

Deep Alternating Direction Multiplier Method Network for Event Detection
-
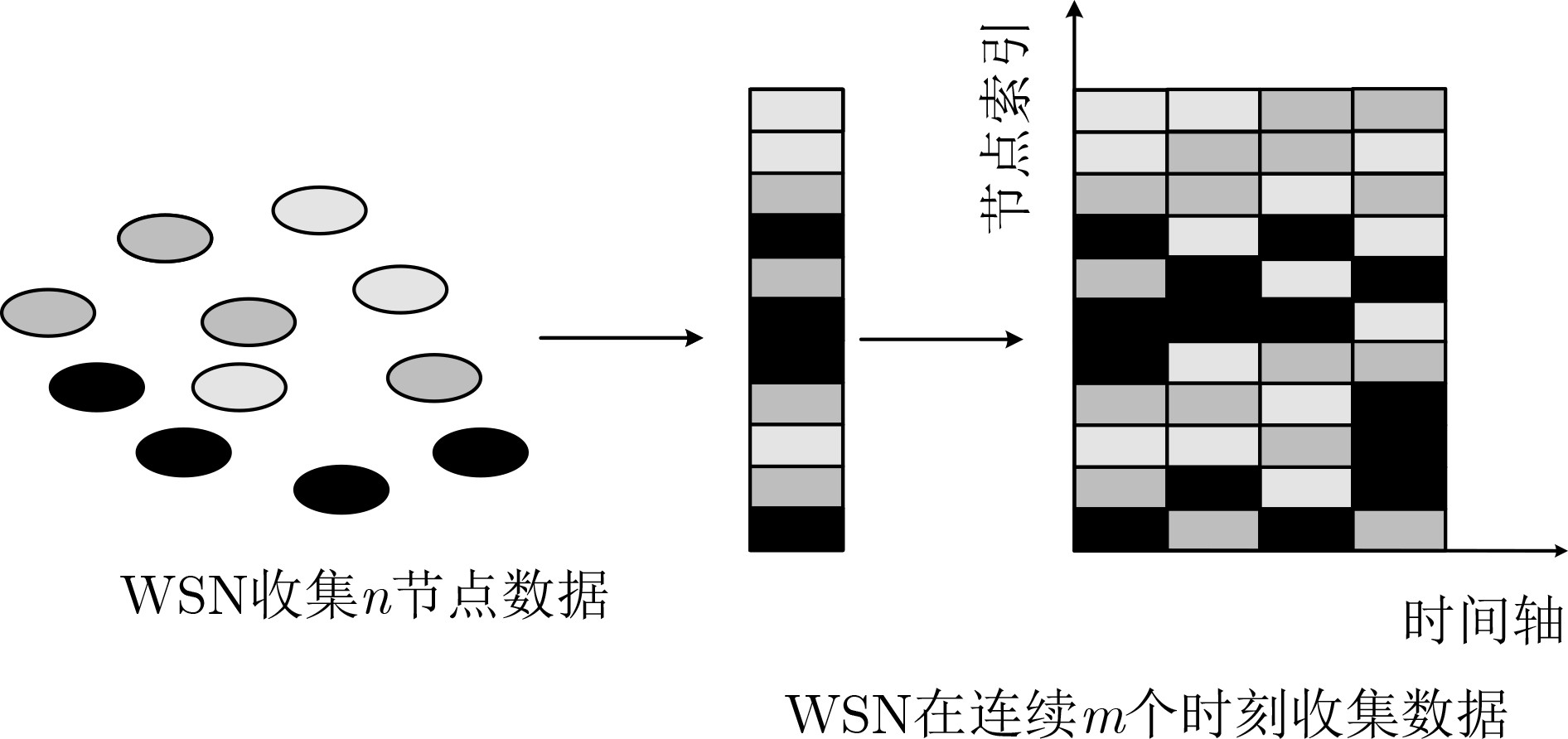
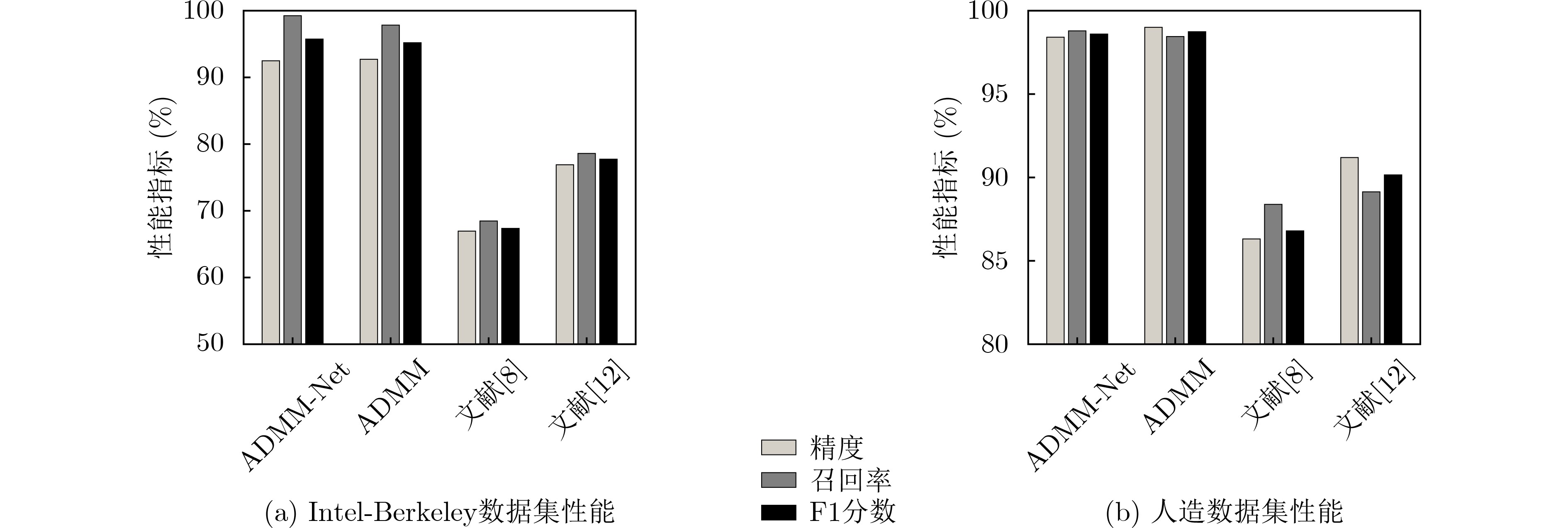
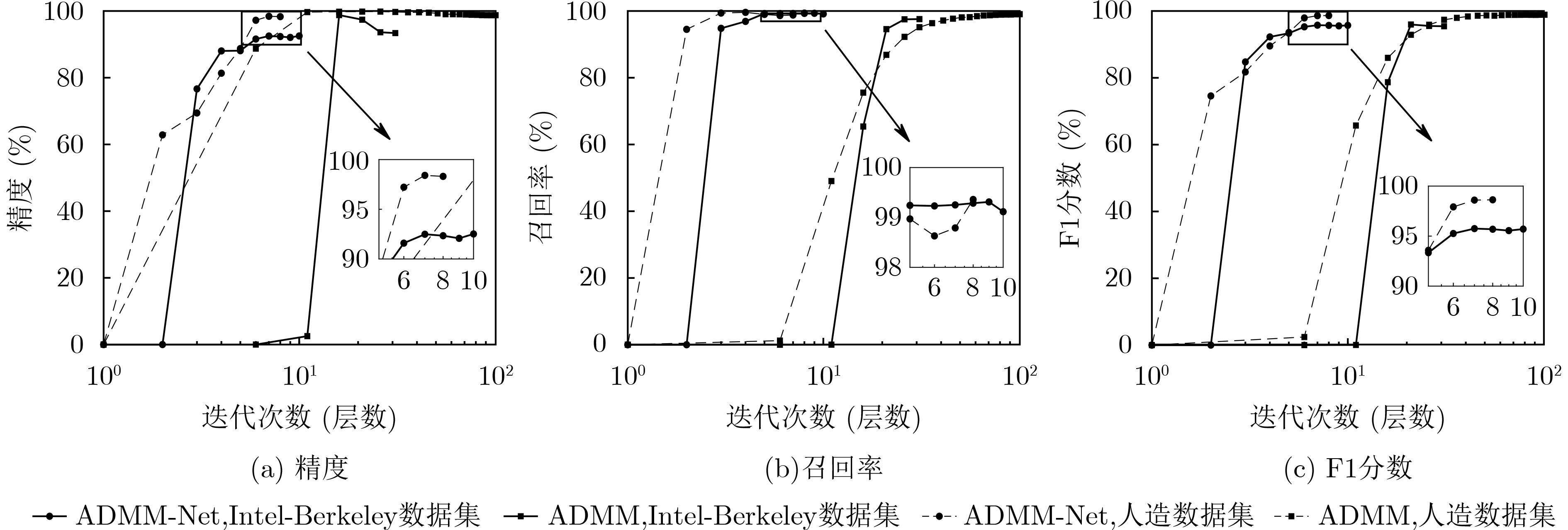
摘要: 针对大规模无线传感器网络(WSN)中的事件检测问题(EDP),传统的方法通常依赖先验信息,阻碍了实际应用。该文为 EDP 提出了一种基于深度学习的算法,称为交替方向乘子法网络(ADMM-Net)。首先,采用低秩稀疏矩阵分解来建模事件的时空相关性。之后,EDP 被表述为一个带约束的优化问题并用交替方向乘子法(ADMM)求解。然而,优化算法收敛慢且算法的性能依赖于对先验参数的仔细选择。该文基于深度学习中“展开”的概念,提出了一种用于EDP的深度神经网络ADMM-Net。通过“展开”ADMM算法的方式得到。 ADMM-Net 具有固定层数,其参数可以通过监督学习训练获得。无需先验信息。相比于传统算法,提出的 ADMM-Net 收敛快且不需先验信息。人造数据集和真实数据集的仿真结果验证了ADMM-Net 的有效性。Abstract: Considering the Event Detection Problem (EDP) in the large-scale Wireless Sensor Network (WSN), the conventional methods rely generally on some prior information, which obstacles the actual application. In this paper, a deep learning-based algorithm, named as Alternating Direction Multiplier Method Network (ADMM-Net), is proposed for the EDP. Firstly, the low rank and sparse matrix decomposition is adopted to capture the spatial-temporal correlation of events. After that, the EDP is formulated as a constrained optimization problem and solved by the Alternating Direction Multiplier Method (ADMM). However, the optimization algorithm suffers from low convergence. Besides, the algorithm’s performance relies heavily on the careful selection of prior parameters. By adopting the conception of “unfolding” in deep learning field, a deep learning network which is named ADMM-Net, is proposed for the EDP in this paper. The ADMM-Net is obtained by unfolding the ADMM algorithm. The ADMM-Net is with fixed layers, whose parameters can be trained via supervised learning. No prior information is required. Compared to the conventional methods, the proposed ADMM-Net does not require any prior information while enjoying fast convergence. Simulation results on both synthesis and realistic datasets verify the effectiveness of the proposed ADMM-Net.
-
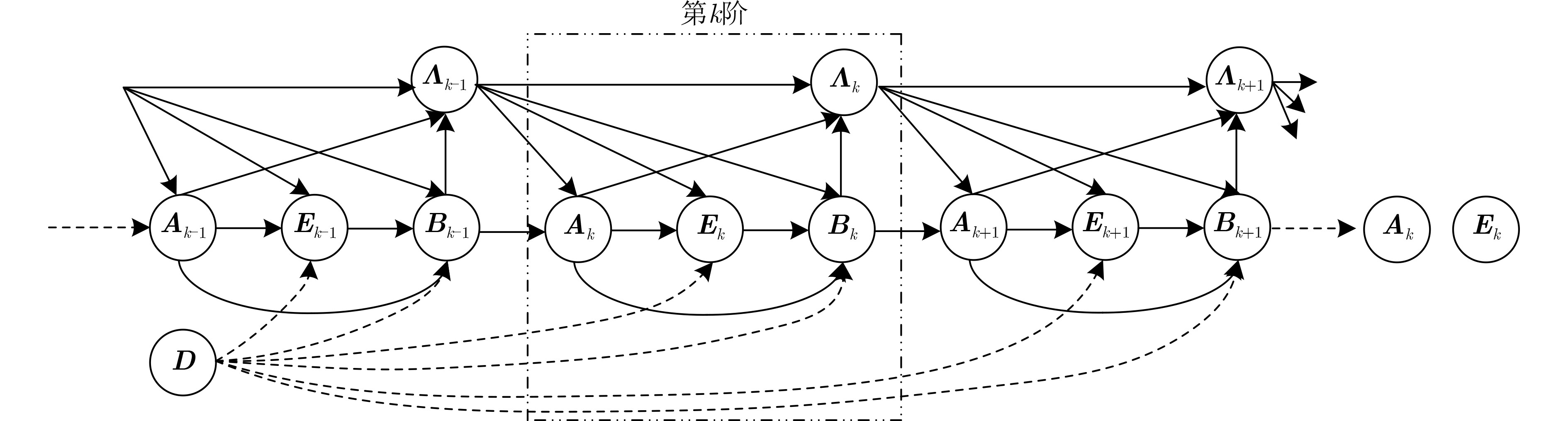
算法1 ADMM-Net事件检测算法 已知:数据矩阵D,深度神经网络层数K,和初始化随机生成参
数:${\boldsymbol{\varTheta } } = \{ {\eta _k},{\zeta _k},{\gamma _k},{\varphi _k},{\phi _k},{\xi _k}\} ,k = 1,2, \cdots ,K.$(1) 初始化 ${ {\boldsymbol{A} }_0} = { {\boldsymbol{B} }_0} = { {\boldsymbol{E} }_0} = {{\boldsymbol{\varLambda}} _0} = { { {\textit{0} } } }$为全0矩阵,$k = 0$ (2) 正向传播: (3) for 数据集中的每个样本 do (4) While $ k < K $ do (5) $ {{\boldsymbol{P}}_k} = {{\boldsymbol{B}}_k} - {\eta _k}{\Lambda _{k - 1}} $ (6) $ {{\boldsymbol{A}}_k} = {\text{SVT}}\left( {{{\boldsymbol{P}}_k},{\zeta _k}} \right) $ (7) ${ {\boldsymbol{Q} }_k} = {\boldsymbol{D} } - { {\boldsymbol{A} }_k} + {\gamma _k}{{\boldsymbol{\varLambda}} _{k - 1} }$ (8) $ {{\boldsymbol{E}}_k} = {\text{ST}}\left( {{{\boldsymbol{Q}}_k},{\varphi _k}} \right) $ (9) $ {{\boldsymbol{B}}_k} = {\phi _k}\left( {{\boldsymbol{D}} - {{\boldsymbol{E}}_k}} \right) + (1 - {\phi _k}){{\boldsymbol{Q}}_k} $ (10) ${{\boldsymbol{\varLambda}} _k} = {{\boldsymbol{\varLambda}} _{k - 1} } + {\xi _k}\left( { { {\boldsymbol{A} }_k} - { {\boldsymbol{B} }_k} } \right)$ (11) $ k = k + 1 $ (12) end while (13) 输出${{\boldsymbol{A}}_K}$和${{\boldsymbol{E}}_K}$,并计算归一化均方误差 (14) 反向传播: (15) for 隐藏层或输出层的每个神经元 do (16) 更新网络中的每一个权值和偏差 (17) end for (18) end for  下载: 导出CSV
下载: 导出CSV
-
[1] STOYANOVA M, NIKOLOUDAKIS Y, PANAGIOTAKIS S, et al. A survey on the internet of things (IoT) forensics: Challenges, approaches, and open issues[J]. IEEE Communications Surveys & Tutorials, 2020, 22(2): 1191–1221. doi: 10.1109/COMST.2019.2962586 [2] JAVADI S H. Detection over sensor networks: A tutorial[J]. IEEE Aerospace and Electronic Systems Magazine, 2016, 31(3): 2–18. doi: 10.1109/MAES.2016.140128 [3] ARAD J, HOUSH M, PERELMAN L, et al. A dynamic thresholds scheme for contaminant event detection in water distribution systems[J]. Water Research, 2013, 47(5): 1899–1908. doi: 10.1016/j.watres.2013.01.017 [4] LIU Li, HAN Guangjie, HE Yu, et al. Fault-tolerant event region detection on trajectory pattern extraction for industrial wireless sensor networks[J]. IEEE Transactions on Industrial Informatics, 2020, 16(3): 2072–2080. doi: 10.1109/TII.2019.2933238 [5] YU Manzhu, BAMBACUS M, CERVONE G, et al. Spatiotemporal event detection: A review[J]. International Journal of Digital Earth, 2020, 13(12): 1339–1365. doi: 10.1080/17538947.2020.1738569 [6] YIN Jie, HU D H, and YANG Qiang. Spatio-temporal event detection using dynamic conditional random fields[C]. The 21st International Joint Conference on Artificial Intelligence, Pasadena, USA, 2009: 1321–1326. [7] GRANJON P. The CuSum algorithm-a small review[EB/OL].https://hal.archives-ouvertes.fr/hal-00914697, 2013. [8] KRISHNAMACHARIB and IYENGAR S. Distributed Bayesian algorithms for fault-tolerant event region detection in wireless sensor networks[J]. IEEE Transactions on Computers, 2004, 53(3): 241–250. doi: 10.1109/TC.2004.1261832 [9] CHEN Xianda, KIM K T, and YOUN H Y. Integration of Markov random field with Markov chain for efficient event detection using wireless sensor network[J]. Computer Networks, 2016, 108: 108–119. doi: 10.1016/j.comnet.2016.07.004 [10] WU Tao and CHENG Qi. Online dynamic event region detection using distributed sensor networks[J]. IEEE Transactions on Aerospace and Electronic Systems, 2014, 50(1): 393–405. doi: 10.1109/TAES.2013.120308 [11] WANG T Y, YANG M H, and WU J Y. Distributed detection of dynamic event regions in sensor networks with a Gibbs field distribution and Gaussian corrupted measurements[J]. IEEE Transactions on Communications, 2016, 64(9): 3932–3945. doi: 10.1109/TCOMM.2016.2593467 [12] WANG Jiejie and LIU Bin. Online fault-tolerant dynamic event region detection in sensor networks via trust model[C]. 2017 IEEE Wireless Communications and Networking Conference (WCNC), San Francisco, USA, 2017: 1–6. [13] CANDÈS E J, LI Xiaodong, MA Yi, et al. Robust principal component analysis?[J]. Journal of the ACM, 2011, 58(3): 11. doi: 10.1145/1970392.1970395 [14] GAO Lianru, HONG Danfeng, YAO Jing, et al. Spectral superresolution of multispectral imagery with joint sparse and low-rank learning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(3): 2269–2280. doi: 10.1109/TGRS.2020.3000684 [15] MONGA V, LI Yuelong, and ELDAR Y C. Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing[J]. IEEE Signal Processing Magazine, 2021, 38(2): 18–44. doi: 10.1109/MSP.2020.3016905 [16] JOHNSTON J, LI Yinchuan, LOPS M, et al. ADMM-Net for communication interference removal in stepped-frequency radar[J]. IEEE Transactions on Signal Processing, 2021, 69: 2818–2832. doi: 10.1109/TSP.2021.3076900 [17] YANG Liu, WANG Haifeng, and QIAN Hua. An ADMM-ResNet for data recovery in wireless sensor networks with guaranteed convergence[J]. Digital Signal Processing, 2021, 111: 102956. doi: 10.1016/j.dsp.2020.102956 [18] AYBAT N S and IYENGAR G. An alternating direction method with increasing penalty for stable principal component pursuit[J]. Computational Optimization and Applications, 2015, 61(3): 635–668. doi: 10.1007/s10589-015-9736-6 [19] Intel Berkeley Research Lab. Intel lab data[EB/OL]. http://db.lcs.mit.edu/labdata/labdata.html, 2019. -

 下载:
下载:



图(7) / 表(1)
计量
- 文章访问数: 750
- HTML全文浏览量: 633
- PDF下载量: 79
- 被引次数: 0
