

Blockchain Smart Contract Classification Method Based on Double Siamese Neural Network
-
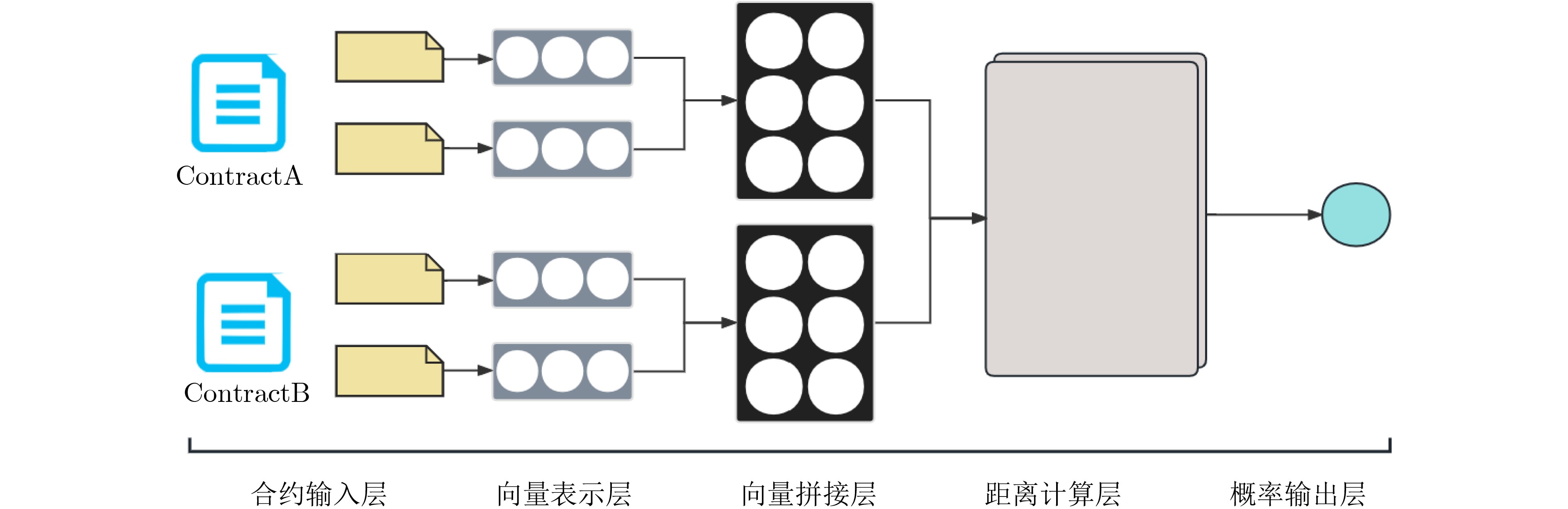
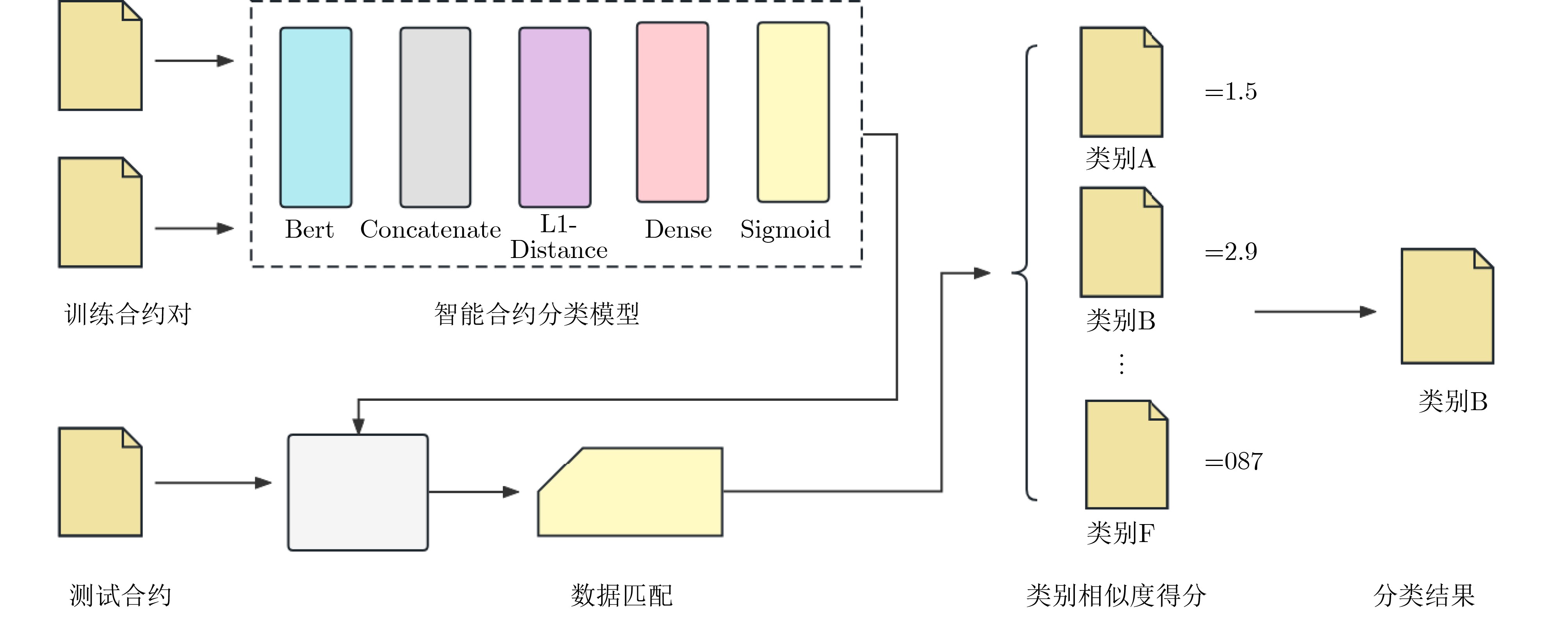
摘要: 当前通过深度学习方法进行区块链智能合约分类的方法越来越流行,但基于深度学习的方法往往需要大量的样本标签数据去进行有监督的模型训练,才能达到较高的分类性能。该文针对当前可用智能合约数据集存在数据类别不均衡以及标注数据量过少会导致模型训练困难,分类性能不佳的问题,提出基于双层孪生神经网络的小样本场景下的区块链智能合约分类方法:首先,通过分析智能合约数据特征,构建了可以捕获较长合约数据特征的双层孪生神经网络模型;然后,基于该模型设计了小样本场景下的智能合约训练策略和分类方法。最后,实验结果表明,该文所提方法在小样本场景下的分类性能优于目前最先进的智能合约分类方法,分类准确率达到94.7%,F1值达到94.6%,同时该方法对标签数据的需求更低,仅需同类型其他方法约20%数据量。Abstract: At present, methods for classifying blockchain smart contracts using deep learning methods are becoming increasingly popular. However, methods based on deep learning often require a large amount of sample label data for supervised model training to achieve high classification performance. A blockchain smart contract classification method based on a two-level twin neural network in a small sample scenario is proposed to address the problem that currently available smart contract datasets have uneven data categories and insufficient labeled data volumes, which can lead to difficulty in model training and poor classification performance. Firstly, by analyzing the characteristics of smart contract data, a two-level twin neural network model that can capture the characteristics of longer contract data is constructed; Then, based on this model, a training strategy and classification method for smart contracts in small sample scenarios are designed. Finally, experimental results show that the classification performance of the proposed method in this paper is superior to the most advanced smart contract classification methods in small sample scenarios, with a classification accuracy of 94.7% and an F1 value of 94.6%. At the same time, this method requires less tag data, requiring only about 20% data from other methods of the same type.
-
Key words:
- Smart contract /
- Blockchain /
- Siamese network /
- Ethereum
-
表 1 智能合约类别名称及数据量
游戏 赌博 社交 金融 交换 软件 DEFI NFT 媒体 钱包 交易 864 299 159 256 232 100 261 236 100 45 115 治理 安全 Farm 财产 Tools 身份 能源 健康 保险 存储 52 33 72 67 15 17 15 12 2 5  下载: 导出CSV
下载: 导出CSV
表 2 数据集类别
序号 类别 序号 类别 1 游戏 9 财产 2 赌博 10 媒体 3 社交 11 钱包、存储 4 金融 12 交易 5 交换 13 治理 6 软件 14 Farm 7 DEFI 15 NFT 8 Tools、能源、健康、保险
下载: 导出CSV
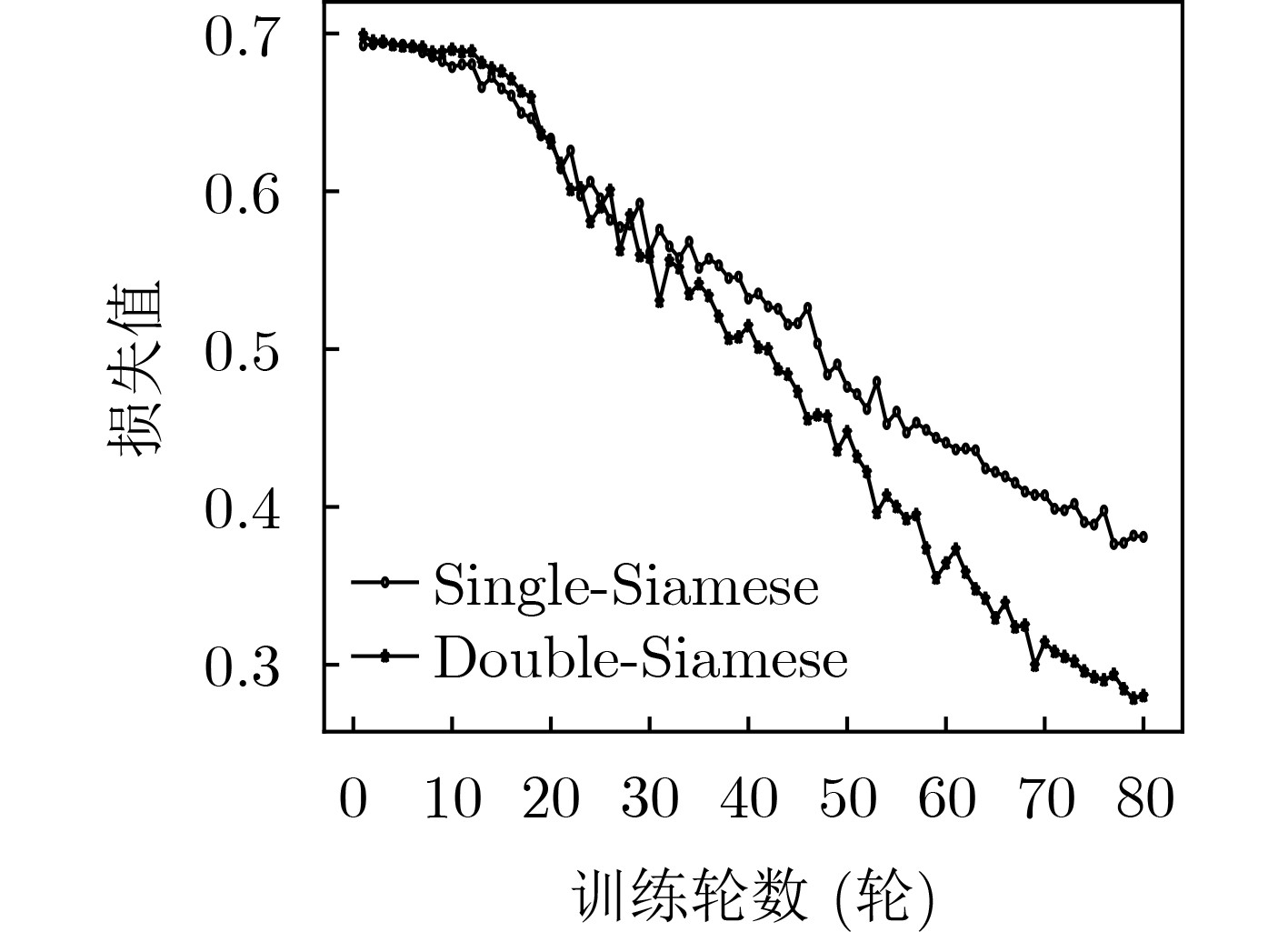
表 3 单双层孪生网络模型实验结果对比
模型 Precision Recall F1 Single-Siamese 0.880 0.873 0.874 Double-Siamese 0.947 0.946 0.946
下载: 导出CSV
表 4 向量拼接方式实验结果对比
向量拼接方式 Precision Recall F1 $({\boldsymbol{u}},{\boldsymbol{v}})$ 0.848 0.844 0.845 $(|{\boldsymbol{u}} - {\boldsymbol{v}}|)$ 0.889 0.833 0.860 $({\boldsymbol{u}} \times {\boldsymbol{v}})$ 0.894 0.880 0.886 $({\boldsymbol{u}},{\boldsymbol{v}},{\boldsymbol{u}} \times {\boldsymbol{v}})$ 0.927 0.920 0.923 $(|{\boldsymbol{u}} - {\boldsymbol{v}}|,{\boldsymbol{u}} \times {\boldsymbol{v}})$ 0.916 0.924 0.920 $ ({\boldsymbol{u}},{\boldsymbol{v}},|{\boldsymbol{u}} - {\boldsymbol{v}}|) $ 0.947 0.946 0.946
下载: 导出CSV
表 5 类别数据量实验结果
类别数据量 Precision Recall F1 10(8/2) 0.867 0.833 0.849 20(16/4) 0.921 0.900 0.910 30(24/6) 0.928 0.922 0.924 40(32/8) 0.930 0.925 0.927 50(40/10) 0.947 0.946 0.946
下载: 导出CSV
表 6 合约分类对比实验结果
模型 Precision Recall F1 支持向量机+交易信息 0.852 0.854 0.852 神经网络+交易信息 0.889 0.881 0.849 HANN-SCA 0.931 0.920 0.926 SCC-BiLSTM 0.917 0.906 0.911 Double-Siamese 0.947 0.946 0.946
下载: 导出CSV
-
[1] SZABO N. Formalizing and securing relationships on public networks[J]. First Monday, 1997, 2(9). [2] MOHANTA B K, PANDA S S, and JENA D. An overview of smart contract and use cases in blockchain technology[C]. The 9th International Conference on Computing, Communication and Networking Technologies, Bengaluru, India, 2018: 1–4. [3] GONG Jianhu and NAVIMIPOUR N J. An in-depth and systematic literature review on the blockchain-based approaches for cloud computing[J]. Cluster Computing, 2022, 25(1): 383–400. doi: 10.1007/s10586-021-03412-2. [4] 牛淑芬, 杨平平, 谢亚亚, 等. 区块链上基于云辅助的密文策略属性基数据共享加密方案[J]. 电子与信息学报, 2021, 43(7): 1864–1871. doi: 10.11999/JEIT200124.NIU Shufen, YANG Pingping, XIE Yaya, et al. Cloud-assisted ciphertext policy attribute based encryption data sharing encryption scheme based on BlockChain[J]. Journal of Electronics &Information Technology, 2021, 43(7): 1864–1871. doi: 10.11999/JEIT200124. [5] ABDELMABOUD A, AHMED A I A, ABAKER M, et al. Blockchain for IoT applications: Taxonomy, platforms, recent advances, challenges and future research directions[J]. Electronics, 2022, 11(4): 630. doi: 10.3390/electronics11040630. [6] JOHARI R, KUMAR V, GUPTA K, et al. BLOSOM: BLOckchain technology for security of medical records[J]. ICT Express, 2022, 8(1): 56–60. doi: 10.1016/j.icte.2021.06.002. [7] ZHENG Zibin, XIE Shaoan, DAI Hongning, et al. An overview on smart contracts: Challenges, advances and platforms[J]. Future Generation Computer Systems, 2020, 105: 475–491. doi: 10.1016/j.future.2019.12.019. [8] CHEN Weili, ZHENG Zibin, NGAI E C H, et al. Exploiting blockchain data to detect smart Ponzi schemes on Ethereum[J]. IEEE Access, 2019, 7: 37575–37586. doi: 10.1109/ACCESS.2019.2905769. [9] TORRES C F, STEICHEN M, and STATE R. The art of the scam: Demystifying honeypots in Ethereum smart contracts[C]. The 28th USENIX Conference on Security Symposium, Santa Clara, USA, 2019: 1591–1607. [10] LI Yikai, CHEN C L P, and ZHANG Tong. A survey on Siamese network: Methodologies, applications, and opportunities[J]. IEEE Transactions on Artificial Intelligence, 2022, 3(6): 994–1014. doi: 10.1109/TAI.2022.3207112. [11] ZHANG Jianwei, ZHANG Xubin, LV Lei, et al. An applicative survey on few-shot learning[J]. Recent Patents on Engineering, 2022, 16(5): 104–124. doi: 10.2174/1872212115666210715121344. [12] WANG Zhenzhi, WANG Limin, WU Tao, et al. Negative sample matters: A renaissance of metric learning for temporal grounding[C]. The 36th AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2022: 2613–2623. [13] BARTOLETTI M and POMPIANU L. An empirical analysis of smart contracts: Platforms, applications, and design patterns[C]. The International Conference on Financial Cryptography and Data Security, Sliema, Malta, 2017: 494–509. [14] 黄步添, 刘琦, 何钦铭, 等. 基于语义嵌入模型与交易信息的智能合约自动分类系统[J]. 自动化学报, 2017, 43(9): 1532–1543. doi: 10.16383/j.aas.2017.c160655.HUANG Butian, LIU Qi, HE Qinming, et al. Towards automatic smart-contract codes classification by means of word embedding model and transaction information[J]. Acta Automatica Sinica, 2017, 43(9): 1532–1543. doi: 10.16383/j.aas.2017.c160655. [15] MIKOLOV T, SUTSKEVER I, CHEN Kai, et al. Distributed representations of words and phrases and their compositionality[C]. The 26th International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada, 2013: 3111–3119. [16] 高飞. 基于区块链技术的智能合约自动分类系统设计[J]. 高原科学研究, 2018, 2(4): 51–59. doi: 10.16249/j.cnki.2096-4617.2018.04.007.GAO Fei. Design of intelligent contract automatic classification system based on blockchain technology[J]. Plateau Science Research, 2018, 2(4): 51–59. doi: 10.16249/j.cnki.2096-4617.2018.04.007. [17] SUN Xun, LIN Xingwei, and LIAO Zhou. An ABI-based classification approach for Ethereum smart contracts[C]. 2021 IEEE International Conference on Dependable, Autonomic and Secure Computing, International Conference on Pervasive Intelligence and Computing, International Conference on Cloud and Big Data Computing, International Conference on Cyber Science and Technology Congress, Calgary, Canada, 2021: 99–104. [18] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000-6010. [19] 吴雨芯, 蔡婷, 张大斌. 基于层级注意力机制与双向长短期记忆神经网络的智能合约自动分类模型[J]. 计算机应用, 2020, 40(4): 978–984. doi: 10.11772/j.issn.1001-9081.2019081327.WU Yuxin, CAI Ting, and ZHANG Dabin. Automatic smart contract classification model based on hierarchical attention mechanism and bidirectional long short-term memory neural network[J]. Journal of Computer Applications, 2020, 40(4): 978–984. doi: 10.11772/j.issn.1001-9081.2019081327. [20] ENAMOTO L, SANTOS A R A S, MAIA R, et al. Multi-label legal text classification with BiLSTM and attention[J]. International Journal of Computer Applications in Technology, 2022, 68(4): 369–378. doi: 10.1504/IJCAT.2022.125186. [21] TIAN Gang, WANG Qibo, ZHAO Yi, et al. Smart contract classification with a Bi-LSTM based approach[J]. IEEE Access, 2020, 8: 43806–43816. doi: 10.1109/ACCESS.2020.2977362. [22] LIU Han, YANG Zhiqiang, LIU Chao, et al. EClone: Detect semantic clones in Ethereum via symbolic transaction sketch[C]. The 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Lake Buena Vista, USA, 2018: 900–903. [23] REIMERS N and GUREVYCH I. Sentence-BERT: Sentence embeddings using Siamese BERT-networks[C]. The 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 2019. [24] DEVLIN J, CHANG Mingwei, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]. The 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, USA, 2019. [25] SUN Chi, QIU Xipeng, XU Yige, et al. How to fine-tune BERT for text classification?[C]. The 18th China National Conference on Chinese Computational Linguistics, Kunming, China, 2019: 194–206. -


 下载:
下载:




图(7) / 表(6)
计量
- 文章访问数: 990
- HTML全文浏览量: 608
- PDF下载量: 65
- 被引次数: 0
