

3-D Localization Method Based on Wireless Tags in Warehouse Scenarios
-
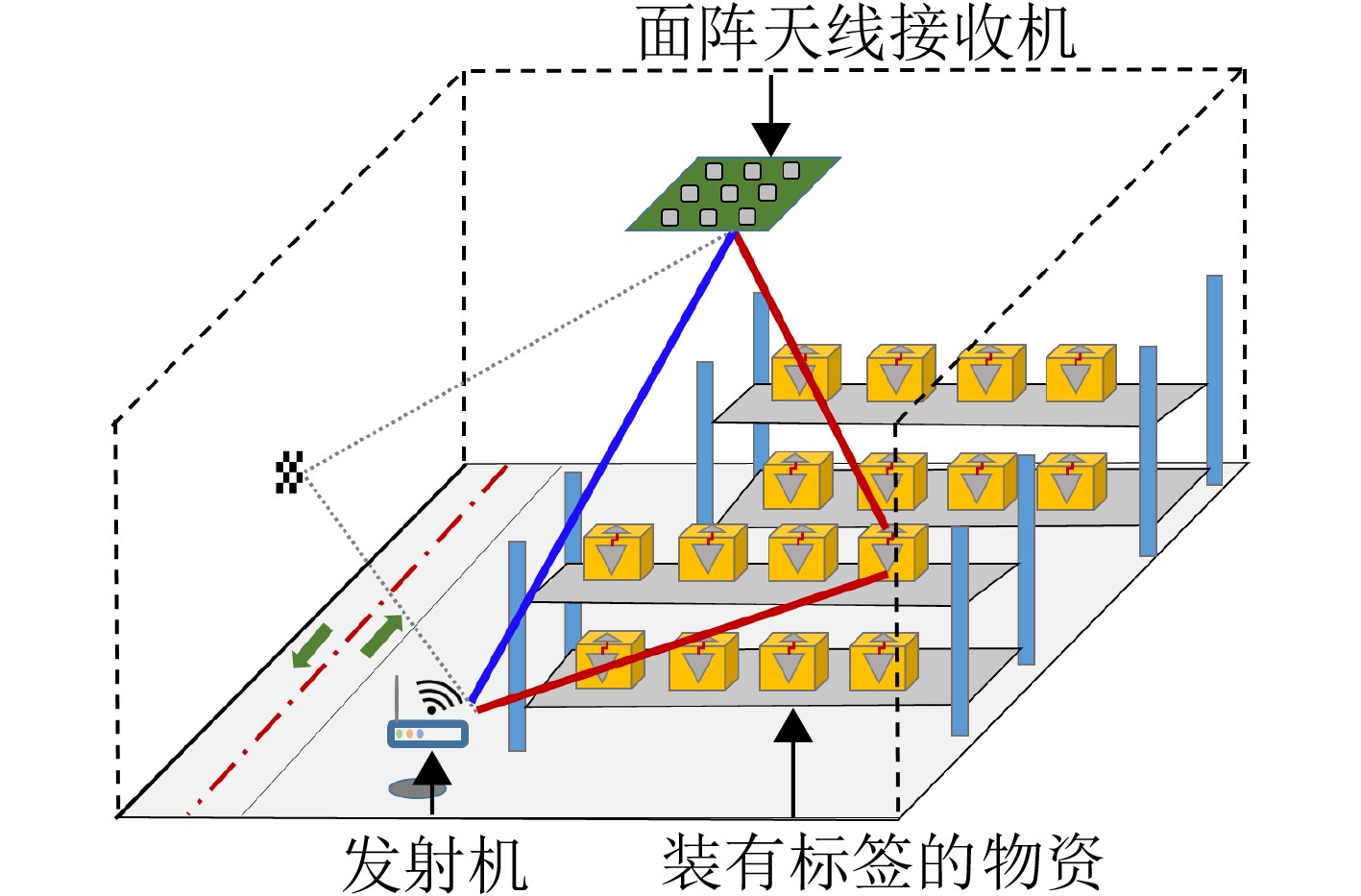
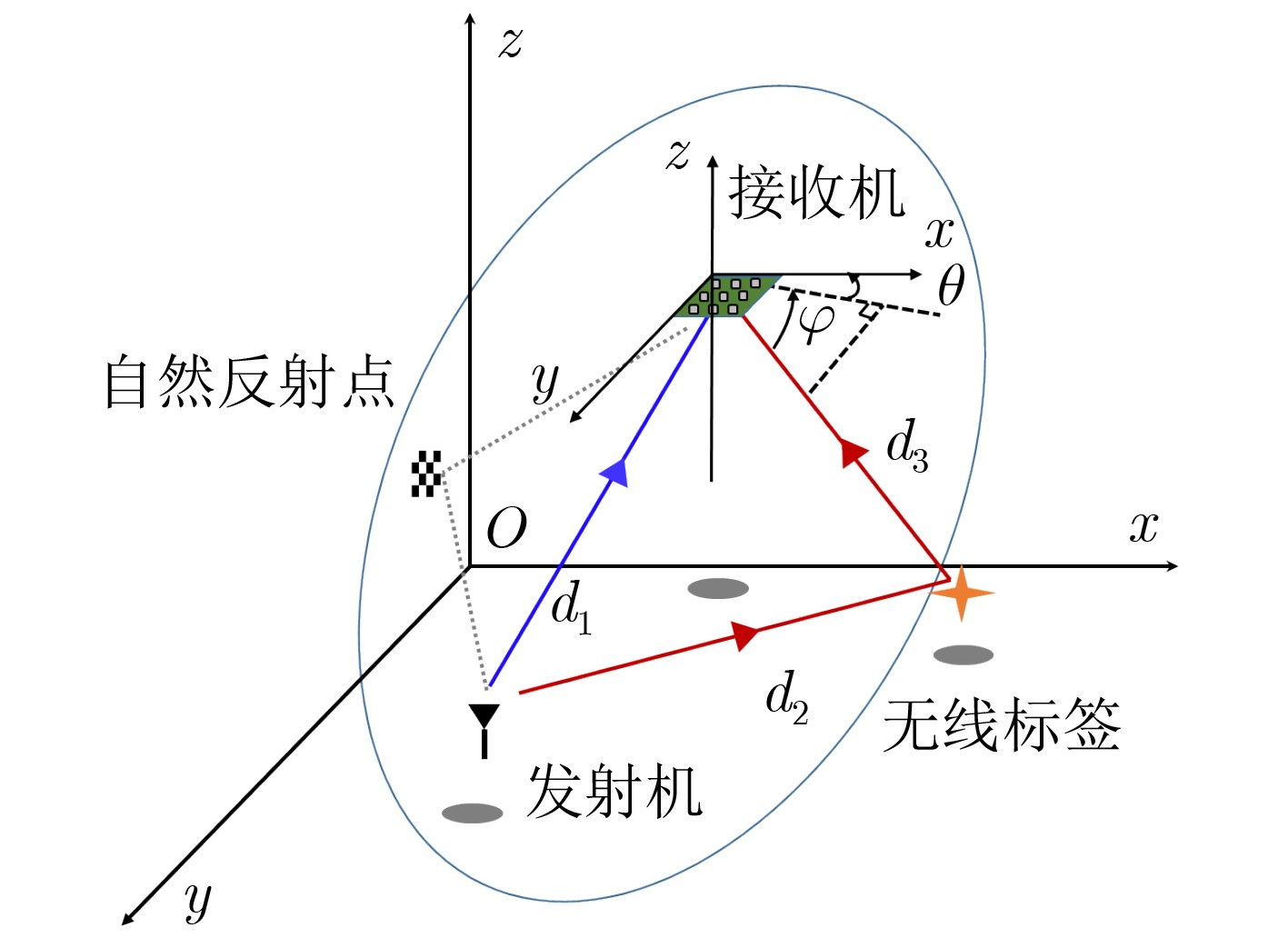
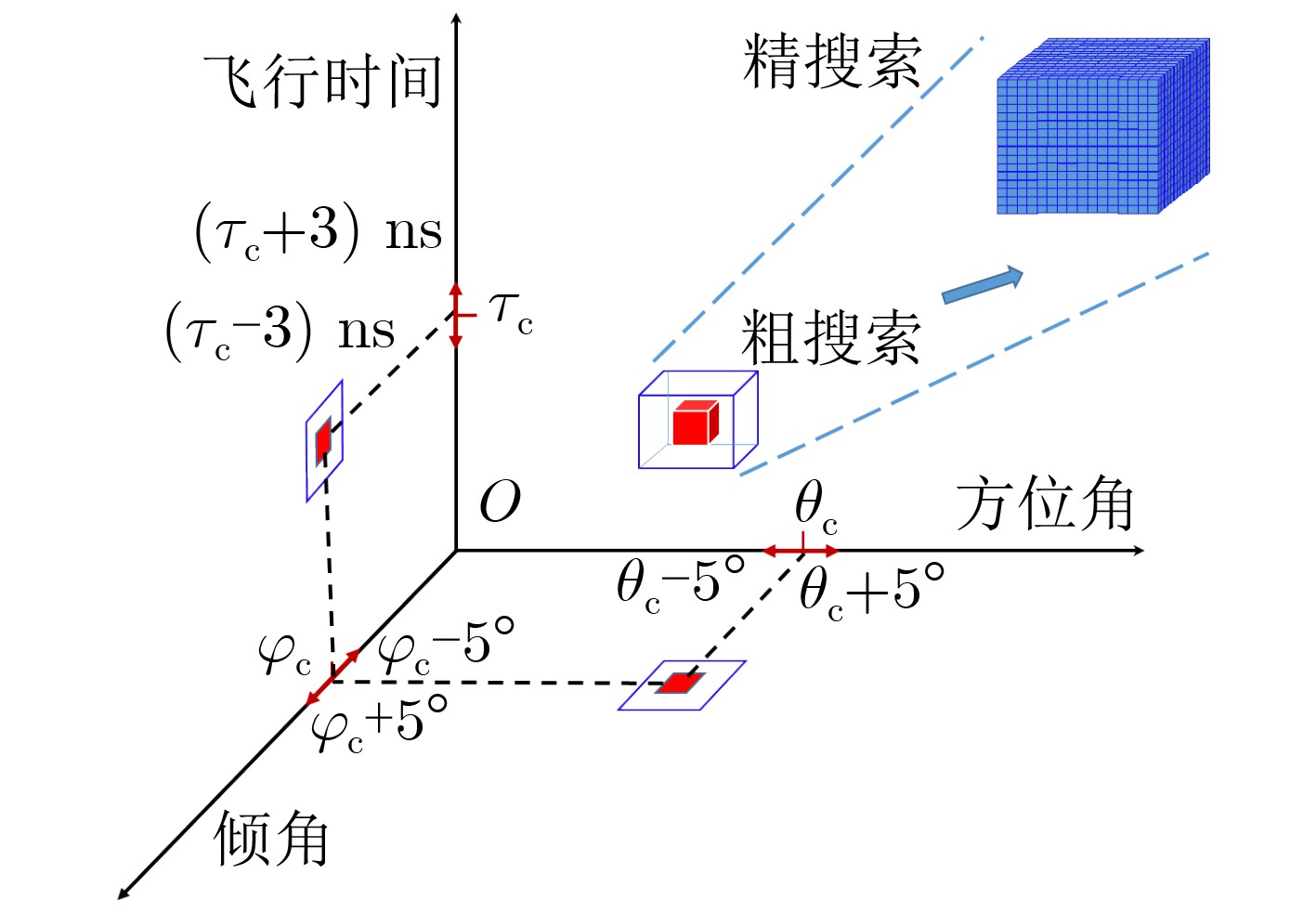
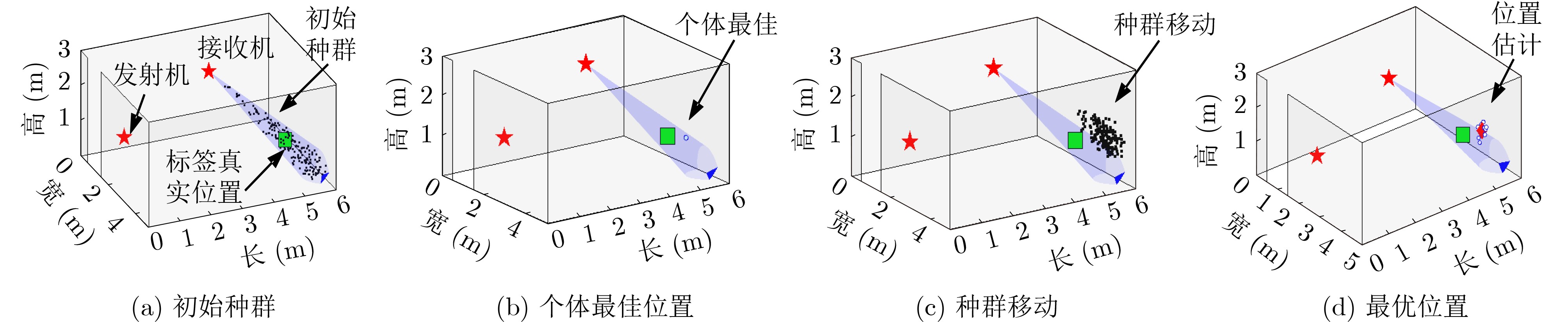
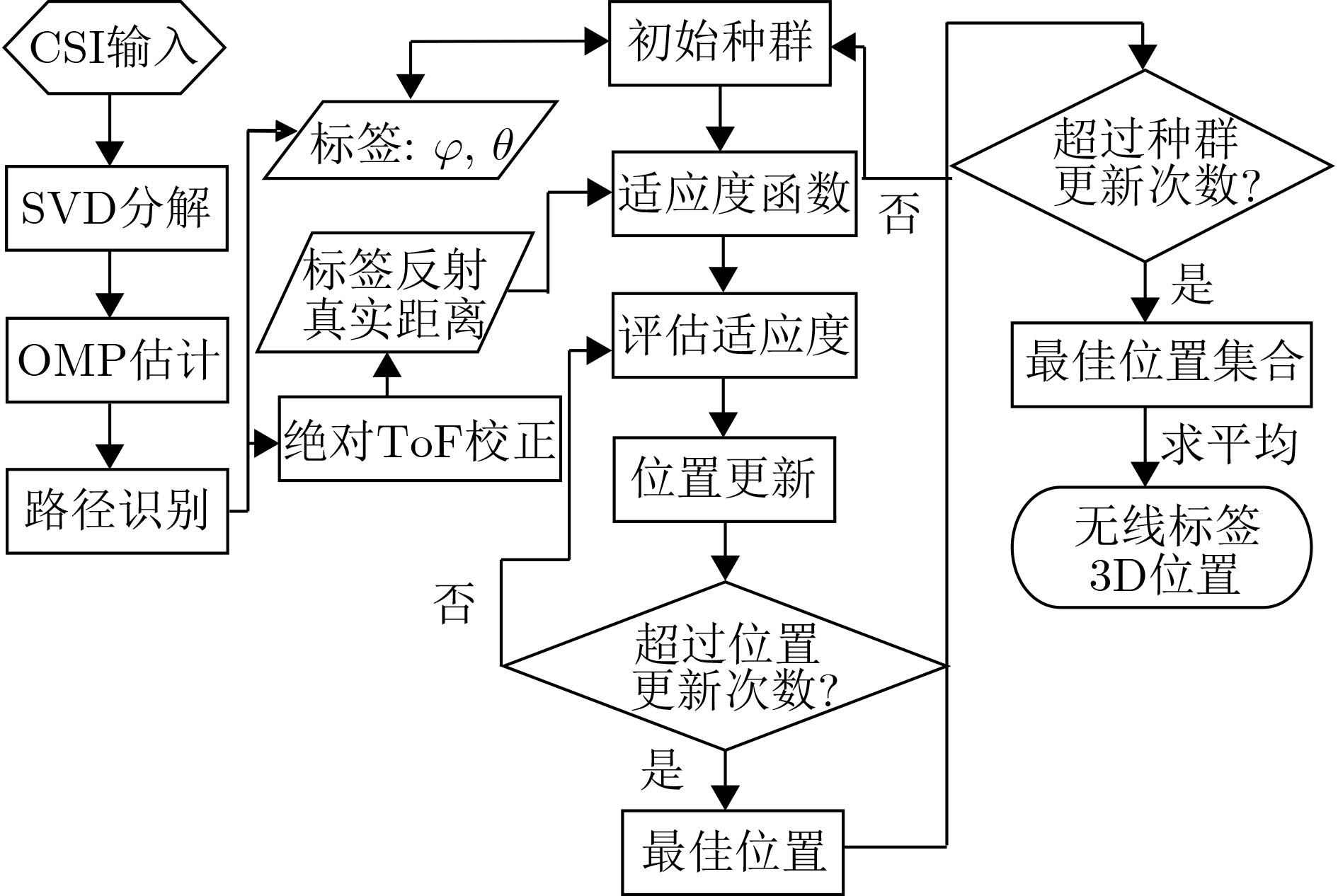
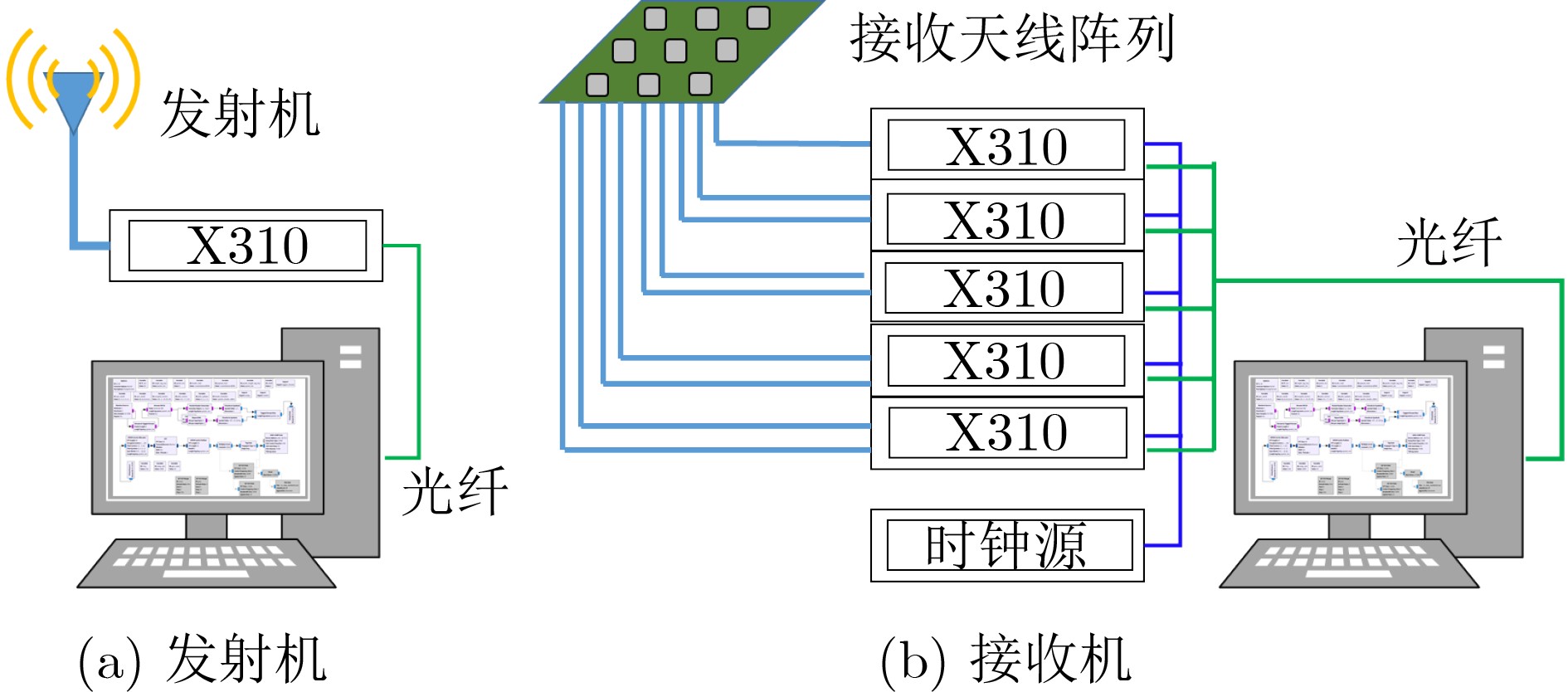
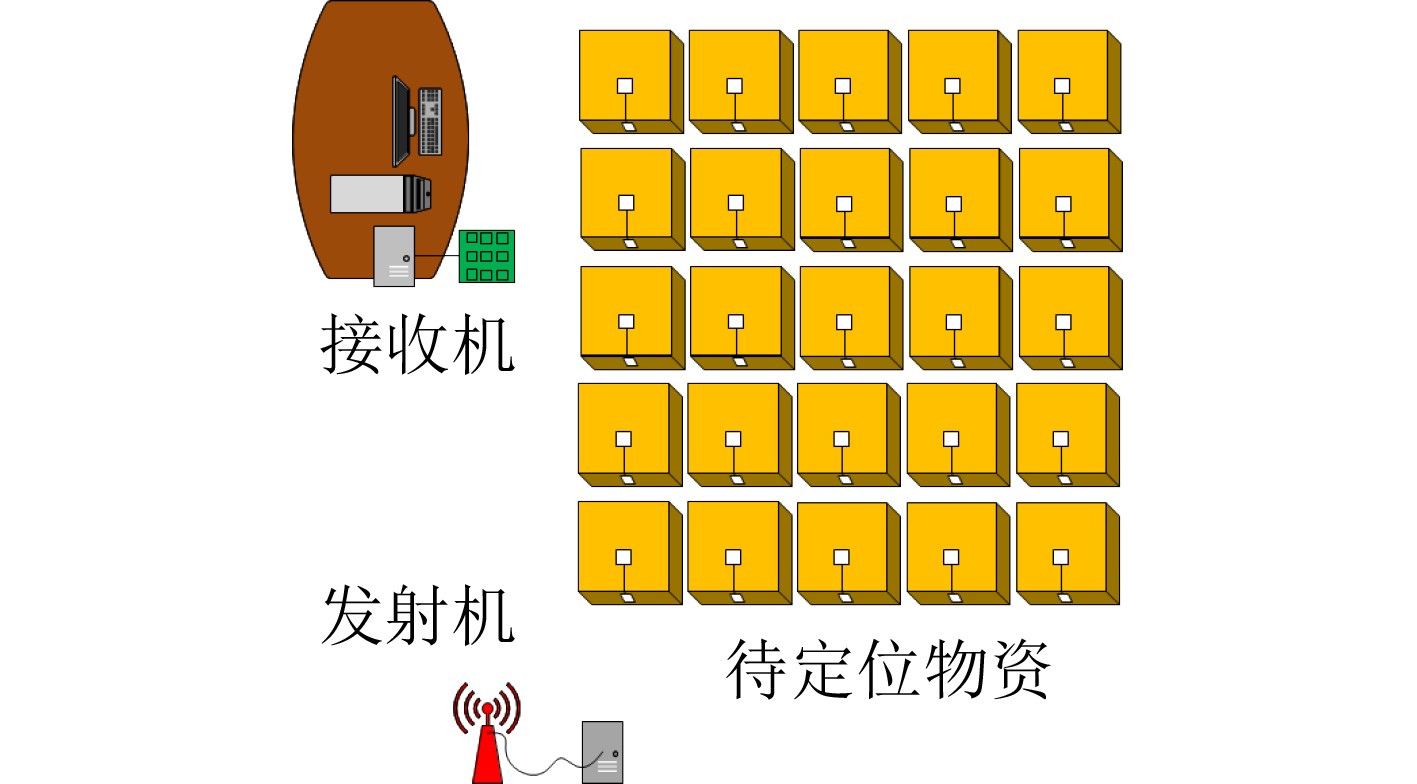
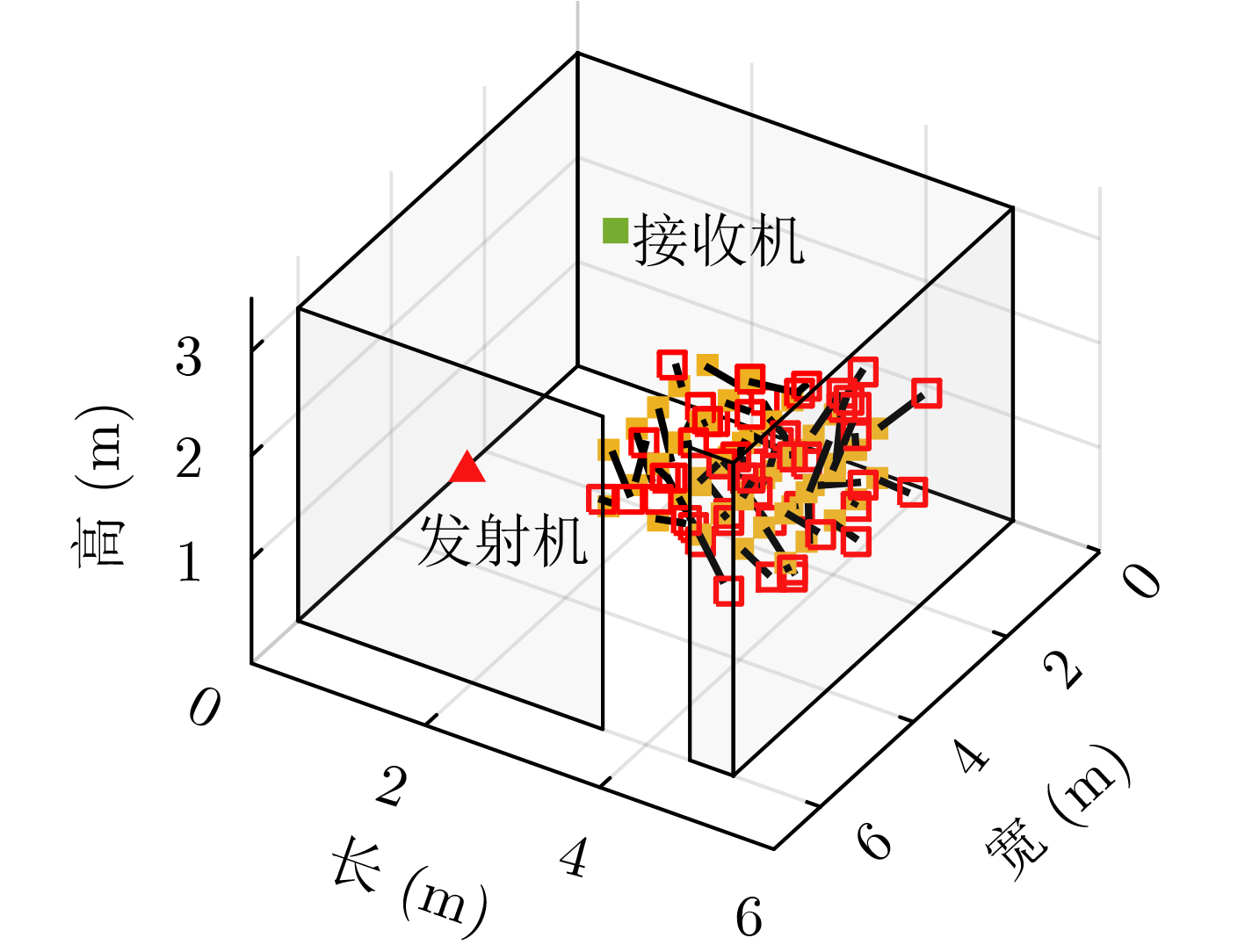
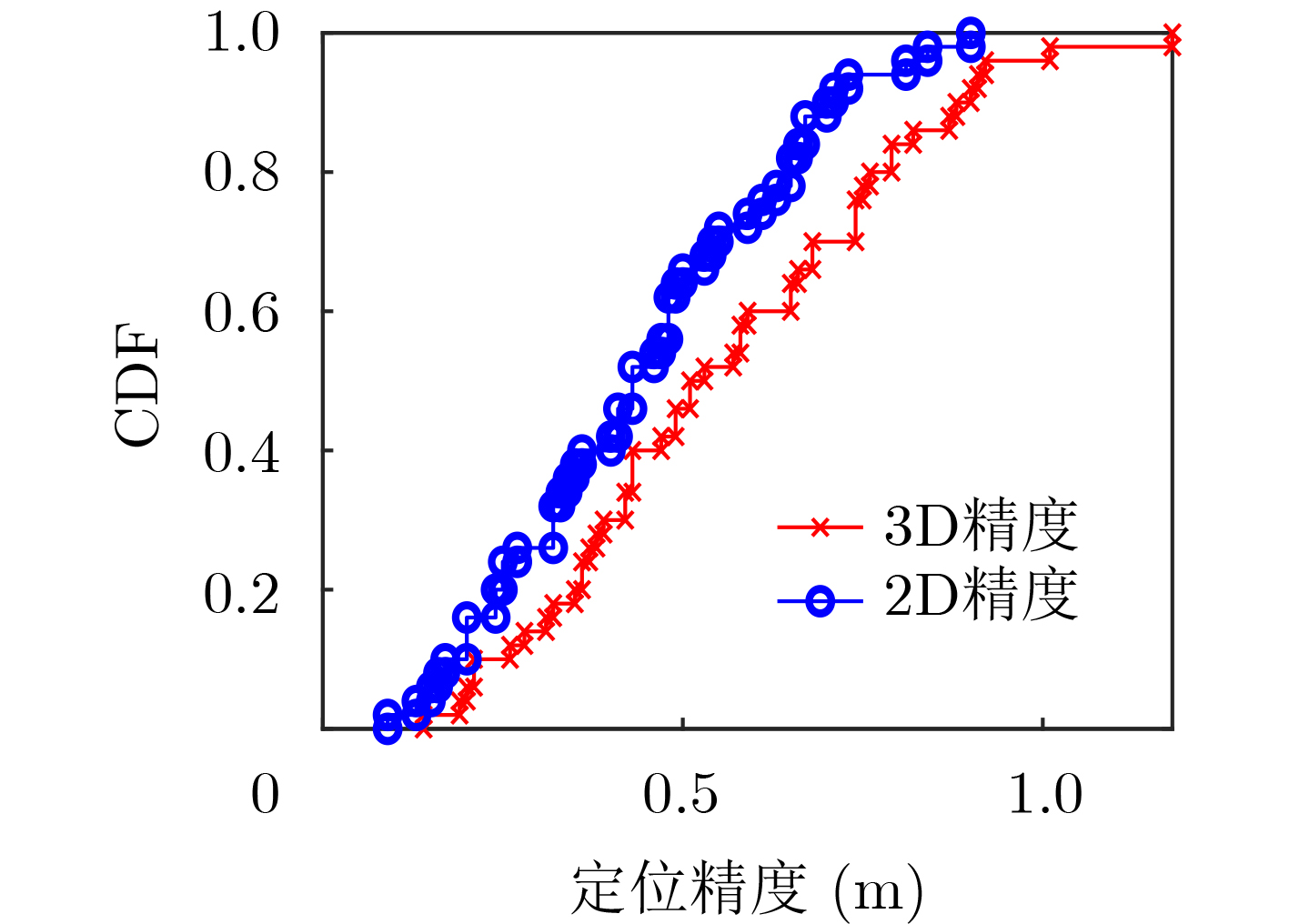
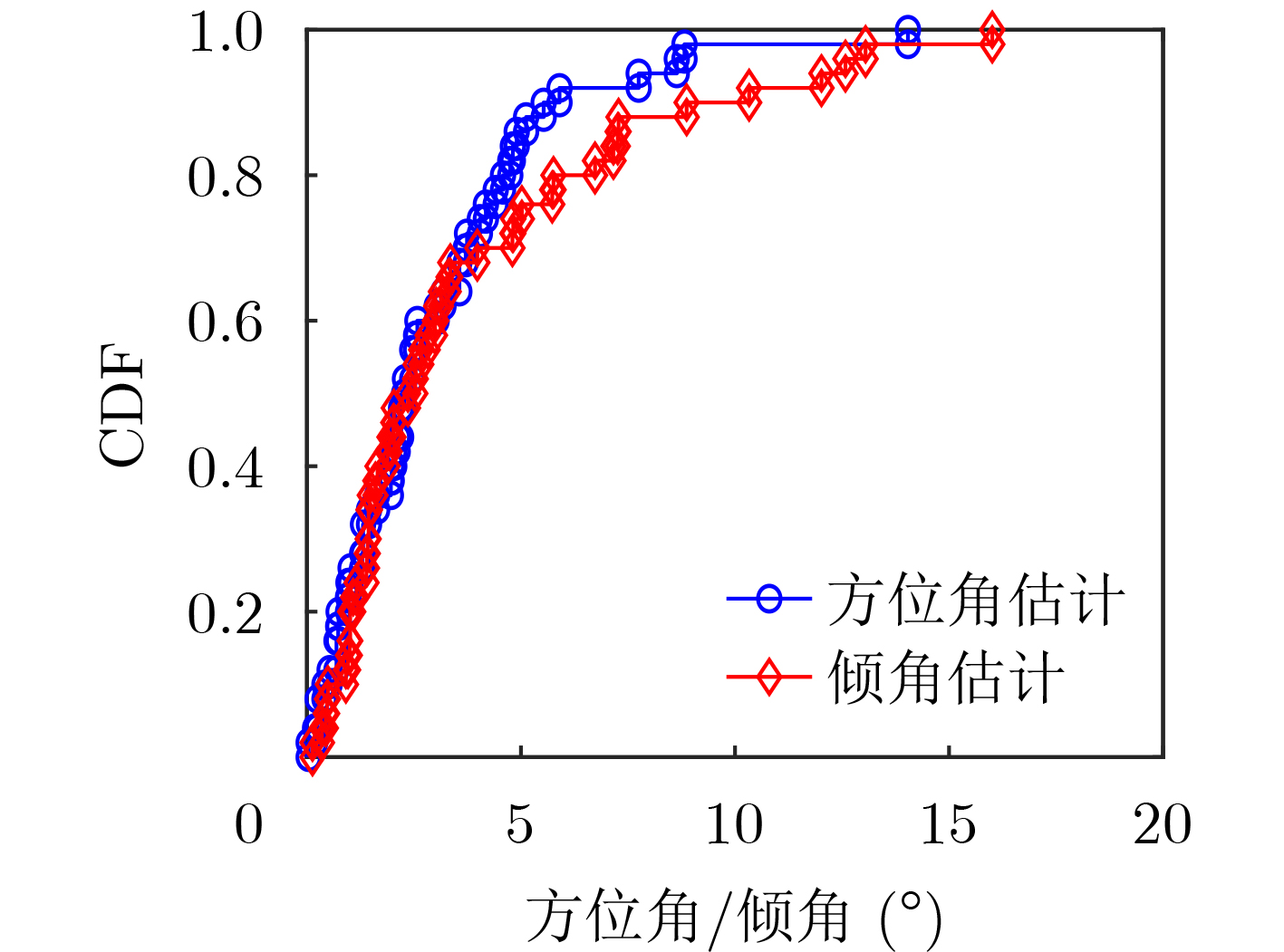
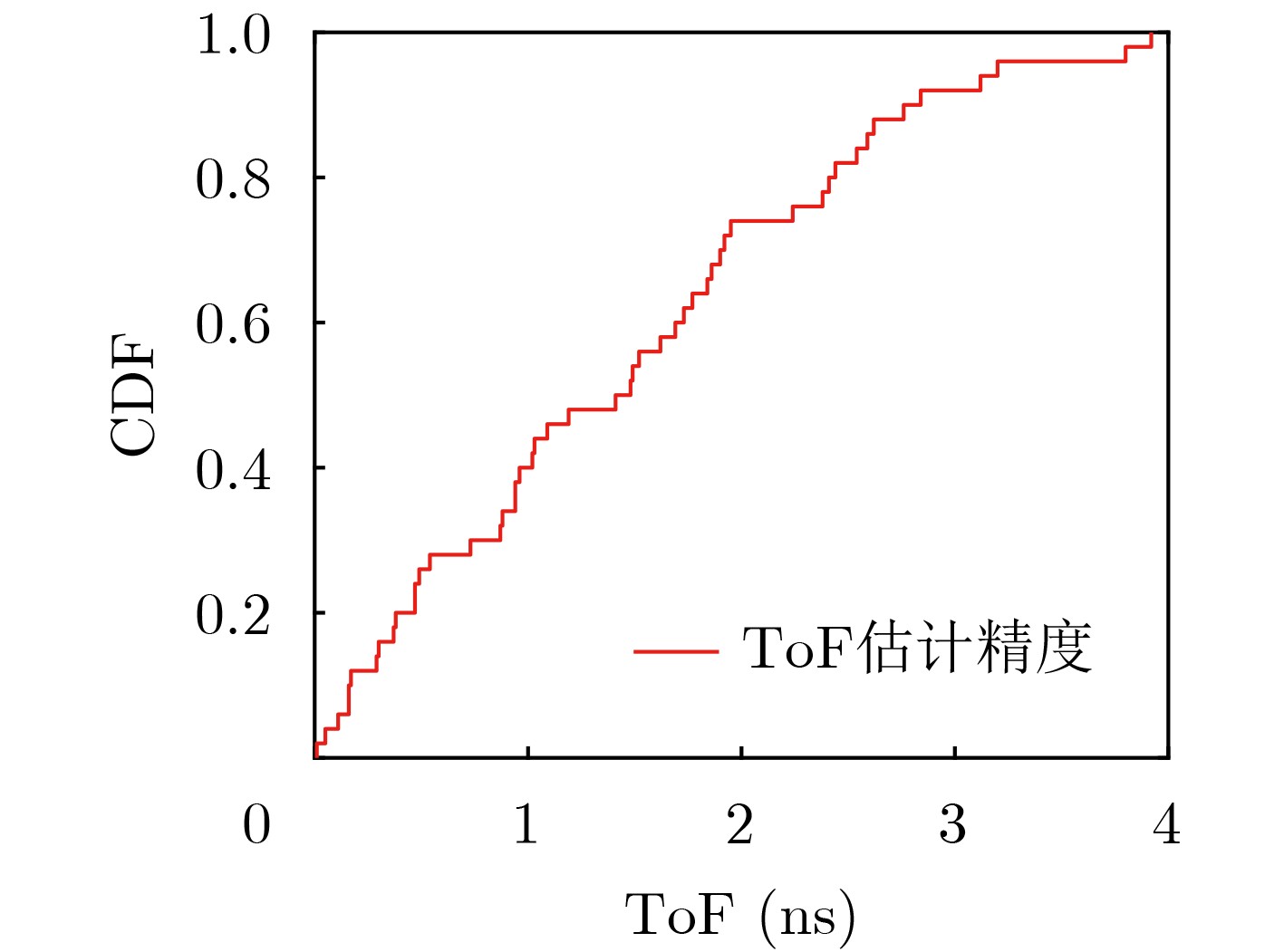
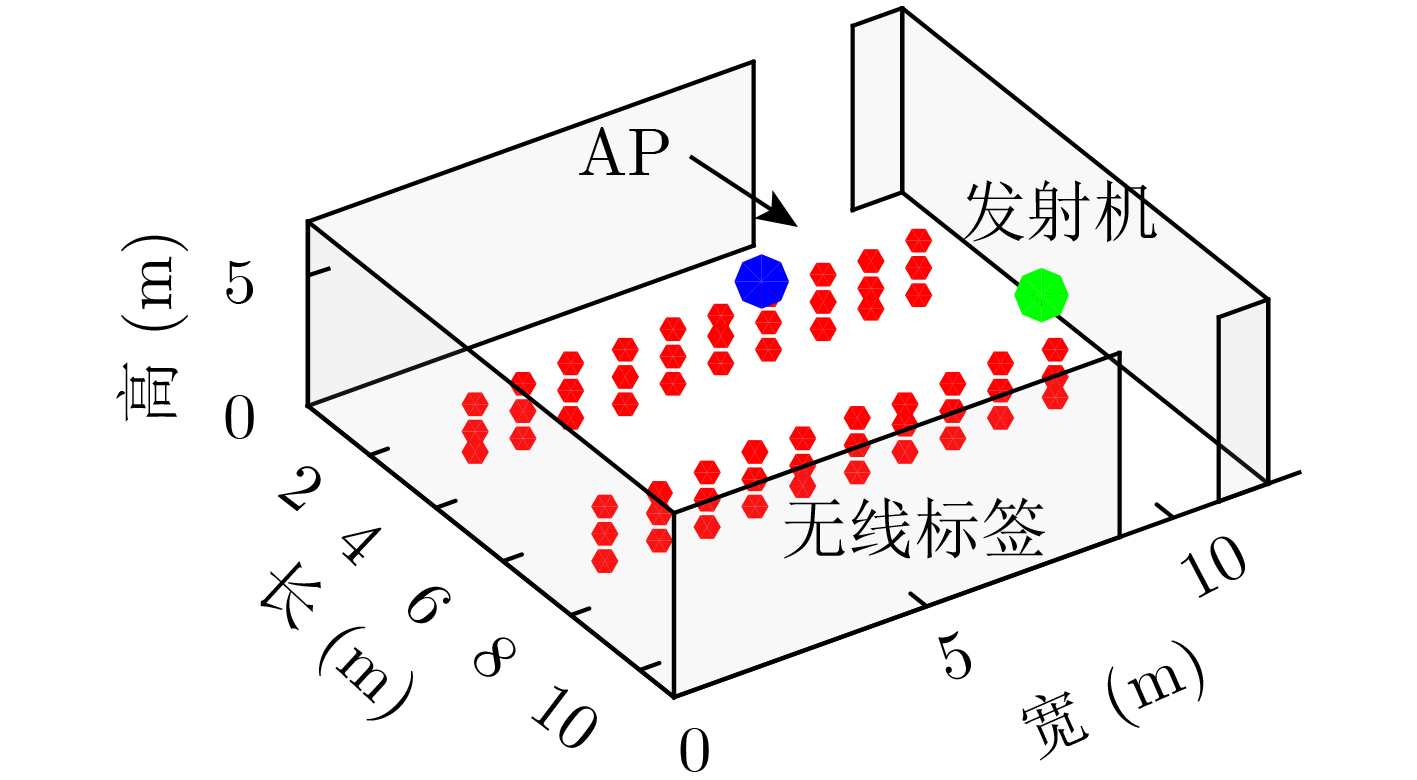
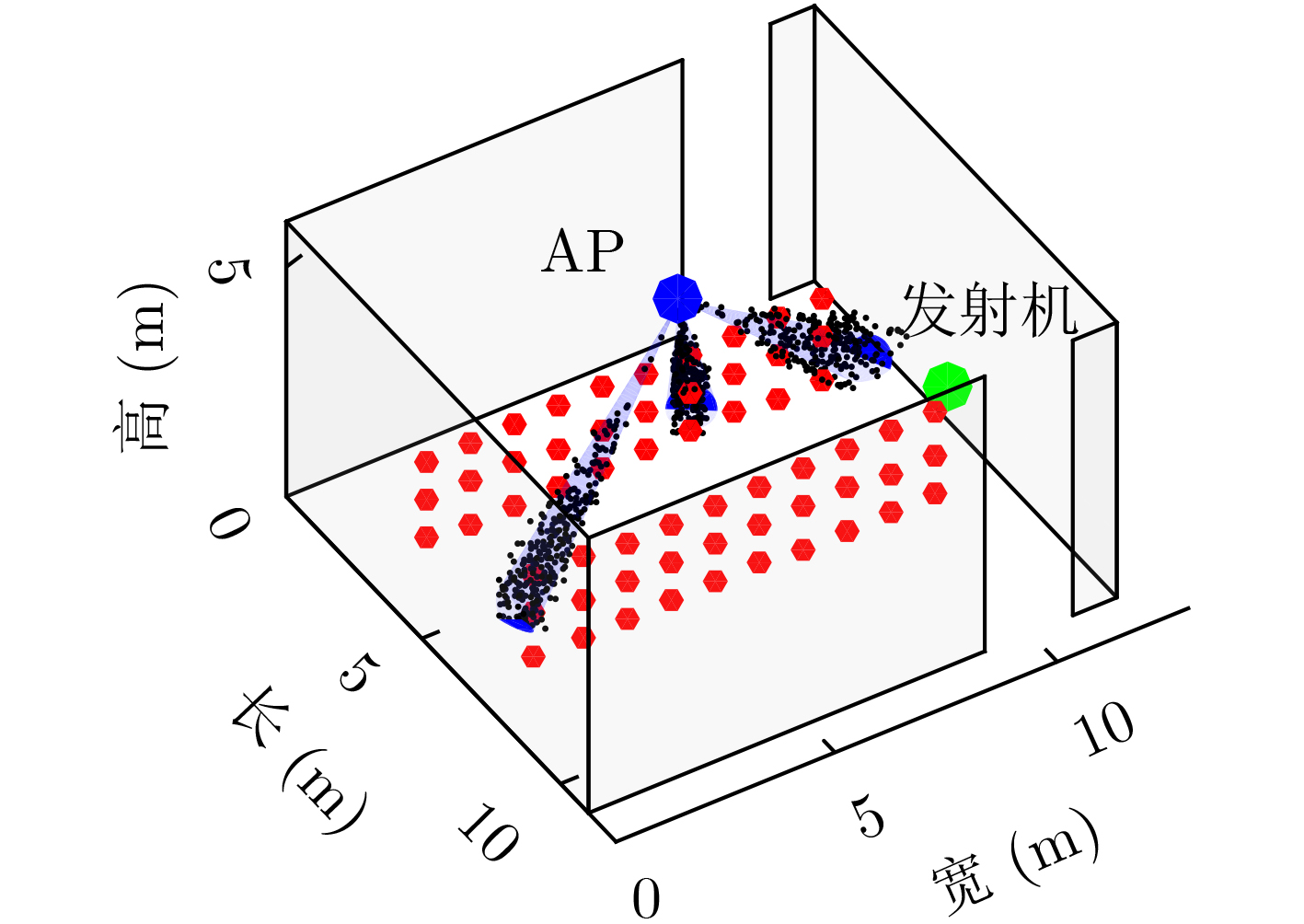
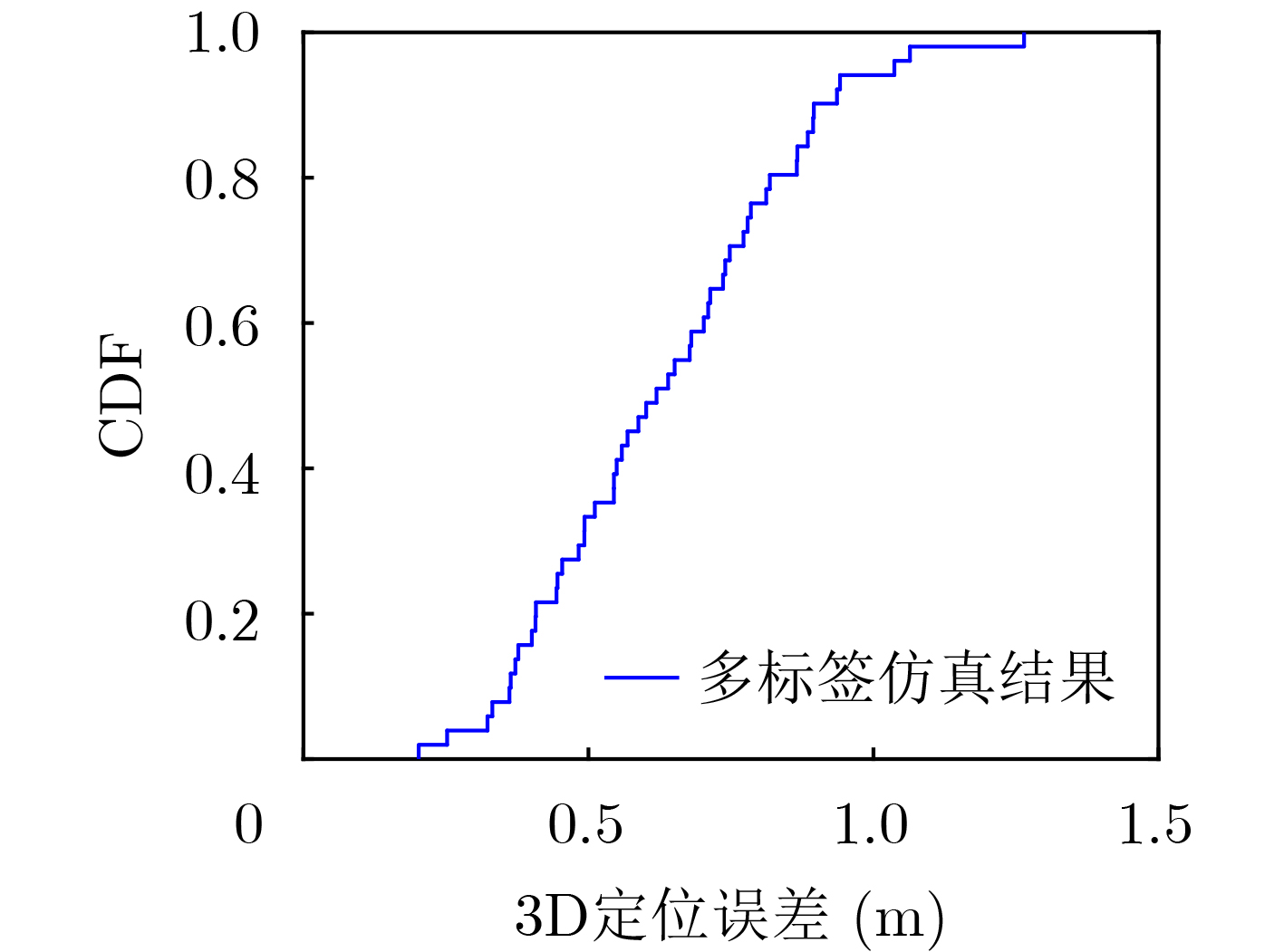
摘要: 仓储行业在面向智能化发展中面临因无法获取物资的室内位置信息而导致出库、入库难等问题,为实现对物资准确定位,该文提出一种基于无线标签的目标3维定位方法。设计的无线标签安置在待定位物资上,将来自发射机正交频分复用(OFDM)信号反射到具有均匀面阵(UPA)天线阵列的接收机,进行多通道的信道估计后,利用分步的稀疏恢复算法实现高维无线信道参数估计,并结合发射机、标签和接收机的空间几何位置,建立标签位置的优化问题,最后采用群智能算法搜索得到目标准确的3维位置。为验证系统,实现了标签及收发机原型,实测结果表明,目标的中值3维定位精度达到0.53 m。Abstract: The warehousing industry is striding forward in the direction of intelligence. Still, the challenges of in-storage and out-storage, caused by the lack of location information of goods indoors, hinder it. To achieve accurate localization of goods, a 3-D localization method based on wireless tags is proposed. The designed tags are mounted on the goods, reflecting the Orthogonal Frequency Division Multiplexing (OFDM) signals from the transmitter. The receiver with a Uniform Planar Array (UPA) as receiving antenna receives the signals and gets the channel estimates on multiple antenna channels. Then, the multi-dimensional wireless channel parameters are obtained using the two-step sparse recovery algorithm. An optimization problem for solving the unknown tags' locations is built according to the geometric locations of the receiver, transmitter, and tags in 3-D space. Finally, the swarm intelligence method is utilized to search accurately the tags' locations. The tag prototype, OFDM transmitter, and receiver are realized to validate the system based on the proposed scheme. Experimental results demonstrate that the system can achieve a 3-D median accuracy of 0.53 m.
-
[1] 房殿军. 仓储物流技术发展趋势分析[J]. 物流技术与应用, 2020, 25(6): 90–95. doi: 10.3969/j.issn.1007-1059.2020.06.009FANG Dianjun. Analysis of development trend of warehousing logistics technology[J]. Logistics &Material Handling, 2020, 25(6): 90–95. doi: 10.3969/j.issn.1007-1059.2020.06.009 [2] 钱志鸿, 田春生, 郭银景, 等. 智能网联交通系统的关键技术与发展[J]. 电子与信息学报, 2020, 42(1): 2–19. doi: 10.11999/JEIT190787QIAN Zhihong, TIAN Chunsheng, GUO Yinjing, et al. The key technology and development of intelligent and connected transportation system[J]. Journal of Electronics &Information Technology, 2020, 42(1): 2–19. doi: 10.11999/JEIT190787 [3] BOTTIGLIERO S, MILANESIO D, SACCANI M, et al. A low-cost indoor real-time locating system based on TDOA estimation of UWB pulse sequences[J]. IEEE Transactions on Instrumentation and Measurement, 2021, 70: 5502211. doi: 10.1109/TIM.2021.3069486 [4] LUO Zhihong, ZHANG Qiping, MA Yunfei, et al. 3D backscatter localization for fine-grained robotics[C]. The 16th USENIX Conference on Networked Systems Design and Implementation, Boston, USA, 2019: 765–781. [5] WU Haibing, TAO Bo, GONG Zeyu, et al. A fast UHF RFID localization method using unwrapped phase-position model[J]. IEEE Transactions on Automation Science and Engineering, 2019, 16(4): 1698–1707. doi: 10.1109/TASE.2019.2895104 [6] KOTARU M, JOSHI K, BHARADIA D, et al. SpotFi: Decimeter level localization using WiFi[C]. The 2015 ACM Conference on Special Interest Group on Data Communication, London, UK, 2015: 269–282. [7] KOTARU M, ZHANG Pengyu, and KATTI S. Localizing low-power backscatter tags using commodity WiFi[C]. The 13th International Conference on emerging Networking Experiments and Technologies, Incheon, Korea, 2017: 251–262. [8] CHUO Lixuan, LUO Zhihong, SYLVESTER D, et al. RF-Echo: A non-line-of-sight indoor localization system using a low-power active RF reflector ASIC tag[C]. The 23rd Annual International Conference on Mobile Computing and Networking, Utah: USA, 2017: 222–234. [9] SOLTANAGHAEI E, DONGARE A, PRABHAKARA A, et al. TagFi: Locating ultra-low power WiFi tags using unmodified WiFi infrastructure[J]. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 2021, 5(1): 34. doi: 10.1145/3448082 [10] TROPP J A and GILBERT A C. Signal recovery from random measurements via orthogonal matching pursuit[J]. IEEE Transactions on Information Theory, 2007, 53(12): 4655–4666. doi: 10.1109/TIT.2007.909108 [11] LUO Jiaqing and SHIN K G. Detecting misplaced RFID tags on static shelved items[C]. The 17th Annual International Conference on Mobile Systems, Applications, and Services, Seoul, Korea, 2019: 378–390. [12] ABEDI A, DEHBASHI F, MAZAHERI M H, et al. WiTAG: Seamless WiFi backscatter communication[C]. The Annual Conference of the ACM Special Interest Group on Data Communication on the Applications, Technologies, Architectures, and Protocols for Computer Communication, New York, USA, 2020: 240–252. [13] CHEN Zhe, ZHU Guorong, WANG Sulei, et al. M3: Multipath assisted Wi-Fi localization with a single access point[J]. IEEE Transactions on Mobile Computing, 2021, 20(2): 588–602. doi: 10.1109/TMC.2019.2950315 [14] SAHOO S K and MAKUR A. Signal recovery from random measurements via extended orthogonal matching pursuit[J]. IEEE Transactions on Signal Processing, 2015, 63(10): 2572–2581. doi: 10.1109/TSP.2015.2413384 [15] LIU Kaikai, TIAN Zengshan, LI Ze, et al. HiLoc: Sub-meter level indoor localization using a single access point with distributed antennas in wireless sensor networks[J]. IEEE Sensors Journal, 2022, 22(6): 4869–4881. doi: 10.1109/JSEN.2020.3048903 [16] XIE Yaxiong, XIONG Jie, LI Mo, et al. mD-Track: Leveraging multi-dimensionality for passive indoor Wi-Fi tracking[C]. The 25th Annual International Conference on Mobile Computing and Networking, Los Cabos, Mexico, 2019: 8. [17] KAZAZ T, JANSSEN G J M, ROMME J, et al. Delay estimation for ranging and localization using multiband channel state information[J]. IEEE Transactions on Wireless Communications, 2022, 21(4): 2591–2607. doi: 10.1109/TWC.2021.3113771 [18] JAIN M, CHOI J I, KIM T, et al. Practical, real-time, full duplex wireless[C]. The 17th Annual International Conference on Mobile Computing and Networking, Nevada, USA, 2011: 301–312. [19] ANDERSON C R, KRISHNAMOORTHY S, RANSON C G, et al. Antenna isolation, wideband multipath propagation measurements, and interference mitigation for on-frequency repeaters[C]. IEEE SoutheastCon, 2004 Proceedings, USA, 2004: 110–114. [20] ZHANG Pengyu, JOSEPHSON C, BHARADIA D, et al. FreeRider: Backscatter communication using commodity radios[C]. The 13th International Conference on Emerging Networking Experiments and Technologies, Incheon, Korea, 2017: 389–401. -

 下载:
下载:






图(18) / 表(1)
计量
- 文章访问数: 971
- HTML全文浏览量: 724
- PDF下载量: 154
- 被引次数: 0
