

Ultra High-speed High-precision Analog Subtractor Applied to Always-on Intelligent Visual Sense-computing System
-
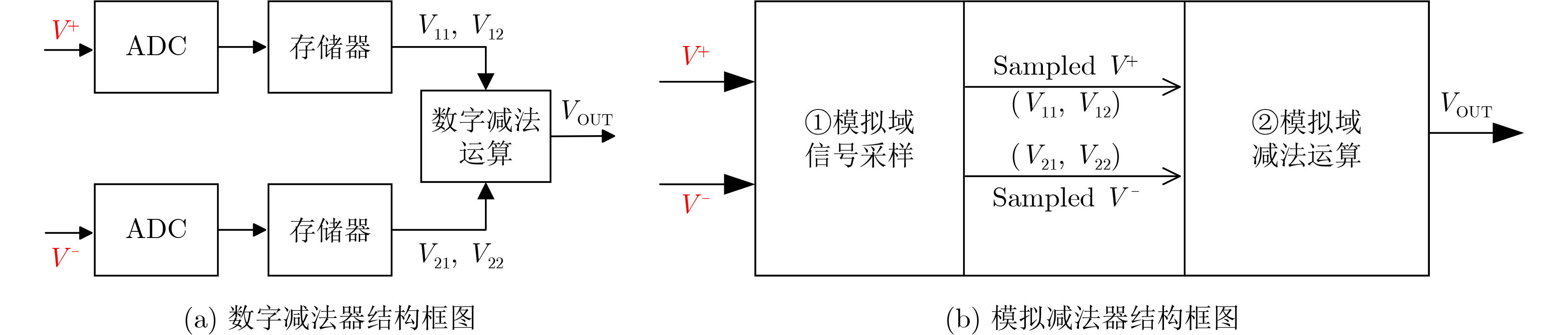
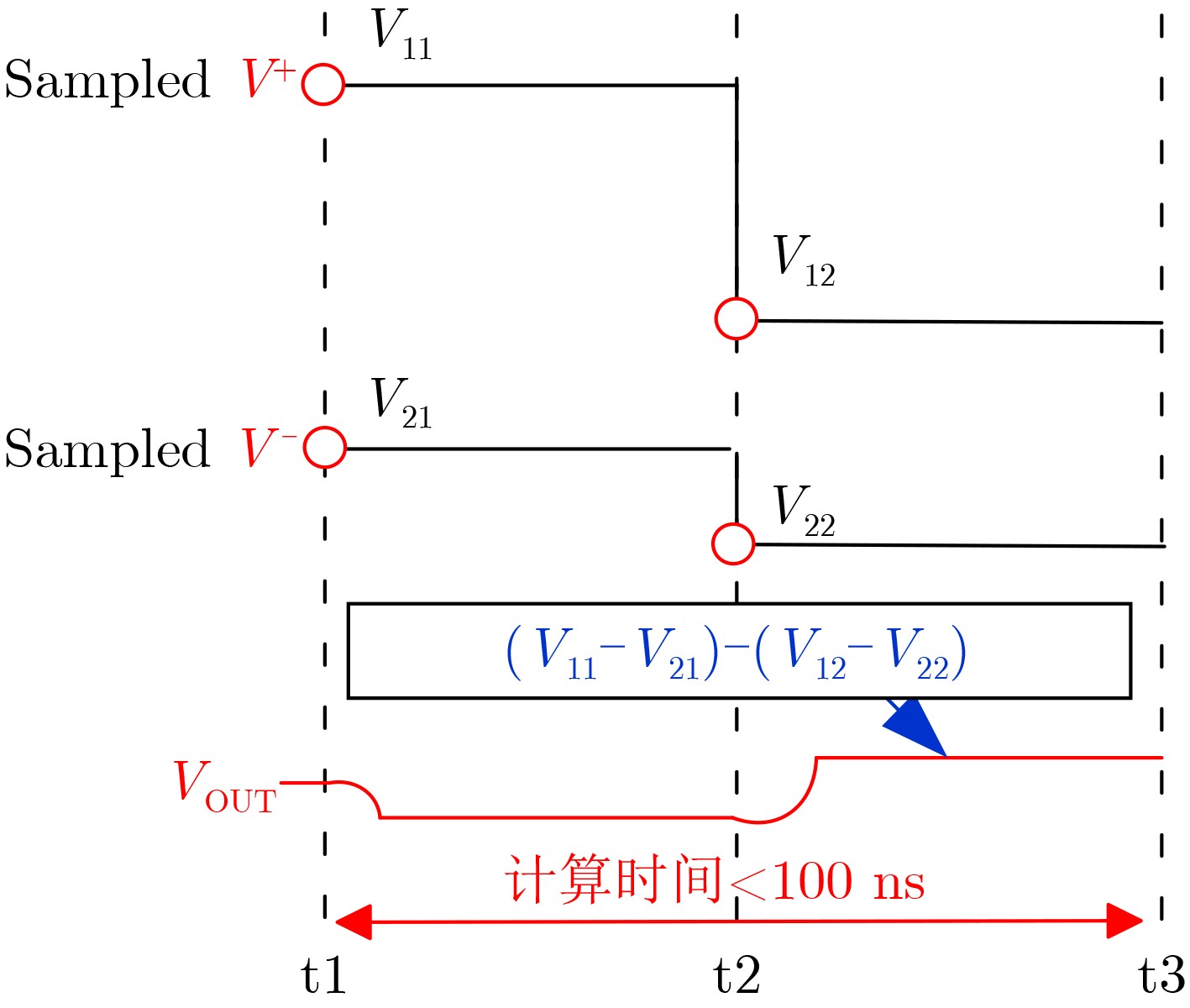
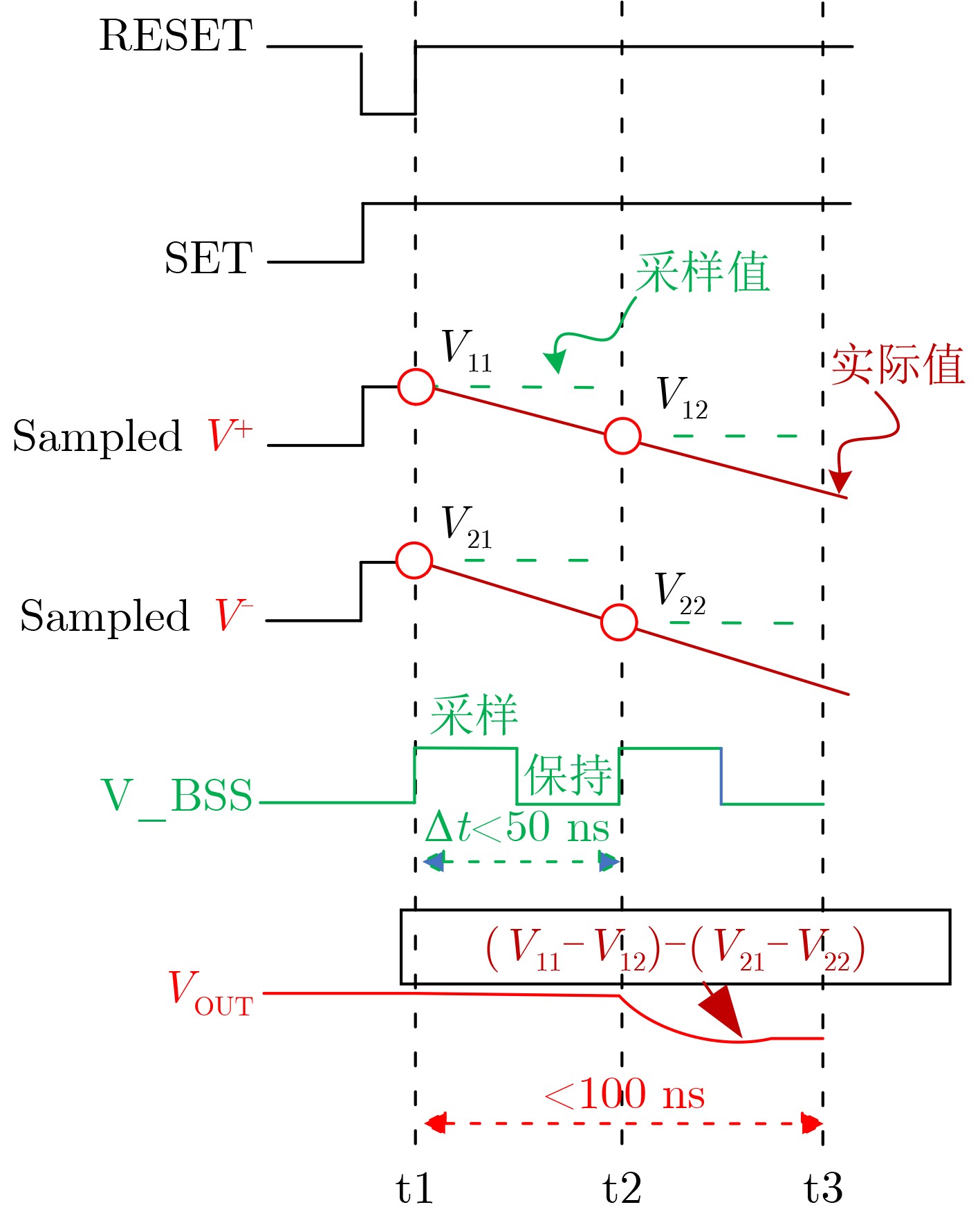
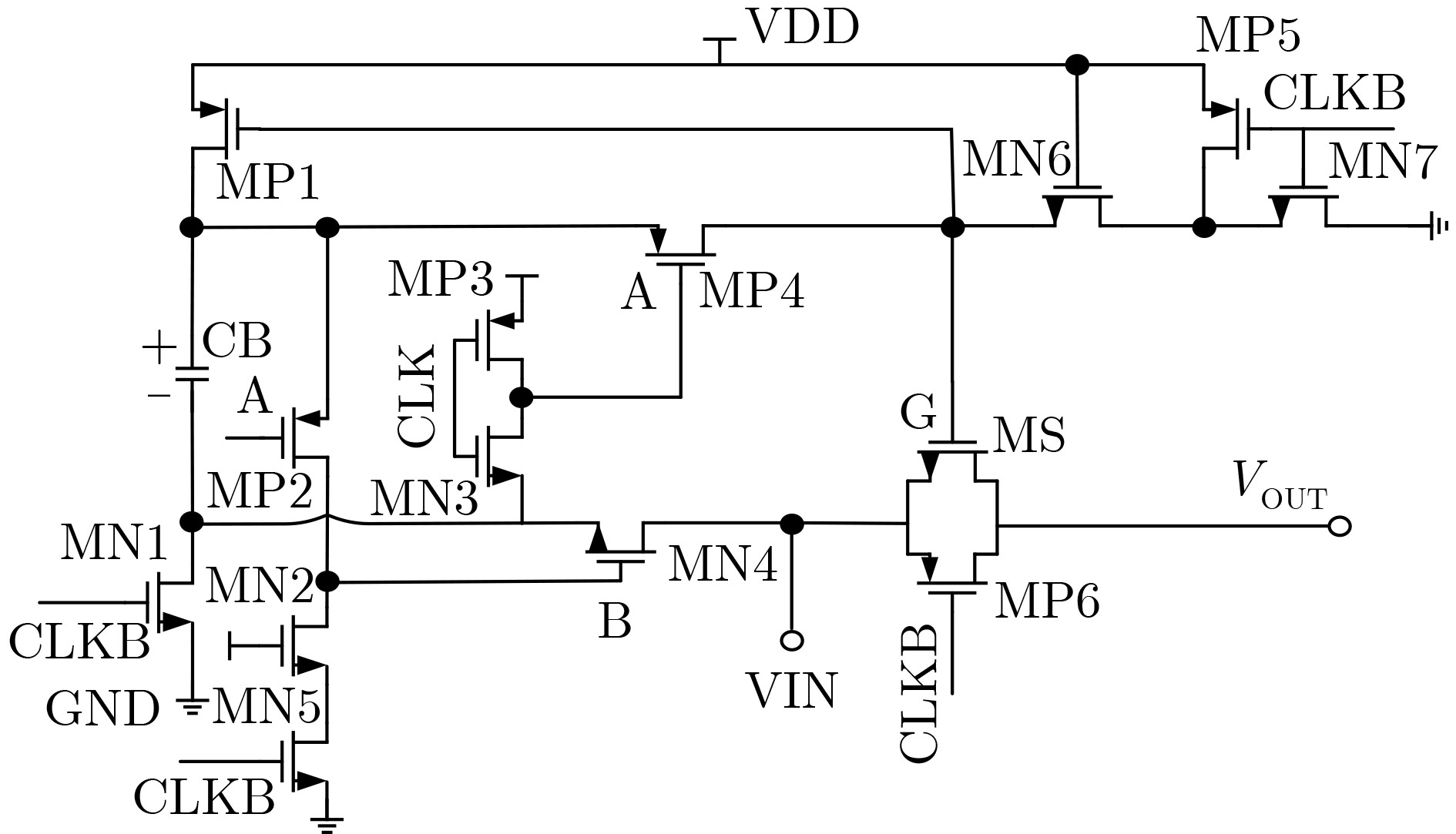
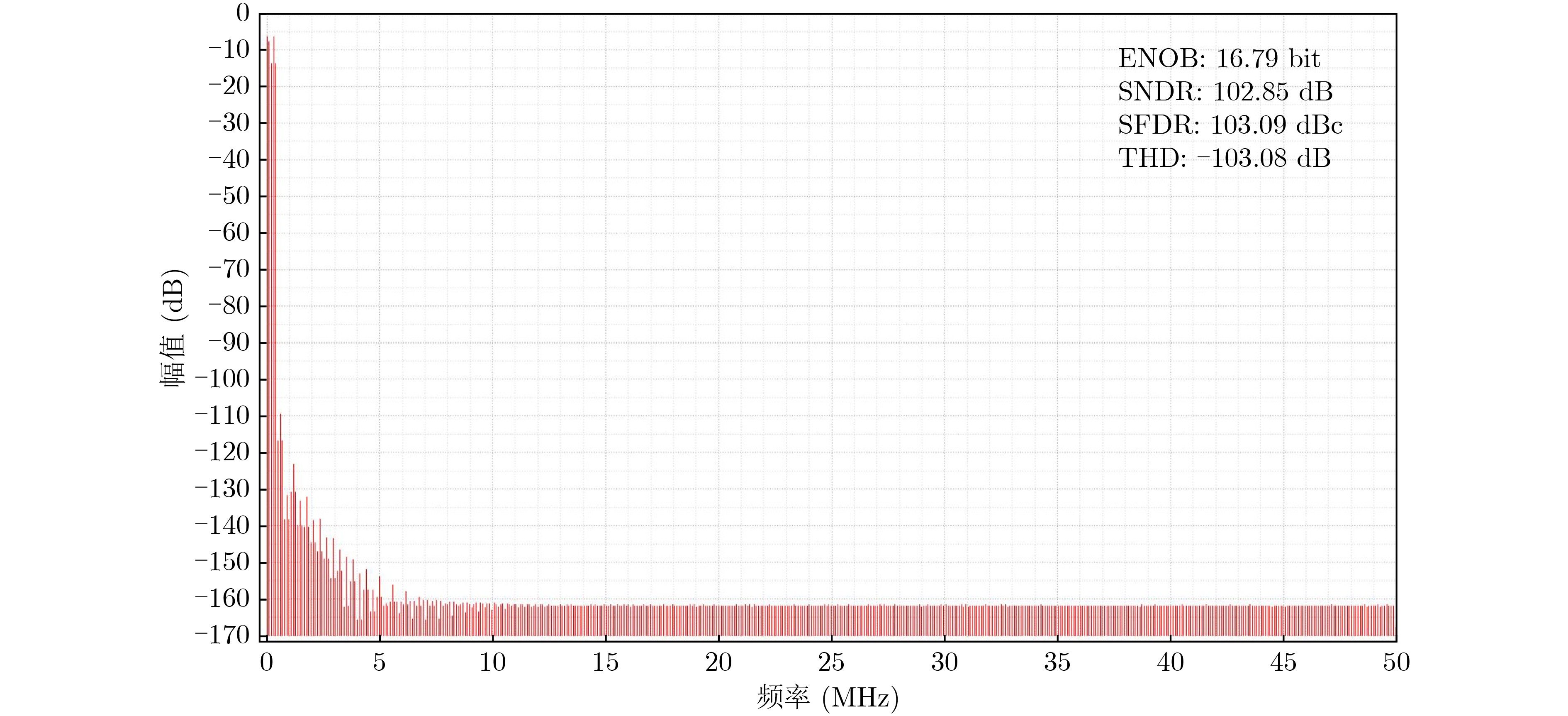
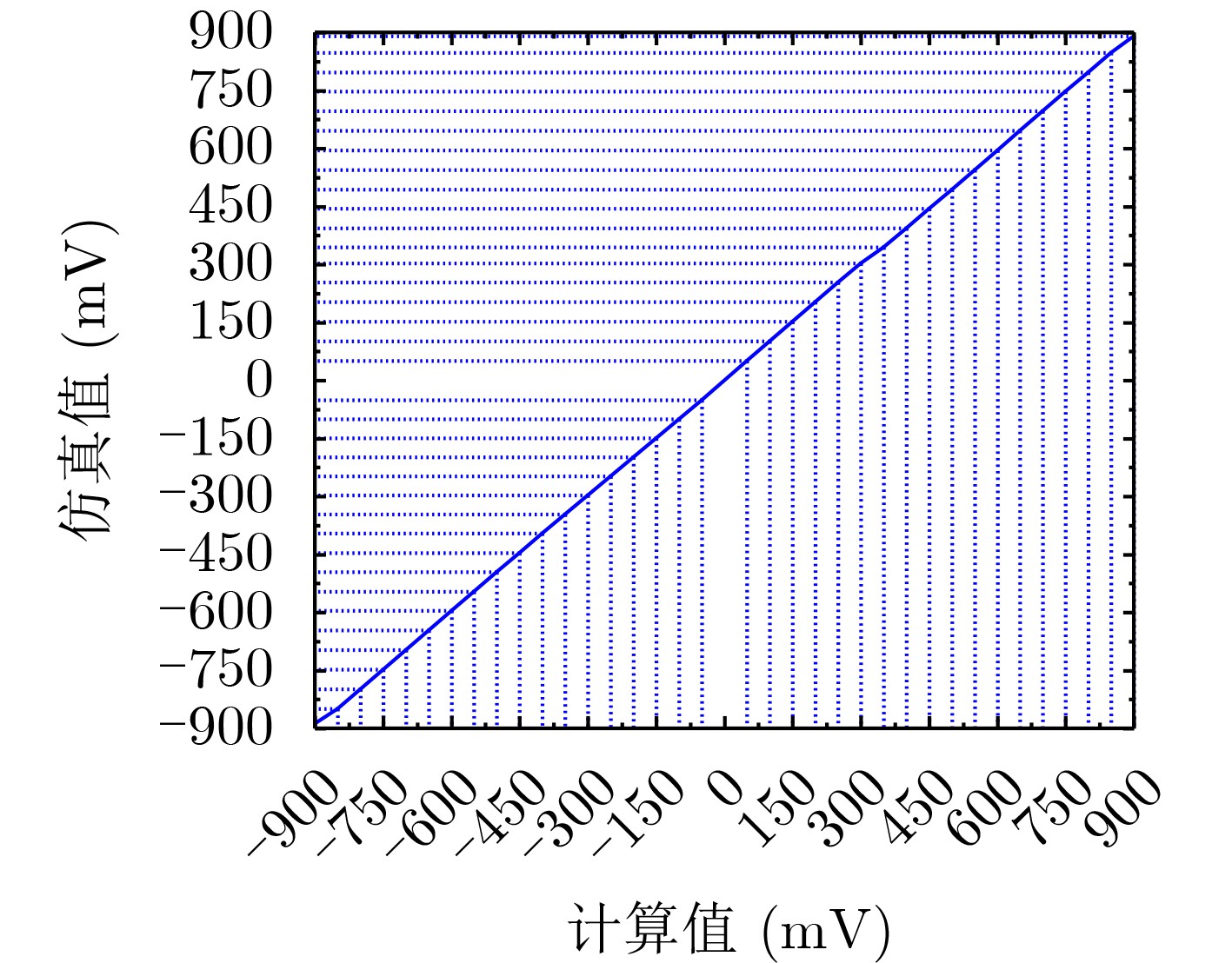
摘要: 常开型智能视觉感算系统对图像边缘特征提取的精度和实时性要求更高,其硬件能耗也随之暴增。采用模拟减法器代替传统数字处理在模拟域同步实现感知和边缘特征提取,可有效降低感存算一体系统的整体能耗,但与此同时,突破10–7 s数量级的长计算时间也成为了模拟减法器设计的瓶颈。该文提出一种新型的模拟减法运算电路结构,由模拟域的信号采样和减法运算两个功能电路组成。信号采样电路进一步由经改进的自举采样开关和采样电容组成;减法运算则由所提出的一种新型开关电容式模拟减法电路执行,可在2次采样时间内实现3次减法运算的高速并行处理。基于TSMC 180 nm/1.8 V CMOS工艺,完成整体模拟减法运算电路的设计。仿真实验结果表明,该减法器能够实现在模拟域中信号采样与计算的同步并行处理,一次并行处理的周期仅为20 ns,具备高速计算能力;减法器的计算取值范围宽至–900~900 mV,相对误差小于1.65%,最低仅为0.1%左右,处理精度高;电路能耗为25~27.8 pJ,处于中等可接受水平。综上,所提模拟减法器具备良好的速度、精度和能耗的性能平衡,可有效适用于高性能常开型智能视觉感知系统。Abstract: Always-on intelligent visual sense-computing (Senputing) system has higher requirement on the accuracy and real-time of edge feature extraction on target image, and thus the accompanying hardware energy consumption increases accordingly. Since an analog subtracter can realize visual sensing and edge feature extraction synchronously in analogue domain instead of the traditional digital processing, the overall energy consumption of sensing-storage-computing integrated system can be effectively reduced. But meanwhile, the long calculation time beyond the order of 10–7 s has also become the bottleneck of design of analog subtracter circuits. A novel analogue subtraction circuit structure is proposed in this paper, which consists of two functional circuits in analogue domain: signal sampling and subtraction module. The signal sampling circuit is further composed of an improved bootstrapped sampling switch and a pair of sampling capacitors; The subtraction operation is performed by a novel switched capacitor analog subtraction circuit, which can realize high-speed parallel processing of three subtraction operations in two sampling times. Based on TSMC 180 nm/1.8 V CMOS technology, the design of the whole analog subtraction circuit is implemented. The simulation results show that, The proposed analog subtracter can realize synchronous parallel processing of signal sampling and computation in analogue domain, and the cycle of one parallel processing is only 20 ns, which has high-speed computing capability. The calculated value range of the subtracter is sufficiently wide from –900~900 mV, the relative error is less than 1.65%, the lowest one is only about 0.1%, which proves that the computing accuracy is high; The energy consumption is 25~27.8 pJ, which is in the acceptable medium level. Therefore, the proposed analog subtracter has a significant performance trade-off on speed, precision and energy consumption, and can be effectively applied to high-performance always-on intelligent visual senputing system.
-
[1] HSU Y C and CHANG R C H. Intelligent chips and technologies for AIoT era[C]. Proceedings of 2020 IEEE Asian Solid-State Circuits Conference, Hiroshima, Japan, 2020: 1–4. doi: 10.1109/A-SSCC48613.2020.9336122. [2] HOCKLEY W E. The picture superiority effect in associative recognition[J]. Memory & Cognition, 2008, 36(7): 1351–1359. doi: 10.3758/MC.36.7.1351. [3] 姚峰林. 数字图像处理及在工程中的应用[M]. 北京: 北京理工大学出版社, 2014.YAO Fenglin. Digital Image Processing and Application in Engineering[M]. Beijing: Beijing Institute of Technology Press, 2014. [4] CHOI J, SHIN J, KANG Dongwu, et al. Always-on CMOS image sensor for mobile and wearable devices[J]. IEEE Journal of Solid-State Circuits, 2016, 51(1): 130–140. doi: 10.1109/JSSC.2015.2470526. [5] CHIOU A Y C and HSIEH C C. An ULV PWM CMOS imager with adaptive-multiple-sampling linear response, HDR imaging, and energy harvesting[J]. IEEE Journal of Solid-State Circuits, 2019, 54(1): 298–306. doi: 10.1109/JSSC.2018.2870559. [6] AL BAHOU A, KARUNARATNE G, ANDRI R, et al. XNORBIN: A 95 TOp/s/W hardware accelerator for binary convolutional neural networks[C]. Proceedings of 2018 IEEE Symposium in Low-Power and High-Speed Chips, Yokohama, Japan, 2018: 1–3. doi: 10.1109/CoolChips.2018.8373076. [7] KRESTINSKAYA O and JAMES A P. Binary weighted memristive analog deep neural network for near-sensor edge processing[C]. Proceedings of 2018 IEEE 18th International Conference on Nanotechnology, Cork, Ireland, 2018: 1–4. doi: 10.1109/NANO.2018.8626224. [8] ZHANG Jintao, WANG Zhuo, and VERMA N. In-memory computation of a machine-learning classifier in a standard 6T SRAM array[J]. IEEE Journal of Solid-State Circuits, 2017, 52(4): 915–924. doi: 10.1109/JSSC.2016.2642198. [9] JOKIC P, EMERY S, and BENINI L. BinaryEye: A 20 kfps streaming camera system on FPGA with real-time on-device image recognition using binary neural networks[C]. Proceedings of 2018 IEEE 13th International Symposium on Industrial Embedded Systems, Graz, Austria, 2018: 1–7. doi: 10.1109/SIES.2018.8442108. [10] LI Ziwei, XU Han, LIU Zheyu, et al. A 2.17μW@120fps ultra-low-power dual-mode CMOS image sensor with senputing architecture[C]. Proceedings of 2022 27th Asia and South Pacific Design Automation Conference, Taipei, China, 2022: 92–93. doi: 10.1109/ASP-DAC52403.2022.9712591. [11] TAKAHASHI N, FUJITA K, and SHIBATA T. A pixel-parallel self-similitude processing for multiple-resolution edge-filtering analog image sensors[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2009, 56(11): 2384–2392. doi: 10.1109/TCSI.2009.2015598. [12] TAKAHASHI N and SHIBATA T. A row-parallel cyclic-line-access edge detection CMOS image sensor employing global thresholding operation[C]. Proceedings of 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 2010: 625–628. doi: 10.1109/ISCAS.2010.5537512. [13] DORZHIGULOV A, BERDALIYEV Y, and JAMES A P. Coarse to fine difference edge detection with binary neural firing model[C]. Proceedings of 2017 International Conference on Advances in Computing, Communications and Informatics, Udupi, India, 2017: 1098–1102. doi: 10.1109/ICACCI.2017.8125988. [14] GARCIA-LAMONT J. Analogue CMOS prototype vision chip with Prewitt edge processing[J]. Analog Integrated Circuits and Signal Processing, 2012, 71(3): 507–514. doi: 10.1007/s10470-011-9694-6. [15] CHIU M Y, CHEN Guancheng, HUANG Y H, et al. A 0.56V/0.8V vision sensor with temporal contrast pixel and column-parallel local binary pattern extraction for dynamic depth sensing using stereo vision[C]. Proceedings of 2022 IEEE Asian Solid-State Circuits Conference, Taipei, China, 2022: 1–3. doi: 10.1109/A-SSCC56115.2022.9980799. [16] LIU Liqiao, REN Xu, ZHAO Kai, et al. FD-SOI-based pixel with real-time frame difference for motion extraction and image preprocessing[J]. IEEE Transactions on Electron Devices, 2023, 70(2): 594–599. doi: 10.1109/TED.2022.3231573. [17] XU Han, LIN Ningchao, LUO Li, et al. Senputing: An ultra-low-power always-on vision perception chip featuring the deep fusion of sensing and computing[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2022, 69(1): 232–243. doi: 10.1109/TCSI.2021.3090668. [18] JAKLIN M, GARCÍA-LESTA D, BREA V M, et al. Low-power techniques on a CMOS vision sensor chip for event generation by frame differencing with high dynamic range[C]. Proceedings of 2022 29th IEEE International Conference on Electronics, Circuits and Systems, Glasgow, United Kingdom, 2022: 1–4. doi: 10.1109/ICECS202256217.2022.9970907. [19] KRESTINSKAYA O and JAMES A P. Real-time analog pixel-to-pixel dynamic frame differencing with memristive sensing circuits[C]. Proceedings of 2018 IEEE SENSORS, New Delhi, India, 2018: 1–4. doi: 10.1109/ICSENS.2018.8589849. [20] NAZHAMAITI M, XU Han, LIU Zheyu, et al. NS-MD: Near-sensor motion detection with energy harvesting image sensor for always-on visual perception[J]. IEEE Transactions on Circuits and Systems II: Express Briefs, 2021, 68(9): 3078–3082. doi: 10.1109/TCSII.2021.3087840. [21] ABO A M and GRAY P R. A 1.5-V, 10-bit, 14.3-MS/s CMOS pipeline analog-to-digital converter[J]. IEEE Journal of Solid-State Circuits, 1999, 34(5): 599–606. doi: 10.1109/4.760369. [22] CAO Chao, ZHAO Wei, FAN Jihui, et al. A complementary high linearity bootstrap switch based on negative voltage bootstrap capacitor[J]. Microelectronics Journal, 2023, 133: 105695. doi: 10.1016/j.mejo.2023.105695. [23] ZHAO Wei, CAO Chao, FAN Jihui, et al. Improved complementary bootstrap switch based on negative voltage bootstrap capacitance[C]. Proceedings of 2022 IEEE 16th International Conference on Solid-State & Integrated Circuit Technology, Nangjing, China, 2022: 1–3. doi: 10.1109/ICSICT55466.2022.9963367. [24] WEI Cong, WEI Rongshan, and HE Minghua. Bootstrapped switch with improved linearity based on a negative-voltage bootstrapped capacitor[J]. IEICE Electronics Express, 2021, 18(7): 20210062. doi: 10.1587/elex.18.20210062. [25] KHAJEH M G and SOBHI J. An 87-dB-SNDR 1MS/s bilateral bootstrapped CMOS switch for sample-and-hold circuit[C]. Proceedings of 2020 28th Iranian Conference on Electrical Engineering, Tabriz, Iran, 2020: 1–5. doi: 10.1109/ICEE50131.2020.9260778. -


 下载:
下载:










图(15) / 表(2)
计量
- 文章访问数: 822
- HTML全文浏览量: 490
- PDF下载量: 55
- 被引次数: 0
