

Discriminant Adversarial Hashing Transformer for Cross-modal Vessel Image Retrieval
-
摘要: 针对当前主流的基于卷积神经网络(CNN)范式的跨模态图像检索算法无法有效提取舰船图像细节特征,以及跨模态“异构鸿沟”难以消除等问题,该文提出一种基于对抗机制的判别性哈希变换器(DAHT)用于舰船图像的跨模态快速检索。该网络采用双流视觉变换器(ViT)结构,依托ViT的自注意力机制进行舰船图像的判别性特征提取,并设计了Hash Token结构用于哈希生成;为了消除同类别图像的跨模态差异,整个检索框架以一种对抗的方式进行训练,通过对生成哈希码进行模态辨别实现模态混淆;同时设计了一种基于反馈机制的跨模加权5元组损失(NW-DCQL)以保持网络对不同类别图像的语义区分性。在两组数据集上开展的4类跨模态检索实验中,该文方法相比次优检索结果分别取得了9.8%, 5.2%, 19.7%, 21.6%的性能提升(32 bit),在单模态检索任务中亦具备一定的性能优势。Abstract: In view of the problems that the current mainstream cross-modal image retrieval algorithm based on Convolutional Neural Network (CNN) paradigm can not extract details of ship images effectively, and the cross-modal “heterogeneous gap” is difficult to eliminate, a Discriminant Adversarial Hash Transformer (DAHT) is proposed for fast cross-modal retrieval of ship images. The network adopts dual-stream Vision Transformer(ViT) structure and relies on the self-attention mechanism of ViT to extract the discriminant features of ship images. Based on this, a Hash Token structure is designed for Hash generation. In order to eliminate the cross-modal difference of the same category image, the whole retrieval framework is trained in an adversarial way, and modal confusion is realized by modal discrimination of generated Hash codes. At the same time, a Normalized discounted cumulative gain Weighting based Discriminant Cross-modal Quintuplet Loss (NW-DCQL) is designed to maintain the semantic discrimination of different types of images. In the four types of cross-modal retrieval tasks carried out on two datasets, the proposed method achieves 9.8 %, 5.2 %, 19.7 %, and 21.6 % performance improvement compared with the suboptimal retrieval results (32 bit), and also has certain performance advantages in unimodal retrieval tasks.
-
Key words:
- Cross-modal retrieval /
- Vessel image /
- Adversarial training /
- Hash transform /
- Transformer
-
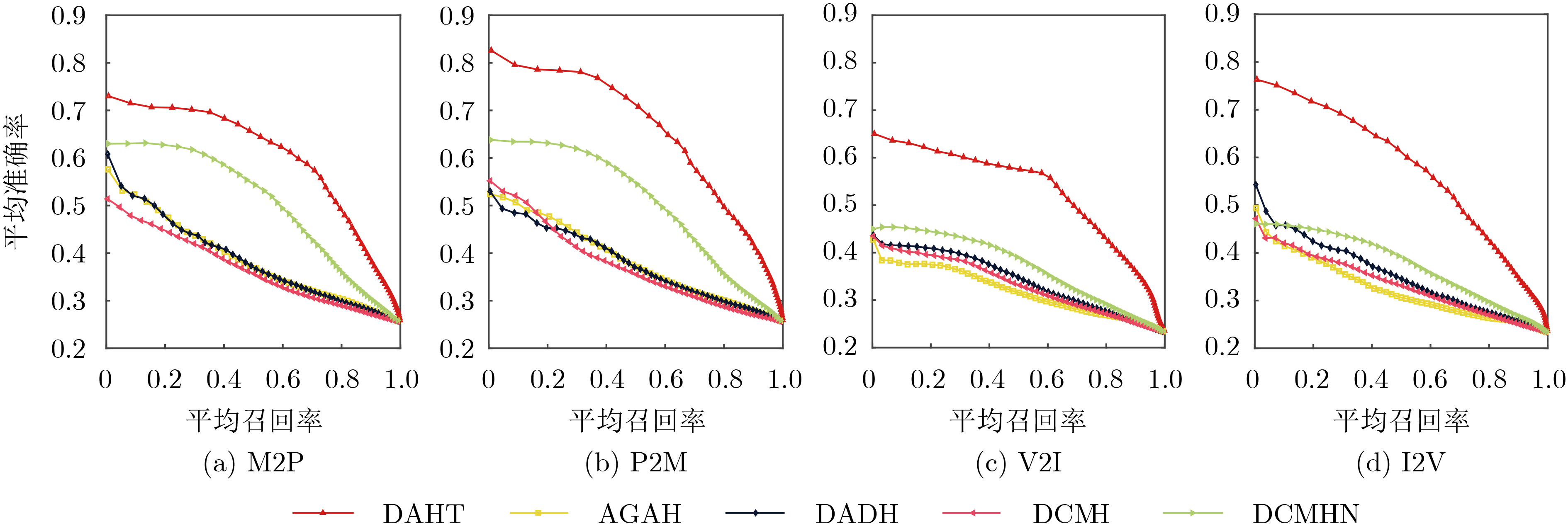
表 2 不同哈希码长度下跨模态检索mAP值对比
数据集 方法 检索任务 32 bit 64 bit 128 bit 256 bit MPSC DAHT M2P 0.696 0.691 0.696 0.693 P2M 0.715 0.713 0.729 0.714 AGAH M2P 0.437 0.444 0.432 0.437 P2M 0.446 0.457 0.443 0.446 DADH M2P 0.455 0.458 0.446 0.432 P2M 0.453 0.461 0.470 0.439 DCMH M2P 0.378 0.400 0.332 0.440 P2M 0.346 0.370 0.268 0.422 DCMHN M2P 0.598 0.589 0.601 0.599 P2M 0.563 0.561 0.593 0.568 VAIS DACH V2I 0.599 0.582 0.617 0.603 I2V 0.603 0.615 0.611 0.635 AGAH V2I 0.390 0.401 0.387 0.368 I2V 0.369 0.390 0.383 0.361 DADH V2I 0.389 0.398 0.401 0.413 I2V 0.386 0.392 0.387 0.388 DCMH V2I 0.401 0.404 0.403 0.396 I2V 0.384 0.368 0.384 0.372 DCMHN V2I 0.402 0.399 0.411 0.428 I2V 0.387 0.379 0.402 0.404  下载: 导出CSV
下载: 导出CSV
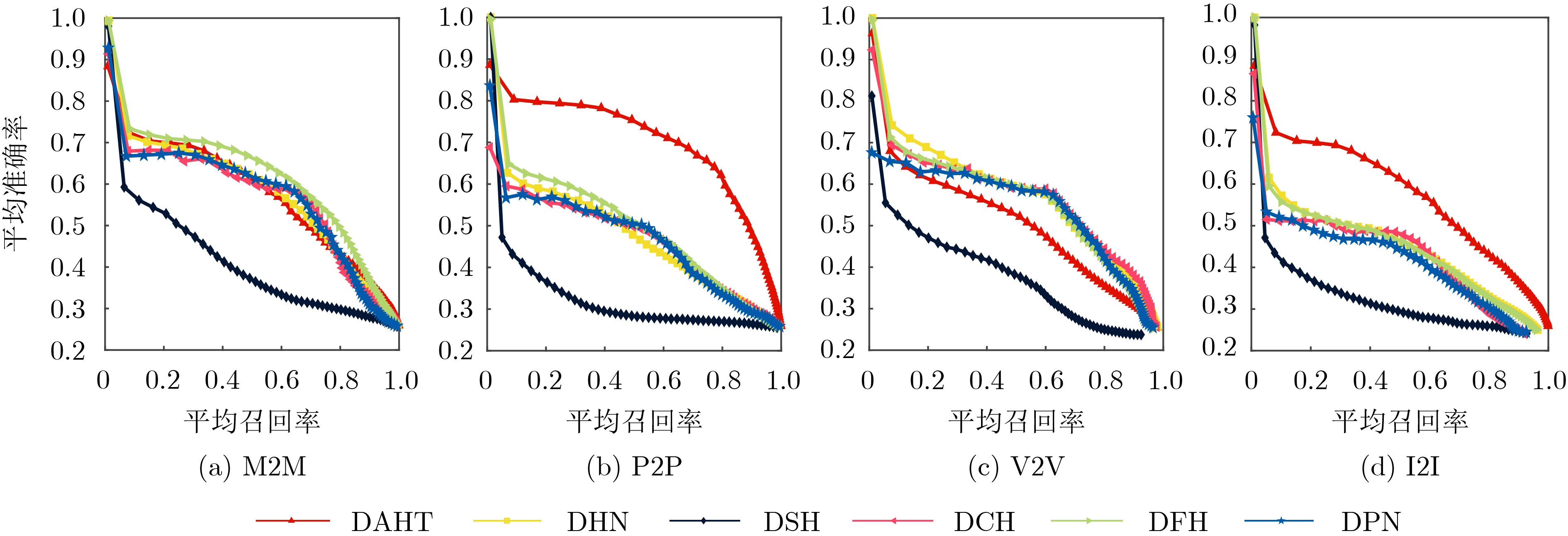
表 3 不同哈希码长度下单模态检索mAP值对比
数据集 方法 检索任务 32 bit 64 bit 128 bit 256 bit MPSC DAHT M2M 0.648 0.548 0.657 0.640 P2P 0.777 0.759 0.781 0.780 DHN M2M 0.678 0.685 0.668 0.651 P2P 0.545 0.551 0.559 0.543 DSH M2M 0.501 0.471 0.485 0.476 P2P 0.366 0.405 0.388 0.360 DCH M2M 0.695 0.683 0.692 0.669 P2P 0.561 0.557 0.572 0.544 DFH M2M 0.665 0.700 0.691 0.695 P2P 0.569 0.568 0.570 0.572 DPN M2M 0.646 0.651 0.659 0.654 P2P 0.532 0.551 0.536 0.553 VAIS DAHT V2V 0.637 0.625 0.639 0.633 I2I 0.719 0.743 0.752 0.736 DHN V2V 0.613 0.602 0.620 0.641 I2I 0.504 0.529 0.509 0.510 DSH V2V 0.571 0.554 0.494 0.442 I2I 0.468 0.416 0.397 0.356 DCH V2V 0.631 0.659 0.667 0.656 I2I 0.512 0.529 0.521 0.499 DFH V2V 0.622 0.648 0.642 0.633 I2I 0.510 0.525 0.514 0.509 DPN V2V 0.620 0.634 0.663 0.645 I2I 0.487 0.491 0.492 0.489
下载: 导出CSV
表 4 消融实验mAP值
网络 跨模态检索 单模态检索 M2P P2M V2I I2V M2M P2P V2V I2I DAHT-1 0.680 0.691 0.601 0.615 0.636 0.764 0.540 0.722 DAHT-2 0.600 0.655 0.595 0.591 0.600 0.755 0.519 0.725 DAHT-3 0.682 0.689 0.591 0.584 0.630 0.761 0.534 0.707 DAHT-4 0.668 0.679 0.600 0.595 0.630 0.731 0.509 0.726 DAHT-5 0.608 0.631 0.555 0.579 0.566 0.725 0.521 0.661 DAHT-6 0.668 0.692 0.588 0.596 0.638 0.762 0.529 0.715 DAHT 0.693 0.714 0.603 0.635 0.640 0.780 0.553 0.736
下载: 导出CSV
表 5 不同方法训练时间及参数量对比
DAHT DAHT-5 DAHT-6 AGAH DADH DCMH DCMHN DHN DSH DCH DFH DPN 训练时间(s) 49.61 30.87 53.10 13.91 17.05 10.84 15.98 11.63 11.85 11.57 12.90 11.75 参数量(M) 85.8 25.6 85.8 57.5 50.8 47.1 53.8 23.6 23.6 23.6 23.6 23.6
下载: 导出CSV
-
[1] MUKHERJEE S, COHEN S, and GERTNER I. Content-based vessel image retrieval[J]. SPIE Automatic Target Recognition XXVI, Baltimore, USA, 2016, 9844: 984412. [2] 何柏青, 王自敏. 反馈机制的大规模舰船图像检索[J]. 舰船科学技术, 2018, 40(4A): 157–159. doi: 10.3404/j.issn.1672-7649.2018.4A.053HE Baiqing and WANG Zimin. The feedback mechanism of large-scale ship image retrieval[J]. Ship Science and Technology, 2018, 40(4A): 157–159. doi: 10.3404/j.issn.1672-7649.2018.4A.053 [3] LI Yansheng, ZHANG Yongjun, HUANG Xin, et al. Learning source-invariant deep hashing convolutional neural networks for cross-source remote sensing image retrieval[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(11): 6521–6536. doi: 10.1109/TGRS.2018.2839705 [4] XIONG Wei, LV Yafei, ZHANG Xiaohan, et al. Learning to translate for cross-source remote sensing image retrieval[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(7): 4860–4874. doi: 10.1109/TGRS.2020.2968096 [5] ZHU Junyan, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2242–2251. [6] XIONG Wei, XIONG Zhenyu, CUI Yaqi, et al. A discriminative distillation network for cross-source remote sensing image retrieval[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020, 13: 1234–1247. doi: 10.1109/JSTARS.2020.2980870 [7] SUN Yuxi, FENG Shanshan, YE Yunming, et al. Multisensor fusion and explicit semantic preserving-based deep hashing for cross-modal remote sensing image retrieval[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5219614. doi: 10.1109/TGRS.2021.3136641 [8] HU Peng, PENG Xi, ZHU Hongyuan, et al. Learning cross-modal retrieval with noisy labels[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 5399–5409. [9] XU Xing, SONG Jingkuan, LU Huimin, et al. Modal-adversarial semantic learning network for extendable cross-modal retrieval[C]. 2018 ACM on International Conference on Multimedia Retrieval, Yokohama, Japan, 2018: 46–54. [10] WANG Bokun, YANG Yang, XU Xing, et al. Adversarial cross-modal retrieval[C]. The 25th ACM International Conference on Multimedia, Mountain View, USA, 2017: 154–162. [11] DONG Xinfeng, LIU Li, ZHU Lei, et al. Adversarial graph convolutional network for cross-modal retrieval[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(3): 1634–1645. doi: 10.1109/TCSVT.2021.3075242 [12] GU Wen, GU Xiaoyan, GU Jingzi, et al. Adversary guided asymmetric hashing for cross-modal retrieval[C]. 2019 on International Conference on Multimedia Retrieval, Ottawa, Canada, 2019: 159–167. [13] HU Rong, YANG Jie, ZHU Bangpei, et al. Research on ship image retrieval based on BoVW model under hadoop platform[C]. The 1st International Conference on Information Science and Systems, Jeju, Korea, 2018: 156–160. [14] TIAN Chi, XIA Jinfeng, TANG Ji, et al. Deep image retrieval of large-scale vessels images based on BoW model[J]. Multimedia Tools and Applications, 2020, 79(13/14): 9387–9401. doi: 10.1007/s11042-019-7725-y [15] 邹利华. 基于PCA降维的舰船图像检索方法[J]. 舰船科学技术, 2020, 42(24): 97–99.ZOU Lihua. Research on ship image retrieval method based on PCA dimension reduction[J]. Ship Science and Technology, 2020, 42(24): 97–99. [16] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C/OL]. The 9th International Conference on Learning Representations, 2021. [17] HERMANS A, BEYER L, and LEIBE B. In defense of the triplet loss for person re-identification[J]. arXiv: 1703.07737, 2017. [18] LI Tao, ZHANG Zheng, PEI Lishen, et al. HashFormer: Vision transformer based deep hashing for image retrieval[J]. IEEE Signal Processing Letters, 2022, 29: 827–831. doi: 10.1109/LSP.2022.3157517 [19] LI Mengyang, SUN Weiwei, DU Xuan, et al. Ship classification by the fusion of panchromatic image and multi-spectral image based on pseudo siamese LightweightNetwork[J]. Journal of Physics: Conference Series, 2021, 1757: 012022. [20] ZHANG M M, CHOI J, DANIILIDIS K, et al. VAIS: A dataset for recognizing maritime imagery in the visible and infrared spectrums[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, USA, 2015: 10–16. [21] 关欣, 国佳恩, 衣晓. 基于低秩双线性池化注意力网络的舰船目标识别[J]. 系统工程与电子技术, 2023, 45(5): 1305–1314.GUAN Xin, GUO Jiaen, and YI Xiao. Low rank bilinear pooling attention network for ship target recognition[J]. Systems Engineering and Electronics, 2023, 45(5): 1305–1314. [22] BAI Cong, ZENG Chao, MA Qing, et al. Deep adversarial discrete hashing for cross-modal retrieval[C]. 2020 International Conference on Multimedia Retrieval, Dublin, Ireland, 2020: 525–531. [23] JIANG Qingyuan and LI Wujun. Deep cross-modal hashing[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 3270–3278. [24] XIONG Wei, XIONG Zhenyu, ZHANG Yang, et al. A deep cross-modality hashing network for SAR and optical remote sensing images retrieval[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020, 13: 5284–5296. doi: 10.1109/JSTARS.2020.3021390 [25] ZHU Han, LONG Mingsheng, WANG Jianmin, et al. Deep hashing network for efficient similarity retrieval[C]. The Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, USA, 2016: 2415–2421. [26] LIU Haomiao, WANG Ruiping, SHAN Shiguang, et al. Deep supervised hashing for fast image retrieval[J]. International Journal of Computer Vision, 2019, 127(9): 1217–1234. doi: 10.1007/s11263-019-01174-4 [27] CAO Yue, LONG Mingsheng, LIU Bin, et al. Deep Cauchy hashing for hamming space retrieval[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 1229–1237. [28] LI Yunqiang, PEI Wenjie, ZHA Yufei, et al. Push for quantization: Deep fisher hashing[C]. The 30th British Machine Vision Conference 2019, Cardiff, UK, 2019. [29] FAN Lixin, NG K W, JU Ce, et al. Deep polarized network for supervised learning of accurate binary hashing codes[C]. The Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 2020: 825–831. -

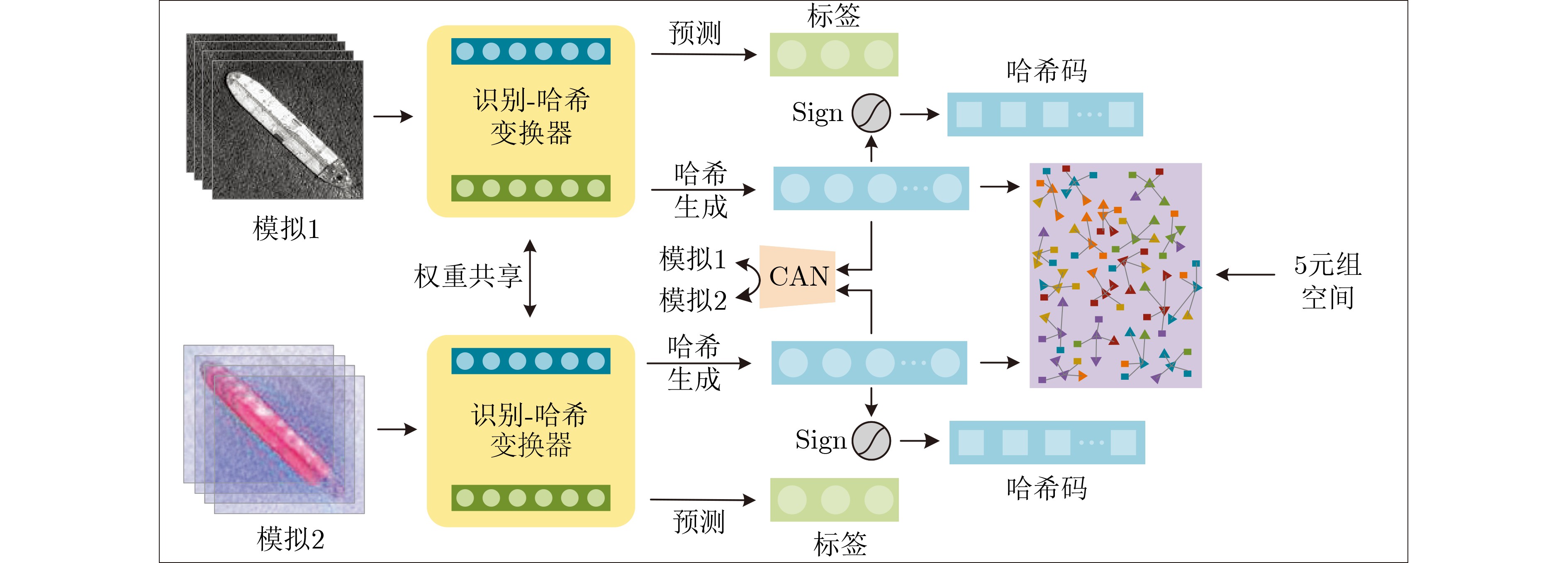
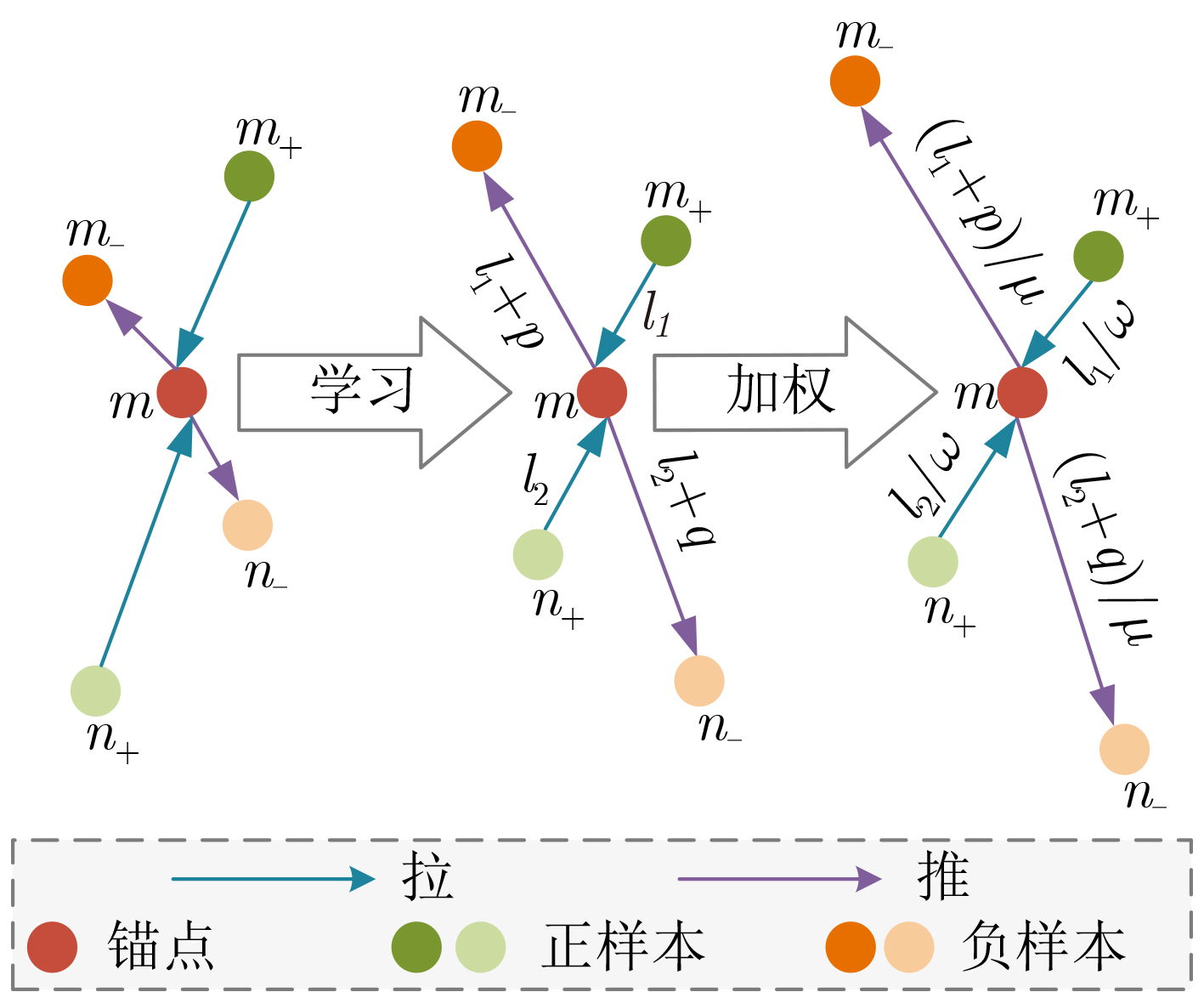
 下载:
下载:

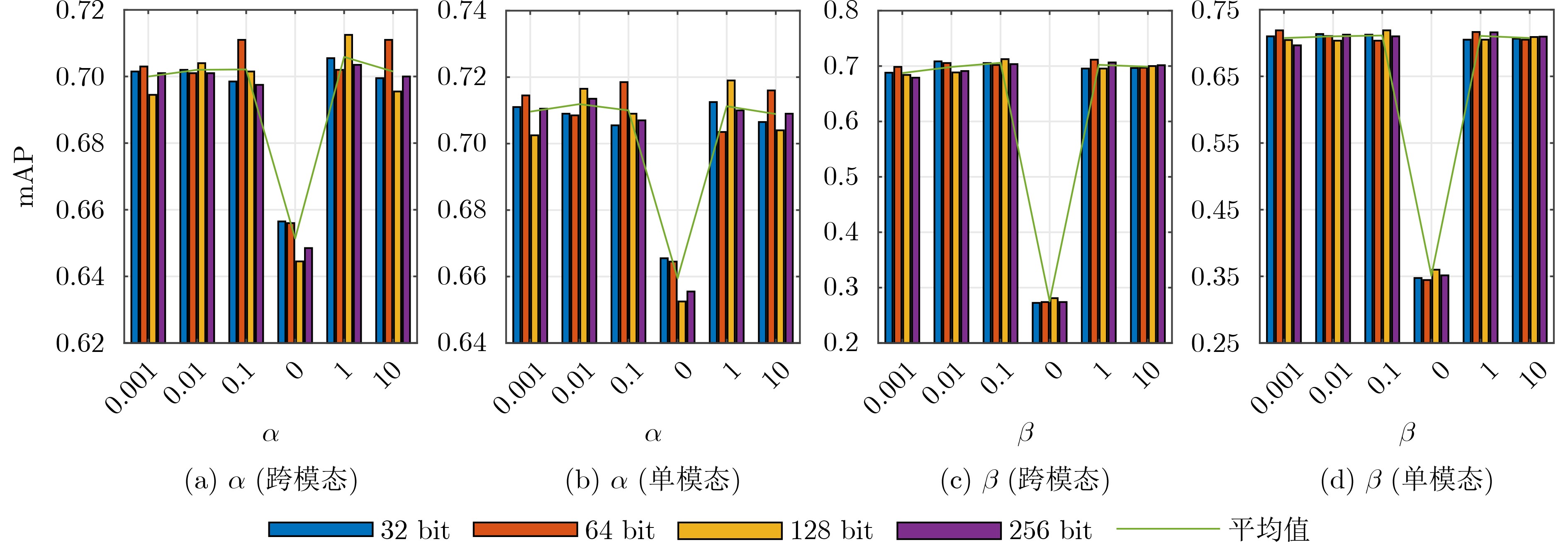


图(6) / 表(5)
计量
- 文章访问数: 1026
- HTML全文浏览量: 694
- PDF下载量: 142
- 被引次数: 0
