

Non-Autoregressive Sign Language Translation Technology Based on Transformer and Multimodal Alignment
-
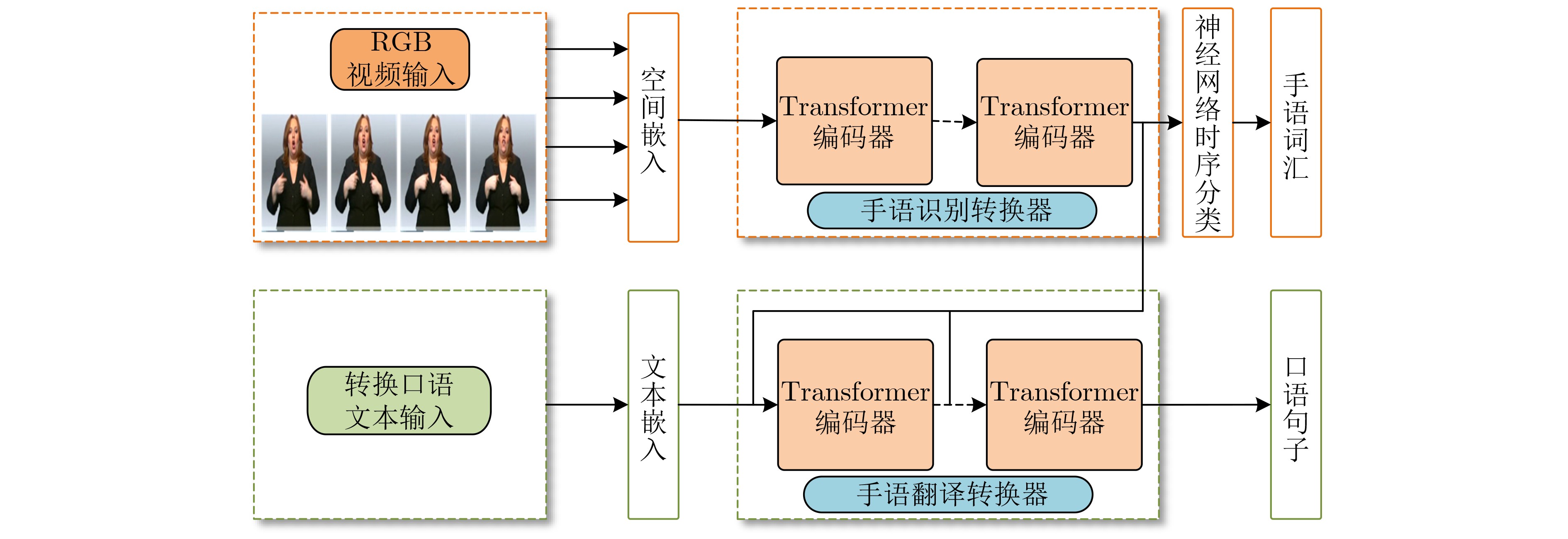
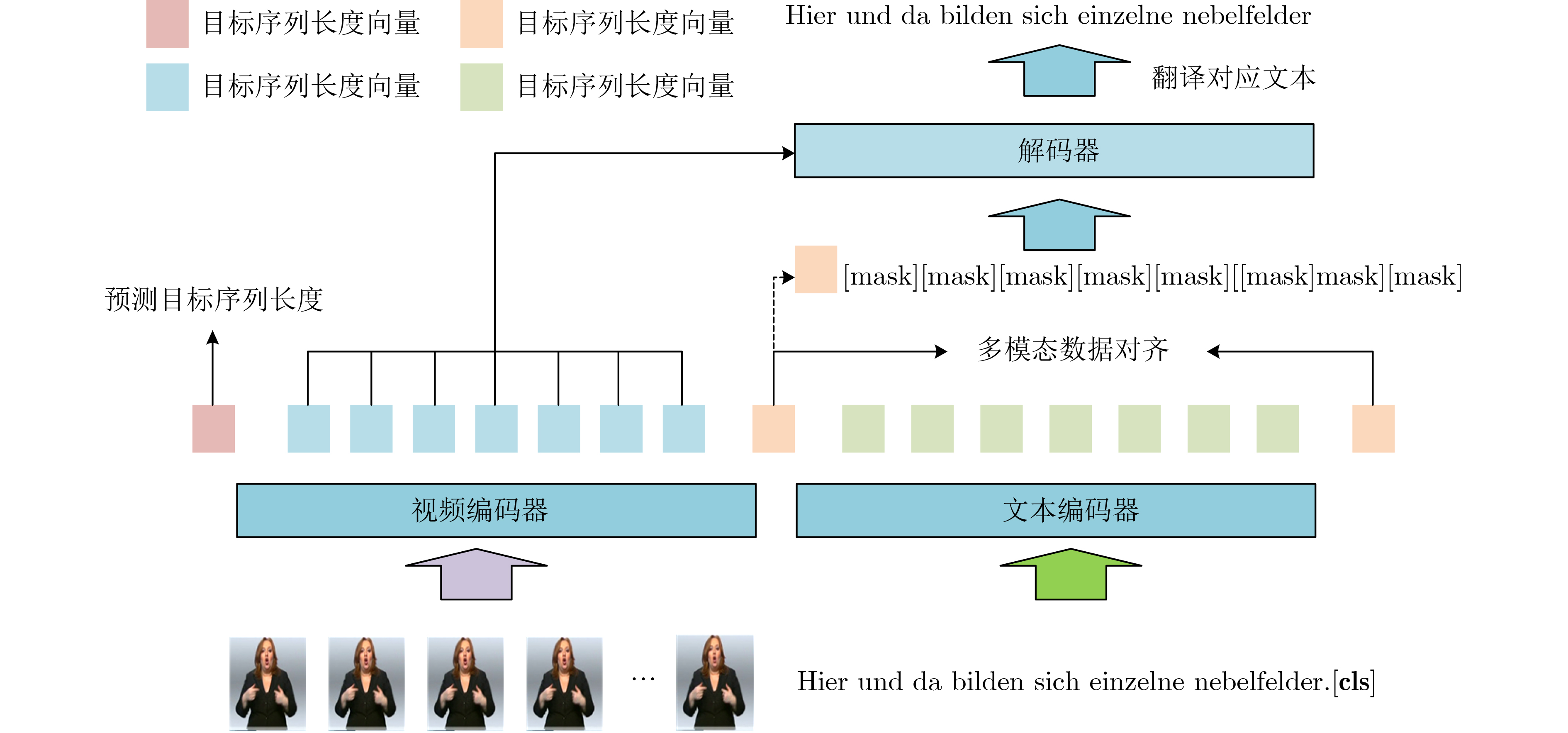
摘要: 为了解决多模态数据的对齐及手语翻译速度较慢的问题,该文提出一个基于自注意力机制模型Transformer的非自回归手语翻译模型(Trans-SLT-NA),同时引入了对比学习损失函数进行多模态数据的对齐,通过学习输入序列(手语视频)和目标序列(文本)的上下文信息和交互信息,实现一次性地将手语翻译为自然语言。该文所提模型在公开数据集PHOENIX-2014T(德语)、CSL(中文)和How2Sign(英文)上进行实验评估,结果表明该文方法相比于自回归模型翻译速度提升11.6~17.6倍,同时在双语评估辅助指标(BLEU-4)、自动摘要评估指标(ROUGE)指标上也接近自回归模型。Abstract: To address the challenge of aligning multimodal data and improving the slow translation speed in sign language translation, a Transformer Sign Language Translation Non-Autoregression (Trans-SLT-NA) is proposed in this paper, which utilizes a self-attention mechanism. Additionally, it incorporates a contrastive learning loss function to align the multimodal data. By capturing the contextual and interaction information between the input sequence (sign language videos) and the target sequence (text), the proposed model is able to perform sign language translation to natural language in s single step. The effectiveness of the proposed model is evaluated on publicly available datasets, including PHOENIX-2014-T (German), CSL (Chinese) and How2Sign (English). Results demonstrate that the proposed method achieves a significant improvement in translation speed, with a speed boost ranging from 11.6 to 17.6 times compared to autoregressive models, while maintaining comparable performance in terms of BiLingual Evaluation Understudy (BLEU-4) and Recall-Oriented Understudy for Gisting Evaluation (ROUGE) metrics.
-
表 1 训练模型使用的数据集信息
数据集 语言 训练集 验证集 测试集 总数 PHOENIX-2014T 德语 7 096 519 642 8 257 CSL-Daily 中文 18 401 1 077 1 176 20 654 How2Sign 英文 31 128 1 741 2 322 35 191  下载: 导出CSV
下载: 导出CSV
表 2 模型在PHOENIX-2014T数据集上的结果
方法 生成方式 验证集 测试集 推理速度 BLEU-4 ROUGE BLEU-4 ROUGE RNN-based[15] AR 9.94 31.8 9.58 31.8 2.3X SLTR-T[5] AR 20.69 – 20.17 – 1.0X Multi-C[26] AR 19.51 44.59 18.51 43.57 – STMC-T[24] AR 24.09 48.24 23.65 46.65 – PiSLTRc[17] AR 21.48 47.89 21.29 48.13 0.92X Trans-SLT-NA NAR 18.81 47.32 19.03 48.22 11.6X 注:AR表示自回归生成方式,NAR表示非自回归生成。
下载: 导出CSV
表 4 How2Sign数据集上的对比结果
方法 生成方式 验证集 测试集 推理速度 BLEU-4 ROUGE BLEU-4 ROUGE Baseline AR 8.89 – 8.03 – 1X Trans-SLT-NA NAR 8.14 32.84 8.58 33.17 17.6X
下载: 导出CSV
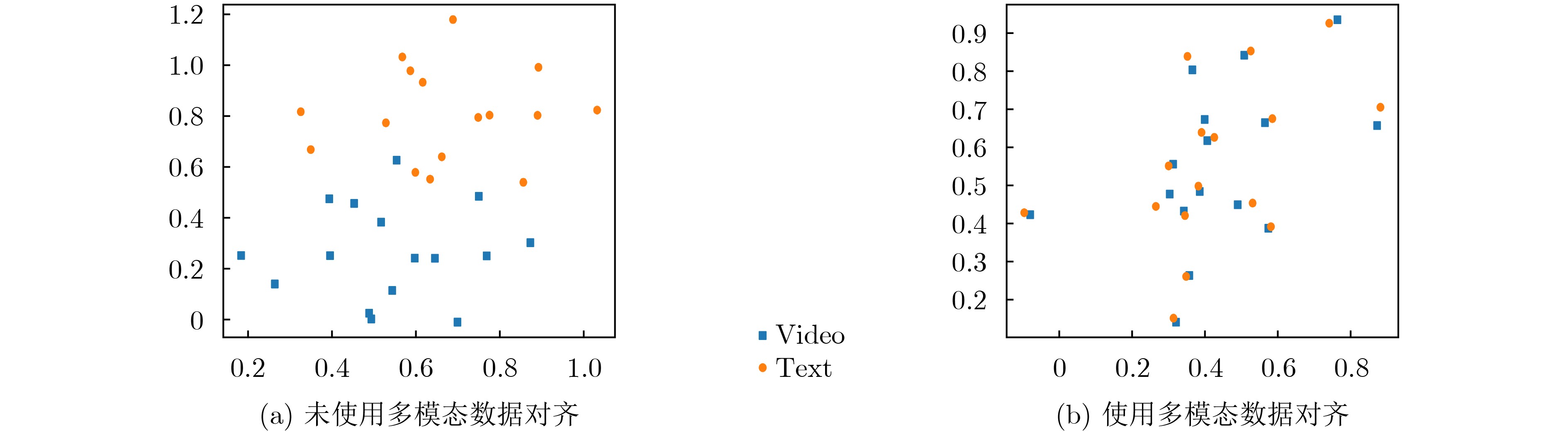
表 5 多模态数据对齐的有效性验证
模型 数据集 数据对齐 验证集 测试集 BLEU-4 ROUGE BLEU-4 ROUGE Trans-SLT-NA PHOENIX-2014T w 18.81 47.32 19.03 48.22 w/o 16.02 43.21 15.97 42.85 CSL-Daily w 16.22 43.74 16.72 44.67 w/o 14.43 42.27 15.21 42.84 How2Sign w 8.14 32.84 8.58 33.17 w/o 7.81 30.16 8.23 30.59 注:w表示使用数据对齐,w/o表示不使用数据对齐。
下载: 导出CSV
表 6 空间Embedding对于模型性能的影响结果
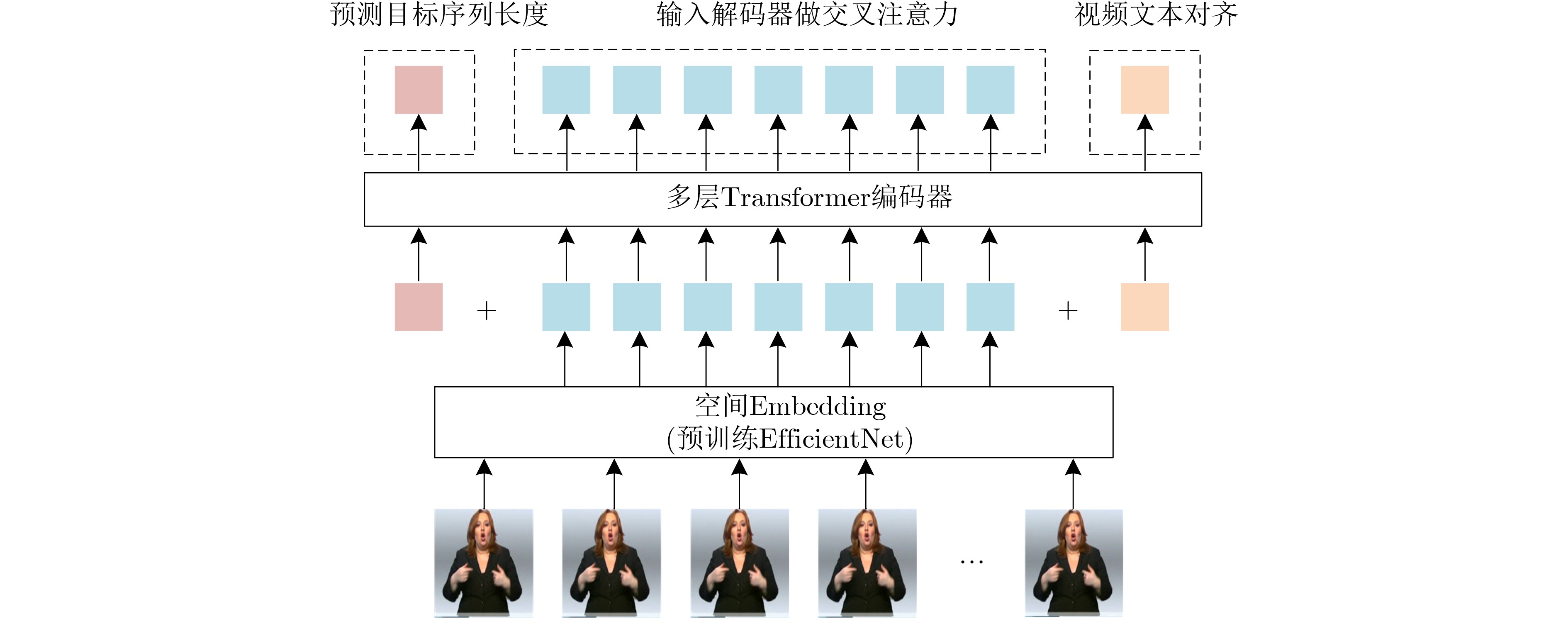
空间Embedding 预训练 验证集 测试集 BLEU-4 ROUGE BLEU-4 ROUGE VGG-19 w/o 14.42 38.76 14.36 39.17 ResNet-50 15.57 40.26 15.33 41.17 EfficientNet-B0 16.32 40.11 16.04 41.27 VGG-19 w 16.84 43.31 16.17 42.09 ResNet-50 17.79 45.63 16.93 44.53 EfficientNet-B0 18.81 47.32 19.03 48.22
下载: 导出CSV
表 7 损失函数超参数对于模型性能的结果
${\lambda _{\mathrm{p}}}$ ${\lambda _{\mathrm{c}}}$ 验证集 测试集 BLEU-4 ROUGE BLEU-4 ROUGE 1 0 16.02 43.21 15.97 42.85 0.8 0.2 17.37 44.89 16.87 42.46 0.5 0.5 18.81 47.32 19.03 48.22 0.2 0.8 18.04 46.17 18.26 47.10
下载: 导出CSV
-
[1] 闫思伊, 薛万利, 袁甜甜. 手语识别与翻译综述[J]. 计算机科学与探索, 2022, 16(11): 2415–2429. doi: 10.3778/j.issn.1673-9418.2205003.YAN Siyi, XUE Wanli, and YUAN Tiantian. Survey of sign language recognition and translation[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(11): 2415–2429. doi: 10.3778/j.issn.1673-9418.2205003. [2] 陶唐飞, 刘天宇. 基于手语表达内容与表达特征的手语识别技术综述[J]. 电子与信息学报, 2023, 45(10): 3439–3457. doi: 10.11999/JEIT221051.TAO Tangfei and LIU Tianyu. A survey of sign language recognition technology based on sign language expression content and expression characteristics[J]. Journal of Electronics & Information Technology, 2023, 45(10): 3439–3457. doi: 10.11999/JEIT221051. [3] DUARTE A, PALASKAR S, VENTURA L, et al. How2Sign: A large-scale multimodal dataset for continuous American sign language[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 2734–2743. doi: 10.1109/CVPR46437.2021.00276. [4] 周乐员, 张剑华, 袁甜甜, 等. 多层注意力机制融合的序列到序列中国连续手语识别和翻译[J]. 计算机科学, 2022, 49(9): 155–161. doi: 10.11896/jsjkx.210800026.ZHOU Leyuan, ZHANG Jianhua, YUAN Tiantian, et al. Sequence-to-sequence Chinese continuous sign language recognition and translation with multilayer attention mechanism fusion[J]. Computer Science, 2022, 49(9): 155–161. doi: 10.11896/jsjkx.210800026. [5] CAMGÖZ N C, KOLLER O, HADFIELD S, et al. Sign language transformers: Joint end-to-end sign language recognition and translation[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 10020–10030. doi: 10.1109/CVPR42600.2020.01004. [6] HUANG Jie, ZHOU Wengang, ZHANG Qilin, et al. Video-based sign language recognition without temporal segmentation[C]. 32nd AAAI Conference on Artificial Intelligence, New Orleans, USA, 2018: 2257–2264. doi: 10.1609/aaai.v32i1.11903. [7] ZHOU Hao, ZHOU Wengang, and LI Houqiang. Dynamic pseudo label decoding for continuous sign language recognition[C]. 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 2019: 1282–1287. doi: 10.1109/ICME.2019.00223. [8] SONG Peipei, GUO Dan, XIN Haoran, et al. Parallel temporal encoder for sign language translation[C]. 2019 IEEE International Conference on Image Processing (ICIP), Taipei, China, 2019: 1915–1919. doi: 10.1109/ICIP.2019.8803123. [9] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010. [10] 路飞, 韩祥祖, 程显鹏, 等. 基于轻量3D CNNs和Transformer的手语识别[J]. 华中科技大学学报:自然科学版, 2023, 51(5): 13–18. doi: 10.13245/j.hust.230503.LU Fei, HAN Xiangzu, CHENG Xianpeng, et al. Sign language recognition based on lightweight 3D CNNs and transformer[J]. Journal of Huazhong University of Science and Technology:Natural Science Edition, 2023, 51(5): 13–18. doi: 10.13245/j.hust.230503. [11] WANG Hongyu, MA Shuming, DONG Li, et al. DeepNet: Scaling transformers to 1, 000 layers[EB/OL]. https://arxiv.org/abs/2203.00555, 2022. [12] KISHORE P V V, KUMAR D A, SASTRY A S C S, et al. Motionlets matching with adaptive kernels for 3-D Indian sign language recognition[J]. IEEE Sensors Journal, 2018, 18(8): 3327–3337. doi: 10.1109/JSEN.2018.2810449. [13] XIAO Yisheng, WU Lijun, GUO Junliang, et al. A survey on non-autoregressive generation for neural machine translation and beyond[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(10): 11407–11427. doi: 10.1109/TPAMI.2023.3277122. [14] LI Feng, CHEN Jingxian, and ZHANG Xuejun. A survey of non-autoregressive neural machine translation[J]. Electronics, 2023, 12(13): 2980. doi: 3390/electronics12132980. [15] CAMGOZ N C, HADFIELD S, KOLLER O, et al. Neural sign language translation[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7784–7793. doi: 10.1109/CVPR.2018.00812. [16] ARVANITIS N, CONSTANTINOPOULOS C, and KOSMOPOULOS D. Translation of sign language glosses to text using sequence-to-sequence attention models[C]. 2019 15th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Sorrento, Italy, 2019: 296–302. doi: 10.1109/SITIS.2019.00056. [17] XIE Pan, ZHAO Mengyi, and HU Xiaohui. PiSLTRc: Position-informed sign language transformer with content-aware convolution[J]. IEEE Transactions on Multimedia, 2022, 24: 3908–3919. doi: 10.1109/TMM.2021.3109665. [18] CHEN Yutong, WEI Fangyun, SUN Xiao, et al. A simple multi-modality transfer learning baseline for sign language translation[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, USA, 2022: 5110–5120. doi: 10.1109/CVPR52688.2022.00506. [19] ZHOU Hao, ZHOU Wengang, QI Weizhen, et al. Improving sign language translation with monolingual data by sign back-translation[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 1316–1325. doi: 10.1109/CVPR46437.2021.00137. [20] ZHENG Jiangbin, WANG Yile, TAN Cheng, et al. CVT-SLR: Contrastive visual-textual transformation for sign language recognition with variational alignmen[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 23141–23150. doi: 10.1109/CVPR52729.2023.02216. [21] GU Jiatao, BRADBURY J, XIONG Caiming, et al. Non-autoregressive neural machine translation[C]. 6th International Conference on Learning Representations, Vancouver, Canada, 2018. doi: 10.48550/arXiv.1711.02281. [22] WANG Yiren, TIAN Fei, HE Di, et al. Non-autoregressive machine translation with auxiliary regularization[C]. The 33rd AAAI Conference on Artificial Intelligence, Honolulu, USA, 2019: 5377–5384. doi: 10.1609/aaai.v33i01.33015377. [23] XIE Pan, LI Zexian, ZHAO Zheng, et al. MvSR-NAT: Multi-view subset regularization for non-autoregressive machine translation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022: 1–10. doi: 10.1109/TASLP.2022.3221043. [24] ZHOU HAO, ZHOU Wengang, ZHOU Yun, et al. Spatial-temporal multi-cue network for sign language recognition and translation[J]. IEEE Transactions on Multimedia, 2022, 24: 768–779. doi: 10.1109/TMM.2021.3059098. [25] TARRÉS L, GÁLLEGO G I, DUARTE A, et al. Sign language translation from instructional videos[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Vancouver, Canada, 2023: 5625–5635. doi: 10.1109/CVPRW59228.2023.00596. [26] CAMGOZ N C, KOLLER O, HADFIELD S, et al. Multi-channel transformers for multi-articulatory sign language translation[C]. ECCV 2020 Workshops on Computer Vision, Glasgow, UK, 2020: 301–319. doi: 10.1007/978-3-030-66823-5_18. [27] FU Biao, YE Peigen, ZHANG Liang, et al. A token-level contrastive framework for sign language translation[C]. 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 2023: 1–5. doi: 10.1109/ICASSP49357.2023.10095466. -

 下载:
下载:


图(4) / 表(7)
计量
- 文章访问数: 1561
- HTML全文浏览量: 1180
- PDF下载量: 145
- 被引次数: 0
