

A Research and Design of Reconfigurable CNN Co-Processor for Edge Computing
-
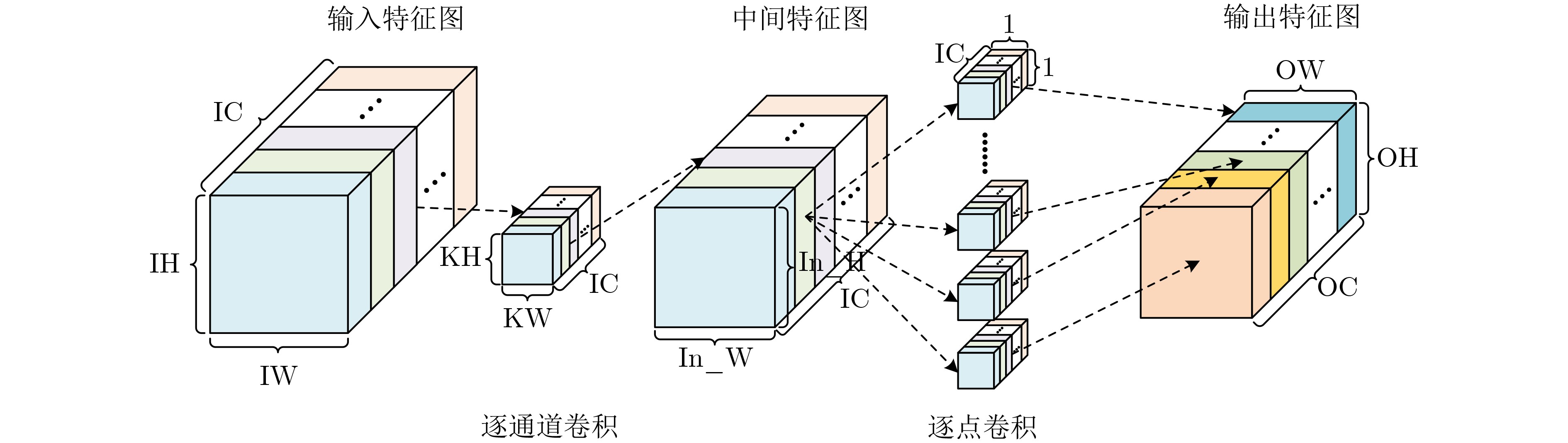
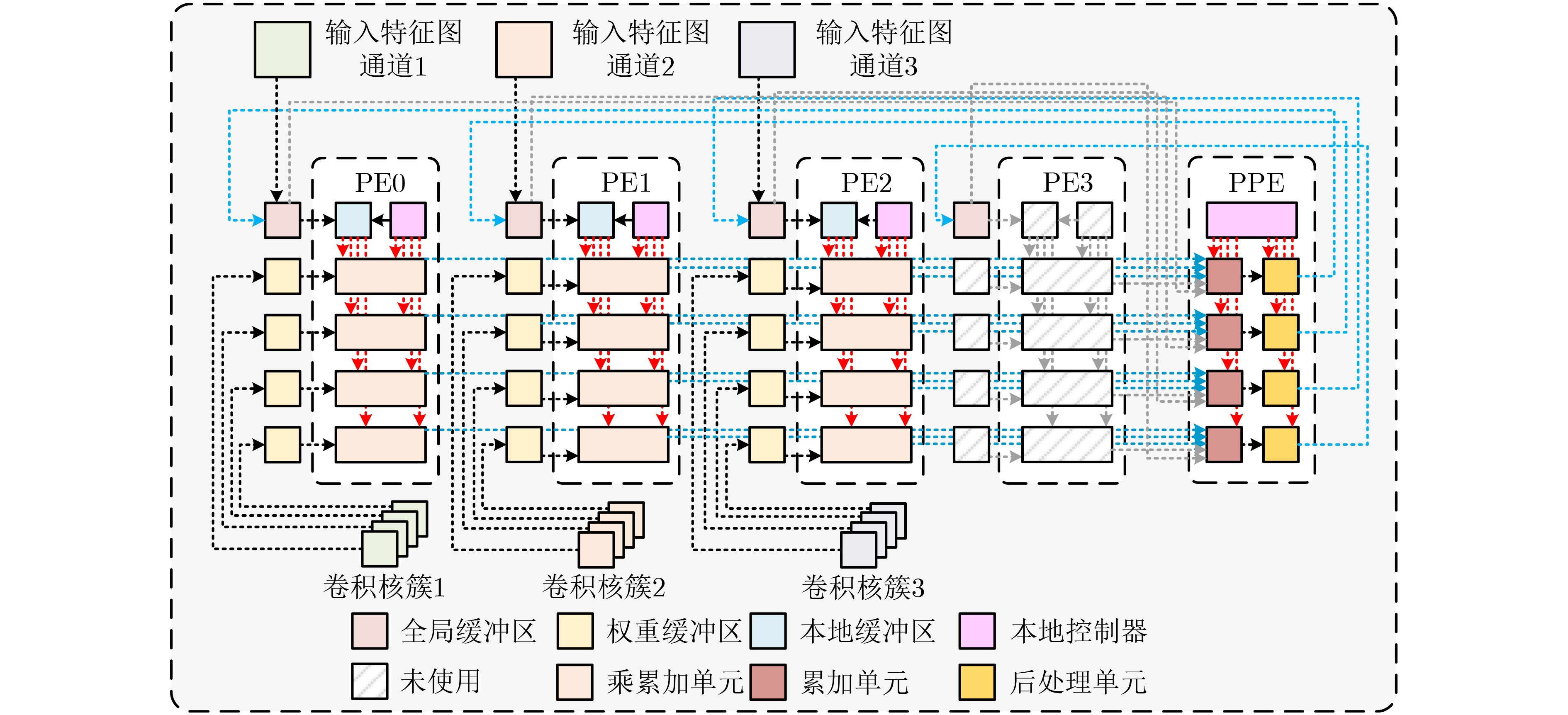
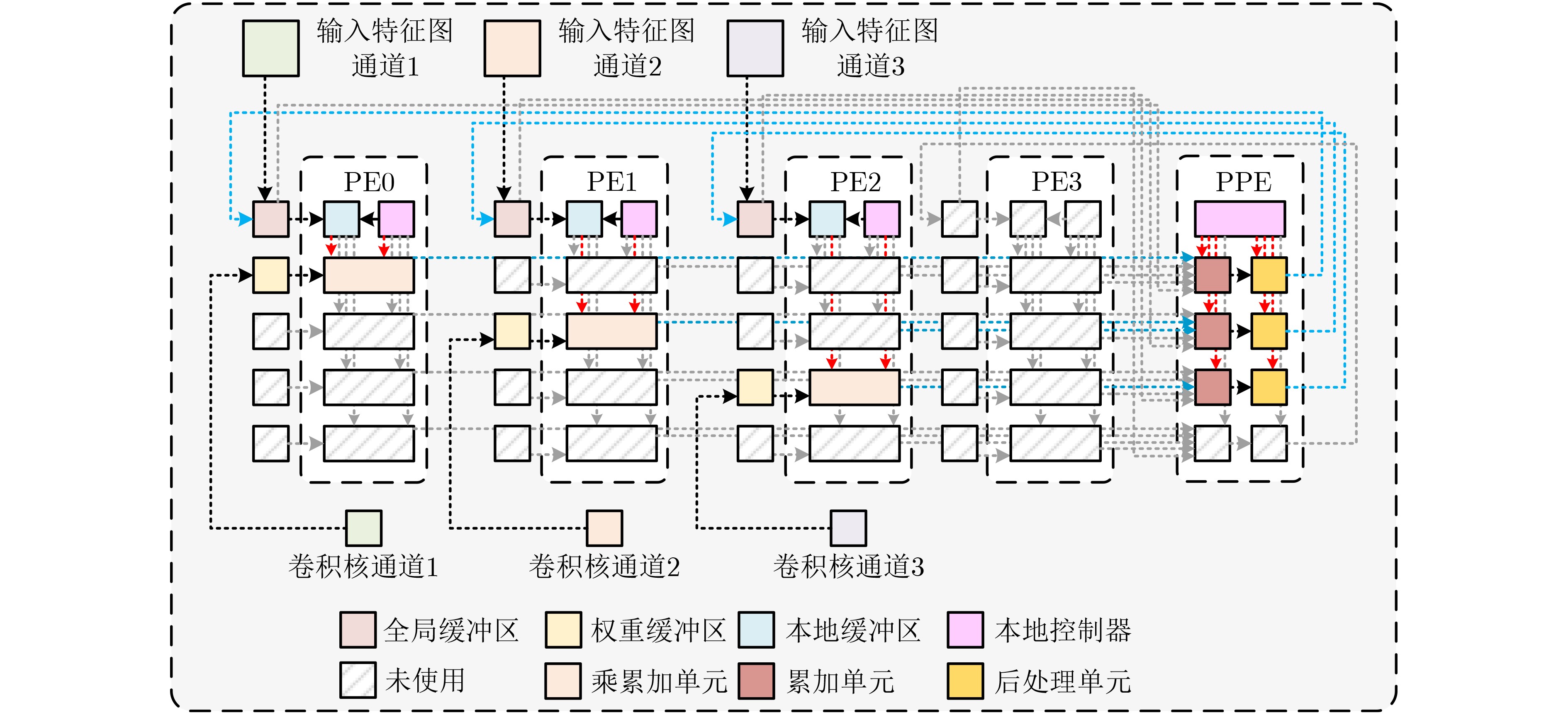
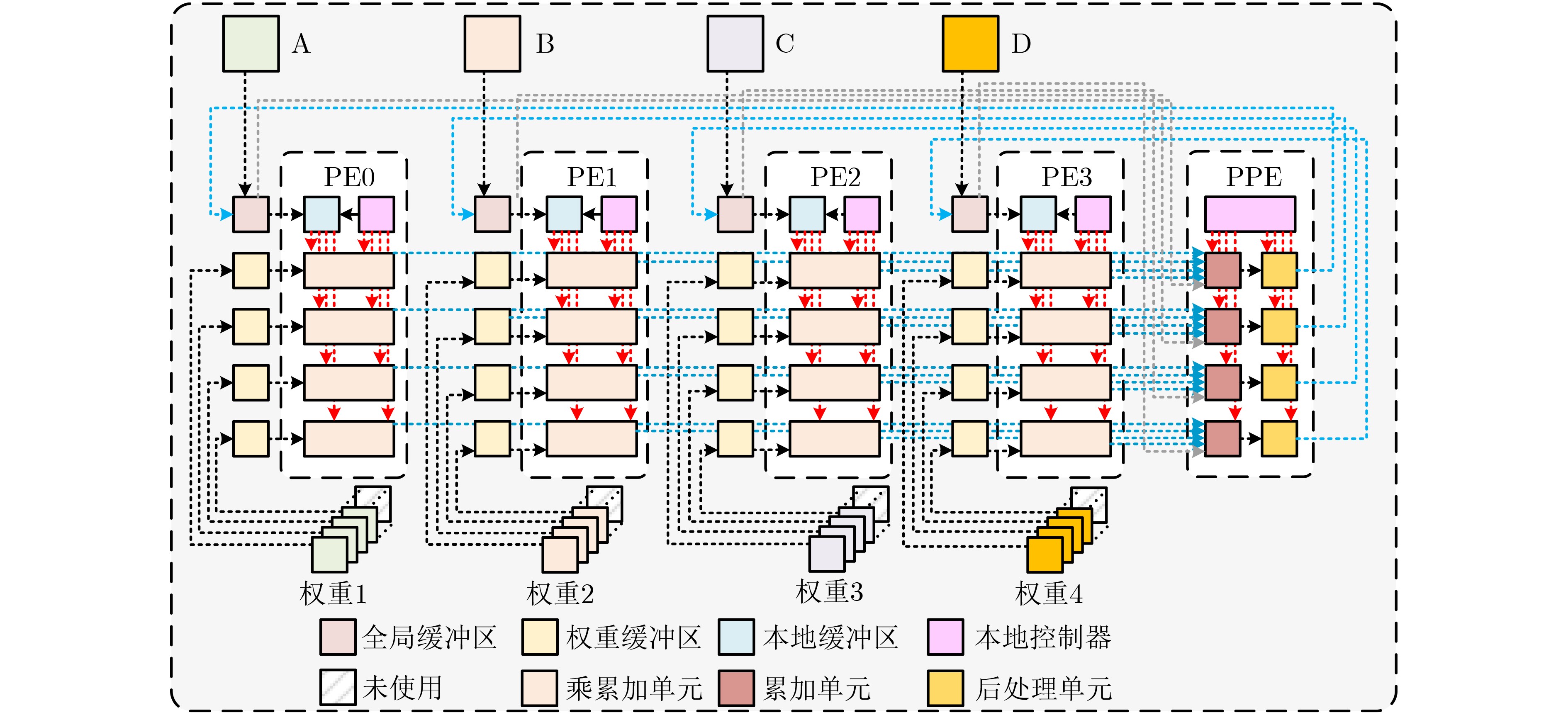
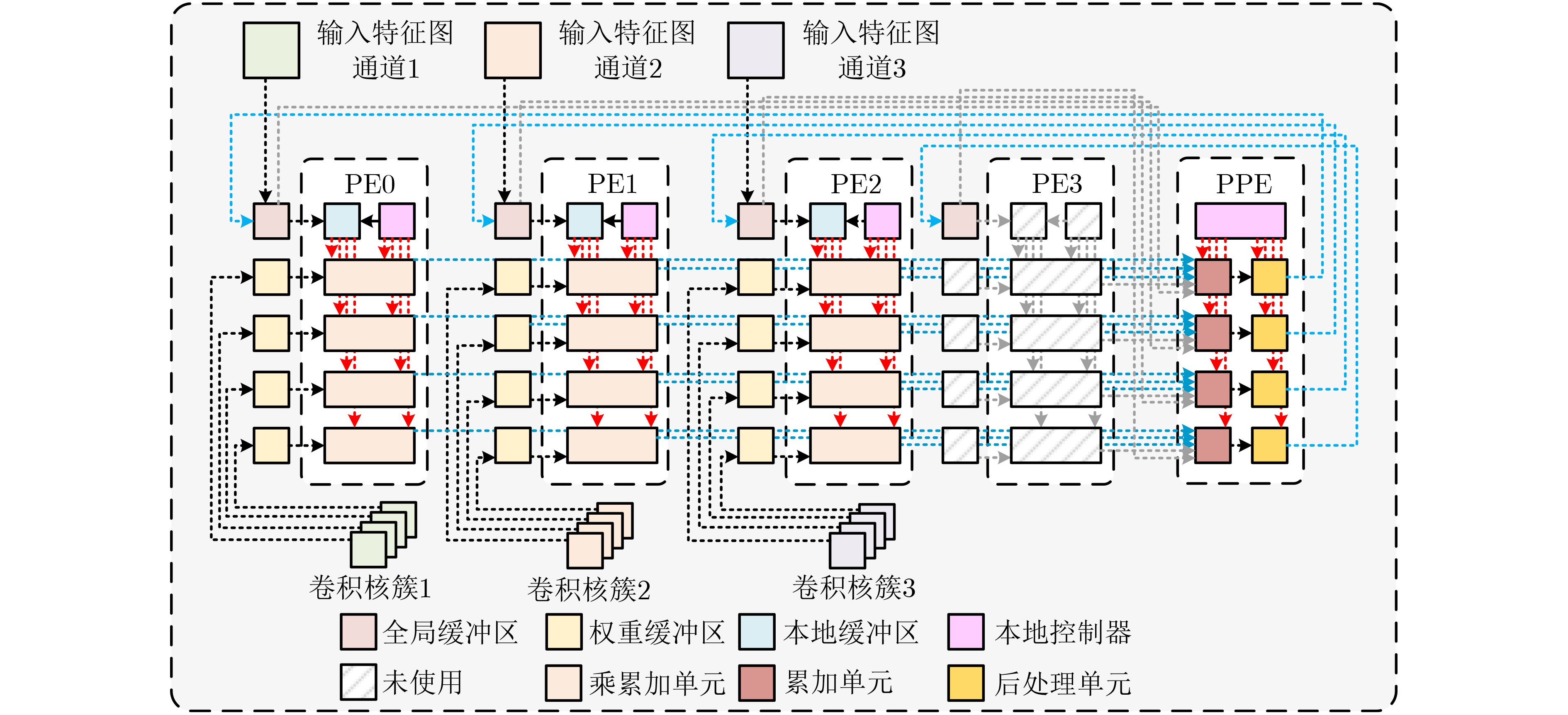
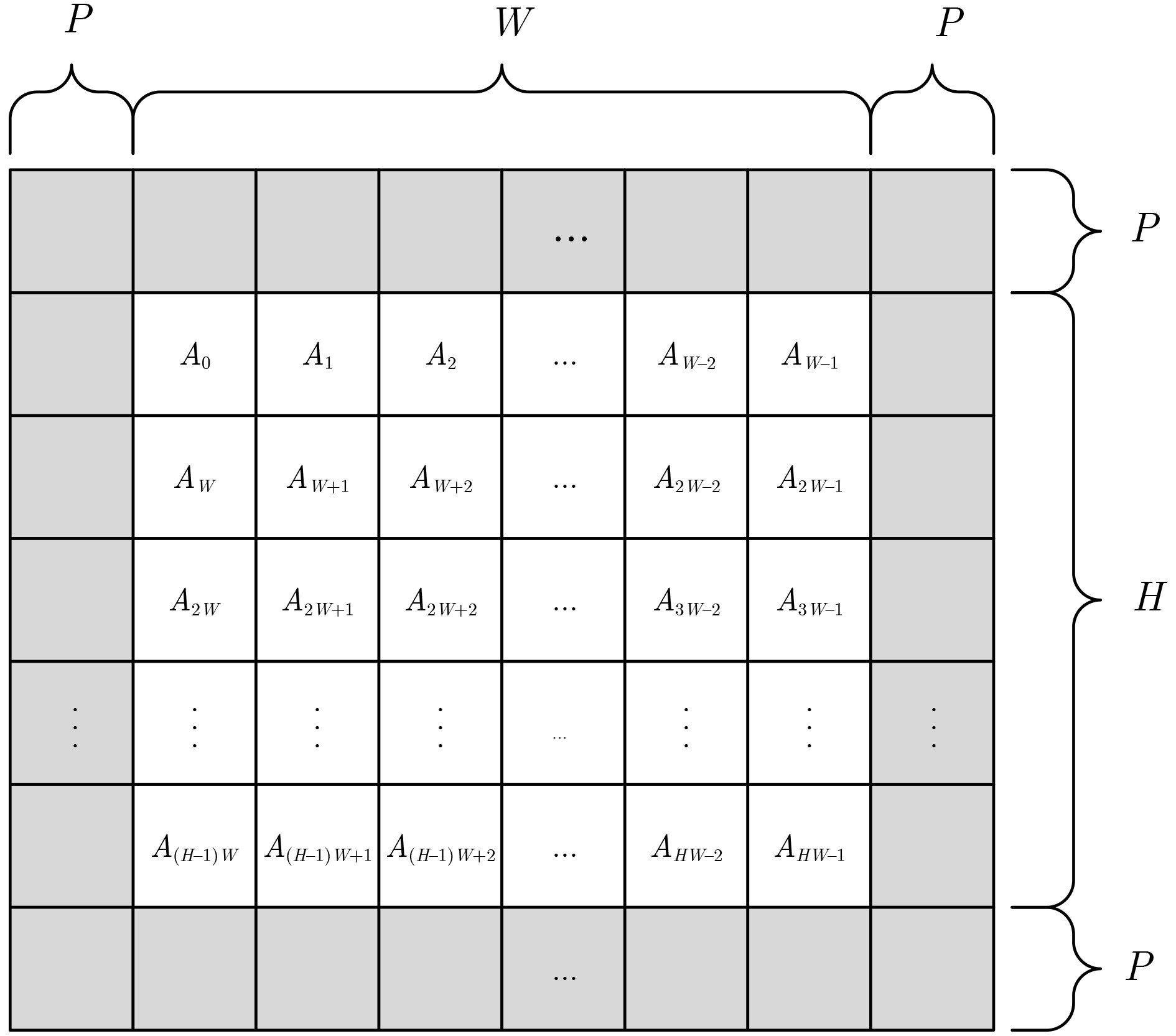
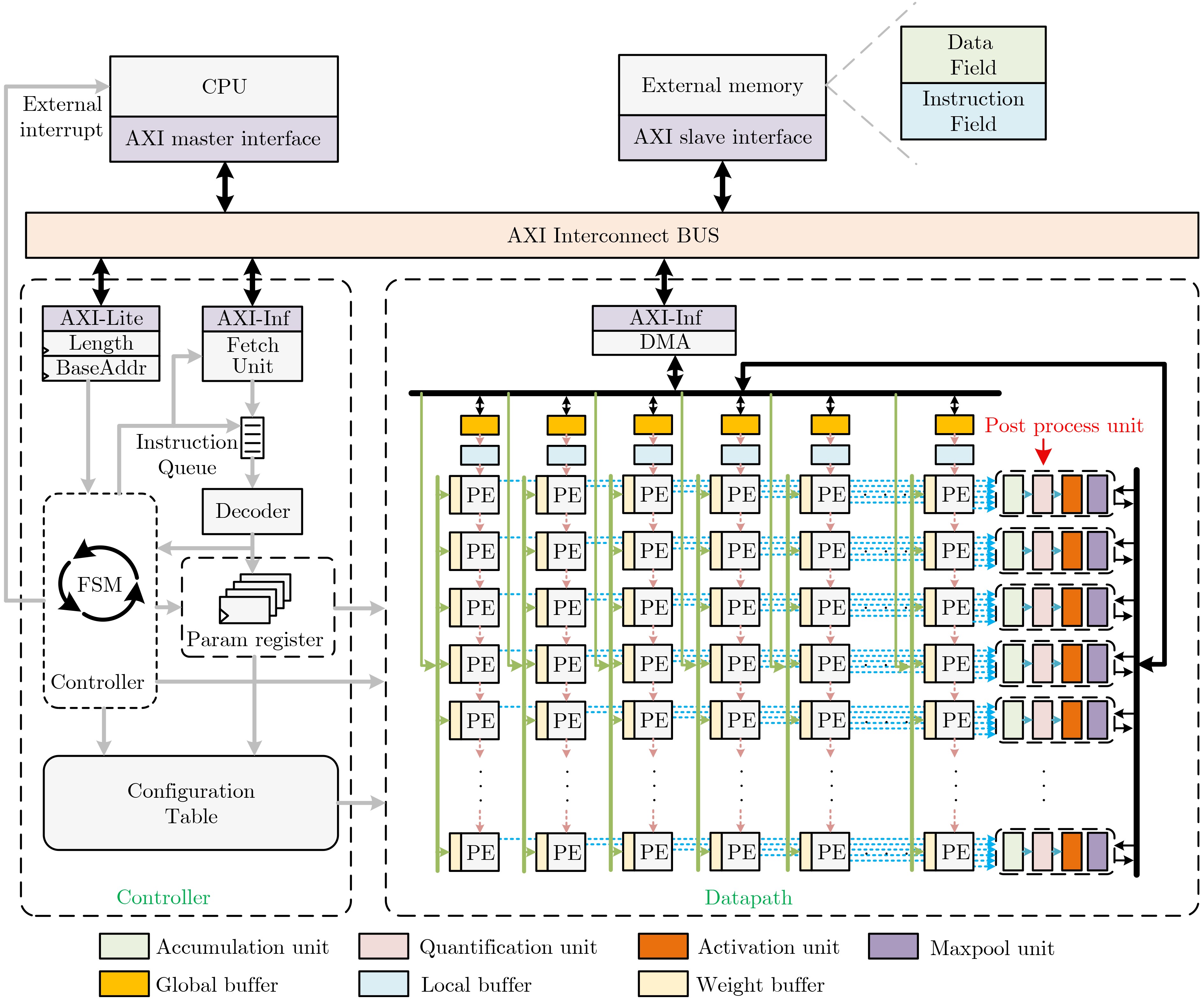
摘要: 随着深度学习技术的发展,卷积神经网络模型的参数量和计算量急剧增加,极大提高了卷积神经网络算法在边缘侧设备的部署成本。因此,为了降低卷积神经网络算法在边缘侧设备上的部署难度,减小推理时延和能耗开销,该文提出一种面向边缘计算的可重构CNN协处理器结构。基于按通道处理的数据流模式,提出的两级分布式存储方案解决了片上大规模的数据搬移和重构运算时PE单元间的大量数据移动导致的功耗开销和性能下降的问题;为了避免加速阵列中复杂的数据互联网络传播机制,降低控制的复杂度,该文提出一种灵活的本地访存机制和基于地址转换的填充机制,使得协处理器能够灵活实现任意规格的常规卷积、深度可分离卷积、池化和全连接运算,提升了硬件架构的灵活性。本文提出的协处理器包含256个PE运算单元和176 kB的片上私有存储器,在55 nm TT Corner(25 °C,1.2 V)的CMOS工艺下进行逻辑综合和布局布线,最高时钟频率能够达到328 MHz,实现面积为4.41 mm2。在320 MHz的工作频率下,该协处理器峰值运算性能为163.8 GOPs,面积效率为37.14 GOPs/mm2,完成LeNet-5和MobileNet网络的能效分别为210.7 GOPs/W和340.08 GOPs/W,能够满足边缘智能计算场景下的能效和性能需求。Abstract: With the development of Deep Learning, the number of parameters and computation of Convolutional Neural Network (CNN) increases dramatically, which greatly raises the cost of deploying CNN algorithms on edge devices. To reduce the difficulty of the deployment and decrease the inference latency and energy consumption of CNN on the edge side, a Reconfigurable CNN Co-Processor for edge computing is proposed. Based on the data flow pattern of channel-wise processing, the proposed two-level distributed storage scheme solves the problem of power consumption overhead and performance degradation caused by large data movement between PE units and large-scale migration of intermediate data on chip. To avoid the complex data interconnection network propagation mechanism in PE arrays and reduce the complexity of control, a flexible local access mechanism and a padding mechanism based on address translation are proposed, which can perform conventional convolution, deep separable convolution, pooling and fully connected operations with great flexibility. The proposed co-processor contains 256 Processing Elements (PEs) and 176 kB on-chip SRAM. Synthesized and post-layout with 55-nm TT Corner CMOS process (25 °C, 1.2 V), the CNN co-processor achieves a maximum clock frequency of 328 MHz and an area of 4.41 mm2. The peak performance of the co-processor is 163.8 GOPs at 320 MHz and the area efficiency is 37.14 GOPs/mm2, the energy efficiency of LeNet-5 and MobileNet are 210.7 GOPs/W and 340.08 GOPs/W, respectively, which is able to meet the energy-efficiency and performance requirements of edge intelligent computing scenarios.
-
Key words:
- Hardware acceleration /
- Convolutional Neural Network (CNN) /
- Reconfigurable /
- ASIC
-
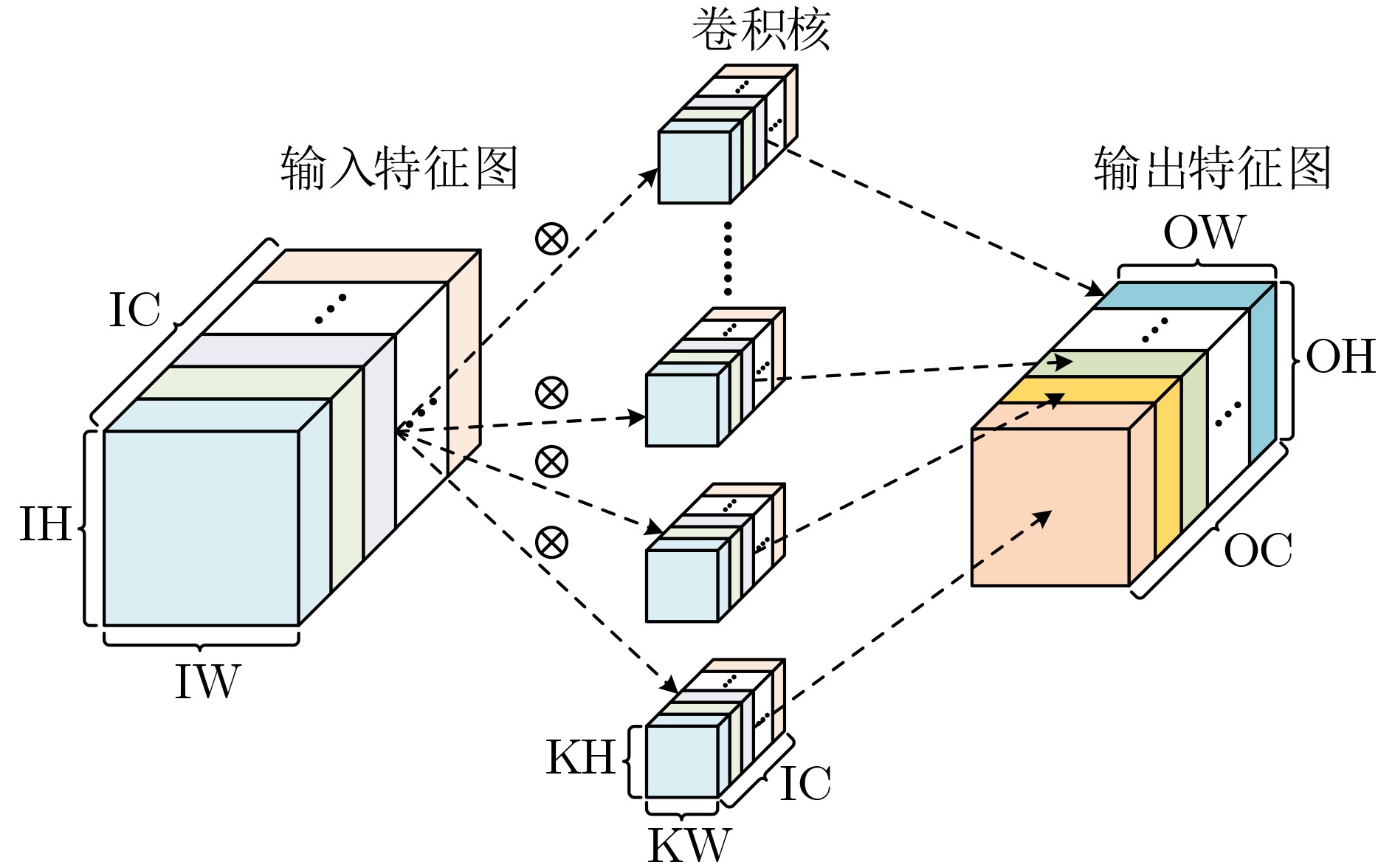
算法1 常规3D卷积 输入:IC, OC, OH, OW, KH, KW, If, K, S 输出:Of FOR no=0; no<OC; no++ { FOR ni=0; ni<IC; ni++ { FOR Or=0; Or<OH; Or++ { FOR Oc=0; Oc<OW; Oc++ { FOR i=0; i<KH; i++ { FOR j=0; j<KW; j++ { Of[no][Or][Oc] += K[no][ni][i][j]×If[ni][S×Or+i][S×Oc+j]; } } } } } }  下载: 导出CSV
下载: 导出CSV
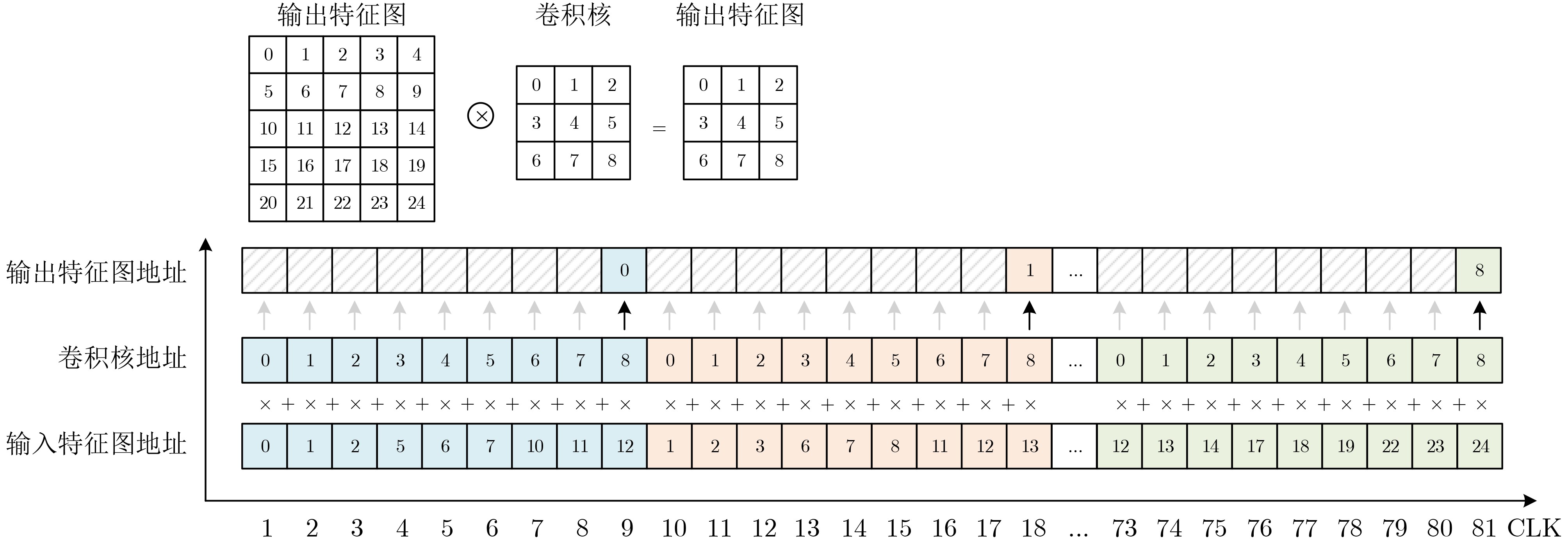
算法2 按通道处理的常规3D卷积 输入:IC, OC, OH, OW, KH, KW, If, K, S, N 输出:Of FOR no=0; no<$\left\lceil {{\mathrm{OC}}/N} \right\rceil $; no++ { FOR ni=0; ni<$\left\lceil {{\mathrm{IC}}/N} \right\rceil $; ni++ { FOR Or=0; Or<OH; Or++ { FOR Oc=0; Oc<OW; Oc++ { FOR i=0; i<KH; i++{ FOR j=0; j<KW; j++ { Of[no×N][Or][Oc] += K[no×N][ni×N][i][j]×If[ni×N][S×Or+i]
[S×Oc+j]+ K[no×N][ni×N+1][i][j]×If[ni×N+1][S×Or+i]
[S×Oc+j]+…+K[no×N][ni×N+N–1][i][j]×If[ni×N+N–1]
[S×Or+i][S×Oc+j];Of[no×N+1][Or][Oc] += K[no×N+1][ni×N][i][j]×If[ni×N][S×Or+i][S×Oc+j]+ K[no×N+1][ni×N+1][i][j]×If[ni×N+1][S×Or+i][S×Oc+j]+…+ K[no×N+1][ni×N+N–1][i][j]×If[ni×N+N–1][S×Or+i][S×Oc+j]; … Of[no×N+N–1][Or][Oc] += K[no×N+N–1][ni×N][i][j]×If[ni×N][S×Or+i][S×Oc+j] + K[no×N+N–1][ni×N+1][i][j]×If[ni×N+1][S×Or+i]
[S×Oc+j]+…+K[no×N+N–1][ni×N+N–1][i][j]×If[ni×N+N–1][S×Or+i][S×Oc+j]; } } } } } } }
下载: 导出CSV
表 1 不同硬件加速平台的能效对比
CPU GPU 本文 工艺(nm) 12 12 55 精度 INT8 INT8 INT8 测试模型 LeNet-5 MobileNet LeNet-5 MobileNet LeNet-5 MobileNet 功耗(W) 3.4 6.3 3.9 25.1 0.138 0.279 能效(GOPs/W) 2.21 8.97 2.75 19.85 210.7 340.0 识别率(Images/s) 8771 602 12345 5617 41851 1272
下载: 导出CSV
表 2 不同CNN加速器性能对比
JSSC 2017
DISP[17]TOCC 2020
ZASCAD[18]AICAS
2020[20]TCAS-I 2021
CARLA[19]TCAS-I 2021
IECA[21]本文方案 工艺制程(nm) 65 65 40 65 55 55 测量方案 Chip Post-Layout Post-Layout Post-Layout Chip Post-Layout On-Chip SRAM (KB) 139.6 36.9 44.3 85.5 109.0 176.0 电压(V) 1.2 – – – 1.0 1.2 PE单元数量 64 192 144 192 168 256 工作时钟频率(MHz) 250 200 750 200 250 320 峰值性能(GOPs) 32 76.8 216 77.4 84.0 163.8 面积(mm2) 12.25 6 8.04 6.2 2.75 4.41 (1)面积效率(GOPs/mm2) 6.48 15.12 19.53 14.75 30.55 37.14 (1) 工艺比例: process/55nm
下载: 导出CSV
表 3 不同CNN加速器能效对比
JSSC 2017
Eyeriss[10]JETCAS 2019
Eyeriss V2[22]AICAS
2021[23]TCAS-I 2021
CARLA[19]本文方案 工艺(nm) 65 65 65 65 55 测量方案 Chip Post-Layout Post-Layout Post-Layout Post-Layout On-Chip SRAM (KB) 181.5 246 216 85.5 176 量化精度(bit) 16 8 8 16 8 电压(V) 1.0 – 1.2 – 1.2 工作时钟频率 200 200 – 200 320 测试模型 AlexNet MobileNet MobileNet VGG-16 MobileNet 功耗(mW) 278 – – 247 279.6 能效(GOPs/W) 166.2 193.7 45.8 313.4 340.0
下载: 导出CSV
-
[1] FIROUZI F, FARAHANI B, and MARINŠEK A. The convergence and interplay of edge, fog, and cloud in the AI-driven Internet of Things (IoT)[J]. Information Systems, 2022, 107: 101840. doi: 10.1016/j.is.2021.101840. [2] ALAM F, ALMAGHTHAWI A, KATIB I, et al. IResponse: An AI and IoT-enabled framework for autonomous COVID-19 pandemic management[J]. Sustainability, 2021, 13(7): 3797. doi: 10.3390/su13073797. [3] CHAUDHARY V, KAUSHIK A, FURUKAWA H, et al. Review-Towards 5th generation AI and IoT driven sustainable intelligent sensors based on 2D MXenes and borophene[J]. ECS Sensors Plus, 2022, 1(1): 013601. doi: 10.1149/2754-2726/ac5ac6. [4] KRIZHEVSKY A, SUTSKEVER I, and HINTON G E. Imagenet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84–90. doi: 10.1145/3065386. [5] LU Wenyan, YAN Guihai, LI Jiajun, et al. FlexFlow: A flexible dataflow accelerator architecture for convolutional neural networks[C]. 2017 IEEE International Symposium on High Performance Computer Architecture (HPCA), Austin, USA, 2017: 553–564. doi: 10.1109/HPCA.2017.29. [6] PARK J S, PARK C, KWON S, et al. A multi-mode 8k-MAC HW-utilization-aware neural processing unit with a unified multi-precision Datapath in 4-nm flagship mobile SoC[J]. IEEE Journal of Solid-State Circuits, 2023, 58(1): 189–202. doi: 10.1109/JSSC.2022.3205713. [7] GOKHALE V, JIN J, DUNDAR A, et al. A 240 G-ops/s mobile coprocessor for deep neural networks[C]. IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, USA, 2014: 682–687. doi: 10.1109/CVPRW.2014.106. [8] DU Zidong, FASTHUBER R, CHEN Tianshi, et al. ShiDianNao: Shifting vision processing closer to the sensor[C]. 2015 ACM/IEEE 42nd Annual International Symposium on Computer Architecture (ISCA), Portland, USA, 2015: 92–104. doi: 10.1145/2749469.2750389. [9] ZHANG Chen, LI Peng, SUN Guangyu, et al. Optimizing FPGA-based accelerator design for deep convolutional neural networks[C]. The 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, USA, 2015: 161–170. doi: 10.1145/2684746.2689060. [10] CHEN Y H, KRISHNA T, EMER J S, et al. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks[J]. IEEE Journal of Solid-State Circuits, 2017, 52(1): 127–138. doi: 10.1109/JSSC.2016.2616357. [11] HOWARD A G, ZHU Menglong, CHEN Bo, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications[EB/OL]. https://arxiv.org/abs/1704.04861, 2017. [12] DING Caiwen, WANG Shuo, LIU Ning, et al. REQ-YOLO: A resource-aware, efficient quantization framework for object detection on FPGAs[C]. The 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, USA, 2019: 33–42. doi: 10.1145/3289602.3293904. [13] LE M Q, NGUYEN Q T, DAO V H, et al. CNN quantization for anatomical landmarks classification from upper gastrointestinal endoscopic images on Edge devices[C]. 2022 IEEE Ninth International Conference on Communications and Electronics (ICCE), Nha Trang, Vietnam, 2022: 389–394. doi: 10.1109/ICCE55644.2022.9852098. [14] KWAK J, KIM K, LEE S S, et al. Quantization aware training with order strategy for CNN[C]. 2022 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Yeosu, Republic of Korea, 2022: 1–3. doi: 10.1109/ICCE-Asia57006.2022.9954693. [15] JACOB B, KLIGYS S, CHEN Bo, et al. Quantization and training of neural networks for efficient integer-arithmetic-only inference[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 2704–2713. doi: 10.1109/CVPR.2018.00286. [16] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278–2324. doi: 10.1109/5.726791. [17] JO J, CHA S, RHO D, et al. DSIP: A scalable inference accelerator for convolutional neural networks[J]. IEEE Journal of Solid-State Circuits, 2018, 53(2): 605–618. doi: 10.1109/JSSC.2017.2764045. [18] ARDAKANI A, CONDO C, and GROSS W J. Fast and efficient convolutional accelerator for edge computing[J]. IEEE Transactions on Computers, 2020, 69(1): 138–152. doi: 10.1109/TC.2019.2941875. [19] AHMADI M, VAKILI S, and LANGLOIS J M P. CARLA: A convolution accelerator with a reconfigurable and low-energy architecture[J]. IEEE Transactions on Circuits and Systems I:Regular Papers, 2021, 68(8): 3184–3196. doi: 10.1109/TCSI.2021.3066967. [20] LU Yi, WU Yilin and HUANG J D. A coarse-grained dual-convolver based CNN accelerator with high computing resource utilization[C]. 2020 2nd IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), Genova, Italy, 2020: 198–202. doi: 10.1109/AICAS48895.2020.9073835. [21] HUANG Boming, HUAN Yuxiang, CHU Haoming, et al. IECA: An in-execution configuration CNN accelerator with 30.55 GOPS/mm² area efficiency[J]. IEEE Transactions on Circuits and Systems I:Regular Papers, 2021, 68(11): 4672–4685. doi: 10.1109/TCSI.2021.3108762. [22] CHEN Y H, YANG T J, EMER J, et al. Eyeriss v2: A flexible accelerator for emerging deep neural networks on mobile devices[J]. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 2019, 9(2): 292–308. doi: 10.1109/JETCAS.2019.2910232. [23] HOSSAIN M D S and SAVIDIS I. Energy efficient computing with heterogeneous DNN accelerators[C]. 2021 IEEE 3rd International Conference on Artificial Intelligence Circuits and Systems (AICAS), Washington, USA, 2021: 1–4. doi: 10.1109/AICAS51828.2021.9458474. -

 下载:
下载:




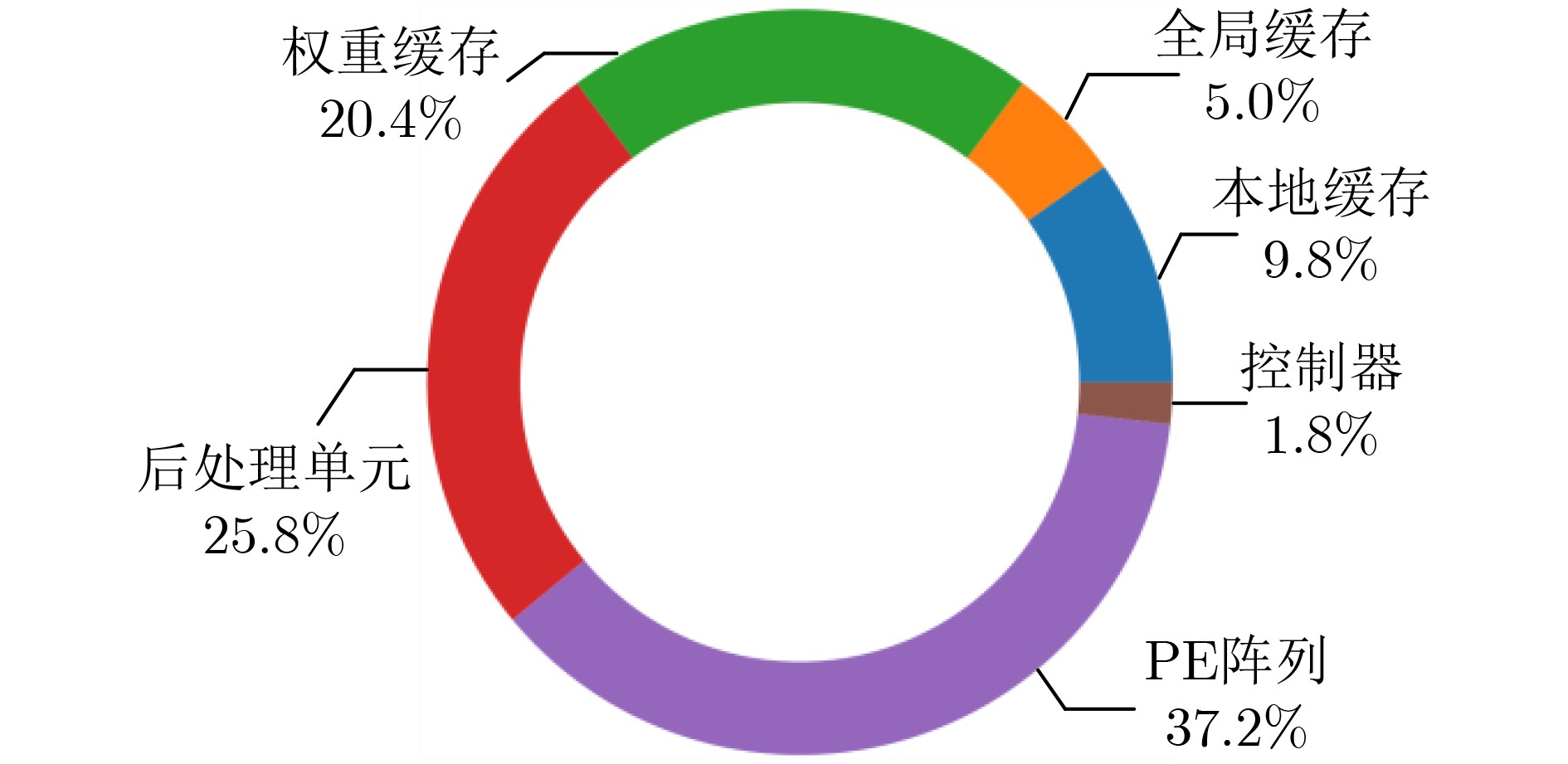
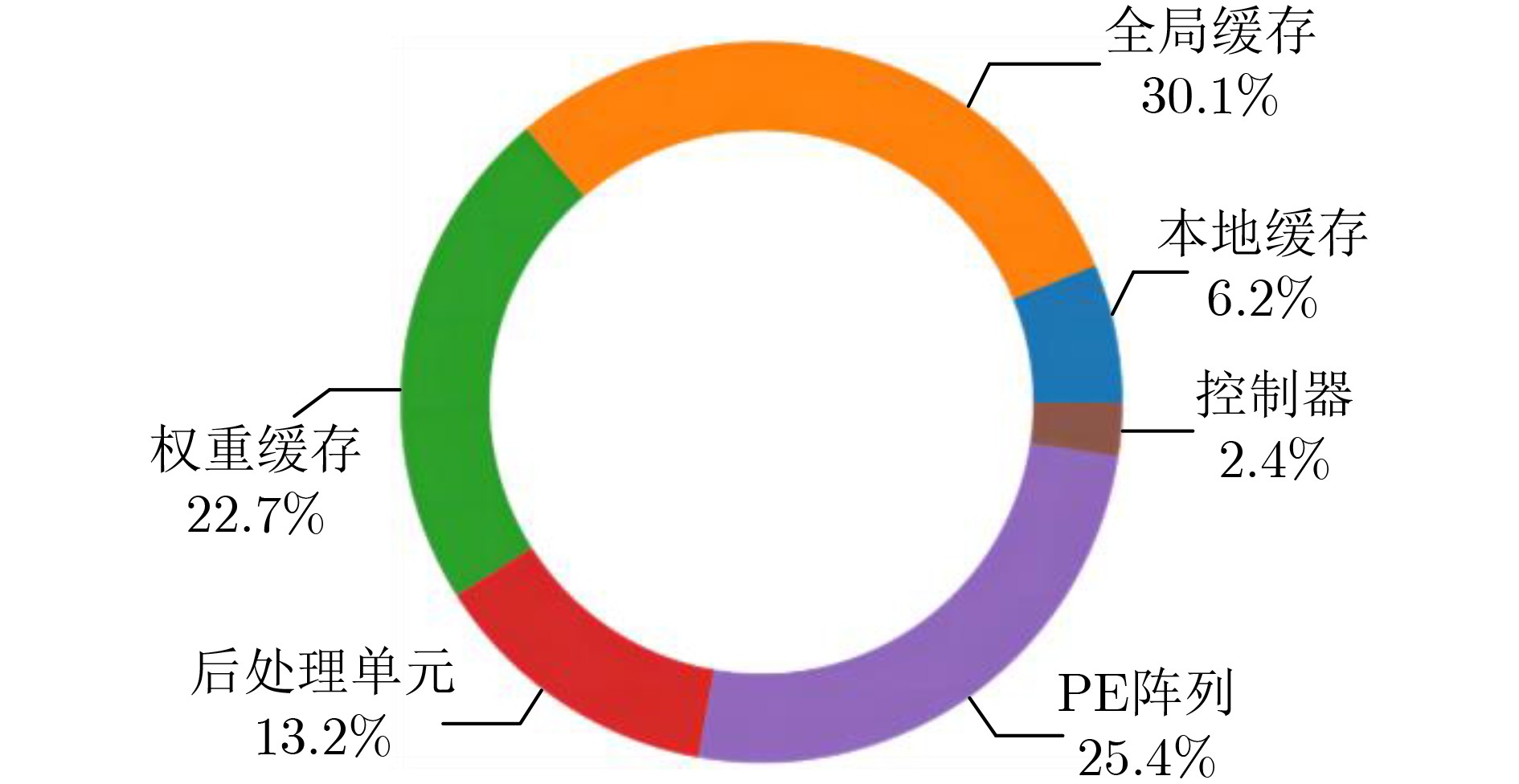


图(18) / 表(5)
计量
- 文章访问数: 1059
- HTML全文浏览量: 1288
- PDF下载量: 106
- 被引次数: 0
