

Radar Target Detection Aided by Log-Normal Texture Range Correlation in Sea Clutter
-
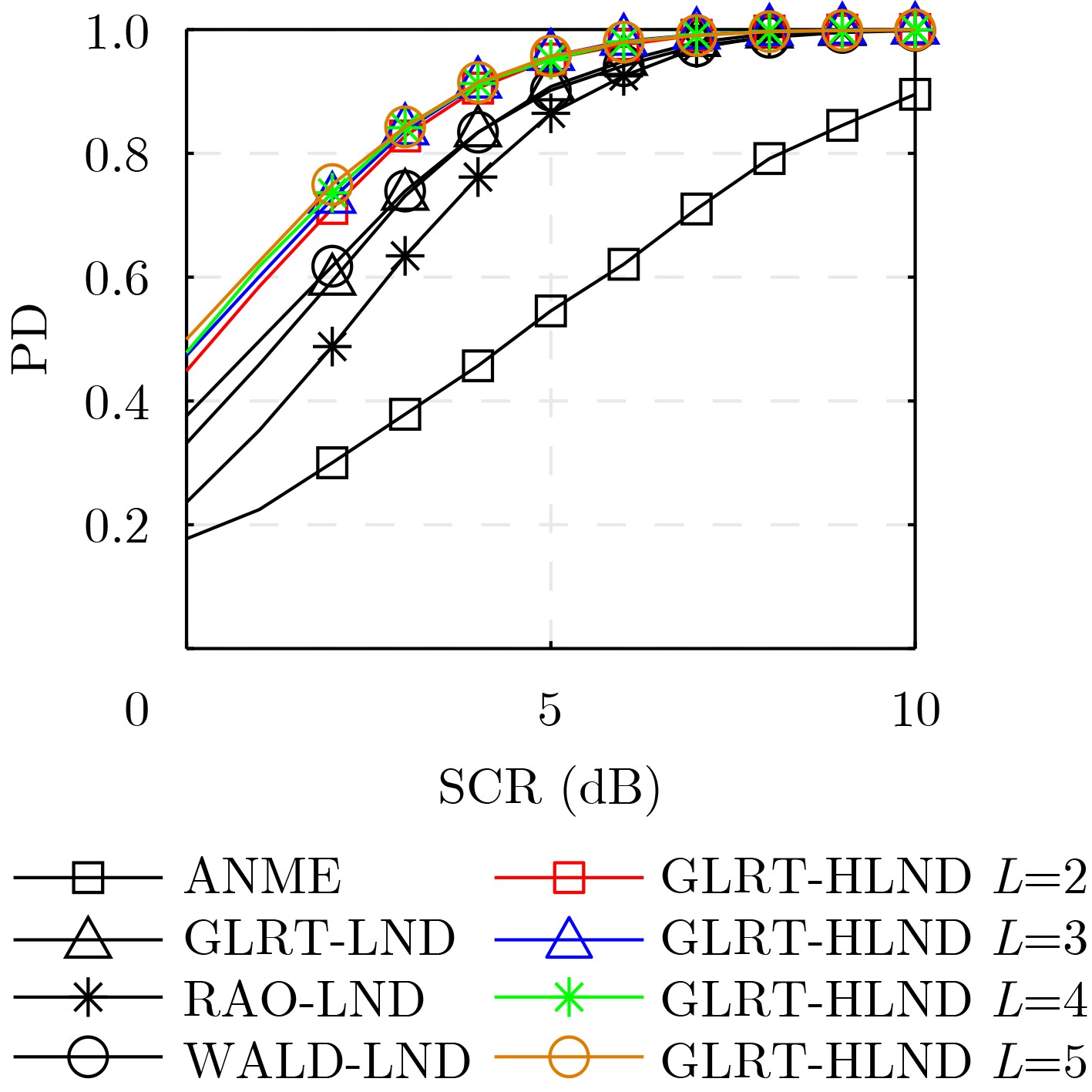
摘要: 传统的海杂波背景雷达目标自适应检测器通常假设杂波纹理在距离维上独立同分布,忽略了纹理在距离维的相关性信息。为了改善纹理距离相关海杂波环境下雷达目标自适应检测性能,该文首先将复合高斯海杂波的纹理分量建模为对数正态随机变量,然后基于广义似然比检验提出一种基于均匀对数正态纹理的广义似然比检测器。提出的雷达目标自适应检测器融合了纹理的先验分布知识及其在距离维的相关性信息。仿真和所用实测数据表明,与已有检测方法相比,所提方法对纹理距离相关海杂波背景下的雷达目标具有更高的检测概率。Abstract: The traditional radar adaptive target detectors in sea clutter usually assumes that the clutter texture is independent and identically distributed in the range dimension, ignoring the correlation information of the texture in the range dimension. In order to improve the adaptive detection performance of radar targets in sea clutter with texture range correlation, the texture component of compound Gaussian sea clutter is modeled as a lognormal random variable, and then a generalized likelihood ratio test with homogeneous lognormal texture detector is proposed based on the generalized likelihood ratio test. The proposed detector uses the prior distribution of texture and the correlated information of texture range. The simulation and the measured data beging used show that the detection probability of this detector for radar targets in compound Gaussian sea clutter with texture range correlation is higher than that of the existing detectors.
-
Key words:
- Radar target detection /
- Sea clutter /
- Log-normal texture /
- Range correlation
-
[1] SHUI Penglang, LIU Ming, and XU Shuwen. Shape-parameter-dependent coherent radar target detection in K-distributed clutter[J]. IEEE Transactions on Aerospace and Electronic Systems, 2016, 52(1): 451–465. doi: 10.1109/TAES.2015.140109. [2] SHI Sainan and SHUI Penglang. Optimum coherent detection in homogenous K-distributed clutter[J]. IET Radar, Sonar & Navigation, 2016, 10(8): 1477–1484. doi: 10.1049/iet-rsn.2015.0602. [3] 于涵, 水鹏朗, 施赛楠, 等. 复合高斯海杂波模型下最优相干检测进展[J]. 科技导报, 2017, 35(20): 109–118. doi: 10.3981/j.issn.1000-7857.2017.20.012.YU Han, SHUI Penglang, SHI Sainan, et al. Development of optimum coherent detection in compound-Gaussian sea clutter models[J]. Science & Technology Review, 2017, 35(20): 109–118. doi: 10.3981/j.issn.1000-7857.2017.20.012. [4] 石星宇, 许述文, 王晓峰, 等. 复合高斯杂波下距离扩展目标斜对称自适应子空间检测器[J]. 信号处理, 2023, 39(6): 1036–1046. doi: 10.16798/j.issn.1003-0530.2023.06.009.SHI Xingyu, XU Shuwen, WANG Xiaofeng, et al. Persymmetric adaptive subspace detectors for range-spread targets in compound-Gaussian clutter[J]. Journal of Signal Processing, 2023, 39(6): 1036–1046. doi: 10.16798/j.issn.1003-0530.2023.06.009. [5] 薛健, 朱圆玲, 潘美艳, 等. 基于Wald检验的海面雷达目标贝叶斯检测方法[J]. 西安邮电大学学报, 2023, 27(3): 30–38. doi: 10.13682/j.issn.2095-6533.2022.03.005.XUE Jian, ZHU Yuanling, PAN Meiyan, et al. Wald-based Bayesian detection for sea marine targets[J]. Journal of Xi’an University of Posts and Telecommunications, 2023, 27(3): 30–38. doi: 10.13682/j.issn.2095-6533.2022.03.005. [6] XUE Jian, MA Manshan, LIU Jun, et al. Wald-and Rao-based detection for maritime radar targets in sea clutter with lognormal texture[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5119709. doi: 10.1109/TGRS.2022.3217615. [7] WARD K D. Compound representation of high resolution sea clutter[J]. Electronics Letters, 1981, 17(16): 561–563. doi: 10.1049/el:19810394. [8] JAKEMAN E and PUSEY P. A model for non-Rayleigh sea echo[J]. IEEE Transactions on Antennas and Propagation, 1976, 24(6): 806–814. doi: 10.1109/TAP.1976.1141451. [9] YU Han, SHUI Penglang, and LU Kai. Outlier-robust tri-percentile parameter estimation of K-distributions[J]. Signal Processing, 2021, 181: 107906. doi: 10.1016/j.sigpro.2020.107906. [10] 于涵, 水鹏朗, 施赛楠, 等. 广义Pareto分布海杂波模型参数的组合双分位点估计方法[J]. 电子与信息学报, 2019, 41(12): 2836–2843. doi: 10.11999/JEIT190148.YU Han, SHUI Penglang, SHI Sainan, et al. Combined bipercentile parameter estimation of generalized pareto distributed sea clutter model[J]. Journal of Electronics & Information Technology, 2019, 41(12): 2836–2843. doi: 10.11999/JEIT190148. [11] SHUI Penglang, YU Han, SHI Lixiang, et al. Explicit bipercentile parameter estimation of compound‐Gaussian clutter with inverse gamma distributed texture[J]. IET Radar, Sonar & Navigation, 2018, 12(2): 202–208. doi: 10.1049/iet-rsn.2017.0174. [12] 水鹏朗, 田超, 封天. 逆高斯纹理复合高斯杂波对异常样本稳健的三分位点估计方法[J]. 电子与信息学报, 2023, 45(2): 542–549. doi: 10.11999/JEIT211483.SHUI Penglang, TIAN Chao, and FENG Tian. Outlier-robust tri-percentile parameter estimation method of compound-Gaussian clutter with inverse Gaussian textures[J]. Journal of Electronics & Information Technology, 2023, 45(2): 542–549. doi: 10.11999/JEIT211483. [13] LIU Weijian, LIU Jun, LIU Tao, et al. Detector design and performance analysis for target detection in subspace interference[J]. IEEE Signal Processing Letters, 2023, 30: 618–622. doi: 10.1109/LSP.2023.3270080. [14] LIU Weijian, LIU Jun, HAO Chengpeng, et al. Multichannel adaptive signal detection: Basic theory and literature review[J]. Science China Information Sciences, 2022, 65(2): 121301. doi: 10.1007/s11432-020-3211-8. [15] JAY E, OVARLEZ J P, DECLERCQ D, et al. BORD: Bayesian optimum radar detector[J]. Signal Processing, 2003, 83(6): 1151–1162. doi: 10.1016/S0165-1684(03)00034-3. [16] SANGSTON K J, GINI F, and GRECO M S. Coherent radar target detection in heavy-tailed compound-gaussian clutter[J]. IEEE Transactions on Aerospace and Electronic Systems, 2012, 48(1): 64–77. doi: 10.1109/TAES.2012.6129621. [17] CHEN Sijia, KONG Lingjiang, and YANG Jianyu. Adaptive detection in compound-Gaussian clutter with inverse Gaussian texture[J]. Progress in Electromagnetics Research M, 2013, 28: 157–167. doi: 10.2528/PIERM12121209. [18] XUE Jian, XU Shuwen, and SHUI Penglang. Near-optimum coherent CFAR detection of radar targets in compound-Gaussian clutter with inverse Gaussian texture[J]. Signal Processing, 2020, 166: 107236. doi: 10.1016/j.sigpro.2019.07.029. [19] 施赛楠, 水鹏朗, 刘明. 基于复合高斯杂波纹理结构的相干检测[J]. 电子与信息学报, 2016, 38(8): 1969–1976. doi: 10.11999/JEIT151194.SHI Sainan, SHUI Penglang, and LIU Ming. Coherent detection based on texture structure in compound-gaussian clutter[J]. Journal of Electronics & Information Technology, 2016, 38(8): 1969–1976. doi: 10.11999/JEIT151194. [20] 施赛楠, 水鹏朗, 杨春娇, 等. 基于逆高斯纹理空间相关性的雷达目标检测[J]. 系统工程与电子技术, 2017, 39(10): 2215–2220. doi: 10.3969/j.issn.1001-506X.2017.10.09.SHI Sainan, SHUI Penglang, YANG Chunjiao, et al. Radar target detection based on spatial correlation of inverse-Gaussian texture[J]. Systems Engineering and Electronics, 2017, 39(10): 2215–2220. doi: 10.3969/j.issn.1001-506X.2017.10.09. [21] BARNARD T J and WEINER D D. Non-Gaussian clutter modeling with generalized spherically invariant random vectors[J]. IEEE Transactions on Signal Processing, 1996, 44(10): 2384–2390. doi: 10.1109/78.539023. [22] FENG Tian and SHUI Penglang. Outlier-robust tri-percentile parameter estimation of compound-Gaussian clutter with lognormal distributed texture[J]. Digital Signal Processing, 2022, 120: 103307. doi: 10.1016/j.dsp.2021.103307. [23] GINI F and GRECO M. Covariance matrix estimation for CFAR detection in correlated heavy tailed clutter[J]. Signal Processing, 2002, 82(12): 1847–1859. doi: 10.1016/S0165-1684(02)00315-8. [24] CONTE E, LOPS M, and RICCI G. Asymptotically optimum radar detection in compound-Gaussian clutter[J]. IEEE Transactions on Aerospace and Electronic Systems, 1995, 31(2): 617–625. doi: 10.1109/7.381910. [25] 关键, 丁昊, 黄勇, 等. 实测海杂波数据空间相关性研究[J]. 电波科学学报, 2012, 27(5): 943–953. doi: 10.13443/j.cjors.2012.05.026.GUAN Jian, DING Hao, HUANG Yong, et al. Spatial correlation property with measured sea clutter data[J]. Chinese Journal of Radio Science, 2012, 27(5): 943–953. doi: 10.13443/j.cjors.2012.05.026. -

 下载:
下载:







图(6)
计量
- 文章访问数: 773
- HTML全文浏览量: 387
- PDF下载量: 76
- 被引次数: 0
