

Integrating Multiple Context and Hybrid Interaction for Salient Object Detection
-
摘要: 显著性目标检测目的是识别和分割图像中的视觉显著性目标,它是计算机视觉任务及其相关领域的重要研究内容之一。当下基于全卷积网络(FCNs)的显著性目标检测方法已经取得了不错的性能,然而现实场景中的显著性目标类型多变且尺寸不固定,这使得准确检测并完整分割出显著性目标仍然是一个巨大的挑战。为此,该文提出集成多种上下文和混合交互的显著性目标检测方法,通过利用密集上下文信息探索模块和多源特征混合交互模块来高效预测显著性目标。密集上下文信息探索模块采用空洞卷积、不对称卷积和密集引导连接渐进地捕获具有强关联性的多尺度和多感受野上下文信息,通过集成这些信息来增强每个初始多层级特征的表达能力。多源特征混合交互模块包含多种特征聚合操作,可以自适应交互来自多层级特征中的互补性信息,以生成用于准确预测显著性图的高质量特征表示。此方法在5个公共数据集上进行了性能测试,实验结果表明,该文方法在不同的评估指标下与19种基于深度学习的显著性目标检测方法相比取得优越的预测性能。Abstract: Salient Object Detection (SOD) aims to recognize and segment visual salient objects in images, which is one of the important research contents in computer vision tasks and related fields. Existing Fully Convolutional Networks (FCNs)-based SOD methods have achieved good performance. However, the types and sizes of salient objects are variable and unfixed in real-world scenes, which makes it still a huge challenge to detect and segment salient objects accurately and completely. For that, in this paper, a novel integrating multiple context and hybrid interaction for SOD task is proposed to efficiently predict salient objects by collaborating Dense Context Information Exploration (DCIE) module and Multi-source Feature Hybrid Interaction (MFHI) module. The DCIE module uses dilated convolution, asymmetric convolution and dense guided connection to progressively capture the strongly correlated multi-scale and multi-receptive field context information, and enhances the expression ability of each initial input feature by aggregating context information. The MFHI module contains diverse feature aggregation operations, which can adaptively interact with complementary information from multi-level features to generate high-quality feature representations for accurately predicting saliency maps. The performance of the proposed method is tested on five public datasets. The performance of the proposed method is tested on five public datasets. Experimental results demonstrate that our method achieves superior prediction performance compared with 19 state-of-the-art SOD methods under different evaluation metrics.
-
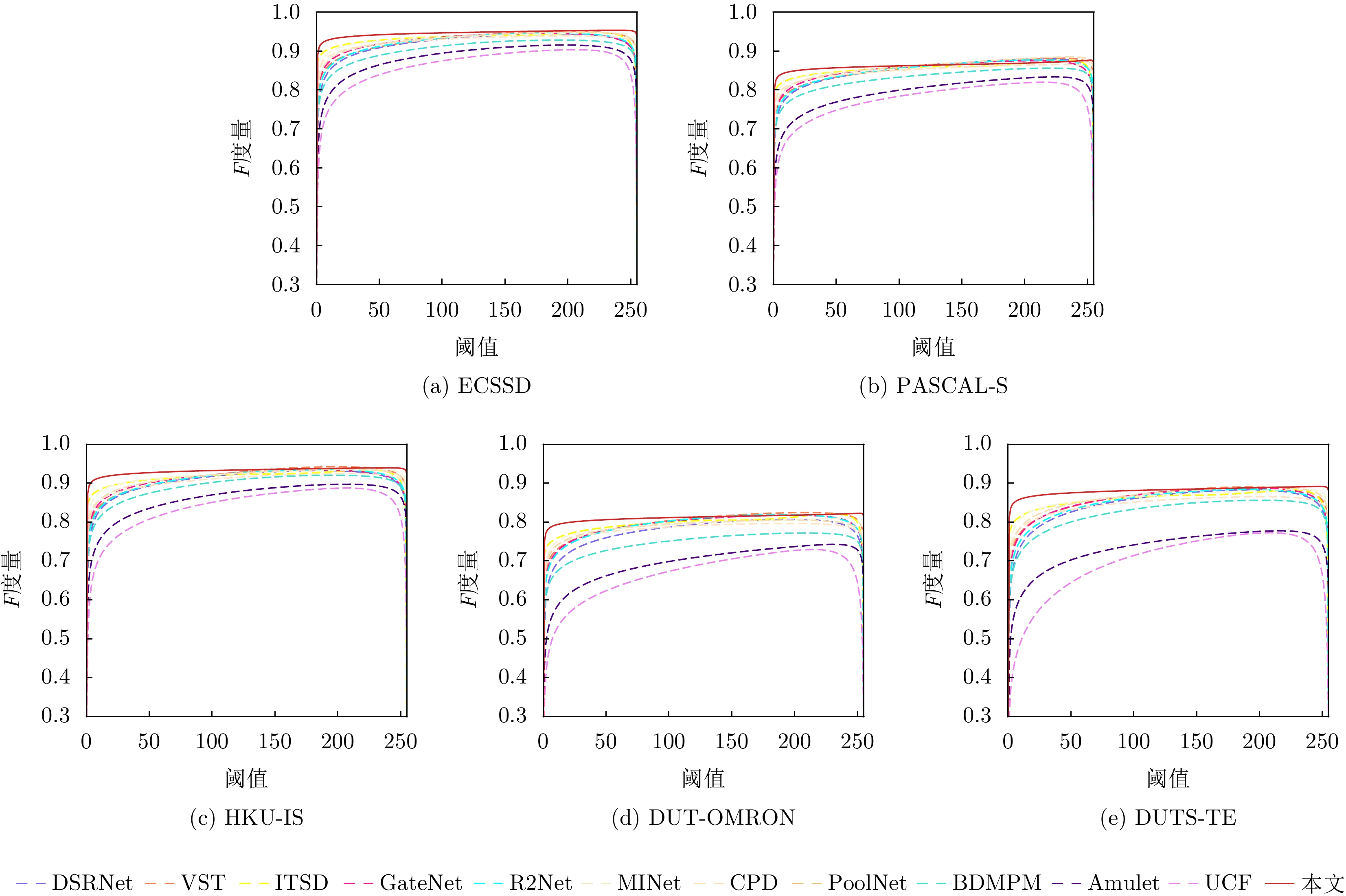
表 1 MAE, AFm和WFm的定量比较结果
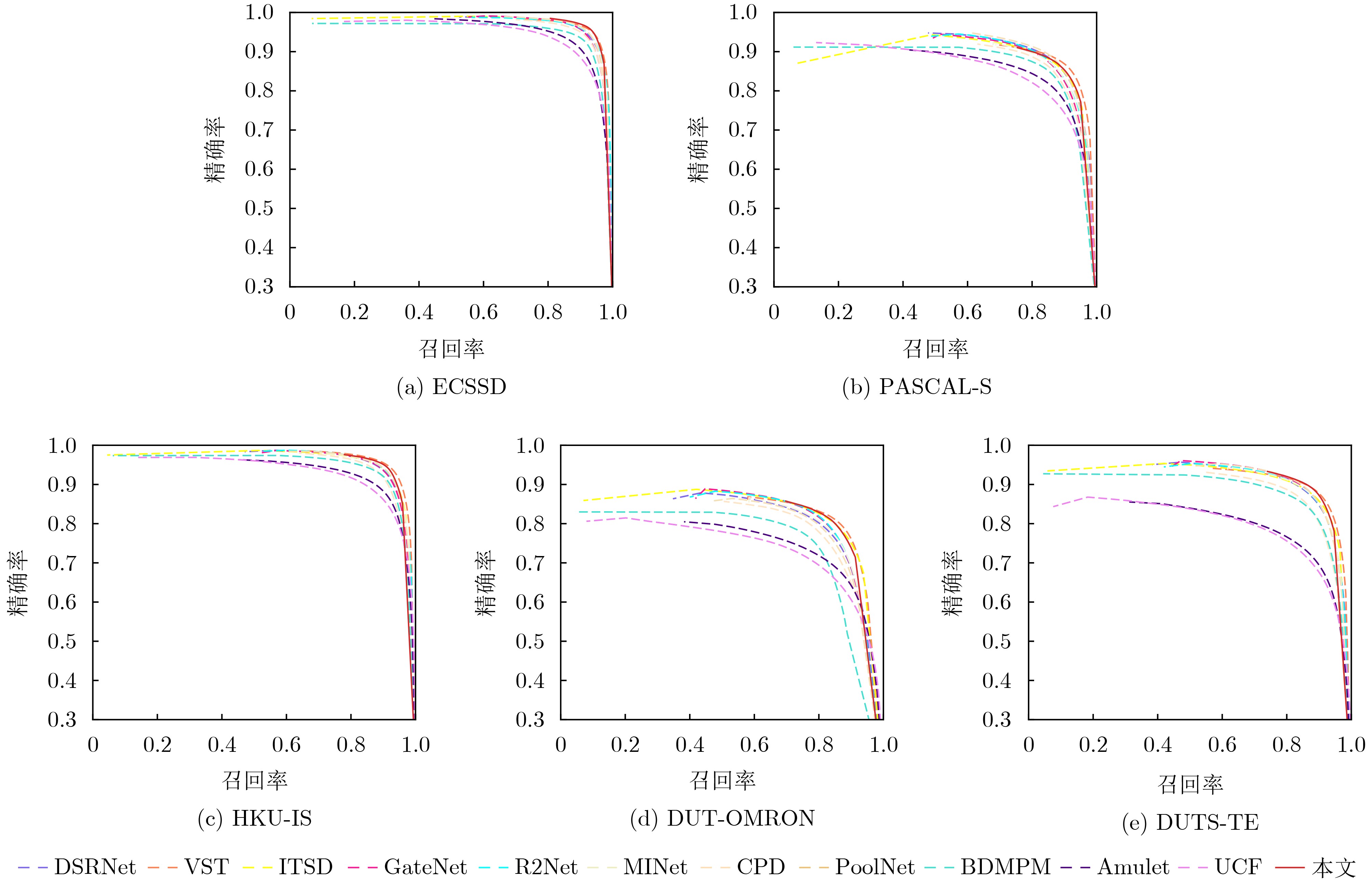
方法 ECSSD (1000) PASCAL-S (850) HKU-IS (4447) DUT-OMRON (5168) DUTS-TE (5019) MAE AFm WFm MAE AFm WFm MAE AFm WFm MAE AFm WFm MAE AFm WFm Amulet17 0.059 0.868 0.840 0.100 0.757 0.728 0.051 0.841 0.817 0.098 0.647 0.626 0.085 0.678 0.658 UCF17 0.069 0.844 0.806 0.116 0.726 0.726 0.062 0.823 0.779 0.120 0.621 0.574 0.112 0.631 0.596 DGRL18 0.046 0.893 0.871 0.077 0.794 0.772 0.041 0.875 0.851 0.066 0.711 0.688 0.054 0.755 0.748 BDMPM18 0.045 0.869 0.871 0.074 0.758 0.774 0.039 0.871 0.859 0.064 0.692 0.681 0.049 0.746 0.761 PoolNet19 0.039 0.915 0.896 0.075 0.815 0.793 0.032 0.900 0.883 0.056 0.739 0.721 0.040 0.809 0.807 CPD19 0.037 0.917 0.898 0.071 0.820 0.794 0.033 0.895 0.879 0.056 0.747 0.719 0.043 0.805 0.795 AFNet19 0.042 0.908 0.886 0.070 0.815 0.792 0.036 0.888 0.869 0.057 0.739 0.717 0.046 0.793 0.785 R2Net20 0.038 0.914 0.899 0.069 0.817 0.793 0.033 0.896 0.880 0.054 0.744 0.728 0.041 0.801 0.804 GateNet20 0.040 0.916 0.894 0.067 0.819 0.797 0.033 0.899 0.880 0.055 0.746 0.729 0.040 0.807 0.809 ITSD20 0.035 0.895 0.911 0.066 0.785 0.812 0.031 0.899 0.894 0.061 0.756 0.750 0.041 0.804 0.824 MINet20 0.034 0.924 0.911 0.064 0.829 0.809 0.029 0.909 0.897 0.056 0.756 0.738 0.037 0.828 0.825 SUCA21 0.036 0.915 0.906 0.067 0.818 0.803 0.031 0.897 0.890 – – – 0.044 0.803 0.802 CANet21 0.044 0.900 0.878 0.073 0.813 0.792 0.037 0.882 0.866 0.058 0.731 0.720 0.044 0.785 0.788 DSRNet21 0.039 0.910 0.891 0.067 0.819 0.801 0.035 0.893 0.873 0.061 0.727 0.711 0.043 0.791 0.794 VST21 0.033 0.920 0.910 0.061 0.829 0.816 0.029 0.900 0.897 0.058 0.756 0.755 0.037 0.818 0.828 DNA22 0.042 0.891 0.883 0.079 0.790 0.772 0.035 0.863 0.864 0.063 0.694 0.696 0.046 0.747 0.765 DCENet22 0.035 0.926 0.913 0.061 0.845 0.825 0.029 0.908 0.898 0.055 0.771 0.754 0.038 0.842 0.834 DNTDF22 0.034 0.900 0.909 0.064 0.810 0.814 0.028 0.905 0.901 0.051 0.748 0.732 0.033 0.822 0.839 ICON23 0.032 0.928 0.918 0.064 0.833 0.818 0.029 0.910 0.902 0.057 0.772 0.761 0.037 0.838 0.837 本文 0.032 0.935 0.922 0.060 0.841 0.822 0.026 0.923 0.911 0.049 0.778 0.759 0.034 0.862 0.846  下载: 导出CSV
下载: 导出CSV
表 2 参数量、推理速度和模型内存的比较结果
方法 输入尺寸 参数量 (M) 推理速度 (帧/s) 模型内存 (MB) Amulet 320×320 33.15 8 132 DGRL 384×384 161.74 8 631 BDMPM 256×256 - 22 259 PoolNet 384×384 68.26 17 410 GateNet 384×384 128.63 30 503 MINet 320×320 162.38 25 635 DSRNet 400×400 75.29 15 290 本文 320×320 29.97 26 117
下载: 导出CSV
表 3 本文方法使用不同模块定量比较结果
方法 HKU-IS (4447) DUTS-TE (5019) MAE AFm WFm MAE AFm WFm Res 0.042 0.866 0.843 0.053 0.772 0.760 Res+FPN 0.037 0.884 0.870 0.045 0.800 0.784 Res+DCIE+FPN 0.028 0.913 0.900 0.037 0.845 0.828 Res+DCIE+MFHI 0.026 0.923 0.911 0.034 0.862 0.846
下载: 导出CSV
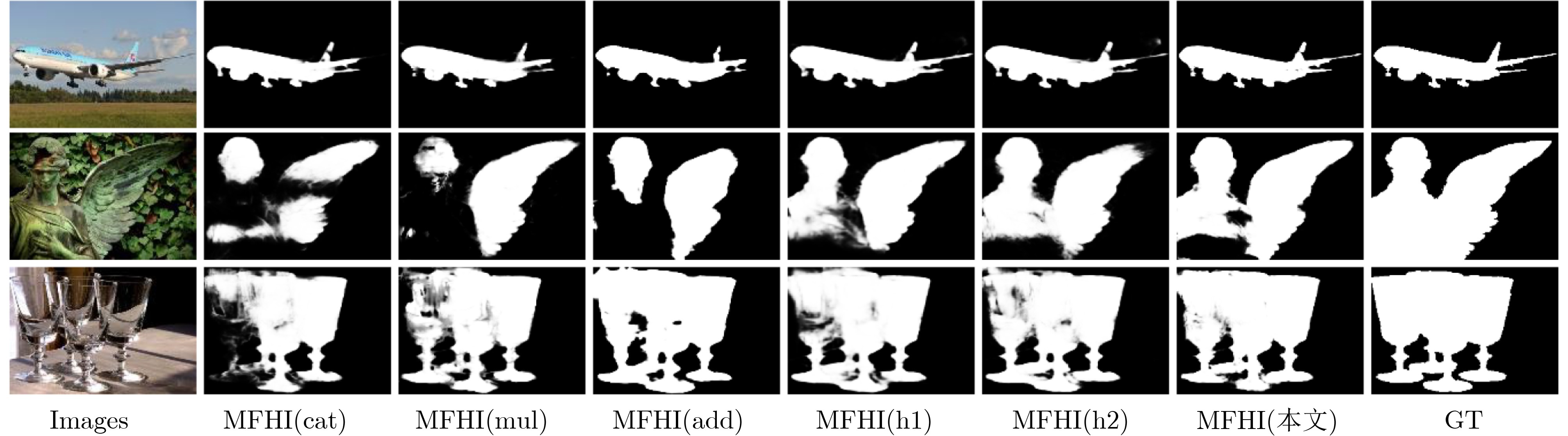
表 4 MFHI模块不同聚合策略定量比较结果
方法 HKU-IS (4447) DUTS-TE (5019) MAE AFm WFm MAE AFm WFm Res+MFHI(cat) 0.030 0.903 0.892 0.041 0.822 0.813 Res+MFHI(mul) 0.032 0.899 0.888 0.041 0.818 0.811 Res+MFHI(add) 0.033 0.894 0.884 0.042 0.818 0.803 Res+MFHI(h1) 0.030 0.903 0.892 0.039 0.825 0.815 Res+MFHI(h2) 0.031 0.902 0.891 0.039 0.824 0.815 Res+MFHI 0.029 0.906 0.898 0.039 0.832 0.819
下载: 导出CSV
表 5 不同模块对比测试
方法 HKU-IS (4447) DUTS-TE (5019) MAE AFm WFm MAE AFm WFm Res+ASPP+FPN 0.031 0.905 0.892 0.040 0.825 0.815 Res+RFB+FPN 0.031 0.903 0.891 0.039 0.828 0.818 Res+PDC+FPN 0.032 0.899 0.899 0.040 0.826 0.813 Res+DCIE+FPN 0.028 0.913 0.900 0.037 0.845 0.828
下载: 导出CSV
表 6 DCIE模块消融分析
方法 HKU-IS (4447) DUTS-TE (5019) MAE AFm WFm MAE AFm WFm Res+DCIE(w D)+FPN 0.032 0.898 0.886 0.039 0.823 0.815 Res+DCIE(w A)+FPN 0.032 0.898 0.886 0.040 0.822 0.814 Res+DCIE(w D+A)+FPN 0.030 0.907 0.895 0.038 0.839 0.823 Res+DCIE+FPN 0.028 0.913 0.900 0.037 0.845 0.828
下载: 导出CSV
-
[1] LIU Mingyuan, SCHONFELD D, and TANG Wei. Exploit visual dependency relations for semantic segmentation[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 9726–9735. doi: 10.1109/CVPR46437.2021.00960. [2] ZHANG Xi and WU Xiaolin. Attention-guided image compression by deep reconstruction of compressive sensed saliency skeleton[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 13354–13364. doi: 10.1109/cvpr46437.2021.01315. [3] LEE S, SEONG H, LEE S, et al. Correlation verification for image retrieval[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 5374–5384. doi: 10.1109/CVPR52688.2022.00530. [4] ZHU Junyan, WU Jianjun, XU Yan, et al. Unsupervised object class discovery via saliency-guided multiple class learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(4): 862–875. doi: 10.1109/tpami.2014.2353617. [5] GUPTA D K, ARYA D, and GAVVES E. Rotation equivariant Siamese networks for tracking[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 12362–12371. doi: 10.1109/cvpr46437.2021.01218. [6] PANG Youwei, ZHAO Xiaoqi, XIANG Tianzhu, et al. Zoom in and out: A mixed-scale triplet network for camouflaged object detection[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 2160–2170. doi: 10.1109/cvpr52688.2022.00220. [7] PENG Houwen, LI Bing, LING Haibin, et al. Salient object detection via structured matrix decomposition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 818–832. doi: 10.1109/TPAMI.2016.2562626. [8] SHEN Xiaohui and WU Ying. A unified approach to salient object detection via low rank matrix recovery[C]. 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, USA, 2012: 853–860. doi: 10.1109/cvpr.2012.6247758. [9] 唐红梅, 白梦月, 韩力英, 等. 基于低秩背景约束与多线索传播的图像显著性检测[J]. 电子与信息学报, 2021, 43(5): 1432–1440. doi: 10.11999/JEIT200193.TANG Hongmei, BAI Mengyue, HAN Liying, et al. Image saliency detection based on background constraint of low rank and multi-cue propagation[J]. Journal of Electronics & Information Technology, 2021, 43(5): 1432–1440. doi: 10.11999/JEIT200193. [10] MARGOLIN R, TAL A, and ZELNIK-MANOR L. What makes a patch distinct?[C]. 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, USA, 2013: 1139–1146. doi: 10.1109/cvpr.2013.151. [11] TONG Na, LU Huchuan, RUAN Xiang, et al. Salient object detection via bootstrap learning[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 1884–1892. doi: 10.1109/cvpr.2015.7298798. [12] JIANG Zhuolin and DAVIS L S. Submodular salient region detection[C]. 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, USA, 2013: 2043–2050. doi: 10.1109/cvpr.2013.266. [13] LI Guanbin and YU Yizhou. Visual saliency based on multiscale deep features[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 5455–5463. doi: 10.1109/cvpr.2015.7299184. [14] LIU Nian and HAN Junwei. DHSnet: Deep hierarchical saliency network for salient object detection[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 678–686. doi: 10.1109/cvpr.2016.80. [15] SHELHAMER E, LONG J, and DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640–651. doi: 10.1109/TPAMI.2016.2572683. [16] ZHAO Ting and WU Xiangqian. Pyramid feature attention network for saliency detection[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 3085–3094. doi: 10.1109/cvpr.2019.00320. [17] SIRIS A, JIAO Jianbo, TAM G K L, et al. Scene context-aware salient object detection[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 4156–4166. doi: 10.1109/iccv48922.2021.00412. [18] CHEN Zuyao, XU Qianqian, CONG Runmin, et al. Global context-aware progressive aggregation network for salient object detection[C]. The 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 10599–10606. doi: 10.1609/aaai.v34i07.6633. [19] WU Zhenyu, LI Shuai, CHEN Chenglizhao, et al. Salient object detection via dynamic scale routing[J]. IEEE Transactions on Image Processing, 2022, 31: 6649–6663. doi: 10.1109/tip.2022.3214332. [20] ZHANG Pingping, WANG Dong, LU Huchuan, et al. Amulet: Aggregating multi-level convolutional features for salient object detection[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 202–211. doi: 10.1109/iccv.2017.31. [21] HOU Qibin, CHENG Mingming, HU Xiaowei, et al. Deeply supervised salient object detection with short connections[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(4): 815–828. doi: 10.1109/TPAMI.2018.2815688. [22] LI Junxia, PAN Zefeng, LIU Qingshan, et al. Stacked U-shape network with channel-wise attention for salient object detection[J]. IEEE Transactions on Multimedia, 2021, 23: 1397–1409. doi: 10.1109/TMM.2020.2997192. [23] ZHANG Lu, DAI Ju, LU Huchuan, et al. A bi-directional message passing model for salient object detection[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 1741–1750. doi: 10.1109/cvpr.2018.00187. [24] 雷大江, 杜加浩, 张莉萍, 等. 联合多流融合和多尺度学习的卷积神经网络遥感图像融合方法[J]. 电子与信息学报, 2022, 44(1): 237–244. doi: 10.11999/JEIT200792.LEI Dajiang, DU Jiahao, ZHANG Liping, et al. Multi-stream architecture and multi-scale convolutional neural network for remote sensing image fusion[J]. Journal of Electronics & Information Technology, 2022, 44(1): 237–244. doi: 10.11999/JEIT200792. [25] 李珣, 李林鹏, LAZOVIK A, 等. 基于改进双流卷积递归神经网络的RGB-D物体识别方法[J]. 光电工程, 2021, 48(2): 200069. doi: 10.12086/oee.2021.200069.LI Xun, LI Linpeng, LAZOVIK A, et al. RGB-D object recognition algorithm based on improved double stream convolution recursive neural network[J]. Opto-Electronic Engineering, 2021, 48(2): 200069. doi: 10.12086/oee.2021.200069. [26] 邓箴, 王一斌, 刘立波. 视觉注意机制的注意残差稠密神经网络弱光照图像增强[J]. 液晶与显示, 2021, 36(11): 1463–1473. doi: 10.37188/CJLCD.2021-0098.DENG Zhen, WANG Yibin, and LIU Libo. Attentive residual dense network of visual attention mechanism for weakly illuminated image enhancement[J]. Chinese Journal of Liquid Crystals and Displays, 2021, 36(11): 1463–1473. doi: 10.37188/CJLCD.2021-0098. [27] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/cvpr.2016.90. [28] LIU Jiangjiang, HOU Qibin, CHENG Mingming, et al. A simple pooling-based design for real-time salient object detection[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 3917–3926. doi: 10.1109/cvpr.2019.00404. [29] 卢珊妹, 郭强, 王任, 等. 基于多特征注意力循环网络的显著性检测[J]. 计算机辅助设计与图形学学报, 2020, 32(12): 1926–1937. doi: 10.3724/sp.j.1089.2020.18240.LU Shanmei, GUO Qiang, WANG Ren, et al. Salient object detection using multi-scale features with attention recurrent mechanism[J]. Journal of Computer-Aided Design & Computer Graphics, 2020, 32(12): 1926–1937. doi: 10.3724/sp.j.1089.2020.18240. [30] HUANG Gao, LIU Zhuang, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 4700–4708. doi: 10.1109/cvpr.2017.243. [31] ZHANG Xiangyu, ZHOU Xinyu, LIN Mengxiao, et al. ShuffleNet: An extremely efficient convolutional neural network for mobile devices[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 6848–6856. doi: 10.1109/cvpr.2018.00716. [32] ZHANG Pingping, WANG Dong, LU Huchuan, et al. Learning uncertain convolutional features for accurate saliency detection[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 212–221. doi: 10.1109/iccv.2017.32. [33] WANG Tiantian, ZHANG Lihe, WANG Shuo, et al. Detect globally, refine locally: A novel approach to saliency detection[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 3127–3135. doi: 10.1109/cvpr.2018.00330. [34] FENG Mengyang, LU Huchuan, and DING Errui. Attentive feedback network for boundary-aware salient object detection[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 1623–1632. doi: 10.1109/cvpr.2019.00172. [35] WU Zhe, SU Li, and HUANG Qingming. Cascaded partial decoder for fast and accurate salient object detection[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 3907–3916. doi: 10.1109/cvpr.2019.00403. [36] FENG Mengyang, LU Huchuan, and YU Yizhou. Residual learning for salient object detection[J]. IEEE Transactions on Image Processing, 2020, 29: 4696–4708. doi: 10.1109/tip.2020.2975919. [37] ZHAO Xiaoqi, PANG Youwei, ZHANG Lihe, et al. Suppress and balance: A simple gated network for salient object detection[C]. The 16th European Conference on Computer Vision, Glasgow, United Kingdom, 2020: 35–51. doi: 10.1007/978-3-030-58536-5_3. [38] ZHOU Huajun, XIE Xiaohua, LAI Jianhuang, et al. Interactive two-stream decoder for accurate and fast saliency detection[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 9141–9150. doi: 10.1109/cvpr42600.2020.00916. [39] PANG Youwei, ZHAO Xiaoqi, ZHANG Lihe, et al. Multi-scale interactive network for salient object detection[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 9413–9422. doi: 10.1109/cvpr42600.2020.00943. [40] REN Qinghua, LU Shijian, ZHANG Jinxia, et al. Salient object detection by fusing local and global contexts[J]. IEEE Transactions on Multimedia, 2021, 23: 1442–1453. doi: 10.1109/tmm.2020.2997178. [41] WANG Liansheng, CHEN Rongzhen, ZHU Lei, et al. Deep sub-region network for salient object detection[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(2): 728–741. doi: 10.1109/tcsvt.2020.2988768. [42] LIU Nian, ZHANG Ni, WAN Kaiyuan, et al. Visual saliency transformer[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 4722–4732. doi: 10.1109/iccv48922.2021.00468. [43] LIU Yun, CHENG Mingming, ZHANG Xinyu, et al. DNA: Deeply supervised nonlinear aggregation for salient object detection[J]. IEEE Transactions on Cybernetics, 2022, 52(7): 6131–6142. doi: 10.1109/tcyb.2021.3051350. [44] MEI Haiyang, LIU Yuanyuan, WEI Ziqi, et al. Exploring dense context for salient object detection[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(3): 1378–1389. doi: 10.1109/tcsvt.2021.3069848. [45] FANG Chaowei, TIAN Haibin, ZHANG Dingwen, et al. Densely nested top-down flows for salient object detection[J]. Science China Information Sciences, 2022, 65(8): 182103. doi: 10.1007/s11432-021-3384-y. [46] ZHUGE Mingchen, FAN Dengping, LIU Nian, et al. Salient object detection via integrity learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(3): 3738–3752. doi: 10.1109/tpami.2022.3179526. [47] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2117–2125. doi: 10.1109/cvpr.2017.106. [48] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834–848. doi: 10.1109/tpami.2017.2699184. [49] LIU Songtao, HUANG Di, and WANG Yunhong. Receptive field block net for accurate and fast object detection[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 385–400. doi: 10.1007/978-3-030-01252-6_24. -

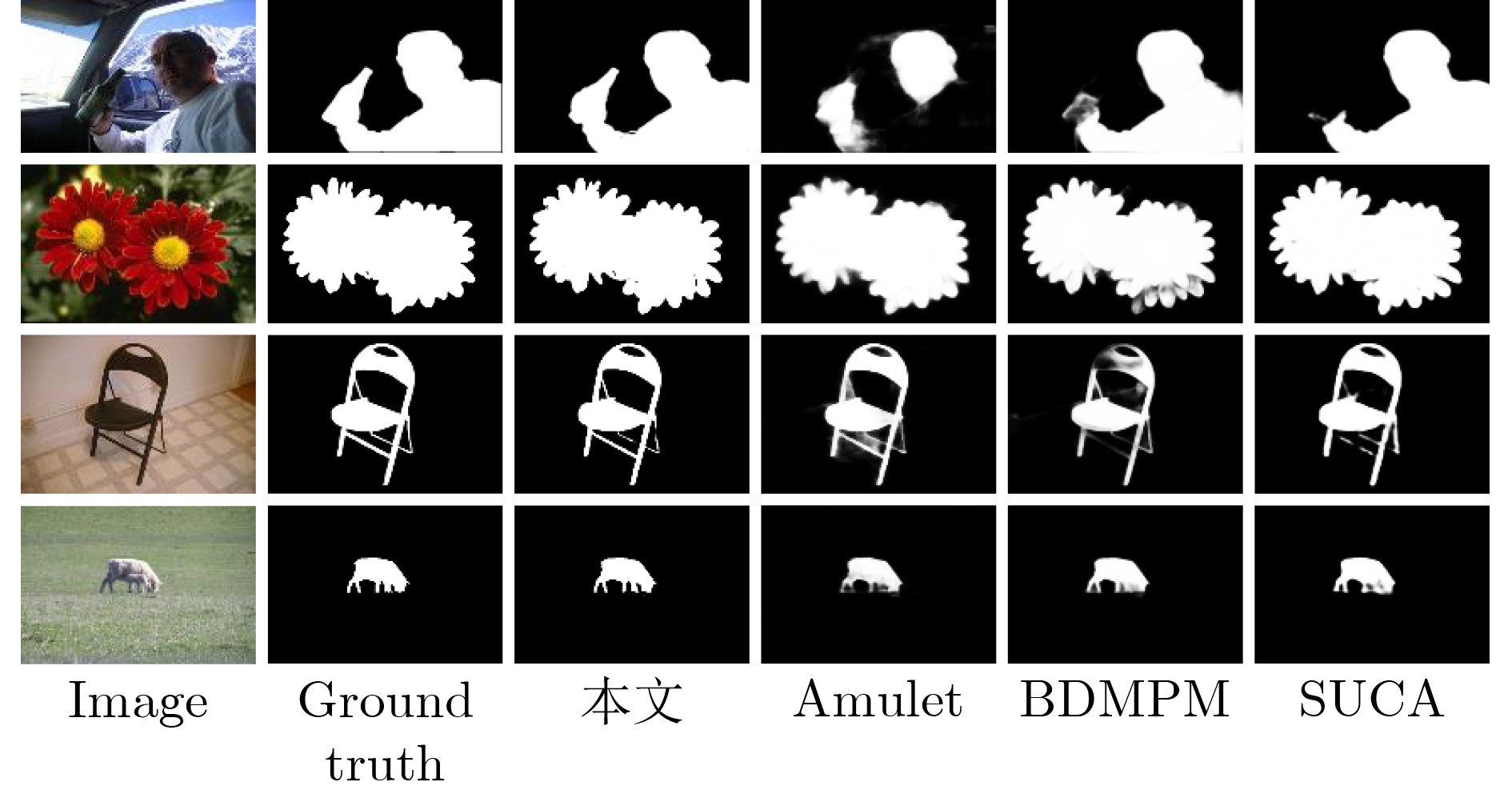
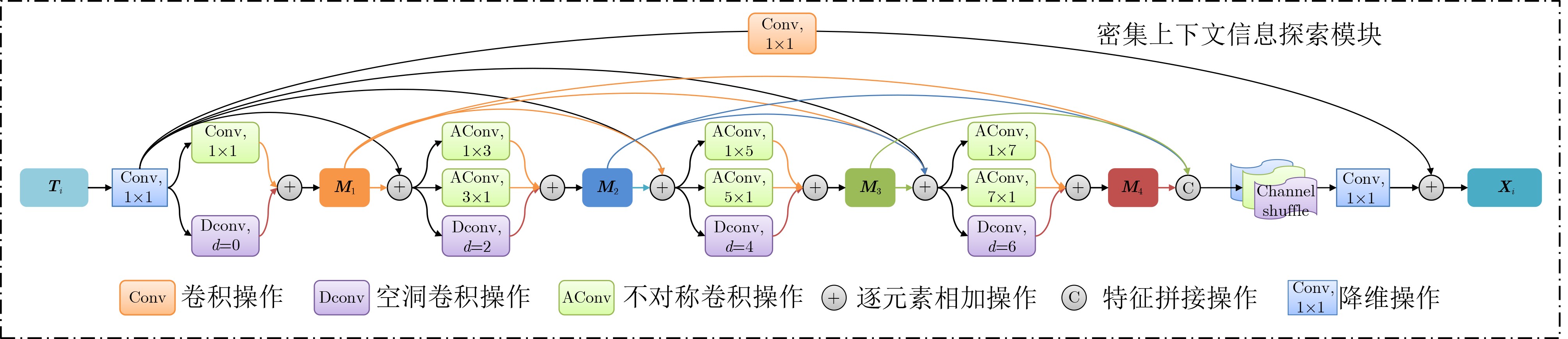
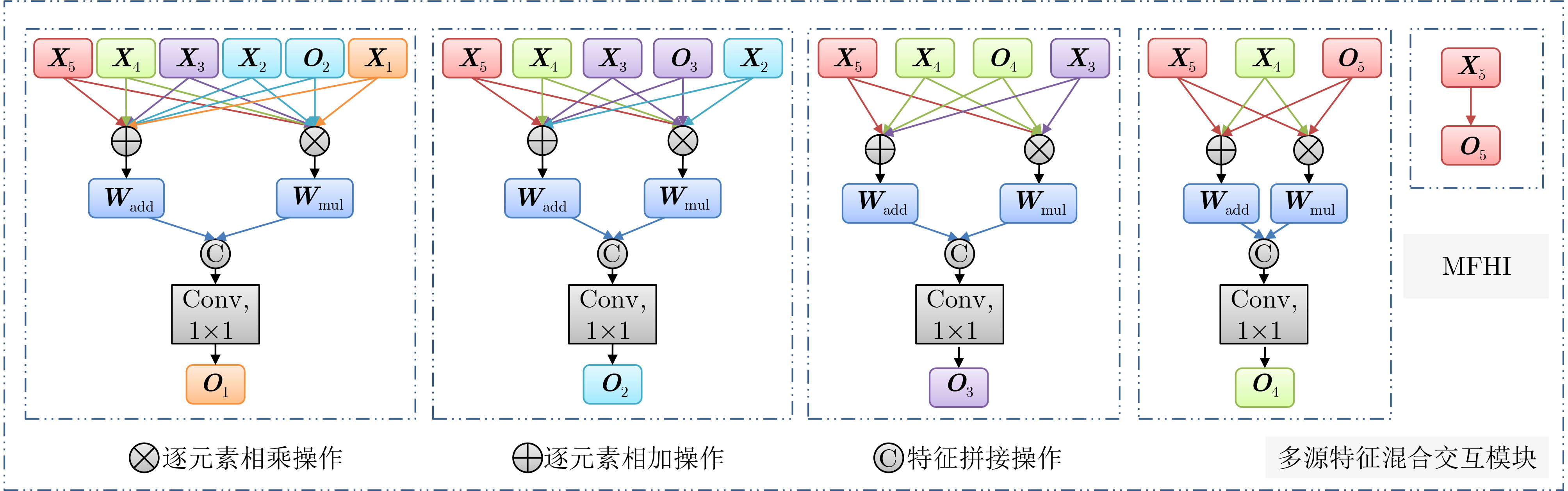
 下载:
下载:







图(11) / 表(6)
计量
- 文章访问数: 1219
- HTML全文浏览量: 586
- PDF下载量: 112
- 被引次数: 0
