

Weakly Supervised Object Real-time Detection Based on High-resolution Class Activation Mapping Algorithm
-
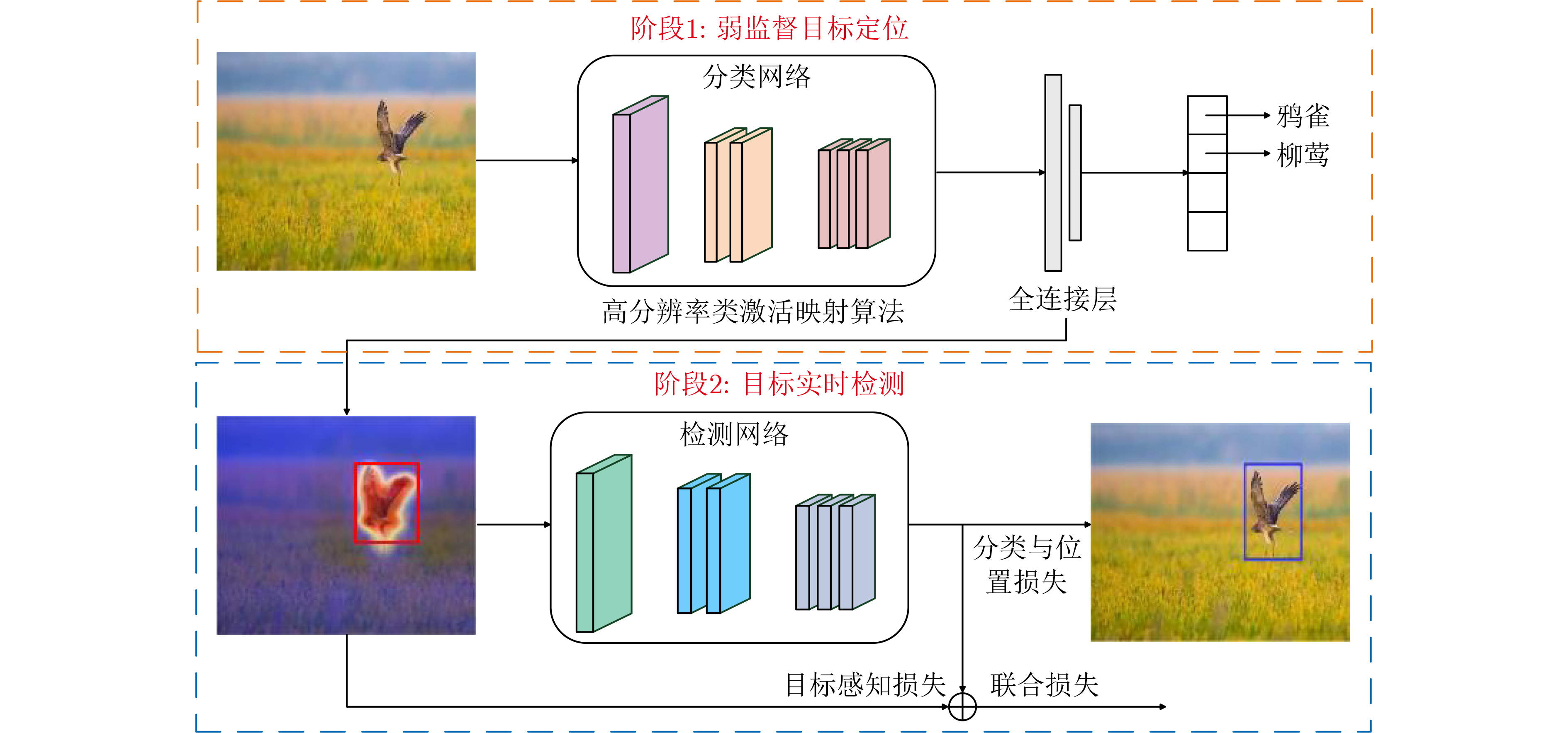
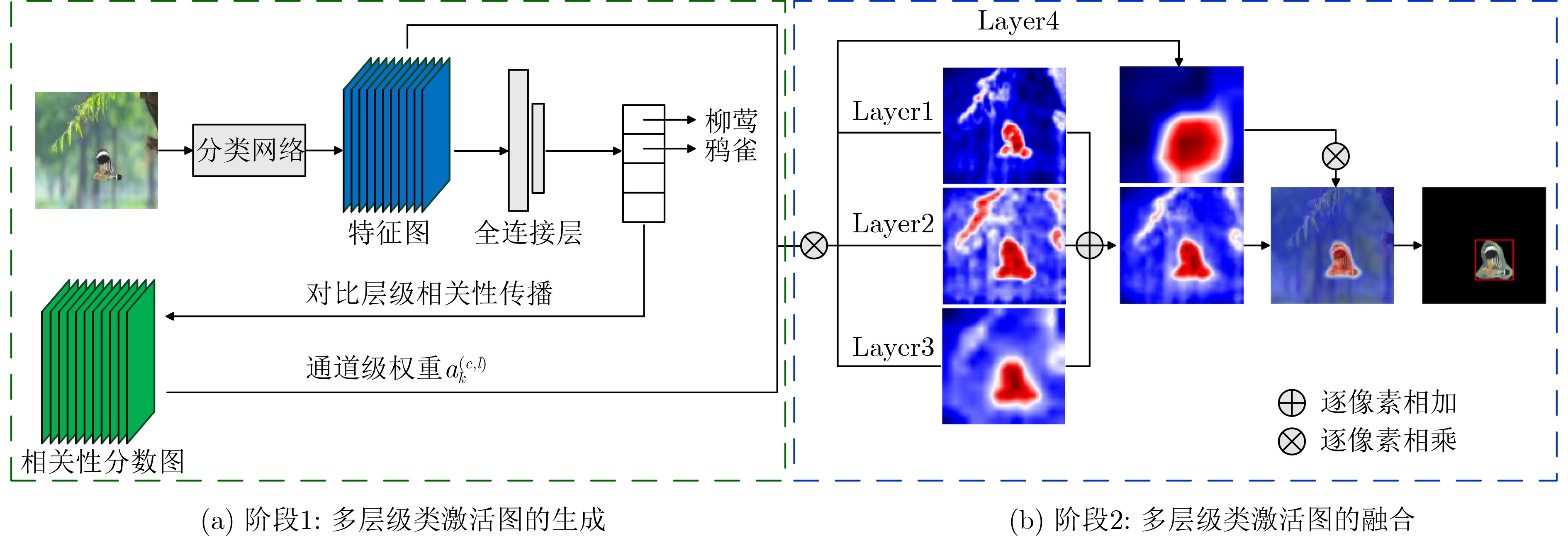
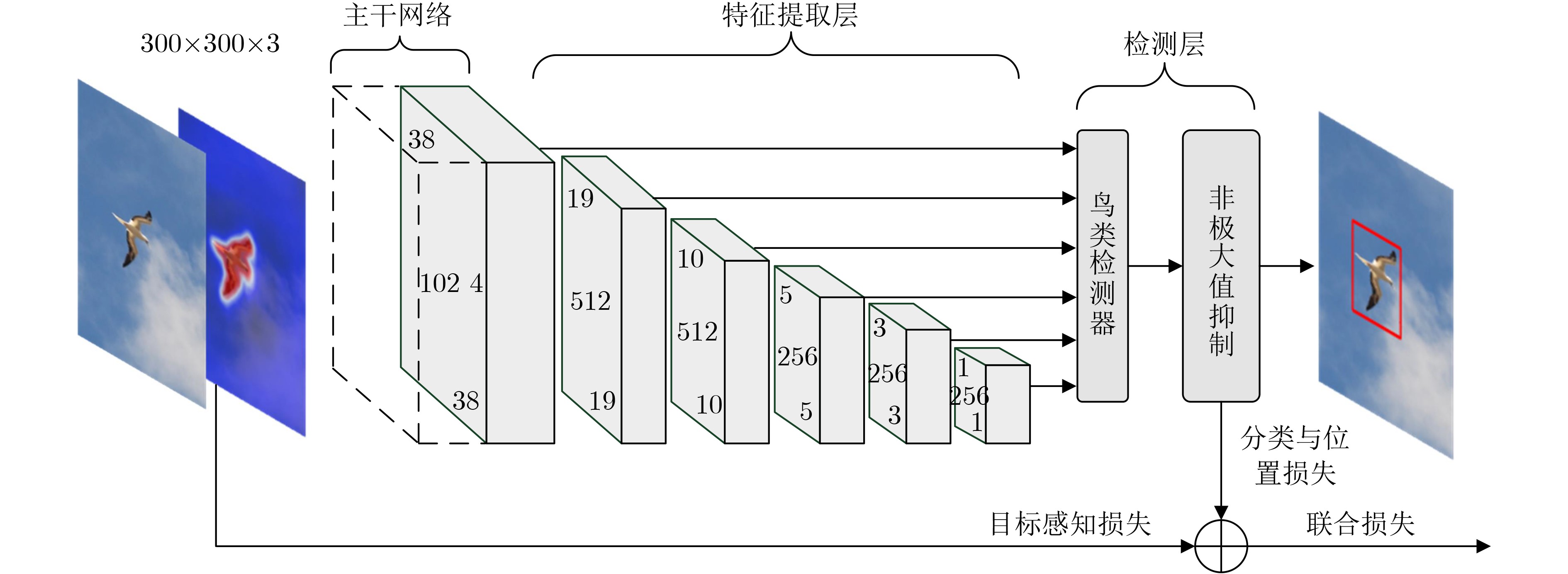
摘要: 受益于深度学习的发展,目标检测技术在各类视觉任务中得到广泛关注。然而,获取目标的边框标注需要高昂的时间和人工成本,阻碍了目标检测技术在实际场景中的应用。为此,该文在仅使用图像类别标签的基础上,提出一种基于高分辨率类激活映射算法的弱监督目标实时检测方法,降低网络对目标实例标注的依赖。该方法将目标检测细划分为弱监督目标定位和目标实时检测两个子任务。在弱监督定位任务中,该文利用对比层级相关性传播理论设计了一种新颖的高分辨率类激活映射算法(HR-CAM),用于获取高质量目标类激活图,生成目标伪检测标注框。在实时检测任务中,该文选取单镜头多盒检测器(SSD)作为目标检测网络,并基于类激活图设计目标感知损失函数(OA-Loss),与目标伪检测标注框共同监督SSD网络的训练过程,提高网络对目标的检测性能。实验结果表明,该文方法在CUB200和TJAB52数据集上实现了对目标准确高效的检测,验证了该文方法的有效性和优越性。
-
关键词:
- 弱监督定位 /
- 目标检测 /
- 对比层级相关性传播理论 /
- 类激活映射算法 /
- 目标感知损失函数
Abstract: Thanks to the development of deep learning technology, object detection techniques have gained wide attention in various vision tasks. However, obtaining bounding box annotations for objects requires high time and labor costs, which hinders the application of object detection technology in practical scenarios. Therefore, a weakly supervised real-time object detection method based on high resolution class activation mapping algorithm is proposed, using only image class labels to reduce the dependence of network on object instance labels. It subdivides object detection into two subtasks: weakly supervised object localization and real-time object detection. In weakly supervised object localization task, a novel High Resolution Class Activation Mapping(HR-CAM) algorithm based on contrastive layer-wise relevance propagation theory is designed. It can obtain high quality class activation maps and generate pseudo detection annotation box. In real-time detection task, Single Shot multibox Detector(SSD) network as object detector is selected and an Object-Aware Loss function(OA-Loss) based on the class activation maps is designed. It can jointly supervise the training process of the SSD network with generated pseudo detection annotation box, to improve the networks' detection performance for objects. The experimental results show that the method proposed in this paper can achieve accurate and efficient object detection on the CUB200 and TJAB52 datasets, verifying the effectiveness and superiority of this method. -
表 1 不同弱监督定位方法在CUB200数据集实验结果对比(%)
方法 分类网络 CUB200 Top-1 Top-5 GT-know CAM[17] VGG16 41.06 50.66 55.10 ACoL[18] VGG16 45.92 56.51 62.96 ADL[19] VGG16 52.36 – 75.41 DANet[20] VGG16 52.52 61.96 67.70 I2C[21] VGG16 55.99 68.34 – MEIL[22] VGG16 57.46 – 73.84 GCNet[23] VGG16 63.24 75.54 81.10 PSOL[24] VGG16 66.30 84.05 89.11 SPA[25] VGG16 60.27 72.50 77.29 SLT[31] VGG16 67.80 – 87.60 FAM[13] VGG16 69.26 – 89.26 本文方法 VGG16 67.43 82.59 87.34 CAM[17] Resnet50 46.71 54.44 57.35 ADL[19] Resnet50-SE 62.29 – – I2C[21] Resnet50 – – – PSOL[24] Resnet50 70.68 86.64 90.00 WTL[32] Resnet50 64.70 – 77.35 FAM[13] Resnet50 73.74 – 85.73 本文方法 Resnet50 71.82 85.29 87.19  下载: 导出CSV
下载: 导出CSV
表 2 TJAB52鸟类数据集弱监督定位实验结果(%)
主干网络 Acc Top-1 Top-5 GT-know Vgg16 85.92 76.68 89.52 90.83 Resnet50 89.07 81.35 93.37 94.96
下载: 导出CSV
表 3 CUB200和TJAB52数据集目标检测实验结果(%)
评价指标 CUB200 TJAB52 伪标注 真实标注 伪标注 真实标注 Acc 81.43 82.24 83.79 85.94 Top-1 77.96 83.61 81.03 87.46 Top-5 80.32 87.56 85.90 92.15
下载: 导出CSV
-
[1] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]. The 28th International Conference on Neural Information Processing Systems. Montreal, Canada, 2015: 1137–1149. [2] LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: Single shot multiBox detector[C]. 14th European Conference on Computer Vision. Amsterdam, The Netherlands, Springer, 2016: 21–37. [3] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]. The 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 779–788. [4] REDMON J and FARHADI A. YOLO9000: Better, faster, stronger[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, USA, 2017: 6517–6525. [5] REDMON J and FARHADI A. YOLOv3: An incremental improvement[EB/OL].https://arxiv.org/abs/1804.02767, 2018. [6] BOCHKOVSKIY A, WANG C Y, and LIAO H Y M. YOLOv4: Optimal speed and accuracy of object detection[EB/OL].https://arxiv.org/abs/2004.10934, 2020. [7] 王蕊, 史玉龙, 孙辉, 等. 基于轻量化的高分辨率鸟群识别深度学习网络[J]. 华中科技大学学报(自然科学版), 2023, 51(5): 81–87. doi: 10.13245/j.hust.230513.WANG Rui, SHI Yulong, SUN Hui, et al. Lightweight-based high resolution bird flocking recognition deep learning network[J]. Journal of Huazhong University of Science and Technology (Nature Science Edition), 2023, 51(5): 81–87. doi: 10.13245/j.hust.230513. [8] 王蕊, 李金洺, 史玉龙, 等. 基于视觉的机场无人驱鸟车路径规划算法[J/OL]. https://doi.org/10.13700/j.bh.1001-5965.2022.0717, 2022.WANG Rui, LI Jinming, SHI Yulong, et al. Vision-based path planning algorithm of unmanned bird-repelling vehicles in airports[J/OL]. https://doi.org/10.13700/j.bh.1001-5965.2022.0717, 2022. [9] CARBONNEAU M A, CHEPLYGINA V, GRANGER E, et al. Multiple instance learning: A survey of problem characteristics and applications[J]. Pattern Recognition, 2018, 77: 329–53. doi: 10.1016/j.patcog.2017.10.009. [10] 程帅, 孙俊喜, 曹永刚, 等. 多示例深度学习目标跟踪[J]. 电子与信息学报, 2015, 37(12): 2906–2912. doi: 10.11999/JEIT150319.CHENG Shuai, SUN Junxi, CAO Yonggang, et al. Target tracking based on multiple instance deep learning[J]. Journal of Electronics &Information Technology, 2015, 37(12): 2906–2912. doi: 10.11999/JEIT150319. [11] 罗艳, 项俊, 严明君, 等. 基于多示例学习和随机蕨丛检测的在线目标跟踪[J]. 电子与信息学报, 2014, 36(7): 1605–1611. doi: 10.3724/SP.J.1146.2013.01358.LUO Yan, XIANG Jun, YAN Mingjun, et al. Online target tracking based on mulitiple instance learning and random ferns detection[J]. Journal of Electronics &Information Technology, 2014, 36(7): 1605–1611. doi: 10.3724/SP.J.1146.2013.01358. [12] XIE Jinheng, LUO Cheng, ZHU Xiangping, et al. Online refinement of low-level feature based activation map for weakly supervised object localization[C]. The 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 132–141. [13] MENG Meng, ZHANG Tianzhu, TIAN Qi, et al. Foreground activation maps for weakly supervised object localization[C]. The 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 3365–3375. [14] 孙辉, 史玉龙, 王蕊. 基于对比层级相关性传播的由粗到细的类激活映射算法研究[J]. 电子与信息学报, 2023, 45(4): 1454–1463. doi: 10.11999/JEIT220113.SUN Hui, SHI Yulong, and WANG Rui. Study of coarse-to-fine class activation mapping algorithms based on contrastive layer-wise relevance propagation[J]. Journal of Electronics &Information Technology, 2023, 45(4): 1454–1463. doi: 10.11999/JEIT220113. [15] IBRAHEM H, SALEM A D A, and KANG H S. Real-time weakly supervised object detection using center-of-features localization[J]. IEEE Access, 2021, 9: 38742–38756. doi: 10.1109/ACCESS.2021.3064372. [16] BOLEI Z, KHOSLA A, LAPEDRIZA A, et al. Object detectors emerge in deep scene CNNs[EB/OL]. https://arxiv.org/abs/1412.6856, 2014. [17] ZHOU Bolei, KHOSLA A, LAPEDRIZA A, et al. Learning deep features for discriminative localization[C]. The 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 2921–2929. [18] ZHANG Xiaolin, WEI Yunchao, FENG Jiashi, et al. Adversarial complementary learning for weakly supervised object localization[C]. The 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 1325–1334. [19] CHOE J and SHIM H. Attention-based dropout layer for weakly supervised object localization[C]. The 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 2219–2228. [20] XUE Haolan, LIU Chang, WAN Fang, et al. DANet: Divergent activation for weakly supervised object localization[C]. The 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 6588–6597. [21] ZHANG Xiaolin, WEI Yunchao, and YANG Yi. Inter-image communication for weakly supervised localization[C]. 16th European Conference on Computer Vision, Glasgow, UK, 2020: 271–287. [22] MAI Jinjie, YANG Meng, and LUO Wenfeng. Erasing integrated learning: A simple yet effective approach for weakly supervised object localization[C]. The 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 8763–8772. [23] LU Weizeng, JIA Xi, XIE Weicheng, et al. Geometry constrained weakly supervised object localization[C]. 16th European Conference on Computer Vision, Glasgow, UK, 2020: 481–496. [24] ZHANG Chenlin, CAO Yunhao, and WU Jianxin. Rethinking the route towards weakly supervised object localization[C]. The 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 13457–13466. [25] PAN Xingjia, GAO Yingguo, LIN Zhiwen, et al. Unveiling the potential of structure preserving for weakly supervised object localization[C]. The 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 11637–11646. [26] GU Jindong, YANG Yinchong, and TRESP V. Understanding individual decisions of CNNs via contrastive backpropagation[C]. 14th Asian Conference on Computer Vision, Perth, Australia, 2018: 119–134. [27] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. The 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. [28] SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. https://arxiv.org/abs/1409.1556, 2014. [29] 柳毅, 徐焕然, 袁红, 等. 天津滨海国际机场鸟类群落结构及多样性特征[J]. 生态学杂志, 2017, 36(3): 740–746. doi: 10.13292/j.1000-4890.201703.029.LIU Yi, XU Huanran, YUAN Hong, et al. Bird community structure and diversity at Tianjin Binhai International Airport[J]. Chinese Journal of Ecology, 2017, 36(3): 740–746. doi: 10.13292/j.1000-4890.201703.029. [30] WAH C, BRANSON S, WELINDER P, et al. The Caltech-UCSD birds-200–2011 dataset[R]. Pasadena: California Institute of Technology, 2011. [31] GUO Guangyu, HAN Junwei, WAN Fang, et al. Strengthen learning tolerance for weakly supervised object localization[C]. The 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 7399–7408. [32] BABAR S and DAS S. Where to look?: Mining complementary image regions for weakly supervised object localization[C]. The 2021 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2021: 1010–1019. -

 下载:
下载:






图(7) / 表(3)
计量
- 文章访问数: 1045
- HTML全文浏览量: 751
- PDF下载量: 77
- 被引次数: 0
