

User Matching Method for Cross Social Networks Based on Deep Learning
-
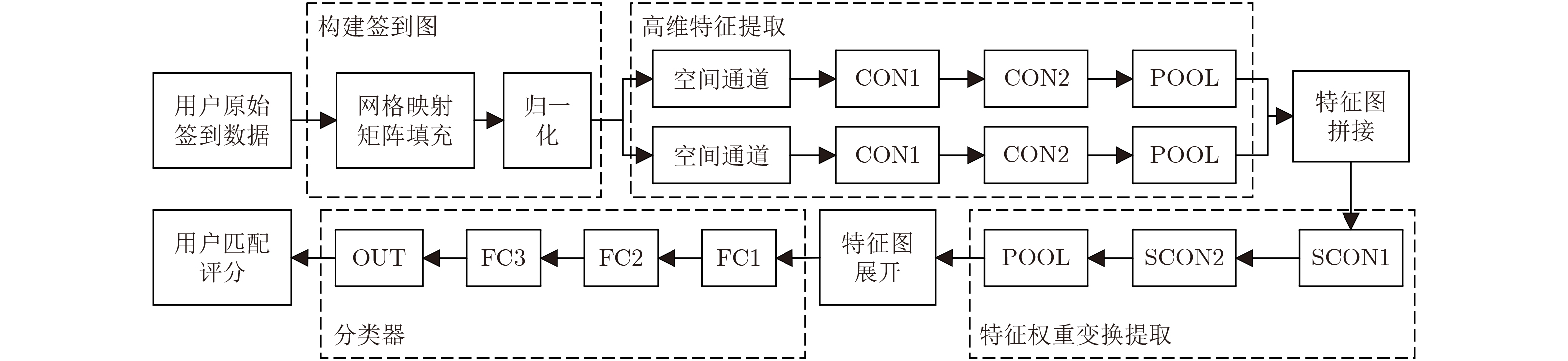
摘要: 现有基于时空信息的跨社交网络用户匹配方案,存在着难以耦合时空信息、特征提取困难问题,导致匹配精度下降。该文提出一种基于深度学习的跨社交网络用户匹配方法(DLUMCN),首先对用户签到数据进行时空尺度的网格映射,生成包含用户特征的签到矩阵集合,对其归一化后构成用户签到图。然后采用卷积从签到图中生成高维度的时空特征图,利用深度可分离卷积对特征图权重变换和特征融合,对特征图1维展开获得特征向量。最后利用全连接前馈网络构建分类器并输出用户匹配评分。通过在两组真实社交网络的数据集上进行实验验证,实验结果表明,与现有相关算法相比,所提算法在匹配的准确率以及F1-值均得到提升,验证了所提算法的有效性。Abstract: The existing spatio-temporal information based user matching schemes for cross social networks have problems of spatio-temporal information decoupling and feature extraction difficulties, which result in a decrease in matching accuracy. A Deep Learning based User Matching method for Cross social Networks (DLUMCN) is proposed. Firstly, grid mapping at the spatio-temporal scale is carried out on the user sign-in data. The sign-in matrix set is generated, which contains user characteristics. User sign-in map is formed after normalization. Secondly, the convolution is used to generate high-dimensional spatio-temporal feature maps from the user sign-in map. The weight transformation and feature fusion of feature maps are carried out by deep separable convolution. The feature vector is obtained by one-dimensional expansion of feature maps. Finally, the fully connected feedforward network is used to build a classifier and output the user matching score. Experimental results on two sets of datasets of real social networks show that the proposed method has improved matching accuracy and F1-value, compared with the existing related methods. The effectiveness of the proposed method is demonstrated.
-
Key words:
- Cross social networks /
- User matching /
- Deep learning /
- Sign-in similarity
-
算法1 单点填充算法 输入: 用户签到集S,与S待匹配签到集Smatch,网格密度系数k 输出:用户签到矩阵集SMS 初始化: 初始化k维的零矩阵集SMS={As1, As2, At1, At2},通
过S和Smatch设定全局时空域(1) 遍历签到集S: (2) 获取时空网格:gs=(xs, ys),gt=(xt, yt) (3) 链接并填充矩阵:As1[xs, ys] += 1;At1[xt, yt] += 1 (4) 通过S和Smatch设定局部时空域,将As1和At1替换为As2和At2,
重复执行步骤1~步骤3(5) 输出SMS  下载: 导出CSV
下载: 导出CSV
算法2 关联填充算法 输入:用户签到集S,与S待匹配签到集Smatch,网格密度系数k,
关联系数s,填充系数p输出:用户签到矩阵集SMS (1) 通过单点填充算法获得SMS={As1, As2, At1, At2},定义空
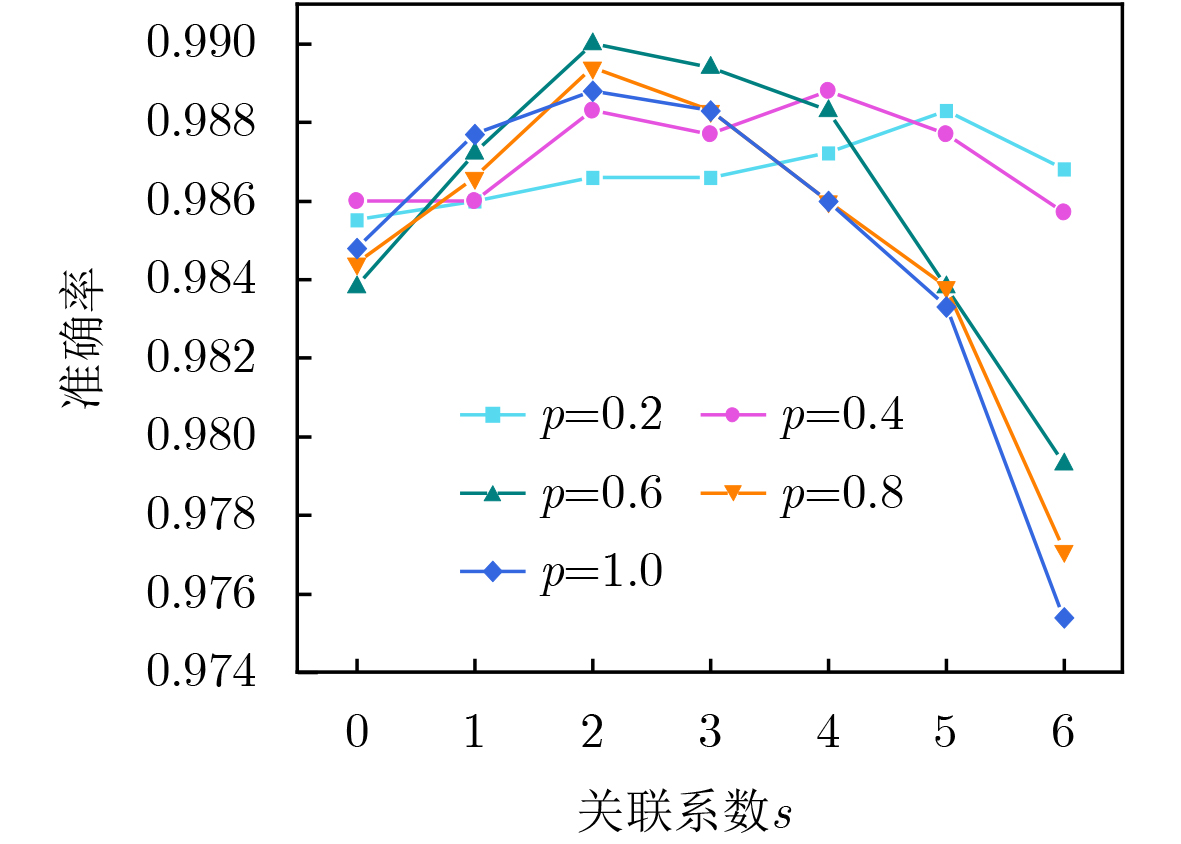
集合A, B(2) 通过S和Smatch设定全局时空域,选定As = As1 At = At1, (3) 遍历签到集S中任意签到sign: (4) 获取sign的时空网格表示gs=(xs, ys)和gt=(xt, yt) (5) 将满足d(g, gs) <= s的网格g,将其添加到临时集合At (6) 将满足d(g, gt) <= s的网格g,将其添加到临时集合Bt (7) 对任意网格g=(x, y): (8) 若g ∈ At∩A:As[x, y]+=p (9) 若g ∈ Bt∩B:At[x, y]+=p (10) 更新集合A和B:A=At,B=Bt (11) 若当前映射空间为全局时空域:通过S和Smatch设定局部时
空域,选定As = As2 At = At2,重复执行步骤3~步骤10(12) 否则:输出SMS
下载: 导出CSV
算法3 模型优化算法 输入:训练样本集train_data,迭代轮数epoch,批次尺寸bs,
学习率α输出:model (1) 随机初始化model{WC1, ···, WF1, WOUT, B C1, ···, B F1, b} (2) for i =1 to epoch: (3) for batch_data in train_data: #按批次遍历整个训练
样本集(4) for sample in batch_data: #按样本遍历单个批次 (5) 构建样本签到图MAP (6) 根据式(12)进行前向传播,计算模型各层输出 (7) 根据式(13)—式(16)计算模型预测的损失和各层参数
的梯度(8) 更新模型各层参数:W–= α×δW,B–= α×δB (9) 输出 model
下载: 导出CSV
表 1 数据集概况
数据集 Brightkite(样本量50686) Gowalla(样本量107092) 划分部分 a b a b 平均签到数 111 111 75 75 起始时间 2008–03–22 06:34:37 2008–03–21 20:36:21 2009–02–05 06:27:43 2009–02–04 05:17:38 终止时间 2010–10–18 18:34:01 2010–10–18 18:39:58 2010–10–23 05:22:06 2010–10–23 05:22:06 经度范围 –163.193~151.198 –163.193~151.198 –90.011~105.659 –90.011~105.625 纬度范围 –179.824~179.999 –179.824~179.999 –176.309~177.463 –166.525~177.453
下载: 导出CSV
表 2 匹配模型的其他参数
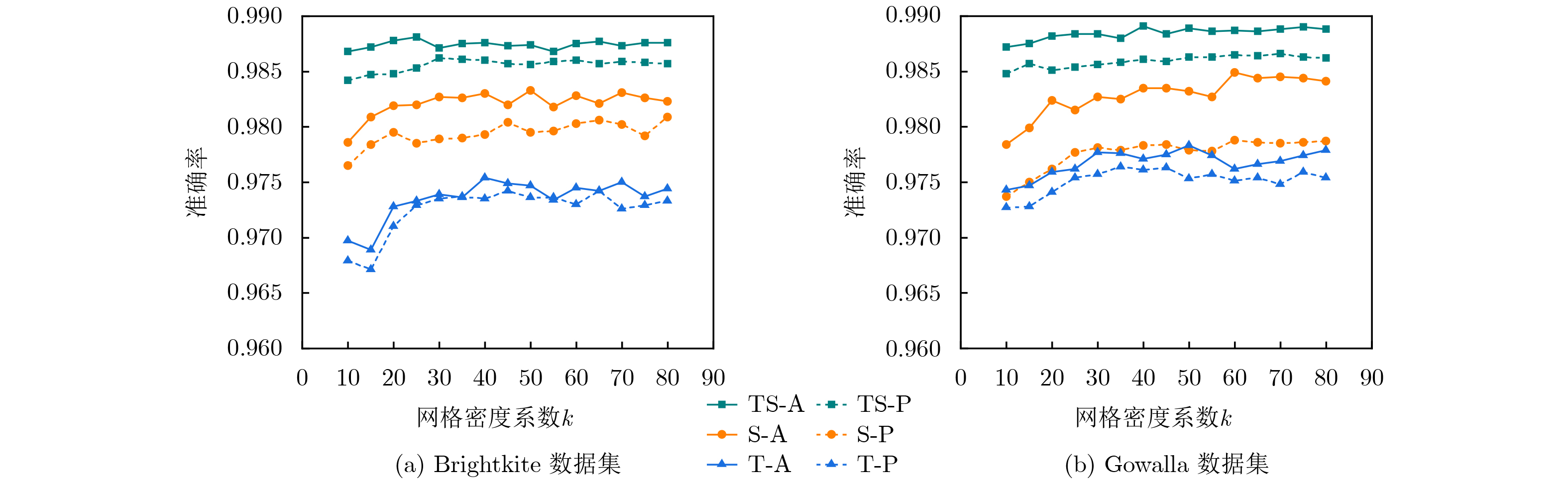
模型参数 设定值 说明 k 65(Brightkite) / 75(Gowalla) 网格密度系数 det/mt 1×10–4/0.5 调节因子/匹配阈值 batch-size,α 256, 1×10–3 训练的批次样本量,学习率 kcc1(fc1), kcc2(fc2) 16(3), 32(3) CON1, CON2卷积核数 (尺寸) kcs1(fs1), kcs2(fs2) 1(2), 64(1) SCON1, SCON2卷积核数(尺寸) nF1, nF2, nF3 16, 12, 8 前馈网络隐藏层神经元数量
下载: 导出CSV
表 3 不同算法的复杂度以及耗时(s)
算法 时间复杂度 空间复杂度 (Brightkite数据集) (Gowalla数据集) 训练时间 测试时间 训练时间 测试时间 UNICORN O(N2·S·k2) O(N·S) – 11.85 – 25.12 STUL O(N·S 3) O(N·S) – 451.663 – 1394.156 CDTraj2vec O(N·S 2) O(N·S 2) 375.833 11.85 587.174 26.385 UIDwST O(N2·S 2) O (N·S) – 217.775 – 631.105 DLUMCN O(N·S·k2) O(N·k2) 69.678 0.475 200.066 1.311
下载: 导出CSV
表 4 不同算法在两组数据集上的测试结果
算法 (Brightkite数据集) (Gowalla数据集) acc pre rec f1 acc pre rec f1 UNICORN 0.8801 0.8085 0.9960 0.8925 0.8847 0.8194 0.9870 0.8954 STUL 0.9253 0.9039 0.9516 0.9271 0.9281 0.9094 0.9447 0.9267 CDTraj2vec 0.9529 0.9833 0.9212 0.9512 0.9567 0.9686 0.9360 0.9520 UIDwST 0.9740 0.9594 0.9897 0.9743 0.9773 0.9619 0.9870 0.9742 DLUMCN 0.9881 0.9949 0.9814 0.9881 0.9890 0.9969 0.9812 0.9889
下载: 导出CSV
-
[1] DENG Kaikai, XING Ling, ZHENG Longshui, et al. A user identification algorithm based on user behavior analysis in social networks[J]. IEEE Access, 2019, 7: 47114–47123. doi: 10.1109/ACCESS.2019.2909089 [2] 邢玲, 邓凯凯, 吴红海, 等. 复杂网络视角下跨社交网络用户身份识别研究综述[J]. 电子科技大学学报, 2020, 49(6): 905–917. doi: 10.12178/1001-0548.2019182XING Ling, DENG Kaikai, WU Honghai, et al. Review of user identification across social networks: The complex network approach[J]. Journal of University of Electronic Science and Technology of China, 2020, 49(6): 905–917. doi: 10.12178/1001-0548.2019182 [3] 张树森, 梁循, 弭宝瞳, 等. 基于内容的社交网络用户身份识别方法[J]. 计算机学报, 2019, 42(8): 1739–1754. doi: 10.11897/SP.J.1016.2019.01739ZHANG Shusen, LIANG Xun, MI Baotong, et al. Content-based social network user identification methods[J]. Chinese Journal of Computers, 2019, 42(8): 1739–1754. doi: 10.11897/SP.J.1016.2019.01739 [4] HAO Tianyi, ZHOU Jingbo, CHENG Yunsheng, et al. User identification in cyber-physical space: A case study on mobile query logs and trajectories[C]. The 24th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Burlingame, USA, 2016: 71. [5] CHEN Wei, YIN Hongzhi, WANG Weiqing, et al. Exploiting spatio-temporal user behaviors for user linkage[C]. The ACM International Conference on Information and Knowledge Management, Singapore, 2017: 517–526. [6] KONDOR D, HASHEMIAN B, DE MONTJOYE Y A, et al. Towards matching user mobility traces in large-scale datasets[J]. IEEE Transactions on Big Data, 2020, 6(4): 714–726. doi: 10.1109/TBDATA.2018.2871693 [7] HAO Tianyi, ZHOU Jingbo, CHENG Yunsheng, et al. A unified framework for user identification across online and offline data[J]. IEEE Transactions on Knowledge and Data Engineering, 2022, 34(4): 1562–1575. doi: 10.1109/TKDE.2020.3000287 [8] HE Wenqiang, LI Yongjun, ZHANG Yinyin, et al. A binary-search-based locality-sensitive hashing method for cross-site user identification[J]. IEEE Transactions on Computational Social Systems, 2022, 10(2): 480–491. [9] 王前东. 经典轨迹的鲁棒相似度量算法[J]. 电子与信息学报, 2020, 42(8): 1999–2005. doi: 10.11999/JEIT190550WANG Qiandong. A robust trajectory similarity measure method for classical trajectory[J]. Journal of Electronics &Information Technology, 2020, 42(8): 1999–2005. doi: 10.11999/JEIT190550 [10] QI Mengjun, WANG Zhongyuan, HE Zheng, et al. User identification across asynchronous mobility trajectories[J]. Sensors, 2019, 19(9): 2102. doi: 10.3390/s19092102 [11] HAN Xiaohui, WANG Lianhai, XU Lijuan, et al. Social Media account linkage using user-generated geo-location data[C]. IEEE Conference on Intelligence and Security Informatics, Tucson, USA, 2016: 157–162. [12] 冯朔, 申德荣, 聂铁铮, 等. 一种基于最大公共子图的社交网络对齐方法[J]. 软件学报, 2019, 30(7): 2175–2187. doi: 10.13328/j.cnki.jos.005831FENG Shuo, SHEN Derong, NIE Tiezheng, et al. Maximum common subgraph based social network alignment method[J]. Journal of Software, 2019, 30(7): 2175–2187. doi: 10.13328/j.cnki.jos.005831 [13] 陈鸿昶, 徐乾, 黄瑞阳, 等. 一种基于用户轨迹的跨社交网络用户身份识别算法[J]. 电子与信息学报, 2018, 40(11): 2758–2764. doi: 10.11999/JEIT180130CHEN Hongchang, XU Qian, HUANG Ruiyang, et al. User identification across social networks based on user trajectory[J]. Journal of Electronics &Information Technology, 2018, 40(11): 2758–2764. doi: 10.11999/JEIT180130 [14] MA Jiangtao, QIAO Yaqiong, HU Guangwu, et al. Social account linking via weighted bipartite graph matching[J]. International Journal of Communication Systems, 2018, 31(7): e3471. doi: 10.1002/dac.3471 [15] XIAO Xiangye, ZHENG Yu, LUO Qiong, et al. Inferring social ties between users with human location history[J]. Journal of Ambient Intelligence and Humanized Computing, 2014, 5(1): 3–19. doi: 10.1007/s12652-012-0117-z [16] WANG Fengzi, ZHU Xinning, and MIAO Jiansong. Semantic trajectories-based social relationships discovery using WiFi monitors[J]. Personal and Ubiquitous Computing, 2017, 21(1): 85–96. doi: 10.1007/s00779-016-0983-z [17] LI Yongjun, JI Wenli, GAO Xing, et al. Matching user accounts with spatio-temporal awareness across social networks[J]. Information Sciences, 2021, 570: 1–15. doi: 10.1016/j.ins.2021.04.030 [18] 张伟, 李扬, 张吉, 等. 融合时空行为与社交关系的用户轨迹识别模型[J]. 计算机学报, 2021, 44(11): 2173–2188. doi: 10.11897/SP.J.1016.2021.02173ZHANG Wei, LI Yang, ZHANG Ji, et al. A user trajectory identification model with fusion of spatio-temporal behavior and social relation[J]. Chinese Journal of Computers, 2021, 44(11): 2173–2188. doi: 10.11897/SP.J.1016.2021.02173 [19] 沈佳琪, 周国民. 跨社交网络的同一用户识别算法[J]. 电子技术应用, 2022, 48(1): 109–114. doi: 10.16157/j.issn.0258-7998.211518SHEN Jiaqi and ZHOU Guomin. User alignment across social networks[J]. Application of Electronic Technique, 2022, 48(1): 109–114. doi: 10.16157/j.issn.0258-7998.211518 [20] HAN Xiaohui, WANG Lianhai, XU Shujiang, et al. Linking social network accounts by modeling user spatiotemporal habits[C]. 2017 IEEE International Conference on Intelligence and Security Informatics (ISI), Beijing, China, 2017: 19–24. [21] CHEN Wei, WANG Weiqing, YIN Hongzhi, et al. User account linkage across multiple platforms with location data[J]. Journal of Computer Science and Technology, 2020, 35(4): 751–768. doi: 10.1007/s11390-020-0250-7 [22] ZHOU Xueyan and YANG Jing. Matching user accounts based on location verification across social networks[J]. Revista Internacional de Métodos Numéricos para Cálculo y Diseñ o en Ingeniería, 2020, 36(1): 8. doi: 10.23967/j.rimni.2019.12.001 -

 下载:
下载:



图(4) / 表(7)
计量
- 文章访问数: 1186
- HTML全文浏览量: 913
- PDF下载量: 123
- 被引次数: 0
