

Deployment Algorithm of Service Function Chain Based on Multi-Agent Soft Actor-Critic Learning
-
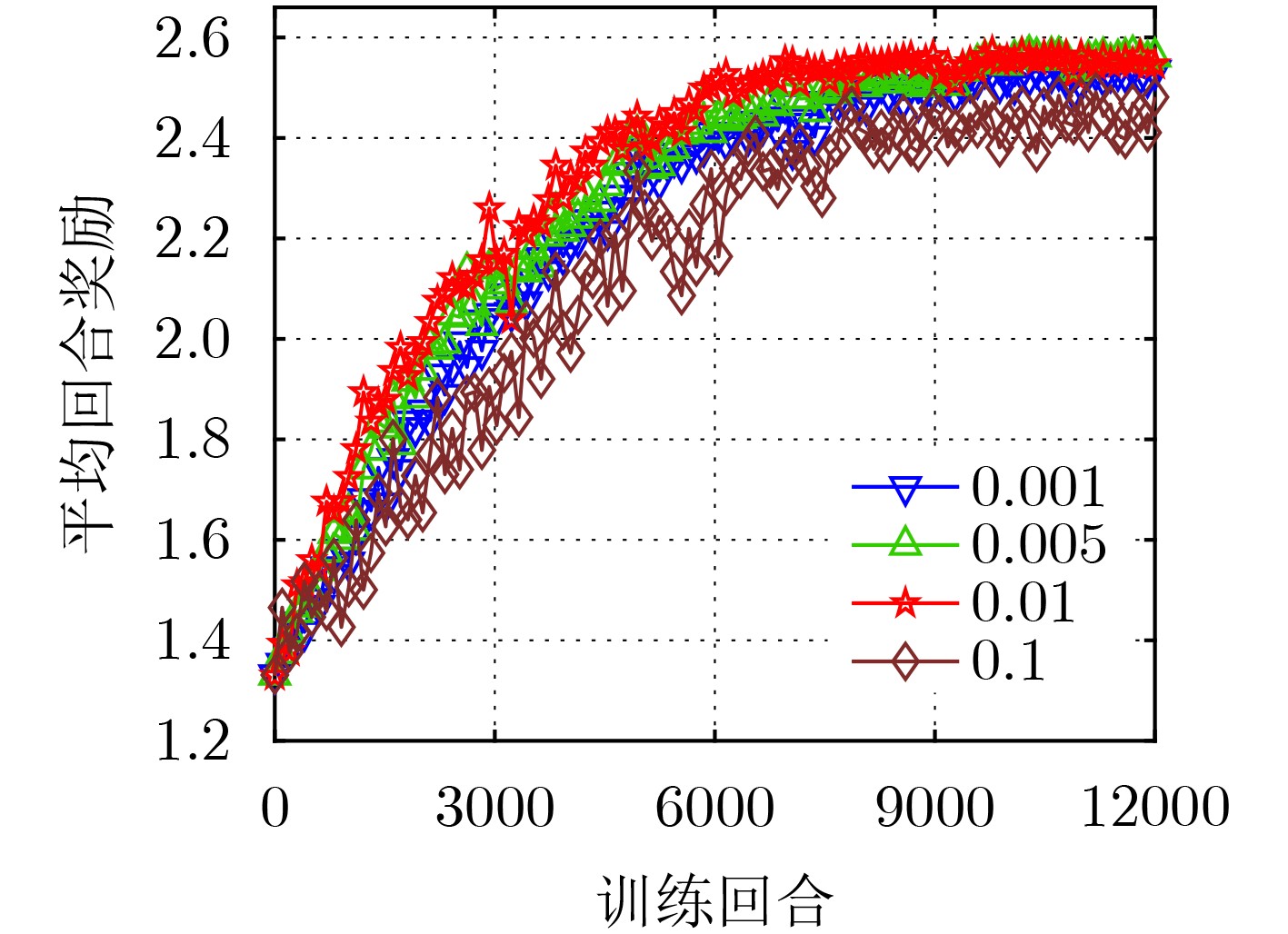
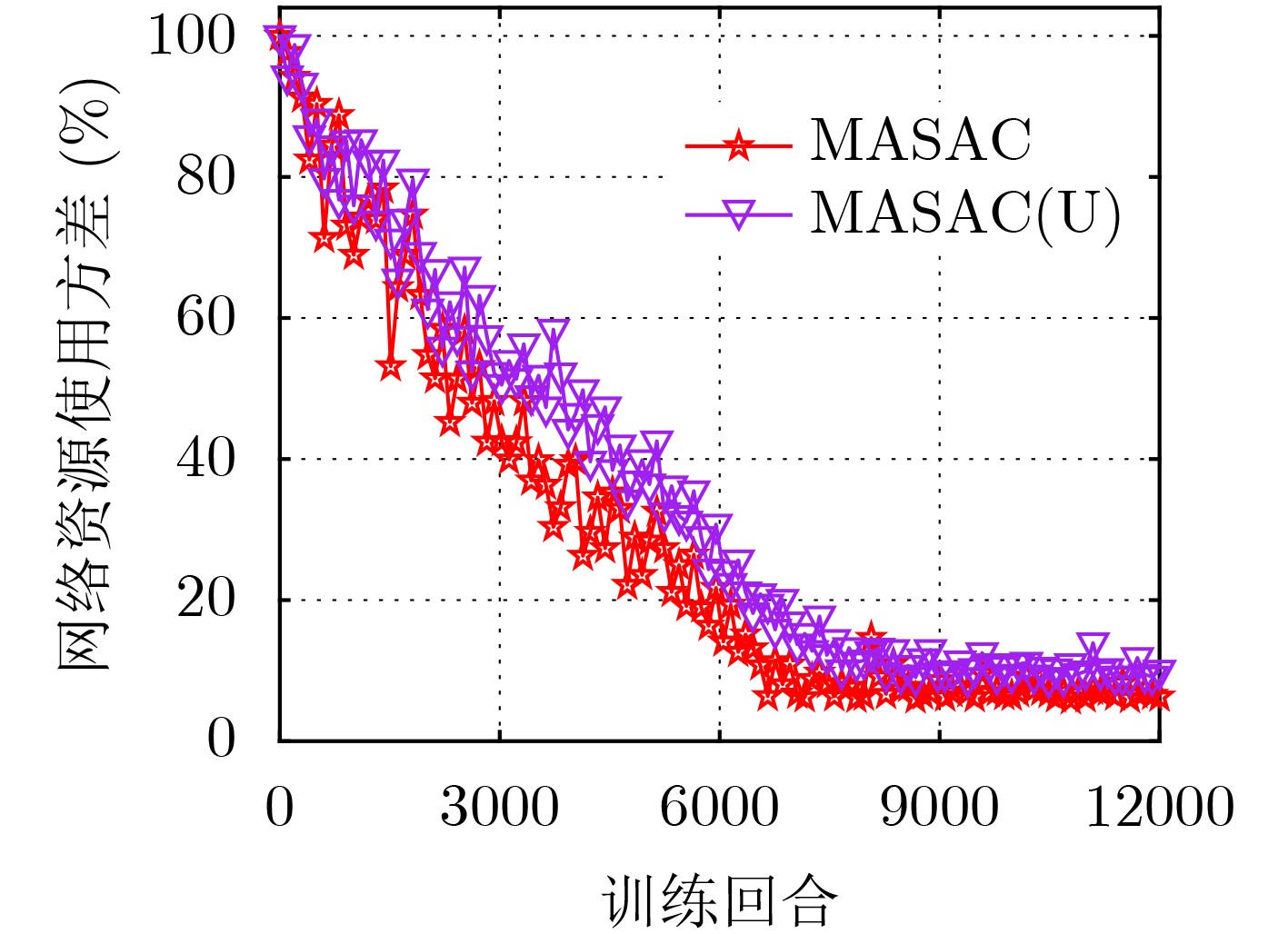
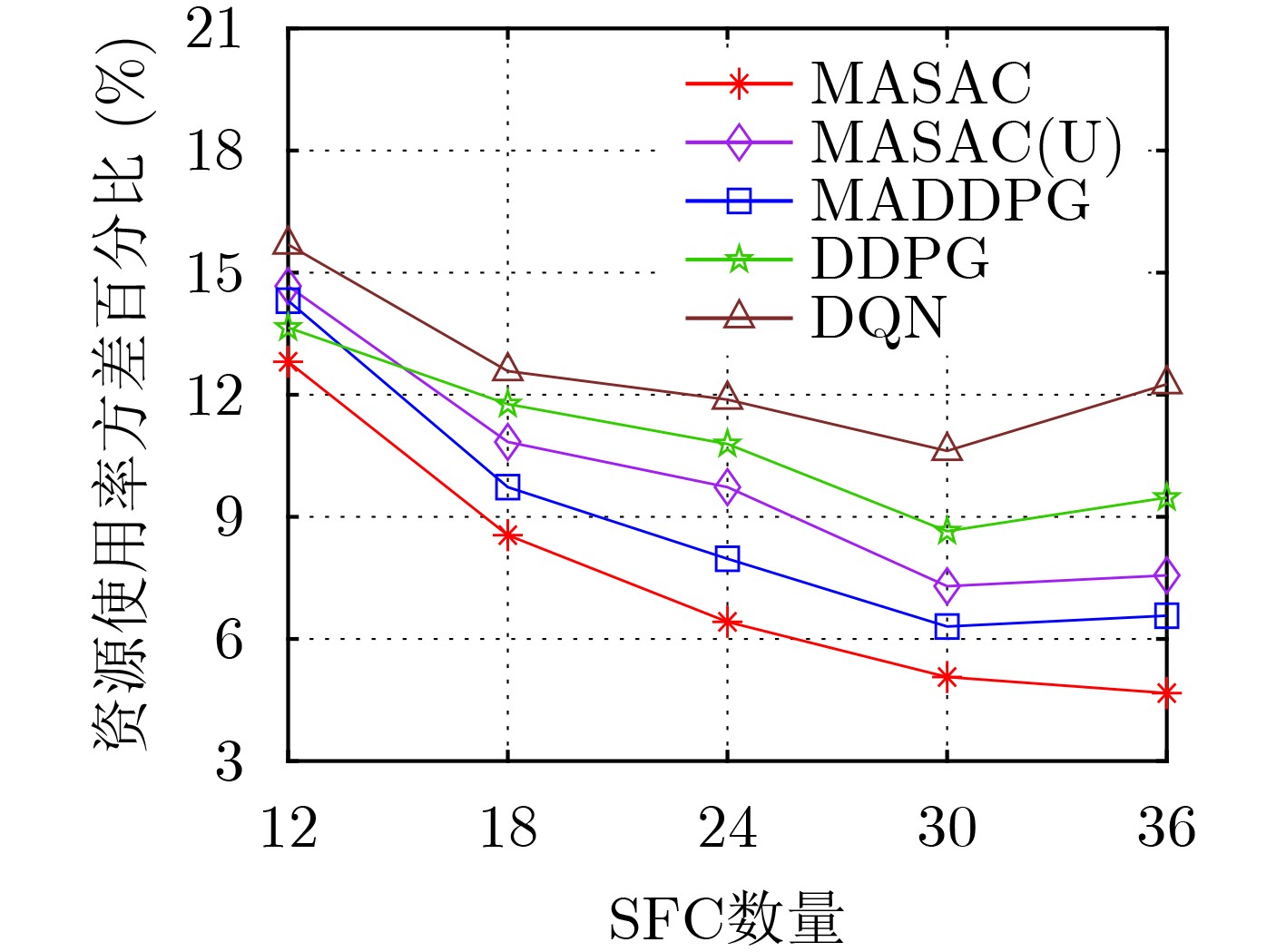
摘要: 针对网络功能虚拟化(NFV)架构下业务请求动态变化引起的服务功能链(SFC)部署优化问题,该文提出一种基于多智能体柔性演员-评论家(MASAC)学习的SFC部署优化算法。首先,建立资源负载惩罚、SFC部署成本和时延成本最小化的模型,同时受限于SFC端到端时延和网络资源预留阈值约束。其次,将随机优化问题转化为马尔可夫决策过程(MDP),实现SFC动态部署和资源的均衡调度,还进一步提出基于业务分工的多决策者编排方案。最后,在分布式多智能体系统中采用柔性演员-评论家(SAC)算法以增强探索能力,并引入了中央注意力机制和优势函数,能够动态和有选择性地关注获取更大部署回报的信息。仿真结果表明,所提算法可以实现负载惩罚、时延和部署成本的优化,并随业务请求量的增加能更好地扩展。
-
关键词:
- 网络功能虚拟化 /
- 服务功能链 /
- 柔性演员-评论家学习 /
- 多智能体强化学习
Abstract: Considering the problem of Service Function Chain (SFC) deployment optimization caused by the dynamic change of service requests under the Network Function Virtualization (NFV) architecture, an SFC deployment optimization algorithm based on Multi-Agent Soft Actor-Critic (MASAC) learning is proposed. Firstly, the model of minimizing resource load penalty, SFC deployment cost and delay cost is established, which is constrained by SFC end-to-end delay and reservation threshold of network resource. Secondly, the stochastic optimization is transformed into a Markov Decision Process (MDP) to realize the dynamic deployment of SFC and the balanced scheduling of resources. The arrangement scheme according to services division for multiple decision makers is further proposed. At last, the Soft Actor-Critic (SAC) algorithm is adopted in distributed multi-agent system to enhance exploration, then the central attention mechanism and advantage function are further introduced, which can dynamically and selectively focus on the information to obtain greater deployment return. Simulation results show that the proposed algorithm can optimize the load penalty, delay and deployment cost, and scale better with the increase of service requests. -
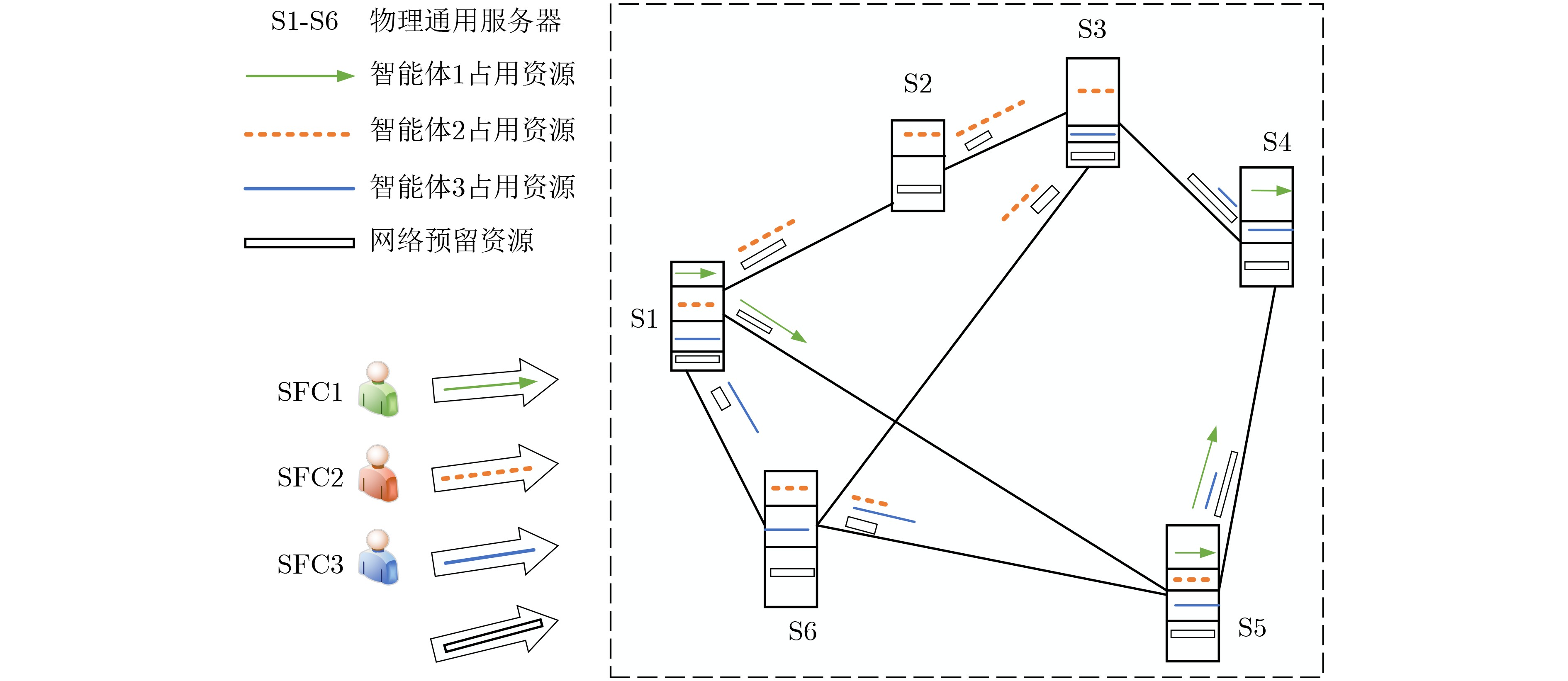
算法1 基于多智能体柔性演员-评论家学习的SFC部署算法 输入:多智能体数量$ N $,软更新因子$ \tau $,折扣因子$ \gamma $,温度参数$ \alpha $,注意力头数量$ h $,回放缓存池大小$ D $,回合数$ M $,回合最大长度$ T $ 输出:各智能体的策略 (1) 初始化:$ E $个并行的环境,回放缓存池$ D $,${T_{{\rm{update}}} } \leftarrow 0$ (2) for $ {i_{ep}} $= $1,2, \cdots ,M$ episodes do (3) 重置SFC部署的环境,初始化各决策者$ i $的观察$ o_i^e $ (4) for$ t $=$ 1,2, \cdots ,T $ do (5) 并行环境为决策者$ i $选取动作$a_i^e{\text{~} }{\pi _i}( \cdot {\text{|} }o_i^e)$,进行VNF放置和节点CPU、链路带宽资源分配 (6) 所有决策者获得SFC部署的局部观察$o{'}_i^e$,得到VNF放置与资源分配的奖励$ r_i^e $ (7) if $ \text{C}1~\text{C9} $约束满足,在$ D $中储存各环境的转变 (8) ${T_{{\rm{update}}} }{\text{ = } }{T_{{\rm{update}}} }{\text{ + } }E$ (9) if ${T_{{\rm{update}}} } \ge$更新的最小步数,then (10) for $ j = 1,2, \cdots ,{\text{num}} $ 评论家网络 更新 do (11) 从缓存池中打包小批次样本$ B $,$(o_{1 \cdots N}^B,a_{1 \cdots N}^B,r_{1 \cdots N}^B,o{'}_{1 \cdots N}^B) \leftarrow B$ (12) 在并行环境中,由式(22)与式(23)计算各决策者的观察-动作值$ Q_i^\psi (o_{1 \cdots N}^B,a_{1 \cdots N}^B) $,通过目标策略网络计算$a{'}_i^B{\text{~} }\pi _i^{\overline \theta }(o{'}_i^B)$,
通过目标评论家网络计算$Q_i^{\overline \psi }(o{'}_{1 \cdots N}^B,a{'}_{1 \cdots N}^B)$(13) 由式(25)计算联合损失函数$ {L_Q}(\psi ) $,并结合Adam来更新评论家网络 (14) end for (15) for $ j = 1,2, \cdots ,{\text{num}} $ 演员网络 更新 do (16) 采取样本$m \times ({o_{1 \cdots N} }){\text{~}}D$ (17) 计算$a_{1 \cdots N}^B{\text{~}}\pi _i^{\overline \theta }(o{'}_i^B),i \in 1,2, \cdots ,N$,$ Q_i^\psi (o_{1 \cdots N}^B,a_{1 \cdots N}^B) $ (18) 由式(28)计算优势函数,再代入式(30)计算$ {\nabla _{{\theta _i}}}J({\pi _\theta }) $,并结合Adam来更新演员网络 (19) end for (20) 由式(27),更新目标评论家和演员网络参数:$ \overline \psi \leftarrow (1 - \tau )\overline \psi + \tau \psi $,$ \overline \theta \leftarrow (1 - \tau )\overline \theta + \tau \theta $ (21) ${T_{{\rm{update}}} } \leftarrow 0$ (22) end if (23) end for (24) end for  下载: 导出CSV
下载: 导出CSV
-
[1] CHAHBAR M, DIAZ G, DANDOUSH A, et al. A comprehensive survey on the E2E 5G network slicing model[J]. IEEE Transactions on Network and Service Management, 2021, 18(1): 49–62. doi: 10.1109/TNSM.2020.3044626 [2] GONZALEZ A J, NENCIONI G, KAMISINSKI A, et al. Dependability of the NFV orchestrator: state of the art and research challenges[J]. IEEE Communications Surveys & Tutorials, 2018, 20(4): 3307–3329. doi: 10.1109/COMST.2018.2830648 [3] SUN Gang, XU Zhu, YU Hongfang, et al. Low-latency and resource-efficient service function chaining orchestration in network function virtualization[J]. IEEE Internet of Things Journal, 2020, 7(7): 5760–5772. doi: 10.1109/JIOT.2019.2937110 [4] LI Junling, SHI Weisen, YE Qiang, et al. Joint virtual network topology design and embedding for cybertwin-enabled 6G core networks[J]. IEEE Internet of Things Journal, 2021, 8(22): 16313–16325. doi: 10.1109/JIOT.2021.3097053 [5] CHAI Rong, XIE Desheng, LUO Lei, et al. Multi-objective optimization-based virtual network embedding algorithm for software-defined networking[J]. IEEE Transactions on Network and Service Management, 2020, 17(1): 532–546. doi: 10.1109/TNSM.2019.2953297 [6] CAO Haotong, DU Jianbo, ZHAO Haitao, et al. Resource-ability assisted service function chain embedding and scheduling for 6G networks with virtualization[J]. IEEE Transactions on Vehicular Technology, 2021, 70(4): 3846–3859. doi: 10.1109/TVT.2021.3065967 [7] SOLOZABAL R, CEBERIO J, SANCHOYERTO A, et al. Virtual network function placement optimization with deep reinforcement learning[J]. IEEE Journal on Selected Areas in Communications, 2020, 38(2): 292–303. doi: 10.1109/JSAC.2019.2959183 [8] CHEN Jing, CHEN Jia, and ZHANG Hongke. DRL-QOR: Deep reinforcement learning-based QoS/QoE-aware adaptive online orchestration in NFV-enabled networks[J]. IEEE Transactions on Network and Service Management, 2021, 18(2): 1758–1774. doi: 10.1109/TNSM.2021.3055494 [9] HUANG Haojun, ZENG Cheng, ZHAO Yangmin, et al. Scalable orchestration of service function chains in NFV-enabled networks: A federated reinforcement learning approach[J]. IEEE Journal on Selected Areas in Communications, 2021, 39(8): 2558–2571. doi: 10.1109/JSAC.2021.3087227 [10] GHARBAOUI M, CONTOLI C, DAVOLI G, et al. Demonstration of latency-aware and self-adaptive service chaining in 5G/SDN/NFV infrastructures[C]. 2018 IEEE Conference on Network Function Virtualization and Software Defined Networks (NFV-SDN), Verona, Italy, 2018: 1–2. [11] LIU Yu, SHANG Xiaojun, and YANG Yuanyuan. Joint SFC deployment and resource management in heterogeneous edge for latency minimization[J]. IEEE Transactions on Parallel and Distributed Systems, 2021, 32(8): 2131–2143. doi: 10.1109/TPDS.2021.3062341 [12] YANG Jian, ZHANG Shuben, WU Xiaomin, et al. Online learning-based server provisioning for electricity cost reduction in data center[J]. IEEE Transactions on Control Systems Technology, 2017, 25(3): 1044–1051. doi: 10.1109/TCST.2016.2575801 [13] PEI Jianing, HONG Peilin, XUE Kaiping, et al. Resource aware routing for service function chains in SDN and NFV-enabled network[J]. IEEE Transactions on Services Computing, 2021, 14(4): 985–997. doi: 10.1109/TSC.2018.2849712 [14] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010. [15] LI Han, LÜ Tiejun, and ZHANG Xuewei. Deep deterministic policy gradient based dynamic power control for self-powered ultra-dense networks[C]. 2018 IEEE Globecom Workshops (GC Wkshps), Abu Dhabi, United Arab Emirates, 2018: 1–6. -


 下载:
下载:



图(8) / 表(1)
计量
- 文章访问数: 1231
- HTML全文浏览量: 816
- PDF下载量: 105
- 被引次数: 0
