

Action Recognition Network Combining Spatio-Temporal Adaptive Graph Convolution and Transformer
-
摘要: 在一个以人为中心的智能工厂中,感知和理解工人的行为是至关重要的,不同工种类别往往与工作时间和工作内容相关。该文通过结合自适应图和Transformer两种方式使模型更关注骨架的时空信息来提高模型识别的准确率。首先,采用一个自适应的图方法去关注除人体骨架之外的连接关系。进一步,采用Transformer框架去捕捉工人骨架在时间维度上的动态变化信息。为了评估模型性能,制作了智能生产线装配任务中6种典型的工人动作数据集,并进行验证,结果表明所提模型在Top-1精度上与主流动作识别模型相当。最后,在公开的NTU-RGBD和Skeleton-Kinetics数据集上,将该文模型与一些主流方法进行对比,实验结果表明,所提模型具有良好鲁棒性。
-
关键词:
- 智能工厂 /
- 工人动作识别 /
- 深度学习 /
- 自适应图 /
- Transformer
Abstract: In a human-centered smart factory, perceiving and understanding workers’ behavior is crucial, as different job categories are often associated with work time and tasks. In this paper, the accuracy of the model’s recognition is improved by combining two approaches, namely adaptive graphs and Transformers, to focus more on the spatiotemporal information of the skeletal structure. Firstly, an adaptive graph method is employed to capture the connectivity relationships beyond the human body skeleton. Furthermore, the Transformer framework is utilized to capture the dynamic temporal variations of the worker’s skeleton. To evaluate the model’s performance, six typical worker action datasets are created for intelligent production line assembly tasks and validated. The results indicate that the model proposed in this article has a Top-1 accuracy comparable to mainstream action recognition models. Finally, the proposed model is compared with several mainstream methods on the publicly available NTU-RGBD and Skeleton-Kinetics datasets, and the experimental results demonstrate the robustness of the model proposed in this paper. -
表 2 工人的行为数据集样本分布
自愿者编号 GT HN UP DW TS UT 1 39 27 25 18 28 41 2 21 35 15 24 17 32 3 25 20 37 31 33 35 4 31 30 18 29 46 29 合计 116 112 95 102 124 137  下载: 导出CSV
下载: 导出CSV
表 4 在NTU-RGBD数据集上和其他有竞争力的方法进行比较(%)
方法 X-Sub X-View Lie Group [4] 50.10 82.80 Deep LSTM [23] 60.70 67.30 ARRN-LSTM [10] 80.70 88.80 nd-RNN [11] 81.80 88.00 TCN [13] 74.30 83.10 Clips+CNN+MTLN [14] 79.60 84.80 Synthesized CNN [15] 80.00 87.20 CNN+Motion+Trans [16] 83.20 89.30 ST-GCN [18] 81.50 88.30 Shift-GCN [12] 90.70 96.50 MSST-Net [9] 86.60 92.80 DPRL+GCNN [19] 83.50 89.80 本文模型 85.95 91.85
下载: 导出CSV
表 6 比较Transformer的各个组件对工人动作识别精度(%)的影响
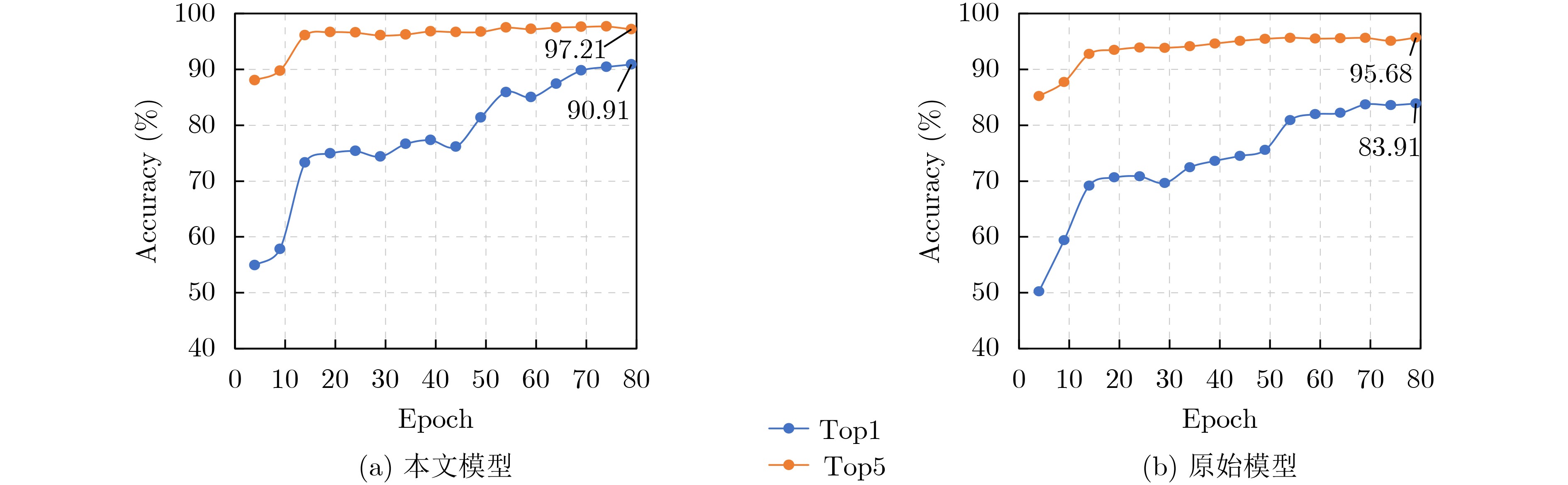
方法 Top-1 Top-5 MHA 38.28 40.95 MHA+FFN 54.67 62.61 MHA+FFN+PE 76.68 87.88 GCN+FFN+PE 70..53 81.37 AGCN+FFN+PE 75.42 86.68 ST-GCN+Transformer 87.61 92.91 STA-GCN+Transformer 90.91 97.21
下载: 导出CSV
-
[1] 石跃祥, 朱茂清. 基于骨架动作识别的协作卷积Transformer网络[J]. 电子与信息学报, 2023, 45(4): 1485–1493. doi: 10.11999/JEIT220270.SHI Yuexiang and ZHU Maoqing. Collaborative convolutional transformer network based on skeleton action recognition[J]. Journal of Electronics & Information Technology, 2023, 45(4): 1485–1493. doi: 10.11999/JEIT220270. [2] GEDAMU K, JI Yanli, GAO Lingling, et al. Relation-mining self-attention network for skeleton-based human action recognition[J]. Pattern Recognition, 2023, 139: 109455. doi: 10.1016/j.patcog.2023.109455. [3] GUO Hongling, ZHANG Zhitian, YU Run, et al. Action recognition based on 3D skeleton and LSTM for the monitoring of construction workers’ safety harness usage[J]. Journal of Construction Engineering and Management, 2023, 149(4): 04023015. doi: 10.1061/JCEMD4.COENG-12542. [4] VEMULAPALLI R, ARRATE F, and CHELLAPPA R. Human action recognition by representing 3D skeletons as points in a lie group[C]. 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 588–595. doi: 10.1109/CVPR.2014.82. [5] HEDEGAARD L, HEIDARI N, and IOSIFIDIS A. Continual spatio-temporal graph convolutional networks[J]. Pattern Recognition, 2023, 140: 109528. doi: 10.1016/j.patcog.2023.109528. [6] YU B X B, LIU Yan, ZHANG Xiang, et al. Mmnet: A model-based multimodal network for human action recognition in RGB-D videos[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(3): 3522–3538. doi: 10.1109/TPAMI.2022.3177813. [7] SHI Lei, ZHANG Yifan, CHENG Jian, et al. Decoupled spatial-temporal attention network for skeleton-based action-gesture recognition[C]. The 15th Asian Conference on Computer Vision, Kyoto, Japan, 2021. doi: 10.1007/978-3-030-69541-5_3. [8] 陈莹, 龚苏明. 改进通道注意力机制下的人体行为识别网络[J]. 电子与信息学报, 2021, 43(12): 3538–3545. doi: 10.11999/JEIT200431.CHEN Ying and GONG Suming. Human action recognition network based on improved channel attention mechanism[J]. Journal of Electronics & Information Technology, 2021, 43(12): 3538–3545. doi: 10.11999/JEIT200431. [9] CHENG Qin, REN Ziliang, CHENG Jun, et al. Skeleton-based action recognition with multi-scale spatial-temporal convolutional neural network[C]. 2021 IEEE International Conference on Real-time Computing and Robotics, Xining, China, 2021: 957–962. doi: 10.1109/RCAR52367.2021.9517665. [10] LI Lin, ZHANG Wu, ZHANG Zhaoxiang, et al. Skeleton-based relational modeling for action recognition[J]. arXiv preprint arXiv: 1805.02556, 2018. [11] LI Shuai, LI Wangqiang, COOK C, et al. Independently recurrent neural network (IndRNN): Building a longer and deeper RNN[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 5457–5466. doi: 10.1109/CVPR.2018.00572. [12] CHENG Ke, ZHANG Yifan, HE Xiangyu, et al. Skeleton-based action recognition with shift graph convolutional network[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 183–192. doi: 10.1109/CVPR42600.2020.00026. [13] KIM T S and REITER A. Interpretable 3D human action analysis with temporal convolutional networks[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, USA, 2017: 1623–1631. doi: 10.1109/CVPRW.2017.207. [14] KE Q H, BENNAMOUN M, AN S J, et al. A new representation of skeleton sequences for 3D action recognition[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 3288–3297. doi: 10.1109/CVPR.2017.486. [15] LIU Mengyuan, LIU Hong, and CHEN Chen. Enhanced skeleton visualization for view invariant human action recognition[J]. Pattern Recognition, 2017, 68: 346–362. doi: 10.1016/j.patcog.2017.02.030. [16] DU Yong, FU Yun, and WANG Liang. Skeleton based action recognition with convolutional neural network[C]. 2015 3rd IAPR Asian Conference on Pattern Recognition, Kuala Lumpur, Malaysia, 2015: 579–583. doi: 10.1109/ACPR.2015.7486569. [17] DUAN Haodong, ZHAO Yue, CHEN Kai, et al. Revisiting skeleton-based action recognition[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 2969–2978. doi: 10.1109/CVPR52688.2022.00298. [18] YAN Sijie, XIONG Yuanjun, and LIN Dahua. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]. The Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, New Orleans, USA, 2018: 912. [19] TANG Yansong, TIAN Yi, LU Jiwen, et al. Deep progressive reinforcement learning for skeleton-based action recognition[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 5323–5332. doi: 10.1109/CVPR.2018.00558. [20] BASAK H, KUNDU R, SINGH P K, et al. A union of deep learning and swarm-based optimization for 3D human action recognition[J]. Scientific Reports, 2022, 12(1): 5494. doi: 10.1038/s41598-022-09293-8. [21] CAO Zhe, SIMON T, WEI S E, et al. Realtime multi-person 2D pose estimation using part affinity fields[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 7291–7299. doi: 10.1109/CVPR.2017.143. [22] CHEN Yuxin, ZHANG Ziqi, YUAN Chunfeng, et al. Channel-wise topology refinement graph convolution for skeleton-based action recognition[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 13359–13368. doi: 10.1109/ICCV48922.2021.01311. [23] SHAHROUDY A, LIU Jun, NG T T, et al. NTU RGB+d: A large scale dataset for 3D human activity analysis[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 1010–1019. doi: 10.1109/CVPR.2016.115. [24] SEIDENARI L, VARANO V, BERRETTI S, et al. Recognizing actions from depth cameras as weakly aligned multi-part bag-of-poses[C]. 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, USA, 2013: 479–485. doi: 10.1109/CVPRW.2013.77. [25] SLAMA R, WANNOUS H, DAOUDI M, et al. Accurate 3D action recognition using learning on the Grassmann manifold[J]. Pattern Recognition, 2015, 48(2): 556–567. doi: 10.1016/j.patcog.2014.08.011. [26] SHI Lei, ZHANG Yifan, CHENG Jian, et al. Skeleton-based action recognition with multi-stream adaptive graph convolutional networks[J]. IEEE Transactions on Image Processing, 2020, 29: 9532–9545. doi: 10.1109/TIP.2020.3028207. [27] STIEFMEIER T, ROGGEN D, OGRIS G, et al. Wearable activity tracking in car manufacturing[J]. IEEE Pervasive Computing, 2008, 7(2): 42–50. doi: 10.1109/MPRV.2008.40. [28] WANG Limin, XIONG Yuanjun, WANG Zhe, et al. Temporal segment networks: Towards good practices for deep action recognition[C]. The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 20–36. doi: 10.1007/978-3-319-46484-8_2. [29] JIANG Wenchao and YIN Zhaozheng. Human activity recognition using wearable sensors by deep convolutional neural networks[C]. The 23rd ACM international conference on Multimedia, Brisbane, Australia, 2015: 1307–1310. doi: 10.1145/2733373.2806333. [30] TAO Wenjin, LEU M C, and YIN Zhaozheng. Multi-modal recognition of worker activity for human-centered intelligent manufacturing[J]. Engineering Applications of Artificial Intelligence, 2020, 95: 103868. doi: 10.1016/j.engappai.2020.103868. [31] SONG Yifan, ZHANG Zhang, SHAN Caifeng, et al. Constructing stronger and faster baselines for skeleton-based action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(2): 1474–1488. doi: 10.1109/TPAMI.2022.3157033. -

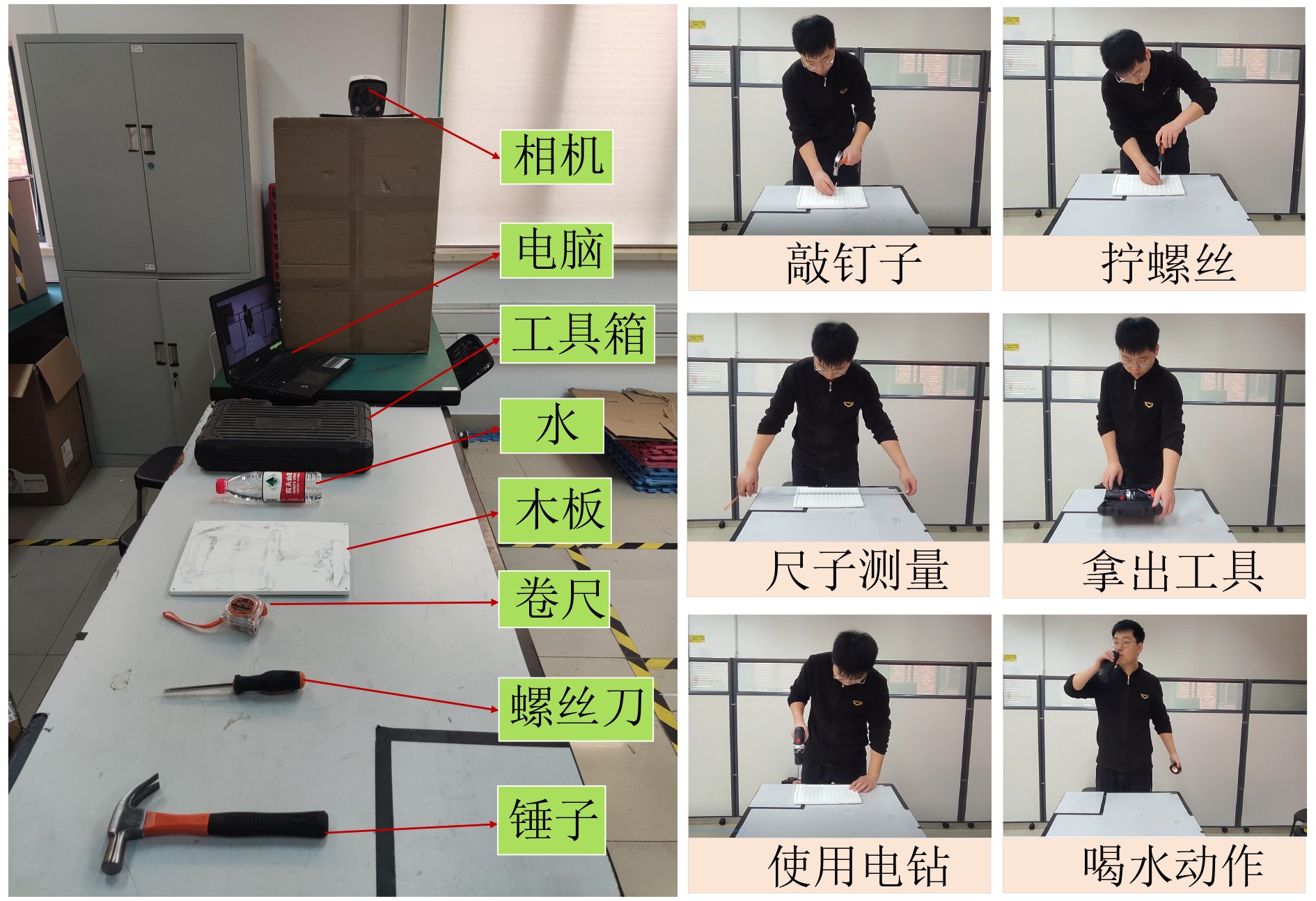
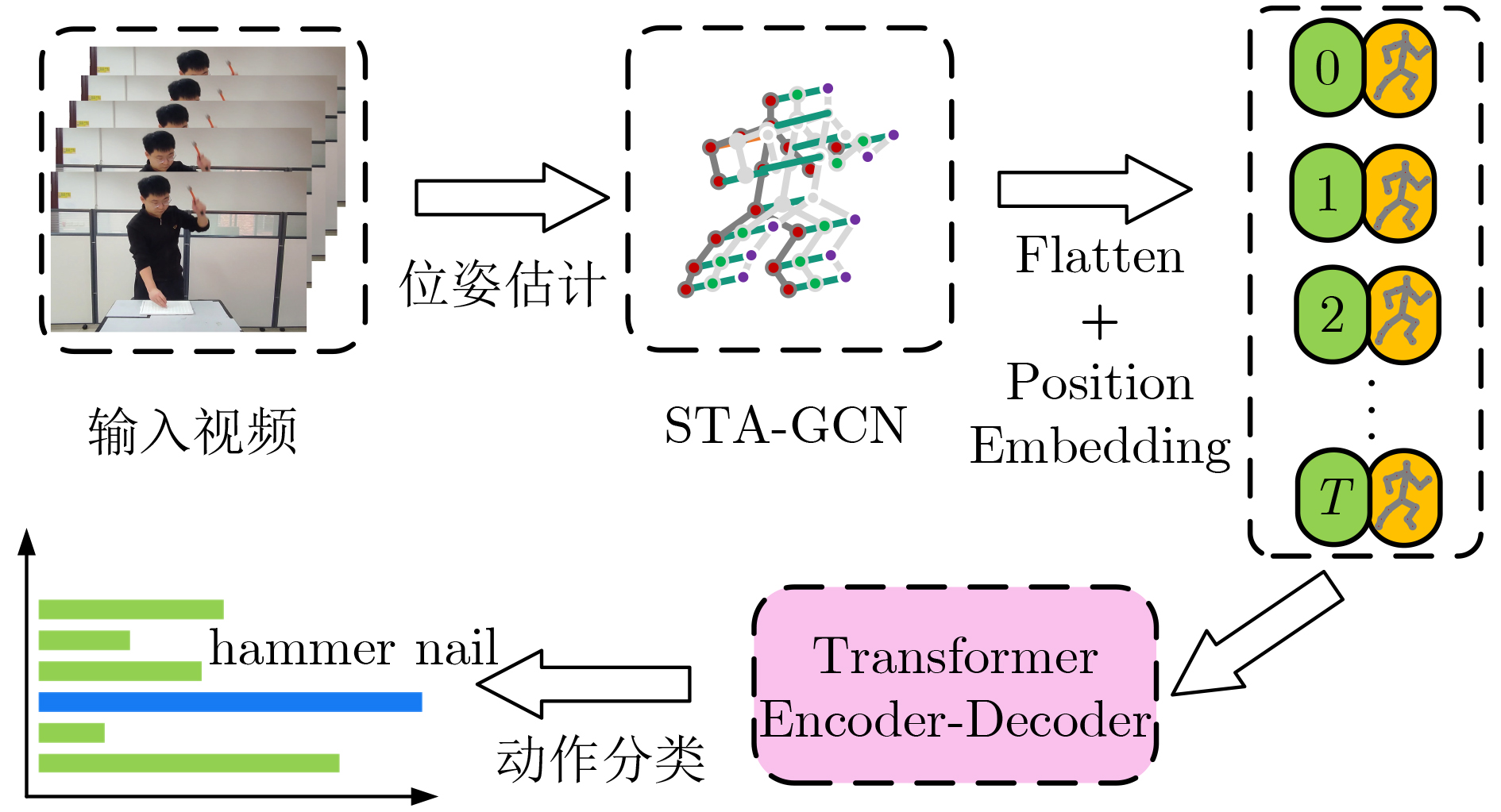
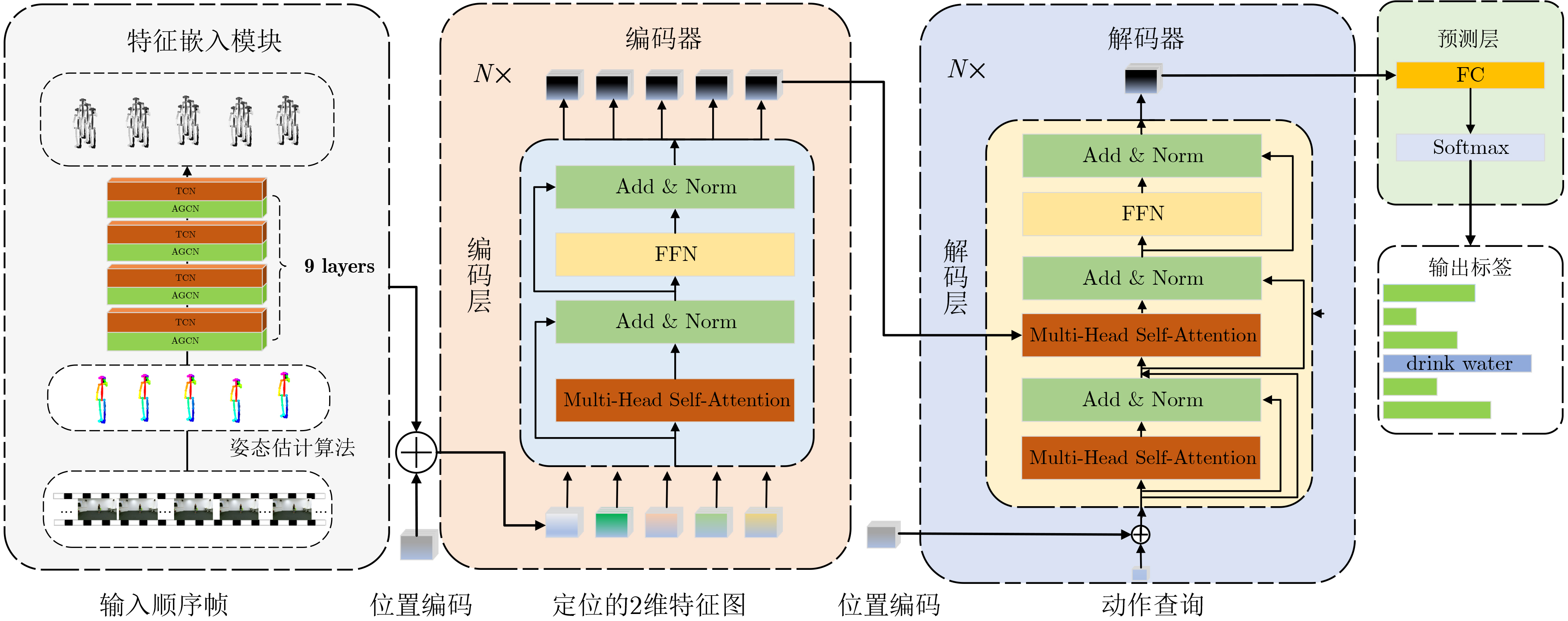
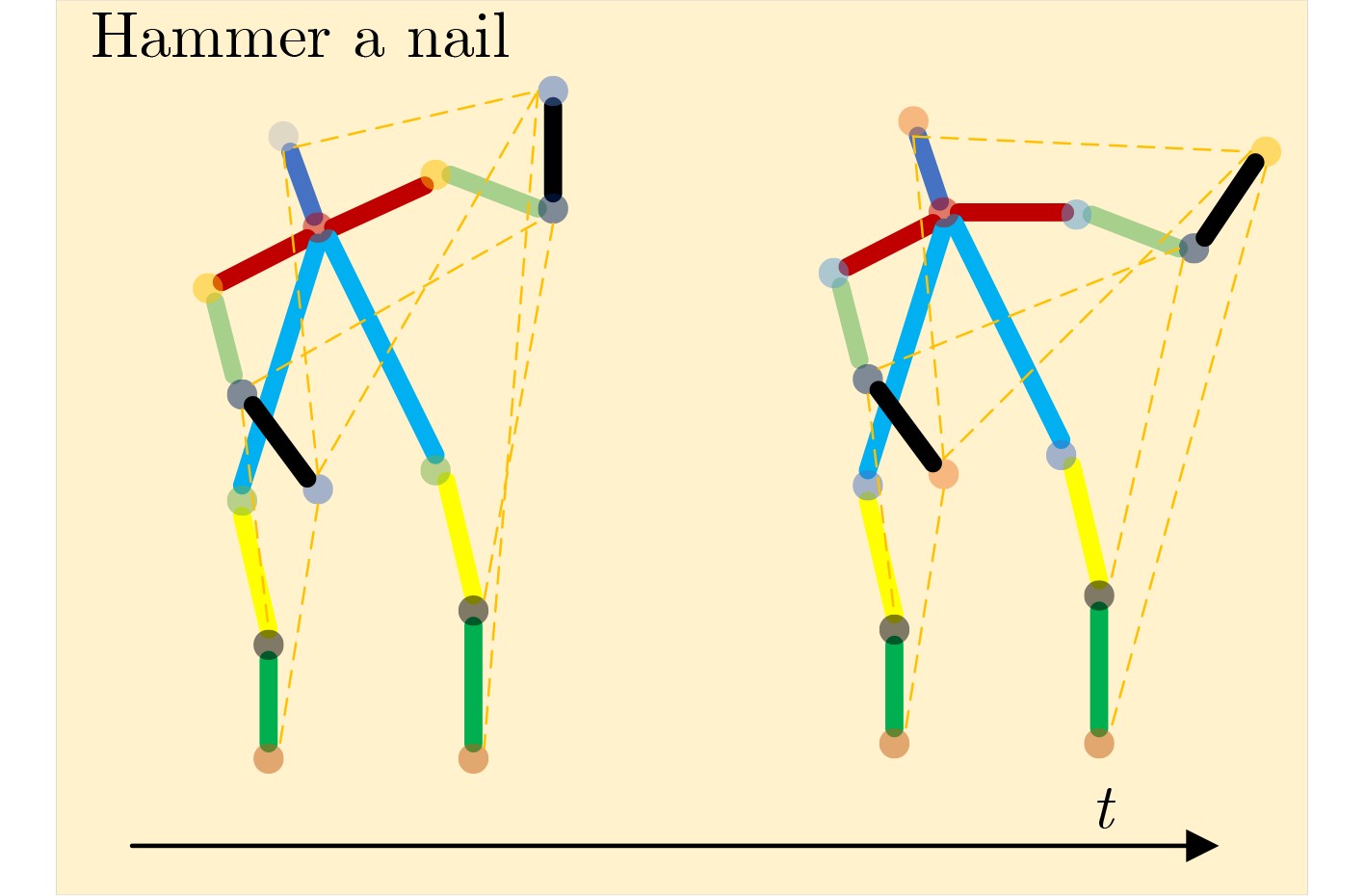
 下载:
下载:




图(8) / 表(6)
计量
- 文章访问数: 1366
- HTML全文浏览量: 1183
- PDF下载量: 112
- 被引次数: 0
