

Entropy-based Federated Incremental Learning and Optimization in Industrial Internet of Things
-
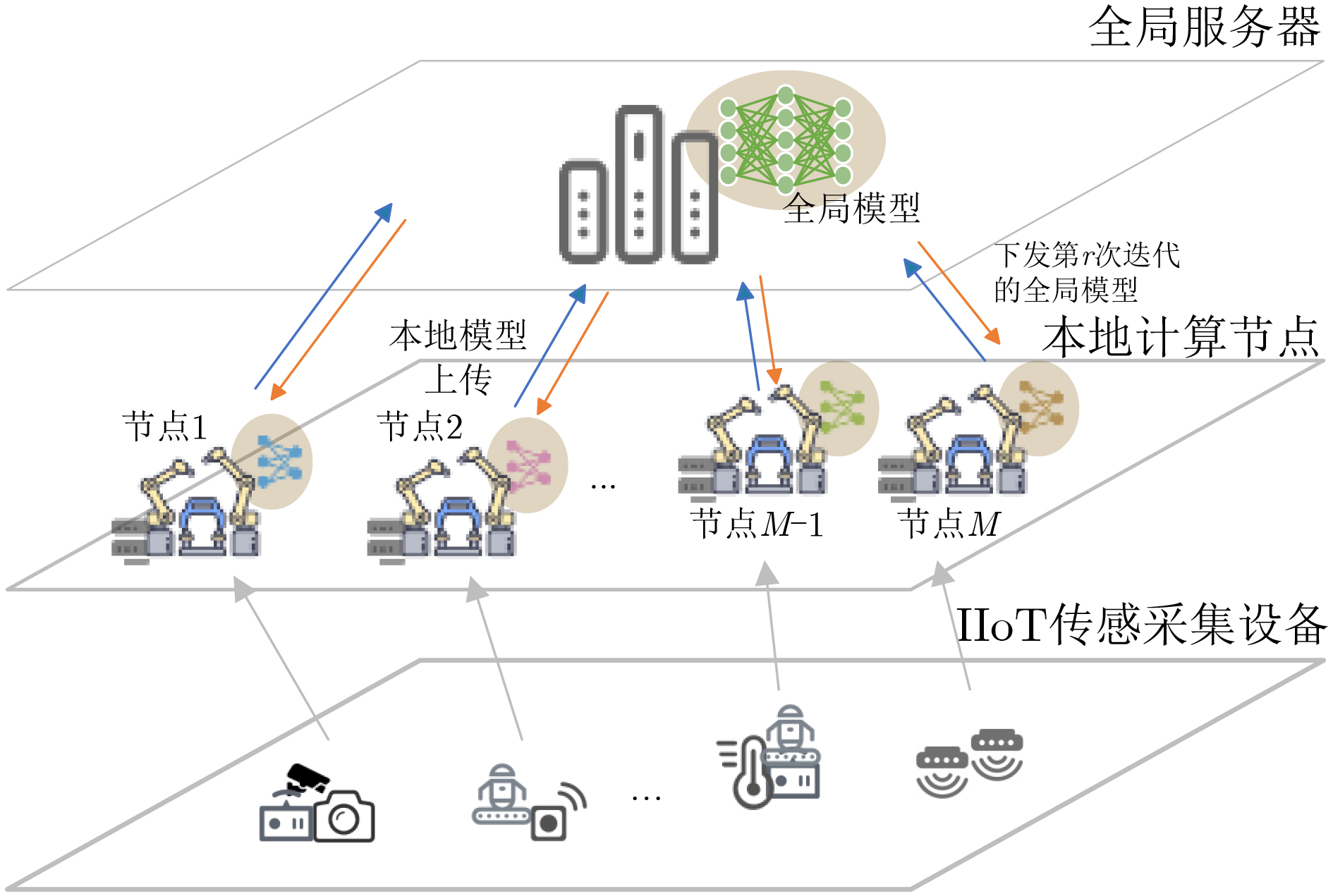
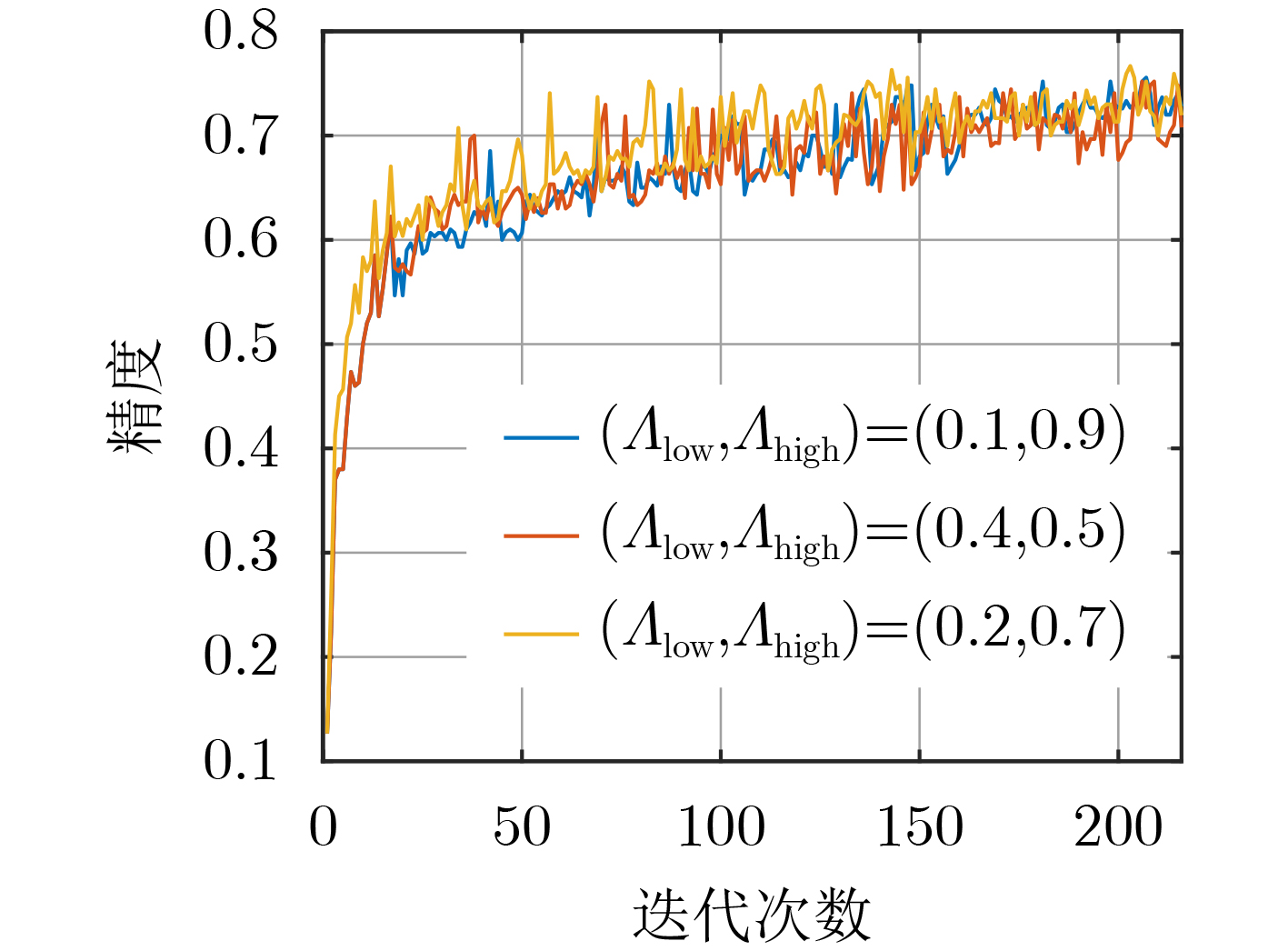
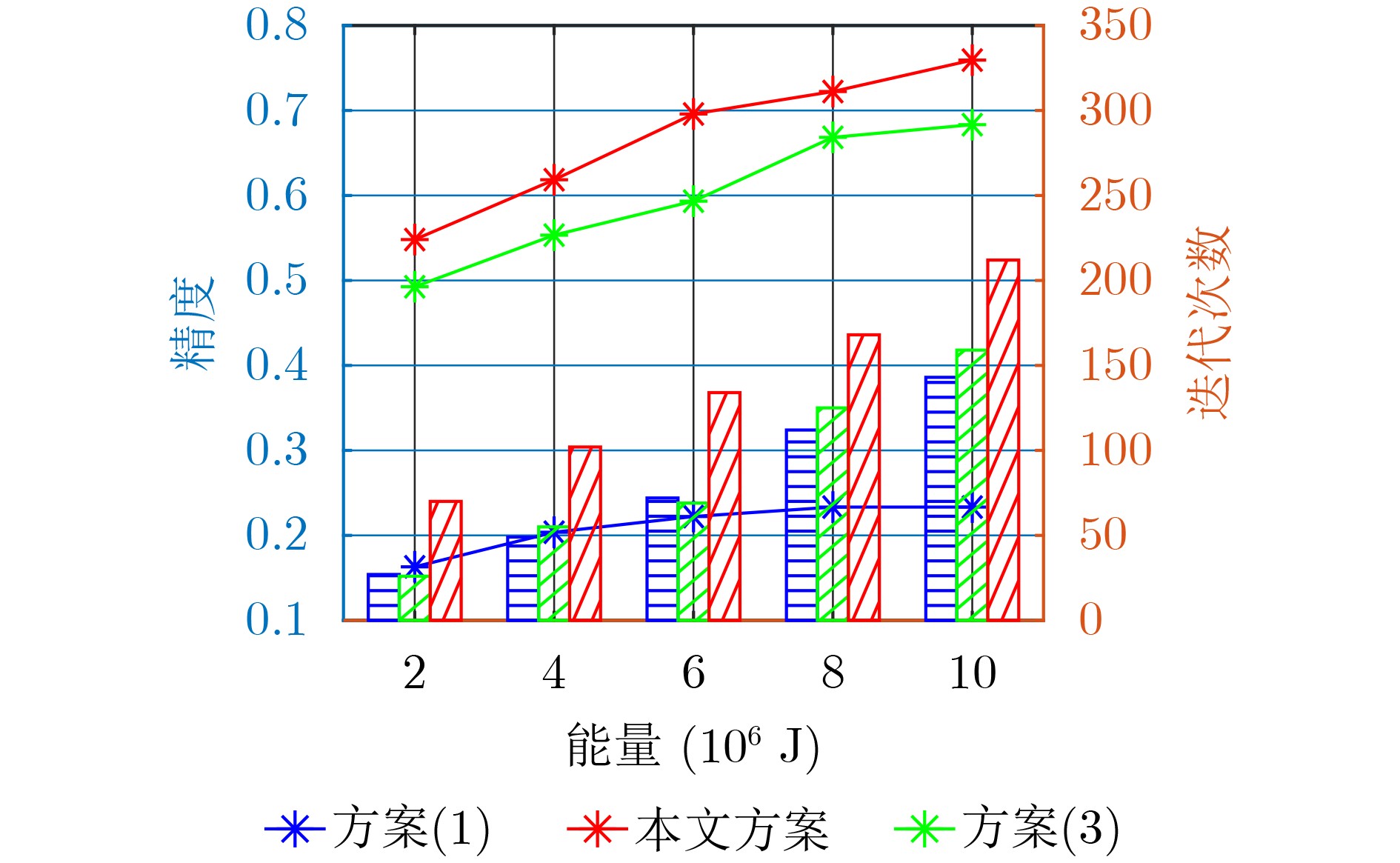
摘要: 面对工业生产过程中大规模、多样且随时间增长的数据和机器学习任务,该文提出一种基于信息熵的联邦增量学习(FIL)与优化方法。基于联邦框架,各本地计算节点可利用本地数据进行模型训练,并计算信息平均熵上传至服务器,以此辅助识别类增任务;全局服务器则根据本地反馈的平均熵选择参与当前轮次训练的本地节点,并判决任务是否产生增量后,进行全局模型下发与聚合更新。所提方法结合平均熵和阈值进行不同情况下的节点选择,实现低平均熵下的模型稳定学习和高平均熵下的模型增量式扩展。在此基础上,采用凸优化,在资源有限的情况下自适应地调整聚合频率和资源分配,最终实现模型的有效收敛。仿真结果表明,在不同的情景下,该文所提方法都可以加速模型收敛并提升训练精度。Abstract: In the face of large-scale, diverse, and time-evolving data, as well as machine learning tasks in industrial production processes, a Federated Incremental Learning(FIL) and optimization method based on information entropy is proposed in this paper. Within the federated framework, local computing nodes utilize local data for model training, and compute the average entropy to be transmitted to the server to assist in identifying class-incremental tasks. The global server then selects local nodes for current round training based on the locally provided average entropy and makes decisions on task incrementality, followed by global model deployment and aggregation updates. The proposed method combines average entropy and thresholds for nodes selection in various situations, achieving stable model learning under low average entropy and incremental model expansion under high average entropy. Additionally, convex optimization is employed to adaptively adjust aggregation frequency and resource allocation in resource-constrained scenarios, ultimately achieving effective model convergence. Simulation results demonstrate that the proposed method accelerates model convergence and enhances training accuracy in different scenarios.
-
表 1 符号描述
符号 描述 $ {\boldsymbol{\theta}} ^{r,t},{\boldsymbol{\theta}} _m^{\tau ,t} $ 全局模型及本地节点$m$处的局部模型 $ f_{\rm c}^{}( \cdot ),f_{{\mathrm{d}}}^{}( \cdot ) $ 模型训练损失与蒸馏损失 $ \mathcal{S}^r $ 第$ r $次迭代选择的节点集合 $M,N$ 节点总数与每轮选中节点数 $ \mathcal{H}_m^{r,t} $ 本地数据与模型间的信息熵 $ \mathcal{I}( \cdot ) $ 熵函数 $ {\varLambda _{{\mathrm{low}}}},{\varLambda _{{\mathrm{high}}}} $ 贪婪算法下节点选择的阈值 $\eta $ 学习率 $c^{\rm{loc}},c^{\rm{ent}}$ 本地节点训练任务负载 $c^{\rm{glo}}$ 全局聚合复杂度 $ t^*,E^* $ 模型迭代中的时延及能耗 $R^{\rm{glo}},R^{\rm{loc}}$ 全局及本地训练迭代次数 $f_m^{\rm{cmp}}$ 计算能力 $ \varphi ,\beta ,\delta $ 凸优化过程中理论存在的中间值 $ {\hat \varphi ^{r,t}} $,$ {\hat \beta ^{r,t}} $,${\hat \delta ^{r,t}}$ 凸优化过程中实测的中间值  下载: 导出CSV
下载: 导出CSV
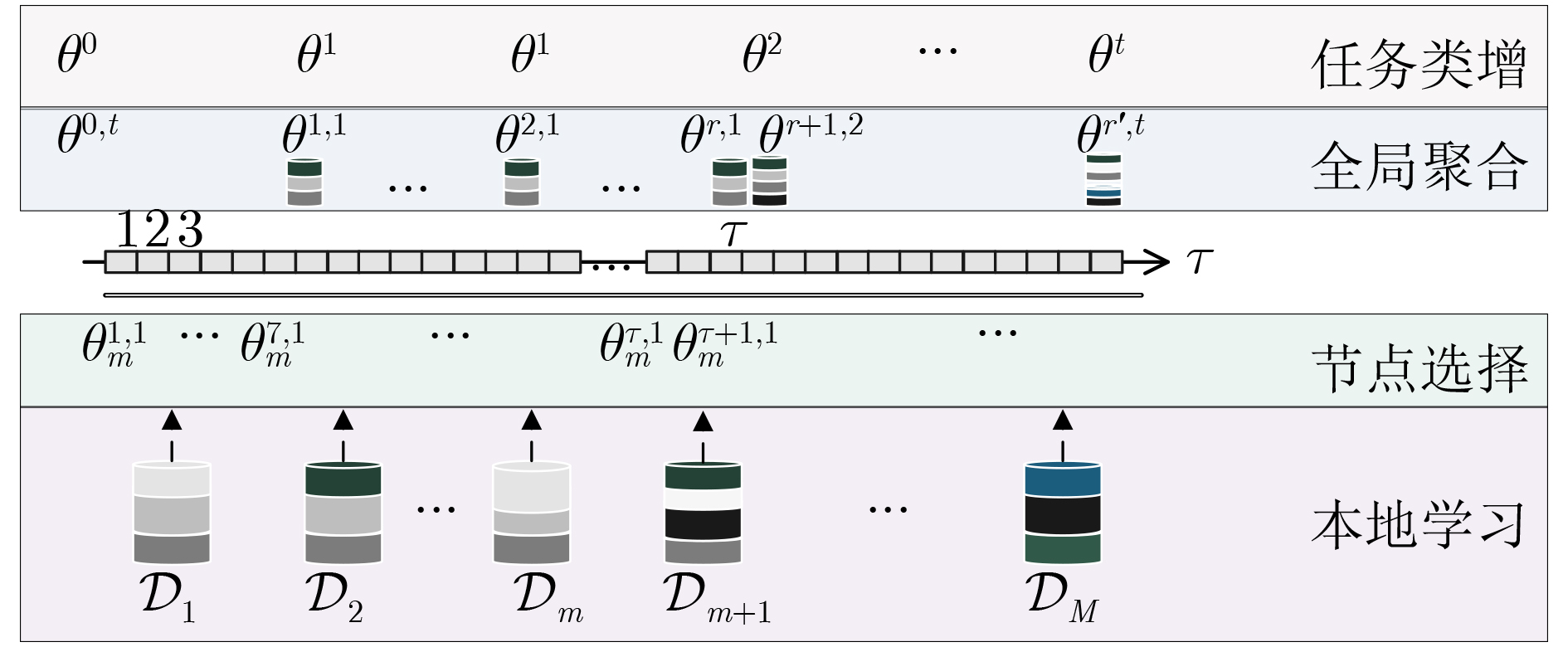
1 基于信息熵的节点选择
(1)输入:待选节点数$M$;输出:选中的节点集合${\mathcal{S}^r}$ (2)初始化选择系数${\varLambda _{\rm{low}}}$和${\varLambda _{\rm{high}}}$,开始轮次$\mathcal{E}$ (3)for $ r = 1,\; 2,\;\cdots ,\;{{\mathrm{epoch}}} $ (4) for $\forall m \in M$then利用式(6)计算$ \mathcal{H}_m^{r,t} $上传给CPU (5) $ \mathcal{H}^{r,t} = \{ \mathcal{H}_m^{r,t}\} $,随机获取${r_{\rm{and}}} \in (0,1)$ (6) if $r < \mathcal{E}$ and $ {r_{\rm{and}}} < {\varLambda _{\rm{low}}} $ (7) then 随机选择$ N $个节点为$\mathcal{S}$, go to (10) (8) if $ {\varLambda _{\rm{low}}} \le {r_{\rm{and}}} < {\varLambda _{\rm{high}}} $ then选$ \mathcal{H}_m^{r,t} $最小的$ N $个节点为${\mathcal{S}^r}$ (9) else:排序$ \mathcal{H}^{r,t} $,选$ \mathcal{H}_m^{r,t} $最大的$ N $个节点为${\mathcal{S}^r}$ (10) 被选节点$ s_{m*}^t = 1 $, $ q_{m*}^r = 1 $
下载: 导出CSV
2 优化模型求解
(1)初始化:$ {{\boldsymbol{\zeta}} ^{(0)}} $, $ v = 0 $ (2)if $ {{\boldsymbol{\zeta}} ^{(v)}} $为稳态解, then返回$ {{\boldsymbol{\zeta}} ^{(v)}} $ (3)$ \widehat{\boldsymbol{\zeta}}({\boldsymbol{\zeta}}^{(v)})\triangleq \mathrm{arg}\mathrm{min}\tilde{U}({\boldsymbol{\zeta}} ,{{\boldsymbol{\zeta}} }^{(v)}) $ (4)$ {\boldsymbol{\zeta}}^{(v+1)}={\boldsymbol{\zeta}}^{(v)}+{k}^{(v)}{(}\widehat{\boldsymbol{\zeta}}({\boldsymbol{\zeta}}^{(v)})-{\boldsymbol{\zeta}}^{(v)}) $ (5)$v \leftarrow v + 1$,转到(2)
下载: 导出CSV
表 2 参数说明
参数 定义 值 $ M $ 节点数量 [10, 200] $ E $ 总能量 [500, 1 000] J $t$ 总时间 [2 000, 20 000] s $ \left| {{\mathcal{D}_m}} \right| $ 节点$m$数据集大小 [120, 200] $ {c^{\rm{loc}}} $ 本地计算负荷 15 cycles $ {c^{\rm{glo}}} $ 全局计算负荷 25 cycles $ f_m^{\rm{cmp}} $ 节点$m$计算能力 [1, 10] GHz $ \psi /2 $ 节点计算芯片组的有效电容系数 $ {10^{ - 28}} $ $p_m^{\min },p_m^{\max }$ 设备节点功率约束 [0.2, 1] W
下载: 导出CSV
-
[1] BJORNSON E and SANGUINETTI L. Scalable cell-free massive MIMO systems[J]. IEEE Transactions on Communications, 2020, 68(7): 4247–4261. doi: 10.1109/tcomm.2020.2987311. [2] YU Wanke and ZHAO Chunhui. Broad convolutional neural network based industrial process fault diagnosis with incremental learning capability[J]. IEEE Transactions on Industrial Electronics, 2020, 67(6): 5081–5091. doi: 10.1109/tie.2019.2931255. [3] HUO Ru, ZENG Shiqin, WANG Zhihao, et al. A comprehensive survey on Blockchain in industrial internet of things: Motivations, research progresses, and future challenges[J]. IEEE Communications Surveys & Tutorials, 2022, 24(1): 88–122. doi: 10.1109/comst.2022.3141490. [4] SU Hang, QI Wen, HU Yingbai, et al. An incremental learning framework for human-like redundancy optimization of anthropomorphic manipulators[J]. IEEE Transactions on Industrial Informatics, 2022, 18(3): 1864–1872. doi: 10.1109/tii.2020.3036693. [5] KIRKPATRICK J, PASCANU R, RABINOWITZ N, et al. Overcoming catastrophic forgetting in neural networks[J]. Proceedings of the National Academy of Sciences of the United States of America, 2017, 114(13): 3521–3526. doi: 10.1073/pnas.1611835114. [6] SHOHAM N, AVIDOR T, KEREN A, et al. Overcoming forgetting in federated learning on non-IID data[J]. arXiv: 1910.07796, 2019. doi: 10.48550/arXiv.1910.07796. [7] LI Zhizhong and HOIEM D. Learning without forgetting[C]. The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 614–629. doi: 10.1007/978-3-319-46493-0_37. [8] DONG Jiahua, WANG Lixu, FANG Zhen, et al. Federated class-incremental learning[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, USA, 2022: 10154–10163. doi: 10.1109/cvpr52688.2022.00992. [9] MAZUR M, PUSTELNIK Ł, KNOP S, et al. Target layer regularization for continual learning using Cramer-Wold distance[J]. Information Sciences, 2022, 609: 1369–1380. doi: 10.1016/j.ins.2022.07.085. [10] REBUFFI S-A, KOLESNIKOV A, SPERL G, et al. iCaRL: Incremental classifier and representation learning[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, USA, 2017: 5533–5542. doi: 10.1109/cvpr.2017.587. [11] WANG Qiang, LIU Jiayi, JI Zhong, et al. Hierarchical correlations replay for continual learning[J]. Knowledge-Based Systems, 2022, 250: 109052. doi: 10.1016/j.knosys.2022.109052. [12] JI Zhong, LI Jin, WANG Qiang, et al. Complementary calibration: Boosting general continual learning with collaborative distillation and self-supervision[J]. IEEE Transactions on Image Processing, 2023, 32: 657–667. doi: 10.1109/tip.2022.3230457. [13] HAO Meng, LI Hongwei, LUO Xizhao, et al. Efficient and privacy-enhanced federated learning for industrial artificial intelligence[J]. IEEE Transactions on Industrial Informatics, 2020, 16(10): 6532–6542. doi: 10.1109/tii.2019.2945367. [14] CHEN Zhixiong, YI Wenqiang, DENG Yansha, et al. Device scheduling for wireless federated learning with latency and representativity[C]. 2022 International Conference on Electrical, Computer, Communications and Mechatronics Engineering (ICECCME), Maldives, Maldives, 2022: 1–6. doi: 10.1109/iceccme55909.2022.9988590. [15] YANG Zhaohui, CHEN Mingzhe, SAAD W, et al. Energy efficient federated learning over wireless communication networks[J]. IEEE Transactions on Wireless Communications, 2021, 20(3): 1935–1949. doi: 10.1109/twc.2020.3037554. [16] DINH C T, TRAN N H, NGUYEN M N H, et al. Federated learning over wireless networks: Convergence analysis and resource allocation[J]. IEEE/ACM Transactions on Networking, 2021, 29(1): 398–409. doi: 10.1109/tnet.2020.3035770. [17] JING Shusen and XIAO Chengshan. Federated learning via over-the-air computation with statistical channel state information[J]. IEEE Transactions on Wireless Communications, 2022, 21(11): 9351–9365. doi: 10.1109/twc.2022.3175887. [18] YANG Ruizhe. The adaptive distributed learning based on homomorphic encryption and blockchain[J]. High Technology Letters, 2022, 28(4): 337–344. doi: 10.3772/j.issn.1006-6748.2022.04.001. [19] ZHAO Rui, SONG Jinming, YUAN Yufeng, et al. Maximum entropy population-based training for zero-shot human-AI coordination[C]. The AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 6145–6153. doi: 10.1609/aaai.v37i5.25758. [20] ZHANG Peiying, WANG Chao, JIANG Chunxiao, et al. Deep reinforcement learning assisted federated learning algorithm for data management of IIoT[J]. IEEE Transactions on Industrial Informatics, 2021, 17(12): 8475–8484. doi: 10.1109/tii.2021.3064351. [21] WANG Shiqiang, TUOR T, SALONIDIS T, et al. Adaptive federated learning in resource constrained edge computing systems[J]. IEEE Journal on Selected Areas in Communications, 2019, 37(6): 1205–1221. doi: 10.1109/jsac.2019.2904348. [22] KRIZHEVSKY A and HINTON G. Learning multiple layers of features from tiny images[J]. Handbook of Systemic Autoimmune Diseases, 2009, 1(4). [23] SHAFIQ M and GU Zhaoquan. Deep residual learning for image recognition: A survey[J]. Applied Sciences, 2022, 12(18): 8972. doi: 10.3390/app12188972. [24] MINAEE S, KALCHBRENNER N, CAMBRIA E, et al. Deep learning-based text classification: A comprehensive review[J]. ACM Computing Surveys, 2022, 54(3): 62. doi: 10.1145/3439726. -

 下载:
下载:




图(6) / 表(4)
计量
- 文章访问数: 817
- HTML全文浏览量: 678
- PDF下载量: 68
- 被引次数: 0
