

Zero-shot 3D Shape Classification Based on Semantic-enhanced Language-Image Pre-training Model
-
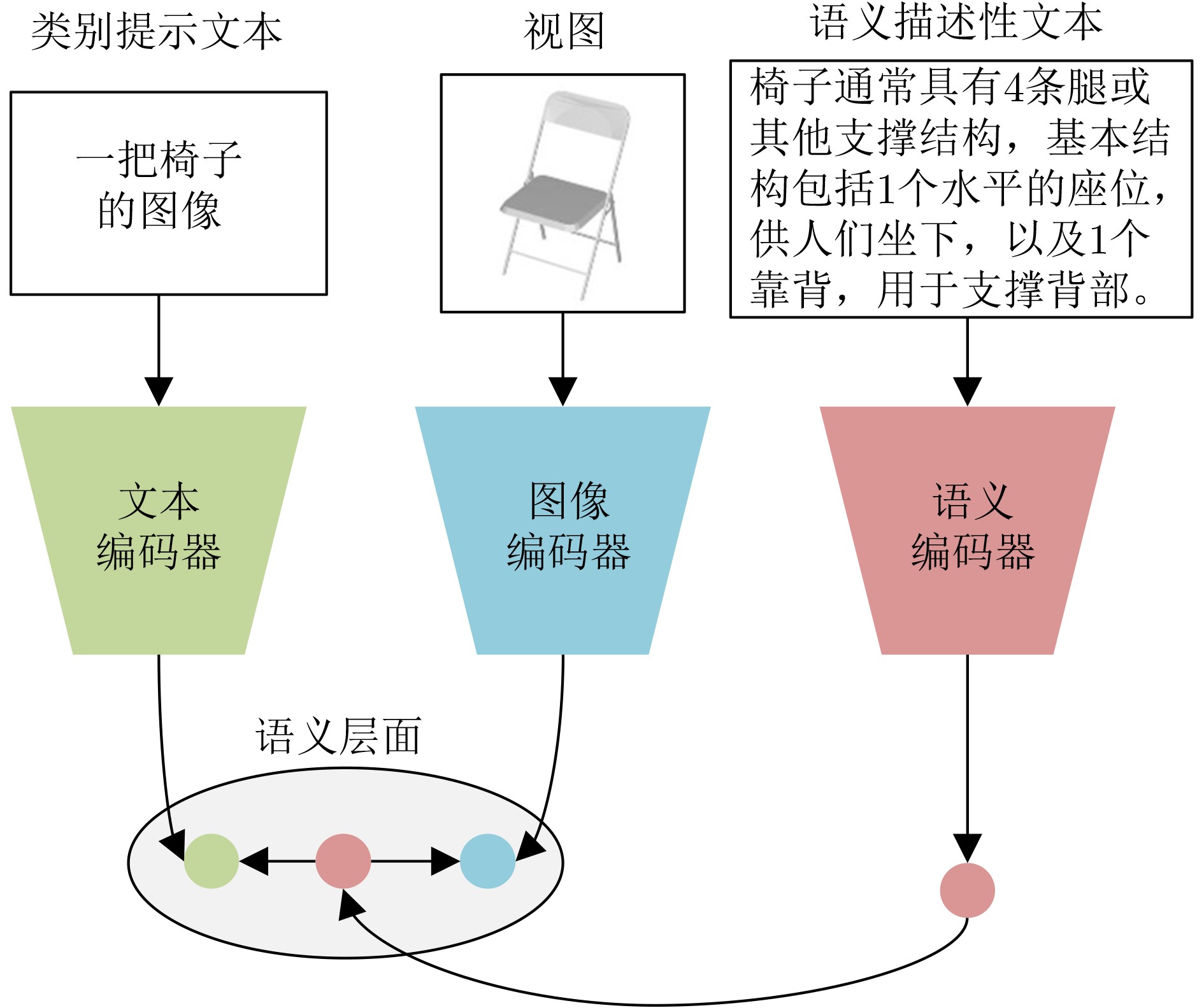
摘要: 目前,基于对比学习的图像-文本预训练模型(CLIP)在零样本3维模型分类任务上表现出了巨大潜力,然而3维模型和文本之间存在巨大的模态鸿沟,影响了分类准确率的进一步提高。针对以上问题,该文提出一种语义增强CLIP的零样本3维模型分类方法。该方法首先将3维模型表示成多视图;然后为了增强零样本学习对未知类别的识别能力,通过视觉语言生成模型获得每张视图及其类别的语义描述性文本,并将其作为视图和类别提示文本之间的语义桥梁,语义描述性文本采用图像字幕和视觉问答两种方式获取;最后微调语义编码器将语义描述性文本具化为类别的语义描述,其拥有丰富的语义信息和较好的可解释性,有效减小了视图和类别提示文本的语义鸿沟。实验表明,该文方法在ModelNet10和ModelNet40数据集上的分类性能优于现有的零样本分类方法。
-
关键词:
- 3维模型分类 /
- 零样本 /
- 基于对比学习的图像-文本预训练模型 /
- 语义描述性文本
Abstract: Currently, the Contrastive Language-Image Pre-training (CLIP) has shown great potential in zero-shot 3D shape classification. However, there is a large modality gap between 3D shapes and texts, which limits further improvement of classification accuracy. To address the problem, a zero-shot 3D shape classification method based on semantic-enhanced CLIP is proposed in this paper. Firstly, 3D shapes are represented as views. Then, in order to improve recognition ability of unknown categories in zero-shot learning, the semantic descriptive text of each view and its corresponding category are obtained through a visual language generative model, and it is used as the semantic bridge between views and category prompt texts. The semantic descriptive texts are obtained through image captioning and visual question answering. Finally, the finely-adjusted semantic encoder is used to concretize the semantic descriptive texts to the semantic descriptions of each category, which have rich semantic information and strong interpretability, and effectively reduce the semantic gap between views and category prompt texts. Experiments show that our method outperforms existing zero-shot classification methods on the ModelNet10 and ModelNet40 datasets. -
表 2 在ModelNet10和ModelNet40数据集上零样本分类准确率(%)
方法 ModelNet10 ModelNet40 CLIP2Point 66.63 49.38 PointCLIP 30.23 23.78 PointCLIP V2 73.13 64.22 CLIP+图像字幕 79.63 67.59 CLIP+视觉问答 79.74 69.73  下载: 导出CSV
下载: 导出CSV
表 3 在ModelNet10和ModelNet40上数据集上2-shot分类准确率(%)
方法 ModelNet10 ModelNet40 PointNet – 33.10 SimpleView – 36.43 CurveNet – 56.56 PointNet++ – 56.93 PointCLIP – 68.31 CLIP+图像字幕 86.01 76.74 CLIP+视觉问答 86.89 78.48
下载: 导出CSV
表 4 图像字幕生成方法在类别提示文本上的准确率(%)
类别提示文本 ModelNet10 ModelNet40 “image of a {CLASS}.” 79.63 67.59 “a view of a {CLASS}.” 82.60 67.95 “a 3D shape view of a {CLASS}.” 83.15 70.91 “a 3D shape of a {CLASS}.” 83.15 70.66
下载: 导出CSV
表 5 视觉问答生成方法在类别提示文本上的准确率(%)
类别提示文本 ModelNet10 ModelNet40 “image of a {CLASS}.” 79.74 69.73 “a view of a {CLASS}.” 80.73 70.91 “a 3D shape view of a {CLASS}.” 81.28 72.57 “a 3D shape of a {CLASS}.” 83.15 72.89
下载: 导出CSV
表 6 不同的图像编码器上的准确率(%)
方法 RN50 RN101 ViT-B\16 ViT-B\32 CLIP+图像字幕 26.10 28.90 67.59 60.05 CLIP+视觉问答 28.89 30.33 69.73 65.80
下载: 导出CSV
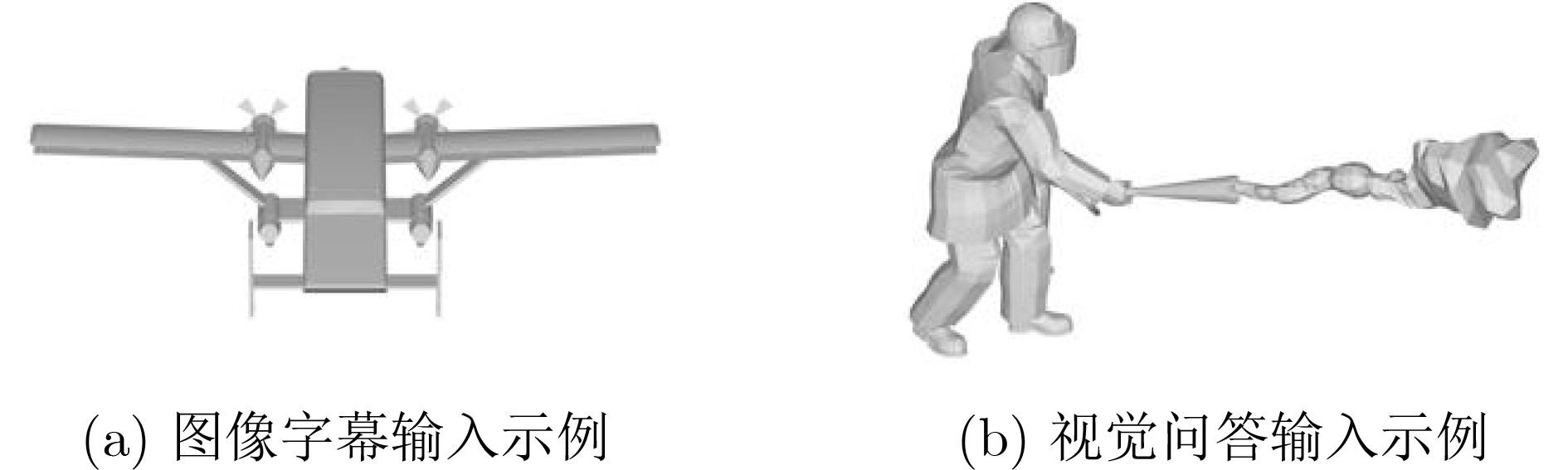
表 7 生成的文本提示示例






图像字幕 flying goblet plastic straight line tin can wooden chair 视觉问答 3D model of a fighter jet isolated on white background a tall glass of milk on a white background a white trash can with a lid on a white background a long line of gray stairs on a white background a stack of metal cans with plants growing out of them a 3D model of a beach chair
下载: 导出CSV
-
[1] 赵鹏, 汪纯燕, 张思颖, 等. 一种基于融合重构的子空间学习的零样本图像分类方法[J]. 计算机学报, 2021, 44(2): 409–421. doi: 10.11897/SP.J.1016.2021.00409.ZHAO Peng, WANG Chunyan, ZHANG Siying, et al. A zero-shot image classification method based on subspace learning with the fusion of reconstruction[J]. Chinese Journal of Computers, 2021, 44(2): 409–421. doi: 10.11897/SP.J.1016.2021.00409. [2] FU Yanwei, XIANG Tao, JIANG Yugang, et al. Recent advances in zero-shot recognition: Toward data-efficient understanding of visual content[J]. IEEE Signal Processing Magazine, 2018, 35(1): 112–125. doi: 10.1109/MSP.2017.2763441. [3] ZHAI Xiaohua, WANG Xiao, MUSTAFA B, et al. LiT: Zero-shot transfer with locked-image text tuning[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 18102–18112. doi: 10.1109/CVPR52688.2022.01759. [4] JI Zhong, YAN Jiangtao, WANG Qiang, et al. Triple discriminator generative adversarial network for zero-shot image classification[J]. Science China Information Sciences, 2021, 64(2): 120101. doi: 10.1007/s11432-020-3032-8. [5] LIU Yang, ZHOU Lei, BAI Xiao, et al. Goal-oriented gaze estimation for zero-shot learning[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 3793–3802. doi: 10.1109/CVPR46437.2021.00379. [6] CHOI H, KIM J, JOE S, et al. Analyzing zero-shot cross-lingual transfer in supervised NLP tasks[C]. The 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 2021: 9608–9613. doi: 10.1109/ICPR48806.2021.9412570. [7] GAO Rui, HOU Xingsong, QIN Jie, et al. Zero-VAE-GAN: Generating unseen features for generalized and transductive zero-shot learning[J]. IEEE Transactions on Image Processing, 2020, 29: 3665–3680. doi: 10.1109/TIP.2020.2964429. [8] RAMESH A, PAVLOV M, GOH G, et al. Zero-shot text-to-image generation[C]. The 38th International Conference on Machine Learning, 2021: 8821–8831. [9] NICHOL A Q, DHARIWAL P, RAMESH A, et al. GLIDE: Towards photorealistic image generation and editing with text-guided diffusion models[C]. The 39th International Conference on Machine Learning, Baltimore, USA, 2022: 16784–16804. [10] RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]. The 38th International Conference on Machine Learning, 2021: 8748–8763. [11] CHENG Ruizhe, WU Bichen, ZHANG Peizhao, et al. Data-efficient language-supervised zero-shot learning with self-distillation[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Nashville, USA, 2021: 3119–3124. doi: 10.1109/CVPRW53098.2021.00348. [12] Doshi K, Garg A, Uzkent B, et al. A multimodal benchmark and improved architecture for zero shot learning[C]. The IEEE/CVF Winter Conference on Applications of Computer Vision. 2024: 2021–2030. [13] LUO Huaishao, JI Lei, ZHONG Ming, et al. CLIP4Clip: An empirical study of CLIP for end to end video clip retrieval and captioning[J]. Neurocomputing, 2022, 508: 293–304. doi: 10.1016/j.neucom.2022.07.028. [14] CHEN Long, ZHENG Yuhang, and XIAO Jun. Rethinking data augmentation for robust visual question answering[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 95–112. doi: 10.1007/978-3-031-20059-5_6. [15] CHO J, YOON S, KALE A, et al. Fine-grained image captioning with CLIP reward[C]. Findings of the Association for Computational Linguistics: NAACL 2022, Seattle, United States, 2022: 517–527. doi: 10.18653/v1/2022.findings-naacl.39. [16] LIANG Feng, WU Bichen, DAI Xiaoliang, et al. Open-vocabulary semantic segmentation with mask-adapted clip[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 7061–7070. doi: 10.1109/CVPR52729.2023.00682. [17] XIE Jinheng, HOU Xianxu, YE Kai, et al. CLIMS: Cross language image matching for weakly supervised semantic segmentation[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 4473–4482. doi: 10.1109/CVPR52688.2022.00444. [18] ZHOU Chong, LOY C C, and DAI Bo. Extract free dense labels from CLIP[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 696–712. doi: 10.1007/978-3-031-19815-1_40. [19] WANG Fengyun, PAN Jinshan, XU Shoukun, et al. Learning discriminative cross-modality features for RGB-D saliency detection[J]. IEEE Transactions on Image Processing, 2022, 31: 1285–1297. doi: 10.1109/TIP.2022.3140606. [20] WU Zhirong, SONG Shuran, KHOSLA A, et al. 3D shapeNets: A deep representation for volumetric shapes[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 1912–1920. doi: 10.1109/CVPR.2015.7298801. [21] CHERAGHIAN A, RAHMAN S, and PETERSSON L. Zero-shot learning of 3D point cloud objects[C]. The 16th International Conference on Machine Vision Applications, Tokyo, Japan, 2019. DOI: 10.23919/MVA.2019.8758063. [22] CHERAGHIAN A, RAHMAN S, CAMPBELL D, et al. Mitigating the hubness problem for zero-shot learning of 3D objects[C]. The 30th British Machine Vision Conference, Cardiff, UK, 2019. doi: 10.48550/arXiv.1907.06371. [23] CHERAGHIAN A, RAHMAN S, CAMPBELL D, et al. Transductive zero-shot learning for 3D point cloud classification[C]. 2020 IEEE Winter Conference on Applications of Computer Vision, Snowmass, USA, 2020: 912–922. doi: 10.1109/WACV45572.2020.9093545. [24] CHERAGHIAN A, RAHMAN S, CHOWDHURY T F, et al. Zero-shot learning on 3D point cloud objects and beyond[J]. International Journal of Computer Vision, 2022, 130(10): 2364–2384. doi: 10.1007/s11263-022-01650-4. [25] ZHANG Renrui, GUO Ziyu, ZHANG Wei, et al. PointCLIP: Point cloud understanding by CLIP[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 8552–8562. doi: 10.1109/CVPR52688.2022.00836. [26] HUANG Tianyu, DONG Bowen, YANG Yunhan, et al. CLIP2Point: Transfer CLIP to point cloud classification with image-depth pre-training[C]. 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023. doi: 10.1109/ICCV51070.2023.02025. [27] XUE Le, GAO Mingfei, XING Chen, et al. ULIP: Learning unified representation of language, image and point cloud for 3D understanding[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023. doi: 10.1109/CVPR52729.2023.00120. [28] HEGDE D, VALANARASU J M J, and PATEL V M. CLIP goes 3D: Leveraging prompt tuning for language grounded 3D recognition[C]. 2023 IEEE/CVF International Conference on Computer Vision Workshops, Paris, France, 2023. doi: 10.1109/ICCVW60793.2023.00217. [29] ZHU Xiangyang, ZHANG Renrui, HE Bowei, et al. PointCLIP V2: Prompting CLIP and GPT for powerful 3D open-world learning[J]. arXiv: 2211.11682, 2022. doi: 10.48550/arXiv.2211.11682. [30] BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020. [31] GAO Tianyu, FISCH A, and CHEN Danqi. Making pre-trained language models better few-shot learners[C]. The 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, 2021: 3816–3830. doi: 10.18653/v1/2021.acl-long.295. [32] SORENSEN T, ROBINSON J, RYTTING C, et al. An information-theoretic approach to prompt engineering without ground truth labels[C]. The 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 2022: 819–862. doi: 10.18653/v1/2022.acl-long.60. [33] ZHANG Yuhao, JIANG Hang, MIURA Y, et al. Contrastive learning of medical visual representations from paired images and text[C]. 2022 Machine Learning for Healthcare Conference, Durham, USA, 2022: 2–25. doi: 10.48550/arXiv.2010.00747. [34] LESTER B, AL-RFOU R, and CONSTANT N. The power of scale for parameter-efficient prompt tuning[C]. The 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 2021: 3045–3059. doi: 10.18653/v1/2021.emnlp-main.243. [35] LI X L and LIANG P. Prefix-Tuning: Optimizing continuous prompts for generation[C]. The 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021: 4582–4597. doi: 10.18653/v1/2021.acl-long.353. [36] LIU Xiao, ZHENG Yanan, DU Zhengxiao, et al. GPT understands, too[J]. AI Open, 2023. doi: 10.1016/j.aiopen.2023.08.012. [37] ZHOU Kaiyang, YANG Jingkang, LOY C C, et al. Learning to prompt for vision-language models[J]. International Journal of Computer Vision, 2022, 130(9): 2337–2348. doi: 10.1007/s11263-022-01653-1. [38] ZHOU Kaiyang, YANG Jingkang, LOY C C, et al. Conditional prompt learning for vision-language models[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 16816–16825. doi: 10.1109/CVPR52688.2022.01631. [39] LI Chenliang, XU Haiyang, TIAN Junfeng, et al. mPLUG: Effective and efficient vision-language learning by cross-modal skip-connections[C]. The 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 2022. doi: 10.18653/v1/2022.emnlp-main.488. [40] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [41] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C]. The 9th International Conference on Learning Representations, 2021. [42] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017. doi: 10.48550/arXiv.1706.03762. [43] SU Hang, MAJI S, KALOGERAKIS E, et al. Multi-view convolutional neural networks for 3D shape recognition[C]. 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 945–953. doi: 10.1109/ICCV.2015.114. [44] 白静, 司庆龙, 秦飞巍. 基于卷积神经网络和投票机制的三维模型分类与检索[J]. 计算机辅助设计与图形学学报, 2019, 31(2): 303–314. doi: 10.3724/SP.J.1089.2019.17160.BAI Jing, SI Qinglong, and QIN Feiwei. 3D model classification and retrieval based on CNN and voting scheme[J]. Journal of Computer-Aided Design & Computer Graphics, 2019, 31(2): 303–314. doi: 10.3724/SP.J.1089.2019.17160. [45] QI CHARLES R, SU Hao, KAICHUN M, et al. PointNet: Deep learning on point sets for 3D classification and segmentation[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 652–660. doi: 10.1109/CVPR.2017.16. [46] QI CHARLES R, YI Li, SU Hao, et al. PointNet++: Deep hierarchical feature learning on point sets in a metric space[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017. [47] GOYAL A, LAW H, LIU Bowei, et al. Revisiting point cloud shape classification with a simple and effective baseline[C]. The 38th International Conference on Machine Learning, 2021: 3809–3820. [48] XIANG Tiange, ZHANG Chaoyi, SONG Yang, et al. Walk in the cloud: Learning curves for point clouds shape analysis[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 895–904. doi: 10.1109/ICCV48922.2021.00095. -

 下载:
下载:



图(3) / 表(7)
计量
- 文章访问数: 1307
- HTML全文浏览量: 915
- PDF下载量: 59
- 被引次数: 0
