

Hole Filling for Virtual View Synthesized Image by Combining with Contextual Feature Fusion
-
摘要: 由于参考纹理视图的前景遮挡和不同视点间的视角差异,基于深度图的虚拟视点合成会产生大量空洞,先前的空洞填充方法耗时较长且填充区域与合成图像缺乏纹理一致性。该文首先对深度图进行预处理来减少空洞填充时的前景渗透;然后,针对经3D-warping后输出合成图像中的空洞,设计了一种基于生成对抗网络(GAN)架构的图像生成网络来填充空洞。该网络模型由2级子网络构成,第1级网络生成空洞区域的纹理结构信息,第2级网络采用了一种结合上下文特征融合的注意力模块来提升空洞填充质量。提出的网络模型能有效解决当虚拟视点图像中的前景对象存在快速运动时,空洞填充区易产生伪影的问题。在多视点深度序列上的实验结果表明,提出方法在主客观质量上均优于已有的虚拟视点图像空洞填充方法。Abstract: Due to the foreground occlusion of the reference texture and the difference in angle-of-views, many holes can be found in the synthesized images produced by depth image-based virtual view rendering. Prior disocclusion methods are time-consuming and need more texture consistency between hole-filled regions and the synthesized image. In this paper, depth maps are first pre-processed to reduce foreground penetration during hole filling. Then, for holes in the synthesized images after 3D warping, an image generation network based on the architecture of a Generative Adversarial Network (GAN) is designed to fill the holes. This network consists of two sub-networks. The first network generates the texture and structure information of hole regions, while the second network adopts an attention module combining contextual feature fusion to improve the quality of the hole-filled regions. The proposed network can effectively solve the problem of the hole-filling areas being prone to producing artifacts when fast motion exist in the foreground objects. Experimental results on multi-view video plus depth sequences show that the proposed method is superior to the existing methods in both subjective and objective quality.
-
Key words:
- Virtual view rendering /
- Hole filling /
- Feature fusion /
- Contextual features
-
表 1 数据集详情
名称 分辨率 总帧数 基线距离(mm) 修复帧数 训练集:
测试集Ballet 1024×768 800 380 100 9:1 Breakdance 1024×768 800 370 100 9:1  下载: 导出CSV
下载: 导出CSV
表 2 不同方法在PSRN上的平均值
测试序列 PSNR↑ BA41 BA43 BA52 BA54 BR56 BR57 Cri[2] 22.057 28.019 23.639 30.471 29.258 27.779 Anh[6] 23.357 27.522 24.681 30.820 29.618 27.797 Luo[8] 24.077 27.996 24.661 32.104 29.552 27.955 VSRS[23] 23.039 27.615 24.361 29.089 29.432 28.177 Df2[16] 22.923 29.214 24.421 32.524 29.593 28.029 Gla[22] 23.674 28.823 25.015 32.284 29.599 28.279 本文 23.576 29.472 25.111 33.227 29.802 28.325
下载: 导出CSV
-
[1] DE OLIVEIRA A Q, DA SILVEIRA T L T, WALTER M, et al. A hierarchical superpixel based approach for DIBR view synthesis[J]. IEEE Transactions on Image Processing, 2021, 30: 6408–6419. doi: 10.1109/TIP.2021.3092817. [2] CRIMINISI A, PEREZ P, and TOYAMA K. Region filling and object removal by exemplar-based image inpainting[J]. IEEE Transactions on Image Processing, 2004, 13(9): 1200–1212. doi: 10.1109/TIP.2004.833105. [3] ZHU Ce and LI Shuai. Depth image based view synthesis: New insights and perspectives on Hole generation and filling[J]. IEEE Transactions on Broadcasting, 2016, 62(1): 82–93. doi: 10.1109/TBC.2015.2475697. [4] CHANG Yuan, CHEN Yisong, and WANG Guoping. Range guided depth refinement and uncertainty-aware aggregation for view synthesis[C]. International Conference on Acoustics, Speech and Signal Processing, Toronto, Canada, 2021: 2290-2294. doi: 10.1109/ICASSP39728.2021.9413981. [5] CHENG Cong, LIU Ju, YUAN Hui, et al. A DIBR method based on inverse mapping and depth-aided image inpainting[C]. 2013 IEEE China Summit and International Conference on Signal and Information Processing, Beijing, China, 2013: 518-522. doi: 10.1109/ChinaSIP.2013.6625394. [6] ANH I and KIM C. A novel depth-based virtual view synthesis method for free viewpoint video[J]. IEEE Transactions on Broadcasting, 2013, 59(4): 614–626. doi: 10.1109/TBC.2013.2281658. [7] RAHAMAN D M M and PAUL M. Virtual view synthesis for free viewpoint video and Multiview video compression using Gaussian mixture modelling[J]. IEEE Transactions on Image Processing, 2018, 27(3): 1190–1201. doi: 10.1109/TIP.2017.2772858. [8] LUO Guibo, ZHU Yuesheng, WENG Zhenyu, et al. A disocclusion inpainting framework for depth-based view synthesis[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(6): 1289–1302. doi: 10.1109/TPAMI.2019.2899837. [9] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]. Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2672–2680. doi: 10.5555/2969033.2969125. [10] RADFORD A, METZ L, and CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks[C]. 4th International Conference on Learning Representations, Puerto Rico, 2016: 1–16. [11] IIZUKA S, SIMO-SERRA E, and ISHIKAWA H. Globally and locally consistent image completion[J]. ACM Transactions on Graphics, 2017, 36(4): 107. doi: 10.1145/3072959.3073659. [12] LI Jingyuan, WANG Ning, ZHANG Lefei, et al. Recurrent feature reasoning for image inpainting[C]. Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 7757–7765. doi: 10.1109/CVPR42600.2020.00778. [13] XU Shunxin, LIU Dong, and XIONG Zhiwei. E2I: Generative inpainting from edge to image[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(4): 1308–1322. doi: 10.1109/TCSVT.2020.3001267. [14] SHIN Y G, SAGONG M C, YEO Y J, et al. PEPSI++: Fast and lightweight network for image inpainting[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(1): 252–265. doi: 10.1109/TNNLS.2020.2978501. [15] 孙磊, 杨宇, 毛秀青, 等. 基于空间特征的生成对抗网络数据生成方法[J]. 电子与信息学报, 2023, 45(6): 1959–1969. doi: 10.11999/JEIT211285.SUN Lei, YANG Yu, MAO Xiuqing, et al. Data Generation based on generative adversarial network with spatial features[J]. Journal of Electronics & Information Technology, 2023, 45(6): 1959–1969. doi: 10.11999/JEIT211285. [16] YU Jiahui, LIN Zhe, YANG Jimei, et al. Free-form image inpainting with gated convolution[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 4470–4479. doi: 10.1109/ICCV.2019.00457. [17] PATHAK D, KRÄHENBÜHL P, DONAHUE J, et al. Context encoders: Feature learning by inpainting[C]. IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 2536–2544. doi: 10.1109/CVPR. [18] LIU Guilin, DUNDAR A, SHIH K J, et al. Partial convolution for padding, inpainting, and image synthesis[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(5): 6096–6110. doi: 10.1109/TPAMI.2022.3209702. [19] Microsoft. MSR 3D Video dataset from official microsoft download center[EB/OL]. https://www.microsoft.com/en-us/download/details.aspx?id=52358, 2014. [20] JOHNSON J, ALAHI A, and LI Feifei. Perceptual losses for real-time style transfer and super-resolution[C]. 14th European Conference Computer Vision 2016, Amsterdam, Netherlands, 2016: 694–711. doi: 10.1007/978-3-319-46475-6_43. [21] YUAN H L and VELTKAMP R C. Free-viewpoint image based rendering with multi-layered depth maps[J]. Optics and Lasers in Engineering, 2021, 147: 106726. doi: 10.1016/j.optlaseng.2021.106726. [22] UDDIN S M N and JUNG Y J. Global and local attention-based free-form image inpainting[J]. Sensors, 2020, 20(11): 3204. doi: 10.3390/s20113204. [23] STANKIEWICZ O and WEGNER K. Depth estimation reference software and view synthesis reference software[S]. Switzerland: ISO/IEC JTC1/SC29/WG11 MPEG/M16027, 2009. [24] LI Zhen, LU Chengze, QIN Jianhua, et al. Towards an end-to-end framework for flow-guided video inpainting[C]. Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 17541–17550. doi: 10.1109/CVPR52688.2022.01704. -

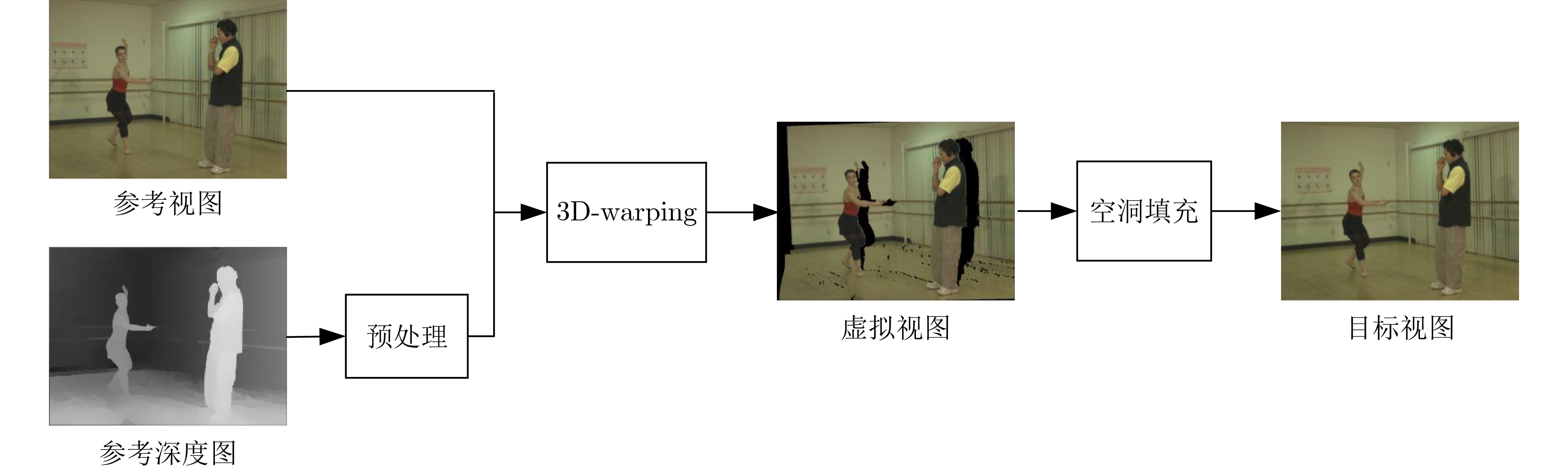
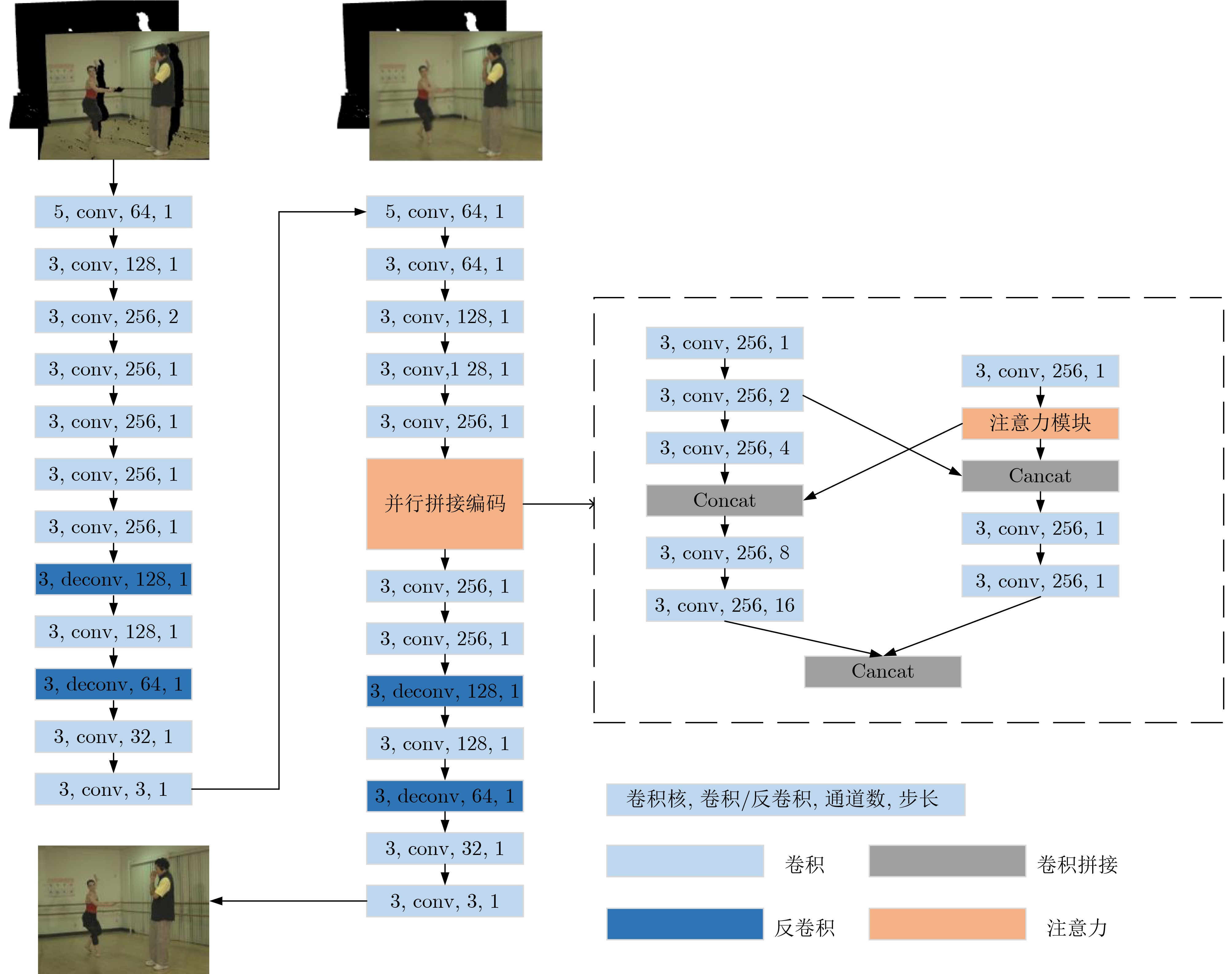
 下载:
下载:


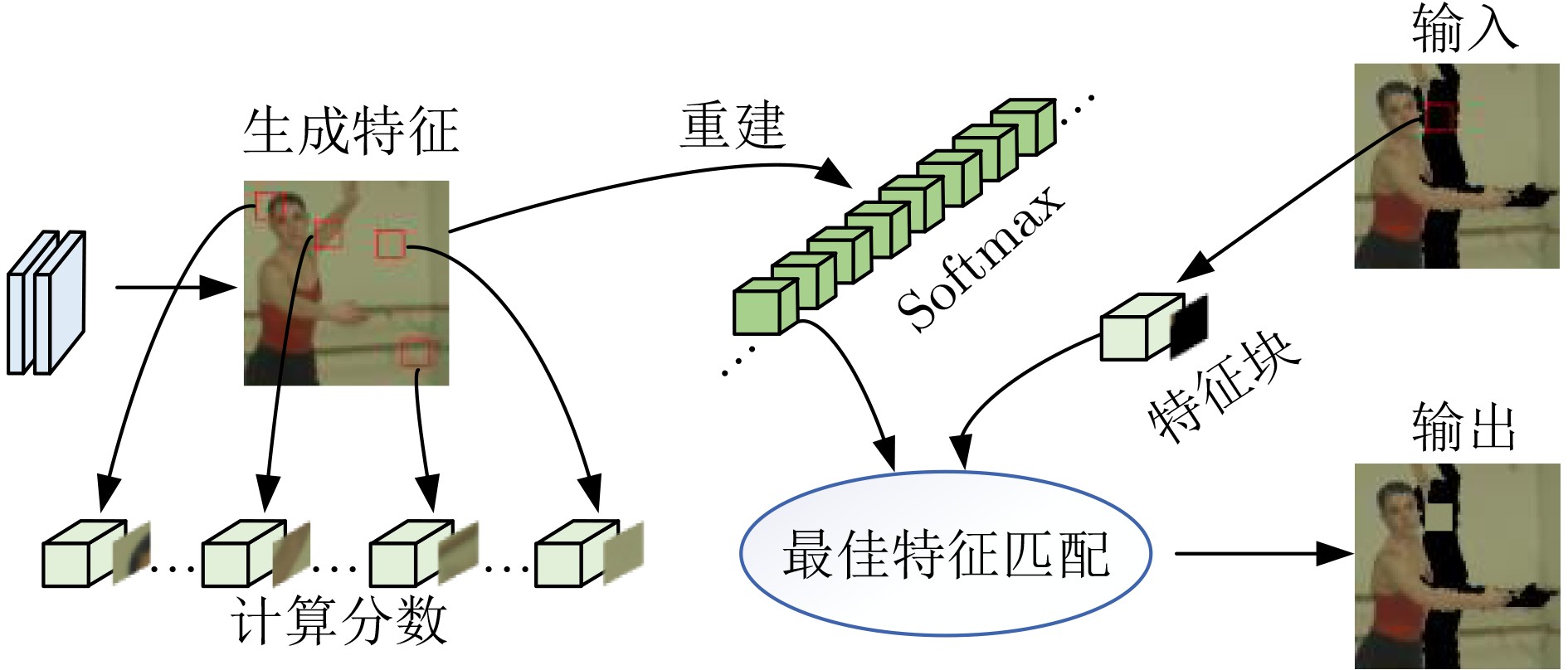





图(8) / 表(4)
计量
- 文章访问数: 757
- HTML全文浏览量: 798
- PDF下载量: 60
- 被引次数: 0
