

Gait Emotion Recognition Based on a Multi-scale Partitioning Directed Spatio-temporal Graph
-
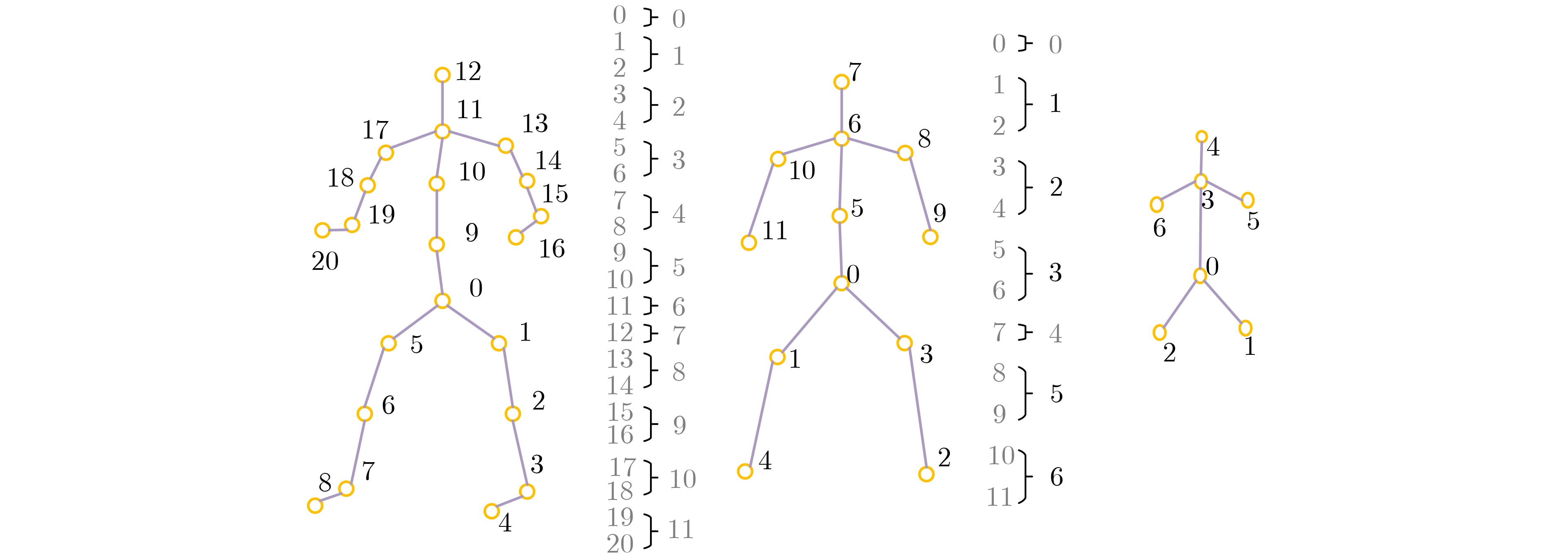
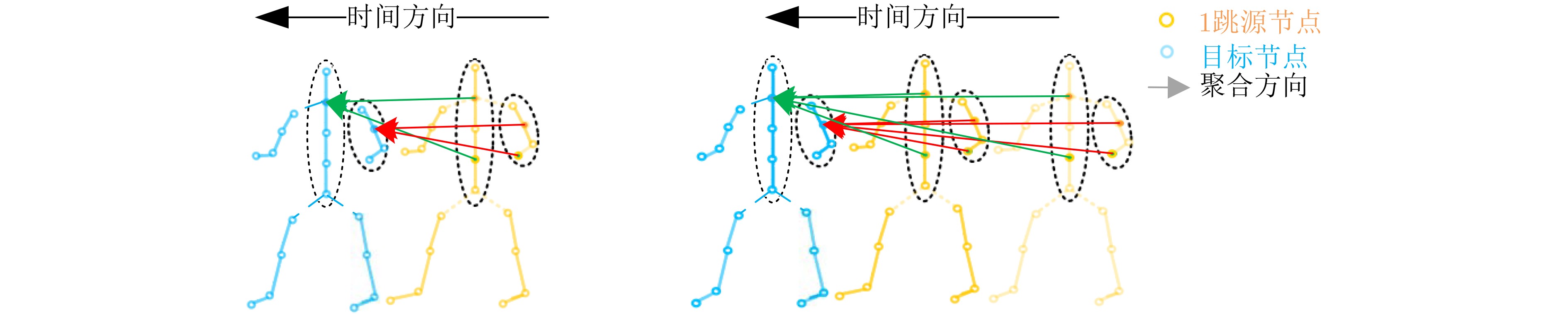
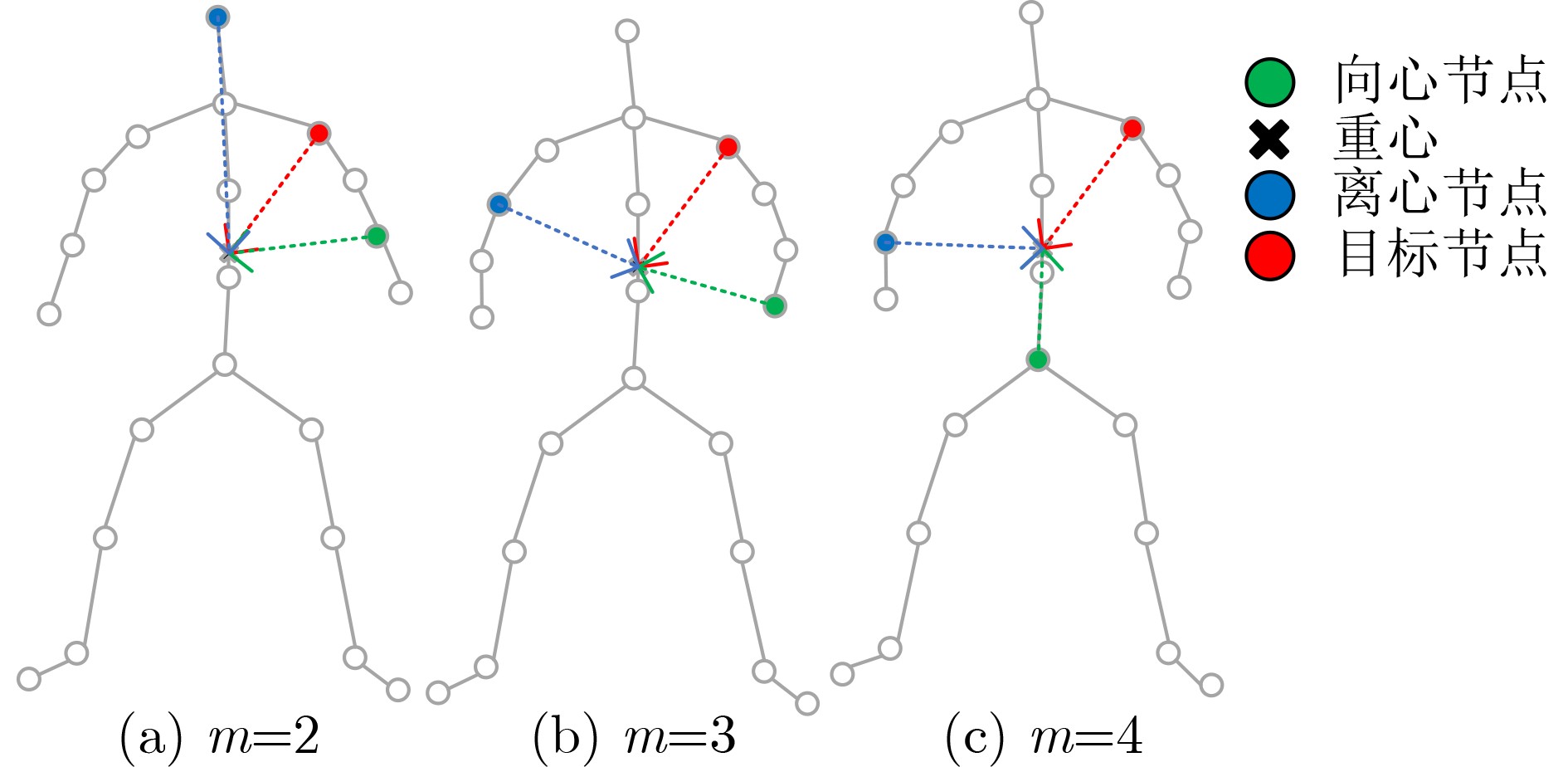
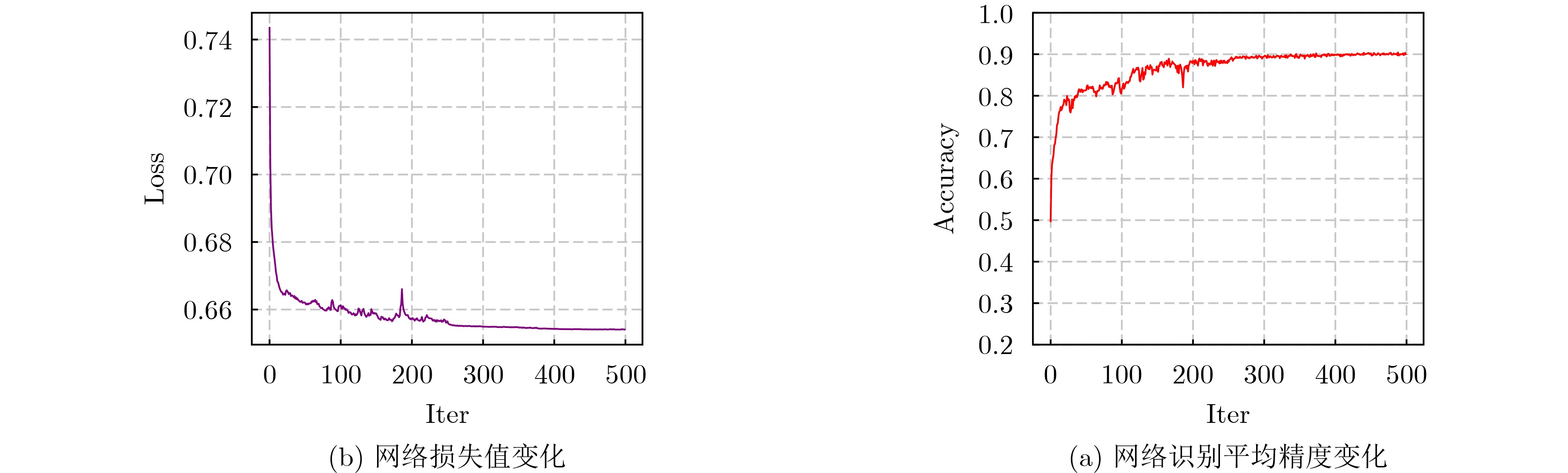
摘要: 为了有效获取节点之间在多尺度、远距离以及在时间和空间位置上的依赖关系,以提高对步态情绪识别精度,本文首先提出一种构建分区有向时空图的方法:使用所有帧节点进行构图,然后按区域有向连接。其次,提出一种多尺度分区聚合与分区融合的方法。通过图深度学习对图节点进行更新。并对相似节点特征进行融合。最后,提出一个多尺度分区有向自适应时空图卷积神经网络(MPDAST-GCN)方法。网络通过在时间维度上构建图,获取远距离帧节点特征,并自适应地学习每帧上的特征数据。MPDAST-GCN将输入数据分类成高兴、伤心、愤怒和平常4种情绪类型。并在发布的Emotion-Gait数据集上,相比于目前最先进的方法实现6%的精度提升。Abstract: To enhance the precision of gait emotion recognition by effectively capturing the dependencies between nodes at multiple scales, long distances, and temporal and spatial positions, a novel method comprising three parts is proposed in this paper. Firstly, a partitioned directed spatio-temporal graph construction method is proposed. It connects all frame nodes in a directed manner based on their regions. Secondly, a multi-scale partition aggregation and fusion method is proposed. This method updates the graph nodes using graph deep learning and fuses similar node features. Lastly, a Multi-scale Partition Directed Adaptive Spatio-Temporal Graph Convolutional Neural network (MPDAST-GCN) is proposed. It constructs a graph in the temporal dimension to obtain the features of distant frame nodes and learns the feature data adaptively on each frame. The MPDAST-GCN classifies input data into four emotion types: happy, sad, angry, and normal. Experimental results on the Emotion-Gait dataset demonstrate that the proposed method outperforms state-of-the-art methods by 6% in terms of accuracy.
-
Key words:
- Gait emotion recognition /
- Emotion recognition /
- Graph deep learning
-
表 2 是否使用分区聚合算法以及不同聚合尺度$k$对网络性能影响
Parameter Accuracy(%) k m Happy Sad Angry Normal MAP 不使用 1 1 96.8 86.0 87.0 70.8 85.1 1 1 98.9 89.4 86.4 70.0 86.2 使用 2 1 98.6 90.3 87.5 68.9 86.3 3 1 98.9 85.0 90.8 72.6 86.8  下载: 导出CSV
下载: 导出CSV
表 3 是否使用分区融合方法对网络性能影响
Parameter Accuracy(%) k m Happy Sad Angry Normal MAP 不使用 1 1 98.9 89.4 86.4 70.0 86.2 使用 1 1 97.8 92.2 88.8 74.3 88.3
下载: 导出CSV
表 4 不同尺度下的图卷积块对网络性能影响
Parameter Accuracy(%) k m Happy Sad Angry Normal MAP MPDAST-GCN 1 1 97.8 92.2 88.8 74.3 88.3 1 2 96.8 92.6 91.0 76.0 89.1 1 3 97.4 90.0 91.8 79.0 89.6
下载: 导出CSV
-
[1] 王汝言, 陶中原, 赵容剑, 等. 多交互图卷积网络用于方面情感分析[J]. 电子与信息学报, 2022, 44(3): 1111–1118. doi: 10.11999/JEIT210459.WANG Ruyan, TAO Zhongyuan, ZHAO Rongjian, et al. Multi-interaction graph convolutional networks for aspect-level sentiment analysis[J]. Journal of Electronics &Information Technology, 2022, 44(3): 1111–1118. doi: 10.11999/JEIT210459. [2] 韩虎, 吴渊航, 秦晓雅. 面向方面级情感分析的交互图注意力网络模型[J]. 电子与信息学报, 2021, 43(11): 3282–3290. doi: 10.11999/JEIT210036.HAN Hu, WU Yuanhang, and QIN Xiaoya. An interactive graph attention networks model for aspect-level sentiment analysis[J]. Journal of Electronics &Information Technology, 2021, 43(11): 3282–3290. doi: 10.11999/JEIT210036. [3] 陈晓禾, 曹旭刚, 陈健生, 等. 基于三维卷积的帕金森患者拖步识别[J]. 电子与信息学报, 2021, 43(12): 3467–3475. doi: 10.11999/JEIT200543.doi:10.11999/JEIT200543.CHEN Xiaohe, CAO Xugang, CHEN Jiansheng, et al. Shuffling step recognition using 3D convolution for parkinsonian patients[J]. Journal of Electronics &Information Technology, 2021, 43(12): 3467–3475. doi: 10.11999/JEIT200543.doi:10.11999/JEIT200543. [4] 许文正, 黄天欢, 贲晛烨, 等. 跨视角步态识别综述[J]. 中国图象图形学报, 2023, 28(5): 1265–1286. doi: 10.11834/jig.220458.XU Wenzheng, HUANG Tianhuan, BEN Xianye, et al. Cross-view gait recognition: A review[J]. Journal of Image and Graphics, 2023, 28(5): 1265–1286. doi: 10.11834/jig.220458. [5] SEPAS-MOGHADDAM A and ETEMAD A. Deep gait recognition: A survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(1): 264–284. doi: 10.1109/TPAMI.2022.3151865. [6] BHATTACHARYA U, RONCAL C, MITTAL T, et al. Take an emotion walk: Perceiving emotions from gaits using hierarchical attention pooling and affective mapping[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 145–163. [7] BHATTACHARYA U, MITTAL T, CHANDRA R, et al. STEP: Spatial temporal graph convolutional networks for emotion perception from gaits[C]. The 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 1342–1350. [8] SUN Xiao, SU Kai, and FAN Chunxiao. VFL—A deep learning-based framework for classifying walking gaits into emotions[J]. Neurocomputing, 2022, 473: 1–13. doi: 10.1016/j.neucom.2021.12.007. [9] SHENG Weijie and LI Xinde. Multi-task learning for gait-based identity recognition and emotion recognition using attention enhanced temporal graph convolutional network[J]. Pattern Recognition, 2021, 114: 107868. doi: 10.1016/j.patcog.2021.107868. [10] HOANG T and CHOI D. Secure and privacy enhanced gait authentication on smart phone[J]. The Scientific World Journal, 2014, 2014: 438254. doi: 10.1155/2014/438254. [11] YAN Sijie, XIONG Yuanjun, and LIN Dahua. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]. Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, USA, 2018. [12] CHEN Zhan, LI Sicheng, YANG Bing, et al. Multi-scale spatial temporal graph convolutional network for skeleton-based action recognition[C]. The 35th AAAI Conference on Artificial Intelligence, 2021: 1113–1122. [13] FENG Dong, WU Zhongcheng, ZHANG Jun, et al. Multi-scale spatial temporal graph neural network for skeleton-based action recognition[J]. IEEE Access, 2021, 9: 58256–58265. doi: 10.1109/ACCESS.2021.3073107. [14] RAHEVAR M, GANATRA A, SABA T, et al. Spatial-temporal dynamic graph attention network for skeleton-based action recognition[J]. IEEE Access, 2023, 11: 21546–21553. doi: 10.1109/ACCESS.2023.3247820. [15] SHI Lei, ZHANG Yifan, CHENG Jian, et al. Two-stream adaptive graph convolutional networks for skeleton-based action recognition[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 12018–12027. DOI: 10.1109/CVPR.2019.01230. [16] SI Chenyang, CHEN Wentao, WANG Wei, et al. An attention enhanced graph convolutional LSTM network for skeleton-based action recognition[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 1227–1236. [17] LIU Ziyu, ZHANG Hongwen, CHEN Zhenghao, et al. Disentangling and unifying graph convolutions for skeleton-based action recognition[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 140–149. [18] GEDAMU K, JI Yanli, GAO Lingling, et al. Relation-mining self-attention network for skeleton-based human action recognition[J]. Pattern Recognition, 2023, 139: 109455. doi: 10.1016/j.patcog.2023.109455. [19] ZHOU Yujie, DUAN Haodong, RAO Anyi, et al. Self-supervised action representation learning from partial spatio-temporal skeleton sequences[C]. The 37th AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 3825–3833. [20] IONESCU C, PAPAVA D, OLARU V, et al. Human3.6m: Large scale datasets and predictive methods for 3D human sensing in natural environments[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(7): 1325–1339. doi: 10.1109/TPAMI.2013.248. [21] NARANG S, BEST A, FENG A, et al. Motion recognition of self and others on realistic 3D avatars[J]. Computer Animation and Virtual Worlds, 2017, 28(3/4): e1762. doi: 10.1002/cav.1762. [22] SHI Lei, ZHANG Yifan, CHENG Jian, et al. Skeleton-based action recognition with directed graph neural networks[C]. Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 7904–7913. [23] DABRAL R, MUNDHADA A, KUSUPATI U, et al. Learning 3D human pose from structure and motion[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 679–696. [24] HABIBIE I, HOLDEN D, SCHWARZ J, et al. A recurrent variational autoencoder for human motion synthesis[C]. In Proceedings of the 28th British Machine Vision Conference (BMVC), London, UK, 2017: 119.1–119.12. [25] RANDHAVANE T, BHATTACHARYA U, KAPSASKIS K, et al. Identifying emotions from walking using affective and deep features[J]. arXiv: 1906.11884, 2019. -


 下载:
下载:
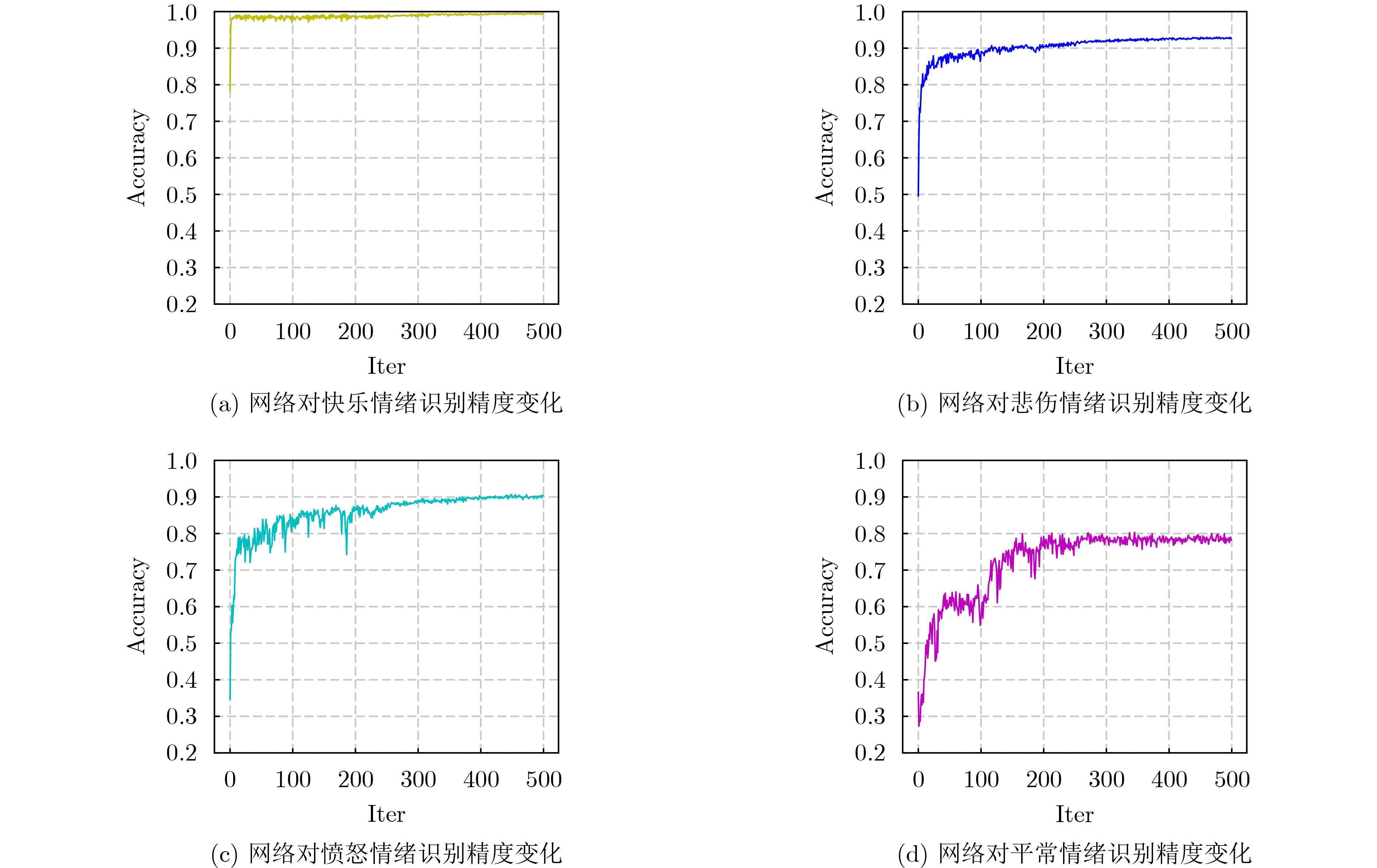


图(6) / 表(4)
计量
- 文章访问数: 1120
- HTML全文浏览量: 731
- PDF下载量: 74
- 被引次数: 0
