

Low-power Communication and Control Joint Optimization for Service Continuity Assurance in Aerial-Ground Integrated Networks
-
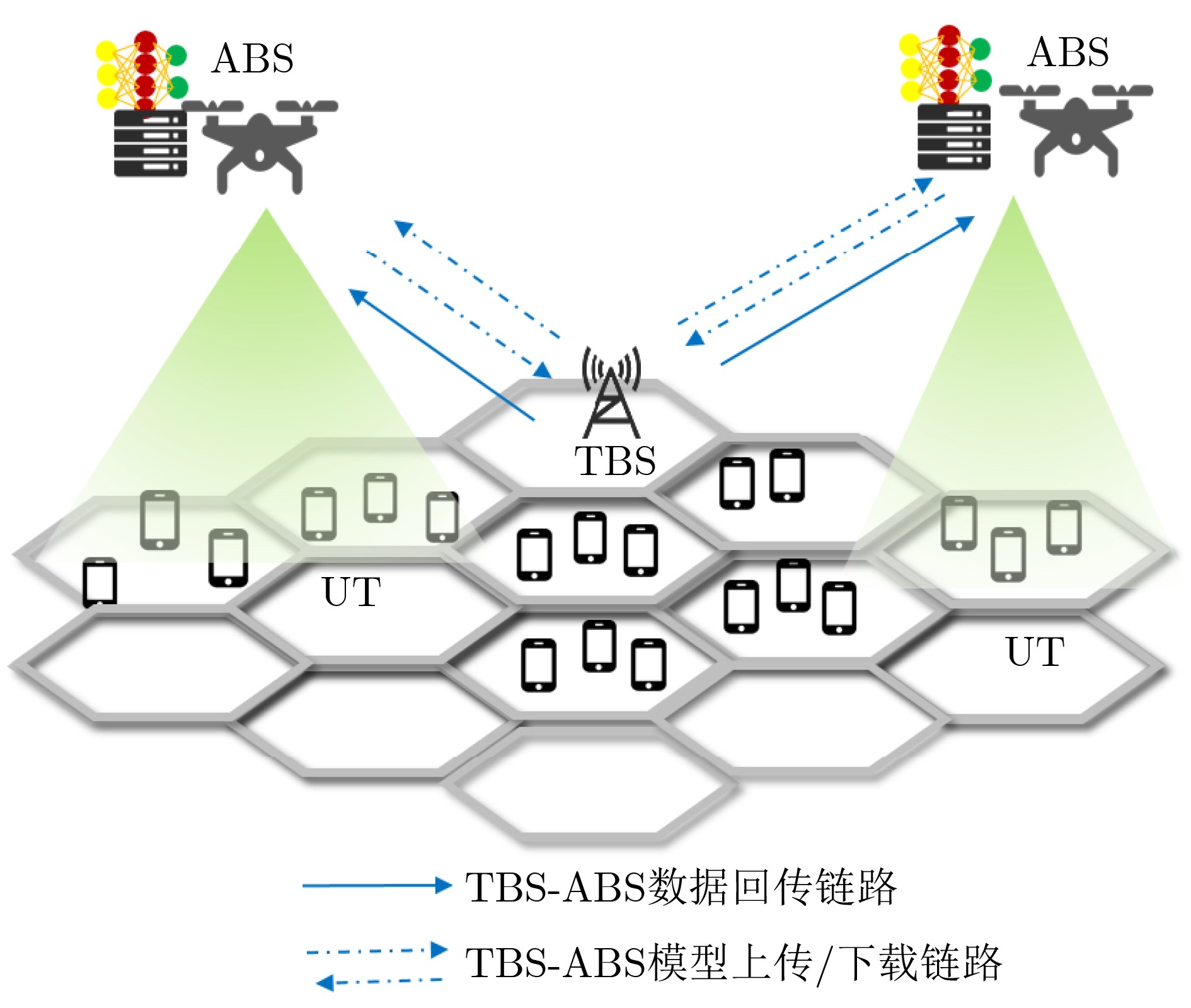
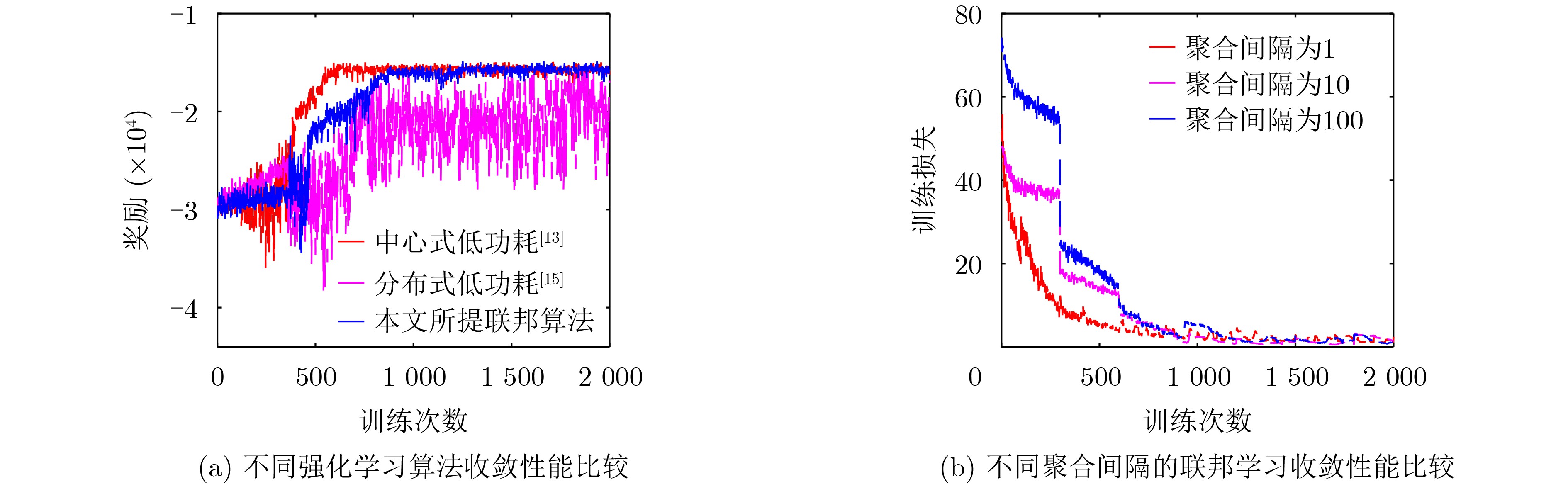
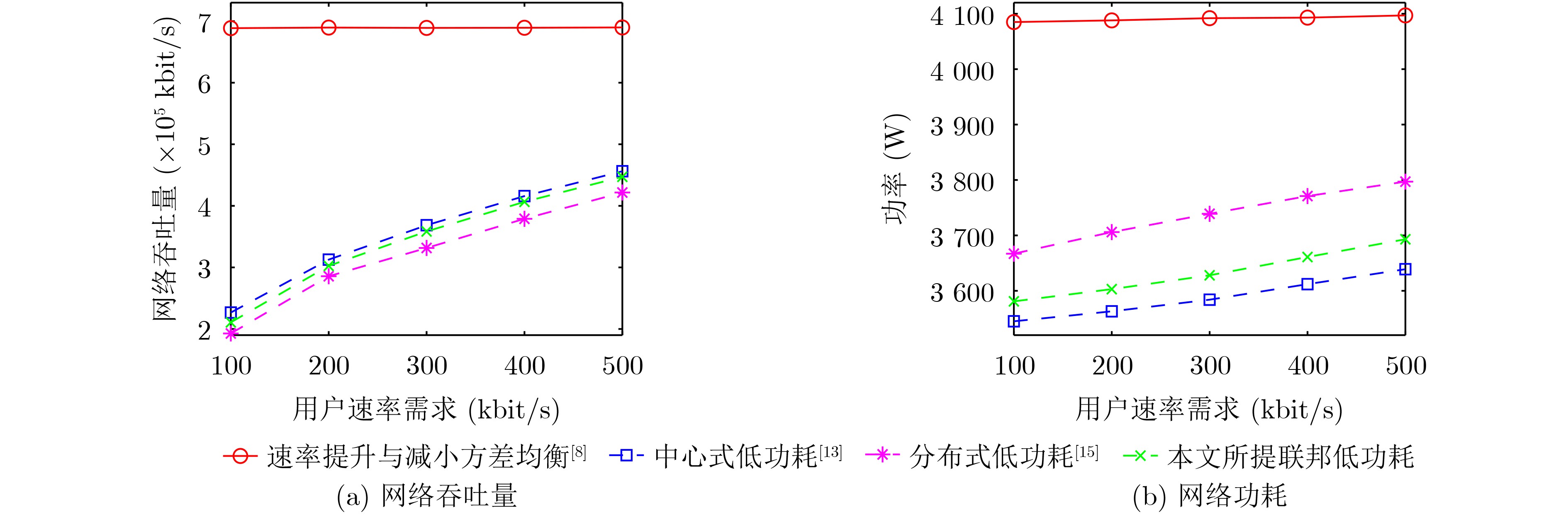
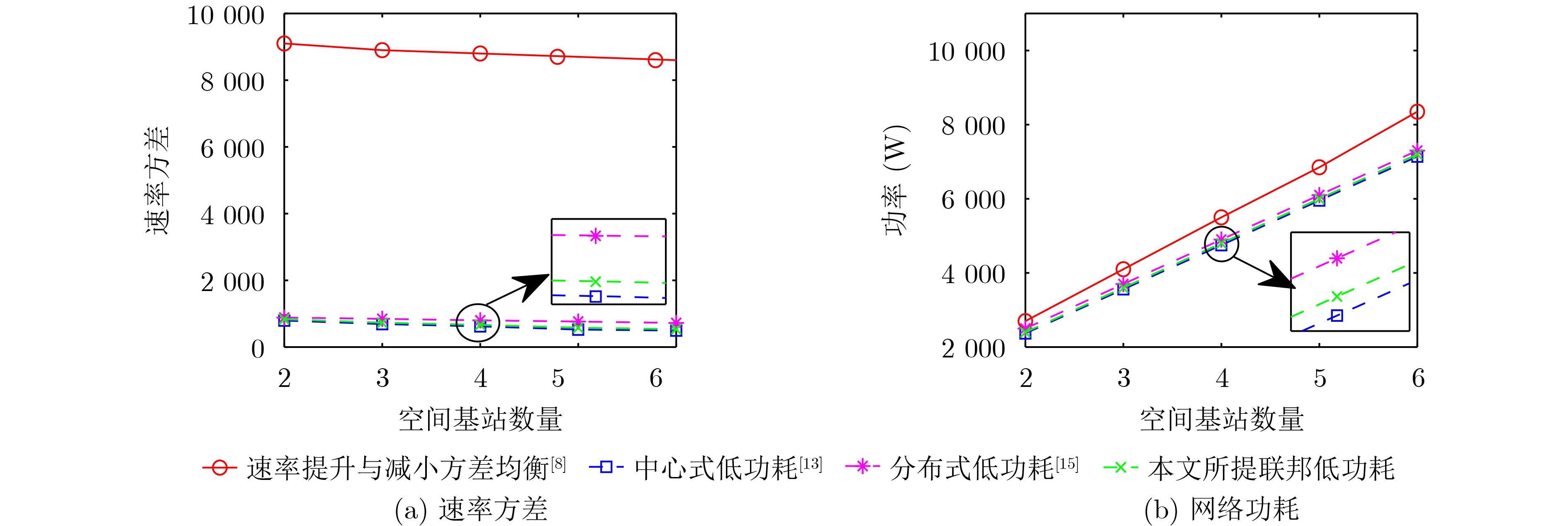
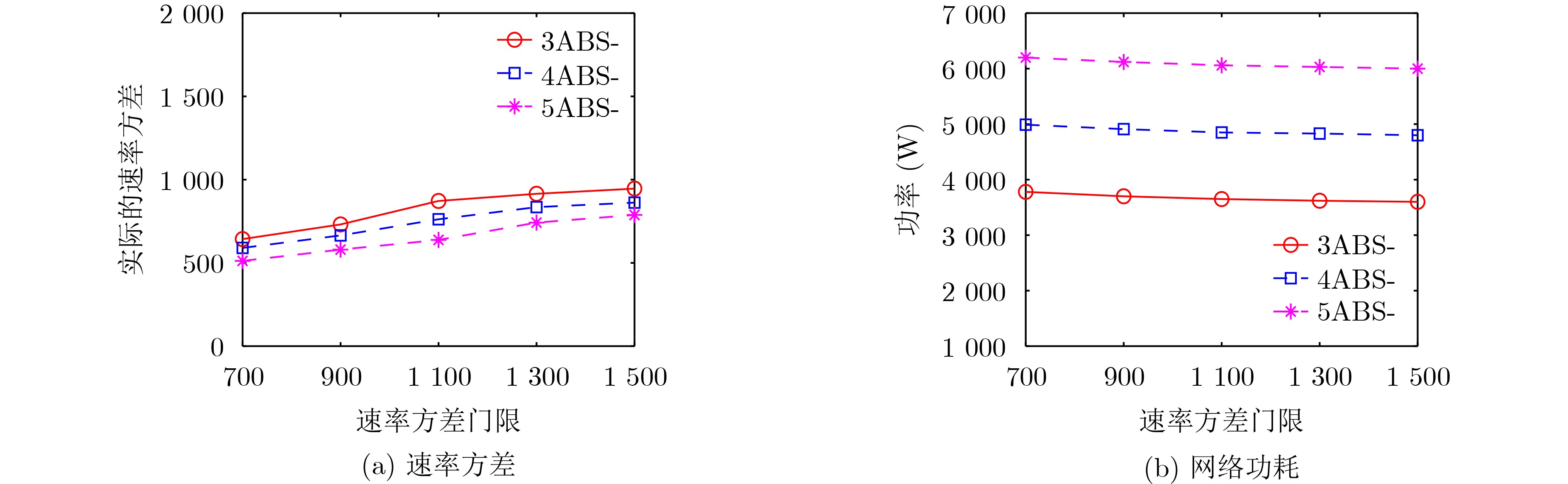
摘要: 空地一体化网络(AGIN)充分利用了空中基站(ABSs)灵活部署的特点,为热点地区提供了按需覆盖与高质量服务。然而,空中基站的高动态性使得网络的服务连续性难以保障。而且,空中基站能量受限,提升服务连续性和降低功耗通常又对应不同的飞行动作,因此,低功耗的服务连续性保障尤为困难。针对上述问题,该文基于联邦深度强化学习(FDRL)提出了一种面向低功耗服务连续性保障的通信与控制联合优化方法。所提方法通过联合优化空中基站的移动控制、用户关联和功率分配来保障网络服务的连续性。针对空中基站的高动态性,通过在所提方法中设计了环境状态经验池来利用信道的时空相关性,并在奖励函数中引入速率方差来保障网络服务连续性。考虑到不同飞行动作的功耗差异,所提方法通过优化空中基站的飞行动作来降低网络功耗。仿真结果说明,该文所提算法在满足用户速率需求和速率方差需求的前提下,能够减小网络功耗,并且所提联邦深度强化学习的性能接近中心式强化学习的性能。
-
关键词:
- 空地一体化网络 /
- 服务连续性保障 /
- 低功耗通信与控制联合优化
Abstract: The Aerial-Ground Integrated Networks (AGIN) take full advantage of the flexible deployment of Aerial Base Stations (ABSs) to provide on-demand coverage and high-quality services in hotspot areas. However, the high dynamics of ABSs pose a great challenge to service continuity assurance in AGIN. Furthermore, given the energy constraints of ABSs, ensuring service continuity with low power consumption becomes an increasingly formidable challenge. This is attributed to the inherent contradiction between enhancing service continuity and reducing power consumption, which typically necessitates distinct flight actions. Focusing on the problem mentioned above, a communication and control joint optimization approach based on Federated Deep Reinforcement Learning (FDRL) is proposed to obtain low-power service continuity assurance in AGIN. The proposed approach ensures service continuity by jointly optimizing the flight actions of ABSs, user associations, and power allocation. To cope with the high dynamics of ABSs, an environmental state experience pool is designed to capture the spatiotemporal correlation of channels, and the rate variance is introduced into the reward function to ensure service continuity. Taking into account the power consumption differences associated with various flight actions, the proposed approach optimizes the flight actions of ABSs to reduce their power consumption. Simulation results demonstrate that, under the premise of satisfying requirements for user rate and rate variance, the proposed approach can effectively reduce network power consumption. Additionally, the performance of FDRL is close to that of centralized reinforcement learning. -
1 均值聚类关联算法
输入:ABS位置$ \{ ({x_m},{y_m},{z_m}),m \in [1,M]\} $,用户位置
$\{ ({x_k},{y_k},0),k \in [1,K]\} $,ABS数量$M$,用户数量$K$,聚类
迭代次数$I$(1) 随机选择$M$个用户作为$M$簇的簇心,它是所有用户位置的
子集(2) ${\text{for }}i = 1,2, \cdots ,I{\text{ do}}$ (3) ${\text{for }}k = 1,2, \cdots ,K{\text{ do}}$ (4) 计算用户$k$与每个簇心的距离 (5) 把用户划分到距离最小的簇内 (6) 重新计算每个簇的簇心 (7) ${\text{end for}}$ (8) 如果簇心不再变化,提前结束聚类过程 (9)) ${\text{end for}}$ (10) 得到用户簇和对应的簇心 (11) ${\text{for }}m = 1,2, \cdots ,M{\text{ do}}$: (12) 计算空中基站$m$与每个簇心的距离,并将距离存储在距
离数组中(13) 找到距离最小的用户簇,并将$m$与其关联 (14) 在空中基站$m$的$R$个子信道集合中按顺序选择子信道,
记录到用户关联列表中(15) 标记已经选择基站的用户簇,使其不能与其他基站关联 (16) ${\text{end for}}$ (17) 输出用户关联列表  下载: 导出CSV
下载: 导出CSV
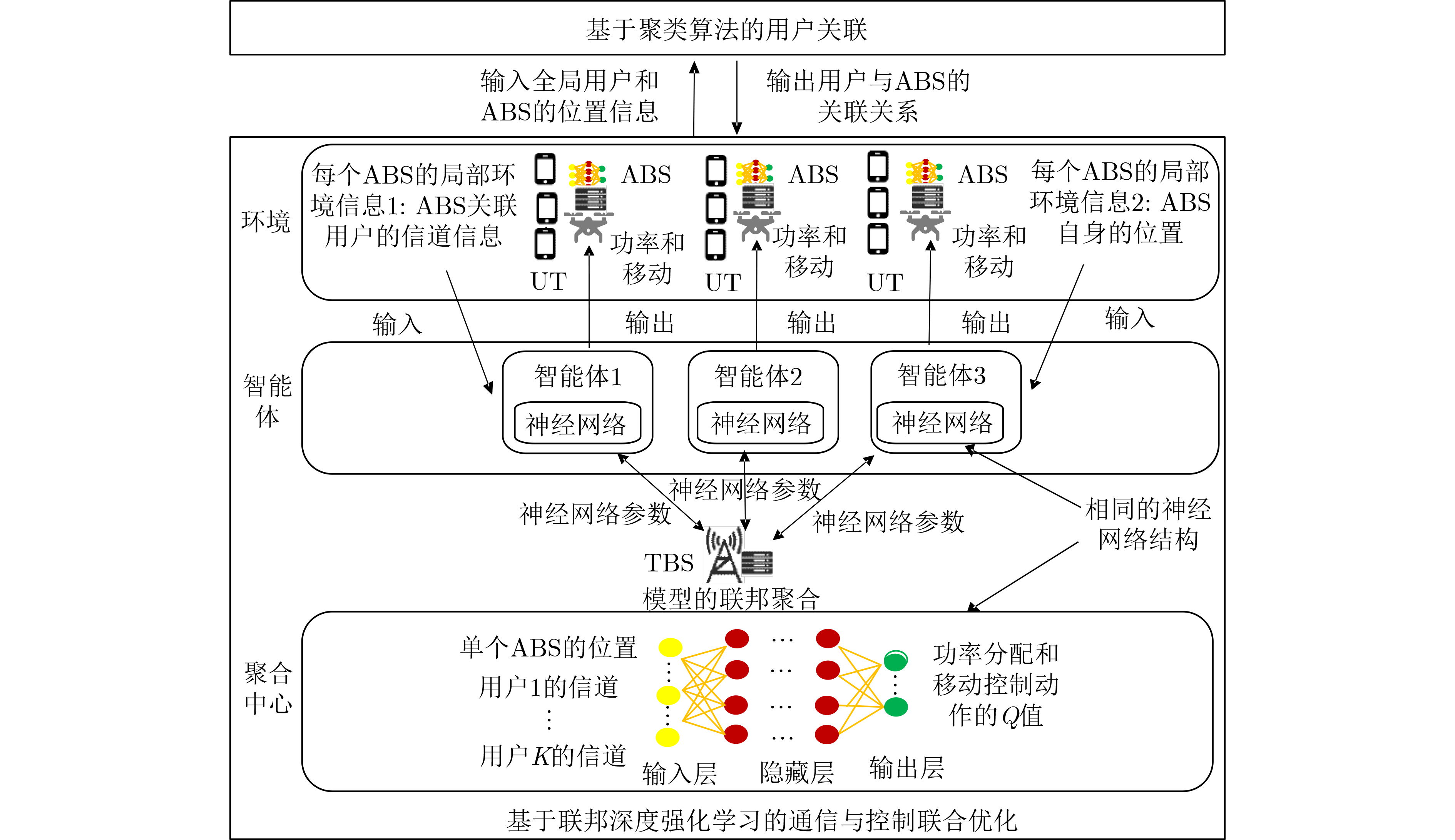
2 联邦深度强化学习算法
输入:聚合间隔$G$,折扣因子$\gamma $,学习率$ \kappa $,探索因子$\varepsilon $,智能体的数量$M$,用于训练的幕数$E$,单幕的时隙数$T$ (1) 初始化环境参数,包含ABS和用户的位置,以及信道增益 (2) 给每一个智能体和全局模型设置初始化的深度神经网络参数 (3) ${\text{for }}i = 1,2, \cdots ,E{\text{ do}}$ (4) ${\text{for }}t = 1,2, \cdots ,T{\text{ do}}$ (5) ${\text{for }}m = 1,2, \cdots ,M{\text{ do}}$ (6) 步骤1:从聚合服务器获取全局的模型参数${\theta ^g}$,初始化智能体$m$的神经网络 (7) 步骤2:从网络环境中获取状态参数$s(t)$ (8) 步骤3:根据$\varepsilon $和式(15)选择动作$a(t)$ (9) 步骤4:执行动作$a(t)$,获得下一个状态$s(t + 1)$和$R(t)$ (10) 步骤5:把$a(t)$, $s(t)$, $s(t + 1)$, $R(t)$记录到环境信息经验池中 (11) 步骤6:当采样数满足训练要求时,从环境信息经验池中选择样本训练深度神经网络训练模型${\theta _m}$,否者返回 (12) ${\text{end for}}$ (13) ${\text{if }}(t\% G = = 0)$ (14) $M$个智能体传输深度神经网络参数到TBS,执行FedAvg聚合,把聚合后的模型传输给各个智能体分布式执行 (15) ${\text{end if}}$ (16) ${\text{end for}}$ (17) ${\text{end for}}$ (18) 输出ABS移动控制和功率分配的动作
下载: 导出CSV
-
[1] LYU Jiangbin, ZENG Yong, and ZHANG Rui. UAV-aided offloading for cellular hotspot[J]. IEEE Transactions on Wireless Communications, 2018, 17(6): 3988–4001. doi: 10.1109/TWC.2018.2818734. [2] MOZAFFARI M, SAAD W, BENNIS M, et al. A tutorial on UAVs for wireless networks: Applications, challenges, and open problems[J]. IEEE Communications Surveys & Tutorials, 2019, 21(3): 2334–2360. doi: 10.1109/COMST.2019.2902862. [3] JIANG Xu, SHENG Min, ZHAO Nan, et al. Green UAV communications for 6G: A survey[J]. Chinese Journal of Aeronautics, 2022, 35(9): 19–34. doi: 10.1016/j.cja.2021.04.025. [4] LI Yang, ZHANG Heli, JI Hong, et al. UAV-assisted cellular communication: Joint trajectory and coverage optimization[C]. 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 2021: 1–6. doi: 10.1109/WCNC49053.2021.9417264. [5] NGUYEN M D, LE L B, and GIRARD A. Integrated UAV trajectory control and resource allocation for UAV-based wireless networks with Co-channel interference management[J]. IEEE Internet of Things Journal, 2022, 9(14): 12754–12769. doi: 10.1109/JIOT.2021.3138374. [6] ZHOU Shiyang, CHENG Yufang, LEI Xia, et al. Resource allocation in UAV-assisted networks: A clustering-aided reinforcement learning approach[J]. IEEE Transactions on Vehicular Technology, 2022, 71(11): 12088–12103. doi: 10.1109/TVT.2022.3189552. [7] XIE Ziwen, LIU Junyu, SHENG Min, et al. Exploiting aerial computing for air-to-ground coverage enhancement[J]. IEEE Wireless Communications, 2021, 28(5): 50–58. doi: 10.1109/MWC.211.2100048. [8] LI Jiandong, ZHOU Chengyi, LIU Junyu, et al. Reinforcement learning based resource allocation for coverage continuity in high dynamic UAV communication networks[J]. IEEE Transactions on Wireless Communications, 2023. doi: 10.1109/TWC.2023.3282909. [9] ZENG Yong and ZHANG Rui. Energy-efficient UAV communication with trajectory optimization[J]. IEEE Transactions on Wireless Communications, 2017, 16(6): 3747–3760. doi: 10.1109/TWC.2017.2688328. [10] ZENG Fanzi, HU Zhenzhen, XIAO Zhu, et al. Resource allocation and trajectory optimization for QoE provisioning in energy-efficient UAV-enabled wireless networks[J]. IEEE Transactions on Vehicular Technology, 2020, 69(7): 7634–7647. doi: 10.1109/TVT.2020.2986776. [11] LI Yabo, ZHANG Haijun, LONG Keping, et al. Joint resource allocation and trajectory optimization with QoS in NOMA UAV networks[C]. GLOBECOM 2020 - 2020 IEEE Global Communications Conference, Taipei, China, 2020: 1–5. doi: 10.1109/GLOBECOM42002.2020.9322351. [12] CUI Yuling, DENG Danhao, WANG Chaowei, et al. Joint trajectory and power optimization for energy efficient UAV communication using deep reinforcement learning[C]. IEEE INFOCOM 2021 - IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Vancouver, Canada, 2021: 1–6. doi: 10.1109/INFOCOMWKSHPS51825.2021.9484490. [13] LIU C H, CHEN Zheyu, TANG Jian, et al. Energy-efficient UAV control for effective and fair communication coverage: A deep reinforcement learning approach[J]. IEEE Journal on Selected Areas in Communications, 2018, 36(9): 2059–2070. doi: 10.1109/JSAC.2018.2864373. [14] ARANI A H, AZARI M M, HU Peng, et al. Reinforcement learning for energy-efficient trajectory design of UAVs[J]. IEEE Internet of Things Journal, 2022, 9(11): 9060–9070. doi: 10.1109/JIOT.2021.3118322. [15] GALKIN B, OMONIWA B, and DUSPARIC I. Multi-agent deep reinforcement learning for optimising energy efficiency of fixed-wing UAV cellular access points[C]. ICC 2022 - IEEE International Conference on Communications, Seoul, Korea, 2022: 1–6. doi: 10.1109/ICC45855.2022.9838809. [16] KAKARLA N B and MAHENDRAN V. Lyapunov meets thompson: Learning-based energy-efficient UAV communication with queuing stability constraints[C]. IEEE INFOCOM 2023 - IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Hoboken, USA, 2023: 1–7. doi: 10.1109/INFOCOMWKSHPS57453.2023.10225765. [17] SUN Yan, XU Dongfang, NG D W K, et al. Optimal 3D-trajectory design and resource allocation for solar-powered UAV communication systems[J]. IEEE Transactions on Communications, 2019, 67(6): 4281–4298. doi: 10.1109/TCOMM.2019.2900630. [18] WANG Ningyuan, LI Feng, CHEN Dong, et al. NOMA-based energy-efficiency optimization for UAV enabled space-air-ground integrated relay networks[J]. IEEE Transactions on Vehicular Technology, 2022, 71(4): 4129–4141. doi: 10.1109/TVT.2022.3151369. [19] LUONG P, GAGNON F, TRAN L N, et al. Deep reinforcement learning-based resource allocation in cooperative UAV-assisted wireless networks[J]. IEEE Transactions on Wireless Communications, 2021, 20(11): 7610–7625. doi: 10.1109/TWC.2021.3086503. [20] DE SENA A S, LIMA F R M, DA COSTA D B, et al. Massive MIMO-NOMA networks with imperfect SIC: Design and fairness enhancement[J]. IEEE Transactions on Wireless Communications, 2020, 19(9): 6100–6115. doi: 10.1109/TWC.2020.3000192. [21] FIORANI M, TOMBAZ S, FARIAS F S, et al. Joint design of radio and transport for green residential access networks[J]. IEEE Journal on Selected Areas in Communications, 2016, 34(4): 812–822. doi: 10.1109/JSAC.2016.2544599. [22] WEI Xizixiang and SHEN Cong. Federated learning over noisy channels: Convergence analysis and design examples[J]. IEEE Transactions on Cognitive Communications and Networking, 2022, 8(2): 1253–1268. doi: 10.1109/TCCN.2022.3140788. -

 下载:
下载:


图(6) / 表(2)
计量
- 文章访问数: 1101
- HTML全文浏览量: 912
- PDF下载量: 135
- 被引次数: 0
