

CL-YOLOv5: PET/CT Lung Cancer Detection With Cross-modal Lightweight YOLOv5 Model
-
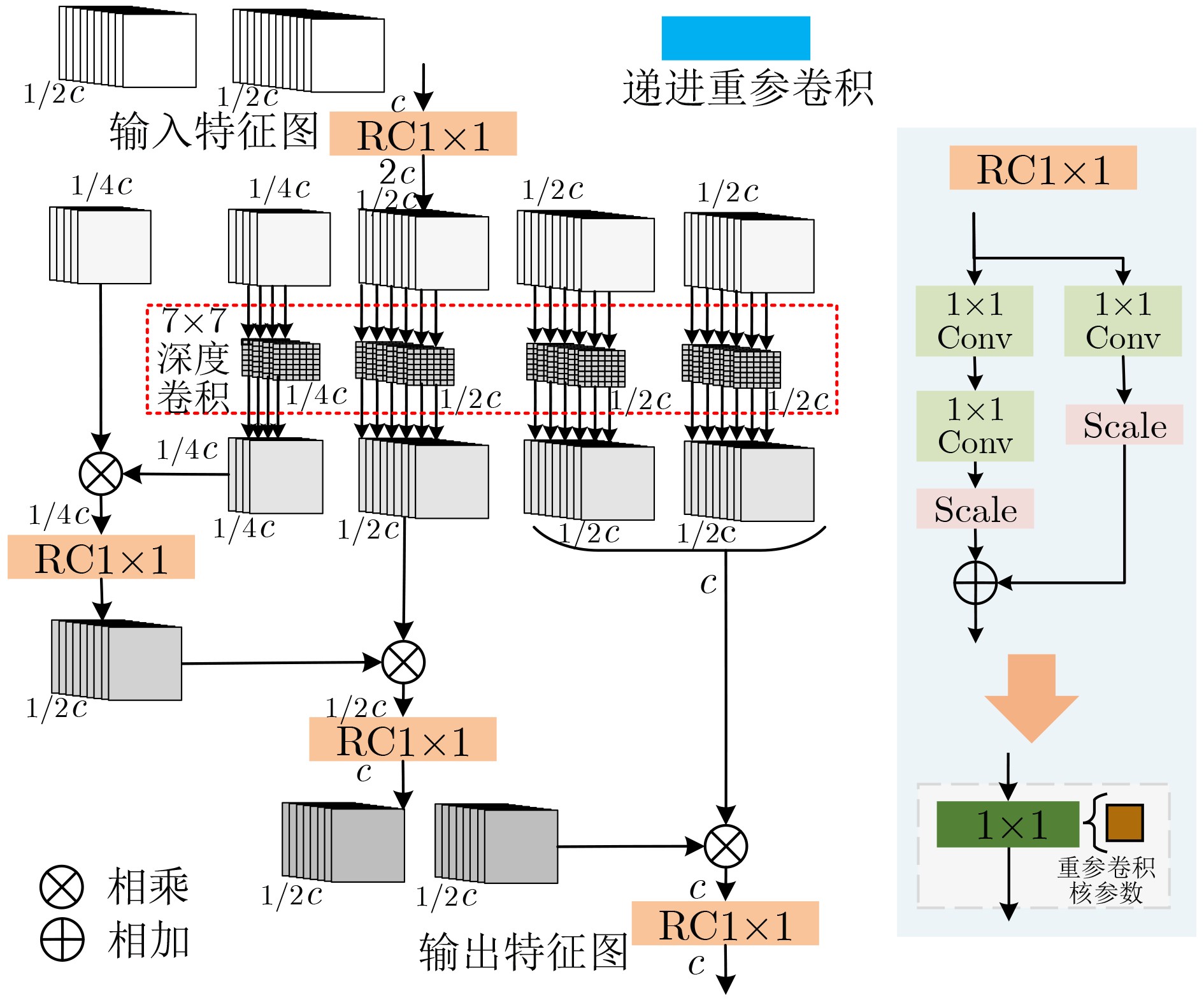
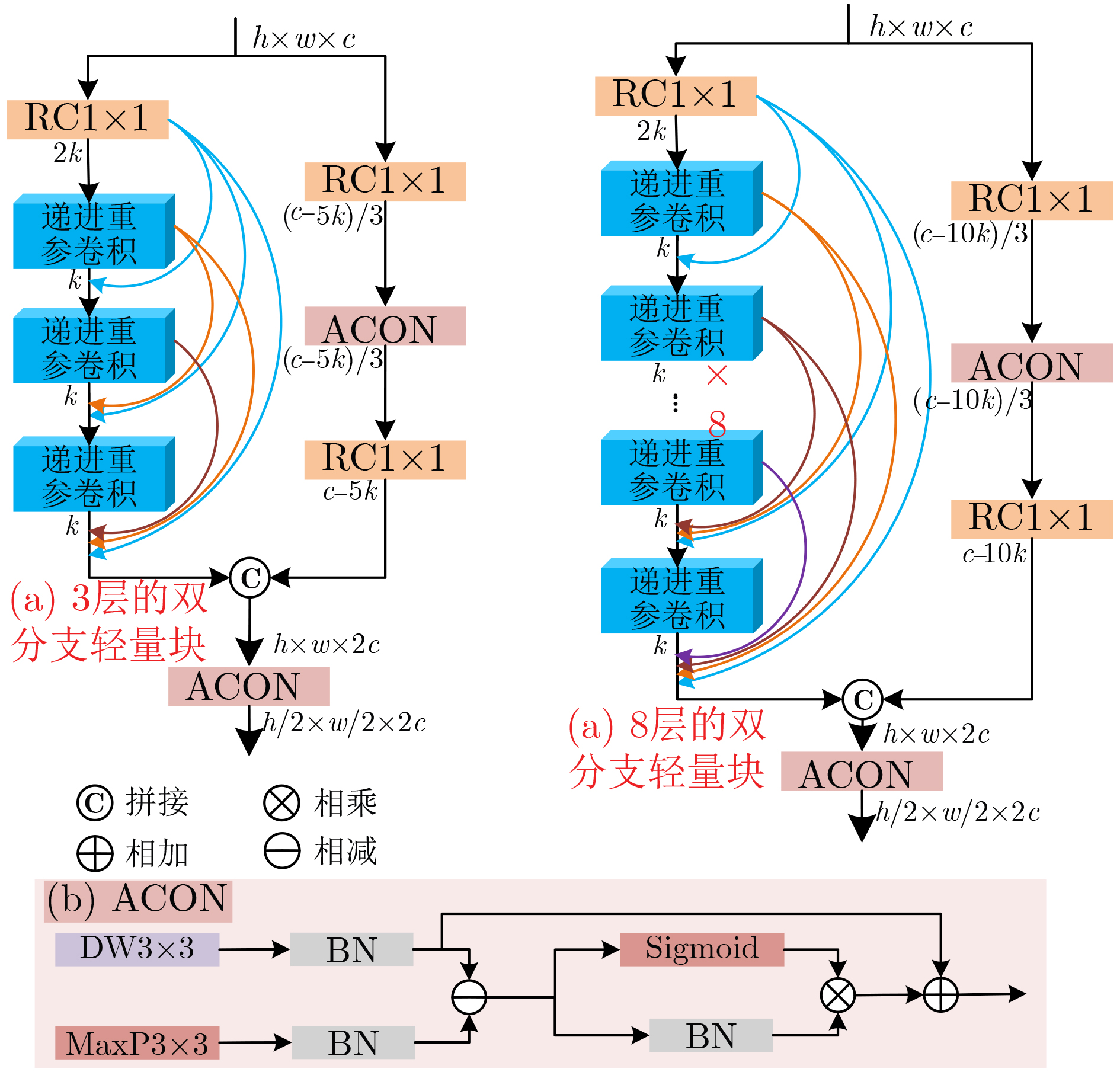
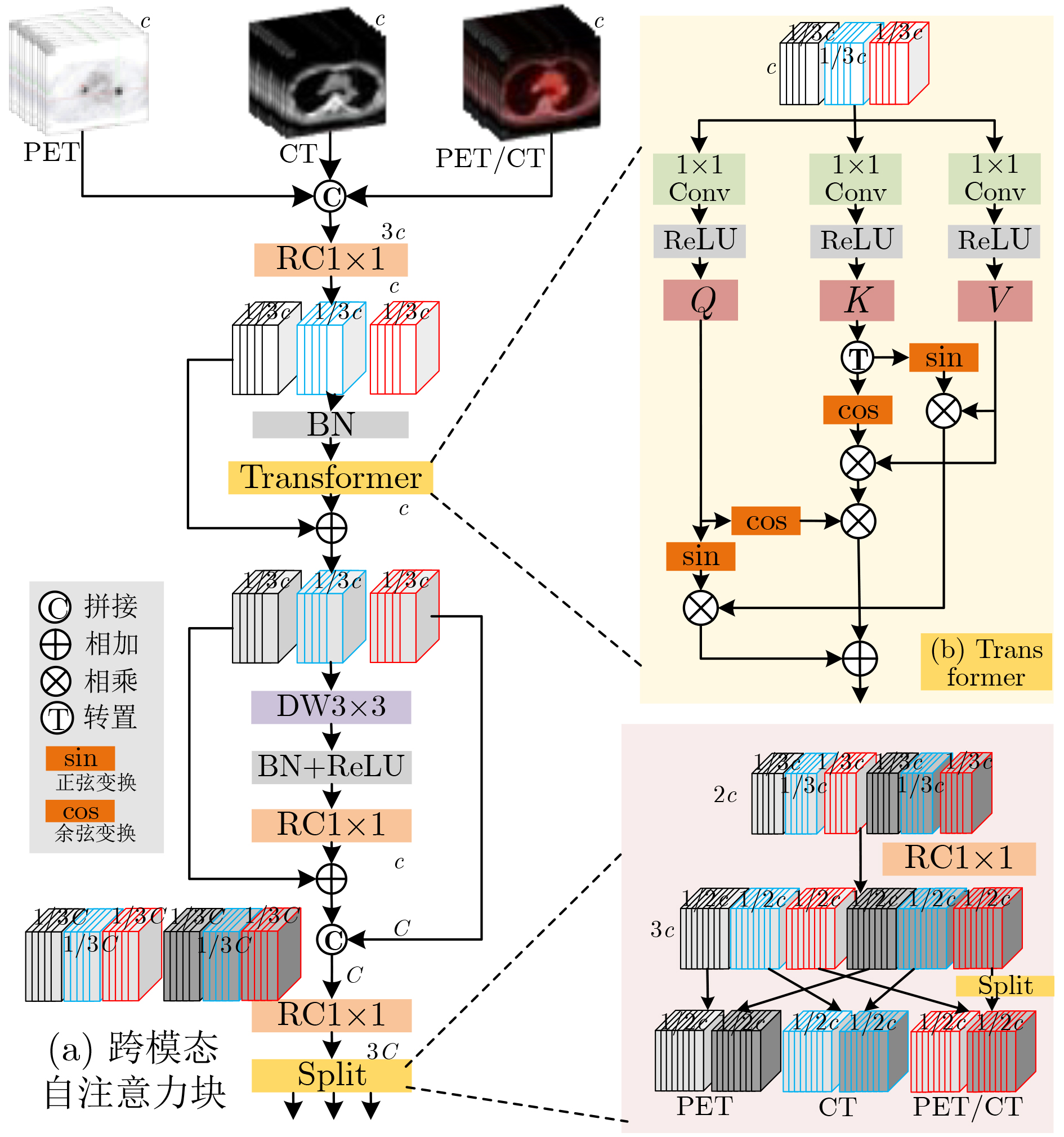
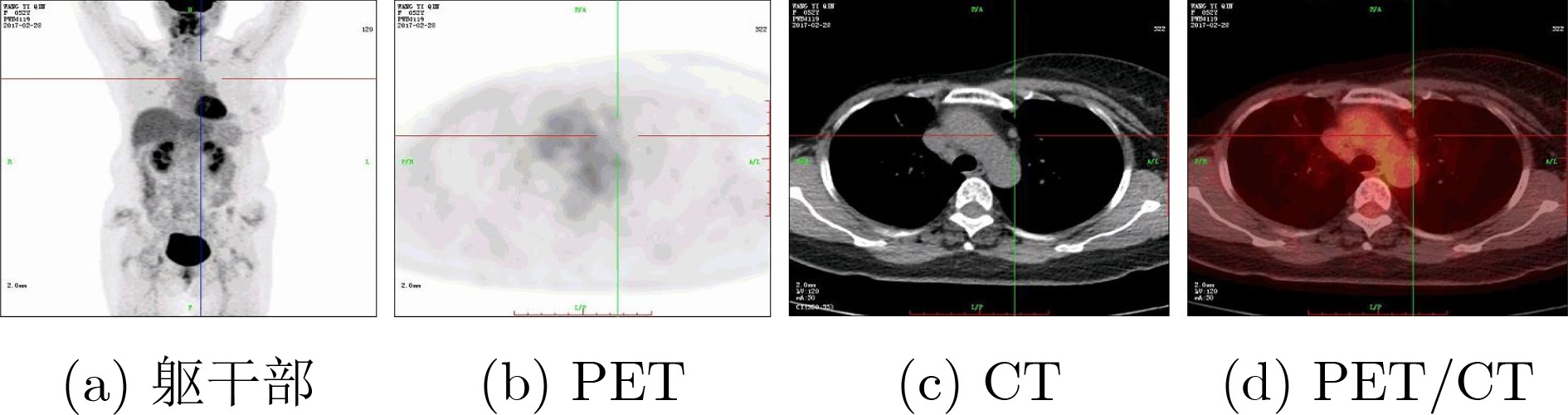
摘要: 多模态医学图像可在同一病灶处提供更多语义信息,针对跨模态语义相关性未充分考虑和模型复杂度过高的问题,该文提出基于跨模态轻量级YOLOv5(CL-YOLOv5)的肺部肿瘤检测模型。首先,提出学习正电子发射型断层显像(PET)、 计算机断层扫描(CT)和PET/CT不同模态语义信息的3分支网络;然后,设计跨模态交互式增强块充分学习多模态语义相关性,余弦重加权计算Transformer高效学习全局特征关系,交互式增强网络提取病灶的能力;最后,提出双分支轻量块, 激活函数簇(ACON)瓶颈结构降低参数同时增加网络深度和鲁棒性,另一分支为密集连接的递进重参卷积,特征传递达到最大化,递进空间交互高效地学习多模态特征。在肺部肿瘤PET/CT多模态数据集中,该文模型获得94.76% mAP最优性能和3238 s最高效率,以及0.81 M参数量,较YOLOv5s和EfficientDet-d0降低7.7倍和5.3倍,多模态对比实验中总体上优于现有的先进方法,消融实验和热力图可视化进一步验证。
-
关键词:
- YOLOv5 /
- 跨模态交互式增强块 /
- 双分支轻量块 /
- PET/CT多模态肺部肿瘤影像
Abstract: Multimodal medical images can provide more semantic information at the same lesion. To address the problems that cross-modal semantic features are not fully considered and model complexity is too high, a Cross-modal Lightweight YOLOv5(CL-YOLOv5) lung cancer detection model is proposed. Firstly, three-branch network is proposed to learn semantic information of Positron Emission Tomography (PET), Computed Tomography (CT) and PET/CT; Secondly, Cross-modal Interactive Enhancement block is designed to fully learn multimodal semantic correlation, cosine reweighted Transformer efficiently learns global feature relationship, interactive enhancement network extracts lesion features; Finally, dual-branch lightweight block is proposed, ACtivate Or Not (ACON) bottleneck structure reduces parameters while increasing network depth and robustness, the other branch is densely connected recursive re-parametric convolution with maximized feature transfer, recursive spatial interaction efficiently learning multimodal features. In lung cancer PET/CT multimodal dataset, the model in this paper achieves 94.76% mAP optimal performance and 3238 s highest efficiency, 0.81 M parameters are obtained, which is 7.7 times and 5.3 times lower than YOLOv5s and EfficientDet-d0, overall outperforms existing state-of-the-art methods in multimodal comparative experiments. In multi-modal comparison experiment, it is generally better than the existing advanced methods, further verification by ablation experiments and heat map visualization ablation experiment. -
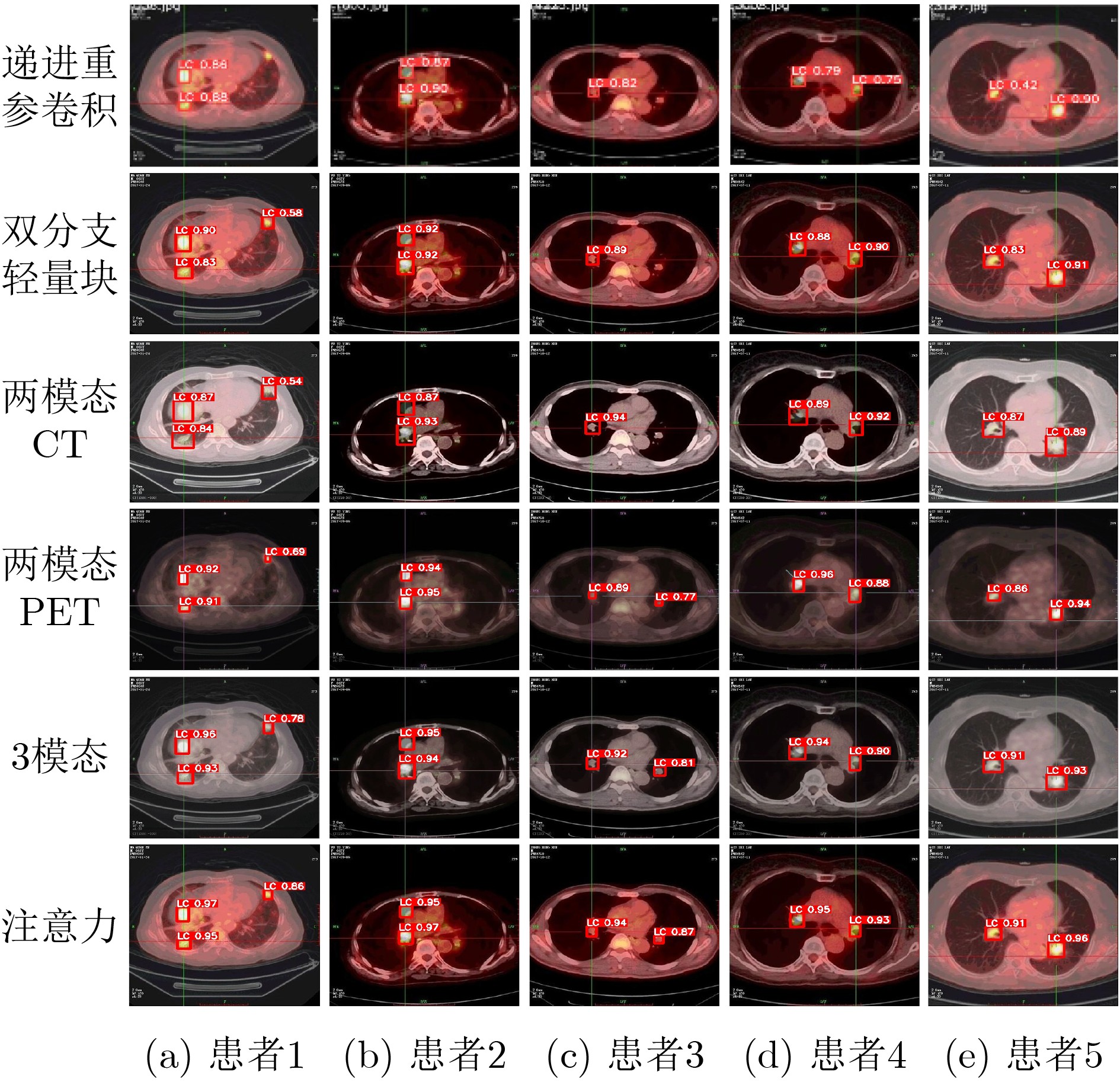
表 1 在肺部肿瘤PET/CT多模态数据集上的消融实验对比结果
实验 添加的模块 参数量 计算量 精度 召回率 mAP F1 FPS 总时间(s) – YOLOv5s 7.06M 5.24G 0.9416±1.2 0.8965±1.4 0.9221±1.5 0.9185±1.4 102.63 3661 1 +递进重参卷积 2.77M 2.23G 0.9514±1.2 0.9108±1.3 0.9402±1.4 0.9306±1.3 124.15 3457 2 +双分支轻量块 473.09K 310.69M 0.9566±1.1 0.9160±1.2 0.9448±1.3 0.9359±1.2 149.34 3049 3 +两模态CT 717.04K 600.92M 0.9609±1.1 0.9186±1.2 0.9486±1.2 0.9393±1.2 141.50 3215 4 +两模态PET 717.04K 600.92M 0.9595±1.1 0.9326±1.0 0.9507±1.1 0.9458±1.1 143.13 3169 5 +3模态 717.04K 600.92M 0.9652±0.9 0.9354±0.9 0.9558±1.0 0.9501±0.9 142.35 3182 6 注意力 814.39K 673.06M 0.9729±0.7 0.9476±0.8 0.9651±0.7 0.9603±0.7 138.47 3238  下载: 导出CSV
下载: 导出CSV
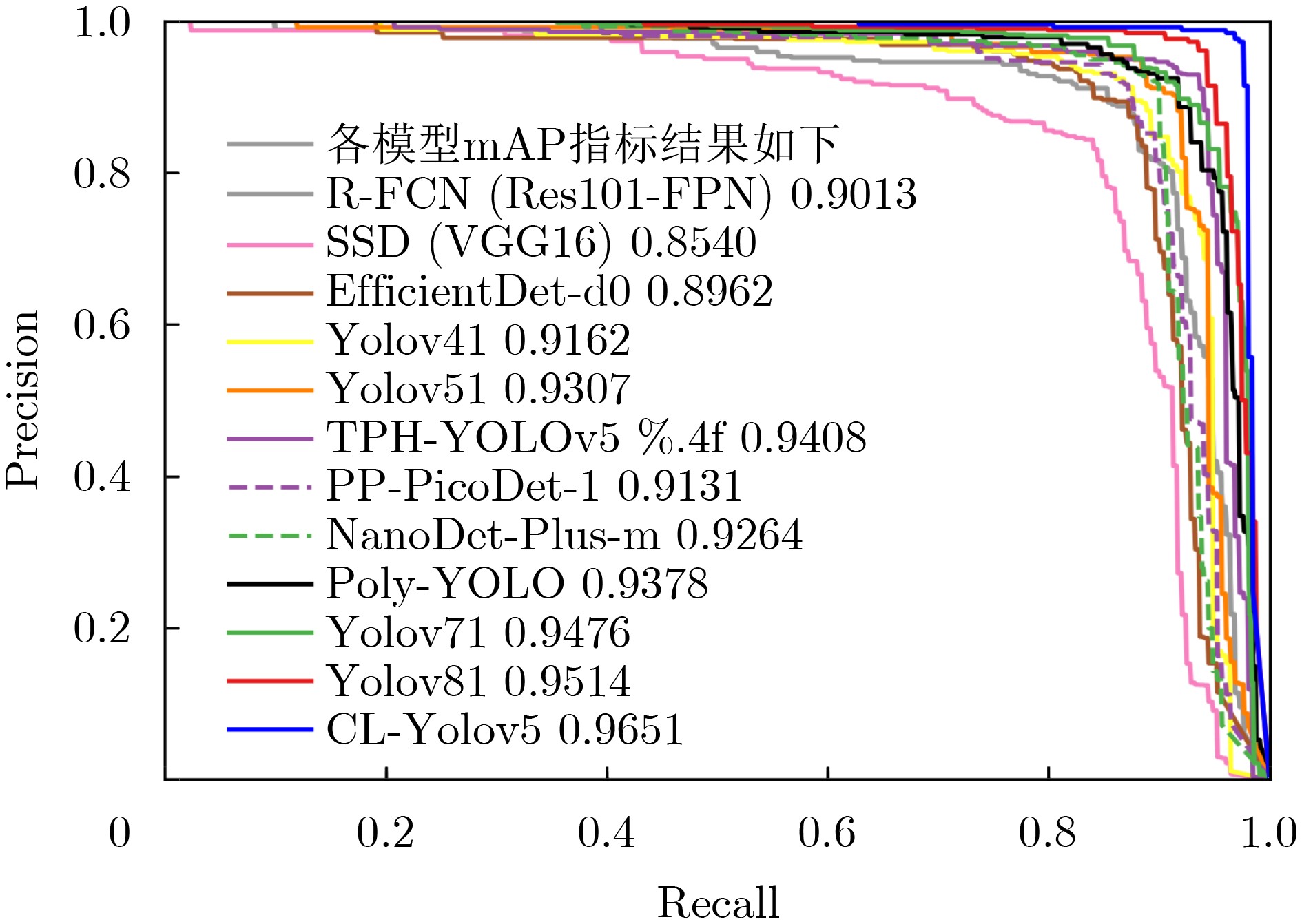
表 2 不同模型在肺部肿瘤PET/CT多模态数据集上的对比结果
检测模型 参数量 计算量 精度 召回率 mAP F1 FPS 总时间(s) R-FCN(Res101-FPN)[2] 50.80M 60.51G 0.8947±1.2 0.8839±1.4 0.9013±1.5 0.8893±1.4 15.33 8010 SSD512(VGG16)[2] 23.75M 87.63G 0.8467±1.6 0.8398±2.1 0.8540±2.1 0.8433±2.0 34.62 4133 EfficientDet-d0[18] 4.31M 2.58G 0.8934±1.3 0.8719±1.5 0.8962±1.7 0.8825±1.5 26.24 4474 YOLOv4l[4] 63.96M 45.28G 0.9374±1.1 0.8926±1.4 0.9162±1.5 0.9146±1.4 63.99 5516 YOLOv5l[5] 46.65M 36.56G 0.9495±1.1 0.8968±1.3 0.9307±1.3 0.9244±1.3 71.94 4968 TPH-YOLOv5[19] 40.83M 36.26G 0.9523±1.2 0.9142±1.3 0.9408±1.4 0.9329±1.3 38.78 6795 PP-PicoDet-l[3] 1.18M 4.59G 0.9342±1.4 0.8873±1.7 0.9131±1.8 0.9101±1.6 109.55 3601 NanoDet-Plus-m[20] 1.19M 1.20G 0.9431±1.3 0.8987±1.6 0.9264±1.6 0.9204±1.5 117.18 3435 Poly-YOLO[4] 6.16M 7.01G 0.9478±1.1 0.9101±1.4 0.9378±1.4 0.9286±1.3 69.12 4491 YOLOv7l[5] 37.19M 33.64G 0.9558±0.9 0.9237±1.2 0.9476±1.2 0.9395±1.2 73.81 4712 YOLOv8l[19] 43.63M 52.93G 0.9592±0.9 0.9287±1.1 0.9514±1.2 0.9437±1.1 56.12 5956 CL-YOLOv5 0.81M 0.67G 0.9729±0.7 0.9476±0.8 0.9651±0.7 0.9603±0.7 138.47 3238
下载: 导出CSV
-
[1] MIRANDA D, THENKANIDIYOOR V, and DINESH D A. Review on approaches to concept detection in medical images[J]. Biocybernetics and Biomedical Engineering, 2022, 42(2): 453–462. doi: 10.1016/j.bbe.2022.02.012. [2] 周涛, 刘赟璨, 陆惠玲, 等. ResNet及其在医学图像处理领域的应用: 研究进展与挑战[J]. 电子与信息学报, 2022, 44(1): 149–167. doi: 10.11999/JEIT210914.ZHOU Tao, LIU Yuncan, LU Huiling, et al. ResNet and its application to medical image processing: Research progress and challenges[J]. Journal of Electronics &Information Technology, 2022, 44(1): 149–167. doi: 10.11999/JEIT210914. [3] YU Guanghua, CHANG Qinyao, LV Wengyu, et al. PP-PicoDet: A better real-time object detector on mobile devices[J]. arXiv: 2111.00902, 2021. [4] HURTIK P, MOLEK V, HULA J, et al. Poly-YOLO: Higher speed, more precise detection and instance segmentation for YOLOv3[J]. Neural Computing and Applications, 2022, 34(10): 8275–8290. doi: 10.1007/s00521-021-05978-9. [5] WANG C Y, BOCHKOVSKIY A, and LIAO H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[J]. arXiv: 2207.02696, 2022. [6] 刘政怡, 段群涛, 石松, 等. 基于多模态特征融合监督的RGB-D图像显著性检测[J]. 电子与信息学报, 2020, 42(4): 997–1004. doi: 10.11999/JEIT190297.LIU Zhenyi, DUAN Quntao, SHI Song, et al. RGB-D image saliency detection based on multi-modal feature-fused supervision[J]. Journal of Electronics &Information Technology, 2020, 42(4): 997–1004. doi: 10.11999/JEIT190297. [7] ASVADI A, GARROTE L, PREMEBIDA C, et al. Real-time deep convnet-based vehicle detection using 3d-lidar reflection intensity data[C]. ROBOT 2017: Third Iberian Robotics Conference, Sevilla, Spain, 2017: 475–486. [8] YADAV R, VIERLING A, and BERNS K. Radar+ RGB fusion for robust object detection in autonomous vehicle[C]. The 2020 IEEE International Conference on Image Processing, Abu Dhabi, United Arab Emirates, 2020: 1986–1990. [9] QIAN Kun, ZHU Shilin, ZHANG Xinyu, et al. Robust multimodal vehicle detection in foggy weather using complementary Lidar and radar signals[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 444–453. [10] CHEN Yiting, SHI Jinghao, YE Zelin, et al. Multimodal object detection via probabilistic ensembling[C]. 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 139–158. [11] HERMESSI H, MOURALI O, and ZAGROUBA E. Multimodal medical image fusion review: Theoretical background and recent advances[J]. Signal Processing, 2021, 183: 108036. doi: 10.1016/j.sigpro.2021.108036. [12] MOKNI R, GARGOURI N, DAMAK A, et al. An automatic computer-aided diagnosis system based on the multimodal fusion of breast cancer (MF-CAD)[J]. Biomedical Signal Processing and Control, 2021, 69: 102914. doi: 10.1016/j.bspc.2021.102914. [13] RUBINSTEIN E, SALHOV M, NIDAM-LESHEM M, et al. Unsupervised tumor detection in dynamic PET/CT imaging of the prostate[J]. Medical Image Analysis, 2019, 55: 27–40. doi: 10.1016/j.media.2019.04.001. [14] MING Yue, DONG Xiying, ZHAO Jihuai, et al. Deep learning-based multimodal image analysis for cervical cancer detection[J]. Methods, 2022, 205: 46–52. doi: 10.1016/j.ymeth.2022.05.004. [15] QIN Ruoxi, WANG Zhenzhen, JIANG Lingyun, et al. Fine-grained lung cancer classification from PET and CT images based on multidimensional attention mechanism[J]. Complexity, 2020, 2020: 6153657. doi: 10.1155/2020/6153657. [16] DIRKS I, KEYAERTS M, NEYNS B, et al. Computer-aided detection and segmentation of malignant melanoma lesions on whole-body 18F-FDG PET/CT using an interpretable deep learning approach[J]. Computer Methods and Programs in Biomedicine, 2022, 221: 106902. doi: 10.1016/j.cmpb.2022.106902. [17] CAO Siyuan, YU Beinan, LUO Lun, et al. PCNet: A structure similarity enhancement method for multispectral and multimodal image registration[J]. Information Fusion, 2023, 94: 200–214. doi: 10.1016/j.inffus.2023.02.004. [18] TAN Mingxing, PANG Ruoming, and LE Q V. EfficientDet: Scalable and efficient object detection[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 10778–10787. [19] LI Chuyi, LI Lulu, GENG Yifei, et al. YOLOv6 v3.0: A full-scale reloading[J]. arXiv: 2301.05586, 2023. [20] LI Dongyang and ZHAI Junyong. A real-time vehicle window positioning system based on nanodet[C]. 2022 Chinese Intelligent Systems Conference, Singapore, 2022: 697–705. -


 下载:
下载:





图(10) / 表(3)
计量
- 文章访问数: 1904
- HTML全文浏览量: 1003
- PDF下载量: 188
- 被引次数: 0
