

Resource Allocation Algorithm of Urban Rail Train-to-Train Communication with A2C-ac
-
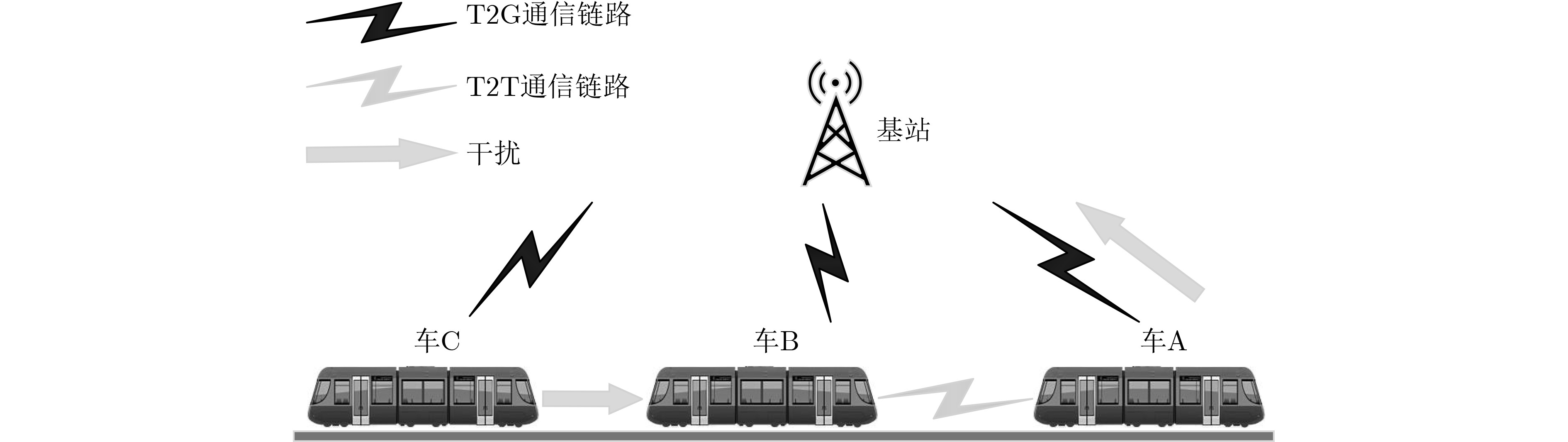
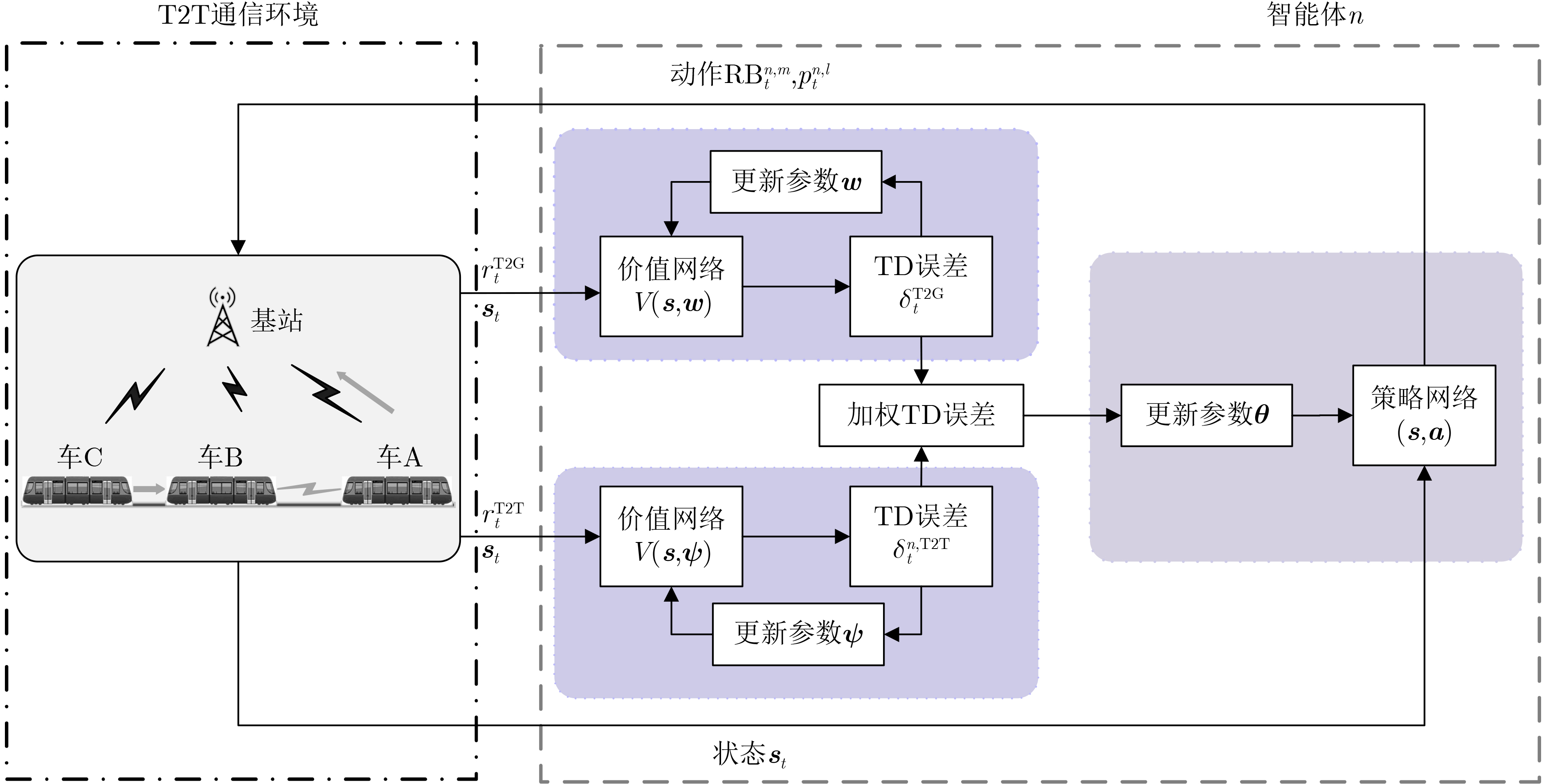
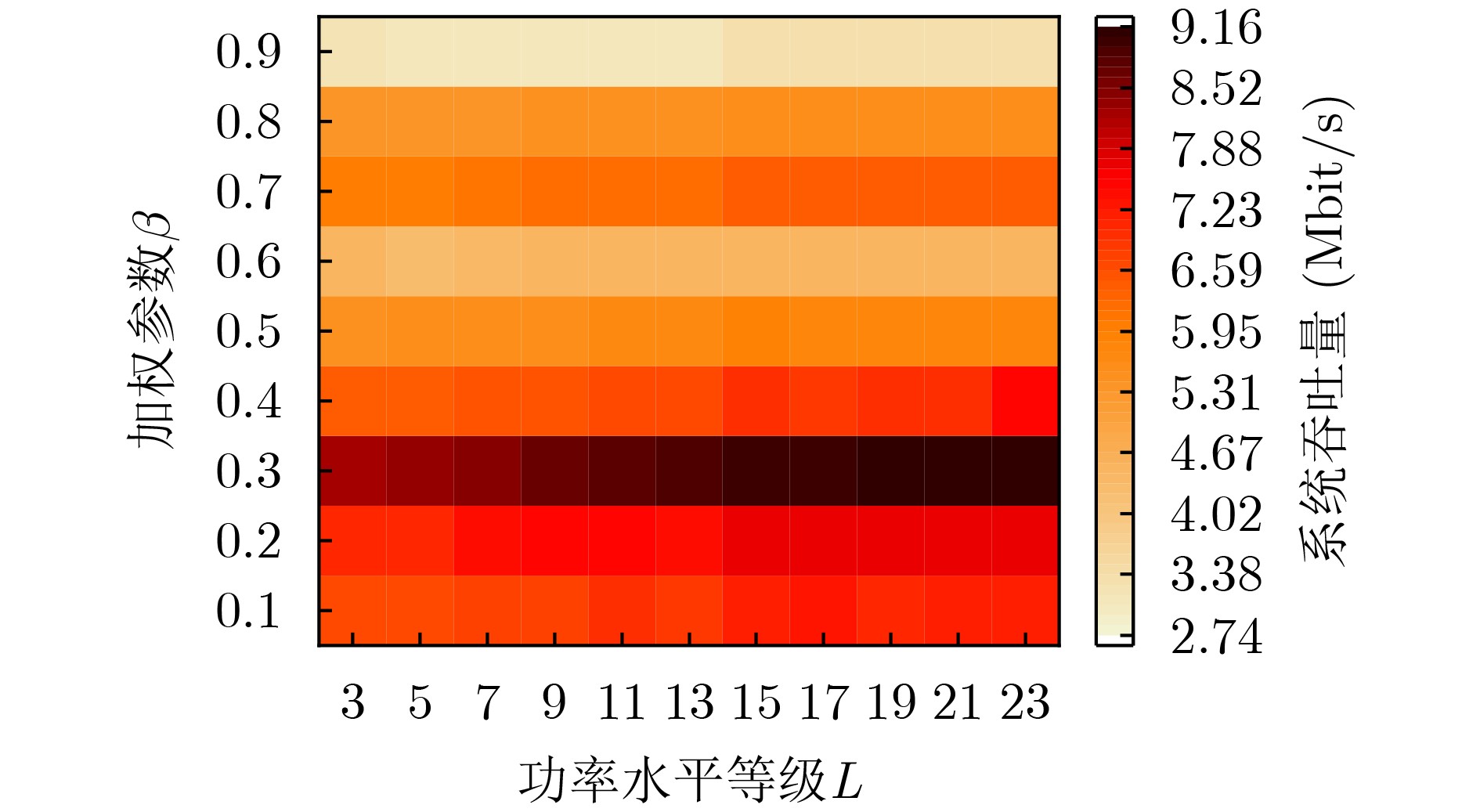
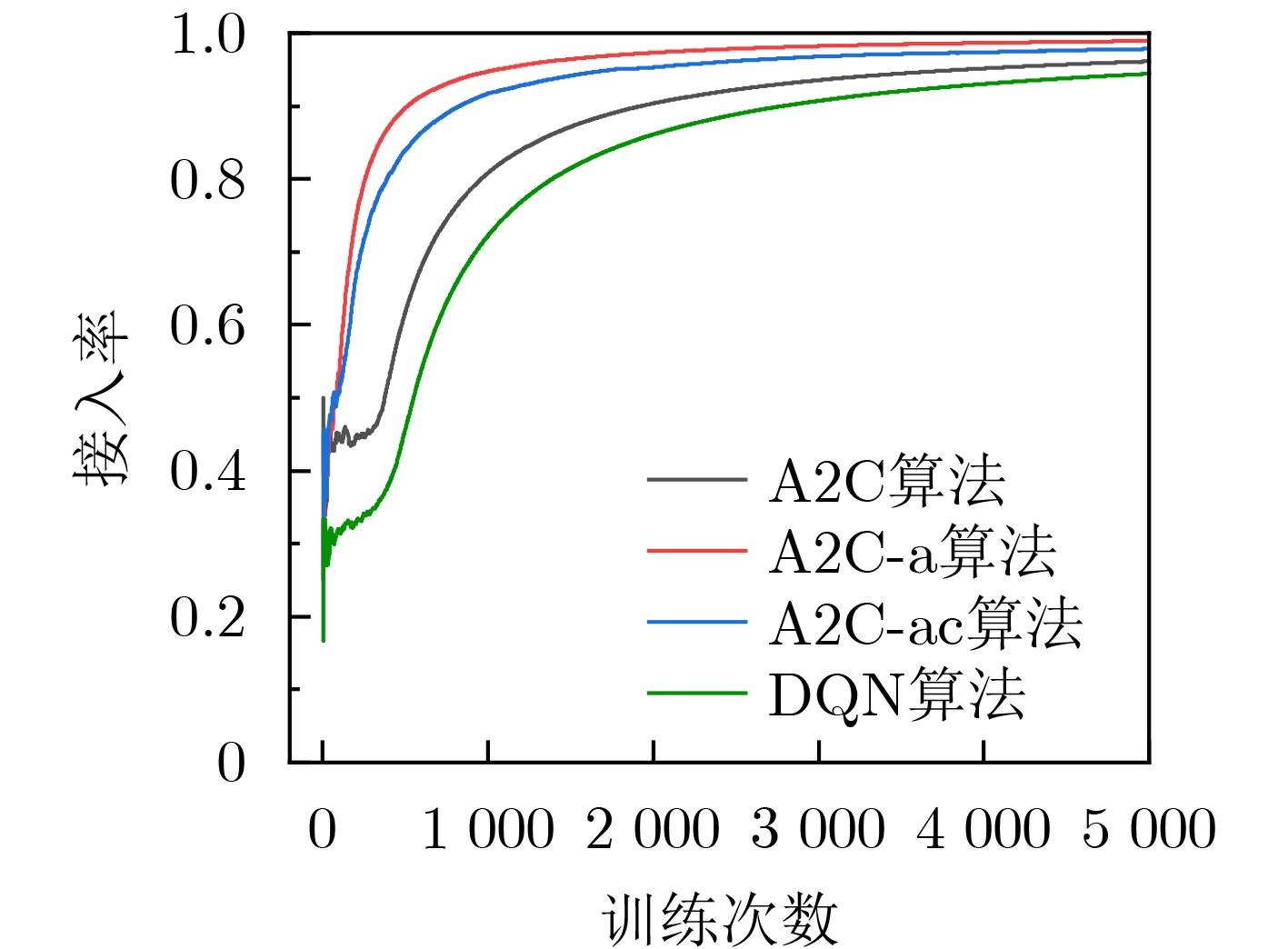
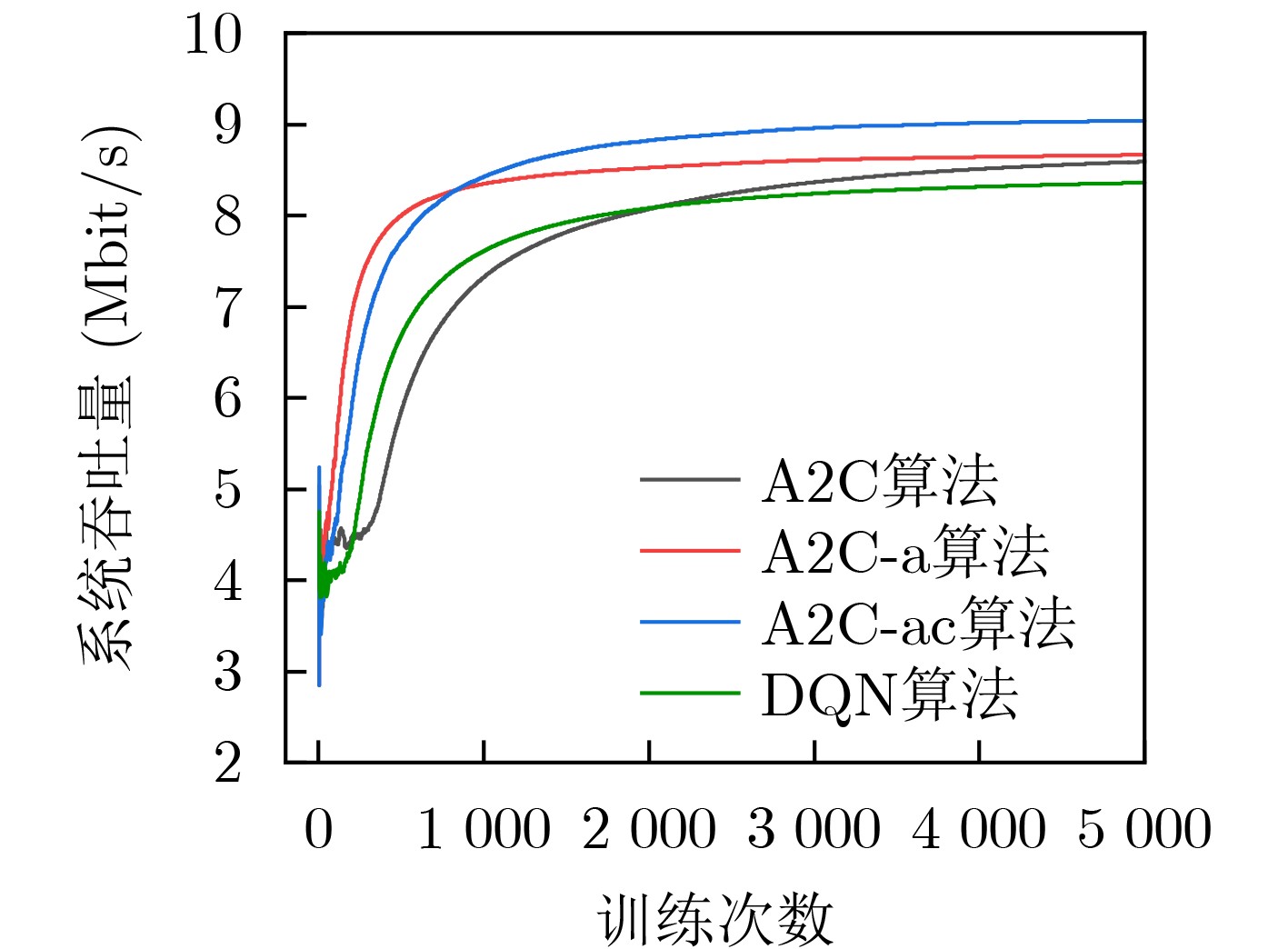
摘要: 在城市轨道交通列车控制系统中,车车(T2T)通信作为新一代列车通信模式,利用列车间直接通信来降低通信时延,提高列车运行效率。在T2T通信与车地(T2G)通信并存场景下,针对复用T2G链路产生的干扰问题,在保证用户通信质量的前提下,该文提出一种基于多智能体深度强化学习(MADRL)的改进优势演员-评论家(A2C-ac)资源分配算法。首先以系统吞吐量为优化目标,以T2T通信发送端为智能体,策略网络采用分层输出结构指导智能体选择需复用的频谱资源和功率水平,然后智能体做出相应动作并与T2T通信环境交互,得到该时隙下T2G用户和T2T用户吞吐量,价值网络对两者分别评价,利用权重因子$ \beta $为每个智能体定制化加权时序差分(TD)误差,以此来灵活优化神经网络参数。最后,智能体根据训练好的模型联合选出最佳的频谱资源和功率水平。仿真结果表明,该算法相较于A2C算法和深度Q网络(DQN)算法,在收敛速度、T2T成功接入率、吞吐量等方面均有明显提升。
-
关键词:
- 城市轨道交通 /
- 资源分配 /
- T2T通信 /
- 多智能体深度强化学习 /
- A2C-ac算法
Abstract: In the train control system of urban rail transit, Train-to-Train (T2T) communication, a new train communication mode, use direct communication between trains to reduce communication delay and improve train operation efficiency. In the scenario of the coexistence of T2T communication and Train to Ground (T2G) communication, an improved Advantage Actor-Critic-ac (A2C-ac) resource allocation algorithm based on Multi-Agent Deep Reinforcement Learning (MADRL) is proposed to solve the interference problem caused by multiplexing T2G links, and under the premise of ensuring the quality of user communication. Firstly, taking the system throughput as the optimization goal and the T2T communication transmitter as the agent, the policy network adopts a hierarchical output structure to guide the agent in selecting the spectrum resources and power level to be reused. Then the agent makes corresponding actions and interacts with the communication environment to obtain the throughput of T2G users and T2T users in the time slot. The value network evaluates the two separately and uses the weight factor $ \beta $ to customize the weighted Temporal Difference (TD) error for each agent to optimize the neural network parameters flexibly. Finally, the agents jointly select the best spectral resources and power levels according to the trained model. The simulation results show that compared with the A2C and Deep Q-Networks (DQN) algorithms, the proposed algorithm has significantly improved the convergence speed, T2T successful access rate, and the throughput. -
算法1 基于A2C-ac的T2T通信资源分配算法 (1) 初始化:初始化超参数$ \gamma $, $ \beta $,$ {\alpha _{\boldsymbol{\theta}} } $, $ {\alpha _{\boldsymbol{w}}} $, $ {\alpha _{\boldsymbol{\psi}} } $;初始环境状态${{\boldsymbol{s}}_0}$;初始化神经网络参数$ {\boldsymbol{\theta}} $, $ {\boldsymbol{w}} $,$ {\boldsymbol{\psi}} $; (2) For $ t $=0: T do (3) For n=0: N do (4) 根据策略${\pi _{\boldsymbol{\theta}} }({ {\rm{RB} } }_t^n|{\boldsymbol{s}})$与${\pi _{\boldsymbol{\theta}} }(p_t^{n,l}|{\boldsymbol{s}})$各采样一个动作${{\rm{RB}}}_t^n$,$ p_t^{n,l} $ (5) End (6) 执行动作${{\rm{RB}}}_t^n$, $ p_t^{n,l} $,得到T2G用户吞吐量奖励$r_t^{ {{\rm{T2G}}} }$和T2T用户吞吐量奖励$r_t^{n,{{\rm{T2T}}} }$,并得到新的观测状态${{\boldsymbol{s}}_{t + 1} }$; (7) 计算T2G用户吞吐量TD误差:$\delta _t^{ { {\rm{T2G} } } } = r_t^{ { {\rm{T2G} } } } + \gamma V_{\boldsymbol{w}}^{ { {\rm{T2G} } } }({{\boldsymbol{s}}_{t + 1} }) - V_{\boldsymbol{w}}^{ {{\rm{T2G}}} }({{\boldsymbol{s}}_t})$; (8) 更新T2G用户价值网络参数: ${ {\boldsymbol{w} }_{t + 1} } = { {\boldsymbol{w} }_t} + {\alpha _w}{ \nabla _w}V_w^{ { {\rm{T2G} } } }({ {\boldsymbol{s} }_t})\delta _t^{ { {\rm{T2G} } } }$; (9) For n=0: N do (10) 计算T2T用户n吞吐量TD误差:$\delta _t^{n,{ {\rm{T2T} } } } = r_t^{n,{ {\rm{T2T} } } } + \gamma V_{\boldsymbol{\psi}} ^{n,{ {\rm{T2T} } } }({ {\boldsymbol{s} }_{t + 1} }) - V_{\boldsymbol{\psi}} ^{n,{ {\rm{T2T} } } }({ {\boldsymbol{s} }_t})$; (11) 更新智能体n的价值网络参数:${\boldsymbol{\psi} } _{t + 1}^n = {\boldsymbol{\psi} } _t^n + {\alpha _{\boldsymbol{\psi} } }{\nabla _{\boldsymbol{\psi}} }V_{\boldsymbol{\psi} } ^{n,{ {\rm{T2T} } } }({ {\boldsymbol{s} }_t})\delta _t^{n,{ {\rm{T2T} } } }$; (12) 计算加权TD误差:$\delta _t^n = \beta \delta _t^{ {{\rm{T2G}}} } + (1 - \beta )\delta _t^{n,{{\rm{T2T}}} }$; (13) 更新智能体n的策略网络参数:${\boldsymbol{\theta}} _{t + 1}^n = {\boldsymbol{\theta}} _t^n + {\alpha _{\boldsymbol{\theta}} }{ \nabla _{\boldsymbol{\theta }}}\ln \pi _{\boldsymbol{\theta}} ^n({ {\rm{RB} } }_t^n|{ {\boldsymbol{s} }_t})\delta _t^n$ ${\boldsymbol{\theta}} _{t + 1}^n = {\boldsymbol{\theta}} _t^n + {\alpha _{\boldsymbol{\theta}} }{ \nabla _{\boldsymbol{\theta}} }\ln \pi _{\boldsymbol{\theta}} ^n(p_t^{n,l}|{ {\boldsymbol{s} }_t})\delta _t^n$ (14) End (15) 更新所有智能体状态:${{\boldsymbol{s}}_t} = {{\boldsymbol{s}}_{t + 1} }$ (16) End  下载: 导出CSV
下载: 导出CSV
-
[1] AI Bo, CHENG Xiang, KÜRNER T, et al. Challenges toward wireless communications for high-speed railway[J]. IEEE Transactions on Intelligent Transportation Systems, 2014, 15(5): 2143–2158. doi: 10.1109/TITS.2014.2310771. [2] 林俊亭, 王晓明, 党垚, 等. 城市轨道交通列车碰撞防护系统设计与研究[J]. 铁道科学与工程学报, 2015, 12(2): 407–413. doi: 10.19713/j.cnki.43-1423/u.2015.02.028.LIN Junting, WANG Xiaoming, DANG Yao, et al. Design and research of the improved train control system with collision avoidance system for urban mass transit[J]. Journal of Railway Science and Engineering, 2015, 12(2): 407–413. doi: 10.19713/j.cnki.43-1423/u.2015.02.028. [3] 胡雪旸, 周庆华. 基于D2D的列控系统车车通信资源分配算法[J]. 铁道标准设计, 2019, 63(3): 153–157. doi: 10.13238/j.issn.1004-2954.201804080010.HU Xueyang and ZHOU Qinghua. T2T (Train to Train) communication resource allocation algorithm based on D2D[J]. Railway Standard Design, 2019, 63(3): 153–157. doi: 10.13238/j.issn.1004-2954.201804080010. [4] 申滨, 孙万平, 张楠, 等. 基于加权二部图及贪婪策略的蜂窝网络D2D通信资源分配[J]. 电子与信息学报, 2023, 45(3): 1055–1064. doi: 10.11999/JEIT220029.SHEN Bin, SUN Wanping, ZHANG Nan, et al. Resource allocation based on weighted bipartite graph and greedy strategy for D2D communication in cellular networks[J]. Journal of Electronics &Information Technology, 2023, 45(3): 1055–1064. doi: 10.11999/JEIT220029. [5] HU Jinming, HENG Wei, ZHU Yaping, et al. Overlapping coalition formation games for joint interference management and resource allocation in D2D communications[J]. IEEE Access, 2018, 6: 6341–6349. doi: 10.1109/ACCESS.2018.2800159. [6] XIAO Yong, CHEN K C, YUEN C, et al. A Bayesian overlapping coalition formation game for device-to-device spectrum sharing in cellular networks[J]. IEEE Transactions on Wireless Communications, 2015, 14(7): 4034–4051. doi: 10.1109/TWC.2015.2416178. [7] 高云波, 程璇, 李翠然, 等. T2T和T2G混合网络中的功率分配算法[J/OL]. 西南交通大学学报, 2022, 1–9.GAO Yunbo, CHENG Xuan, LI Cuiran, et al. Power allocation algorithm in T2T and T2G hybrid network[J/OL]. Journal of Southwest Jiaotong University, 2022, 1–9. [8] 吕宏志. 城市轨道交通车车通信资源分配算法研究[D]. [硕士论文], 兰州交通大学, 2021.LV Hongzhi. Research on train to train communication resource allocation algorithm of urban rail transit[D]. [Master dissertation], Lanzhou Jiaotong University, 2021. [9] 陈垚, 赵军辉, 张青苗, 等. 车车通信中通信模式选择与资源分配算法[J]. 计算机工程与应用, 2022, 58(10): 93–100. doi: 10.3778/j.issn.1002-8331.2012-0104.CHEN Yao, ZHAO Junhui, ZHANG Qingmiao, et al. Communication mode selection and resource allocation algorithm for train-to-train communication[J]. Computer Engineering and Applications, 2022, 58(10): 93–100. doi: 10.3778/j.issn.1002-8331.2012-0104. [10] TAN Junjie, LIANG Yingchang, ZHANG Lin, et al. Deep reinforcement learning for joint channel selection and power control in D2D networks[J]. IEEE Transactions on Wireless Communications, 2021, 20(2): 1363–1378. doi: 10.1109/TWC.2020.3032991. [11] ZHAO Junhui, ZHANG Yang, NIE Yiwen, et al. Intelligent resource allocation for train-to-train communication: A multi-agent deep reinforcement learning approach[J]. IEEE Access, 2020, 8: 8032–8040. doi: 10.1109/ACCESS.2019.2963751. [12] 赵军辉, 陈垚, 张青苗. 基于深度强化学习的车车通信智能频谱共享[J]. 铁道科学与工程学报, 2022, 19(3): 841–848. doi: 10.19713/j.cnki.43-1423/u.t20210364.ZHAO Junhui, CHEN Yao, and ZHANG Qingmiao. Intelligent spectrum sharing for train-to-train communication based on deep reinforcement learning[J]. Journal of Railway Science and Engineering, 2022, 19(3): 841–848. doi: 10.19713/j.cnki.43-1423/u.t20210364. [13] 唐伦, 贺小雨, 王晓, 等. 基于异步优势演员-评论家学习的服务功能链资源分配算法[J]. 电子与信息学报, 2021, 43(6): 1733–1741. doi: 10.11999/JEIT200287.TANG Lun, HE Xiaoyu, WANG Xiao, et al. Resource allocation algorithm of service function chain based on asynchronous advantage actor-critic learning[J]. Journal of Electronics &Information Technology, 2021, 43(6): 1733–1741. doi: 10.11999/JEIT200287. [14] 刘伟, 郑润泽, 张磊, 等. 基于A2C算法的低轨星座动态波束资源调度研究[J]. 中国空间科学技术, 2023, 43(3): 123–133. doi: 10.16708/j.cnki.1000-758X.2023.0045.LIU Wei, ZHENG Runze, ZHANG Lei, et al. Research of dynamic beam resource scheduling of LEO constellation based on A2C algorithm[J]. Chinese Space Science and Technology, 2023, 43(3): 123–133. doi: 10.16708/j.cnki.1000-758X.2023.0045. [15] WANG Xiaoxuan, LIU Liangjia, TANG Tao, et al. Enhancing communication-based train control systems through train-to-train communications[J]. IEEE Transactions on Intelligent Transportation Systems, 2019, 20(4): 1544–1561. doi: 10.1109/TITS.2018.2856635. [16] SUN Zhenfeng and NAKHAI M R. Channel selection and power control for D2D communication via online reinforcement learning[C]. 2021 IEEE International Conference on Communications, Montreal, Canada, 2021: 1–6. -

 下载:
下载:






图(9) / 表(1)
计量
- 文章访问数: 1097
- HTML全文浏览量: 578
- PDF下载量: 44
- 被引次数: 0
