

Multi-Scale Occluded Person Re-Identification Guided by Key Fine-Grained Information
-
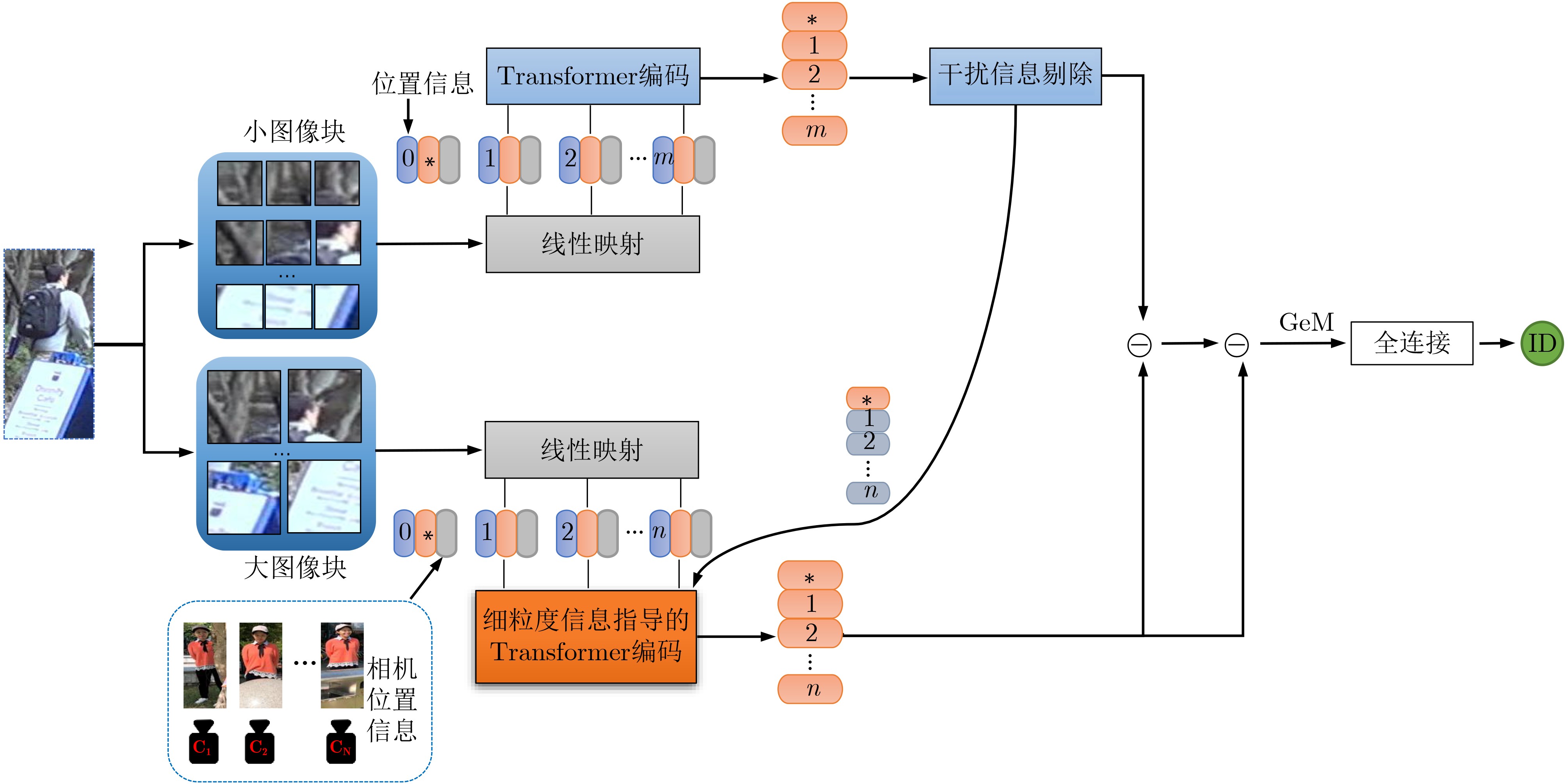
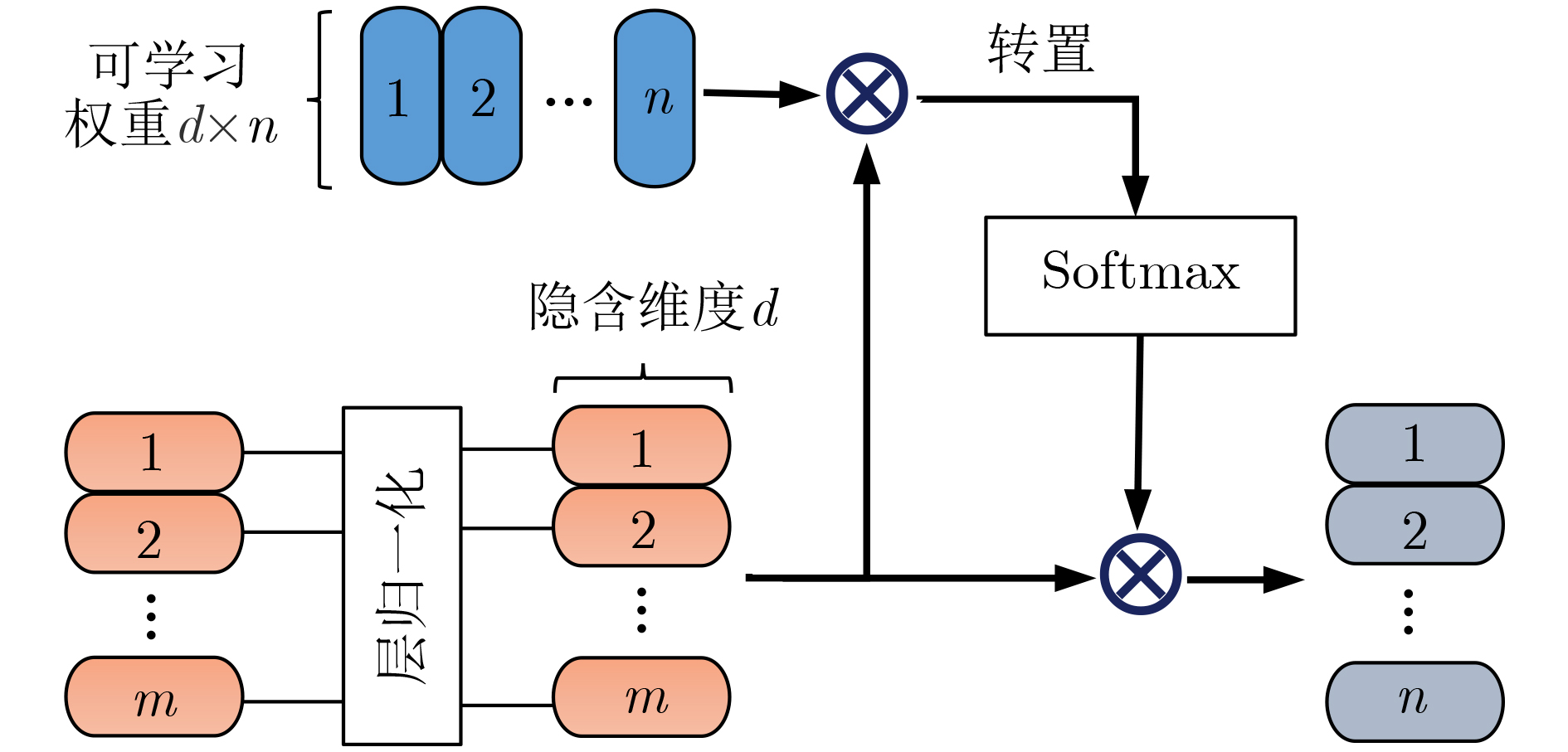
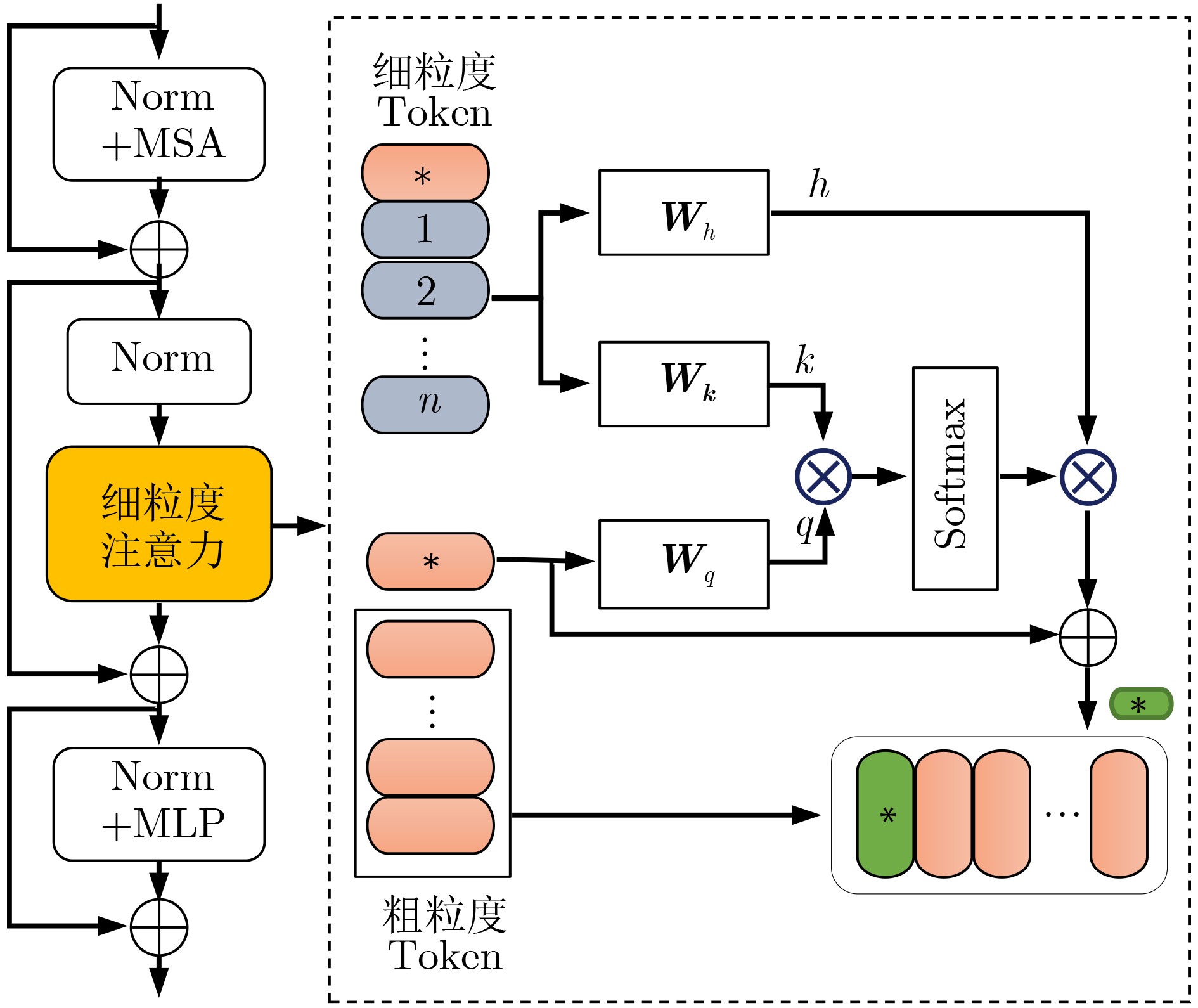
摘要: 为了减轻背景和遮挡等干扰信息对行人身份重识别(ReID)准确率的影响以及充分利用细粒度和粗粒度信息之间的互补性,该文提出关键细粒度信息指导的多尺度遮挡行人重识别网络。首先,将图像划分为两种不同尺寸的重叠图像块,构建同时包含细粒度和粗粒度信息提取分支的多尺度识别网络,以更好模拟人类观察图像时的多尺度特性以及观察相邻区域时的连续性特性。然后,考虑到细粒度分支能够提取更多的图像细节信息且细粒度和粗粒度信息之间存在一定的共性与差异,进一步通过细粒度注意力模块实现细粒度信息对粗粒度信息学习分支的指导。其中,参与指导的细粒度信息是通过干扰信息剔除(IIE)模块滤除干扰信息后保留的关键信息。最后,通过双次差分获取与行人身份识别相关的关键信息,并通过标签和特征等多维度的联合监督,实现行人身份的预测。在多个公开的行人重识别数据库进行的大量实验证明了该算法的性能优越性以及其中各个模块的有效性和必要性。Abstract: To reduce the influence of background and occlusion on the accuracy of pedestrian identity Re-IDentification (ReID) and make full use of the complementarity between fine-grained and coarse-grained information, a multi-scale occluded pedestrian ReID network guided by key fine-grained information is proposed. First, the image is divided into two types of overlapping patches with different sizes to better simulate the multi-scale characteristics of human observing images and the continuity characteristics of human observing adjacent regions, so a multi-scale recognition network containing both fine-grained and coarse-grained information extraction branches is constructed. Then, considering fine-grained information contains more details and there are similarities and differences between fine-grained and coarse-grained information, fine-grained attention module is further employed to realize the guide of the fine-grained branch to the coarse-grained branch. Among them, the fine-grained information is the key information retained after filtering out the interference information by the Interference Information Elimination (IIE) module. Finally, the key information related to pedestrian ReID is obtained by bivariate difference, and the prediction of pedestrian identity is realized by multi-dimensional joint supervision such as tags and features. Extensive experiments on several public pedestrian ReID databases prove the superiority of this algorithm and the effectiveness and necessity of each module.
-
表 3 本文算法及对比算法在全身数据集Market-1501和DukeMTMC上的实验结果(%)
方法 Market-1501 DukeMTMC Rank-1 mAP Rank-1 mAP PCB [5] 92.3 71.4 81.8 66.1 PGFA [8] 91.2 76.8 82.6 65.5 ISP [20] 95.3 88.6 89.6 80.0 HOReID [11] 94.2 84.9 86.9 75.6 MoS [4] 95.4 89.0 90.6 80.2 PAT [21] 95.4 88.0 88.8 78.2 TransReID* [14] 95.2 88.9 90.7 82.0 PFD [5] 95.5 89.7 91.2 83.2 本文算法 95.7 89.5 90.7 82.5  下载: 导出CSV
下载: 导出CSV
表 4 本文算法中各模块的贡献(%)
方法 Rank-1 Rank-5 Rank-10 mAP Baseline 61.9 78.2 83.8 53.1 Baseline +IIE 65.1 80.3 85.4 55.6 无FGI 65.7 80.0 84.6 58.0 无DD 64.2 80.2 85.1 57.0 粗粒度->细粒度 69.1 82.7 86.7 61.5 粗粒度<->细粒度 48.4 66.9 73.6 43.0 本文算法 71.2 82.9 86.9 62.3
下载: 导出CSV
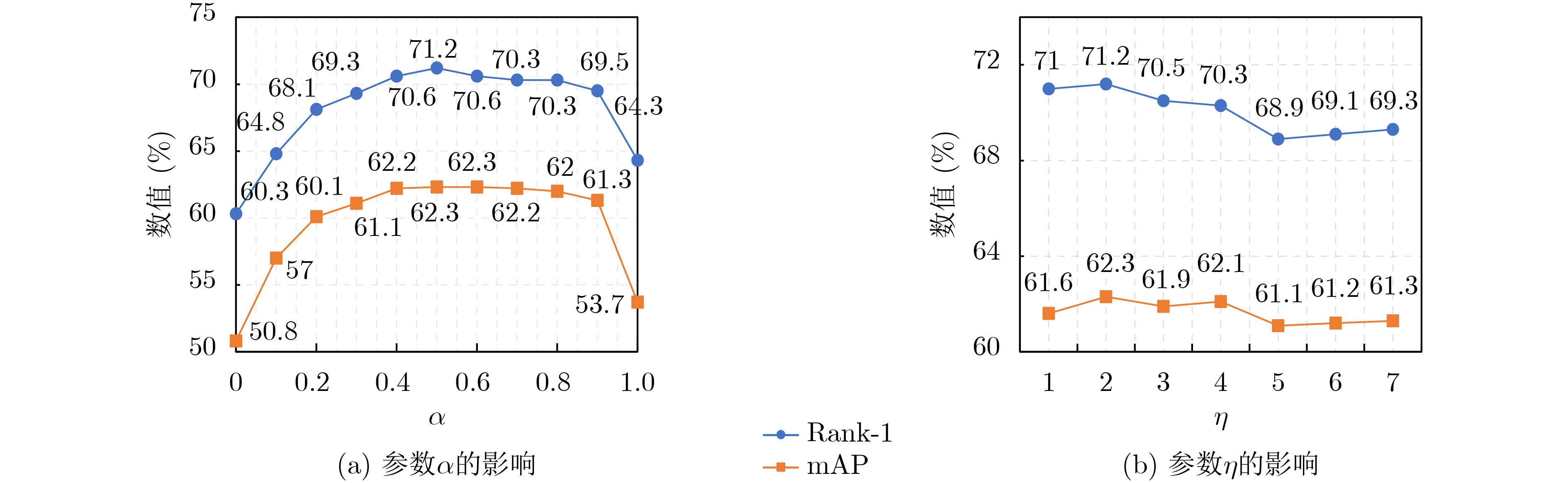
表 5 超参数$ {\omega _1} $和$ {\omega _2} $对算法性能Rank-1(mAP)的影响(%)
0 1 2 3 0 67.1(56.5) 67.1(56.8) 67.3(57.1) 67.9(58.5) 1 66.4(56.4) 68.5(58.1) 68.5(57.9) 67.3(57.4) 2 67.3(57.5) 67.9(57.2) 70.2(62.1) 68.7(58.9) 3 66.6(56.5) 67.6(57.4) 68.6(58.7) 71.2(62.3)
下载: 导出CSV
表 6 图像块尺寸对算法性能的影响(%)
4$ \times $4,
8$ \times $84$ \times $4,
12$ \times $124$ \times $4,
16$ \times $164$ \times $4,
20$ \times $208$ \times $8,
12$ \times $128$ \times $8,
16$ \times $168$ \times $8,
20$ \times $2012$ \times $12,
16$ \times $1612$ \times $12,
20$ \times $2016$ \times $16,
20$ \times $20Rank-1 63.3 66.4 64.3 64.8 69.3 68.7 70.2 71.2 69.6 66.5 mAP 52.9 55.7 53.8 55.4 59.9 59.1 60.2 62.3 59.4 57.2
下载: 导出CSV
表 7 3种尺度输入对算法性能的影响(%)
8$ \times $8, 12$ \times $12, 16$ \times $16 8$ \times $8, 12$ \times $12,20$ \times $20 8$ \times $8, 16$ \times $16,20$ \times $20 12$ \times $12, 16$ \times $16, 20$ \times $20 Rank-1 64 65 66.7 67.3 mAP 53.8 54.3 56 57.4 参数量 (M) 313.47 313.47 313.47 313.47 响应时间(s) 12.57 12.37 12.08 10.25
下载: 导出CSV
-
[1] 石跃祥, 周玥. 基于阶梯型特征空间分割与局部注意力机制的行人重识别[J]. 电子与信息学报, 2022, 44(1): 195–202. doi: 10.11999/JEIT201006.SHI Yuexiang and ZHOU Yue. Person re-identification based on stepped feature space segmentation and local attention mechanism[J]. Journal of Electronics & Information Technology, 2022, 44(1): 195–202. doi: 10.11999/JEIT201006. [2] 许文正, 黄天欢, 贲晛烨, 等. 跨视角步态识别综述[J]. 中国图象图形学报, 2023, 28(5): 1265–1286. doi: 10.11834/jig.220458.XU Wenzheng, HUANG Tianhuan, BEN Xianye, et al. Cross-view gait recognition: A review[J]. Journal of Image and Graphics, 2023, 28(5): 1265–1286. doi: 10.11834/jig.220458. [3] SUN Yifan, XU Qin, LI Yali, et al. Perceive where to focus: Learning visibility-aware part-level features for partial person re-identification[C]. The 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 393–402. doi: 10.1109/CVPR.2019.00048. [4] JIA Mengxi, CHENG Xinhua, ZHAI Yunpeng, et al. Matching on sets: Conquer occluded person re-identification without alignment[C/OL]. The 35th AAAI Conference on Artificial Intelligence, 2021: 1673–1681. doi: 10.1609/aaai.v35i2.16260. [5] WANG Tao, LIU Hong, SONG Pinhao, et al. Pose-guided feature disentangling for occluded person re-identification based on transformer[C/OL]. The 36th AAAI Conference on Artificial Intelligence, 2022: 2540–2549. doi: 10.1609/aaai.v36i3.20155. [6] YANG Jinrui, ZHANG Jiawei, YU Fufu, et al. Learning to know where to see: A visibility-aware approach for occluded person re-identification[C]. The IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 11865–11874. doi: 10.1109/iccv48922.2021.01167. [7] CHENG Xinhua, JIA Mengxi, WANG Qian, et al. More is better: Multi-source dynamic parsing attention for occluded person re-identification[C]. The 30th ACM International Conference on Multimedia, Lisbon, Portugal, 2022: 6840–6849. doi: 10.1145/3503161.3547819. [8] SOMERS V, DE VLEESCHOUWER C, and ALAHI A. Body part-based representation learning for occluded person re-identification[C]. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2023: 1613–1623. doi: 10.1109/WACV56688.2023.00166. [9] MIAO Jiaxu, WU Yu, LIU Ping, et al. Pose-guided feature alignment for occluded person re-identification[C]. The IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 542–551. doi: 10.1109/ICCV.2019.00063. [10] GAO Shang, WANG Jingya, LU Huchuan, et al. Pose-guided visible part matching for occluded person ReID[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 11741–11749. doi: 10.1109/CVPR42600.2020.01176. [11] WANG Guan’an, YANG Shuo, LIU Huanyu, et al. High-order information matters: Learning relation and topology for occluded person re-identification[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 6448–6457. doi: 10.1109/CVPR42600.2020.00648. [12] JIA Mengxi, CHENG Xinhua, LU Shijian, et al. Learning disentangled representation implicitly via transformer for occluded person re-identification[J]. IEEE Transactions on Multimedia, 2023, 25: 1294–1305. doi: 10.1109/tmm.2022.3141267. [13] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[C/OL]. The 9th International Conference on Learning Representations, 2021. [14] HE Shuting, LUO Hao, WANG Pichao, et al. TransReID: Transformer-based object re-identification[C]. The IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 14993–15002. doi: 10.1109/ICCV48922.2021.01474. [15] ZHOU Qinqin, ZHONG Bineng, LAN Xiangyuan, et al. Fine-grained spatial alignment model for person re-identification with focal triplet loss[J]. IEEE Transactions on Image Processing, 2020, 29: 7578–7589. doi: 10.1109/TIP.2020.3004267. [16] ZHUO Jiaxuan, CHEN Zeyu, LAI Jianhuang, et al. Occluded person re-identification[C]. 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, USA, 2018: 1–6. doi: 10.1109/ICME.2018.8486568. [17] ZHENG Liang, SHEN Liyue, TIAN Lu, et al. Scalable person re-identification: A benchmark[C]. The IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 1116–1124. doi: 10.1109/ICCV.2015.133. [18] ZHENG Zhedong, ZHENG Liang, and YANG Yi. Unlabeled samples generated by GAN improve the person re-identification baseline in vitro[C]. The IEEE International Conference on Computer Vision, Venice, Italy, 2017: 3774–3782. doi: 10.1109/ICCV.2017.405. [19] KRIZHEVSKY A, SUTSKEVER I, and HINTON G E. Imagenet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84–90. doi: 10.1145/3065386. [20] SUN Yifan, ZHENG Liang, YANG Yi, et al. Beyond part models: Person retrieval with refined part pooling (and A Strong Convolutional Baseline)[C]. The 15th European Conference on Computer Vision-ECCV, Munich, Germany, 2018: 501–518. doi: 10.1007/978-3-030-01225-0_30. [21] LI Yulin, HE Jianfeng, ZHANG Tianzhu, et al. Diverse part discovery: Occluded person re-identification with part-aware transformer[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 2897–2906. doi: 10.1109/CVPR46437.2021.00292. [22] HE Lingxiao, LIANG Jian, LI Haiqing, et al. Deep spatial feature reconstruction for partial person re-identification: Alignment-free approach[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7073–7082. doi: 10.1109/CVPR.2018.00739. [23] YAN Cheng, PANG Guansong, JIAO Jile, et al. Occluded person re-identification with single-scale global representations[C]. The IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 11855–11864. doi: 10.1109/ICCV48922.2021.01166. -

 下载:
下载:



图(5) / 表(7)
计量
- 文章访问数: 1202
- HTML全文浏览量: 604
- PDF下载量: 128
- 被引次数: 0
