

Multitask Collaborative Multi-modal Remote Sensing Target Segmentation Algorithm
-
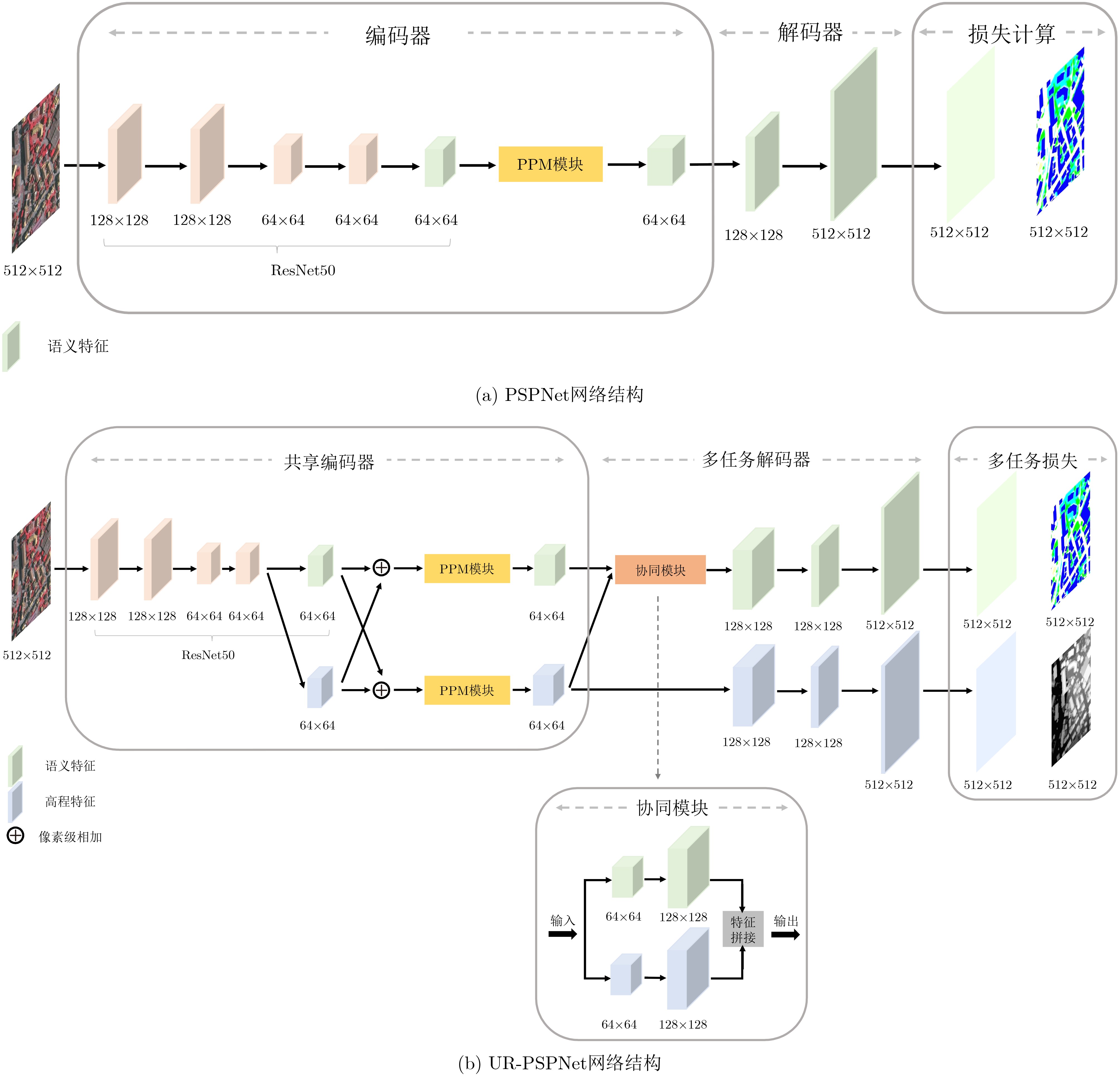
摘要: 利用语义分割技术提取的高分辨率遥感影像目标分割具有重要的应用前景。随着多传感器技术的飞速发展,多模态遥感影像间良好的优势互补性受到广泛关注,对其联合分析成为研究热点。该文同时分析光学遥感影像和高程数据,并针对现实场景中完全配准的高程数据不足导致两类数据融合分类精度不足的问题,提出一种基于多模态遥感数据的多任务协同模型(UR-PSPNet),该模型提取光学图像的深层特征,预测语义标签和高程值,并将高程数据作为监督信息嵌入,以提升目标分割的准确性。该文设计了基于ISPRS的对比实验,证明了该算法可以更好地融合多模态数据特征,提升了光学遥感影像目标分割的精度。Abstract: The use of semantic segmentation technology to extract high-resolution remote sensing image object segmentation has important application prospects. With the rapid development of multi-sensor technology, the good complementary advantages between multimodal remote sensing images have received widespread attention, and joint analysis of them has become a research hotspot. This article analyzes both optical remote sensing images and elevation data, and proposes a multi-task collaborative model based on multimodal remote sensing data (United Refined PSPNet, UR-PSPNet) to address the issue of insufficient fusion classification accuracy of the two types of data due to insufficient fully registered elevation data in real scenarios. This model extracts deep features of optical images, predicts semantic labels and elevation values, and embeds elevation data as supervised information, to improve the accuracy of target segmentation. This article designs a comparative experiment based on ISPRS, which proves that this algorithm can better fuse multimodal data features and improve the accuracy of object segmentation in optical remote sensing images.
-
Key words:
- Semantic segmentation /
- Remote sensing images /
- Multi-modal data /
- Deep learning /
- Elevation estimation
-
表 2 编码器具体网络结构及参数
模块 网络层 类型 核尺寸 输出图像尺寸 修改的ResNet50
主干网模块Conv1 卷积层×3 –,– 128×128 Block1 残差块×3 –,– 128×128 Block2 残差块×4 –,– 64×64 Block3 残差块×6 –,– 64×64 语义分支1 卷积层×2 3*3,256
3*3,664×64 语义上采样1 双线性插值 –,6 512×512 高程分支1 卷积层×2 3*3,256
3*3,164×64 高程上采样1 双线性插值 –,1 512×512 语义Block4 残差块×3 –,– 64×64 高程Block4 残差块×3 –,– 64×64 PPM模块 相加1 相加层 –,2048 64×64 语义分支2_1 全局平均池化 –,512 64×64 语义分支2_2 卷积层 1*1,512 64×64 语义拼接1 通道拼接层 –,2048 64×64 高程分支2_1 全局平均池化 –,512 64×64 高程分支2_2 卷积层 1*1,512 64×64 高程拼接1 通道拼接层 –,2048 64×64  下载: 导出CSV
下载: 导出CSV
表 3 解码器具体网络结构及参数
模块 网络层 类型 核尺寸 输出图像尺寸 协同模块 高程分支3 卷积层 1*1,2048 64×64 高程上采样2 双线性插值 –,2048 128×128 语义分支3 卷积层 1*1,2048 64×64 语义上采样2 双线性插值 –,2048 128×128 拼接1 通道拼接层 –, 4096 128×128 解码器其他部分 语义分支4_1 卷积层 3*3,512 128×128 语义分支4_2 卷积层 1×1,6 128×128 高程分支4_1 卷积层 3*3,512 128×128 高程分支4_2 卷积层 1*1,1 128×128 高程上采样3 双线性插值 –,6 512×512 语义上采样3 双线性插值 –,1 512×512
下载: 导出CSV
-
[1] 李树涛, 李聪妤, 康旭东. 多源遥感图像融合发展现状与未来展望[J]. 遥感学报, 2021, 25(1): 148–166. doi: 10.11834/jrs.20210259.LI Shutao, LI Congyu, and KANG Xudong. Development status and future prospects of multi-source remote sensing image fusion[J]. National Remote Sensing Bulletin, 2021, 25(1): 148–166. doi: 10.11834/jrs.20210259. [2] QIN Rongjun and FANG Wei. A hierarchical building detection method for very high resolution remotely sensed images combined with DSM using graph cut optimization[J]. Photogrammetric Engineering & Remote Sensing, 2014, 80(9): 873–883. doi: 10.14358/PERS.80.9.873. [3] LONG J, SHELHAMER E, and DARRELL T. Fully convolutional networks for semantic segmentation[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 3431–3440. doi: 10.1109/CVPR.2015.7298965. [4] ZHAO Hengshuang, SHI Jianping, QI Xiaojuan, et al. Pyramid scene parsing network[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 6230–6239. doi: 10.1109/CVPR.2017.660. [5] MOU Lichao and ZHU Xiaoxiang. IM2HEIGHT: Height estimation from single monocular imagery via fully residual convolutional-deconvolutional network[J]. 2018. doi: 10.48550/arXiv.1802.10249. [6] GHAMISI P and YOKOYA N. IMG2DSM: Height simulation from single imagery using conditional generative adversarial net[J]. IEEE Geoscience and Remote Sensing Letters, 2018, 15(5): 794–798. doi: 10.1109/LGRS.2018.2806945. [7] YUAN Min, REN Dingbang, FENG Qisheng, et al. MCAFNet: A multiscale channel attention fusion network for semantic segmentation of remote sensing images[J]. Remote Sensing, 2023, 15(2): 361. doi: 10.3390/rs15020361. [8] WENG Liguo, PANG Kai, XIA Min, et al. Sgformer: A local and global features coupling network for semantic segmentation of land cover[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2023, 16: 6812–6824. doi: 10.1109/JSTARS.2023.3295729. [9] HAO Xuejie, YIN Lizeyan, LI Xiuhong, et al. A multi-objective semantic segmentation algorithm based on improved U-Net networks[J]. Remote Sensing, 2023, 15(7): 1838. doi: 10.3390/rs15071838. [10] LV Ning, ZHANG Zenghui, LI Cong, et al. A hybrid-attention semantic segmentation network for remote sensing interpretation in land-use surveillance[J]. International Journal of Machine Learning and Cybernetics, 2023, 14(2): 395–406. doi: 10.1007/s13042-022-01517-7. [11] ZHANG Jiaming, LIU Ruiping, SHI Hao, et al. Delivering arbitrary-modal semantic segmentation[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 1136–1147. doi: 10.1109/CVPR52729.2023.00116. [12] ROTTENSTEINER F, SOHN G, JUNG J, et al. The ISPRS benchmark on urban object classification and 3D building reconstruction[J]. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2012, 1(1): 293–298. doi: 10.5194/isprsannals-I-3-293-2012. [13] CARVALHO M, LE SAUX B, TROUVÉ-PELOUX P, et al. Multitask learning of height and semantics from aerial images[J]. IEEE Geoscience and Remote Sensing Letters, 2020, 17(8): 1391–1395. doi: 10.1109/LGRS.2019.2947783. [14] WANG Yufeng, DING Wenrui, ZHANG Ruiqian, et al. Boundary-aware multitask learning for remote sensing imagery[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14: 951–963. doi: 10.1109/JSTARS.2020.3043442. [15] HE Qibin, SUN Xian, DIAO Wenhui, et al. Multimodal remote sensing image segmentation with intuition-inspired hypergraph modeling[J]. IEEE Transactions on Image Processing, 2023, 32: 1474–1487. doi: 10.1109/TIP.2023.3245324. -

 下载:
下载:





图(4) / 表(5)
计量
- 文章访问数: 1056
- HTML全文浏览量: 832
- PDF下载量: 71
- 被引次数: 0
