

Edge Domain Adaptation for Stereo Matching
-
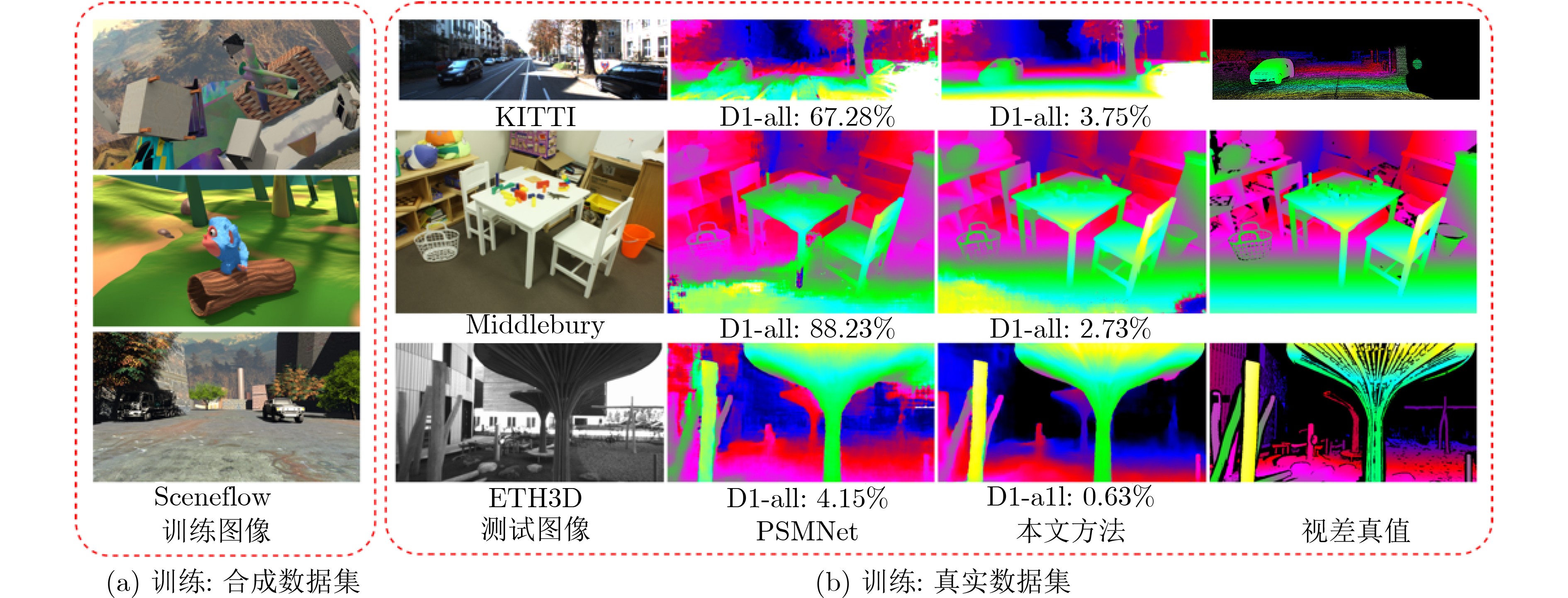
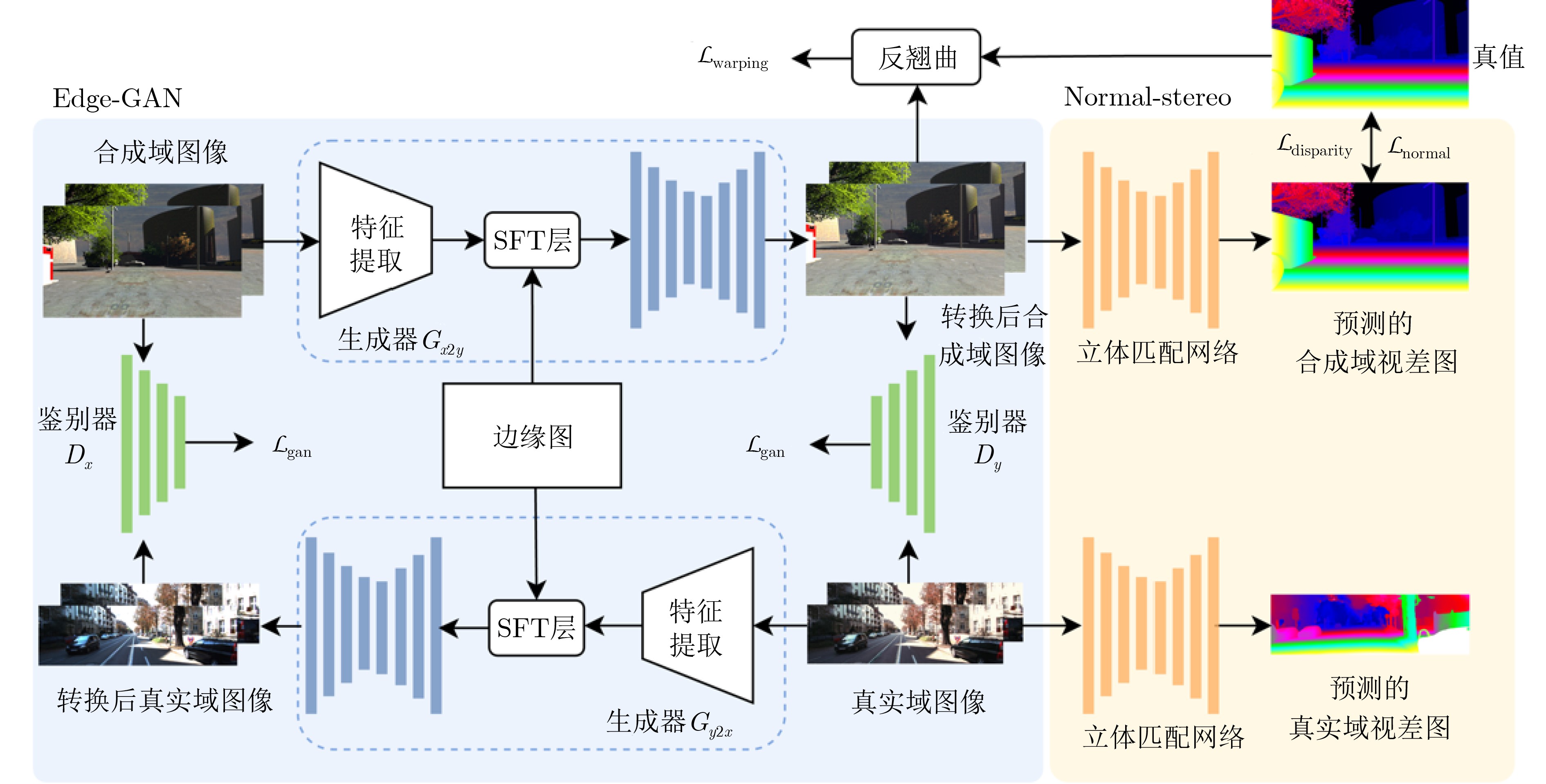
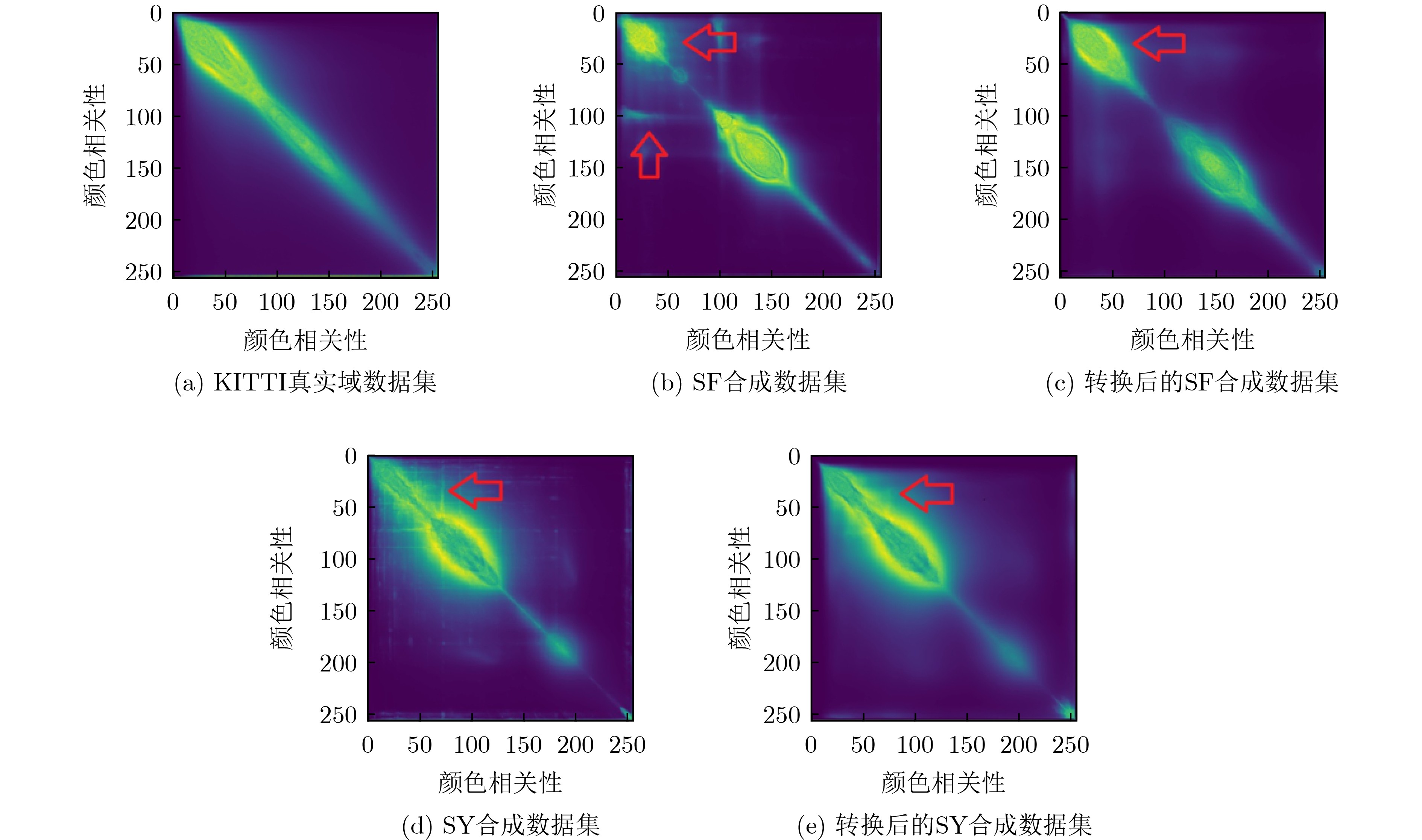
摘要: 风格迁移方法因其较好的域适应性,广泛应用于存在领域差异的计算机视觉领域。当前基于风格迁移的立体匹配任务存在如下挑战: (1)转换后的左右图像需满足配对的前提; (2)转换后图像的内容和空间信息要与原始图像保持一致。针对以上难点,该文提出一种基于边缘领域自适应的立体匹配方法(EDA-Stereo)。首先,构建了边缘引导的生成对抗网络(Edge-GAN),通过空间特征转换(SFT)层融合边缘信息和合成域图像特征,引导生成器输出保留合成域图像结构特征的伪图像。其次,提出翘曲损失函数以迫使基于转换后的右图像所重建出的左图像向原始左图像进行逼近,防止转换后的左右图像对不匹配。最后,提出基于法线损失的立体匹配网络,通过表征局部深度变化来捕获更多的几何细节,有效提高了匹配精度。通过在合成数据集上训练,在真实数据集上与多种方法进行比较,结果表明本该方法能够有效缓解领域差异,在KITTI 2012和KITTI 2015数据集上的D1误差分别为3.9%和4.8%,比当前先进的域不变立体匹配网络(DSM-Net)方法分别相对降低了37%和26%。Abstract: The style transfer method, due to its excellent domain adaptation capability, is widely used to alleviate domain gap of computer vision domain. Currently, stereo matching based on style transfer faces the following challenges: (1) The transformed left and right images need to remain matched; (2) The content and spatial information of the transformed images should remain consistent with the original images. To address these challenges, an Edge Domain Adaptation Stereo matching (EDA-Stereo) method is proposed. First, an Edge-guided Generative Adversarial Network (Edge-GAN) is constructed. By incorporating edge cues and synthetic features through the Spatial Feature Transform (SFT) layer. the Edge-GAN guides the generator to produce pseudo-images that retain the structural features of syntheitic domain images. Second, a warping loss is introduced to guarantee the left image to be reconstructed based on the transformed right image to approximate the original left image, preventing mismatches between the transformed left and right images. Finally, a normal loss based stetreo matching network is proposed to capture more geometric details by characterizing local depth variations, thereby improving matching accuracy. By training on synthetic datasets and comparing with various methods on real datasets, results show the effectiveness in mitigating domain gaps. On the KITTI 2012 and KITTI 2015 datasets, the D1 error is 3.9% and 4.8%, respectively, which is a relative reduction of 37% and 26% compared to the state-of-the-art Domain-invariant Stereo Matching Networks (DSM-Net) method.
-
Key words:
- Stereo matching /
- Domain adaptation /
- Edge-guided /
- Generative Adversarial Network(GAN)
-
表 1 Edge-GAN中损失函数的消融实验
损失函数 KT12 KT15 EPE D1 时间(s) EPE D1 时间(s) w/o $ {\mathcal{L}}_{\mathrm{c}\mathrm{y}\mathrm{c}\mathrm{l}\mathrm{e}} $ 1.68 9.87 0.14 2.05 10.30 0.14 w/o $ {\mathcal{L}}_{\mathrm{i}\mathrm{d}\mathrm{e}\mathrm{n}\mathrm{t}\mathrm{i}\mathrm{t}\mathrm{y}} $ 2.73 26.95 0.21 2.99 31.22 0.21 w/o $ {\mathcal{L}}_{\mathrm{w}\mathrm{a}\mathrm{r}\mathrm{p}\mathrm{i}\mathrm{n}\mathrm{g}} $ 1.24 5.62 0.19 1.52 6.85 0.19 所有损失 1.20 5.37 0.23 1.47 6.58 0.23  下载: 导出CSV
下载: 导出CSV
表 3 Edge-GAN使用不同边缘图的消融实验
网络结构 KT12 KT15 EPE D1 时间(s) EPE D1 时间(s) w/o 边缘 1.24 6.02 0.15 1.54 6.99 0.15 w/ Canny 边缘 1.23 5.51 0.24 1.51 6.70 0.24 w/ HED边缘 1.22 5.47 0.30 1.50 6.65 0.30 w/ Sobel 边缘 1.20 5.37 0.23 1.47 6.58 0.23
下载: 导出CSV
表 4 EDA-Stereo法线损失函数的消融实验
模型 训练集 KT12 KT15 EPE D1 时间(s) EPE D1 时间(s) EDA-Stereo w/o $ {\mathcal{L}}_{\mathrm{n}\mathrm{o}\mathrm{r}\mathrm{m}\mathrm{a}\mathrm{l}} $ SF 1.20 5.37 0.83 1.47 6.58 0.83 EDA-Stereo w/ $ {\mathcal{L}}_{\mathrm{n}\mathrm{o}\mathrm{r}\mathrm{m}\mathrm{a}\mathrm{l}} $ SF 1.18 4.95 0.86 1.47 5.13 0.86 EDA-Stereo w/o $ {\mathcal{L}}_{\mathrm{n}\mathrm{o}\mathrm{r}\mathrm{m}\mathrm{a}\mathrm{l}} $ SY 0.97 4.72 0.83 1.34 5.55 0.83 EDA-Stereo w/ $ {\mathcal{L}}_{\mathrm{n}\mathrm{o}\mathrm{r}\mathrm{m}\mathrm{a}\mathrm{l}} $ SY 1.00 4.52 0.86 1.32 4.91 0.86
下载: 导出CSV
表 2 Edge-GAN中SFT层的消融实验
网络结构 KT12 KT15 EPE D1 时间(s) EPE D1 时间(s) 边缘作为输入 1.23 5.63 0.17 1.52 6.78 0.17 边缘串接特征图 1.22 5.52 0.18 1.51 6.72 0.18 SFT层融合边缘 1.20 5.37 0.23 1.47 6.58 0.23
下载: 导出CSV
表 5 Edge-GAN对不同立体匹配算法的影响对比结果
模型 SF TSF SY TSY EPE D1 EPE D1 EPE D1 EPE D1 在KT12上测试 PSMNet [10] 1.99 15.02 1.66 11.4 1.42 6.8 1.36 6.37 GwcNet [21] 1.70 12.60 1.40 8.90 1.45 7.65 1.32 7.18 NLCA-Net [22] 1.23 6.61 1.20 6.35 1.14 4.67 1.06 4.42 Abc-Net [13] 1.28 7.23 1.20 5.37 1.03 4.96 0.97 4.72 在KT15上测试 PSMNet [10] 2.35 17.33 2.12 14.5 1.75 7.23 1.73 7.04 GwcNet [21] 2.36 12.20 1.76 9.90 1.74 6.89 1.59 6.80 NLCA-Net [22] 1.70 8.20 1.59 8.16 1.40 5.83 1.32 5.45 Abc-Net [13] 1.63 7.88 1.47 6.58 1.34 5.79 1.34 5.55
下载: 导出CSV
表 7 与其他先进方法的D1误差比较结果
模型 领域适应/领域泛化 训练数据 KT12
(D1-noc)KT15
(D1-noc)MB(half)
(Bad 2.0-noc)MB(quarter)
(Bad 2.0-noc)ETH3D
(Bad 1.0-noc)CostFilter[28] – – 21.7 18.9 40.5 17.6 31.1 PatchMatch[29] – – 20.1 17.2 38.6 16.1 24.1 SGM[1] – – 7.1 7.6 25.2 10.7 12.9 HD3-Stereo[30] – SF 23.6 26.5 37.9 20.3 54.2 EdgeStereo[31] – SF 7.8 10.1 11.54 – – GANet-deep[26] – SF 10.1 11.7 20.3 11.2 14.1 DSM-Net[32] $ \surd $ SF 6.2 6.5 13.8 8.1 – MS-GCNet [33] $ \surd $ SF 5.5 6.2 18.52 – 8.84 DANet[34] $ \surd $ SF 5.4 6.1 – – – StereoGan[35] $ \surd $ DR&KT15 25.6 – – – – StereoGan[35] $ \surd $ SY&KT15 11.6 – – – – ITSA-CFNet[36] $ \surd $ SF 4.2 4.7 10.4 8.5 5.1 FC-DSMNet[37] $ \surd $ SF 5.5 6.2 12.0 7.8 6.0 本文算法EDA-Stereo $ \surd $ SF 4.1 4.8 14.4 10.4 8.4 本文算法EDA-Stereo $ \surd $ SY 3.9 4.8 17.4 10.0 10.4
下载: 导出CSV
-
[1] HIRSCHMULLER H. Stereo processing by semiglobal matching and mutual information[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(2): 328–341. doi: 10.1109/TPAMI.2007.1166. [2] 边继龙, 门朝光, 李香. 基于小基高比的快速立体匹配方法[J]. 电子与信息学报, 2012, 34(3): 517–522. doi: 10.3724/SP.J.1146.2011.00826.BIAN Jilong, MEN Chaoguang, and LI Xiang. A fast stereo matching method based on small baseline[J]. Journal of Electronics & Information Technology, 2012, 34(3): 517–522. doi: 10.3724/SP.J.1146.2011.00826. [3] MAYER N, ILG E, HÄUSSER P, et al. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 4040–4048. doi: 10.1109/CVPR.2016.438. [4] KENDALL A, MARTIROSYAN H, DASGUPTA S, et al. End-to-end learning of geometry and context for deep stereo regression[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 66–75. doi: 10.1109/ICCV.2017.17. [5] LI Zhaoshuo, LIU Xingtong, DRENKOW N, et al. Revisiting stereo depth estimation from a sequence-to-sequence perspective with transformers[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 6177–6186. doi: 10.1109/ICCV48922.2021.00614. [6] LIPSON L, TEED Z, and DENG Jia. RAFT-Stereo: Multilevel recurrent field transforms for stereo matching[C]. 2021 International Conference on 3D Vision, London, UK, 2021: 218–227. doi: 10.1109/3DV53792.2021.00032. [7] LI Jiankun, WANG Peisen, XIONG Pengfei, et al. Practical stereo matching via cascaded recurrent network with adaptive correlation[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 16242–16251. doi: 10.1109/CVPR52688.2022.01578. [8] RAO Zhibo, XIONG Bangshu, HE Mingyi, et al. Masked representation learning for domain generalized stereo matching[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 5435–5444. doi: 10.1109/CVPR52729.2023.00526. [9] ROS G, SELLART L, MATERZYNSKA J, et al. The SYNTHIA dataset: A large collection of synthetic images for semantic segmentation of urban scenes[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 3234–3243. doi: 10.1109/CVPR.2016.352. [10] CHANG Jiaren and CHEN Yongsheng. Pyramid stereo matching network[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 5410–5418. doi: 10.1109/CVPR.2018.00567. [11] LIU Shaolei, YIN Siqi, QU Linhao, et al. Reducing domain gap in frequency and spatial domain for cross-modality domain adaptation on medical image segmentation[C]. The 37th AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 1719–1727. doi: 10.1609/aaai.v37i2.25260. [12] 刘彦呈, 董张伟, 朱鹏莅, 等. 基于特征解耦的无监督水下图像增强[J]. 电子与信息学报, 2022, 44(10): 3389–3398. doi: 10.11999/JEIT211517.LIU Yancheng, DONG Zhangwei, ZHU Pengli, et al. Unsupervised underwater image enhancement based on feature disentanglement[J]. Journal of Electronics & Information Technology, 2022, 44(10): 3389–3398. doi: 10.11999/JEIT211517. [13] LI Xing, FAN Yangyu, LV Guoyun, et al. Area-based correlation and non-local attention network for stereo matching[J]. The Visual Computer, 2022, 38(11): 3881–3895. doi: 10.1007/s00371-021-02228-w. [14] WANG Xintao, YU Ke, DONG Chao, et al. Recovering realistic texture in image super-resolution by deep spatial feature transform[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 606–615. doi: 10.1109/CVPR.2018.00070. [15] ZHU Junyan, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2242–2251. doi: 10.1109/ICCV.2017.244. [16] GEIGER A, LENZ P, and URTASUN R. Are we ready for autonomous driving? The KITTI vision benchmark suite[C]. 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, USA, 2012: 3354–3361. doi: 10.1109/CVPR.2012.6248074. [17] MENZE M and GEIGER A. Object scene flow for autonomous vehicles[C]. Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 3061–3070. doi: 10.1109/CVPR.2015.7298925. [18] SCHARSTEIN D, HIRSCHMÜLLER H, KITAJIMA Y, et al. High-resolution stereo datasets with subpixel-accurate ground truth[C]. The 36th DAGM German Conference on Pattern Recognition, Münster, Germany, 2014: 31–42. doi: 10.1007/978-3-319-11752-2_3. [19] SCHÖPS T, SCHÖNBERGER J L, GALLIANI S, et al. A multi-view stereo benchmark with high-resolution images and multi-camera videos[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2538–2547. doi: 10.1109/CVPR.2017.272. [20] XIE Saining and TU Zhuowen. Holistically-nested edge detection[C]. 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 1395–1403. doi: 10.1109/ICCV.2015.164. [21] GUO Xiaoyang, YANG Kai, YANG Wukui, et al. Group-wise correlation stereo network[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 3268–3277. doi: 10.1109/CVPR.2019.00339. [22] RAO Zhibo, HE Mingyi, DAI Yuchao, et al. NLCA-Net: A non-local context attention network for stereo matching[J]. APSIPA Transactions on Signal and Information Processing, 2020, 9(1): e18. doi: 10.1017/ATSIP.2020.16. [23] PASS G, ZABIH R, and MILLER J. Comparing images using color coherence vectors[C]. The Fourth ACM International Conference on Multimedia, New York, USA, 1997: 65–73. doi: 10.1145/244130.244148. [24] CHENG Xuelian, ZHONG Yiran, HARANDI M, et al. Hierarchical neural architecture search for deep stereo matching[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 1858. doi: 10.5555/3495724.3497582. [25] LIANG Zhengfa, FENG Yiliu, GUO Yulan, et al. Learning for disparity estimation through feature constancy[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 2811–2820. doi: 10.1109/CVPR.2018.00297. [26] ZHANG Feihu, PRISACARIU V, YANG Ruigang, et al. GA-Net: Guided aggregation net for end-to-end stereo matching[C]. Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 185–194. doi: 10.1109/CVPR.2019.00027. [27] XU Haofei and ZHANG Juyong. AANet: Adaptive aggregation network for efficient stereo matching[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 1956–1965. doi: 10.1109/CVPR42600.2020.00203. [28] HOSNI A, RHEMANN C, BLEYER M, et al. Fast cost-volume filtering for visual correspondence and beyond[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(2): 504–511. doi: 10.1109/TPAMI.2012.156. [29] BLEYER M, RHEMANN C, and ROTHER C. PatchMatch stereo-stereo matching with slanted support windows[C]. British Machine Vision Conference 2011, Dundee, UK, 2011: 1–11. doi: 10.5244/C.25.14. [30] YIN Zhichao, DARRELL T, and YU F. Hierarchical discrete distribution decomposition for match density estimation[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA: 2019: 6037–6046. doi: 10.1109/CVPR.2019.00620. [31] SONG Xiao, ZHAO Xu, FANG Liangji, et al. EdgeStereo: An effective multi-task learning network for stereo matching and edge detection[J]. International Journal of Computer Vision, 2020, 128(4): 910–930. doi: 10.1007/s11263-019-01287-w. [32] ZHANG Feihu, QI Xiaojuan, YANG Ruigang, et al. Domain-invariant stereo matching networks[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 420–439. doi: 10.1007/978-3-030-58536-5_25. [33] CAI Changjiang, POGGI M, MATTOCCIA S, et al. Matching-space stereo networks for cross-domain generalization[C]. 2020 International Conference on 3D Vision, Fukuoka, Japan, 2020: 364–373. doi: 10.1109/3DV50981.2020.00046. [34] LING Zhi, YANG Kai, LI Jinlong, et al. Domain-adaptive modules for stereo matching network[J]. Neurocomputing, 2021, 461: 217–227. doi: 10.1016/j.neucom.2021.06.004. [35] LIU Rui, YANG Chengxi, SUN Wenxiu, et al. StereoGAN: Bridging synthetic-to-real domain gap by joint optimization of domain translation and stereo matching[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 12754–12763. doi: 10.1109/CVPR42600.2020.01277. [36] CHUAH Weiqin, TENNAKOON R, HOSEINNEZHAD R, et al. ITSA: An information-theoretic approach to automatic shortcut avoidance and domain generalization in stereo matching networks[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 13012–13022. doi: 10.1109/CVPR52688.2022.01268. [37] ZHANG Jiawei, WANH Xiang, BAI Xiao, et al. Revisiting domain generalized stereo matching networks from a feature consistency perspective[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 12991–13001. doi: 10.1109/CVPR52688.2022.01266. -

 下载:
下载:





图(6) / 表(7)
计量
- 文章访问数: 1229
- HTML全文浏览量: 732
- PDF下载量: 73
- 被引次数: 0
