

Analysis on Current Development Situation of Unmanned Ground Vehicle Clusters Collaborative Pursuit
-
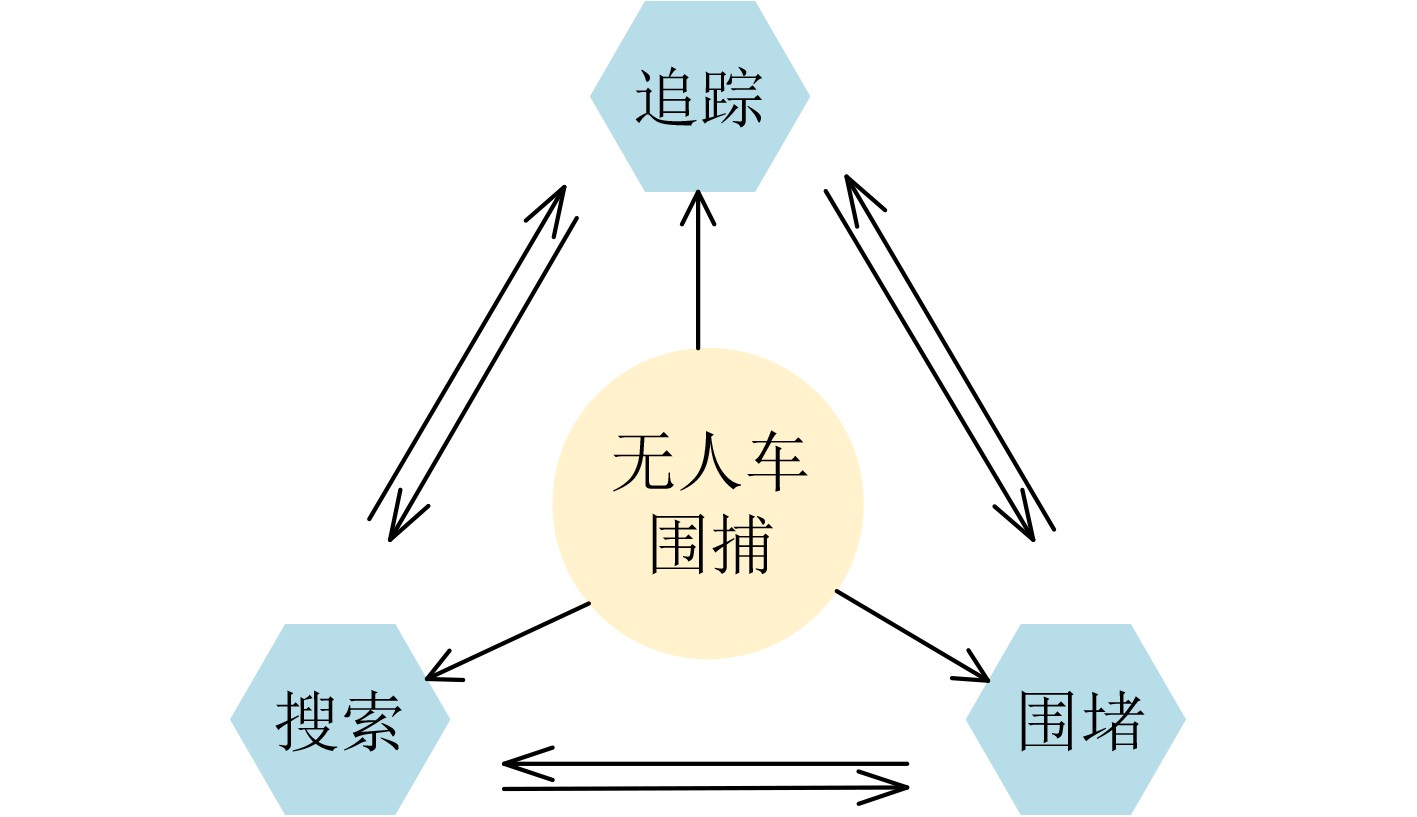
摘要: 无人车集群具有成本低、安全性好、自主程度高等优点,已成为无人驾驶领域的研究热点。基于无人车集群,研究人员提出多种不同协同策略以完成各类任务,其中协同围捕作为重要的应用方向,无论是在军用还是民用领域都受到了广泛关注。针对此问题,该文首先基于无人车集群的相关应用和架构,对协同围捕的策略机理进行了系统分析,并将协同围捕策略划分为搜索、追踪和围堵3个子模式。然后,从博弈论、概率分析和机器学习等角度梳理了协同围捕的关键方法,并对这些算法的优缺点进行了比较。最后,对未来研究提出了意见建议,为进一步提高无人车集群协同围捕的效率和性能提供参考和思路。Abstract: In recent years, there has been a growing interest in unmanned ground vehicle clustering as a research topic in the unmanned driving field for its low cost, good secuity, and high autonomy. Various collaborative strategies have been proposed for unmanned vehicle clusters, with collaborative pursuit being a particularly important application direction that has garnered significant attention in various fields. A systematic analysis of the strategy mechanism for collaborative pursuit in unmanned vehicle clusters is provided, considering relevant applications and architectures. The collaborative pursuit strategy is divided into three sub-modes: search, tracking, and roundup. The key methods for unmanned vehicle cluster collaborative pursuit are compared from the perspectives of game theory, probabilistic analysis, and machine learning, the advantages and disadvantages of these algorithms are highlighted. Finally, comments and suggestions are provided for future research, considering offer references and ideas for further improving the efficiency and performance of collaborative pursuit in unmanned vehicle clusters.
-
Key words:
- Unmanned ground vehicle clusters /
- Collaborative pursuit /
- Strategy mechanism /
- Search /
- Tracking /
- Roundup
-
表 1 无人车集群围捕常规方法
算法 文献 应用 集群规模 协同结构 优点 局限 领航—跟随法 [56](2023年) 追踪 小 集中式 实现单目标及多目标的围捕 灵活性差 虚拟结构法 [57](2019年) 追踪 小 集中式 计算简单高效,易于实现. 在理论上进行验证,未考虑实车情况 基于行为法 [58](2020年) 围捕 小/大 分布式 解决目标比围捕者移动得快的情况 空间需提前限定 快速搜索随机树 [59](2020年) 搜索追踪 小 集中式 兼容静态环境和动态环境 未考虑移动中任务分配 蚁群算法 [60](2017年) 搜索围堵 大 分布式 区域覆盖性能好 不同场景下模型参数的自适应调节差 链阵法 [61](2009年) 围捕 小 集中式 根据实际需求动态调整围捕者数 未考虑复杂障碍环境 反步法 [62](2021年) 围堵 小 集中式 系统整体鲁棒性强 避碰效果有待提高 Voronoi 图 [63](2022年) 搜索 小/大 集中式 降低整个区域不确定度 未考虑通信约束 分布式控制 [64](2019年) 围堵 小/大 分布式 解决无人车退出/加入围堵过程的问题 未考虑无人车间碰撞  下载: 导出CSV
下载: 导出CSV
表 2 无人车集群围捕优化方法探微
算法 文献 应用 目标数量 集群规模 协同结构 优点 局限 博弈论 [77](2019年) 追踪 单/多 小/大 集中式 实现围捕者在线路径规划 只在理论上进行验证,未考虑实车情况 概率分析 [78](2021年) 追踪 单 小 集中式 解决有限数量围捕者故障问题 鲁棒性不强 机器
学习强化
学习[79](2019年) 追踪围堵 单 小/大 集中式 实现围捕算法的解耦 未考虑地形、障碍物对通信影响 [80](2020年) 围堵 多 小/大 集中式 对相似的目标进行聚类,有效聚集和包围相互靠近的目标 目标过于独立时,算法有效性低 深度
强化
学习[75](2022年) 追踪 单 小 集中式训练分布式执行 数据效率和概括能力提高 只适用于单目标 [81](2021年) 追踪 单 小/大 分布式 适用于非完整性围捕者 需要为每一个目标训练一个网络 [82](2023年) 追踪围堵 多 小 集中式训练分布式执行 提高了策略迭代效率及泛化能力 目标数量增多时对结果影响较大 [66](2020年) 追踪 单 小 集中式训练分布式执行 复杂性大大降低 扩展能力有待加强 [83](2020年) 追踪 单 小 集中式训练分布式执行 围捕者和目标同时被训练,更适合与具有一定智力水平的目标 方法只适用于离散空间,未扩展到连续动作空间 [9](2020年) 围堵 单 小 分布式 在连续空间中协同完成目标围堵 收敛性有缺陷;只研究了2维有限连续空间 深度
Q 网络[84](2022年) 搜索 单/多 小/大 分布式 效果稳定,具有泛化能力 不能保证收敛,智能体间缺乏协同合作 [85](2018年) 围堵 单 小/大 集中式 考虑目标从围捕者包围中逃脱 未考虑多个目标和围捕者环境 深度
确定性
策略
梯度[86](2021年) 围捕 多 小 集中式训练分布式执行 缩短训练总时间,提高了算法稳定性、鲁棒性 只在仿真环境中运行,未考虑实际情况 [87](2019年) 追踪 单 小 集中式训练分布式执行 解决训练测试智能体数量不同的问题 - [88](2021年) 追踪 单 小/大 集中式训练分布式执行 降低模型与真实场景间误差 场景简单,围捕者、障碍物数量少 [14](2021年) 编队 单 小 集中式训练分布式执行 有效完成不同队形之间转换 智能体规模较大时效果有待提高 [89](2021年) 搜索追踪 单 小/大 集中式训练分布式执行 提出新型混合编队控制,以随机行为捕捉动态目标 未考虑到多动态目标以及比围捕运动更快的目标 [90](2018年) 追踪围堵 单 小 集中式训练分布式执行 避障效果好 未包含机器人的顶层决策
下载: 导出CSV
-
[1] ZHANG Tianhao, LI Yueheng, LI Shuai, et al. Decentralized circle formation control for fish-like robots in the real-world via reinforcement learning[C]. 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 2021: 8814–8820. doi: 10.1109/ICRA48506.2021.9562019. [2] CAO Ruyue, LI Shichao, JI Yuhan, et al. Task assignment of multiple agricultural machinery cooperation based on improved ant colony algorithm[J]. Computers and Electronics in Agriculture, 2021, 182: 105993. doi: 10.1016/j.compag.2021.105993. [3] HAMED O, HAMLICH M, and ENNAJI M. Hunting strategy for multi-robot based on wolf swarm algorithm and artificial potential field[J]. Indonesian Journal of Electrical Engineering and Computer Science, 2022, 25(1): 159–171. doi: 10.11591/ijeecs.v25.i1.pp159-171. [4] ZHANG Youmin and MEHRJERDI H. A survey on multiple unmanned vehicles formation control and coordination: Normal and fault situations[C]. 2013 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, USA, 2013: 1087–1096. doi: 10.1109/ICUAS.2013.6564798. [5] 李冀, 周战洪, 贺红林, 等. 基于围猎改进哈里斯鹰优化的粒子滤波方法[J]. 电子与信息学报, 2023, 45(6): 2284–2292. doi: 10.11999/JEIT220532.LI Ji, ZHOU Zhanhong, HE Honglin, et al. A particle filter method based on harris hawks optimization improved by encircling strategy[J]. Journal of Electronics & Information Technology, 2023, 45(6): 2284–2292. doi: 10.11999/JEIT220532. [6] CHEN Zhongyu, NIU Ben, ZHANG Liang, et al. Command filtering-based adaptive neural network control for uncertain switched nonlinear systems using event-triggered communication[J]. International Journal of Robust and Nonlinear Control, 2022, 32(11): 6507–6522. doi: 10.1002/rnc.6154. [7] ZHENG Lulu, CHEN Jiarui, WANG Jianhao, et al. Episodic multi-agent reinforcement learning with curiosity-driven exploration[C]. 35th Conferenceon Neural Information Processing Systems, Sydney, Australi, 2021: 3757–3769. doi: 10.48550/arXiv.2111.11032. [8] ZHANG Liwei, LIN Zhibin, WANG Jie, et al. Rapidly-exploring random trees multi-robot map exploration under optimization framework[J]. Robotics and Autonomous Systems, 2020, 131: 103565. doi: 10.1016/j.robot.2020.103565. [9] MA Junchong, LU Huimin, XIAO Junhao, et al. Multi-robot target encirclement control with collision avoidance via deep reinforcement learning[J]. Journal of Intelligent & Robotic Systems, 2020, 99(2): 371–386. doi: 10.1007/s10846-019-01106-x. [10] ACEVEDO J J, ARRUE B C, MAZA I, et al. A decentralized algorithm for area surveillance missions using a team of aerial robots with different sensing capabilities[C]. 2014 IEEE International Conference on Robotics and Automation (ICRA), HongKong, China, 2014: 4735–4740. doi: 10.1109/ICRA.2014.6907552. [11] SUN Yinjiang, ZHANG Rui, LIANG Wenbao, et al. Multi-agent cooperative search based on reinforcement learning[C]. 2020 3rd International Conference on Unmanned Systems (ICUS), Harbin, China, 2020: 891–896. doi: 10.1109/ICUS50048.2020.9275003. [12] CAI Junqi, PENG Zhihong, DING Shuxin, et al. Problem-specific multi-objective invasive weed optimization algorithm for reconnaissance mission scheduling problem[J]. Computers & Industrial Engineering, 2021, 157: 107345. doi: 10.1016/j.cie.2021.107345. [13] BHARATHI V and SAKTHIVEL K. Unmanned mobile robot in unknown obstacle environments for multi switching control tracking using adaptive nonlinear sliding mode control method[J]. Journal of Intelligent & Fuzzy Systems, 2022, 43(3): 3513–3525. doi: 10.3233/jifs-213588. [14] MIYAZAKI K, MATSUNAGA N, and MURATA K. Formation path learning for cooperative transportation of multiple robots using MADDPG[C]. The 21st International Conference on Control, Automation and Systems (ICCAS), Jeju, Korea, 2021: 1619–1623. [15] REZAEI S and BEHNAMIAN J. Benders decomposition-based particle swarm optimization for competitive supply networks with a sustainable multi-agent platform and virtual alliances[J]. Applied Soft Computing, 2022, 114: 107985. doi: 10.1016/j.asoc.2021.107985. [16] BOLSHAKOV V, ALFIMTSEV A, SAKULIN S, et al. Deep reinforcement ant colony optimization for swarm learning[C]. Advances in Neural Computation, Machine Learning, and Cognitive Research V, Moscow, Russia, 2022: 9–15. doi: 10.1007/978-3-030-91581-0_2. [17] SARTORETTI G, KERR J, SHI Yunfei, et al. PRIMAL: Pathfinding via reinforcement and imitation multi-agent learning[J]. IEEE Robotics and Automation Letters, 2019, 4(3): 2378–2385. doi: 10.1109/LRA.2019.2903261. [18] LIU Fen, YUAN Shenghai, MENG Wei, et al. Multiple noncooperative targets encirclement by relative distance-based positioning and neural antisynchronization control[J]. IEEE Transactions on Industrial Electronics, 2024, 71(2): 1675–1685. doi: 10.1109/tie.2023.3257364. [19] AHN K and PARK J. LPMARL: Linear programming based implicit task assignment for hierarchical multi-agent reinforcement learning[C]. The Eleventh International Conference on Learning Representations (ICLR 2023), Kigali, Rwanda 2023: 1–14. [20] ZHAO Fuqing, WANG Zhenyu, WANG Ling, et al. A multi-agent reinforcement learning driven artificial bee colony algorithm with the central controller[J]. Expert Systems with Applications, 2023, 219: 119672. doi: 10.1016/j.eswa.2023.119672. [21] SAYED A S, AMMAR H H, and SHALABY R. Centralized multi-agent mobile robots SLAM and navigation for COVID-19 field hospitals[C]. 2020 2nd Novel Intelligent and Leading Emerging Sciences Conference (NILES), Giza, Egypt, 2020: 444–449. doi: 10.1109/NILES50944.2020.9257919. [22] KOUZEGHAR M, SONG Y, MEGHJANI M, et al. Multi-target pursuit by a decentralized heterogeneous UAV swarm using deep multi-agent reinforcement learning[C]. 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 2023: 3289–3295. doi: 10.1109/ICRA48891.2023.10160919. [23] 姜奇, 蔡明鑫, 程庆丰, 等. 面向分层无人机网络的去中心群组密钥管理方案[J]. 电子与信息学报, 2023, 45(5): 1669–1677. doi: 10.11999/JEIT220347.JIANG Qi, CAI Mingxin, CHENG Qingfeng, et al. Decentralized group key management scheme in hierarchical unmanned aerial vehicle network[J]. Journal of Electronics & Information Technology, 2023, 45(5): 1669–1677. doi: 10.11999/ JEIT220347. doi: 10.11999/JEIT220347. [24] LIN Shiwei, LIU Ang, WANG Jianguo, et al. A review of path-planning approaches for multiple mobile robots[J]. Machines, 2022, 10(9): 773. doi: 10.3390/machines10090773. [25] KWA H L, KIT J L, and BOUFFANAIS R. Balancing collective exploration and exploitation in multi-agent and multi-robot systems: A review[J]. Frontiers in Robotics and AI, 2022, 8: 771520. doi: 10.3389/frobt.2021.771520. [26] LIU Qiang, HE Ming, XU Daqin, et al. A mechanism for recognizing and suppressing the emergent behavior of UAV swarm[J]. Mathematical Problems in Engineering, 2018, 2018: 6734923. doi: 10.1155/2018/6734923. [27] LIANG Dingkun, SUN Ning, WU Yiming, et al. Trajectory planning-based control of underactuated wheeled inverted pendulum robots[J]. Science China Information Sciences, 2019, 62(5): 50207. doi: 10.1007/s11432-018-9623-3. [28] LIU Yuanchang and BUCKNALL R. A survey of formation control and motion planning of multiple unmanned vehicles[J]. Robotica, 2018, 36(7): 1019–1047. doi: 10.1017/s0263574718000218. [29] ZHOU Panpan and CHEN B M. Distributed optimal solutions for multiagent pursuit-evasion games for capture and formation control[J]. IEEE Transactions on Industrial Electronics, 2023, 12(6): 1–10. doi: 10.1109/tie.2023.3283684. [30] MOORTHY S and JOO Y H. Distributed leader-following formation control for multiple nonholonomic mobile robots via bioinspired neurodynamic approach[J]. Neurocomputing, 2022, 492: 308–321. doi: 10.1016/j.neucom.2022.04.001. [31] 张泽锡, 钟文健, 林柏梁. 带时间窗的卡车编队路径优化[J]. 交通运输系统工程与信息, 2022, 22(5): 253–263. doi: 10.16097/j.cnki.1009-6744.2022.05.026.ZHANG Zexi, ZHONG Wenjian, and LIN Bailiang. Optimization of truck platooning routing with time windows[J]. Journal of Transportation Systems Engineering and Information Technology, 2022, 22(5): 253–263. doi: 10.16097/j.cnki.1009-6744.2022.05.026. [32] ZHANG Jingtao, XU Zhipeng, YU Fangchao, et al. A fully distributed multi-robot navigation method without pre-allocating target positions[J]. Autonomous Robots, 2021, 45(4): 473–492. doi: 10.1007/s10514-021-09981-w. [33] SARKAR R, BARMAN D, and CHOWDHURY N. Domain knowledge based genetic algorithms for mobile robot path planning having single and multiple targets[J]. Journal of King Saud University - Computer and Information Sciences, 2022, 34(7): 4269–4283. doi: 10.1016/j.jksuci.2020.10.010. [34] FARIDI A Q, SHARMA S, SHUKLA A, et al. Multi-robot multi-target dynamic path planning using artificial bee colony and evolutionary programming in unknown environment[J]. Intelligent Service Robotics, 2018, 11(2): 171–186. doi: 10.1007/s11370-017-0244-7. [35] 赵明明, 李彬, 王敏立. 不确定信息下基于拍卖算法的多无人机同时到达攻击多目标[J]. 电光与控制, 2015, 22(2): 89–93. doi: 10.3969/j.issn.1671-637X.2015.02.020.ZHAO Mingming, LI Bin, and WANG Minli. Auction algorithm based multi-UAV arriving simultaneously to attack multiple targets with uncertain information[J]. Electronics Optics & Control, 2015, 22(2): 89–93. doi: 10.3969/j.issn.1671-637X.2015.02.020. [36] BAREA A, URRUTXUA H, and CADARSO L. Large-scale object selection and trajectory planning for multi-target space debris removal missions[J]. Acta Astronautica, 2020, 170: 289–301. doi: 10.1016/j.actaastro.2020.01.032. [37] LIN Jie, MORSE A S, and ANDERSON B D O. The multi-agent rendezvous problem[C]. 42nd IEEE International Conference on Decision and Control (IEEE Cat. No. 03ch37475), Maui, USA, 2003: 1508–1513. [38] LI Yongqi, LI Shengquan, ZHANG Yumei, et al. Dynamic route planning for a USV-UAV multi-robot system in the rendezvous task with obstacles[J]. Journal of Intelligent & Robotic Systems, 2023, 107(4): 52. doi: 10.1007/s10846-023-01830-5. [39] SKEIK O, HU Junyan, ARVIN F, et al. Cooperative control of integrator negative imaginary systems with application to rendezvous multiple mobile robots[C]. 12th International Workshop on Robot Motion and Control (RoMoCo), Poznan, Poland, 2019: 15–20. doi: 10.1109/RoMoCo.2019.8787358. [40] SHAO Zhuang, YAN Fei, ZHOU Zhou, et al. Path planning for multi-UAV formation rendezvous based on distributed cooperative particle swarm optimization[J]. Applied Sciences, 2019, 9(13): 2621. doi: 10.3390/app9132621. [41] DONG Yi and HUANG Jie. A leader-following rendezvous problem of double integrator multi-agent systems[J]. Automatica, 2013, 49(5): 1386–1391. doi: 10.1016/j.automatica. 2013.02.024. [42] SZŐTS J and HARMATI I. Optimal strategies of a pursuit-evasion game with three pursuers and one superior evader[J]. Robotics and Autonomous Systems, 2023, 161: 104360. doi: 10.1016/j.robot.2022.104360. [43] ZHANG Leiming, PROROK A, and BHATTACHARYA S. Multi-agent pursuit-evasion under uncertainties with redundant robot assignments: Extended abstract[C]. 2019 International Symposium on Multi-Robot and Multi-Agent Systems (MRS), New Brunswick, USA, 2019: 92–94. doi: 10.1109/MRS.2019.8901055. [44] SUN Zhiyuan, SUN Hanbing, LI Ping, et al. Cooperative strategy for pursuit-evasion problem in the presence of static and dynamic obstacles[J]. Ocean Engineering, 2023, 279: 114476. doi: 10.1016/j.oceaneng.2023.114476. [45] ZHANG Tianle, LIU Zhen, PU Zhiqiang, et al. Multi-target encirclement with collision avoidance via deep reinforcement learning using relational graphs[C]. 2022 IEEE International Conference on Robotics and Automation (ICRA), Philadelphia, USA, 2022: 8794–8800. doi: 10.1109/ICRA46639.2022.9812151. [46] GAO Yan, BAI Chenggang, ZHANG Lei, et al. Multi-UAV cooperative target encirclement within an annular virtual tube[J]. Aerospace Science and Technology, 2022, 128: 107800. doi: 10.1016/j.ast.2022.107800. [47] 宁宇铭, 李团结, 姚聪, 等. 基于快速扩展随机树―贪婪边界搜索的多机器人协同空间探索方法[J]. 机器人, 2022, 44(6): 708–719. doi: 10.13973/j.cnki.robot.210318.NING Yuming, LI Tuanjie, YAO Cong, et al. Multi-robot cooperative space exploration method based on rapidly-exploring random trees and greedy frontier-based exploration[J]. Robot, 2022, 44(6): 708–719. doi: 10.13973/j.cnki.robot.210318. [48] PAEZ D, ROMERO J P, NORIEGA B, et al. Distributed particle swarm optimization for multi-robot system in search and rescue operations[J]. IFAC-PapersOnLine, 2021, 54(4): 1–6. doi: 10.1016/j.ifacol.2021.10.001. [49] YE Sean, NATARAJAN M, WU Zixuan, et al. Diffusion based multi-agent adversarial tracking[J]. arXiv: 2307.06244, 2023. [50] ZHOU Wenhong, LI Jie, LIU Zhihong, et al. Improving multi-target cooperative tracking guidance for UAV swarms using multi-agent reinforcement learning[J]. Chinese Journal of Aeronautics, 2022, 35(7): 100–112. doi: 10.1016/j.cja.2021.09.008. [51] SUN Qinpeng, WANG Zhonghua, LI Meng, et al. Path tracking control of wheeled mobile robot based on improved pure pursuit algorithm[C]. 2019 Chinese Automation Congress (CAC), Hangzhou, China, 2019: 4239–4244. doi: 10.1109/CAC48633.2019.8997258. [52] JIA Qingyong, XU Hongli, FENG Xisheng, et al. A novel cooperative pursuit strategy in multiple underwater robots[C]. OCEANS 2019-Marseille, Marseille, France, 2019: 1–8. doi: 10.1109/OCEANSE.2019.8867227. [53] MA Junchong, YAO Weijia, DAI Wei, et al. Cooperative encirclement control for a group of targets by decentralized robots with collision avoidance[C]. The 37th Chinese Control Conference (CCC), Wuhan, China, 2018: 6848–6853. doi: 10.23919/ChiCC.2018.8483768. [54] ZHANG Fei, SHAO Xingling, XIA Yi, et al. Elliptical encirclement control capable of reinforcing performances for UAVs around a dynamic target[J]. Defence Technology, 2023, 3(13): 1–16. doi: 10.1016/j.dt.2023.03.014. [55] YAMAGUCHI H. A cooperative hunting behavior by mobile-robot troops[J]. The International Journal of Robotics Research, 1999, 18(9): 931–940. doi: 10.1177/02783649922066664. [56] YANG Aiwu, LIANG Xiaolong, HOU Yueqi, et al. An autonomous cooperative interception method with angle constraints using a swarm of UAVs[J]. IEEE Transactions on Vehicular Technology, 2023, 25(6): 1–14. doi: 10.1109/tvt.2023.3298635. [57] JAIN P and PETERSON C K. Encirclement of moving targets using relative range and bearing measurements[C]. 2019 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, USA, 2019: 43–50. doi: 10.1109/ICUAS.2019.8798252. [58] FANG Xu, WANG Chen, XIE Lihua, et al. Cooperative pursuit with multi-pursuer and one faster free-moving evader[J]. IEEE Transactions on Cybernetics, 2022, 52(3): 1405–1414. doi: 10.1109/TCYB.2019.2958548. [59] SHOME R, SOLOVEY K, DOBSON A, et al. dRRT*: Scalable and informed asymptotically-optimal multi-robot motion planning[J]. Autonomous Robots, 2020, 44(3/4): 443–467. doi: 10.1007/s10514-019-09832-9. [60] SONG Hui, JIA Minghan, LIAN Yihang, et al. UAV path planning based on improved ant colony algorithm[J]. Journal of Electronic Research and Application, 2017, 6(2): 10–25. doi: 10.1117/12.2678893. [61] DAHL T S, MATARIĆ M, and SUKHATME G S. Multi-robot task allocation through vacancy chain scheduling[J]. Robotics and Autonomous Systems, 2009, 57(6/7): 674–687. doi: 10.1016/j.robot.2008.12.001. [62] GONZÁLEZ-SIERRA J, FLORES-MONTES D, HERNANDEZ-MARTINEZ E G, et al. Robust circumnavigation of a heterogeneous multi-agent system[J]. Autonomous Robots, 2021, 45(2): 265–281. doi: 10.1007/s10514-020-09962-5. [63] HUANG Heyuan, KANG Yu, WANG Xiaolu, et al. Multi-robot collision avoidance based on buffered voronoi diagram[C]. 2022 International Conference on Machine Learning and Knowledge Engineering (MLKE), Guilin, China, 2022: 227–235. doi: 10.1109/mlke55170.2022.00051. [64] YAO Weijia, LU Huimin, ZENG Zhiwen, et al. Distributed static and dynamic circumnavigation control with arbitrary spacings for a heterogeneous multi-robot system[J]. Journal of Intelligent & Robotic Systems, 2019, 94(3/4): 883–905. doi: 10.1007/s10846-018-0906-5. [65] LIU Shuang and SUN Dong. Leader–follower-based dynamic trajectory planning for multirobot formation[J]. Robotica, 2013, 31(8): 1351–1359. doi: 10.1017/s0263574713000490. [66] WANG Yuanda, DONG Lu, and SUN Changyin. Cooperative control for multi-player pursuit-evasion games with reinforcement learning[J]. Neurocomputing, 2020, 412: 101–114. doi: 10.1016/j.neucom.2020.06.031. [67] ZHAO Zhenyi, HU Qiao, FENG Haobo, et al. A cooperative hunting method for multi-AUV swarm in underwater weak information environment with obstacles[J]. Journal of Marine Science and Engineering, 2022, 10(9): 1266. doi: 10.3390/jmse10091266. [68] MARINO A, PARKER L E, ANTONELLI G, et al. A decentralized architecture for multi-robot systems based on the null-space-behavioral control with application to multi-robot border patrolling[J]. Journal of Intelligent & Robotic Systems, 2013, 71(3): 423–444. doi: 10.1007/s10846-012-9783-5. [69] NI Jianjun, YANG Liu, WU Liuying, et al. An improved spinal neural system-based approach for heterogeneous AUVs cooperative hunting[J]. International Journal of Fuzzy Systems, 2018, 20(2): 672–686. doi: 10.1007/s40815-017-0395-x. [70] ZHENG Yanbin, FAN Wenxin, and HAN Mengyun. Research on multi-agent collaborative hunting algorithm based on game theory and Q-learning for a single escaper[J]. Journal of Intelligent & Fuzzy Systems, 2021, 40(1): 205–219. doi: 10.3233/JIFS-191222. [71] ZHONG Yun, YAO Peiyang, SUN Yu, et al. Method of multi-UAVs cooperative search for markov moving targets[C]. 2017 29th Chinese Control And Decision Conference (CCDC), Chongqing, China, 2017: 6783–6789. doi: 10.1109/CCDC.2017.7978400. [72] OLOFSSON J, HENDEBY G, LAUKNES T R, et al. Multi-agent informed path planning using the probability hypothesis density[J]. Autonomous Robots, 2020, 44(6): 913–925. doi: 10.1007/s10514-020-09904-1. [73] LEONARDOS S, OVERMAN W, PANAGEAS I, et al. Global convergence of multi-agent policy gradient in markov potential games[C]. The Tenth International Conference on Learning Representations, 2021. doi: 10.48550/arXiv.2106.01969. [74] ZHU Xudong, ZHANG Fan, and LI Hui. Swarm deep reinforcement learning for robotic manipulation[J]. Procedia Computer Science, 2022, 198: 472–479. doi: 10.1016/j.procs.2021.12.272. [75] ZHANG Zheng, WANG Xiaohan, ZHANG Qingrui, et al. Multi-robot cooperative pursuit via potential field-enhanced reinforcement learning[C]. 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, USA, 2022: 8808–8814. doi: 10.1109/ICRA46639.2022.9812083. [76] HU Jian, HU Siyue, and LIAO S W. Policy regularization via noisy advantage values for cooperative multi-agent actor-critic methods[J]. arXiv: 2106.14334, 2021. [77] 李瑞珍, 杨惠珍, 萧丛杉. 基于动态围捕点的多机器人协同策略[J]. 控制工程, 2019, 26(3): 510–514. doi: 10.14107/j.cnki.kzgc.161174.LI Ruizhen, YANG Huizhen, and XIAO Congshan. Cooperative hunting strategy for multi-mobile robot systems based on dynamic hunting points[J]. Control Engineering of China, 2019, 26(3): 510–514. doi: 10.14107/j.cnki.kzgc.161174. [78] OLSEN T, STIFFLER N M, and O’KANE J M. Rapid recovery from robot failures in multi-robot visibility-based pursuit-evasion[C]. 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 2021: 9734–9741. doi: 10.1109/IROS51168.2021.9636141. [79] ZHANG Wenyu, GAI Jingyao, ZHANG Zhigang, et al. Double-DQN based path smoothing and tracking control method for robotic vehicle navigation[J]. Computers and Electronics in Agriculture, 2019, 166: 104985. doi: 10.1016/j.compag.2019.104985. [80] QADIR M Z, PIAO Songhao, JIANG Haiyang, et al. A novel approach for multi-agent cooperative pursuit to capture grouped evaders[J]. The Journal of Supercomputing, 2020, 76(5): 3416–3426. doi: 10.1007/s11227-018-2591-3. [81] DE SOUZA C, NEWBURY R, COSGUN A, et al. Decentralized multi-agent pursuit using deep reinforcement learning[J]. IEEE Robotics and Automation Letters, 2021, 6(3): 4552–4559. doi: 10.1109/lra.2021.3068952. [82] ZHAO Liran, ZHANG Yulin, and DANG Zhaohui. PRD-MADDPG: An efficient learning-based algorithm for orbital pursuit-evasion game with impulsive maneuvers[J]. Advances in Space Research, 2023, 72(2): 211–230. doi: 10.1016/j.asr.2023.03.014. [83] QI Qi, ZHANG Xuebo, and GUO Xian. A deep reinforcement learning approach for the pursuit evasion game in the presence of obstacles[C]. 2020 IEEE International Conference on Real-time Computing and Robotics (RCAR), Asahikawa, Japan, 2020: 68–73. doi: 10.1109/RCAR49640.2020.9303044. [84] LIU Bingyan, YE Xiongbing, DONG Xianzhou, et al. Branching improved deep q networks for solving pursuit-evasion strategy solution of spacecraft[J]. Journal of Industrial and Management Optimization, 2022, 18(2): 1223–1245. doi: 10.3934/jimo.2021016. [85] ZHU Jiagang, ZOU Wei, and ZHU Zheng. Learning evasion strategy in pursuit-evasion by deep Q-network[C]. 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 2018: 67–72. doi: 10.1109/ICPR.2018.8546182. [86] GU Shanzhi, GENG Mingyang, and LAN Long. Attention-based fault-tolerant approach for multi-agent reinforcement learning systems[J]. Entropy, 2021, 23(9): 1133. doi: 10.3390/e23091133. [87] XU Lin, HU Bin, GUAN Zhihong, et al. Multi-agent deep reinforcement learning for pursuit-evasion game scalability[C]. Proceedings of 2019 Chinese Intelligent Systems Conference, Singapore, 2020: 658–669. doi: 10.1007/978-981-32-9682-4_69. [88] WAN Kaifang, WU Dingwei, ZHAI Yiwei, et al. An improved approach towards multi-agent pursuit-evasion game decision-making using deep reinforcement learning[J]. Entropy, 2021, 23(11): 1433. doi: 10.3390/e23111433. [89] HAMED O and HAMLICH M. Hybrid formation control for multi-robot hunters based on multi-agent deep deterministic policy gradient[J]. MENDEL, 2021, 27(2): 23–29. doi: 10.13164/mendel.2021.2.023. [90] 马俊冲. 基于多机器人系统的多目标围捕协同控制问题研究[D]. [硕士论文], 国防科技大学, 2018.MA Junchong. Research on encirclement control for a group of targets by multi-robot system[D]. [Master dissertation], National University of Defense Technology, 2018. [91] ZUO Renwei, LI Yinghui, LV Maolong, et al. Learning-based distributed containment control for HFV swarms under event-triggered communication[J]. IEEE Transactions on Aerospace and Electronic Systems, 2023, 59(1): 568–579. doi: 10.1109/TAES.2022.3185969. [92] SUN Lijun, CHANG Yucheng, LYU Chao, et al. Toward multi-target self-organizing pursuit in a partially observable markov game[J]. Information Sciences, 2023, 648: 119475. doi: 10.1016/j.ins.2023.119475. [93] DONG Haotian and XI Junqiang. Model predictive longitudinal motion control for the unmanned ground vehicle with a trajectory tracking model[J]. IEEE Transactions on Vehicular Technology, 2022, 71(2): 1397–1410. doi: 10.1109/TVT.2021.3131314. [94] XIAO Zongxin, HU Minghui, FU Chunyun, et al. Model predictive trajectory tracking control of unmanned vehicles based on radial basis function neural network optimisation[J]. Proceedings of the Institution of Mechanical Engineers, Part D: Journal of Automobile Engineering, 2023, 237(2/3): 347–361. doi: 10.1177/09544070221080158. [95] İŞCI H and GÜNEL G Ö. Fuzzy logic based air-to-air combat algorithm for unmanned air vehicles[J]. International Journal of Dynamics and Control, 2022, 10(1): 230–242. doi: 10.1007/s40435-021-00803-6. [96] LV Jiliang, QU Chenxi, DU Shaofeng, et al. Research on obstacle avoidance algorithm for unmanned ground vehicle based on multi-sensor information fusion[J]. Mathematical Biosciences and Engineering, 2021, 18(2): 1022–1039. doi: 10.3934/mbe.2021055. [97] LONG Qian, ZHOU Zihan, GUPTA A, et al. Evolutionary population curriculum for scaling multi-agent reinforcement learning[C]. 8th International Conference On Learning Representations, Addis Ababa, Ethiopia, 2020. -

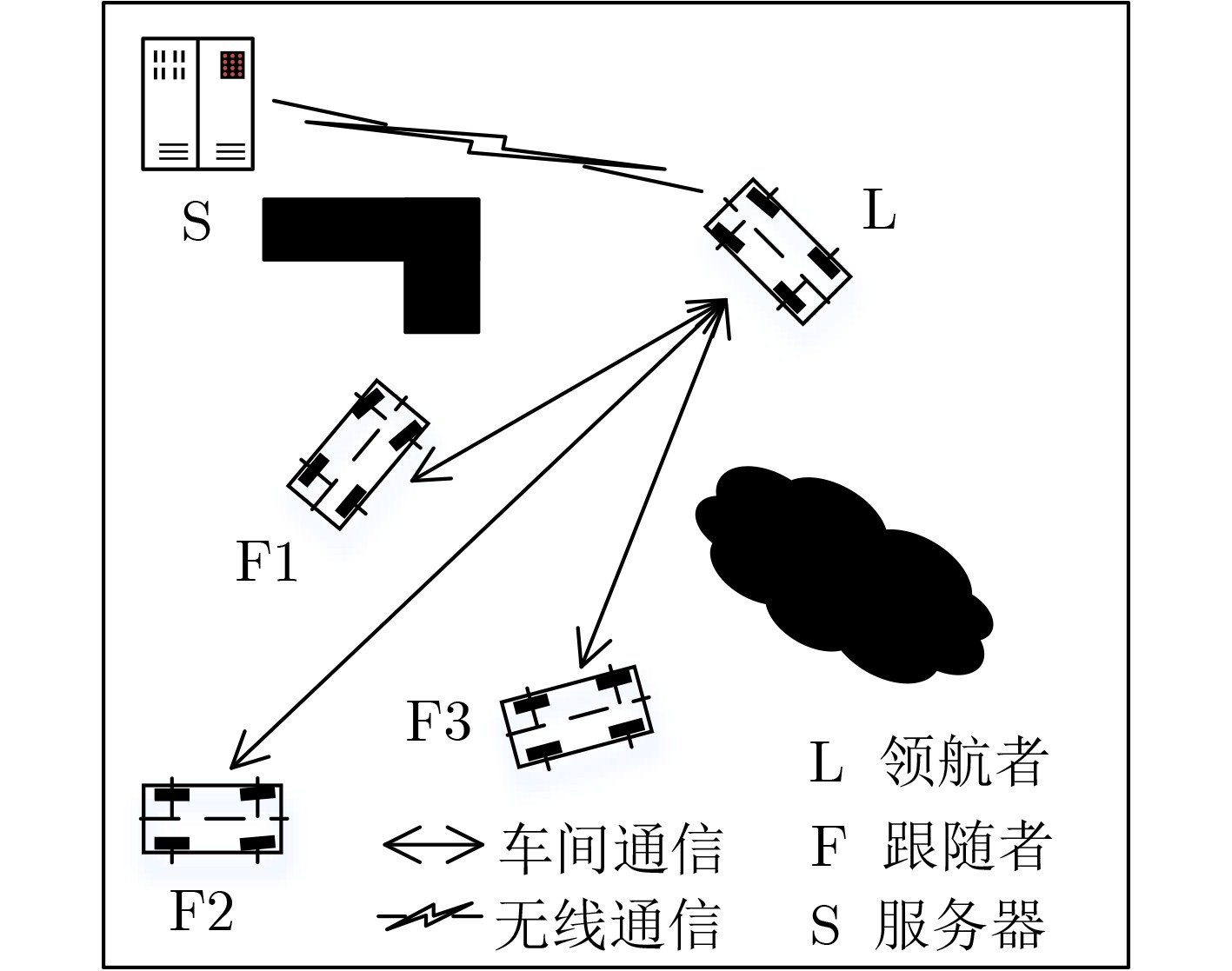
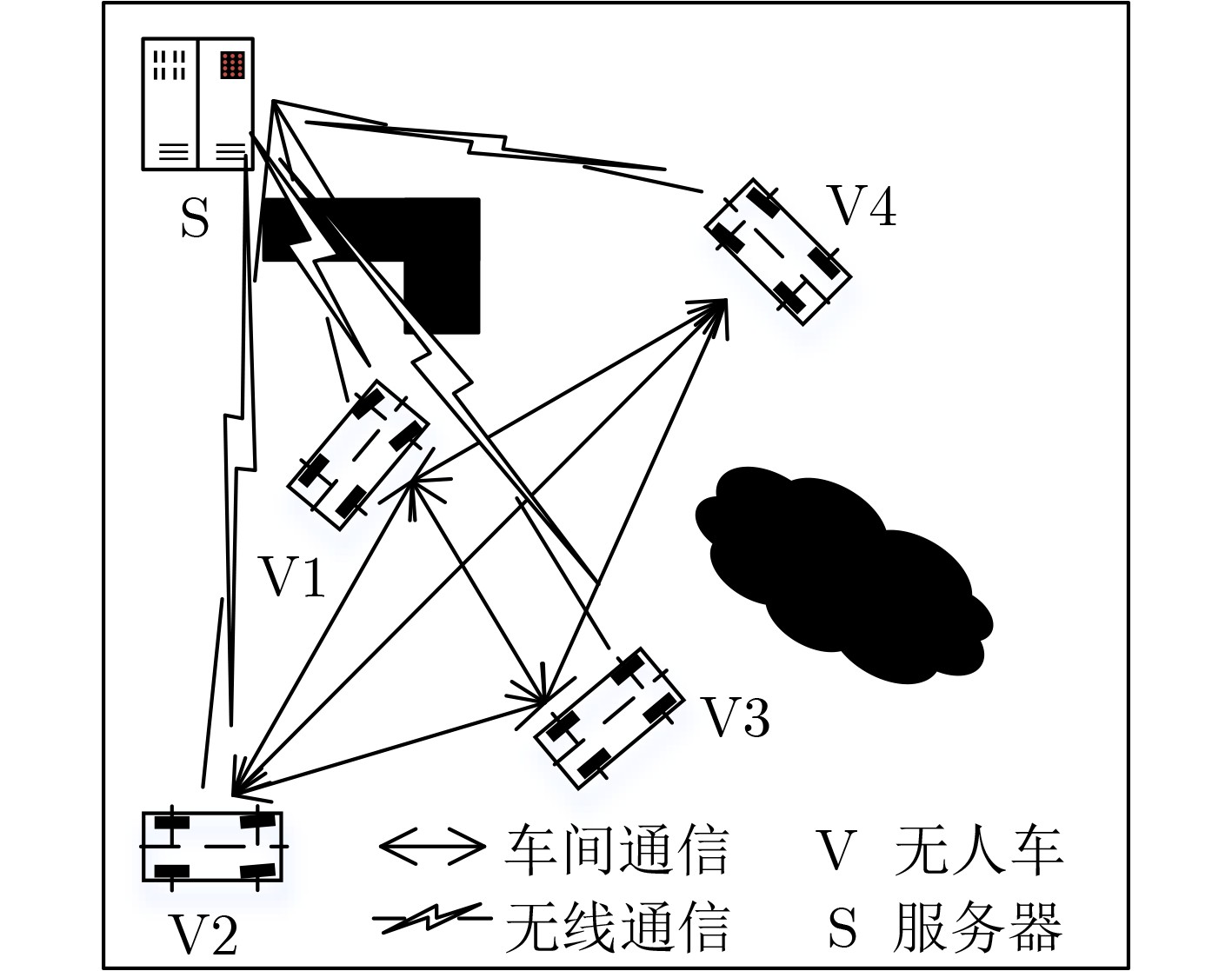
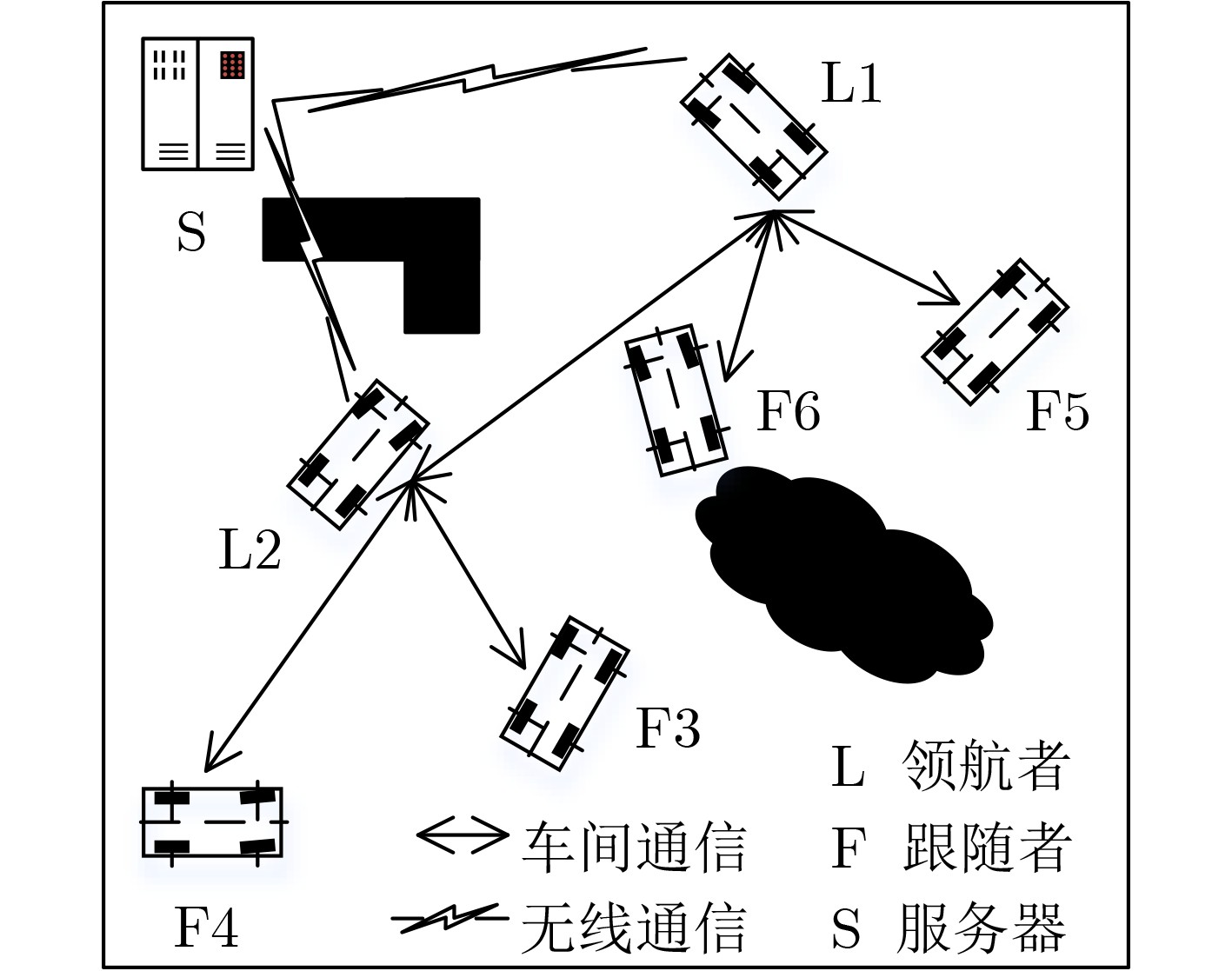
 下载:
下载:
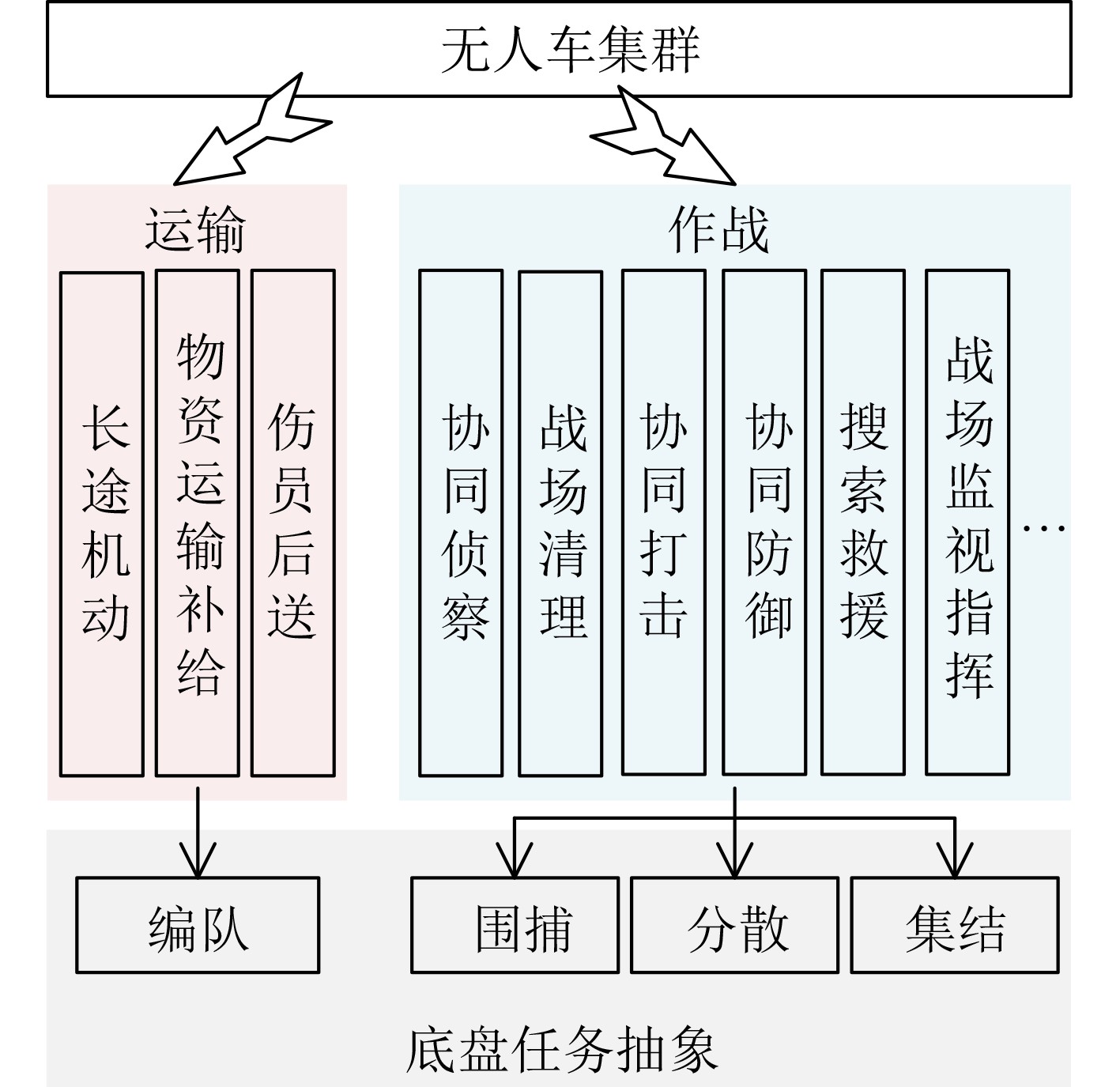
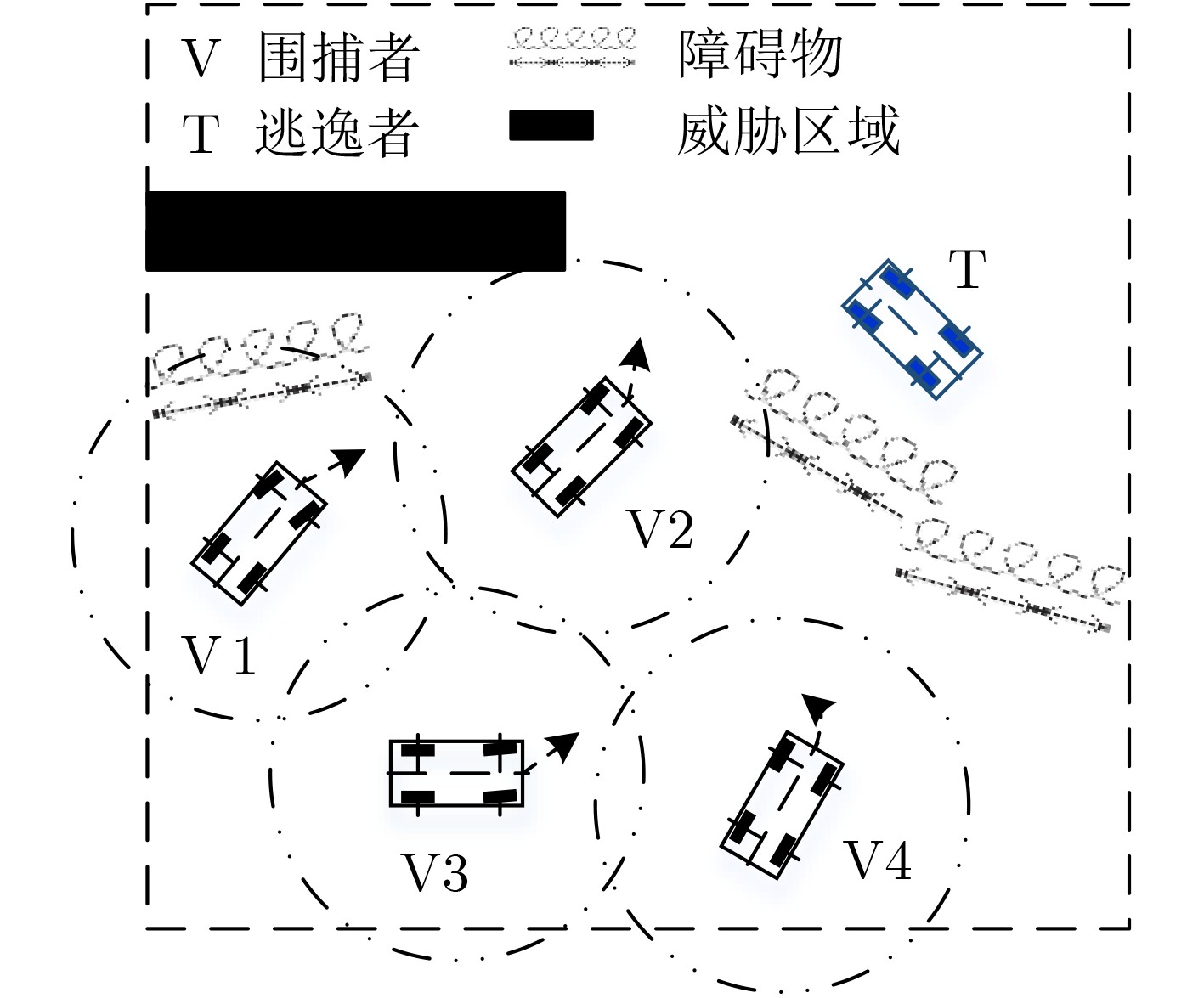
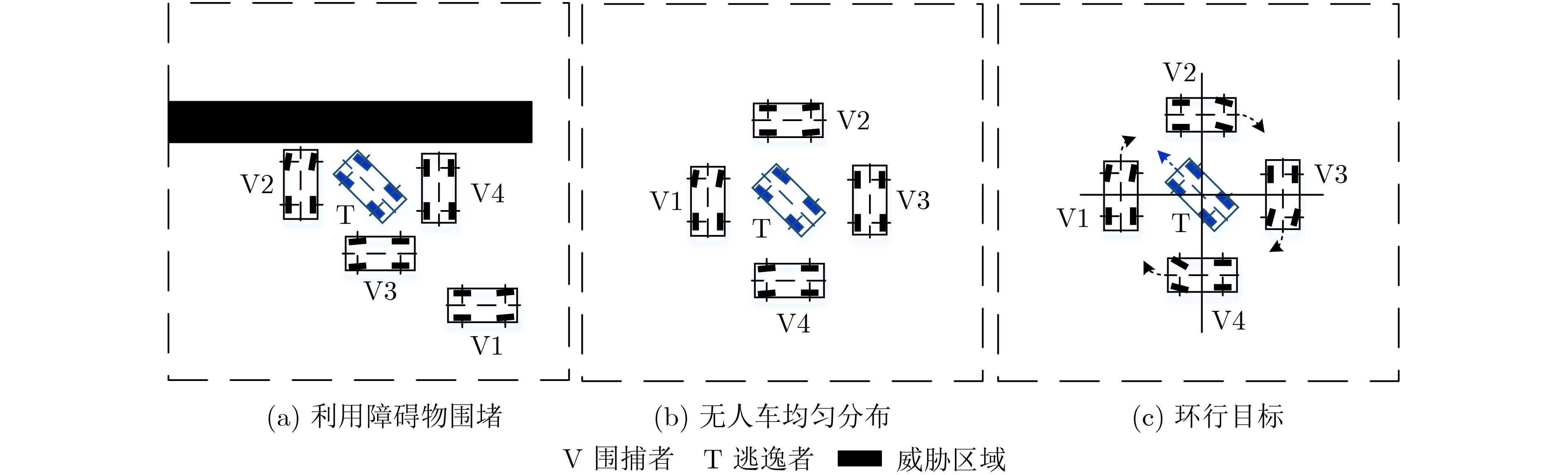


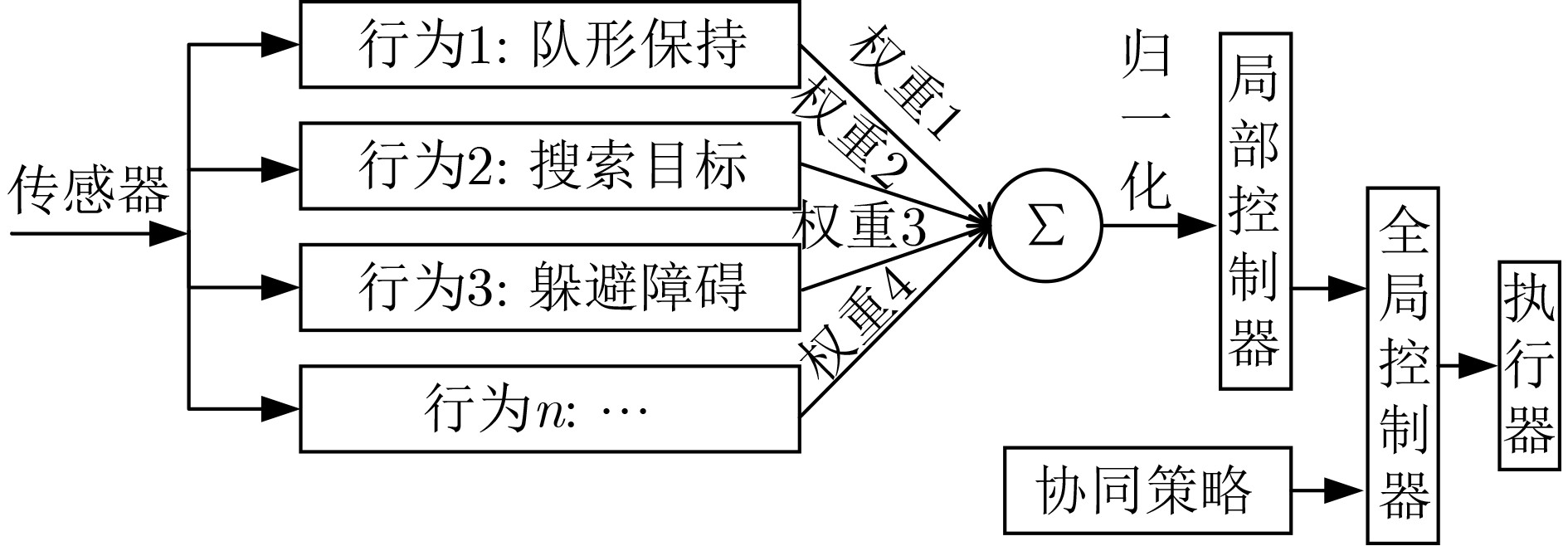
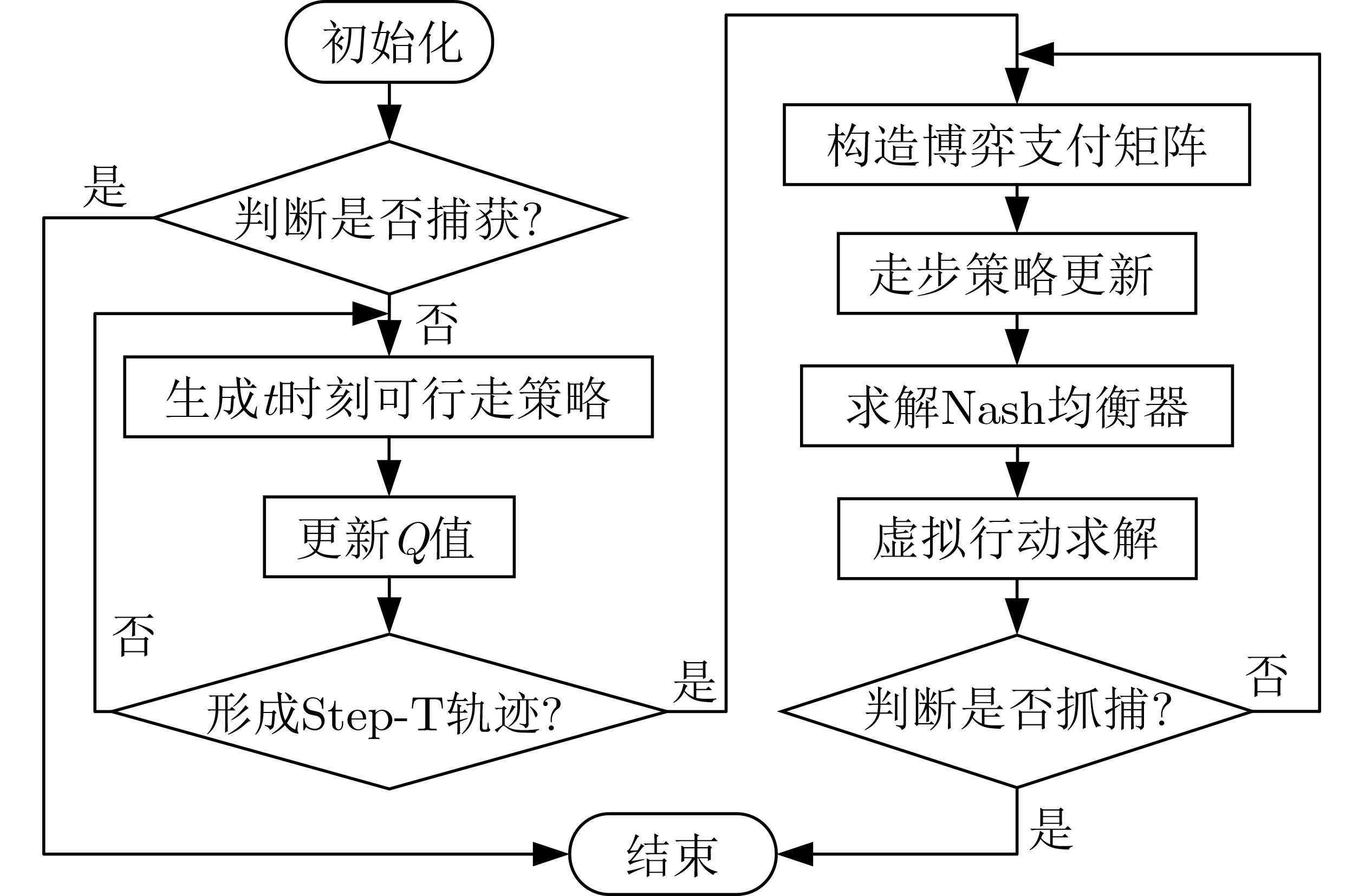


图(11) / 表(2)
计量
- 文章访问数: 2122
- HTML全文浏览量: 1232
- PDF下载量: 290
- 被引次数: 0
