

A High Precision Parallel Principal Skewness Analysis Algorithm and Its Application to Remote Sensing Images
-
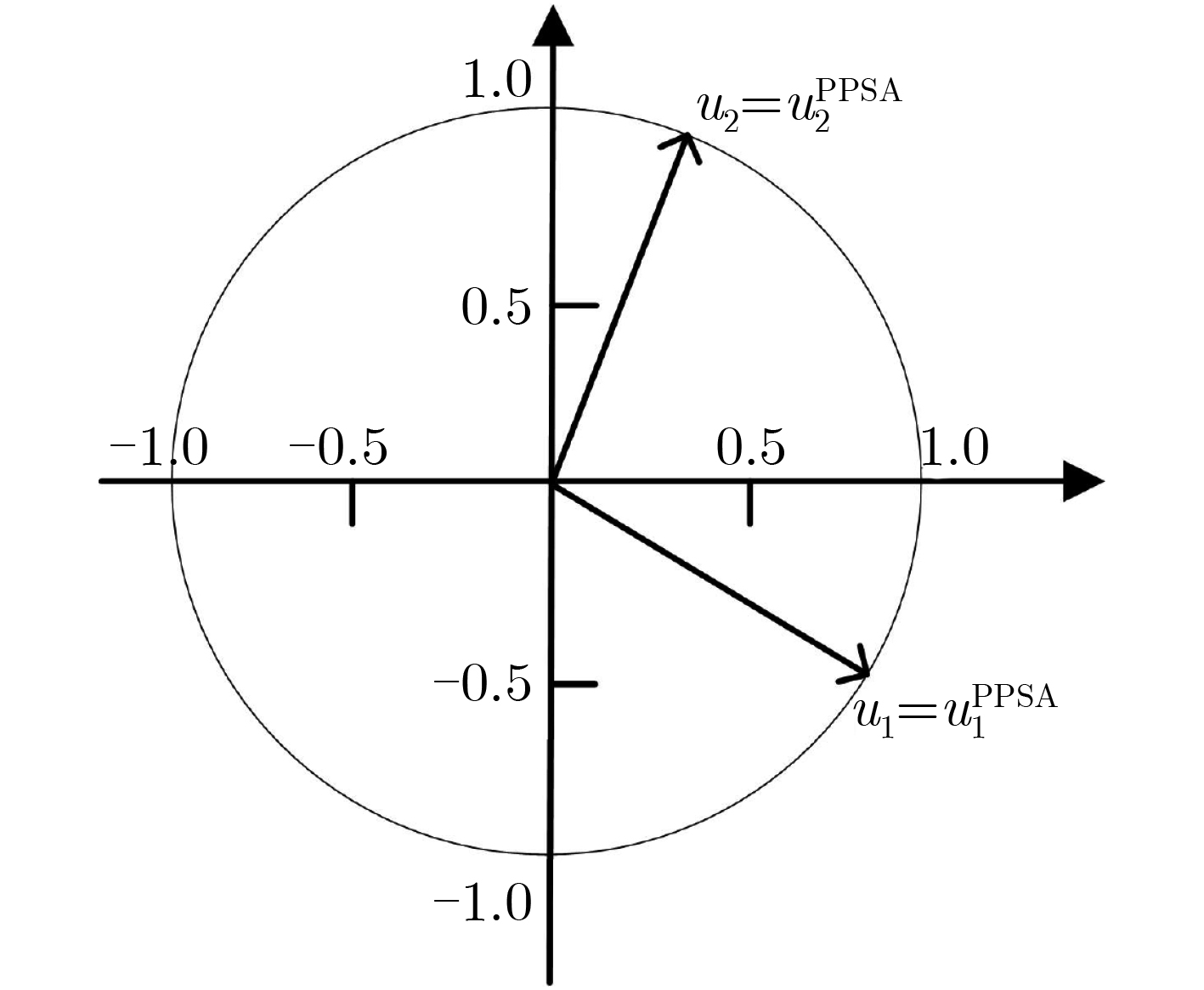
摘要: 主偏度分析(PSA)作为主成分分析(PCA)的一种3阶推广,常用于盲图像分离、SAR图像去噪以及高光谱特征提取等。但现有PSA算法只能得到近似解,这会影响图像后续处理的精度。针对这一问题,该文在现有PSA算法基础上,提出了一种高精度并行主偏度分析(PPSA)算法。PPSA算法充分考虑数据结构,选用协偏度张量的全部切片的特征向量作为迭代的初始值,可以准确地得到实际解。仿真实验以及实际遥感图像实验验证了PPSA算法的有效性与优越性。Abstract: Principal Skewness Analysis (PSA), as a third-order extension of Principal Component Analysis (PCA), is often used for blind image separation, SAR image denoising, and hyperspectral feature extraction. However, the existing PSA algorithm can only obtain approximate solutions, which will affect the accuracy of subsequent image processing. In view of this problem, a high-precision Parallel Principal Skewness Analysis (PPSA) algorithm based on the existing PSA algorithm is proposed. The PPSA algorithm considers fully the data structure, and selects the eigenvectors of all slices of the co-skewness tensor as the initial value of the iteration, which can accurately obtain the actual solution. Simulation experiments and actual remote sensing image experiments verify the effectiveness and superiority of the PSA algorithm.
-
Key words:
- Image separation /
- Image denoising /
- Principal Skewness Analysis (PSA) /
- High precision /
- Parallel /
- Feature extraction
-
算法1 PPSA算法 输入:输入数据${\boldsymbol{R}} \in {{\boldsymbol{R}}^{L \times N} }$ 输出:输出变换矩阵${\boldsymbol{U}}$, ${\boldsymbol{Y}} = {{\boldsymbol{U}}^{\rm{T}}}\tilde {\boldsymbol{R}}$ (1) 白化数据,得到$\tilde {\boldsymbol{R}}$ (2) 根据式(1)计算m阶$L $维张量${\boldsymbol{S}}$ (3) 计算张量${\boldsymbol{S}}$切片的所有特征向量,记为V% main loop: % (4) ${\text{for }}i = 1:{L^2}{\text{ do}} $ (5) k = 0 (6) ${\boldsymbol{u}}_i^{(k)} = {\boldsymbol{V}}(:,i)$ (7) while stop conditions are not meet do (8) ${\boldsymbol{u}}_i^{(k + 1)} = {\boldsymbol{S}}{ \times _1}{\boldsymbol{u}}_i^{(k + 1)}{ \times _3}{\boldsymbol{u}}_i^{(k + 1)}$ (9) ${\boldsymbol{u}}_i^{(k + 1)} = {\boldsymbol{u}}_i^{(k + 1)}/{\left\| {{\boldsymbol{u}}_i^{(k + 1)} } \right\|_2}$ (10) end while (11) ${{\boldsymbol{U}}_{:i} } = {\boldsymbol{u}}_i^{(k + 1)}$ (12) end for  下载: 导出CSV
下载: 导出CSV
表 1 不同初始化方法的比较,选取n个初始值计算100 000次的结果
随机选取$n$个初始值 随机选取$n$个正交初始值 单个切片的特征向量作为初始值 2 49027 89073 98270 3 12864 53080 98029 4 7450 35373 97222 5 2361 15565 85831 6 836 5171 50430 7 89 281 35851 8 27 129 19981 9 8 29 17004
下载: 导出CSV
表 2 不同初始化方法的比较,选取n × n个初始值计算100 000次的结果
随机选取$ n \times n $个初始值 随机选取$ n \times n $正交初始值 全部切片的特征向量作为初始值 2 90833 98184 99997 3 88401 92830 99999 4 88225 90029 99989 5 85646 88451 99994 6 79673 70096 99988 7 79382 69156 99974 8 77576 68546 99991 9 64338 66570 99938
下载: 导出CSV
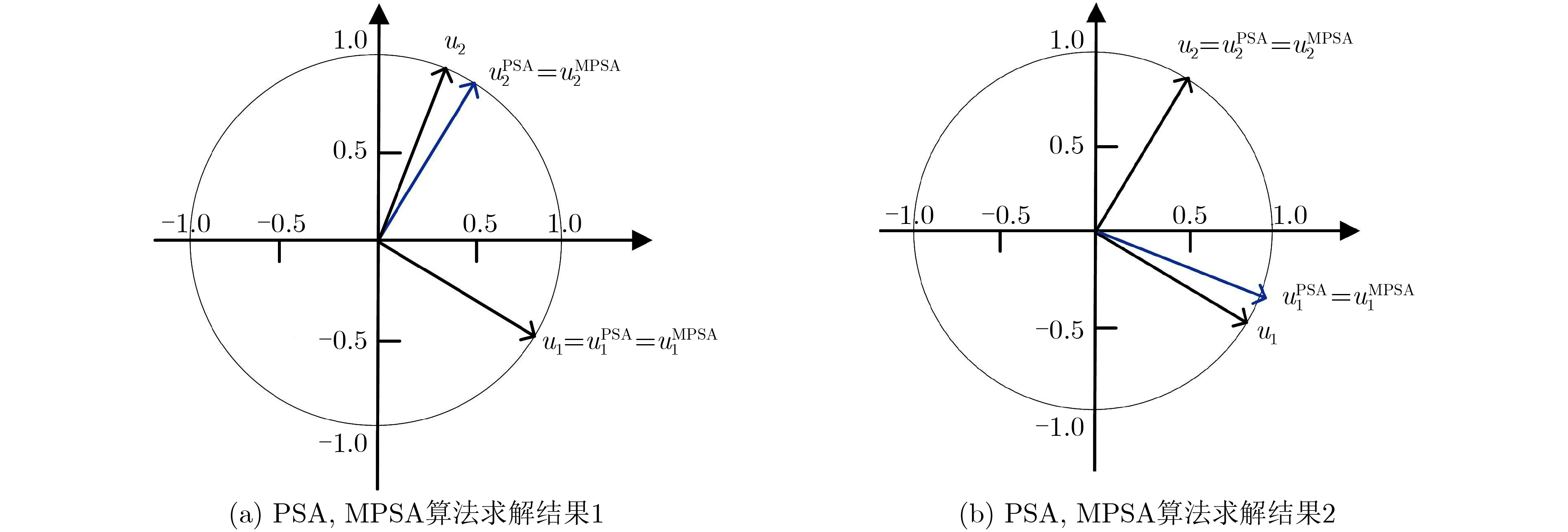
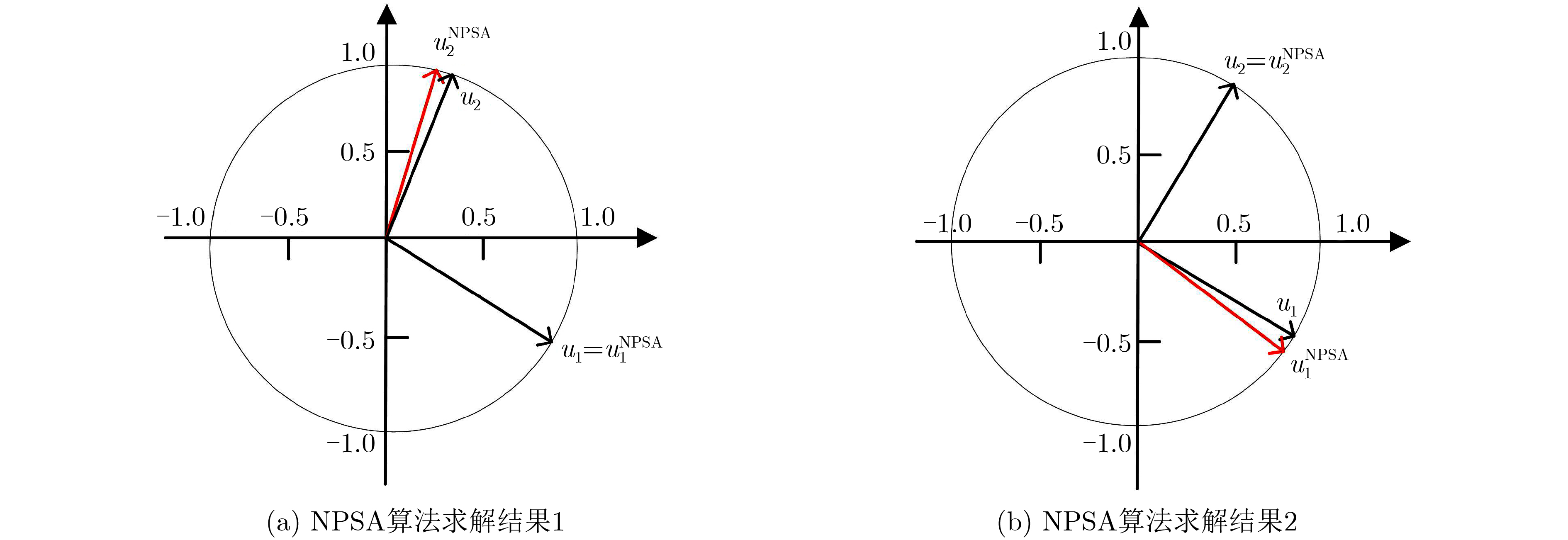
表 3 FastICA, PSA, MPSA, NPSA, MSDP和PPSA算法评估结果
指标 FastICA PSA MPSA NPSA MSDP PPSA
1ISI 0.6757 0.0681 0.0551 0.0253 0.0203 0.0203 TMSE 3.2856×10–11 2.5547×10–11 2.5548×10–11 3.8168×10–11 1.8645×10–11 1.8645×10–11 $ \rho $ 0.9544 0.9954 0.9954 0.9992 0.9998 0.9998 0.9889 0.9992 0.9988 0.99997 0.9992 0.9992 0.9968 1.0000 1.0000 1.0000 1.0000 1.0000 PSNR 66.1696 76.6105 77.7449 83.6350 85.9129 85.9129 70.0325 72.6448 73.7954 74.4358 74.4870 74.4870 79.2579 90.9901 90.4324 91.1667 91.3285 91.3285 T(s) 0.0042 0.0011 0.0010 0.0043 2.8594 0.0032 2 ISI 0.4844 0.1442 0.1524 0.0787 0.0745 0.0745 TMSE 3.2241×10–11 2.6798×10–11 2.6337×10–11 2.5154×10–11 1.9555×10–14 1.9555×10–14 $ \rho $ 0.9749 0.9967 0.9967 0.9995 0.9997 0.9997 0.9900 0.9905 0.9907 0.9920 0.9921 0.9921 0.9970 0.9999 0.9998 1.0000 1.0000 1.0000 PSNR 69.1886 74.9389 75.6708 83.4588 83.7674 83.7674 73.7143 73.1186 74.3531 70.1218 70.6017 70.6017 76.9175 89.0466 90.4683 94.0776 94.7823 94.7823 T(s) 0.0052 0.0011 0.0010 0.0042 3.1046 0.0021 3 ISI 0.2965 0.0405 0.0452 0.0041 0.0006 0.0006 TMSE 2.6603×10–10 2.6628×10–10 1.9986×10–10 3.4050×10–10 1.7480×10–10 1.7480×10–10 $ \rho $ 0.9756 0.9966 0.9962 0.9997 1.0000 1.0000 0.9950 0.9994 0.9995 1.0000 1.0000 1.0000 0.9969 0.9998 0.9999 1.0000 1.0000 1.0000 PSNR 69.9228 83.2559 78.8206 91.4669 96.6388 96.6388 61.8123 61.1492 58.8872 61.2297 64.0212 64.0212 82.3327 87.5416 90.4749 94.0424 95.1910 95.1910 T(s) 0.0048 0.0012 0.0009 0.0033 2.9786 0.0022
下载: 导出CSV
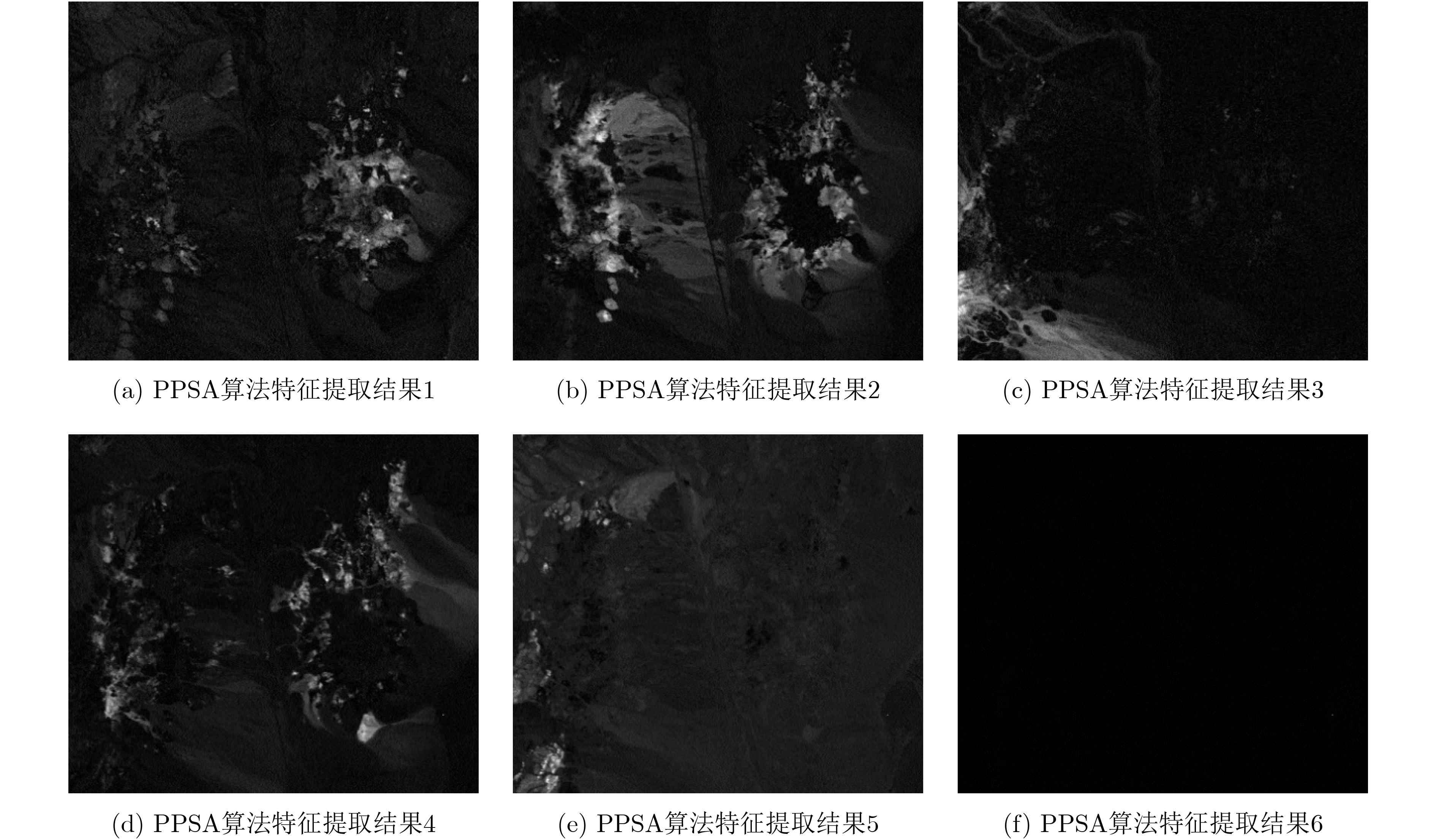
表 4 不同算法的平均峰值信噪比和平均绝对误差(计算10次运行的平均结果)
组合 评估指标 FastICA PSA NPSA PPSA 均值滤波 中值滤波 1 PSNR 64.3293 83.6292 83.9879 84.1115 62.0892 60.9464 MAE 0.0719 0.0127 0.0120 0.0119 0.1749 0.1957 2 PSNR 61.3562 81.4705 81.8815 81.9711 62.7697 62.3189 MAE 0.1631 0.0171 0.0163 0.0161 0.1574 0.1659 3 PSNR 68.6684 78.8200 78.8824 78.9555 64.0314 64.6669 MAE 0.0666 0.0245 0.0243 0.0241 0.1306 0.1233 (注释:组合1中${E_{{\text{gs}}}}$=0, $\delta _{{\text{gs}}}^{\text{2}}$=100, ${E_{{\text{gm}}}}$=2, $\delta _{{\text{gm}}}^{\text{2}}$=80;组合2中${E_{{\text{gs}}}}$=0, $\delta _{{\text{gs}}}^{\text{2}}$=80, ${E_{{\text{gm}}}}$=2, $\delta _{{\text{gm}}}^{\text{2}}$=60;组合3中${E_{{\text{gs}}}}$=0, $\delta _{{\text{gs}}}^{\text{2}}$=60, ${E_{{\text{gm}}}}$=2, $\delta _{{\text{gm}}}^{\text{2}}$=40)
下载: 导出CSV
-
[1] GENG Xiurui, SUN Kang, JI Luyan, et al. Optimizing the endmembers using volume invariant constrained model[J]. IEEE Transactions on Image Processing, 2015, 24(11): 3441–3449. doi: 10.1109/TIP.2015.2446196 [2] CHEN Sibao, WEI Qingsong, WANG Wenzhong, et al. Remote sensing scene classification via multi-branch local attention network[J]. IEEE Transactions on Image Processing, 2022, 31: 99–109. doi: 10.1109/tip.2021.3127851 [3] FENG Xiaoling. Better fusion of multi-scale features for remote sensing object detection[C]. 2022 2nd International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, 2022: 271–274. [4] ZHAO Bin, ULFARSSON M O, SVEINSSON J R, et al. Hyperspectral image denoising using spectral-spatial transform-based sparse and low-rank representations[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5522125. doi: 10.1109/tgrs.2022.3142988 [5] DE OLIVEIRA V A, CHABERT M, OBERLIN T, et al. Satellite image compression and denoising with neural networks[J]. IEEE Geoscience and Remote Sensing Letters, 2022, 19: 4504105. doi: 10.1109/lgrs.2022.3145992 [6] HOTELLING H. Analysis of a complex of statistical variables into principal components[J]. Journal of Educational Psychology, 1933, 24(6): 417–441. doi: 10.1037/h0071325 [7] COMON P. Independent component analysis, a new concept?[J]. Signal Processing, 1994, 36(3): 287–314. doi: 10.1016/0165-1684(94)90029-9 [8] HYVARINEN A. Fast and robust fixed-point algorithms for independent component analysis[J]. IEEE Transactions on Neural Networks, 1999, 10(3): 626–634. doi: 10.1109/72.761722 [9] OJA E and YUAN Zhijian. The FastICA algorithm revisited: Convergence analysis[J]. IEEE Transactions on Neural Networks, 2006, 17(6): 1370–1381. doi: 10.1109/tnn.2006.880980 [10] GENG Xiurui, JI Luyan, and SUN Kang. Principal skewness analysis: Algorithm and its application for multispectral/hyperspectral images indexing[J]. IEEE Geoscience and Remote Sensing Letters, 2014, 11(10): 1821–1825. doi: 10.1109/lgrs.2014.2311168 [11] GENG Xiurui, MENG Lingbo, LI Lin, et al. Momentum principal skewness analysis[J]. IEEE Geoscience and Remote Sensing Letters, 2015, 12(11): 2262–2266. doi: 10.1109/lgrs.2015.2465814 [12] MENG Lingbo, GENG Xiurui, and JI Luyan. Principal kurtosis analysis and its application for remote-sensing imagery[J]. International Journal of Remote Sensing, 2016, 37(10): 2280–2293. doi: 10.1080/01431161.2016.1171927 [13] ANANDKUMAR A, GE Rong, HSU D, et al. Tensor decompositions for learning latent variable models[J]. Journal of Machine Learning Research, 2014, 15: 2773–2832. doi: 10.21236/ada604494 [14] KOLDA T G and BADER B W. Tensor decompositions and applications[J]. SIAM Review, 2009, 51(3): 455–500. doi: 10.1137/07070111X [15] GENG Xiurui and WANG Lei. NPSA: Nonorthogonal principal skewness analysis[J]. IEEE Transactions on Image Processing, 2020, 29: 6396–6408. doi: 10.1109/tip.2020.2984849 [16] LIM L H. Singular values and eigenvalues of tensors: A variational approach[C]. 1st IEEE International Workshop on Computational Advances in Multi-Sensor Adaptive Processing, 2005, Puerto Vallarta, Mexico, 2005: 129–132. [17] QI Liqun. Eigenvalues of a real supersymmetric tensor[J]. Journal of Symbolic Computation, 2005, 40(6): 1302–1324. doi: 10.1016/j.jsc.2005.05.007 [18] WANG Lei and GENG Xiurui. The real eigenpairs of symmetric tensors and its application to independent component analysis[J]. IEEE Transactions on Cybernetics, 2022, 52(10): 10137–10150. doi: 10.1109/tcyb.2021.3055238 -

 下载:
下载:






图(8) / 表(5)
计量
- 文章访问数: 791
- HTML全文浏览量: 328
- PDF下载量: 130
- 被引次数: 0
