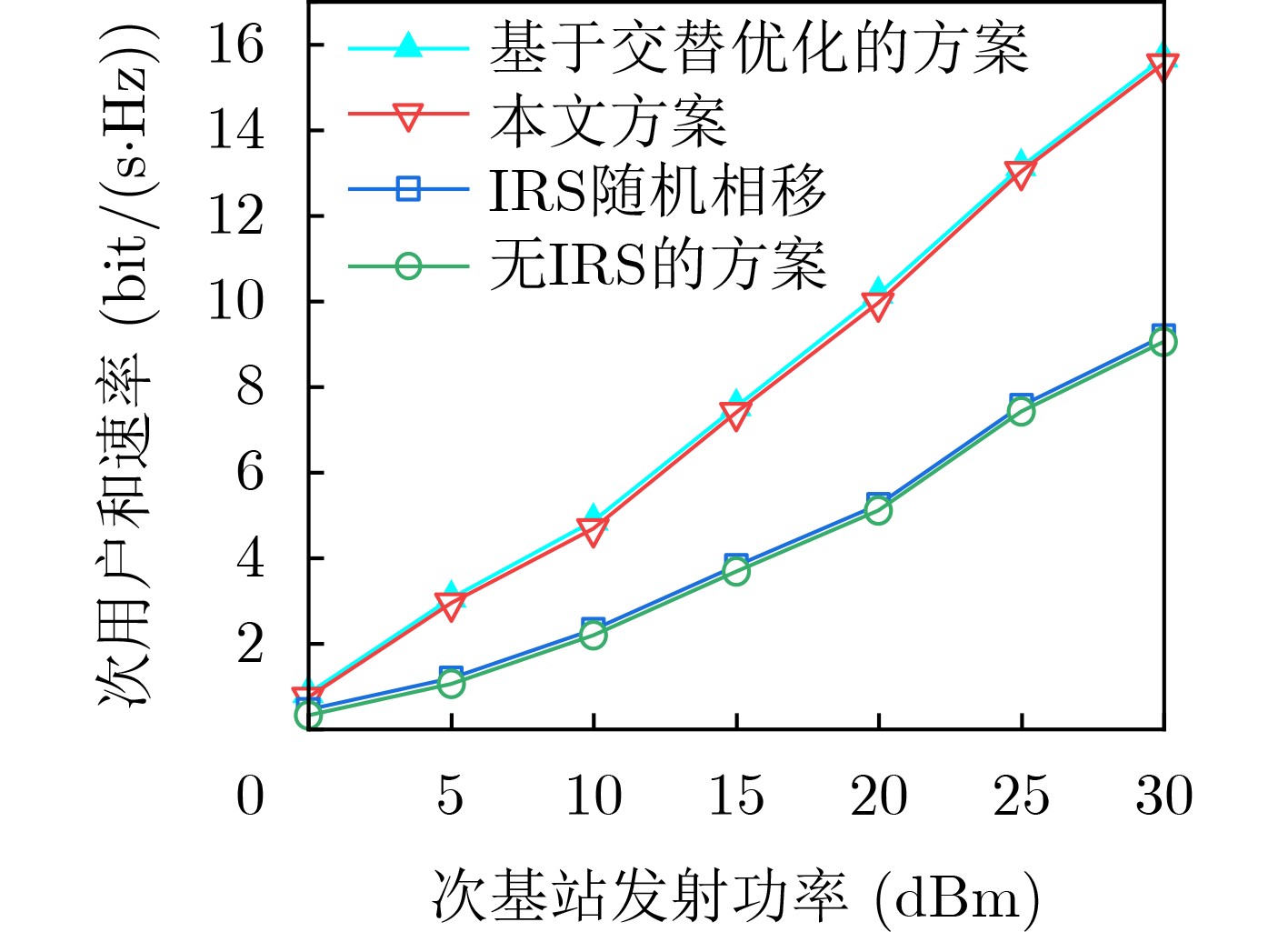
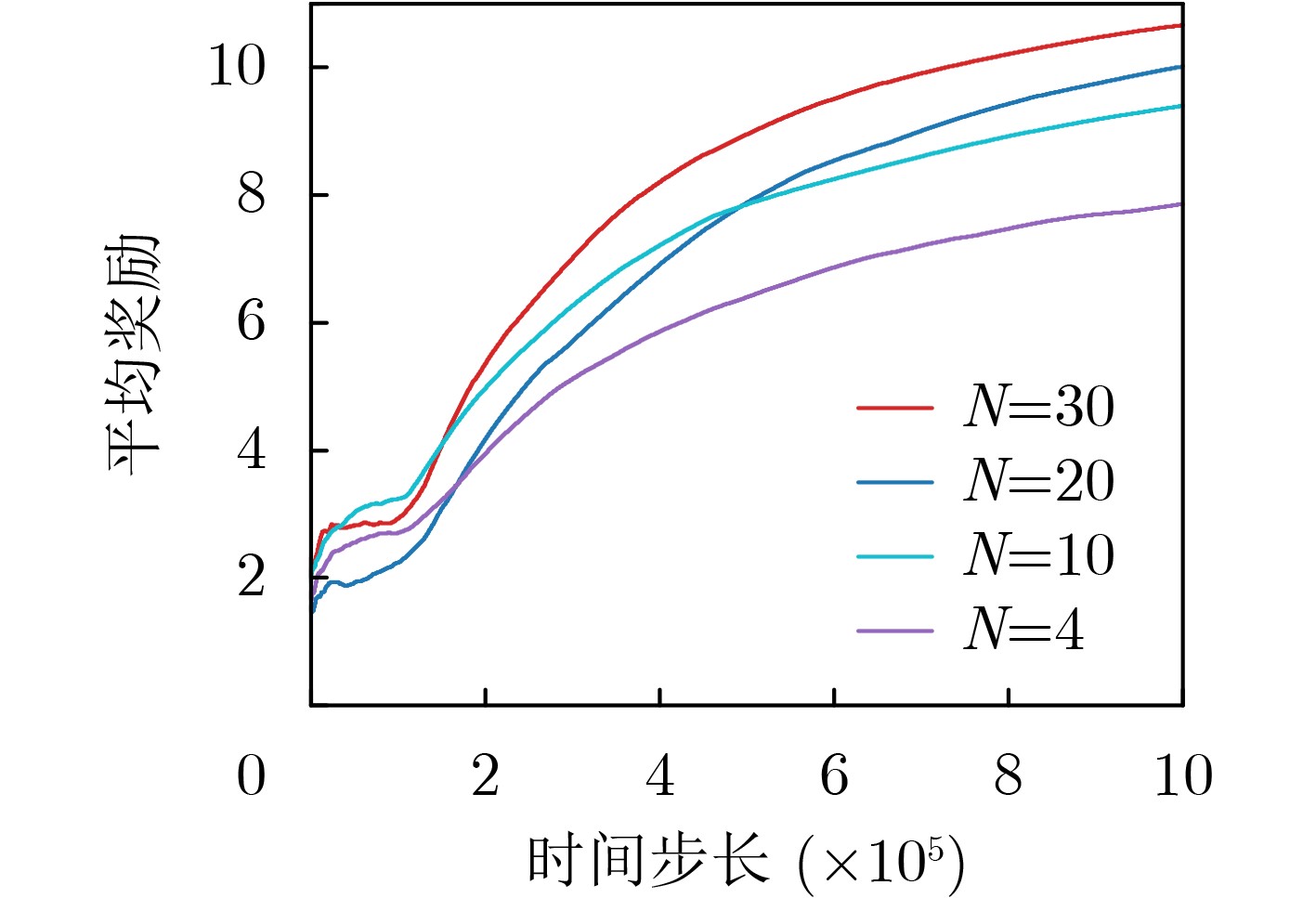
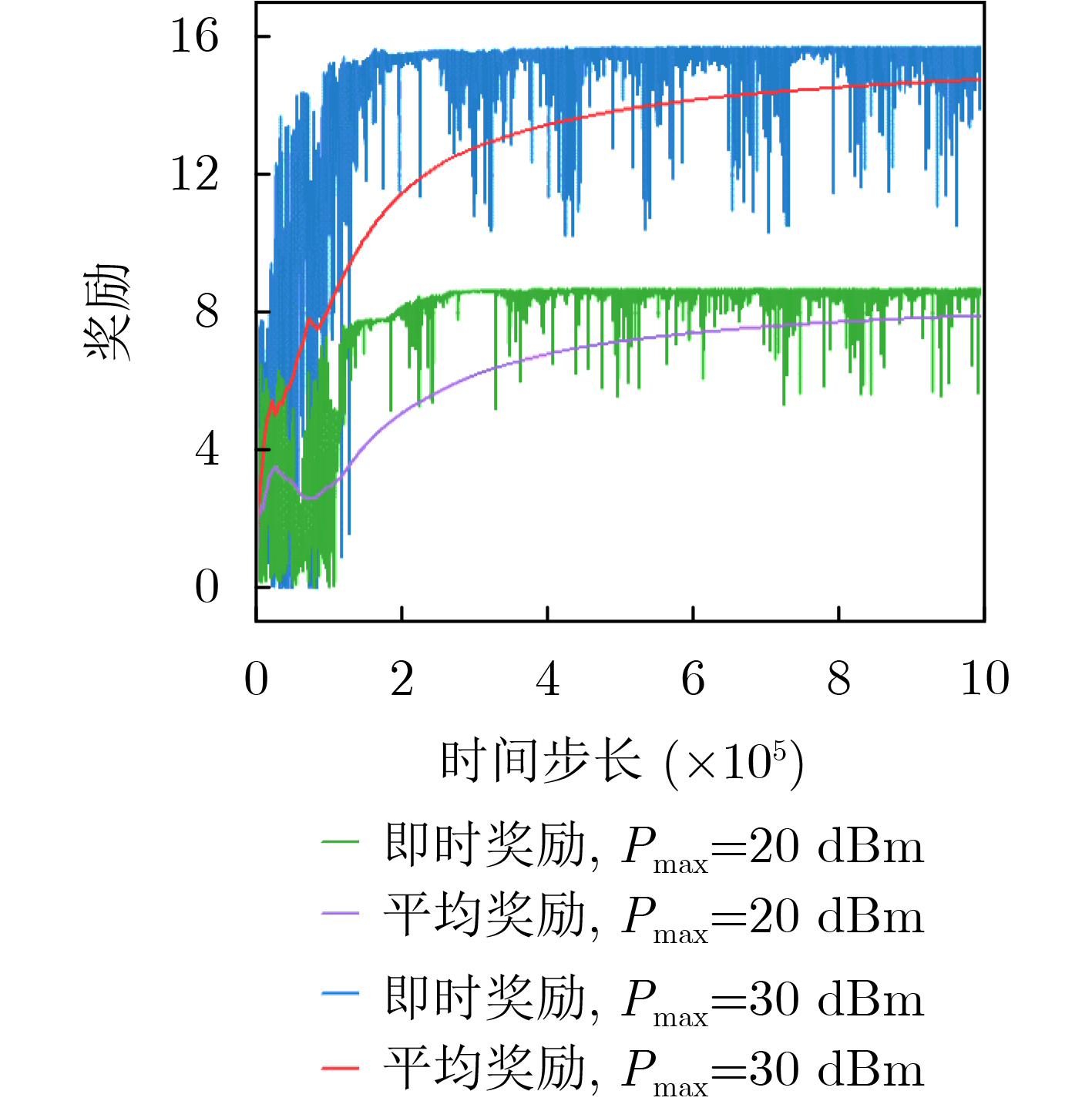
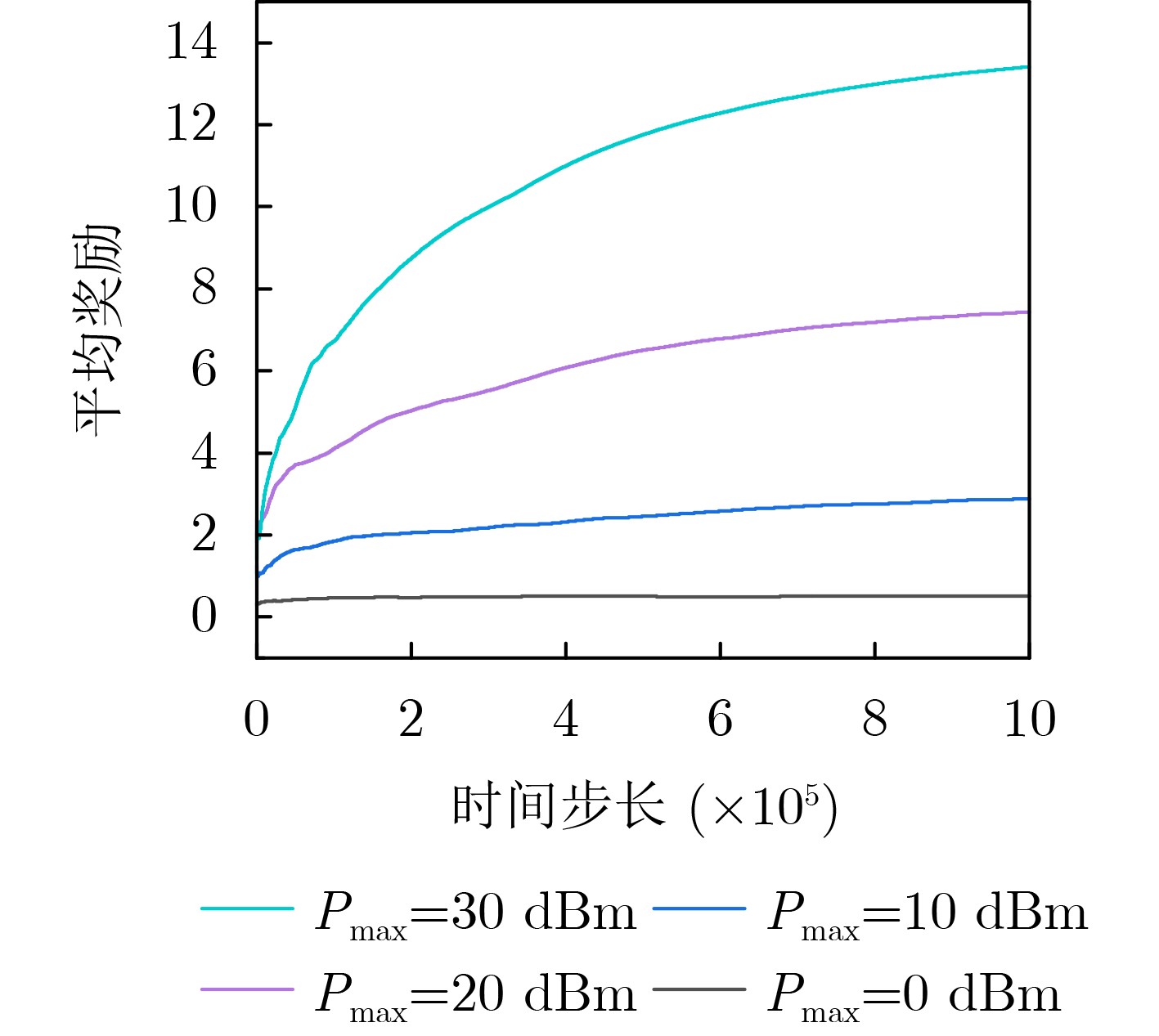
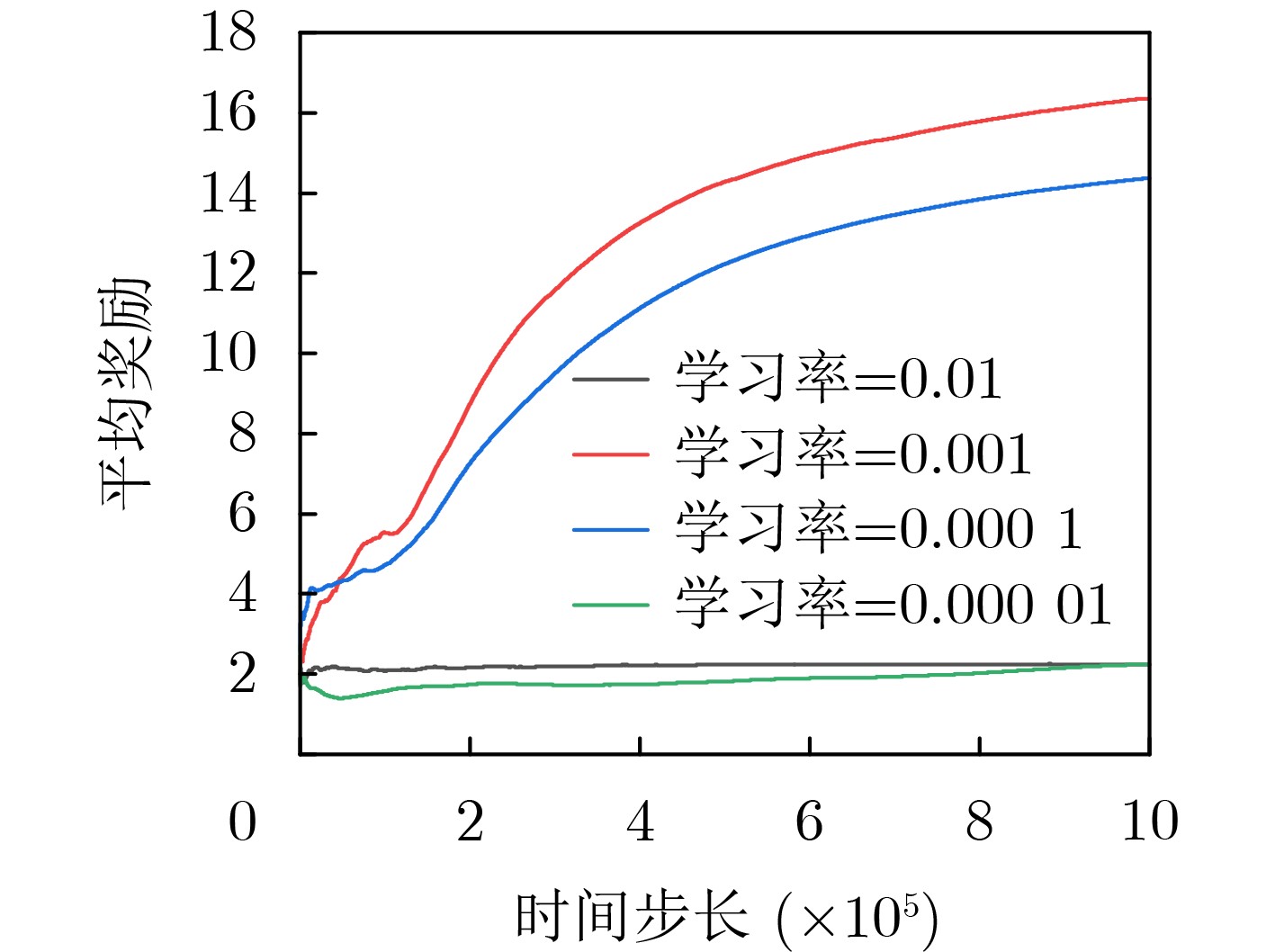
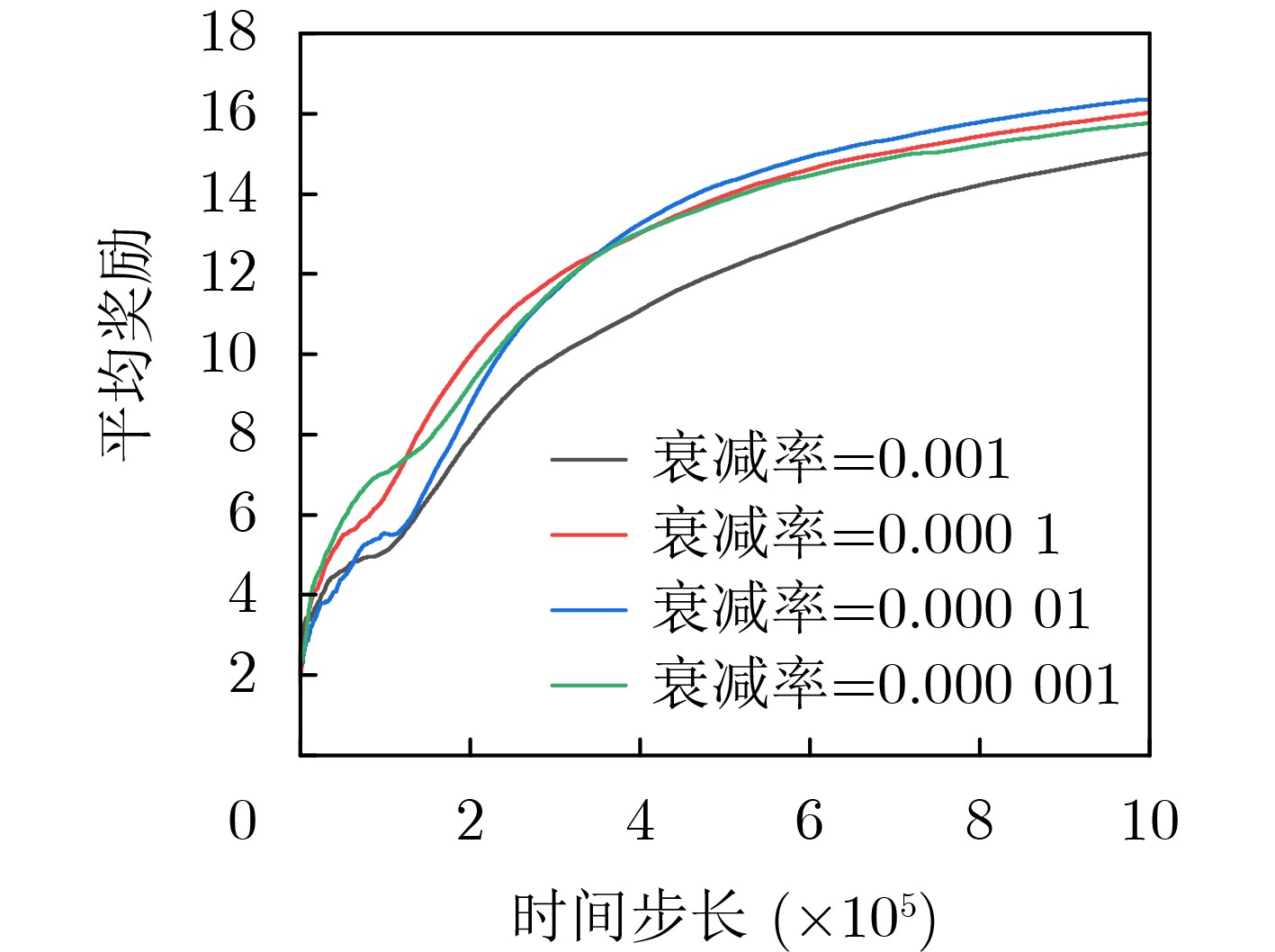
Objective With the rapid development of wireless communication technologies, the demand for spectrum resources has significantly increased. Cognitive Radio (CR) has emerged as a promising solution to improve spectrum utilization by enabling Secondary Users (SUs) to access licensed spectrum bands without causing harmful interference to Primary Users (PUs). However, traditional CR networks face challenges in achieving high spectral efficiency due to limited control over the wireless environment. Intelligent Reflecting Surfaces (IRS) have recently been introduced as a revolutionary technology to enhance communication performance by dynamically reconfiguring the propagation environment. This paper aims to maximize the sum rate of SUs in an IRS-assisted CR network by jointly optimizing the active beamforming at the Secondary Base Station (SBS) and the passive beamforming at the IRS, subject to constraints on the maximum transmit power of the SBS, the interference tolerance of PUs, and the unit modulus of the IRS phase shifts. Methods To address the non-convex and highly coupled optimization problem, a Deep Reinforcement Learning (DRL)-based algorithm is proposed. Specifically, the problem is formulated as a Markov Decision Process (MDP), where the state space includes the Channel State Information (CSI) of the entire system, the Signal-to-Interference-plus-Noise Ratio (SINR) in the SU network, and the action space consists of the SBS beamforming vectors and the IRS phase shift matrix. The reward function is designed to maximize the sum rate of SUs while penalizing violations of the constraints. The Deep Deterministic Policy Gradient (DDPG) algorithm is used to solve the MDP, owing to its ability to handle continuous action spaces. The DDPG framework consists of an actor network, which outputs the optimal actions, and a critic network, which evaluates these actions based on the reward function. The training process involves interacting with the environment to learn the optimal policy, and the algorithm is fine-tuned to ensure convergence and robustness under varying system conditions. Results and Discussions Simulation results show that the proposed scheme achieves comparable sum rate performance with lower time complexity after optimization, compared to traditional optimization algorithms. The proposed algorithm significantly outperforms the no-IRS and IRS-random phase shift schemes ( Fig. 5 ). The results demonstrate that the proposed algorithm achieves a sum rate close to that of alternating optimization-based approaches (Fig. 5 ), while substantially reducing computational complexity (Fig. 5 ,Table 2 ). Additionally, the impact of the number of IRS elements on the sum rate is examined (Fig. 6 ). As expected, the average reward increases with the number of reflecting elements, while the convergence time remains stable, indicating the robustness of the proposed algorithm. The DRL-based algorithm, starting from the identity matrix, can learn and adjust the beamforming vectors and phase shifts to approach the optimal solution through interaction with the environment (Fig. 7 ). It is also observed that the variance of the instantaneous reward increases with the transmit power. This is due to the larger dynamic range of the instantaneous reward at higher power levels, resulting in greater fluctuations and slower convergence. The relationship between average reward and time steps under different transmit power levels is presented, highlighting the sensitivity of the algorithm to high signal-to-noise ratios (Fig. 8 ). Moreover, it can be observed that a learning rate of 0.001 yields the best performance, while excessively high or low learning rates degrade performance (Fig. 9 ). The discount factor has a relatively smaller impact on performance compared to the learning rate (Fig. 10 ).Conclusions This paper proposes a DRL-based algorithm for joint active and passive beamforming optimization in an IRS-assisted CR network. The algorithm utilizes the DDPG framework to maximize the sum rate of SUs while adhering to constraints on transmit power, interference, and IRS phase shifts. Simulation results demonstrate that the proposed algorithm achieves comparable sum rate performance to traditional optimization methods, with significantly lower computational complexity. The findings also highlight the impact of DRL parameter settings on performance. Future work will focus on extending the proposed algorithm to multi-cell scenarios and incorporating imperfect CSI to enhance its robustness in practical environments. -
1 基于DDPG的主被动波束成形算法训练
输入:IRS辅助的下行链路多用户MISO-CR系统的所有CSI 输出:最优动作${\boldsymbol{a}} = \left\{ {{{\boldsymbol{W}}_{\text{s}}},{\boldsymbol{\varTheta}} } \right\}$,Q值函数 初始化:大小为$\mathcal{D}$经验回放池$\mathcal{M}$,随机初始化演员和评论家网
络参数${\theta _\mu }$和${\theta _Q}$,赋值$ {\theta _{Q'}} \leftarrow {\theta _Q}{\text{ }},{\text{ }}{\theta _{\mu '}} \leftarrow {\theta _\mu } $for episode = $1,2,3, \cdots ,{T_1}$,进入循环 初始化发射波束成形矩阵${\boldsymbol{W}}_{\text{s}}^{\left( 0 \right)}$、相移矩阵${{\boldsymbol{\varTheta}} ^{\left( 0 \right)}}$为单位矩阵作
为${{\boldsymbol{a}}^{\left( 0 \right)}}$构建初始状态$ {{\boldsymbol{s}}^{\left( 0 \right)}} $ for time steps= $1,2,3, \cdots ,{T_2}$,进入循环 从演员网络中获取动作${a^{\left( t \right)}}$ 根据式(15)计算即时奖励${r^{\left( t \right)}}$ 根据式(3)计算所有SU的信干噪比$ \gamma _{{\text{SU}}}^{\left( t \right)} $ 构建在动作${{\boldsymbol{a}}^{\left( t \right)}}$下的状态${{\boldsymbol{s}}^{\left( {t + 1} \right)}}$ 存储经验数据组$\left( {{{\boldsymbol{s}}^{\left( t \right)}},{a^{\left( t \right)}},{r^{\left( t \right)}},{{\boldsymbol{s}}^{\left( {t + 1} \right)}}} \right)$到经验回放池中 从$\mathcal{M}$中随机抽取大小为${N_{\mathrm{B}}}$的小批量经验样本 根据式(6)得到目标Q值 根据式(7)得到在线评论家网络损失函数$ L({\theta _Q}) $ 根据式(8)得到在线演员网络策略梯度$ {\nabla _{{\theta _\mu }}}J(\mu ) $ 根据式(9)更新评论家网络参数$ {\iota _Q} $ 根据式(10)更新演员网络参数${\iota _\mu }$ 根据式(11)更新目标评论家网络参数${\tau _Q}$ 根据式(12)更新目标演员网络参数${\tau _\mu }$ 更新状态${{\boldsymbol{s}}^{\left( t \right)}} \leftarrow {{\boldsymbol{s}}^{\left( {t + 1} \right)}}$ end for end for  下载: 导出CSV
下载: 导出CSV
表 1 DDPG算法参数
超参数 描述 参数值 $\gamma $ 折扣率 0.99 ${\iota _\mu },{\iota _Q}$ 演员、评论家网络的学习率 0.001 ${\tau _\mu },{\tau _Q}$ 目标演员、目标评论家网络的学习率 0.001 $ {\lambda _a},{\lambda _c} $ 训练演员、评论家网络的衰减率 0.00001 ${L_1},{L_2}$ DNN隐藏层神经元数 1024 $\mathcal{D}$ 经验回放池$\mathcal{M}$的大小 100000 ${T_1}$ 回合数 10 ${T_2}$ 每个回合的时间步长数 1000000 ${N_{\mathrm{B}}}$ 小批量采样的大小 16
下载: 导出CSV
表 2 不同算法运行时间对比
IRS反射单元数 基于交替优化(ms) 本文算法(ms) N=4 968.76 16.24 N=10 1367.41 16.84 N=20 2248.25 16.36 N=30 3018.52 16.65
下载: 导出CSV
-
[1] LI Guoquan, HONG Zijie, PANG Yu, et al. Resource allocation for sum-rate maximization in NOMA-based generalized spatial modulation[J]. Digital Communications and Networks, 2022, 8(6): 1077–1084. doi: 10.1016/j.dcan.2022.02.005. [2] LI Xingwang, ZHENG Yike, ALSHEHRI M D, et al. Cognitive AmBC-NOMA IoV-MTS networks with IQI: Reliability and security analysis[J]. IEEE Transactions on Intelligent Transportation Systems, 2023, 24(2): 2596–2607. doi: 10.1109/TITS.2021.3113995. [3] 李国权, 党刚, 林金朝, 等. RIS辅助的MISO系统安全鲁棒波束赋形算法[J]. 电子与信息学报, 2023, 45(8): 2867–2875. doi: 10.11999/JEIT220894.LI Guoquan, DANG Gang, LIN Jinzhao, et al. Secure and robust beamforming algorithm for RIS assisted MISO systems[J]. Journal of Electronics & Information Technology, 2023, 45(8): 2867–2875. doi: 10.11999/JEIT220894. [4] CHEN Guang, CHEN Yueyun, MAI Zhiyuan, et al. Joint multiple resource allocation for offloading cost minimization in IRS-assisted MEC networks with NOMA[J]. Digital Communications and Networks, 2023, 9(3): 613–627. doi: 10.1016/j.dcan.2022.10.029. [5] 熊军洲, 李国权, 王钥涛, 等. 基于有源智能反射面反射单元分组的反射调制系统[J]. 电子与信息学报, 2024, 46(7): 2765–2772. doi: 10.11999/JEIT231187.XIONG Junzhou, LI Guoquan, WANG Yuetao, et al. A reflection modulation system based on reflecting element grouping of active intelligent reflecting surface[J]. Journal of Electronics & Information Technology, 2024, 46(7): 2765–2772. doi: 10.11999/JEIT231187. [6] GUAN Xinrong, WU Qingqing, and ZHANG Rui. Joint power control and passive beamforming in IRS-assisted spectrum sharing[J]. IEEE Communications Letters, 2020, 24(7): 1553–1557. doi: 10.1109/LCOMM.2020.2979709. [7] LE A T, DO D T, CAO Haotong, et al. Spectrum efficiency design for intelligent reflecting surface-aided IoT systems[C]. GLOBECOM 2022 - 2022 IEEE Global Communications Conference, Rio de Janeiro, Brazil, 2022: 25–30. doi: 10.1109/GLOBECOM48099.2022.10000937. [8] YUAN Jie, LIANG Yingchang, JOUNG J, et al. Intelligent Reflecting Surface (IRS)-enhanced cognitive radio system[C]. ICC 2020 - 2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 2022: 1–6. doi: 10.1109/ICC40277.2020.9148890. [9] WANG Zining, LIN Min, HUANG Shupei, et al. Robust beamforming for IRS-aided SWIPT in cognitive radio networks[J]. Digital Communications and Networks, 2023, 9(3): 645–654. doi: 10.1016/j.dcan.2022.10.030. [10] LI Guoquan, ZHANG Hui, WANG Yuhui, et al. QoS guaranteed power minimization and beamforming for IRS-assisted NOMA systems[J]. IEEE Wireless Communications Letters, 2023, 12(3): 391–395. doi: 10.1109/LWC.2022.3189272. [11] FENG Keming, WANG Qisheng, LI Xiao, et al. Deep reinforcement learning based intelligent reflecting surface optimization for MISO communication systems[J]. IEEE Wireless Communications Letters, 2020, 9(5): 745–749. doi: 10.1109/LWC.2020.2969167. [12] HUANG Chongwen, MO Ronghong, and YUEN C. Reconfigurable intelligent surface assisted multiuser MISO systems exploiting deep reinforcement learning[J]. IEEE Journal on Selected Areas in Communications, 2020, 38(8): 1839–1850. doi: 10.1109/JSAC.2020.3000835. [13] YANG Helin, XIONG Zehui, ZHAO Jun, et al. Deep reinforcement learning-based intelligent reflecting surface for secure wireless communications[J]. IEEE Transactions on Wireless Communications, 2021, 20(1): 375–388. doi: 10.1109/TWC.2020.3024860. [14] ZHONG Canwei, CUI Miao, ZHANG Guangchi, et al. Deep reinforcement learning-based optimization for IRS-assisted cognitive radio systems[J]. IEEE Transactions on Communications, 2022, 70(6): 3849–3864. doi: 10.1109/TCOMM.2022.3171837. [15] GUO Jianxin, WANG Zhe, LI Jun, et al. Deep reinforcement learning based resource allocation for intelligent reflecting surface assisted dynamic spectrum sharing[C]. 2022 14th International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 2022: 1178–1183. doi: 10.1109/WCSP55476.2022.10039119. [16] LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[C]. 4th International Conference on Learning Representations, San Juan, Puerto Rico, 2016. [17] WEI Yi, ZHAO Mingmin, ZHAO Minjian, et al. Channel estimation for IRS-aided multiuser communications with reduced error propagation[J]. IEEE Transactions on Wireless Communications, 2022, 21(4): 2725–2741. doi: 10.1109/TWC.2021.3115161. [18] HAN Yu, TANG Wankai, JIN Shi, et al. Large intelligent surface-assisted wireless communication exploiting statistical CSI[J]. IEEE Transactions on Vehicular Technology, 2019, 68(8): 8238–8242. doi: 10.1109/TVT.2019.2923997. -


 下载:
下载:




图(10) / 表(3)
计量
- 文章访问数: 885
- HTML全文浏览量: 468
- PDF下载量: 92
- 被引次数: 0
