

Joint Optimization of Edge Selection and Resource Allocation in Digital Twin-assisted Federated Learning
-
摘要: 在基于联邦学习的智能驾驶中,智能网联汽车(ICV)的资源限制和可能出现的设备故障会导致联邦学习训练精度下降、时延和能耗增加等问题。为此该文提出数字孪生辅助联邦学习中的边缘选择和资源分配优化方案。该方案首先提出数字孪生辅助联邦学习机制,使得ICV能够选择在本地或利用其数字孪生体参与联邦学习。其次,通过构建数字孪生辅助联邦学习的计算和通信模型,建立以最小化累积训练时延和能耗为目标的边缘选择和资源分配联合优化问题,并将其转化为部分可观测的马尔可夫决策过程。最后,提出基于多智能体参数化Q网络(MPDQN)的边缘选择和资源分配算法,用于学习近似最优的边缘选择和资源分配策略,以实现联邦学习累积时延和能耗最小化。仿真结果表明,所提算法在保证模型精度的同时,有效降低联邦学习累积训练时延和能耗。Abstract: In intelligent driving based on federated learning, the resource constraints of Intelligent Connected Vehicle (ICV) and possible device failures will lead to the decrease of the precision of federated learning training and the increase of delay and energy consumption. Therefore, an optimization scheme of edge selection and resource allocation in digital twin-assisted federated learning is proposed. Firstly, a digital twin-assisted federated learning mechanism is proposed, allowing ICV to choose to participate in federated learning locally or through its digital twin. Secondly, by constructing a computational and communication model for digital twin-assisted federated learning, an edge selection and computing resource allocation joint optimization problem is established with the objective of minimizing cumulative training delay and energy consumption, and is transformed into a partially observable Markov decision process. Finally, an edge selection and resource allocation algorithm based on Multi-agent Parametrized Deep Q-Networks (MPDQN) is proposed to learn approximately optimal edge selection and resource allocation strategies to minimize federated learning cumulative delay and energy consumption. Simulation results show that the proposed algorithm can effectively reduce cumulative training delay and energy consumption of federated learning training while ensuring model accuracy.
-
Key words:
- Intelligent driving /
- Federated learning /
- Digital twin /
- Deep reinforcement learning
-
算法1 基于MPDQN的边缘选择和资源分配算法 输入:学习率$ ({\lambda _{\text{d}}},{\lambda _{\text{c}}}) $,学习回合数$ {N_{{\text{max}}}} $,概率分布$ \psi $,探索概率$\varepsilon $,小批量大小$B$,采样数据的学习回合数量${N_{{\text{sam}}}}$ 输出:边缘选择和资源分配策略 (1) 初始化网络参数$ ({\theta _{\text{d}}},{\theta _{\text{c}}}) $和经验回放池 (2) for $i = 1,2,\cdots,{N_{{\text{max}}}}$ do (3) 收到初始状态${{\boldsymbol{s}}_1} = {\{ {{\boldsymbol{s}}_{m,1} }\} _{\forall m \in \mathcal{M} } }$ (4) for 数字孪生辅助联邦学习全局迭代$ k\in \mathcal{K} $ do (5) for 智能体$ m \in \mathcal{M} $ do (6) 根据式(22)计算连续动作参数${{\boldsymbol{f}}_m}(k)$ 根据$\varepsilon $贪婪策略选择动作${{\boldsymbol{a}}_{m,k} } = \{ {{\boldsymbol{\varphi}} _m}(k),{ {\boldsymbol{f} }_m}(k)\}$: (7) ${{\boldsymbol{a}}}_{m,k}=\left\{\begin{aligned}& 分布\psi 的样本,\varepsilon \\ & ({{\boldsymbol{\varphi}} }_{m}(k),{\boldsymbol f}_{m}(k)), {\varphi }_{m}(k)=\text{arg}\underset{{\boldsymbol{\varphi}} }{\text{max} }Q({{\boldsymbol{s}}}_{m,k},{{\boldsymbol{\varphi}} }_{m}(k),{\boldsymbol f}_{m}^{*}(k)),1-\varepsilon \end{aligned} \right.$ (9) 执行动作${{\boldsymbol{a}}_{m,k}}$,获得瞬时奖励${{\boldsymbol{r}}_{m,k}}$和下一个状态$ {{\boldsymbol{s}}_{m,k + 1}} $ (10) 将元组$ [{{\boldsymbol{s}}_{m,k}},{{\boldsymbol{a}}_{m,k}},{{\boldsymbol{r}}_{m,k}},{{\boldsymbol{s}}_{m,k + 1}}] $存入经验回放池${\mathcal{D}_m}$ (11) 经验回放池${\mathcal{D}_m}$中采样一组小批量$B$的数据样本 (12) 根据式(19)更新TQN的目标函数$ {y_m}(k) $ (13) 根据式(20)和式(21)分别计算损失函数$ L({\varpi _{m,{\text{d}}}}) $和$ L({\varpi _{m,{\text{c}}}}) $ (15) 根据式(22)和式(23)更新网络参数$ {\varpi _{m,{\text{d}}}}(k + 1) $和$ {\varpi _{m,{\text{c}}}}(k + 1) $ (17) if $(i > {N_{{\text{sam}}}})$ then (18) 从经验回放池$\mathcal{D}$中采样一组小批量$B$的数据样本 (19) 更新参数${\varpi _{ {\text{d,me} } } }(k + 1) \leftarrow {\lambda '_{ {\text{me} } } }{\nabla _{ {\varpi _{ {\text{d,me} } } } } }l{\text{(} }\varpi {\text{)} }$和${\varpi _{ {\text{c,me} } } }(k + 1) \leftarrow {\lambda '_{ {\text{me} } } }\nabla l{\text{(} }{\varpi _{\text{c} } }{\text{)} }$ (21) 融合网络下发最新的参数至各个智能体 (22) end if (23) end for (24) end for (25) end for  下载: 导出CSV
下载: 导出CSV
-
[1] BOUKERCHE A and DE GRANDE R E. Vehicular cloud computing: Architectures, applications, and mobility[J]. Computer Networks, 2018, 135: 171–189. doi: 10.1016/j.comnet.2018.01.004. [2] ARENA F and PAU G. An overview of vehicular communications[J]. Future Internet, 2019, 11(2): 27. doi: 10.3390/fi11020027. [3] BENNIS M. Federated learning and control at the wireless network edge[J]. GetMobile:Mobile Computing and Communications, 2021, 24(3): 9–13. doi: 10.1145/3447853.3447857. [4] CHEN Mingzhe, POOR H V, SAAD W, et al. Convergence time minimization of federated learning over wireless networks[C]. ICC 2020–2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 2020: 1–6. [5] WU Yiwen, ZHANG Ke, and ZHANG Yan. Digital twin networks: a survey[J]. IEEE Internet of Things Journal, 2021, 8(18): 13789–13804. doi: 10.1109/JIOT.2021.3079510. [6] GRIEVES M and VICKERS J. Digital twin: Mitigating unpredictable, undesirable emergent behavior in complex systems[M]. KAHLEN F J, FLUMERFELT S, and ALVES A. Transdisciplinary Perspectives on Complex Systems: New Findings and Approaches. Cham, Germany: Springer, 2017: 85–113. [7] DAI Yueyue, GUAN Yongliang, LEUNG K K, et al. Reconfigurable intelligent surface for low-latency edge computing in 6G[J]. IEEE Wireless Communications, 2021, 28(6): 72–79. doi: 10.1109/MWC.001.2100229. [8] SUN Wen, LEI Shiyu, WANG Lu, et al. Adaptive federated learning and digital twin for industrial internet of things[J]. IEEE Transactions on Industrial Informatics, 2021, 17(8): 5605–5614. doi: 10.1109/TII.2020.3034674. [9] HUI Yilong, ZHAO Gaosheng, LI Chengle, et al. Digital twins enabled on-demand matching for multi-task federated learning in HetVNets[J]. IEEE Transactions on Vehicular Technology, 2023, 72(2): 2352–2364. doi: 10.1109/TVT.2022.3211005. [10] LU Yunlong, MAHARJAN S, and ZHANG Yan. Adaptive edge association for wireless digital twin networks in 6G[J]. IEEE Internet of Things Journal, 2021, 8(22): 16219–16230. doi: 10.1109/JIOT.2021.3098508. [11] XIONG Jiechao, WANG Qing, YANG Zhuoran, et al. Parametrized deep Q-networks learning: Reinforcement learning with discrete-continuous hybrid action space[J]. arXiv: 1810.06394, 2018. [12] YIN Sixing and YU F R. Resource allocation and trajectory design in UAV-aided cellular networks based on multiagent reinforcement learning[J]. IEEE Internet of Things Journal, 2022, 9(4): 2933–2943. doi: 10.1109/JIOT.2021.3094651. [13] XIAO Han, RASUL K, and VOLLGRAF R. Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms[J]. arXiv: 1708.07747, 2017. [14] YU Xiangbin, XU Weiye, LEUNG S H, et al. Power allocation for energy efficient optimization of distributed MIMO system with beamforming[J]. IEEE Transactions on Vehicular Technology, 2019, 68(9): 8966–8981. doi: 10.1109/TVT.2019.2931291. [15] ZHANG Jiaxiang, LIU Yiming, QIN Xiaoqi, et al. Energy-efficient federated learning framework for digital twin-enabled industrial internet of things[C]. The IEEE 32nd Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Helsinki, Finland, 2021: 1160–1166. -


 下载:
下载:

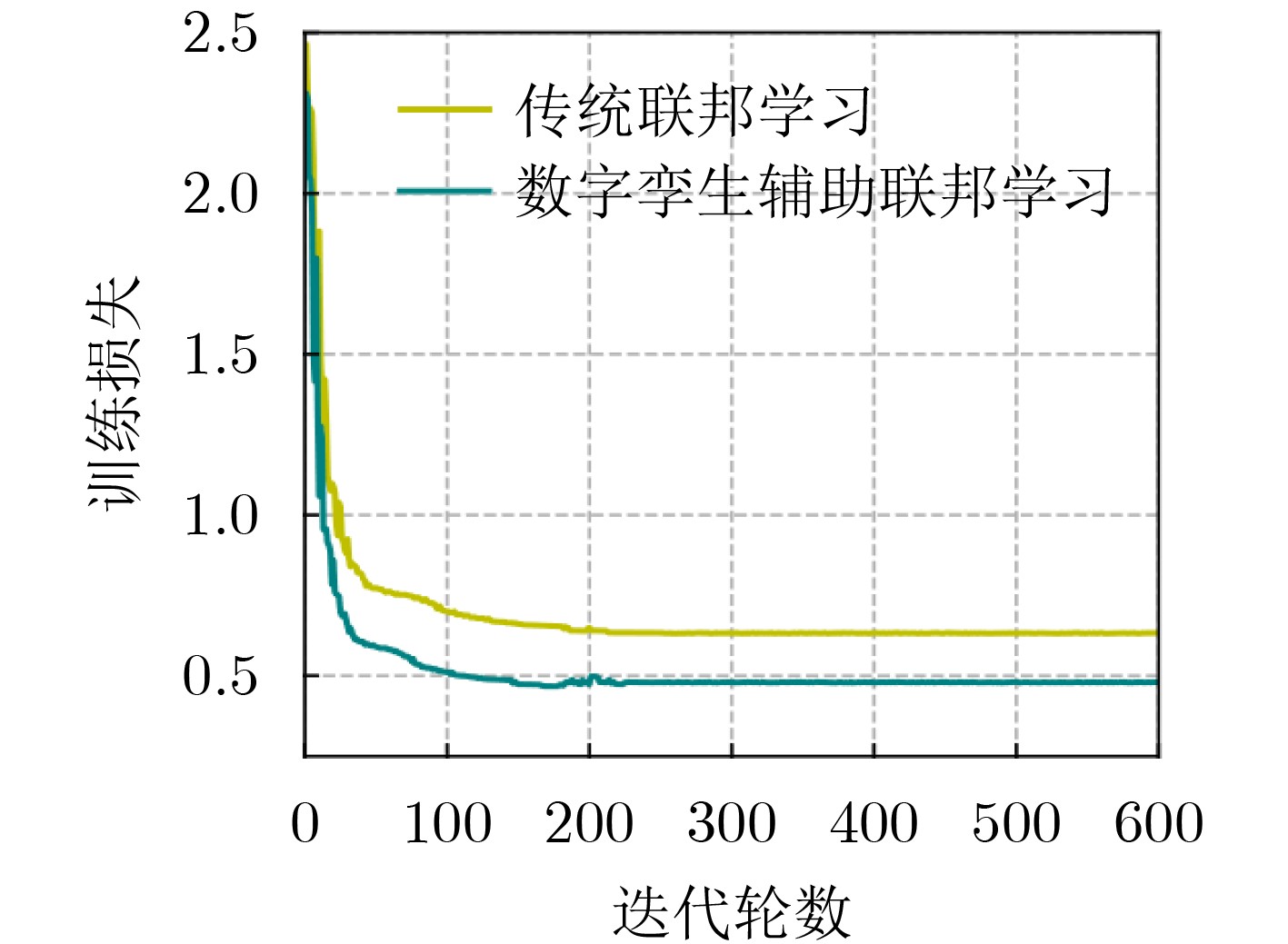







图(8) / 表(1)
计量
- 文章访问数: 1834
- HTML全文浏览量: 981
- PDF下载量: 154
- 被引次数: 0
