

Interference Performance Evaluation Method Based on Transfer Learning and Parameter Optimization
-
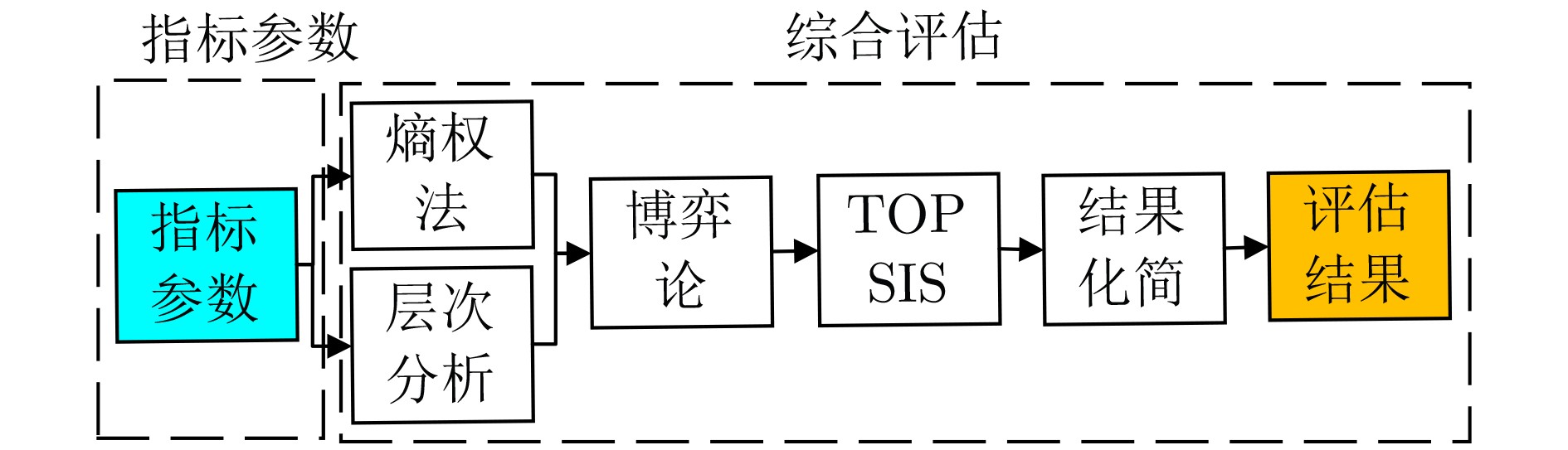
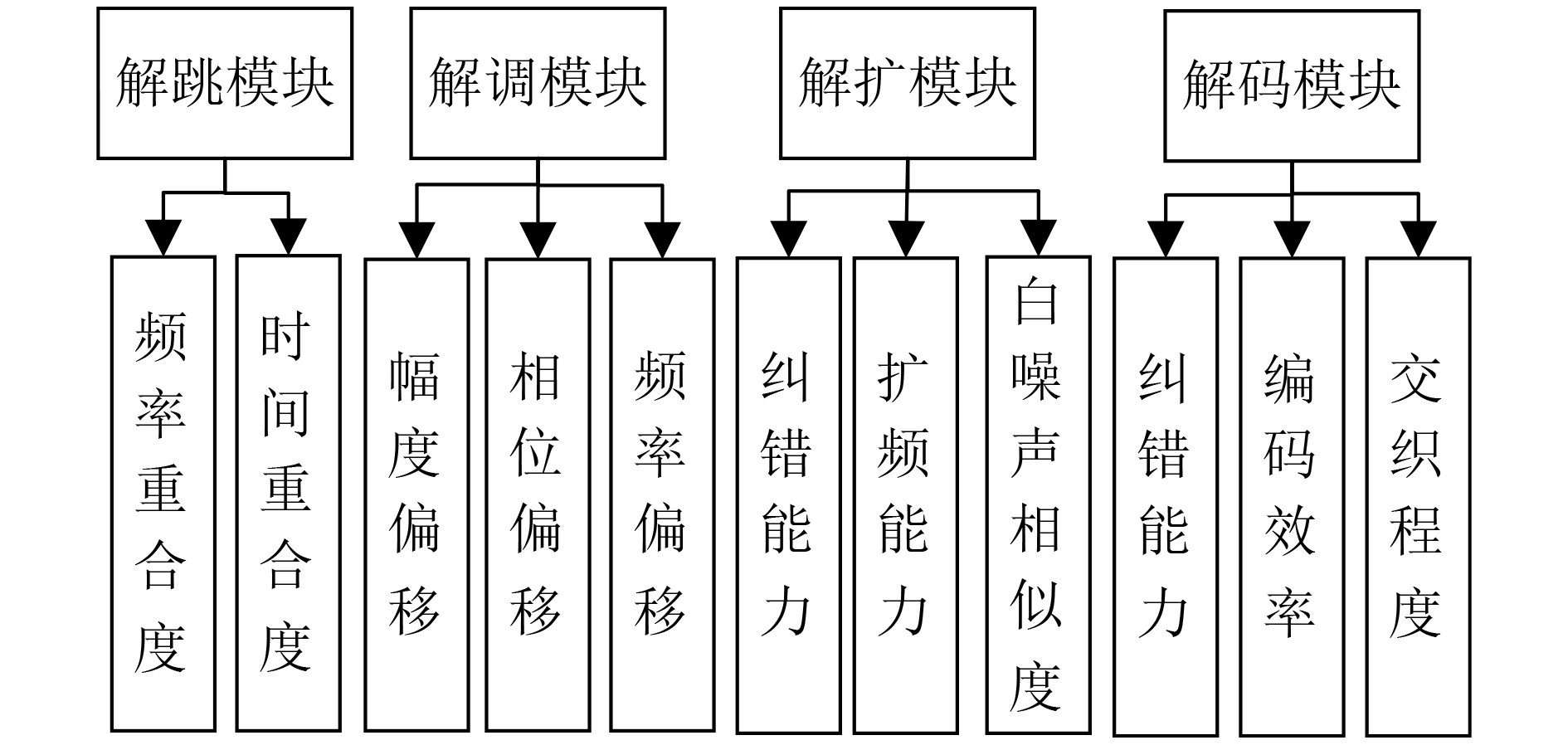
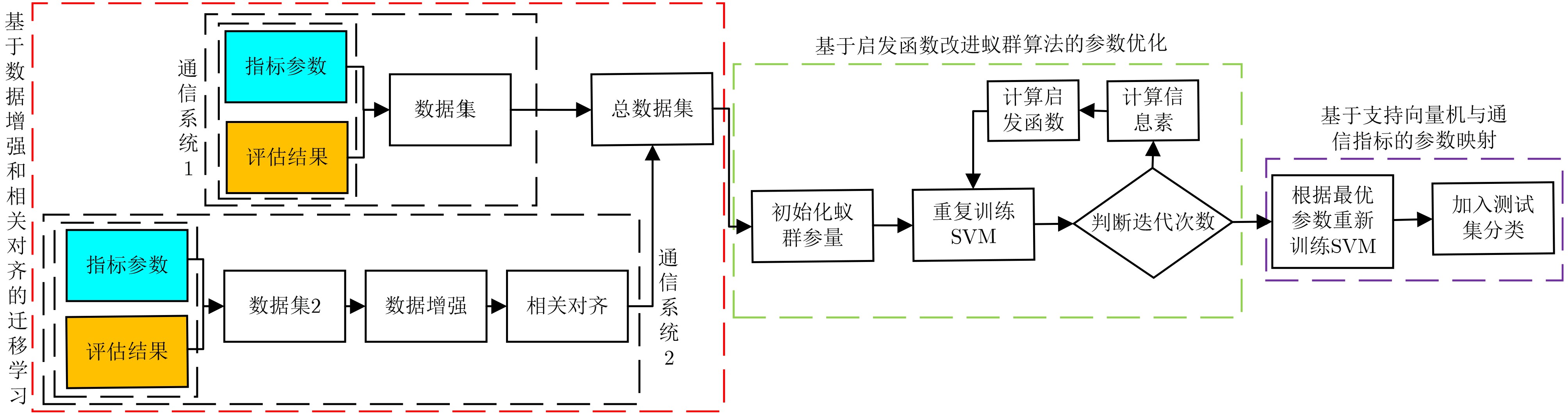
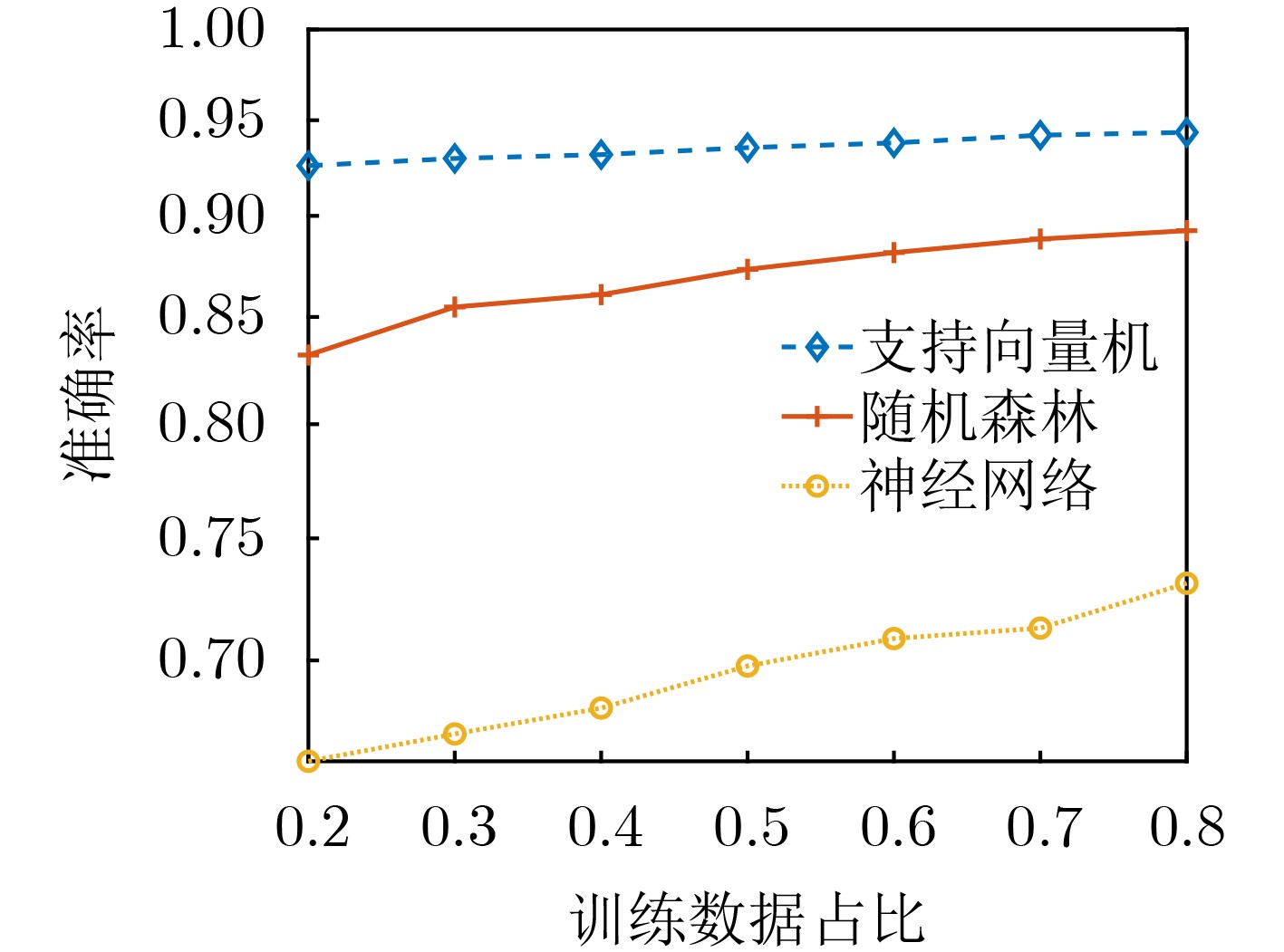
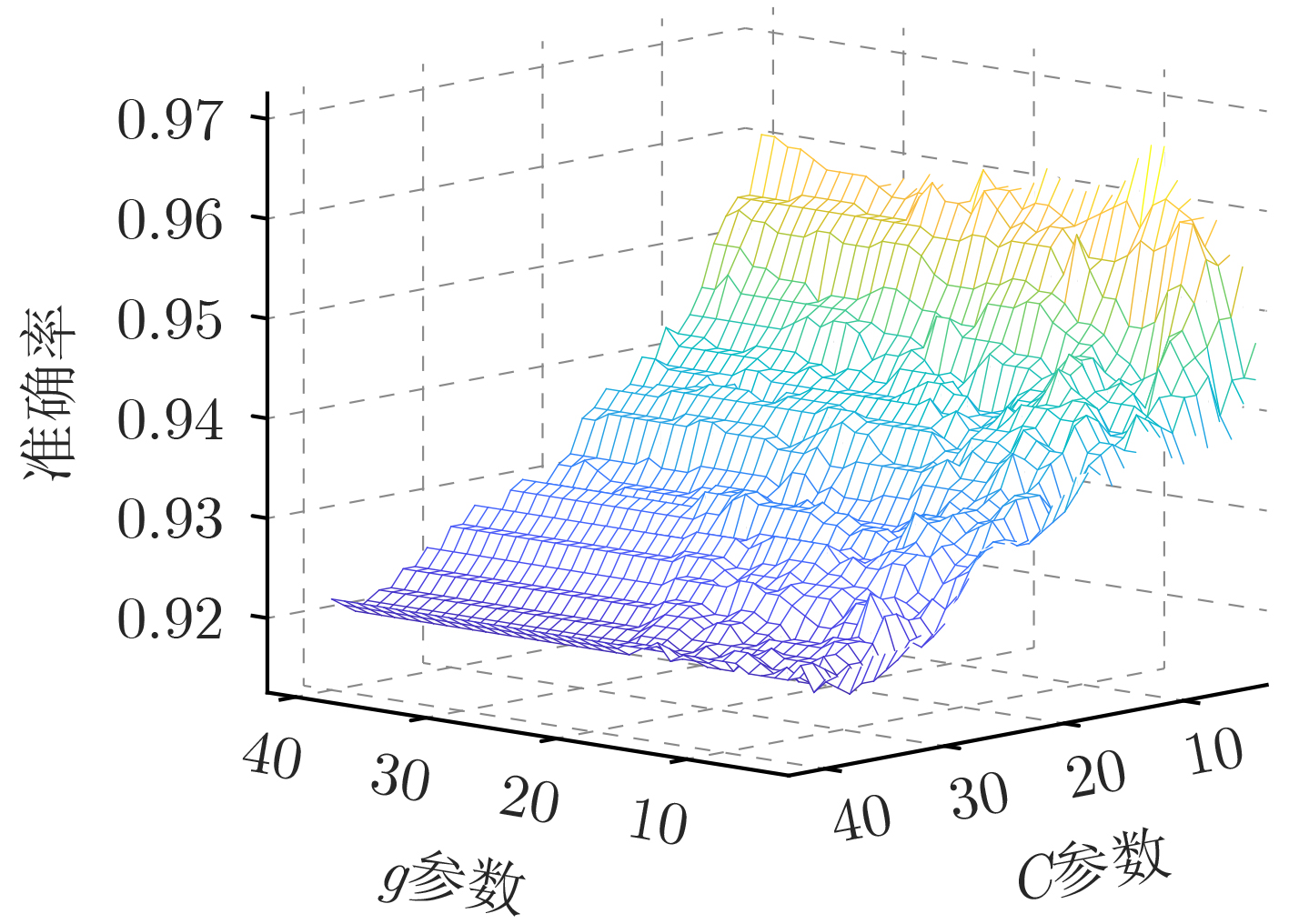
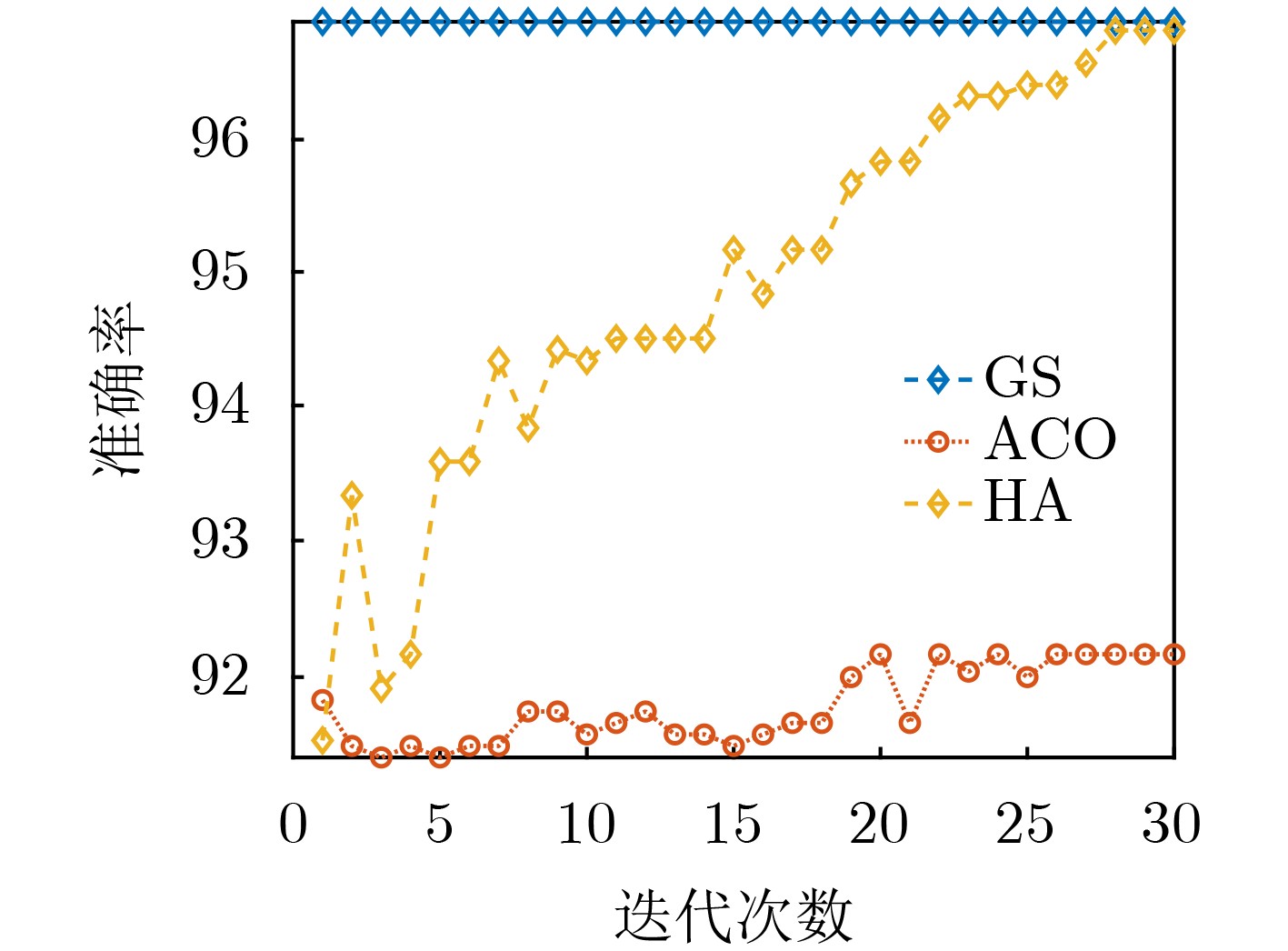
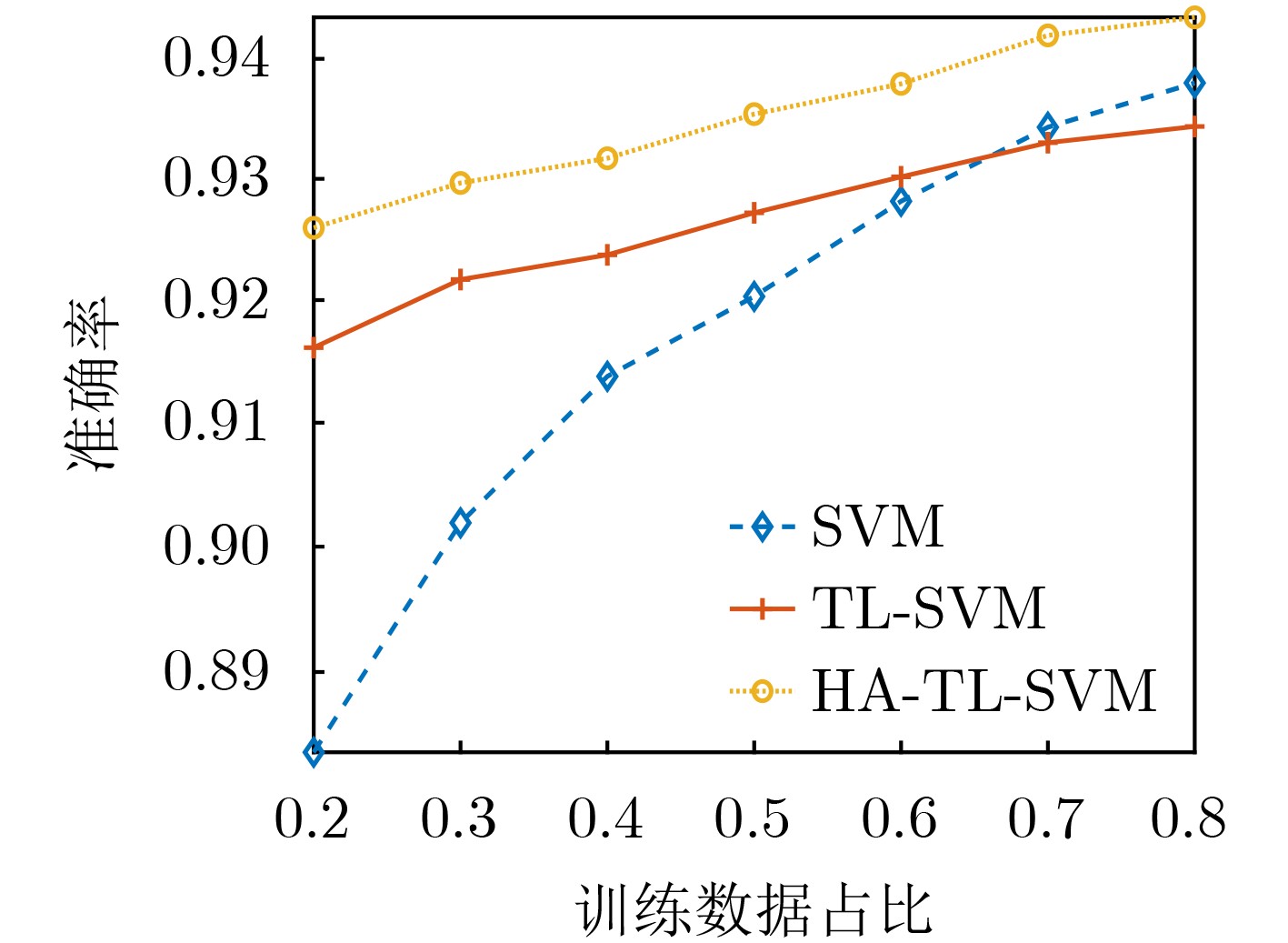
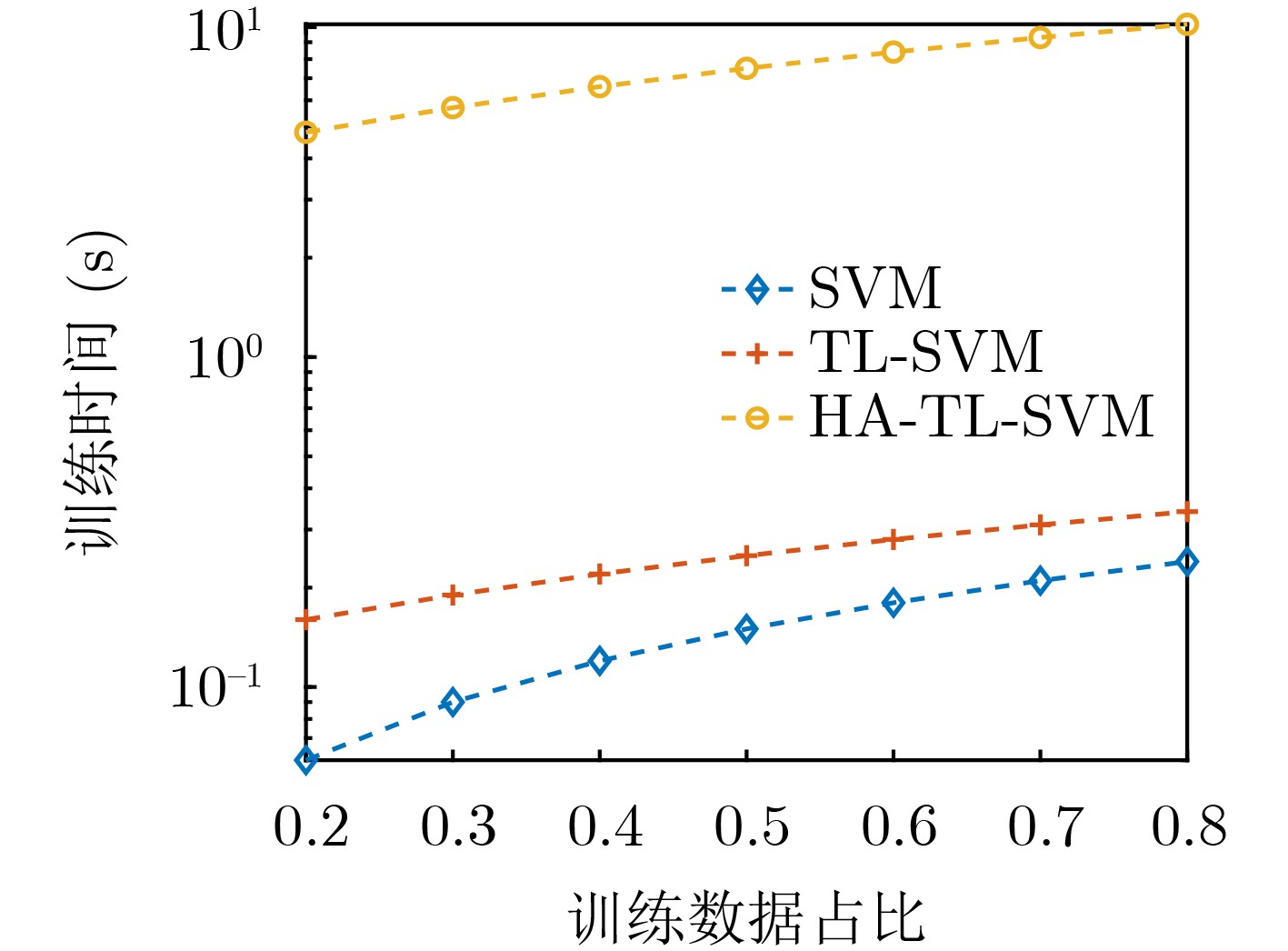
摘要: 针对数字通信系统中传统误码率评估导致干扰效能评估结果单一的问题,该文提出了一种基于迁移学习和参数优化的干扰效能评估方法。该方法选取各信号处理模块的核心参数作为机器学习的训练指标,并以优劣解距离的评估结果作为分类标准,采用支持向量机训练评估模型。通过改进蚁群算法的全局搜索能力和迁移学习的知识传递特性分别解决了支持向量机中的参数优化问题和训练样本中的数据缺失问题。仿真实验结果表明,掌握源域数据集的支持向量机在模型准确度方面提升4.2%,牺牲初始收敛能力的参数优化与最优解的靠近程度提升4.7%,并且可以应用于数字通信系统的干扰效能评估。Abstract: A novel method for evaluating interference performance based on Transfer Learning(TL) and parameter optimization is proposed to address the limitation of single evaluation results obtained using traditional error rate assessment in digital communication systems. This method selects the core parameters of each signal processing module as the training index of machine learning and considers the evaluation results of the Technique for Order Preference by Similarity to the Ideal Solution (TOPSIS) as the classification standard. An SVM (Support Vector Machine) is used to train and evaluate the model. The parameter optimization problem in the SVM is addressed by enhancing the global search capability of Ant Colony Optimization (ACO). Moreover, the issue of missing data in the training samples is solved based on the knowledge transfer properties of TL. The results of the simulation experiments demonstrate that the SVM with access to the source domain dataset increases the model accuracy by 4.2%. Parameter optimization, which sacrifices the initial convergence ability, enhances the proximity to the optimal solution by 4.7%.In addition, it can be employed to evaluate the interference performance of digital communication systems.
-
[1] 王月, 孙付平, 郝金明, 等. GNSS欺骗干扰效能评估指标与方法研究综述[J]. 信息工程大学学报, 2021, 22(1): 8–15. doi: 10.3969/j.issn.1671-0673.2021.01.002.WANG Yu, SUN Fuping, HAO Jinming, et al. Research status and prospect of evaluation indexes and evaluation methods of GNSS spoofing efficiency[J]. Journal of Information Engineering University, 2021, 22(1): 8–15. doi: 10.3969/j.issn.1671-0673.2021.01.002. [2] 周治国, 马文浩, 刘杰强, 等. 小卫星健康状态自主模糊综合评估方法[J]. 电子与信息学报, 2022, 44(10): 3553–3565. doi: 10.11999/JEIT210657.ZHOU Zhiguo, MA Wenhao, LIU Jieqiang, et al. Autonomous fuzzy comprehensive evaluation method for small satellite health state[J]. Journal of Electronics & Information Technology, 2022, 44(10): 3553–3565. doi: 10.11999/JEIT210657. [3] 宿晨庚, 郭树人, 刘旭楠, 等. 北斗三号基本系统空间信号质量评估[J]. 电子与信息学报, 2020, 42(11): 2689–2697. doi: 10.11999/JEIT190683.SU Chengeng, GUO Shuren, LIU Xunan, et al. Signal quality assessment of BDS-3 preliminary system[J]. Journal of Electronics & Information Technology, 2020, 42(11): 2689–2697. doi: 10.11999/JEIT190683. [4] 施端阳, 林强, 胡冰, 等. 综合评估方法研究综述[J]. 中国科技信息, 2022(22): 124–127.SHI Duanyang, LIN Qiang, HU Bing, et al. A review of research on comprehensive evaluation methods[J]. China Science and Technology Information, 2022(22): 124–127. [5] 李晓辉, 方坤, 樊韬, 等. 基于支持向量机的无人机定位信号分离算法研究[J]. 电子与信息学报, 2021, 43(9): 2601–2607. doi: 10.11999/JEIT200725.LI Xiaohui, FANG Kun, FAN Tao, et al. Research on unmanned aerial vehicle location signal separation algorithm based on support vector machines[J]. Journal of Electronics & Information Technology, 2021, 43(9): 2601–2607. doi: 10.11999/JEIT200725. [6] 燕忠, 袁春伟. 基于蚁群智能和支持向量机的人脸性别分类方法[J]. 电子与信息学报, 2004, 26(8): 1177–1182.YAN Zhong and YUAN Chunwei. Gender classification based on ant colony and SVM for frontal facial images[J]. Journal of Electronics & Information Technology, 2004, 26(8): 1177–1182. [7] 邵志文, 周勇, 谭鑫, 等. 基于深度学习的表情动作单元识别综述[J]. 电子学报, 2022, 50(8): 2003–2017. doi: 10.12263/DZXB. 20210639.SHAO Zhiwen, ZHOU Yong, TAN Xin, et al. Survey of expression action unit recognition based on deep learning[J]. Acta Electronica Sinica, 2022, 50(8): 2003–2017. doi: 10.12263/DZXB.20210639. [8] 吴军君, 王涛, 王英楷, 等. 基于迁移学习的LiPON制备工艺模拟优化[J]. 电子学报, 2023, 51(3): 687–693. doi: 10.12263/DZXB.20211241.WU Junjun, WANG Tao, WANG Yingkai, et al. Transfer-learning-based virtual process optimization for LiPON[J]. Acta Electronica Sinica, 2023, 51(3): 687–693. doi: 10.12263/DZXB.20211241. [9] 张立秀, 张淑娟, 孙海霞, 等. 高光谱技术结合网格搜索优化支持向量机的桃缺陷检测[J]. 食品与发酵工业, 2023, 49(16): 269–275. doi: 10.13995/j.cnki.11-1802/ts.033557.ZHANG Lixiu, ZHANG Shujuan, SUN Haixia, et al. Hyperspectral technology combined with grid search optimized support vector machines to detect defects of peach[J]. Food and Fermentation Industries, 2023, 49(16): 269–275. doi: 10.13995/j.cnki.11-1802/ts.033557. [10] 宋佳艳, 苏圣超. 基于改进蚁群优化算法的自动驾驶多车协同运动规划[J]. 计算机工程, 2022, 48(11): 299–305,313. doi: 10.19678/j.issn.1000-3428.0062824.SONG Jiayan and SU Shengchao. Multi-vehicle collaborative motion planning for autonomous driving based on improved ant colony optimization algorithm[J]. Computer Engineering, 2022, 48(11): 299–305,313. doi: 10.19678/j.issn.1000-3428.0062824. [11] 吴月娴, 葛临东, 许志勇. 常用数字调制信号识别的一种新方法[J]. 电子学报, 2007, 35(4): 782–785. doi: 10.3321/j.issn:0372-2112.2007.04.035.WU Yuexian, GE Lindong, and XU Zhiyong. A novel identification method for commonly used digital modulations[J]. Acta Electronica Sinica, 2007, 35(4): 782–785. doi: 10.3321/j.issn:0372-2112.2007.04.035. [12] LIN Haifeng, DU Lin, and LIU Yunfei. Soft decision cooperative spectrum sensing with entropy weight method for cognitive radio sensor networks[J]. IEEE Access, 2020, 8: 109000–109008. doi: 10.1109/ACCESS.2020.3001006. [13] MATHEW M, CHAKRABORTTY R K, and RYAN M J. Selection of an optimal maintenance strategy under uncertain conditions: An interval type-2 fuzzy AHP-TOPSIS method[J]. IEEE Transactions on Engineering Management, 2022, 69(4): 1121–1134. doi: 10.1109/TEM.2020.2977141. [14] WANG Yue, HAO Jinming, LIU Weiping, et al. Dynamic evaluation of GNSS spoofing and jamming efficacy based on game theory[J]. IEEE Access, 2020, 8: 13845–13857. doi: 10.1109/ACCESS.2020.2965728. [15] LIU Huchen, WANG Lien, LI Zhiwu, et al. Improving risk evaluation in FMEA with cloud model and hierarchical TOPSIS method[J]. IEEE Transactions on Fuzzy Systems, 2019, 27(1): 84–95. doi: 10.1109/TFUZZ.2018.2861719. [16] 夏海浜, 黄鸿云, 丁佐华. 基于迁移学习与支持向量机的服装舒适度评估[J]. 纺织学报, 2020, 41(6): 125–131. doi: 10.13475/j.fzxb.20191101007.XIA Haibang, HUANG Hongyun, and DING Zuohua. Clothing comfort evaluation based on transfer learning and support vector machine[J]. Journal of Textile Research, 2020, 41(6): 125–131. doi: 10.13475/j.fzxb.20191101007. [17] 余游, 冯林, 王格格, 等. 一种基于伪标签的半监督少样本学习模型[J]. 电子学报, 2019, 47(11): 2284–2291. doi: 10.3969/j.issn.0372-2112.2019.11.007.YU You, FENG Lin, WANG Gege, et al. A few-shot learning model based on semi-supervised with pseudo label[J]. Acta Electronica Sinica, 2019, 47(11): 2284–2291. doi: 10.3969/j.issn.0372-2112.2019.11.007. [18] 赵晨阳, 王俊岭. 基于隐含上下文支持向量机的服务推荐方法[J]. 通信学报, 2019, 40(9): 61–73. doi: 10.11959/j.issn.1000-436x.2019190.ZHAO Chenyang and WANG Junling. Service recommendation method based on context-embedded support vector machine[J]. Journal on Communications, 2019, 40(9): 61–73. doi: 10.11959/j.issn.1000-436x.2019190. [19] ZHANG Hong and ZHANG Yifan. An improved sparrow search algorithm for optimizing support vector machines[J]. IEEE Access, 2023, 11: 8199–8206. doi: 10.1109/ACCESS.2023.3234579. [20] 线岩团, 陈文仲, 余正涛, 等. 融合类别先验Mixup数据增强的罪名预测方法[J]. 自动化学报, 2022, 48(8): 2097–2107. doi: 10.16383/j.aas.c200908.XIAN Yantuan, CHEN Wenzhong, YU Zhengtao, et al. Category prior guided Mixup data argumentation for charge prediction[J]. Acta Automatica Sinica, 2022, 48(8): 2097–2107. doi: 10.16383/j.aas.c200908. [21] 王毅, 李晓梦, 耿国华, 等. 基于直觉模糊熵的混合粒子群优化算法[J]. 电子学报, 2021, 49(12): 2381–2389. doi: 10.12263/DZXB.20201387.WANG Yi, LI Xiaomeng, GENG Guohua, et al. Hybrid particle swarm optimization algorithm based on intuitionistic fuzzy entropy[J]. Acta Electronica Sinica, 2021, 49(12): 2381–2389. doi: 10.12263/DZXB.20201387. [22] 郑威迪, 李志刚, 贾涵中, 等. 基于改进型鲸鱼优化算法和最小二乘支持向量机的炼钢终点预测模型研究[J]. 电子学报, 2019, 47(3): 700–706. doi: 10.3969/j.issn.0372-2112.2019.03.026.ZHENG Weidi, LI Zhigang, JIA Hanzhong, et al. Research on prediction model of steelmaking end point based on LWOA and LSSVM[J]. Acta Electronica Sinica, 2019, 47(3): 700–706. doi: 10.3969/j.issn.0372-2112.2019.03.026. [23] 徐鹏政, 于启月, 林泓池, 等. 基于毫米波通信的新型机间数据链系统[J]. 通信学报, 2023, 44(4): 27–37. doi: 10.11959/j.issn.1000-436x.2023057.XU Pengzheng, YU Qiyue, LIN Hongchi, et al. Novel air-to-air data link system based on millimeter wave communication[J]. Journal on Communications, 2023, 44(4): 27–37. doi: 10.11959/j.issn.1000-436x.2023057. -

 下载:
下载:
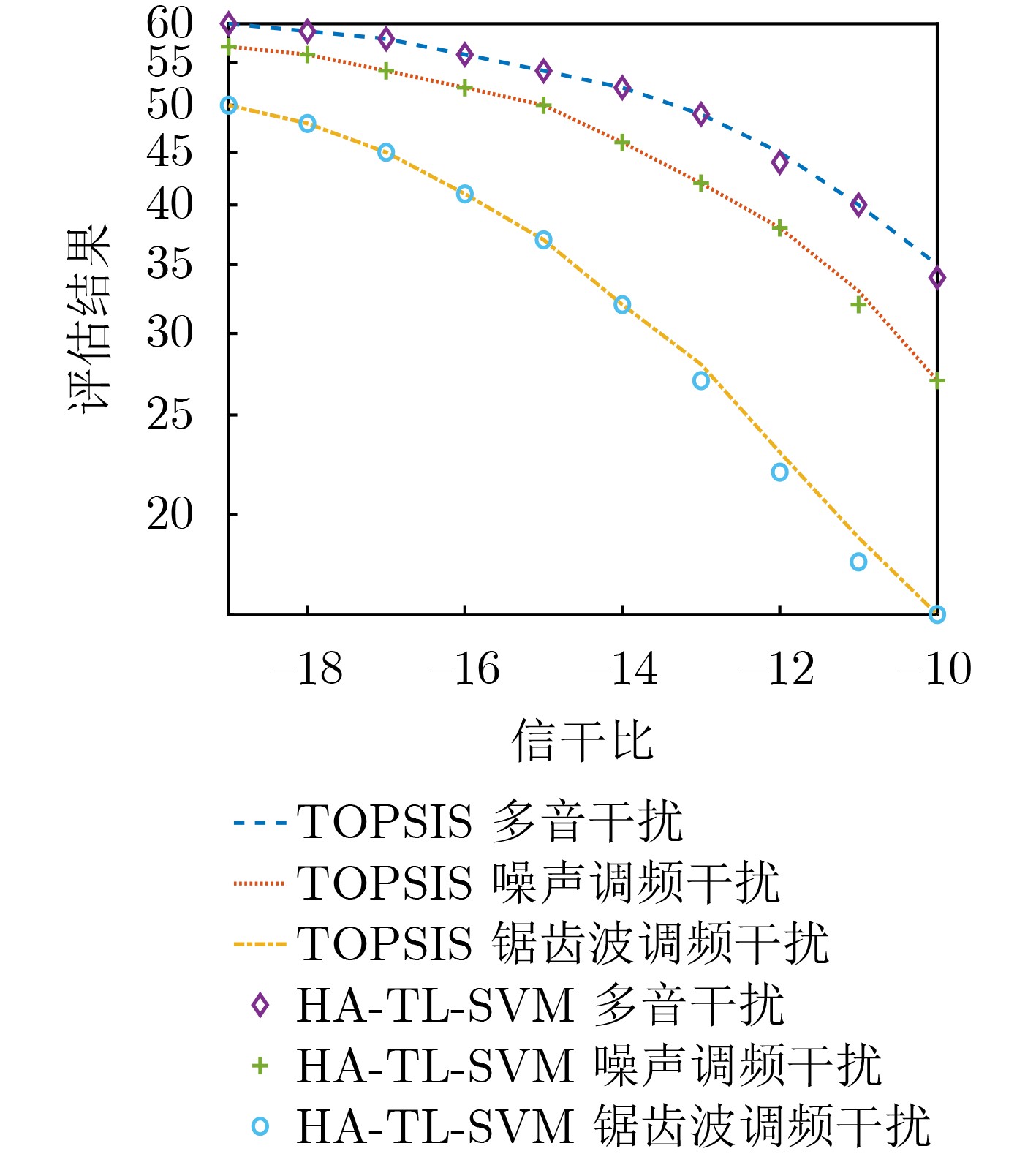
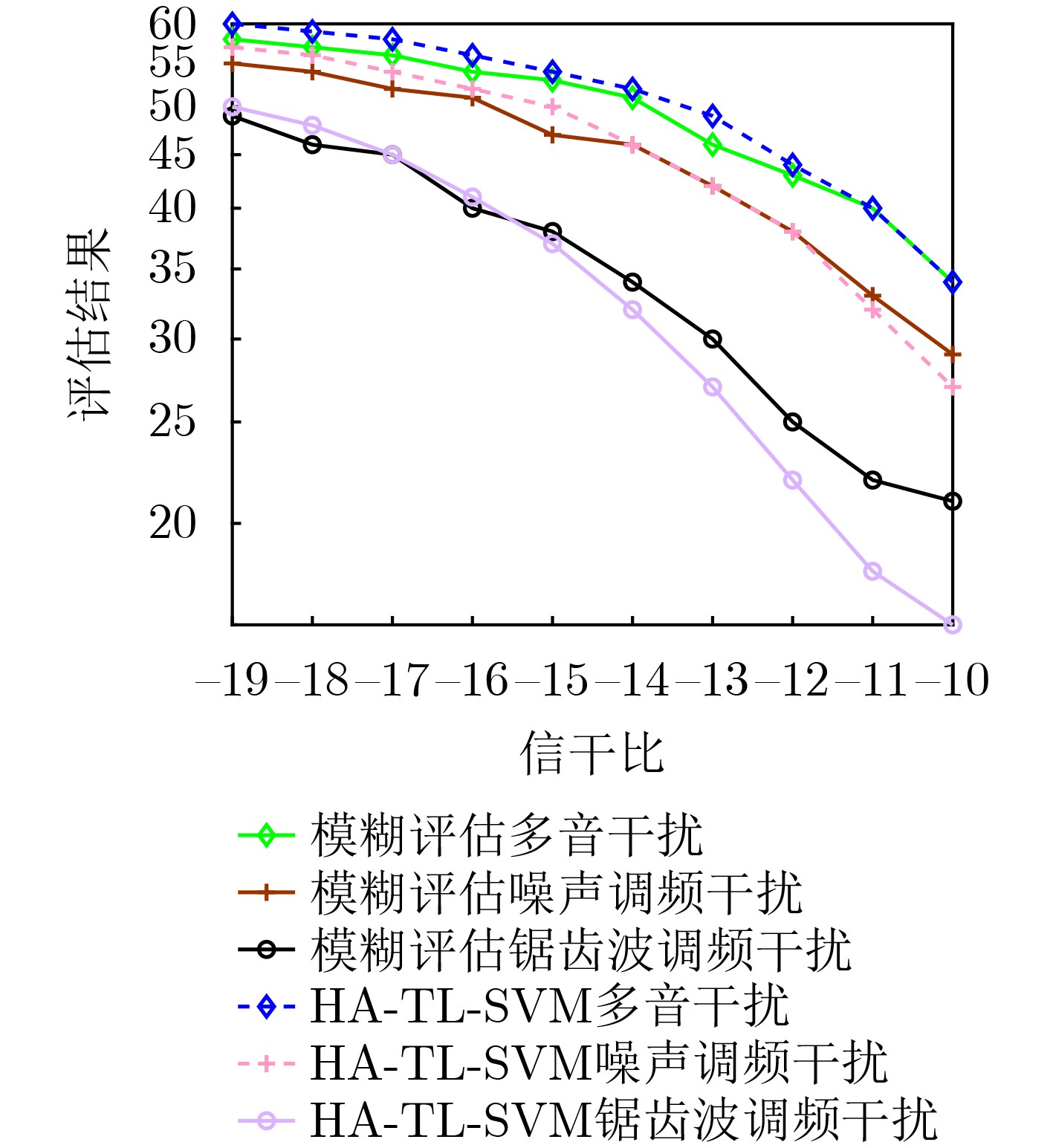
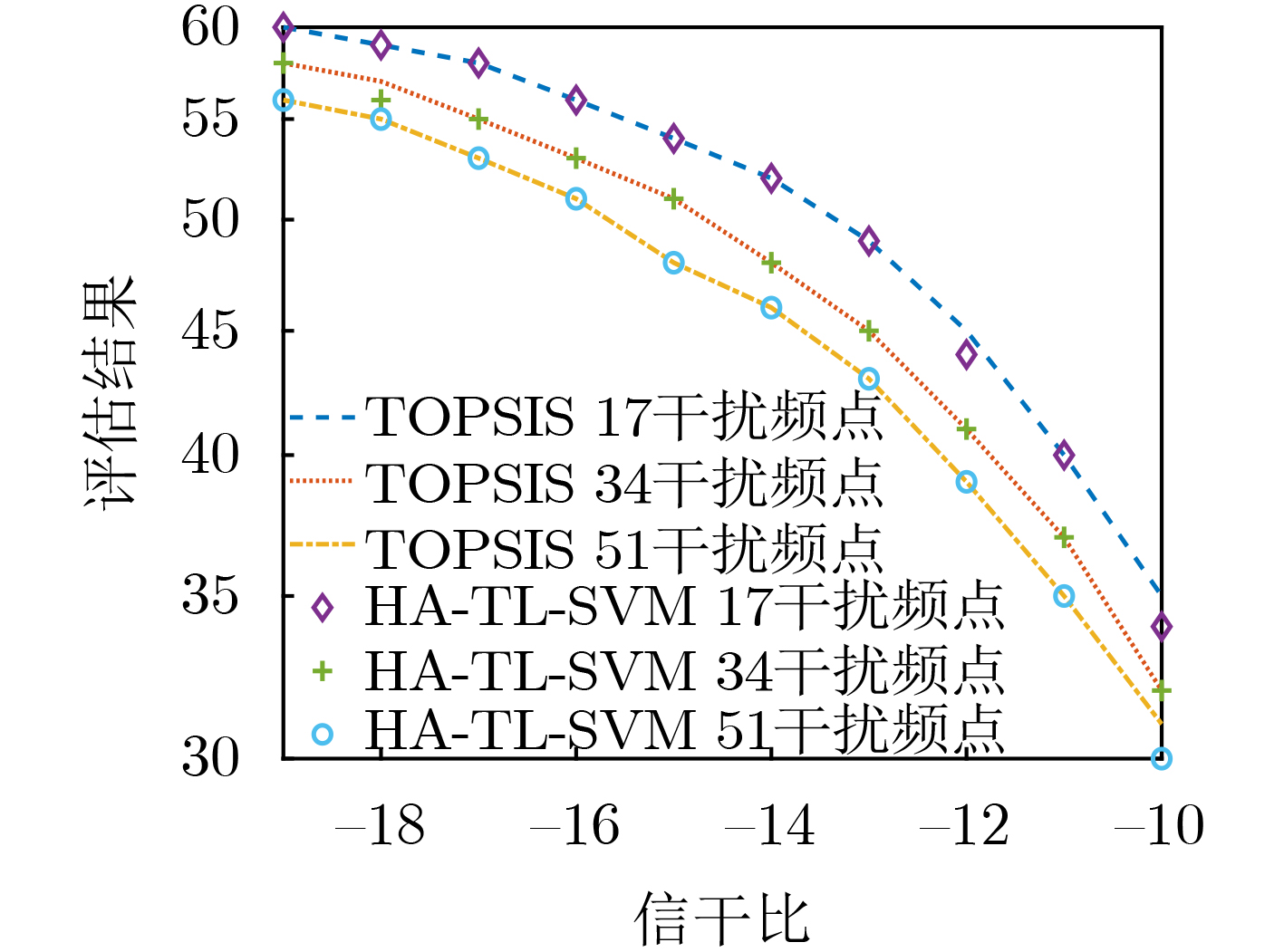
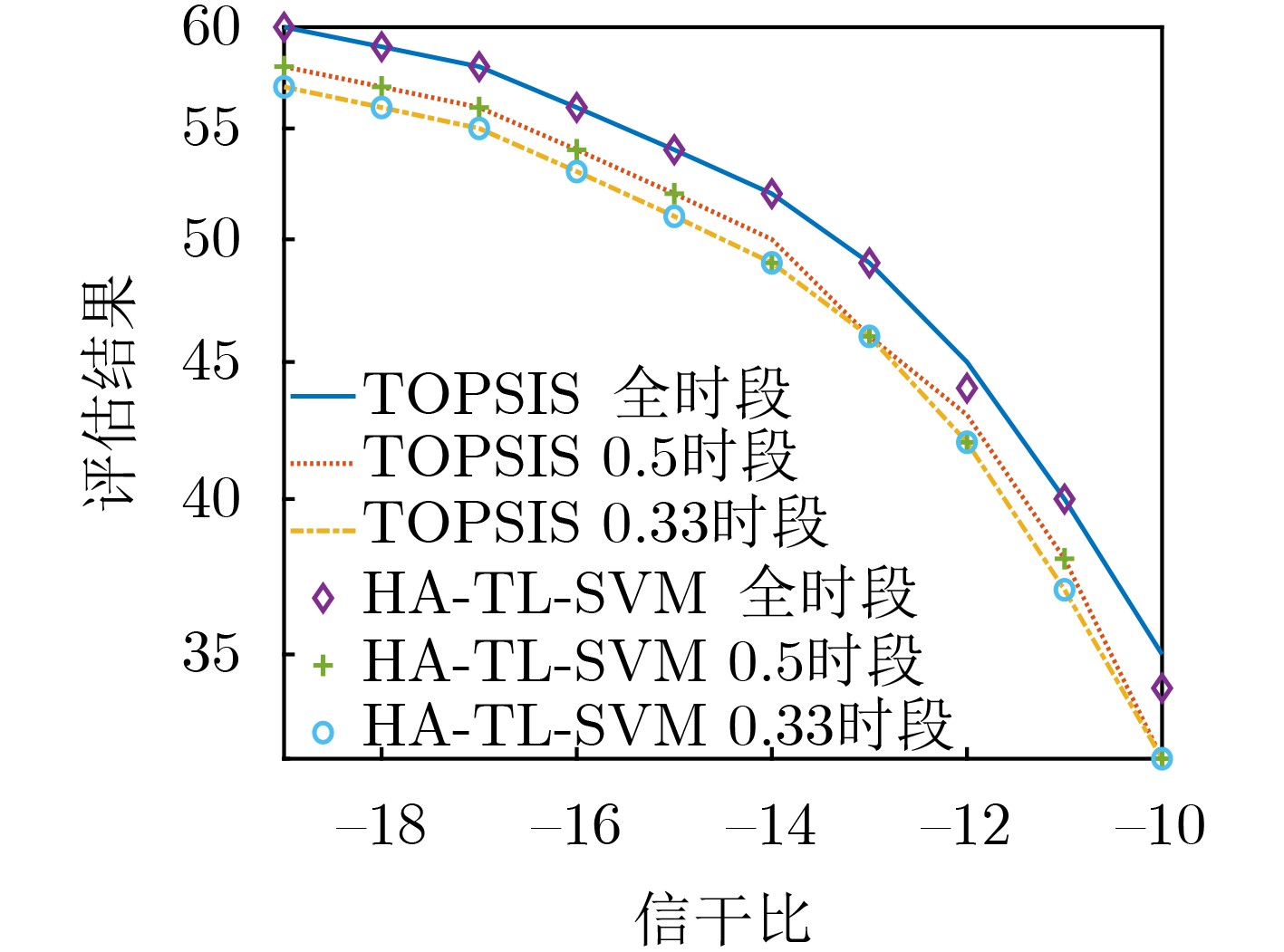
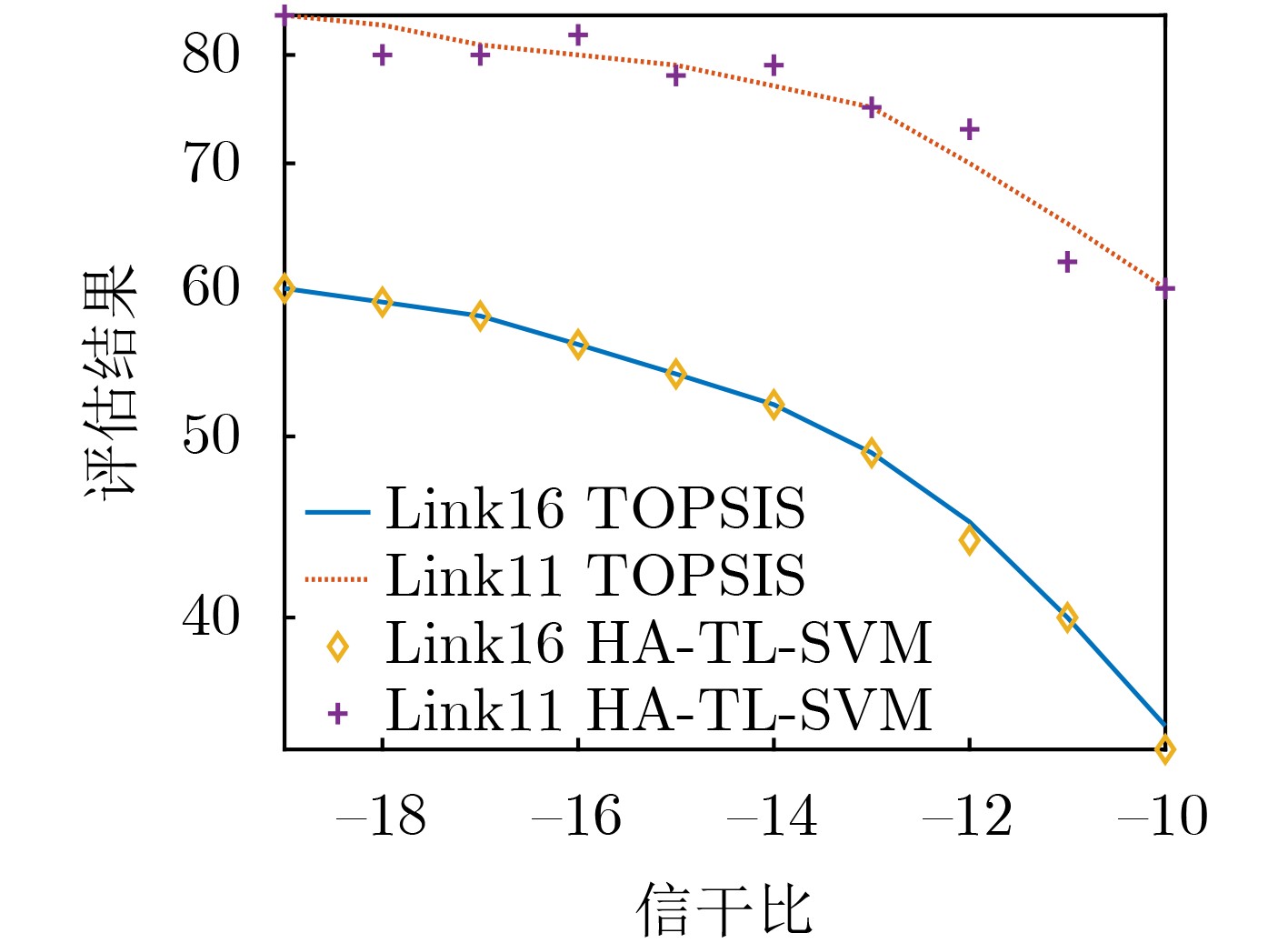


图(13)
计量
- 文章访问数: 1111
- HTML全文浏览量: 767
- PDF下载量: 72
- 被引次数: 0
