

Multi-Scenario Aware Infrared and Visible Image Fusion Framework Based on Visual Multi-Pathway Mechanism
-
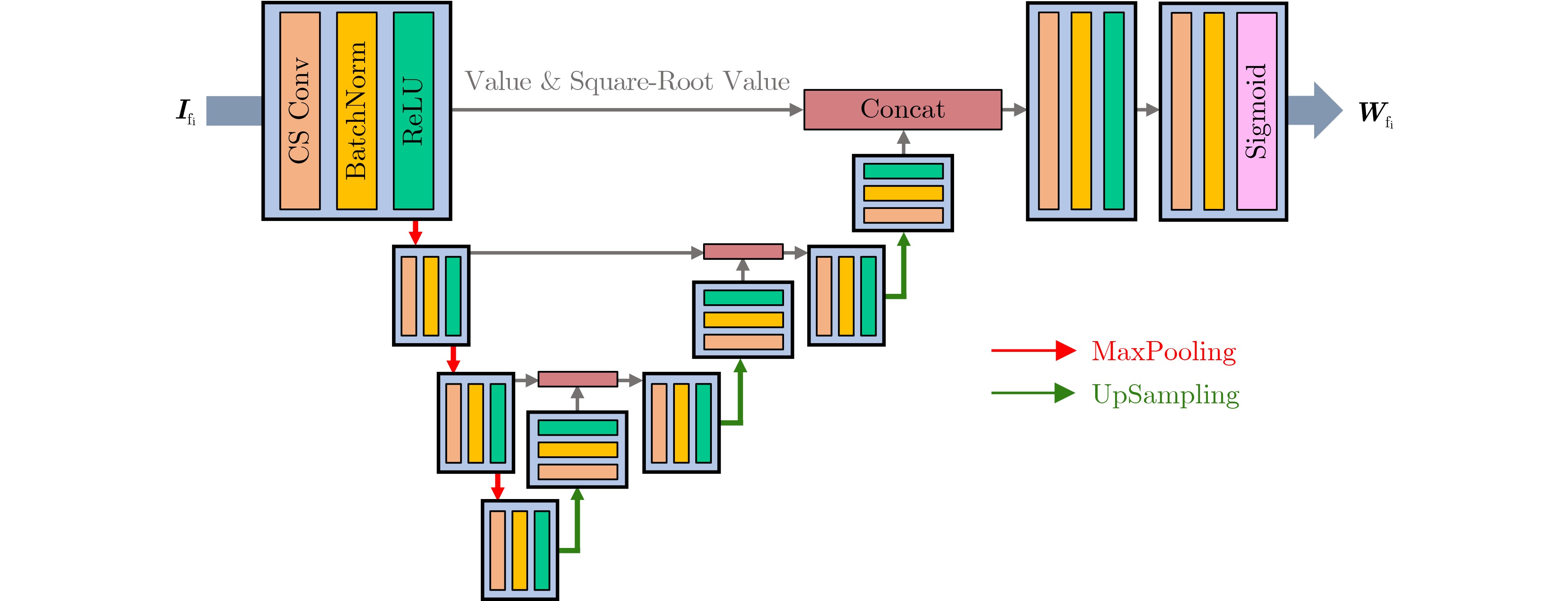
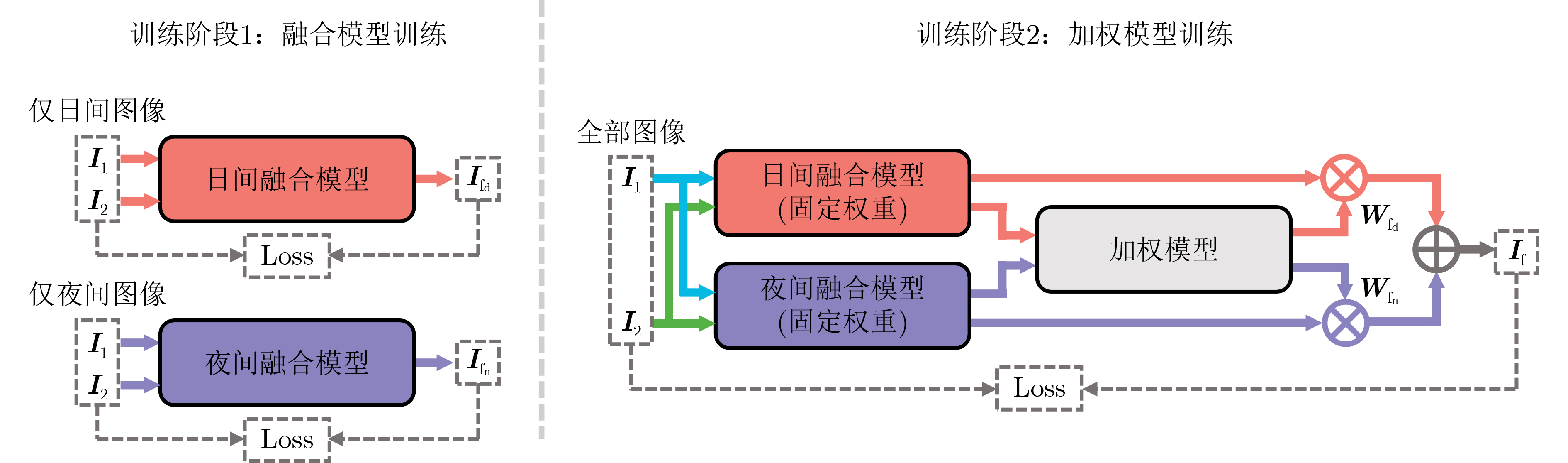
摘要: 现有的红外与可见光图像融合算法往往将日间场景与夜间场景下的图像融合视为同一个问题,这种方式忽略了在日间场景与夜间场景下进行图像融合的差异性,使得算法融合性能受限。生物视觉系统强大的自适应特性能够在不同场景下最大限度地捕获输入视觉刺激中的有效信息,实现自适应的视觉信息处理,有可能为实现性能更为优异的红外与可见光图像融合算法带来新的思路启发。针对上述问题,该文提出一种视觉多通路机制启发的多场景感知红外与可见光图像融合框架。其中,受生物视觉多通路特性启发,该文框架中设计了分别感知日间场景信息与夜间场景信息的两条信息处理通路,源图像首先分别输入感知日间场景信息与感知夜间场景信息的融合网络得到两幅中间结果图像,而后再通过可学习的加权网络生成最终的融合图像。此外,该文设计了模拟生物视觉中广泛存在的中心-外周感受野结构的中心-外周卷积模块,并将其应用于所提出框架中。定性与定量实验结果表明,该文所提方法在主观上能够显著提升融合图像的图像质量,同时在客观评估指标上优于现有融合算法。
-
关键词:
- 红外与可见光图像融合 /
- 类脑计算 /
- 多场景感知框架
Abstract: Most existing infrared and visible image fusion methods neglect the disparities between daytime and nighttime scenarios and consider them similar, leading to low accuracy. However, the adaptive properties of the biological vision system allow for the capture of helpful information from source images and adaptive visual information processing. This concept provides a new direction for improving the accuracy of the deep-learning-based infrared and visible image fusion methods. Inspired by the visual multi-pathway mechanism, this study proposes a multi-scenario aware infrared and visible image fusion framework to incorporate two distinct visual pathways capable of perceiving daytime and nighttime scenarios. Specifically, daytime- and nighttime-scenario-aware fusion networks process the source images to generate two intermediate fusion results. Finally, a learnable weighting network obtains the final result. Additionally, the proposed framework utilizes a novel center-surround convolution module that simulates the widely distributed center-surround receptive field in biological vision. Qualitative and quantitative experiments demonstrate that the proposed framework improves significantly the quality of the fused image and outperforms existing methods in objective evaluation metrics. -
表 1 验证实验中各统计检验实验结果
条件 EN SF SD VIF AG 对于日间测试集:
日间模型优于混合模型是
(p = $\text{1.36×}{\text{10} }^{{-8} }$)是
(p = $ \text{2.59×}{\text{10}}^{{-16}} $)是
(p = $ \text{8.90×}{\text{10}}^{{-15}} $)是
(p = $ \text{2.24×}{\text{10}}^{{-5}} $)是
(p = $ \text{5.18×}{\text{10}}^{{-11}} $)对于混合测试集:
日间模型或夜间模型优于混合模型是
(p = $\text{2.19×}{\text{10} }^{{-30} }$)是
(p = $ \text{5.08×}{\text{10}}^{{-16}} $)是
(p = $ \text{1.34×}{\text{10}}^{{-23}} $)是
(p = $ \text{6.32×}{\text{10}}^{{-17}} $)是
(p = $ \text{4.17×}{\text{10}}^{{-15}} $)对于夜间测试集:
夜间模型优于混合模型是
(p = $\text{2.57×}{\text{10} }^{{-27} }$)是
(p = 1.21$ \text{×}{\text{10}}^{{-2}} $)是
(p = $ \text{7.38×}{\text{10}}^{{-24}} $)是
(p = $ \text{1.81×}{\text{10}}^{{-20}} $)是
(p = $ \text{1.45×}{\text{10}}^{{-10}} $) 下载: 导出CSV
下载: 导出CSV
表 2 MSRS数据集定量评估表
方法 EN SF SD VIF AG MI QAB/F SSIM MS-SSIM FMIpixel FMIw CSR 5.9478 0.0345 7.3181 0.7069 2.7030 2.3414 0.5776 0.9653 0.9433 0.9264 0.3167 GTF 5.4618 0.0314 6.3479 0.5936 2.3857 1.7041 0.3939 0.9085 0.8542 0.9119 0.3543 DenseFuse 6.6146 0.0246 8.4964 0.7482 2.3777 2.6214 0.3006 0.8931 0.9116 0.8881 0.2075 FusionGAN 5.6367 0.0192 6.3723 0.5908 1.7005 1.9360 0.1476 0.7984 0.6711 0.8914 0.2990 PMGI 6.4399 0.0350 8.1380 0.7187 3.2519 2.1371 0.4327 0.9259 0.8657 0.8867 0.3624 GANMcC 6.2789 0.0235 8.6547 0.6760 2.1591 2.5863 0.2825 0.8843 0.8525 0.8966 0.3402 RFN-Nest 6.6113 0.0275 8.4071 0.7692 2.5701 2.5292 0.4351 0.9254 0.9226 0.9048 0.2745 本文算法 7.0326 0.0480 9.2206 1.0310 4.0374 5.1835 0.6625 0.9490 0.9486 0.9202 0.3655
下载: 导出CSV
表 3 TNO数据集定量评估表
方法 EN SF SD VIF AG MI QAB/F SSIM MS-SSIM FMIpixel FMIw CSR 6.4881 0.0344 8.7811 0.6928 3.2025 2.0349 0.5284 0.9428 0.9037 0.9144 0.3837 GTF 6.8816 0.0354 9.5738 0.6228 3.2516 2.7606 0.4031 0.8766 0.8164 0.9042 0.4408 DenseFuse 6.9883 0.0222 9.4056 0.7895 2.5622 2.0975 0.2745 0.8432 0.8965 0.8928 0.1998 FusionGAN 6.6321 0.0244 0.8378 0.6583 2.3133 2.3870 0.2328 0.8106 0.7474 0.8855 0.3907 PMGI 7.0744 0.0323 9.6515 0.8759 3.3519 2.3885 0.4108 0.9305 0.9030 0.9009 0.3992 GANMcC 6.7865 0.0231 9.1537 0.7147 2.4184 2.3224 0.2795 0.8803 0.8623 0.8983 0.3885 RFN-Nest 7.0418 0.0218 9.4329 0.8349 2.5176 2.1621 0.3326 0.8757 0.9091 0.9021 0.3003 本文算法 6.8975 0.0402 9.3660 0.9146 3.9126 3.6862 0.5627 0.8994 0.8479 0.9110 0.3936
下载: 导出CSV
表 4 消融实验结果表
方法 EN SF SD VIF AG MI QAB/F SSIM MS-SSIM FMIpixel FMIw 无CS Conv 6.6527 0.0414 8.4249 1.0352 3.3969 4.3652 0.6180 0.9409 0.9451 0.9305 0.3542 仅日间模型 7.0237 0.0474 9.2902 1.0369 4.0746 4.9832 0.6624 0.9681 0.9607 0.9193 0.3626 仅夜间模型 6.9472 0.0479 9.0583 0.9733 4.1572 4.7346 0.6895 0.9112 0.9221 0.9173 0.3631 本文算法 7.0326 0.0480 9.2206 1.0310 4.0374 5.1835 0.6625 0.9490 0.9486 0.9202 0.3655
下载: 导出CSV
表 5 权重图分析实验结果
条件 最小单幅占比(%) 最大单幅占比(%) 平均单幅占比(%) 统计检验P值 对于日间测试集图像:
日间结果权重图大于等于夜间结果权重图94.54 98.52 96.07 $ \text{4.16×}{\text{10}}^{{-101}} $ 对于夜间测试集图像:
夜间结果权重图大于等于日间结果权重图40.84 84.17 55.37 $ \text{7.74×}{\text{10}}^{{-8}} $
下载: 导出CSV
-
[1] MA Jiayi, MA Yong, and LI Chang. Infrared and visible image fusion methods and applications: A survey[J]. Information Fusion, 2019, 45: 153–178. doi: 10.1016/j.inffus.2018.02.004 [2] ZHANG Hao, XU Han, TIAN Xin, et al. Image fusion meets deep learning: A survey and perspective[J]. Information Fusion, 2021, 76: 323–336. doi: 10.1016/j.inffus.2021.06.008 [3] 朱浩然, 刘云清, 张文颖. 基于对比度增强与多尺度边缘保持分解的红外与可见光图像融合[J]. 电子与信息学报, 2018, 40(6): 1294–1300. doi: 10.11999/JEIT170956ZHU Haoran, LIU Yunqing, and ZHANG Wenying. Infrared and visible image fusion based on contrast enhancement and multi-scale edge-preserving decomposition[J]. Journal of Electronics &Information Technology, 2018, 40(6): 1294–1300. doi: 10.11999/JEIT170956 [4] LIU Yu, CHEN Xun, WARD R K, et al. Image fusion with convolutional sparse representation[J]. IEEE Signal Processing Letters, 2016, 23(12): 1882–1886. doi: 10.1109/LSP.2016.2618776 [5] FU Zhizhong, WANG Xue, XU Jin, et al. Infrared and visible images fusion based on RPCA and NSCT[J]. Infrared Physics & Technology, 2016, 77: 114–123. doi: 10.1016/j.infrared.2016.05.012 [6] MA Jinlei, ZHOU Zhiqiang, WANG Bo, et al. Infrared and visible image fusion based on visual saliency map and weighted least square optimization[J]. Infrared Physics & Technology, 2017, 82: 8–17. doi: 10.1016/j.infrared.2017.02.005 [7] LI Hui, WU Xiaojun, and KITTLER J. Infrared and visible image fusion using a deep learning framework[C]. Proceedings of the 24th International Conference on Pattern Recognition, Beijing, China, 2018: 2705–2710. [8] ZHANG Hao, XU Han, XIAO Yang, et al. Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity[C]. Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 12797–12804. [9] LI Hui and WU Xiaojun. DenseFuse: A fusion approach to infrared and visible images[J]. IEEE Transactions on Image Processing, 2019, 28(5): 2614–2623. doi: 10.1109/TIP.2018.2887342 [10] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[C]. Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 740–755. [11] LI Hui, WU Xiaojun, and KITTLER J. RFN-Nest: An end-to-end residual fusion network for infrared and visible images[J]. Information Fusion, 2021, 73: 72–86. doi: 10.1016/j.inffus.2021.02.023 [12] MA Jiayi, YU Wei, LIANG Pengwei, et al. FusionGAN: A generative adversarial network for infrared and visible image fusion[J]. Information Fusion, 2019, 48: 11–26. doi: 10.1016/j.inffus.2018.09.004 [13] MA Jiayi, ZHANG Hao, SHAO Zhenfeng, et al. GANMcC: A generative adversarial network with multiclassification constraints for infrared and visible image fusion[J]. IEEE Transactions on Instrumentation and Measurement, 2020, 70: 5005014. doi: 10.1109/TIM.2020.3038013 [14] TAN Minjie, GAO Shaobing, XU Wenzheng, et al. Visible-infrared image fusion based on early visual information processing mechanisms[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(11): 4357–4369. doi: 10.1109/TCSVT.2020.3047935 [15] WAXMAN A M, GOVE A N, FAY D A, et al. Color night vision: Opponent processing in the fusion of visible and IR imagery[J]. Neural Networks, 1997, 10(1): 1–6. doi: 10.1016/S0893-6080(96)00057-3 [16] GOODALE M A and MILNER D A. Separate visual pathways for perception and action[J]. Trends in Neurosciences, 1992, 15(1): 20–25. doi: 10.1016/0166-2236(92)90344-8 [17] CHEN Ke, SONG Xuemei, and LI Chaoyi. Contrast-dependent variations in the excitatory classical receptive field and suppressive nonclassical receptive field of cat primary visual cortex[J]. Cerebral Cortex, 2013, 23(2): 283–292. doi: 10.1093/cercor/bhs012 [18] TANG Linfeng, YUAN Jiteng, ZHANG Hao, et al. PIAFusion: A progressive infrared and visible image fusion network based on illumination aware[J]. Information Fusion, 2022, 83/84: 79–92. doi: 10.1016/j.inffus.2022.03.007 [19] ANGELUCCI A and SHUSHRUTH S. Beyond the classical receptive field: Surround modulation in primary visual cortex[M]. WERNER J S and CHALUPA L M. The New Visual Neurosciences. Cambridge: MIT Press, 2013: 425–444. [20] GAO Shaobing, YANG Kaifu, LI Chaoyi, et al. Color constancy using double-opponency[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(10): 1973–1985. doi: 10.1109/TPAMI.2015.2396053 [21] RONNEBERGER O, FISCHER P, and BROX T. U-Net: Convolutional networks for biomedical image segmentation[C]. Proceedings of 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 2015: 234–241. [22] VINKER Y, HUBERMAN-SPIEGELGLAS I, and FATTAL R. Unpaired learning for high dynamic range image tone mapping[C]. Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 14637–14646. [23] TOET A. The TNO multiband image data collection[J]. Data in Brief, 2017, 15: 249–251. doi: 10.1016/j.dib.2017.09.038 [24] MA Jiayi, CHEN Chen, LI Chang, et al. Infrared and visible image fusion via gradient transfer and total variation minimization[J]. Information Fusion, 2016, 31: 100–109. doi: 10.1016/j.inffus.2016.02.001 [25] WANG Di, LIU Jinyuan, FAN Xin, et al. Unsupervised misaligned infrared and visible image fusion via cross-modality image generation and registration[C]. Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, Vienna, Austria, 2022: 3508–3515. -


 下载:
下载:






图(7) / 表(5)
计量
- 文章访问数: 1379
- HTML全文浏览量: 1033
- PDF下载量: 175
- 被引次数: 0
