

Progress in The Application and Research of Approximate Computation Techniques Oriented to The Field of Digital Signal Processing
-
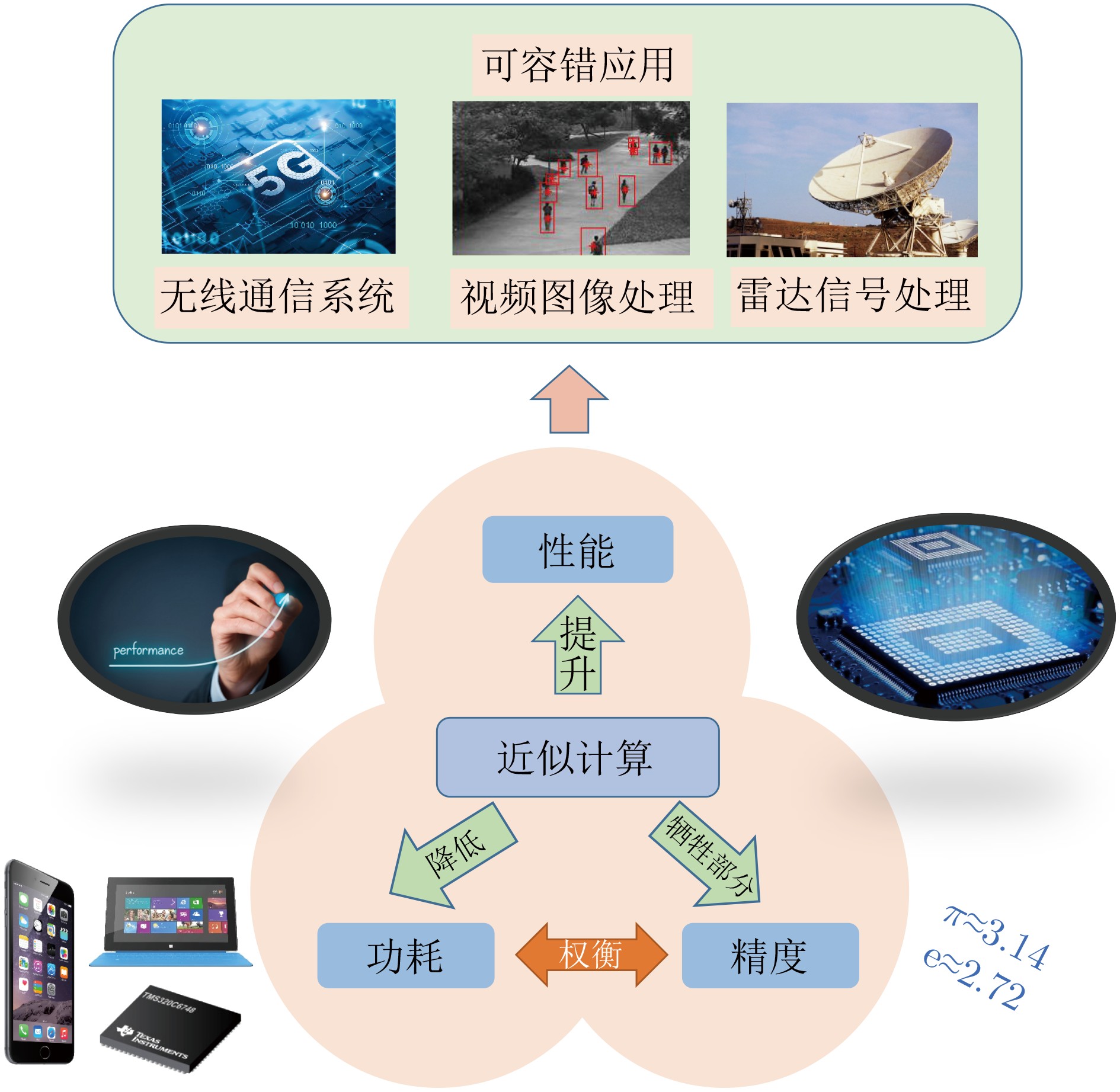
摘要: 在信号处理领域,近似计算技术备受关注。复杂算法和海量数据限制了应用的处理速度且增加了系统硬件消耗。由于信号具有冗余性,精确结果并非必需,满足用户可接受的结果已足够。因此,采用近似计算技术可以有效减少计算量,提高计算效率和系统性能。该文以近似计算技术的不同设计层次为切入,首先介绍了信号处理应用的特点,综述了近年来近似计算技术在算法和电路层面的研究进展,并调研了通信、视频图像以及雷达等信号处理方向的近似计算技术方案。最后,对该领域的发展方向进行了讨论和展望,为推动近似计算技术在信号处理领域的应用提供了思路。Abstract: In the field of signal processing, approximate computing techniques have garnered significant attention. Complex algorithms and massive data impose limitations on processing speed and increase system hardware consumption. Since signals often contain redundancy, precise results are not always necessary, and achieving results acceptable to users is sufficient. Therefore, employing approximate computing techniques can effectively reduce computational complexity, enhance computational efficiency, and improve system performance. This paper takes a hierarchical approach to the design of approximate computing techniques. It first introduces the characteristics of signal processing applications, reviews recent research progress in approximate computing techniques at the algorithm and circuit levels, and investigates approximate computing solutions in signal processing directions such as communication, video imaging, and radar. Finally, it discusses and prospects the development direction of this field, providing insights to promote the application of approximate computing techniques in signal processing.
-
表 1 加法器近似技术
 下载: 导出CSV
下载: 导出CSV
-
[1] LIU Weiqiang and LOMBARDI F. Approximate Computing[M]. Cham: Springer, 2022: 365–368. doi: 10.1007/978-3-030-98347-5. [2] LIU Weiqiang, LOMBARDI F, and SCHULTE M. Approximate computing: From circuits to applications[J]. Proceedings of the IEEE, 2020, 108(12): 2103–2107. doi: 10.1109/JPROC.2020.3033361. [3] CHIPPA V K, MOHAPATRA D, ROY K, et al. Scalable effort hardware design[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2014, 22(9): 2004–2016. doi: 10.1109/TVLSI.2013.2276759. [4] NOWICK S M. Design of a low-latency asynchronous adder using speculative completion[J]. IEE Proceedings - Computers and Digital Techniques, 1996, 143(5): 301–307. doi: 10.1049/ip-cdt:19960704. [5] LU S L. Speeding up processing with approximation circuits[J]. Computer, 2004, 37(3): 67–73. doi: 10.1109/MC.2004.1274006. [6] ESPOSITO D, DE CARO D, NAPOLI E, et al. Variable latency speculative Han-Carlson adder[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2015, 62(5): 1353–1361. doi: 10.1109/TCSI.2015.2403036. [7] SEOK H, SEO H, LEE J, et al. A novel efficient approximate adder design using single input pair based computation[C]. 2022 19th International SoC Design Conference (ISOCC), Gangneung-si, Korea, 2022: 57–58. doi: 10.1109/ISOCC56007.2022.10031341. [8] SEO H and KIM Y. A low latency approximate adder design based on dual sub-adders with error recovery[J]. IEEE Transactions on Emerging Topics in Computing, 2023, 11(3): 811–816. doi: 10.1109/TETC.2023.3270963. [9] MANOHAR P S, ROHAN B, RAMANA P V S, et al. Implementation of carry look Ahead adder with 2-bit approximate adder[C]. 2023 2nd International Conference on Applied Artificial Intelligence and Computing (ICAAIC), Salem, India, 2023: 1543–1547. doi: 10.1109/ICAAIC56838.2023.10140683. [10] YAN Aibin, WEI Shaojie, LI Zhixing, et al. Design of low-cost approximate CMOS full adders[C]. 2023 IEEE International Symposium on Circuits and Systems (ISCAS), Monterey, USA, 2023: 1–5. doi: 10.1109/ISCAS46773.2023.10181531. [11] LAGIDI P, ISWARYA A, RAJESH G, et al. Design of 16-bit and 32-bit approximate full adder using majority logic[C]. 2021 2nd Global Conference for Advancement in Technology (GCAT), Bangalore, India, 2021: 1–5. doi: 10.1109/GCAT52182.2021.9587782. [12] LIU Bo, XUE Anfeng, WANG Ziyu, et al. A reconfigurable approximate computing architecture with dual-VDD for low-power Binarized weight network deployment[J]. IEEE Transactions on Circuits and Systems II: Express Briefs, 2023, 70(1): 291–295. doi: 10.1109/TCSII.2022.3196045. [13] MITCHELL J N. Computer multiplication and division using binary logarithms[J]. IRE Transactions on Electronic Computers, 1962, EC-11(4): 512–517. doi: 10.1109/TEC.1962.5219391. [14] KIM M S, DEL BARRIO A A, OLIVEIRA L T, et al. Efficient Mitchell's approximate log multipliers for convolutional neural networks[J]. IEEE Transactions on Computers, 2019, 68(5): 660–675. doi: 10.1109/TC.2018.2880742. [15] NUNZIATA I, ZACHARELOS E, SAGGESE G, et al. Approximate recursive multipliers using carry truncation and error compensation[C]. 2022 17th Conference on Ph. D. Research in Microelectronics and Electronics (PRIME), Villasimius, Italy, 2022: 137–140. doi: 10.1109/PRIME55000.2022.9816787. [16] WARIS H, WANG Chenghua, LIU Weiqiang, et al. Hybrid partial product-based high-performance approximate recursive multipliers[J]. IEEE Transactions on Emerging Topics in Computing, 2022, 10(1): 507–513. doi: 10.1109/TETC.2020.3013977. [17] SHANKAR R G and ANANTHI D R. Approximate booth multipliers using compressors and counter[C]. 2023 International Conference on Inventive Computation Technologies (ICICT), Lalitpur, Nepal, 2023: 1658–1662. doi: 10.1109/ICICT57646.2023.10134198. [18] LIU Bo, CAI Hao, ZHANG Zilong, et al. Multiplication circuit architecture for error- tolerant CNN-based keywords speech recognition[J]. IEEE Design & Test, 2023, 40(3): 26–35. doi: 10.1109/MDAT.2021.3135346. [19] SAYADI L, TIMARCHI S, and SHEIKH-AKBARI A. Two efficient approximate unsigned multipliers by developing new configuration for approximate 4: 2 compressors[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2023, 70(4): 1649–1659. doi: 10.1109/TCSI.2023.3242558. [20] ZHANG Mingtao, NISHIZAWA S, and KIMURA S. Area efficient approximate 4-2 compressor and probability-based error adjustment for approximate multiplier[J]. IEEE Transactions on Circuits and Systems II: Express Briefs, 2023, 70(5): 1714–1718. doi: 10.1109/TCSII.2023.3257852. [21] XIE Na, ZHANG Renyuan, YAN Han, et al. Compressors evolution based high speed and energy efficient approximate signed multiplier[C]. 2022 IEEE 16th International Conference on Solid-State & Integrated Circuit Technology (ICSICT), Nanjing, China, 2022: 1–3. doi: 10.1109/ICSICT55466.2022.9963435. [22] TONG J Y F, NAGLE D, and RUTENBAR R A. Reducing power by optimizing the necessary precision/range of floating-point arithmetic[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2000, 8(3): 273–286. doi: 10.1109/92.845894. [23] EILERT J, EHLIAR A, and LIU Dake. Using low precision floating point numbers to reduce memory cost for MP3 decoding[C]. 2004 IEEE 6th Workshop on Multimedia Signal Processing, Siena, Italy, 2004: 119–122. doi: 10.1109/MMSP.2004.1436435. [24] ZHANG Hang, PUTIC M, and LACH J. Low power GPGPU computation with imprecise hardware[C]. 51st ACM/EDAC/IEEE Design Automation Conference (DAC), San Francisco, USA, 2014: 1–6. doi: 10.1109/dac.2014.6881426. [25] YIN Peipei, WANG Chenghua, LIU Weiqiang, et al. Design and performance evaluation of approximate floating-point multipliers[C]. 2016 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Pittsburgh, USA, 2016: 296–301. doi: 10.1109/ISVLSI.2016.15. [26] SAVIO M M D, DEEPA T, DHARSHINI P D, et al. Design and implementation of approximate divider for error-resilient image processing applications[C]. 2023 Second International Conference on Electrical, Electronics, Information and Communication Technologies (ICEEICT), Trichirappalli, India, 2023: 1–5. doi: 10.1109/ICEEICT56924.2023.10157050. [27] SHRIRAM A, TIWARI A, ANIL KUMAR U, et al. Power efficient approximate divider architecture for error resilient applications[C]. 2022 IEEE 6th Conference on Information and Communication Technology (CICT), Gwalior, India, 2022: 1–6. doi: 10.1109/CICT56698.2022.9997960. [28] WU Yong, JIANG Honglan, MA Zining, et al. An energy-efficient approximate divider based on logarithmic conversion and piecewise constant approximation[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2022, 69(7): 2655–2668. doi: 10.1109/TCSI.2022.3167894. [29] SAADAT H, JAVAID H, and PARAMESWARAN S. Approximate integer and floating-point dividers with near-zero error bias[C]. 2019 56th ACM/IEEE Design Automation Conference (DAC), Las Vegas, USA, 2019: 1–6. doi: 10.1145/3316781.3317773. [30] LIU Weiqiang, XU Tao, LI Jing, et al. Design of unsigned approximate hybrid dividers based on restoring array and logarithmic dividers[J]. IEEE Transactions on Emerging Topics in Computing, 2022, 10(1): 339–350. doi: 10.1109/TETC.2020.3022290. [31] WUERDIG R N, SARTORI M L L, ABREU B A, et al. Mitigating asynchronous QDI drawbacks on MAC operators with approximate multipliers[C]. 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin, USA, 2022: 1269–1273. doi: 10.1109/ISCAS48785.2022.9937420. [32] MISHRA V, PANDEY D, SINGH S, et al. ART-MAC: Approximate rounding and truncation based MAC unit for fault-tolerant applications[C]. 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin, USA, 2022: 1640–1644. doi: 10.1109/ISCAS48785.2022.9937437. [33] ESPOSITO D, DE CARO D, NAPOLI E, et al. On the use of approximate adders in carry-save multiplier-accumulators[C]. 2017 IEEE International Symposium on Circuits and Systems (ISCAS), Baltimore, USA, 2017: 1–4. doi: 10.1109/ISCAS.2017.8050437. [34] WANG Ziyu, WEI Qingwen, XUE Anfeng, et al. Low-power computing unit based on heterogeneous approximate structure for binary convolutional neural network[C]. 2022 IEEE 16th International Conference on Solid-State & Integrated Circuit Technology (ICSICT), Nanjing, China, 2022: 1–3. doi: 10.1109/ICSICT55466.2022.9963452. [35] MEO G D, SAGGESE G, STROLLO A G M, et al. Approximate MAC unit using static segmentation[J]. IEEE Transactions on Emerging Topics in Computing, 2023. doi: 10.1109/TETC.2023.3315301. [36] LIU Bo, ZHANG Zilong, CAI Hao, et al. Self-compensation tensor multiplication unit for adaptive approximate computing in low-power CNN processing[J]. Science China Information Sciences, 2022, 65(4): 149403. doi: 10.1007/s11432-021-3242-6. [37] LIU Bo, ZHANG Renyuan, SHEN Qiao, et al. W-AMA: Weight-aware approximate multiplication architecture for neural processing[J]. Computers and Electrical Engineering, 2023, 111: 108921. doi: 10.1016/j.compeleceng.2023.108921. [38] JIANG Honglan, LIU Leibo, JONKER P P, et al. A high-performance and energy-efficient FIR adaptive filter using approximate distributed arithmetic circuits[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2019, 66(1): 313–326. doi: 10.1109/TCSI.2018.2856513. [39] ESPOSITO D, DI MEO G, DE CARO D, et al. Quality-scalable approximate LMS filter[C]. 2018 25th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Bordeaux, France, 2018: 849–852. doi: 10.1109/ICECS.2018.8617858. [40] DI MEO G, DE CARO D, PETRA N, et al. A novel low-power DLMS adaptive filter with sign-magnitude learning and approximated FIR section[C]. 2022 17th Conference on Ph. D. Research in Microelectronics and Electronics (PRIME), Villasimius, Italy, 2022: 217–220. doi: 10.1109/PRIME55000.2022.9816770. [41] MONTEIRO M, SEIDEL I, GRELLERT M, et al. Exploring the impacts of multiple kernel sizes of Gaussian filters combined to approximate computing in canny edge detection[C]. 2022 IEEE 13th Latin America Symposium on Circuits and System (LASCAS), Puerto Varas, Chile, 2022: 1–4. doi: 10.1109/LASCAS53948.2022.9789080. [42] BERGLAND G. Fast Fourier transform hardware implementations-An overview[J]. IEEE Transactions on Audio and Electroacoustics, 1969, 17(2): 104–108. doi: 10.1109/TAU.1969.1162041. [43] ELANGO K and MUNIANDI K. VLSI implementation of an area and energy efficient FFT/IFFT core for MIMO-OFDM applications[J]. Annals of Telecommunications, 2020, 75(5/6): 215–227. doi: 10.1007/s12243-019-00742-6. [44] LIU Bo, DING Xiaoling, CAI Hao, et al. Precision adaptive MFCC based on R2SDF-FFT and approximate computing for low-power speech keywords recognition[J]. IEEE Circuits and Systems Magazine, 2021, 21(4): 24–39. doi: 10.1109/MCAS.2021.3118175. [45] LIU Weiqiang, LIAO Qicong, QIAO Fei, et al. Approximate designs for Fast Fourier Transform (FFT) with application to speech recognition[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2019, 66(12): 4727–4739. doi: 10.1109/TCSI.2019.2933321. [46] CHEN W H, SMITH C, and FRALICK S. A fast computational algorithm for the discrete cosine transform[J]. IEEE Transactions on Communications, 1977, 25(9): 1004–1009. doi: 10.1109/TCOM.1977.1093941. [47] POTLURI U S, MADANAYAKE A, CINTRA R J, et al. Improved 8-point approximate DCT for image and video compression requiring only 14 additions[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2014, 61(6): 1727–1740. doi: 10.1109/TCSI.2013.2295022. [48] DA SILVEIRA T L T, CANTERLE D R, COELHO D F G, et al. A class of low-complexity DCT-like transforms for image and video coding[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(7): 4364–4375. doi: 10.1109/TCSVT.2021.3134054. [49] XING Yan, ZHANG Ziji, QIAN Yiduan, et al. An energy-efficient approximate DCT for wireless capsule endoscopy application[C]. 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 2018: 1–4. doi: 10.1109/ISCAS.2018.8351769. [50] CAI Lulin, QIAN Yiduan, HE Yajuan, et al. Design of approximate multiplierless DCT with CSD encoding for image processing[C]. 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Korea, 2021: 1–4. doi: 10.1109/ISCAS51556.2021.9401200. [51] JANHUNEN J, PITKANEN T, SILVEN O, et al. Fixed- and floating-point processor comparison for MIMO-OFDM detector[J]. IEEE Journal of Selected Topics in Signal Processing, 2011, 5(8): 1588–1598. doi: 10.1109/JSTSP.2011.2165830. [52] AMIN-NEJAD S, BASHARKHAH K, and GASHTEROODKHANI T A. Floating point versus fixed point tradeoffs in FPGA implementations of QR decomposition algorithm[J]. European Journal of Electrical Engineering and Computer Science, 2019, 3(5). doi: 10.24018/EJECE.2019.3.5.127. [53] HU Yao and KOIBUCHI M. Accelerating MPI communication using floating-point compression on lossy interconnection networks[C]. 2021 IEEE 46th Conference on Local Computer Networks (LCN), Edmonton, Canada, 2021: 355–358. doi: 10.1109/LCN52139.2021.9524942. [54] PARK J, CHOI J H, and ROY K. Dynamic bit-width adaptation in DCT: An approach to trade off image quality and computation energy[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2010, 18(5): 787–793. doi: 10.1109/TVLSI.2009.2016839. [55] SNIGDHA F S, SENGUPTA D, HU Jiang, et al. Optimal design of JPEG hardware under the approximate computing paradigm[C]. 2016 53rd ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, USA, 2016: 1–6. doi: 10.1145/2897937.2898057. [56] PU Yu, DE GYVEZ J P, CORPORAAL H, et al. An ultra-low-energy multi-standard JPEG co-processor in 65 nm CMOS with sub/near threshold supply voltage[J]. IEEE Journal of Solid-State Circuits, 2010, 45(3): 668–680. doi: 10.1109/JSSC.2009.2039684. [57] FANG Jian, XU Zongben, ZHANG Bingchen, et al. Fast compressed sensing SAR imaging based on approximated observation[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2014, 7(1): 352–363. doi: 10.1109/JSTARS.2013.2263309. [58] JIANG Chenglong, ZHANG Bingchen, FANG Jian, et al. Efficient ℓ q regularisation algorithm with range-azimuth decoupled for SAR imaging[J]. Electronics Letters, 2014, 50(3): 204–205. doi: 10.1049/el.2013.1989. [59] LI Bo, LIU Falin, ZHOU Chongbin, et al. Mixed sparse representation for approximated observation-based compressed sensing radar imaging[J]. Journal of Applied Remote Sensing, 2018, 12(3): 035015. doi: 10.1117/1.JRS.12.035015. [60] LI Bo, LIU Falin, ZHOU Chongbin, et al. Phase error correction for approximated observation-based compressed sensing radar imaging[J]. Sensors, 2017, 17(3): 613. doi: 10.3390/s17030613. -

 下载:
下载:


图(1) / 表(4)
计量
- 文章访问数: 1286
- HTML全文浏览量: 1124
- PDF下载量: 125
- 被引次数: 0
