

Object Detection Method with Spiking Neural Network Based on DT-LIF Neuron and SSD
-
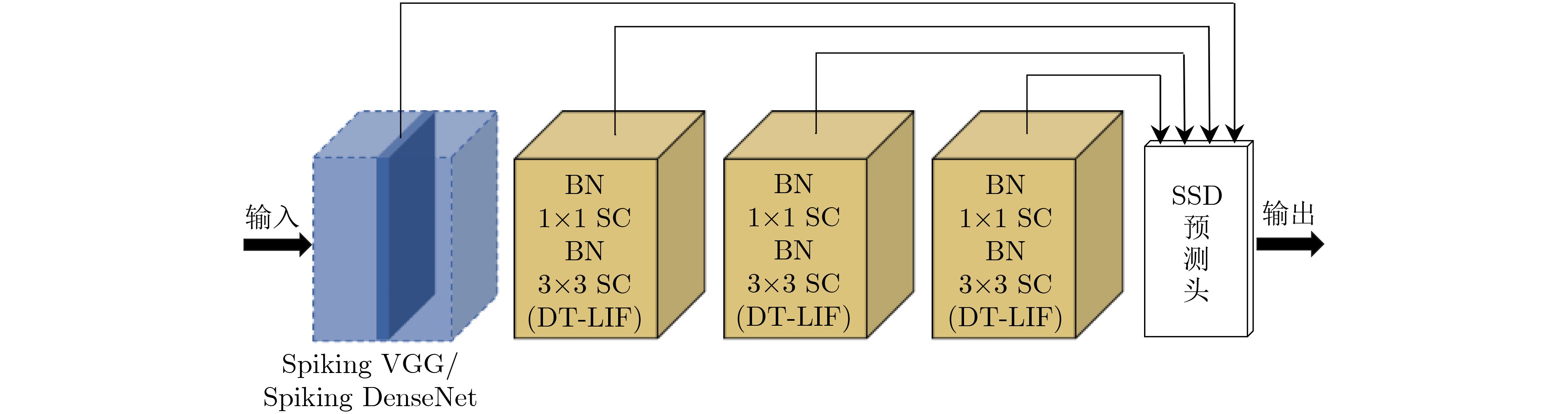
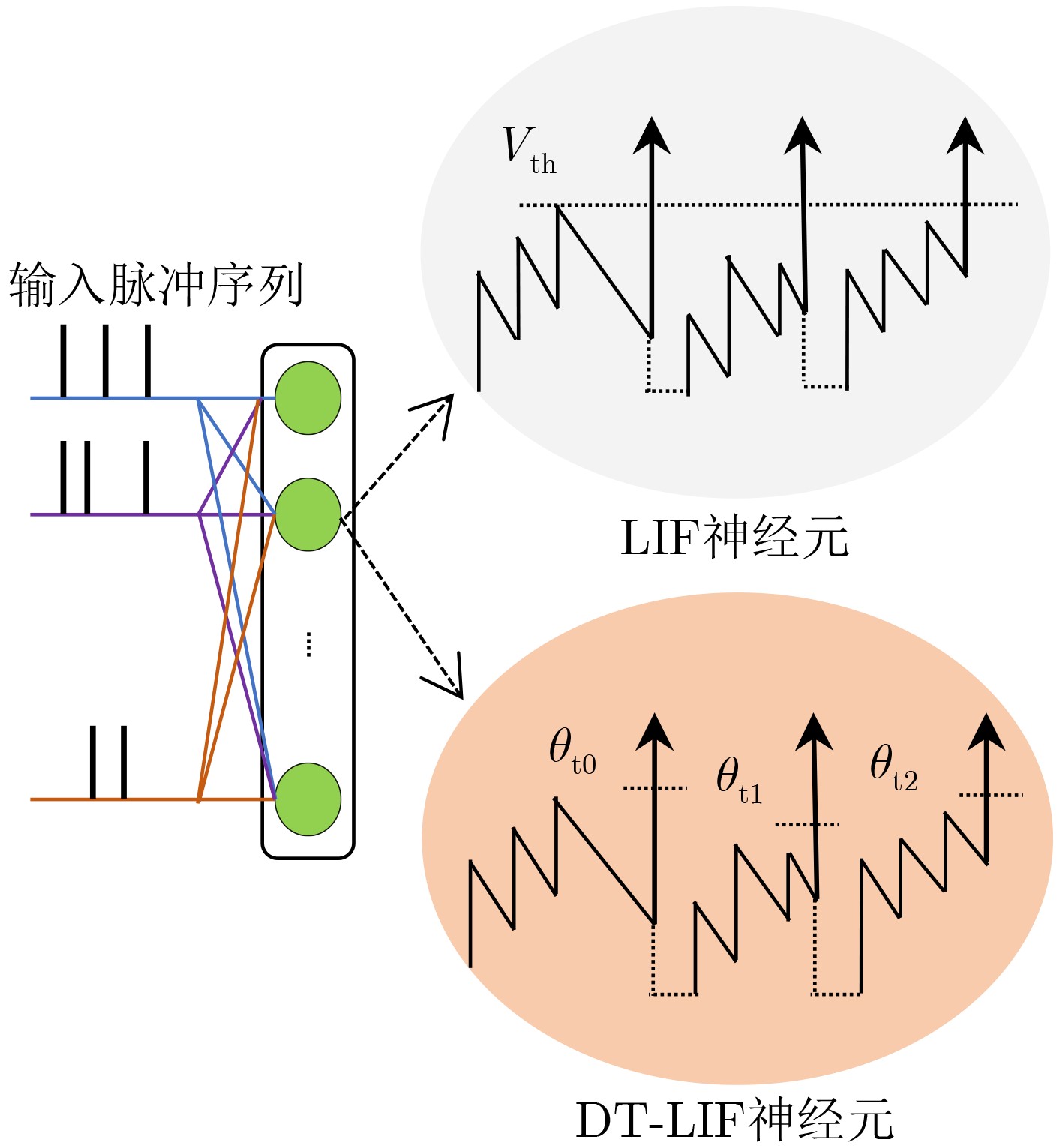
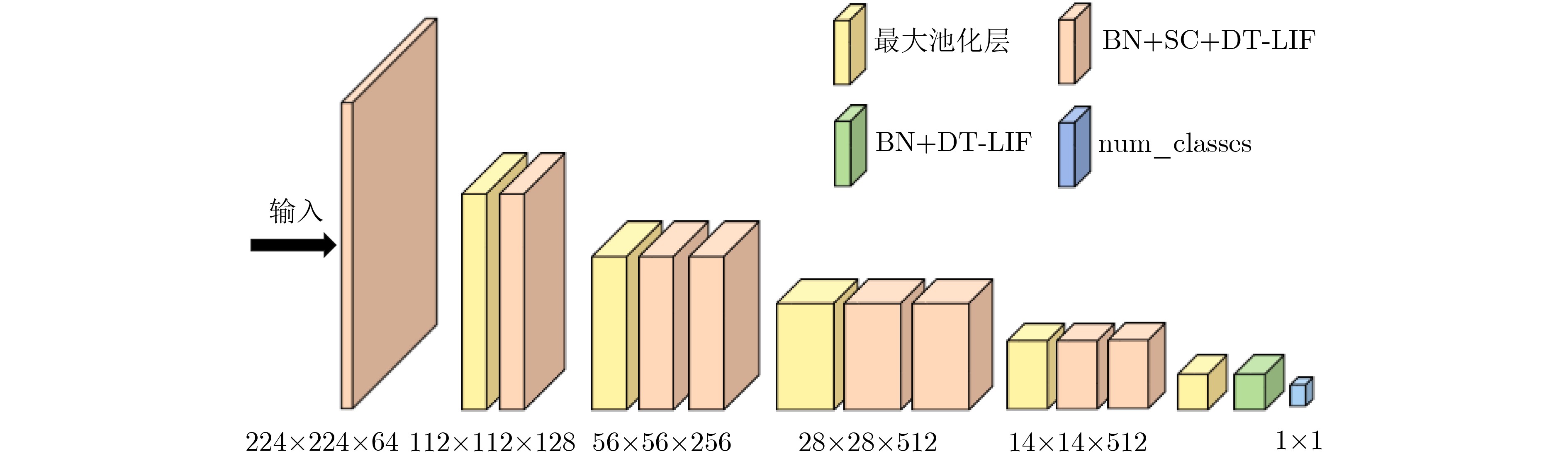
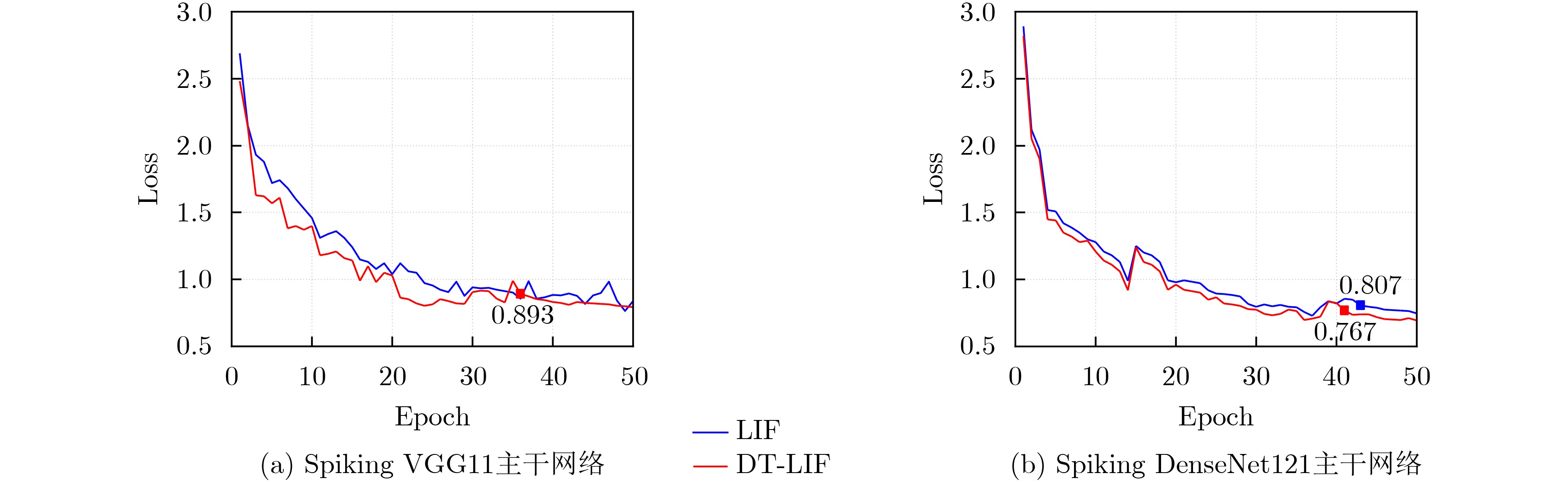
摘要: 相对于传统人工神经网络(ANN),脉冲神经网络(SNN)具有生物可解释性、计算效率高等优势。然而,对于目标检测任务,SNN存在训练难度大、精度低等问题。针对上述问题,该文提出一种基于动态阈值LIF神经元(DT-LIF)与单镜头多盒检测器(SSD)的SNN目标检测方法。首先,设计了一种DT-LIF神经元模型,该模型可根据累积的膜电位动态调整神经元的阈值,以驱动深层网络的脉冲活动,提高推理速度。同时,以DT-LIF神经元为基元,构建了一种基于SSD的混合SNN。该网络以脉冲视觉几何群网络(Spiking VGG)和脉冲密集连接卷积网络(Spiking DenseNet)为主干(Backbone),具有由批处理归一化(BN)层、脉冲卷积(SC)层与DT-LIF神经元构成的3个额外层和SSD预测框头(Head)。实验结果表明,相对于LIF神经元网络,DT-LIF神经元网络在Prophesee GEN1数据集上的目标检测精度提高了25.2%。对比AsyNet算法,所提方法的目标检测精度提高了17.9%。Abstract: Compared with traditional Artificial Neural Network (ANN), the Spiking Neural Network (SNN) has advantages of bioligical reliability and high computational efficiency. However, for object detection task, SNN has problems such as high training difficulty and low accuracy. In response to the above problems, an object detection method with SNN based on Dynamic Threshold Leaky Integrate-and-Fire (DT-LIF) neuron and Single Shot multibox Detector (SSD) is proposed. First, a DT-LIF neuron is designed, which can dynamically adjust the threshold of neuron according to the cumulative membrane potential to drive spike activity of the deep network and imporve the inferance speed. Meanwhile, using DT-LIF neuron as primitive, a hybrid SNN based on SSD is constructed. The network uses Spiking Visual Geometry Group (Spiking VGG) and Spiking Densely Connected Convolutional Network (Spiking DenseNet) as the backbone, and combines with SSD prediction head and three additional layers composed of Batch Normalization (BN) layer , Spiking Convolution (SC) layer, and DT-LIF neuron. Experimental results show that compared with LIF neuron network, the object detection accuracy of DT-LIF neuron network on the Prophesee GEN1 dataset is improved by 25.2%. Compared with the AsyNet algorithm, the object detection accuracy of the proposed method is improved by 17.9%.
-
Key words:
- Computer vision /
- Object detection /
- Spiking Neural Network (SNN) /
- Neuron
-
算法1 DT-LIF发射脉冲过程 参数:θ, p, q, Vth, τm (1) θ = Vth = 1; V = 0; Vreset = 0 // 初始化 (2) for t = 1 to timesteps do (3) for l = 2 to L do (4) for i = 1 to neurons do (5) $ H_{i,t}^l $ = $ V_{i,t-1}^l $ + ($ X_{i,t}^l $ – ($ V_{i,t-1}^l $ – Vreset)) * tau // $ X_{i,t}^l $
是正向传递的输入(6) delta = $ H_{i,t}^l $ – $ V_{i,t-1}^l $ (7) $\theta_{i,t}^l $ = p + q exp (–delta / c) (8) if $ H_{i,t}^l $ ≥ $\theta_{i,t}^l $ then (9) $ S_{i,t}^l $ = 1 (10) $ V_{i,t}^l $ = Vreset (11) end for (12) end for (13) end for  下载: 导出CSV
下载: 导出CSV
-
[1] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 580–587. [2] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904–1916. doi: 10.1109/TPAMI.2015.2389824 [3] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 779–788. [4] LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: Single shot MultiBox detector[C]. The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 21–37. [5] TAN Mingxing and LE Q. EfficientNet: Rethinking model scaling for convolutional neural networks[C]. The 36th International Conference on Machine Learning, Long Beach, USA, 2019: 6105–6114. [6] GERSTNER W and KISTLER W M. Spiking Neuron Models: Single Neurons, Populations, Plasticity[M]. Cambridge: Cambridge University Press, 2002: 421–454. [7] KIM S, PARK S, NA B, et al. Spiking-YOLO: Spiking neural network for energy-efficient object detection[C]. The 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 11270–11277. [8] CHAKRABORTY B, SHE Xueyuan, and MUKHOPADHYAY S. A fully spiking hybrid neural network for energy-efficient object detection[J]. IEEE Transactions on Image Processing, 2021, 30: 9014–9029. doi: 10.1109/TIP.2021.3122092 [9] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2999–3007. [10] KUGELE A, PFEIL T, PFEIFFER M, et al. Hybrid SNN-ANN: Energy-efficient classification and object detection for event-based vision[C]. 43rd DAGM German Conference on Pattern Recognition, Bonn, Germany, 2022: 297–312. [11] 胡一凡, 李国齐, 吴郁杰, 等. 脉冲神经网络研究进展综述[J]. 控制与决策, 2021, 36(1): 1–26. doi: 10.13195/j.kzyjc.2020.1006HU Yifan, LI Guoqi, WU Yujie, et al. Spiking neural networks: A survey on recent advances and new directions[J]. Control and Decision, 2021, 36(1): 1–26. doi: 10.13195/j.kzyjc.2020.1006 [12] TOYOIZUMI T, PFISTER J P, AIHARA K, et al. Spike-timing dependent plasticity and mutual information maximization for a spiking neuron model[C]. The 17th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2004: 1409–1416. [13] HEBB D O. The Organization of Behavior: A Neuropsychological Theory[M]. New York: Psychology Press, 2002. [14] KHERADPISHEH S R, GANJTABESH M, THORPE S J, et al. STDP-based spiking deep convolutional neural networks for object recognition[J]. Neural Networks, 2018, 99: 56–67. doi: 10.1016/j.neunet.2017.12.005 [15] DIEHL P U, NEIL D, BINAS J, et al. Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing[C]. 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 2015: 1–8. [16] NEFTCI E O, MOSTAFA H, and ZENKE F. Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based optimization to spiking neural networks[J]. IEEE Signal Processing Magazine, 2019, 36(6): 51–63. doi: 10.1109/msp.2019.2931595 [17] WU Yujie, DENG Lei, LI Guoqi, et al. Spatio-temporal backpropagation for training high-performance spiking neural networks[J]. Frontiers in Neuroscience, 2018, 12: 331. doi: 10.3389/fnins.2018.00331 [18] ZHENG Hanle, WU Yujie, DENG Lei, et al. Going deeper with directly-trained larger spiking neural networks[C]. The 35th AAAI Conference on Artificial Intelligence, Palo Alto, USA, 2021: 11062–11070. [19] FANG Wei, YU Zhaofei, CHEN Yanqi, et al. Incorporating learnable membrane time constant to enhance learning of spiking neural networks[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 2641–2651. [20] GERSTNER W, KISTLER W M, NAUD R, et al. Neuronal Dynamics: From Single Neurons to Networks and Models of Cognition[M]. Cambridge: Cambridge University Press, 2014. [21] 贺丰收, 何友, 刘准钆, 等. 卷积神经网络在雷达自动目标识别中的研究进展[J]. 电子与信息学报, 2020, 42(1): 119–131. doi: 10.11999/JEIT180899HE Fengshou, HE You, LIU Zhunga, et al. Research and development on applications of convolutional neural networks of radar automatic target recognition[J]. Journal of Electronics &Information Technology, 2020, 42(1): 119–131. doi: 10.11999/JEIT180899 [22] 董小伟, 韩悦, 张正, 等. 基于多尺度加权特征融合网络的地铁行人目标检测算法[J]. 电子与信息学报, 2021, 43(7): 2113–2120. doi: 10.11999/JEIT200450DONG Xiaowei, HAN Yue, ZHANG Zheng, et al. Metro pedestrian detection algorithm based on multi-scale weighted feature fusion network[J]. Journal of Electronics &Information Technology, 2021, 43(7): 2113–2120. doi: 10.11999/JEIT200450 [23] SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]. 3rd International Conference on Learning Representations, San Diego, USA, 2015. [24] AZOUZ R and GRAY C M. Dynamic spike threshold reveals a mechanism for synaptic coincidence detection in cortical neurons in vivo[J]. Proceedings of the National Academy of Sciences of the United States of America, 2000, 97(14): 8110–8115. doi: 10.1073/PNAS.130200797 [25] FONTAINE B, PEÑA J L, and BRETTE R. Spike-threshold adaptation predicted by membrane potential dynamics in vivo[J]. PLoS Computational Biology, 2014, 10(4): e1003560. doi: 10.1371/journal.PCBI.1003560 [26] XIAO Rong, TANG Huajin, MA Yuhao, et al. An event-driven categorization model for AER image sensors using multispike encoding and learning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(9): 3649–3657. doi: 10.1109/tnnls.2019.2945630 [27] FANG Wei, YU Zhaofei, CHEN Yanqi, et al. Deep residual learning in spiking neural networks[C/OL]. The 34th International Conference on Neural Information Processing Systems, 2021: 21056–21069. [28] HUANG Gao, LIU Zhuang, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2261–2269. [29] DE TOURNEMIRE P, NITTI D, PEROT E, et al. A large scale event-based detection dataset for automotive[EB/OL]. https://doi.org/10.48550/arXiv.2001.08499, 2020. [30] 张德祥, 王俊, 袁培成. 基于注意力机制的多尺度全场景监控目标检测方法[J]. 电子与信息学报, 2022, 44(9): 3249–3257. doi: 10.11999/JEIT210664ZHANG Dexiang, WANG Jun, and YUAN Peicheng. Object detection method for multi-scale full-scene surveillance based on attention mechanism[J]. Journal of Electronics &Information Technology, 2022, 44(9): 3249–3257. doi: 10.11999/JEIT210664 [31] MESSIKOMMER N, GEHRIG D, LOQUERCIO A, et al. Event-based asynchronous sparse convolutional networks[C]. 16th European Conference on Computer Vision, Glasgow, UK, 2020: 415–431. -


 下载:
下载:




图(7) / 表(2)
计量
- 文章访问数: 2075
- HTML全文浏览量: 1127
- PDF下载量: 264
- 被引次数: 0
