

Text-to-image Generation Model Based on Diffusion Wasserstein Generative Adversarial Networks
-
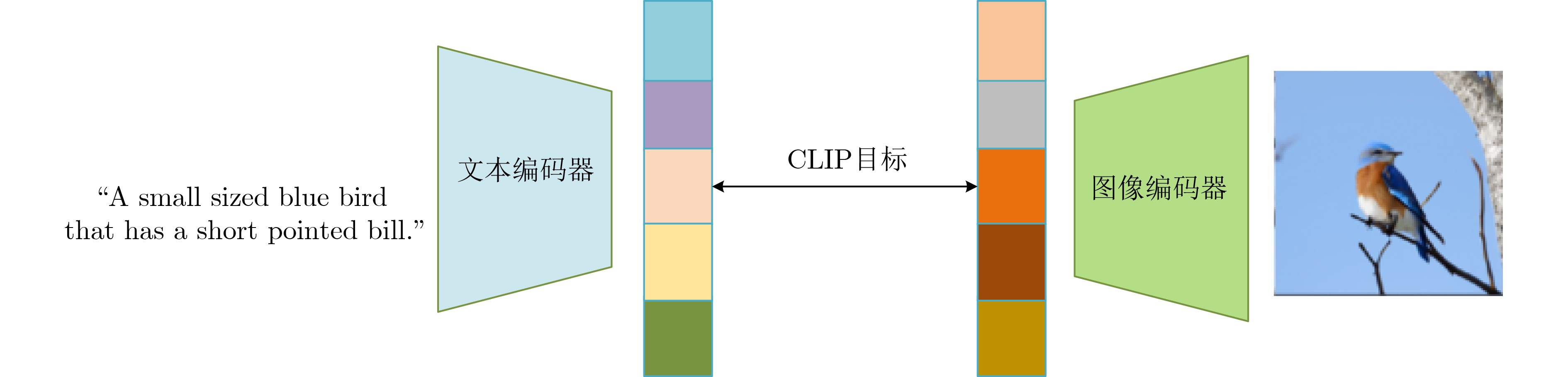
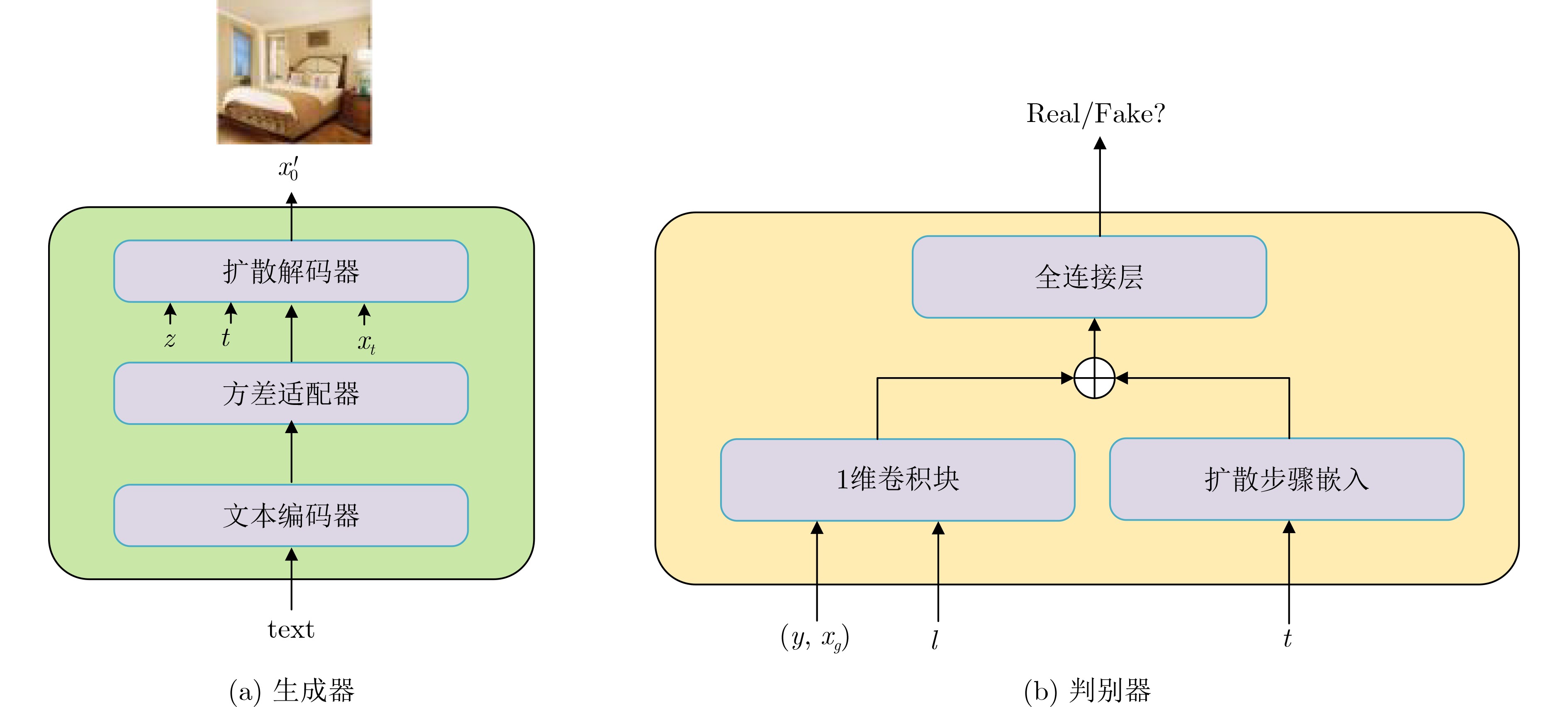
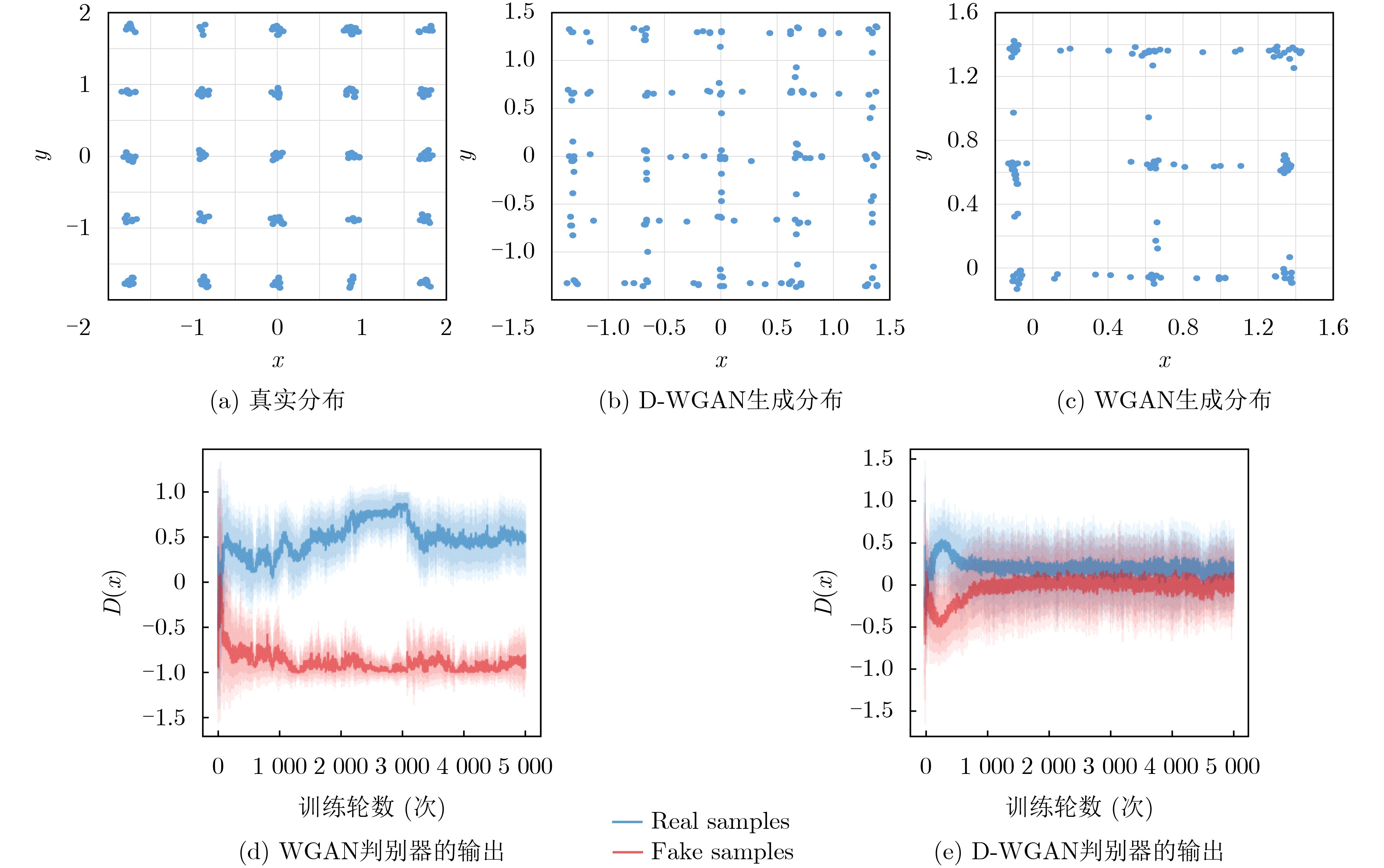
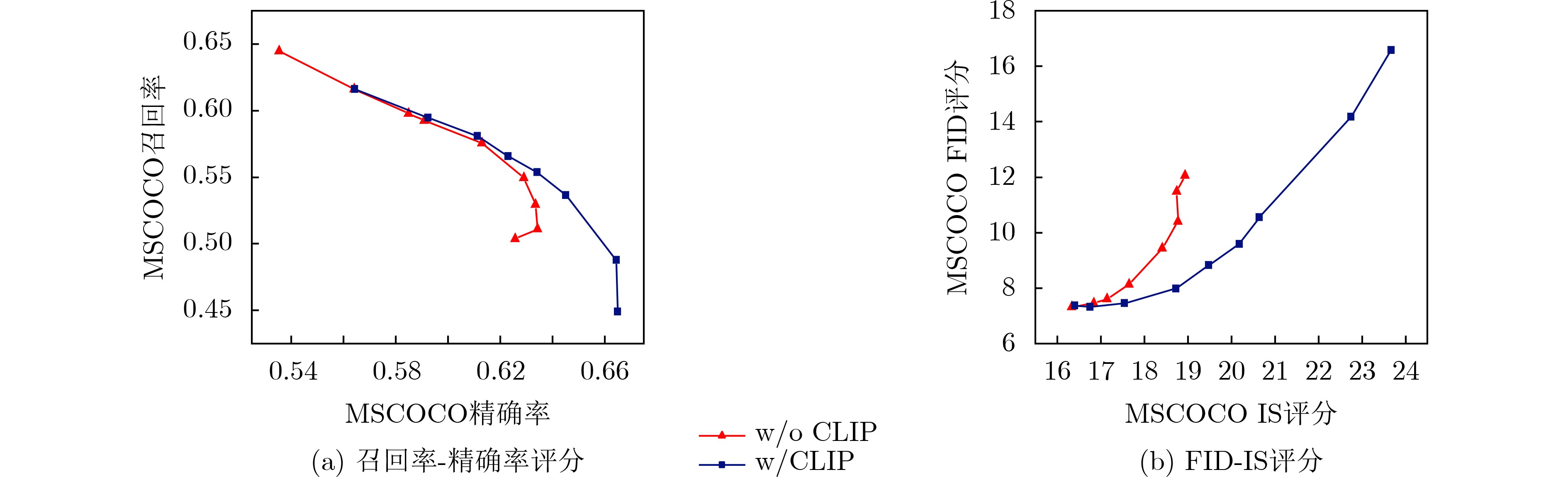
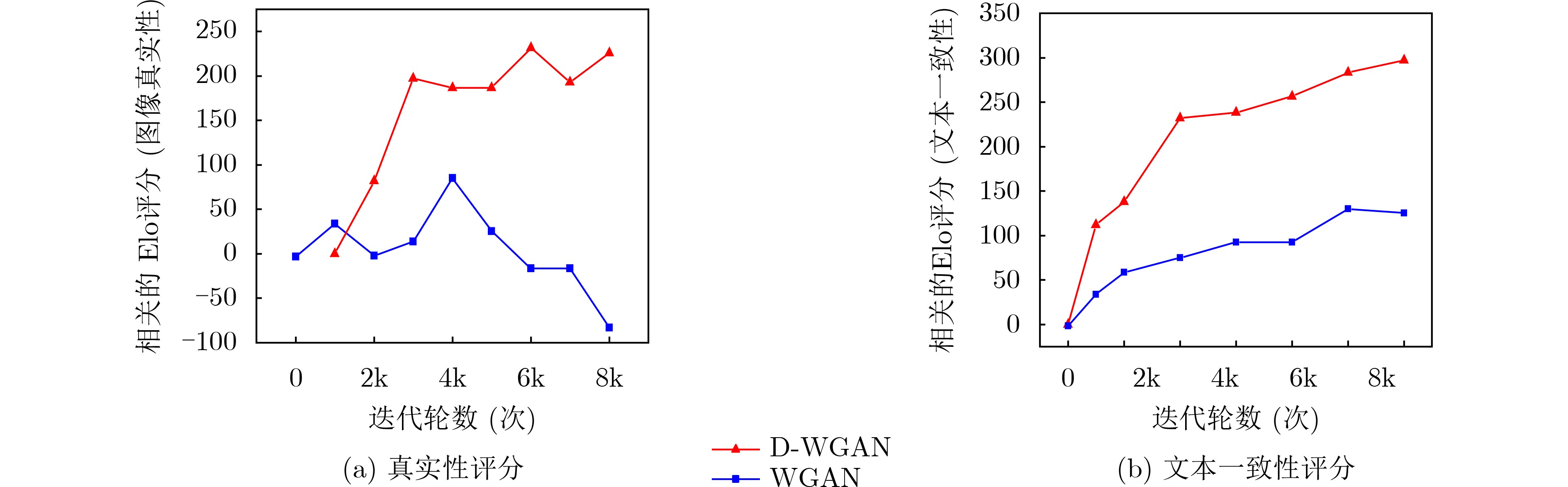
摘要: 文本生成图像是一项结合计算机视觉(CV)和自然语言处理(NLP)领域的综合性任务。以生成对抗网络(GANs)为基础的方法在文本生成图像方面取得了显著进展,但GANs方法的模型存在训练不稳定的问题。为解决这一问题,该文提出一种基于扩散Wasserstein生成对抗网络(WGAN)的文本生成图像模型(D-WGAN)。在D-WGAN中,利用向判别器中输入扩散过程中随机采样的实例噪声,在实现模型稳定训练的同时,生成高质量和多样性的图像。考虑到扩散过程的采样成本较高,引入一种随机微分的方法,以简化采样过程。为了进一步对齐文本与图像的信息,提出使用基于对比学习的语言-图像预训练模型(CLIP)获得文本与图像信息之间的跨模态映射关系,从而提升文本和图像的一致性。在MSCOCO,CUB-200数据集上的实验结果表明,D-WGAN在实现稳定训练的同时,与当前最好的方法相比,FID分数分别降低了16.43%和1.97%,IS分数分别提升了3.38%和30.95%,说明D-WGAN生成的图像质量更高,更具有实用价值。
-
关键词:
- 文本生成图像 /
- 生成对抗网络 /
- 扩散过程 /
- 对比学习的语言-图像预训练模型 /
- 语义匹配
Abstract: Text-to-image generation is a comprehensive task that combines the fields of Computer Vision (CV) and Natural Language Processing (NLP). Research on the methods of text to image based on Generative Adversarial Networks (GANs) continues to grow in popularity and have made some progress, but the methods of GANs model suffer from training instability. To address this problem, a text-to-image generation model based on Diffusion Wasserstein Generative Adversarial Networks (D-WGAN) is proposed, which generates high quality and diverse images and enables stable training process by feeding randomly sampled instance noise from the diffusion process into the discriminator. Considering the high cost of sampling the diffusion process, a stochastic differentiation method is introduced to simplify the sampling process. In order to align further the information of text and image, Contrastive Language-Image Pre-training (CLIP) model is introduced to obtain the cross-modal mapping relationship between text and image information, so as to improve the consistency of text and image. Experimental results on the MSCOCO and CUB-200 datasets show that D-WGAN achieves stable training while reducing Fréchet Inception Distance (FID) scores by 16.43% and 1.97%, respectively, and improving Inception Score (IS) scores by 3.38% and 30.95%, respectively. These results indicate that D-WGAN can generate higher quality images and has more practical value. -
表 2 不同模型的FID分数对比
模型 MSCOCO CUB-200 FID↓ IS↑ FID↓ IS↑ StackGAN[12] 74.05 8.45±0.03 51.89 3.70±0.04 EFF-T2I[13] – – 11.17 4.23±0.05 AttnGAN[14] 35.49 25.83±0.47 23.98 4.36±0.03 DM-GAN [15] 32.64 30.49±0.57 16.09 4.75±0.07 DF-GAN[16] 24.24 – 14.81 5.10±0.05 DALLE[17] 27.50 17.90±0.03 56.10 – VLMGAN [18] 23.62 26.54±0.43 16.04 4.95±0.04 SSA-GAN [19] – – 16.58 5.17±0.08 D-WGAN 19.74 31.52±0.45 10.95 6.77±0.03  下载: 导出CSV
下载: 导出CSV
-
[1] GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial networks[J]. Communications of the ACM, 2020, 63(11): 139–144. doi: 10.1145/3422622 [2] 李云红, 朱绵云, 任劼, 等. 改进深度卷积生成式对抗网络的文本生成图像[J/OL]. 北京航空航天大学学报. http://kns.cnki.net/kcms/detail/11.2625.V.20220207.1115.002.html, 2022.LI Yunhong, ZHU Mianyun, REN Jie, et al. Text-to-image synthesis based on modified deep convolutional generative adversarial network[J/OL]. Journal of Beijing University of Aeronautics and Astronautics. http://kns.cnki.net/kcms/detail/11.2625.V.20220207.1115.002.html, 2022. [3] 谈馨悦, 何小海, 王正勇, 等. 基于Transformer交叉注意力的文本生成图像技术[J]. 计算机科学, 2021, 49(2): 107–115. doi: 10.11896/jsjkx.210600085TAN Xinyue, HE Xiaohai, WANG Zhengyong, et al. Text-to-image generation technology based on transformer cross attention[J]. Computer Science, 2021, 49(2): 107–115. doi: 10.11896/jsjkx.210600085 [4] 赵雅琴, 孙蕊蕊, 吴龙文, 等. 基于改进深度生成对抗网络的心电信号重构算法[J]. 电子与信息学报, 2022, 44(1): 59–69. doi: 10.11999/JEIT210922ZHAO Yaqin, SUN Ruirui, WU Longwen, et al. ECG reconstruction based on improved deep convolutional generative adversarial networks[J]. Journal of Electronics &Information Technology, 2022, 44(1): 59–69. doi: 10.11999/JEIT210922 [5] ARJOVSKY M and BOTTOU L. Towards principled methods for training generative adversarial networks[C]. The 5th International Conference on Learning Representations. Toulon, France, 2017. [6] JALAYER M, JALAYER R, KABOLI A, et al. Automatic visual inspection of rare defects: A framework based on gp-wgan and enhanced faster R-CNN[C]. 2021 IEEE International Conference on Industry 4.0, Artificial Intelligence, and Communications Technology, Bandung, Indonesia, 2021: 221–227. [7] WANG Zhendong, ZHENG Huangjie, HE Pengcheng, et al. Diffusion-GAN: Training GANs with diffusion[J]. arXiv: 2206.02262, 2022. [8] RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]. The 38th International Conference on Machine Learning, Westminster, UK, 2021: 8748–8763. [9] HO J, JAIN A, and ABBEEL P. Denoising diffusion probabilistic models[C]. The 34th Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 6840–6851. [10] CHONG Minjin and FORSYTH D. Effectively unbiased FID and inception score and where to find them[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA 2020: 6069–6078. [11] KYNKÄÄNNIEMI T, KARRAS T, LAINE S, et al. Improved precision and recall metric for assessing generative models[C]. The 33rd Conference on Neural Information Processing Systems, Vancouver, Canada, 2019: 32. [12] ZHANG Han, XU Tao, LI Hongsheng, et al. StackGAN: Text to photo-realistic image synthesis with stacked generative adversarial networks[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 5908–5916. [13] SOUZA D M, WEHRMANN J, and RUIZ D D. Efficient neural architecture for text-to-image synthesis[C]. 2020 International Joint Conference on Neural Networks, Glasgow, UK, 2020: 1–8. [14] XU Tao, ZHANG Pengchuan, HUANG Qiuyuan, et al. AttnGAN: Fine-grained text to image generation with attentional generative adversarial networks[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 1316–1324. [15] ZHU Minfeng, PAN Pingbo, CHEN Wei, et al. Dm-GAN: Dynamic memory generative adversarial networks for text-to-image synthesis[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 5795–5803. [16] TAO Ming, TANG Hao, WU Fei, et al. DF-GAN: A simple and effective baseline for text-to-image synthesis[J]. arXiv: 2008.05865, 2020. [17] RAMESH A, PAVLOV M, GOH G, et al. Zero-shot text-to-image generation[C]. The 38th International Conference on Machine Learning, Westminster, UK, 2021: 8821–8831. [18] CHENG Qingrong, WEN Keyu, and GU Xiaodong. Vision-language matching for text-to-image synthesis via generative adversarial networks[J]. IEEE Transactions on Multimedia, To be published. [19] LIAO Wentong, HU Kai, YANG M Y, et al. Text to image generation with semantic-spatial aware GAN[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 18166–18175. [20] BAIOLETTI M, DI BARI G, POGGIONI V, et al. Smart multi-objective evolutionary GAN[C]. 2021 IEEE Congress on Evolutionary Computation, Kraków, Poland, 2021: 2218–2225. [21] YIN Xusen and MAY J. Comprehensible context-driven text game playing[C]. 2019 IEEE Conference on Games, London, UK, 2019: 1–8. -


 下载:
下载:





图(9) / 表(3)
计量
- 文章访问数: 1969
- HTML全文浏览量: 1260
- PDF下载量: 369
- 被引次数: 0
