

Saliency Detection of Panoramic Images Based on Robust Vision Transformer and Multiple Attention
-
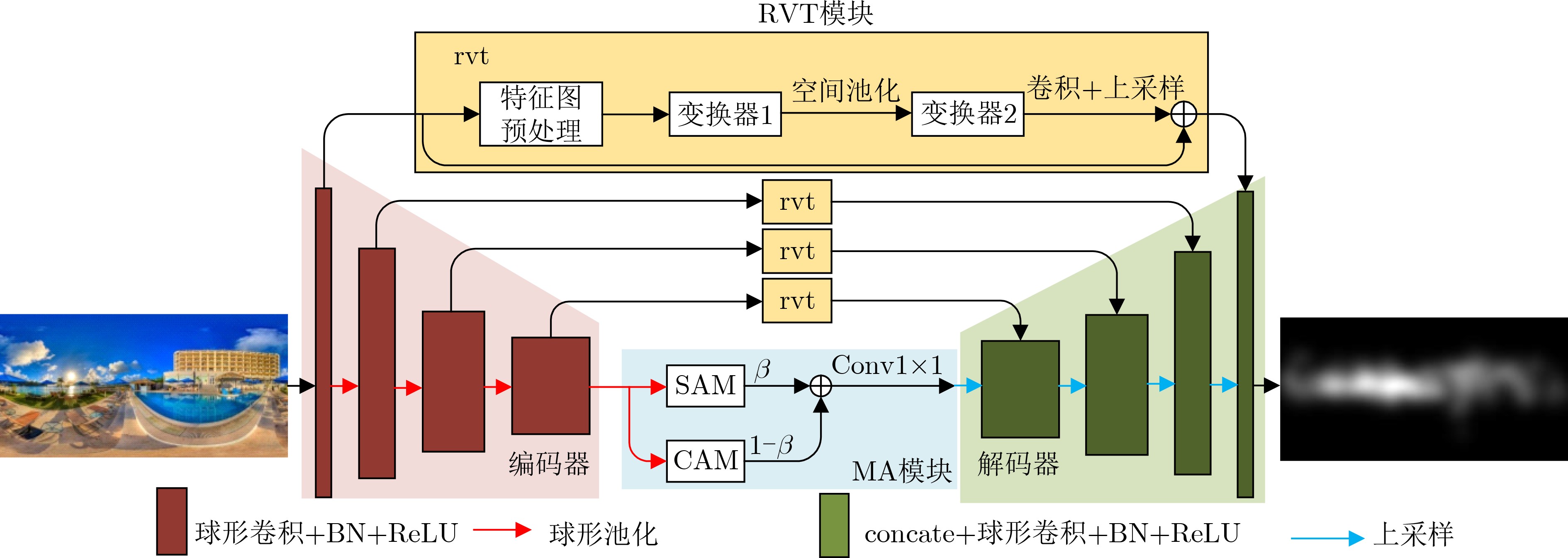
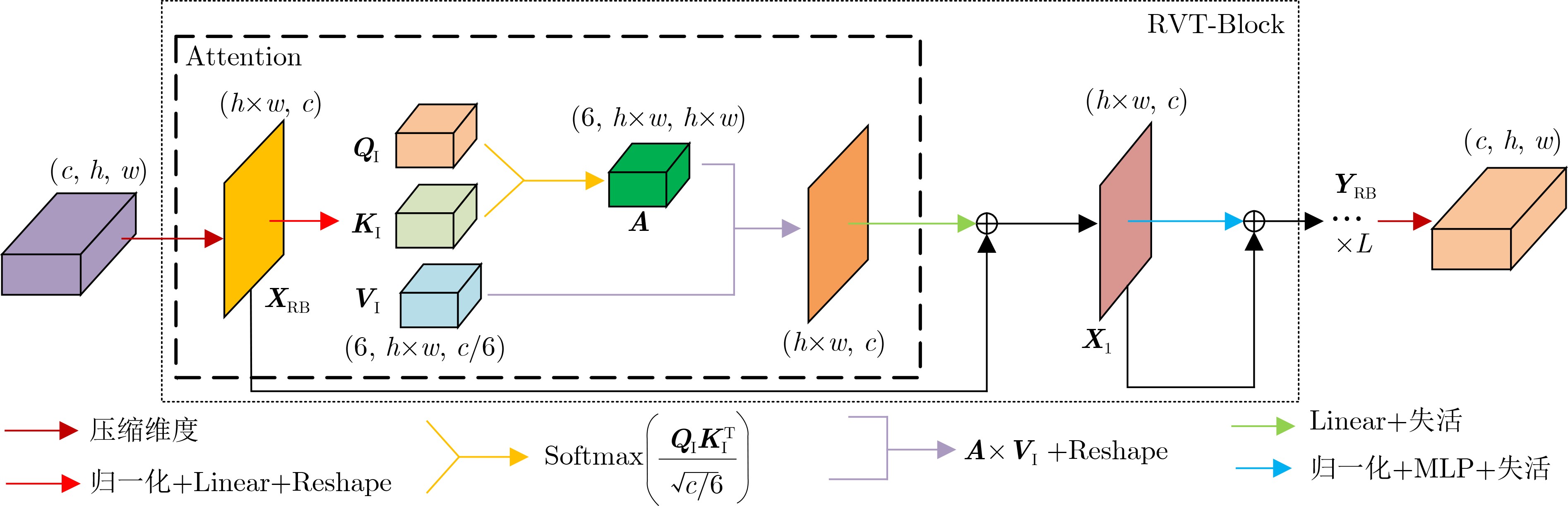
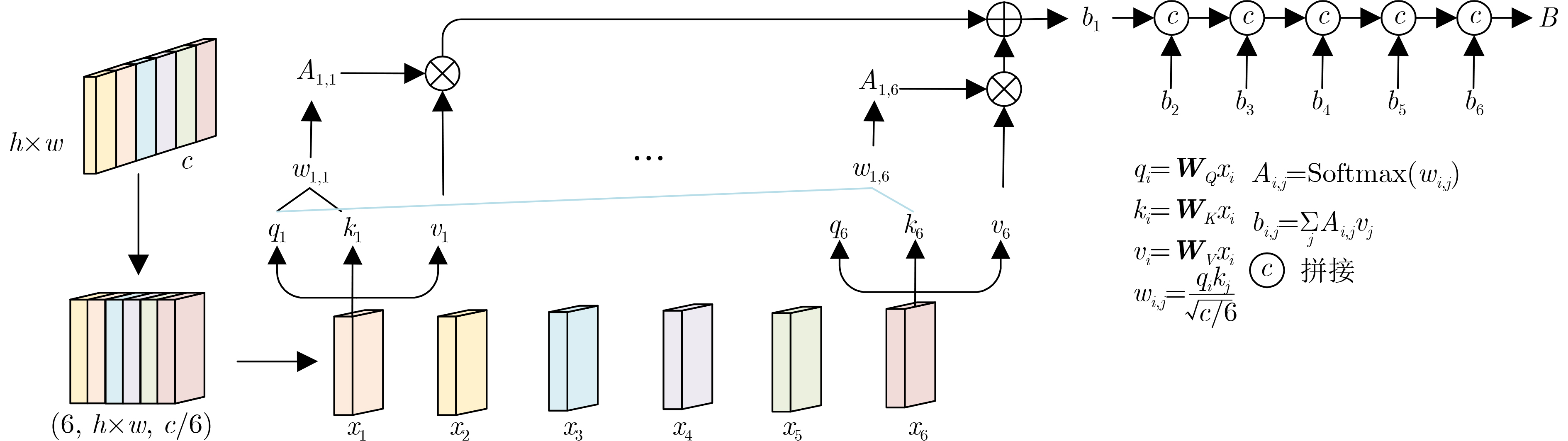
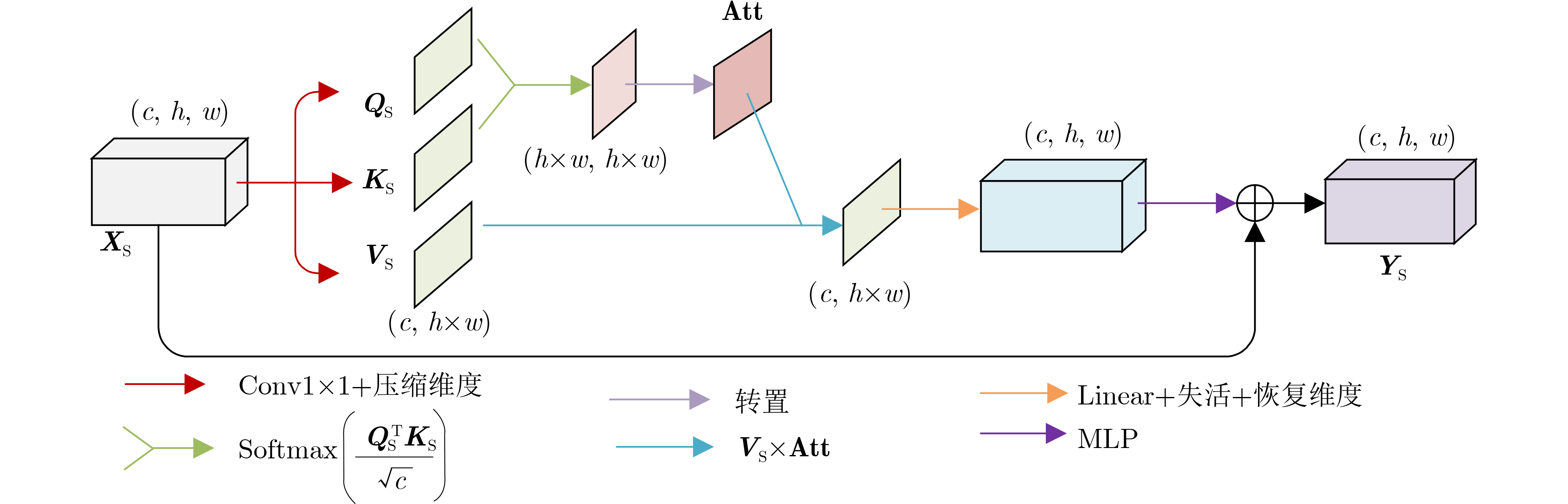
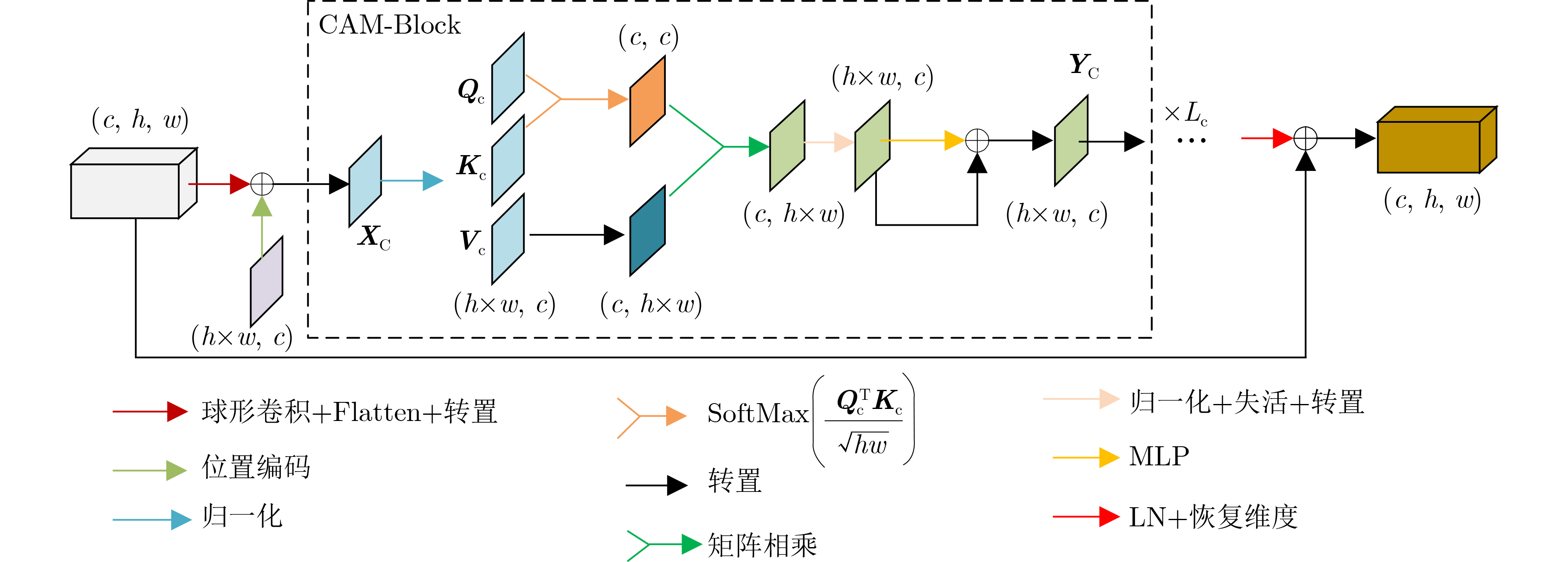
摘要: 针对当前全景图像显著性检测方法存在检测精度偏低、模型收敛速度慢和计算量大等问题,该文提出一种基于鲁棒视觉变换和多注意力的U型网络(URMNet)模型。该模型使用球形卷积提取全景图像的多尺度特征,减轻了全景图像经等矩形投影后的失真。使用鲁棒视觉变换模块提取4种尺度特征图所包含的显著信息,采用卷积嵌入的方式降低特征图的分辨率,增强模型的鲁棒性。使用多注意力模块,根据空间注意力与通道注意力间的关系,有选择地融合多维度注意力。最后逐步融合多层特征,形成全景图像显著图。纬度加权损失函数使该文模型具有更快的收敛速度。在两个公开数据集上的实验表明,该文所提模型因使用了鲁棒视觉变换模块和多注意力模块,其性能优于其他6种先进方法,能进一步提高全景图像显著性检测精度。Abstract: Considering the problems of low detection accuracy, slow model convergence speed and large amount of computation in current panorama image saliency detection methods, a U-Net with Robust vision transformer and Multiple attention at tention modules (URMNet) is proposed. Sphere convolution is used to extract multi-scale features of panoramic images of the model,while reducing the distortion of panoramic images after equirectangular projection.The robust visual transformer module is used to extract the salient information contained in the feature maps of four scales, and the convolutional embedding is used to reduce the resolution of the feature maps and enhance the robustness of the model. The multiple attention module is used to integrate selectively multi-dimensional attention according to the relationship between spatial attention and channel attention. Finally, the multi-layer features are gradually fused to form a panoramic image saliency map. The latitude weighted loss function is used to make the model in this paper have a faster convergence rate. Experiments on two public datasets show that the model proposed in this paper outperforms other 6 advanced methods due to the use of a robust visual transformer module and a multiple attention module, and can further improve the saliency detection accuracy of panoramic images.
-
表 1 不同加权因子的实验结果
SMA $ \beta $ CAM ${{1 - } }\beta$ CC↑ SIM↑ KLDiv↓ NSS↑ AUC_Judd↑ AUC_Borji↑ Grade 0 1.0 0.9005 0.7787 0.1970 3.5346 0.9914 0.9755 3.3809 0.2 0.8 0.8803 0.7785 0.4403 3.4964 0.9861 0.9618 0.7047 0.4 0.6 0.9008 0.7921 0.5070 3.7190 0.9936 0.9795 3.4726 0.5 0.5 0.9067 0.8119 0.2198 3.2849 0.9898 0.9772 3.5050 0.6 0.4 0.8912 0.7871 0.2350 3.2212 0.9840 0.9655 1.2312 0.8 0.2 0.8771 0.7561 0.2317 3.2893 0.9864 0.9756 1.1757 1.0 0 0.9023 0.7890 0.3775 3.6737 0.9919 0.9774 3.4871  下载: 导出CSV
下载: 导出CSV
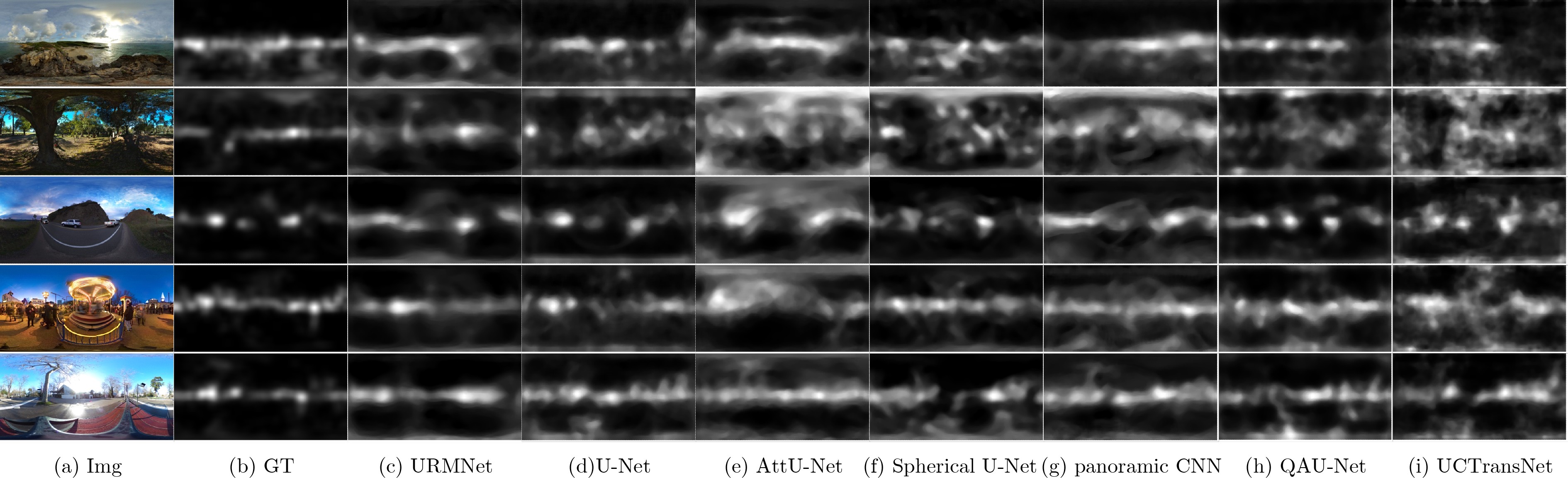
表 2 AAOI数据集上各模型客观指标对比
方法 CC↑ SIM↑ KLDiv↓ NSS↑ AUC_Judd↑ AUC_Borji↑ URMNet 0.8934 0.7918 0.1787 3.7113 0.9865 0.9707 U-Net(2015)[16] 0.8550 0.7694 0.2647 2.9639 0.9741 0.9582 AttU-Net(2018)[17] 0.8663 0.7675 0.2359 3.3212 0.9796 0.9632 Spherical U-Net(2018)[3] 0.7832 0.7304 0.3167 2.4795 0.9467 0.9295 panoramic CNN(2020)[5] 0.8520 0.7533 0.2412 3.1999 0.9778 0.9641 QAU-Net(2021)[18] 0.7314 0.6530 0.4203 1.8678 0.9226 0.8926 UCTransNet(2021)[19] 0.8619 0.7731 0.2105 3.0204 0.9814 0.9625
下载: 导出CSV
表 3 ASalient360数据集上各模型客观指标对比
方法 CC↑ SIM↑ KLDiv↓ NSS↑ AUC_Judd↑ AUC_Borji↑ URMNet 0.6683 0.6602 0.5834 2.9874 0.9449 0.9336 U-Net(2015)[16] 0.6061 0.6404 0.4397 2.6228 0.9180 0.8973 AttU-Net(2018)[17] 0.5589 0.6262 0.4892 1.9840 0.8871 0.8644 Spherical U-Net(2018)[3] 0.6028 0.6412 0.6714 2.5834 0.9384 0.9183 panoramic CNN(2020)[5] 0.6225 0.6527 0.4049 2.0324 0.8975 0.8482 QAU-Net(2021)[18] 0.5641 0.6280 0.5138 2.7556 0.8889 0.8859 UCTransNet(2021)[19] 0.5429 0.6165 0.5246 2.0041 0.8990 0.8683
下载: 导出CSV
表 4 网络和损失函数的消融实验
模型 损失函数 CC↑ SIM↑ KLDiv↓ NSS↑ AUC_Judd↑ AUC_Borji↑ Baseline URMNet L1 L2 L3 Loss √ √ 0.7389 0.6935 2.2079 1.5107 0.8634 0.8310 √ √ 0.7300 0.6886 2.2614 1.5002 0.8636 0.8169 √ √ 0.6629 0.6604 1.2939 1.2369 0.8184 0.7806 √ √ 0.8604 0.7618 0.3906 3.0463 0.9846 0.9614 √ √ 0.7456 0.7007 2.2068 1.5043 0.8627 0.8304 √ √ 0.7565 0.6845 2.9497 1.6848 0.8909 0.8166 √ √ 0.7557 0.6909 3.1000 1.6607 0.8830 0.8465 √ √ 0.9067 0.8119 0.2198 3.2849 0.9898 0.9772
下载: 导出CSV
表 5 RVT和MA模块消融实验结果
RVT MA CC↑ SIM↑ KLDiv↓ NSS↑ AUC_Judd↑ AUC_Borji↑ × × 0.8335 0.7392 0.2947 2.9639 0.9779 0.9604 √ × 0.8664 0.7788 0.3682 3.0885 0.9821 0.9702 × √ 0.8553 0.7118 0.3317 3.4291 0.9848 0.9576 √ √ 0.8922 0.7805 0.2278 3.3100 0.9910 0.9786
下载: 导出CSV
表 6 不同模型泛化性能对比
方法 CC↑ SIM↑ KLDiv↓ NSS↑ AUC_Judd↑ AUC_Borji↑ URMNet 0.5899 0.6116 1.0708 1.8395 0.9181 0.8917 U-Net(2015)[16] 0.5402 0.5733 1.9622 1.6975 0.9022 0.8750 AttU-Net(2018)[17] 0.4906 0.5572 1.9561 1.4668 0.8896 0.8556 panoramic CNN(2020)[5] 0.5146 0.5770 1.1245 1.4486 0.8865 0.8504 QAU-Net(2021)[18] 0.5044 0.5989 0.5373 1.5522 0.8854 0.8362 UCTransNet(2021)[19] 0.5410 0.5760 1.8189 1.7359 0.9100 0.8874
下载: 导出CSV
-
[1] 刘政怡, 段群涛, 石松, 等. 基于多模态特征融合监督的RGB-D图像显著性检测[J]. 电子与信息学报, 2020, 42(4): 997–1004. doi: 10.11999/JEIT190297LIU Zhengyi, DUAN Quntao, SHI Song, et al. RGB-D image saliency detection based on multi-modal feature-fused supervision[J]. Journal of Electronics &Information Technology, 2020, 42(4): 997–1004. doi: 10.11999/JEIT190297 [2] WEN Anzhou. Real-time panoramic multi-target detection based on mobile machine vision and deep learning[J]. Journal of Physics:Conference Series, 2020, 1650: 032113. doi: 10.1088/1742-6596/1650/3/032113 [3] ZHANG Ziheng, XU Yanyu, YU Jingyi, et al. Saliency detection in 360° videos[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 504–520. [4] COORS B, CONDURACHE A P, and GEIGER A. SphereNet: Learning spherical representations for detection and classification in omnidirectional images[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 525–541. [5] MARTÍN D, SERRANO A, and MASIA B. Panoramic convolutions for 360° single-image saliency prediction[C/OL]. The Fourth Workshop on Computer Vision for AR/VR, 2020: 1–4. [6] DAI Feng, ZHANG Youqiang, MA Yike, et al. Dilated convolutional neural networks for panoramic image saliency prediction[C]. 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 2020: 2558–2562. [7] MONROY R, LUTZ S, CHALASANI T, et al. SalNet360: Saliency maps for omni-directional images with CNN[J]. Signal Processing:Image Communication, 2018, 69: 26–34. doi: 10.1016/j.image.2018.05.005 [8] DAHOU Y, TLIBA M, MCGUINNESS K, et al. ATSal: An attention Based Architecture for Saliency Prediction in 360° Videos[M]. Cham: Springer, 2021: 305–320. [9] ZHU Dandan, CHEN Yongqing, ZHAO Defang, et al. Saliency prediction on omnidirectional images with attention-aware feature fusion network[J]. Applied Intelligence, 2021, 51(8): 5344–5357. doi: 10.1007/s10489-020-01857-3 [10] CHAO Fangyi, ZHANG Lu, HAMIDOUCHE W, et al. A multi-FoV viewport-based visual saliency model using adaptive weighting losses for 360° images[J]. IEEE Transactions on Multimedia, 2020, 23: 1811–1826. doi: 10.1109/tmm.2020.3003642 [11] XU Mai, YANG Li, TAO Xiaoming, et al. Saliency prediction on omnidirectional image with generative adversarial imitation learning[J]. IEEE Transactions on Image Processing, 2021, 30: 2087–2102. doi: 10.1109/tip.2021.3050861 [12] GUTIÉRREZ J, DAVID E J, COUTROT A, et al. Introducing un salient360! Benchmark: A platform for evaluating visual attention models for 360° contents[C]. The 2018 Tenth International Conference on Quality of Multimedia Experience, Cagliari, Italy, 2018: 1–3. [13] MAO Xiaofeng, QI Gege, CHEN Yuefeng, et al. Towards robust vision transformer[J]. arXiv: 2105.07926, 2021. [14] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010. [15] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C/OL]. The 9th International Conference on Learning Representations, 2021. [16] RONNEBERGER O, FISCHER P, and BROX T. U-Net: Convolutional networks for biomedical image segmentation[C]. The 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 2015: 234–241. [17] OKTAY O, SCHLEMPER J, LE FOLGOC L, et al. Attention u-net: Learning where to look for the pancreas[J]. arXiv: 1804.03999, 2018. [18] HONG Luminzi, WANG Risheng, LEI Tao, et al. Qau-Net: Quartet attention U-Net for liver and liver-tumor segmentation[C]. 2021 IEEE International Conference on Multimedia and Expo, Shenzhen, China, 2021: 1–6. [19] WANG Haonan, CAO Peng, WANG Jiaqi, et al. UCTransNet: Rethinking the skip connections in U-Net from a channel-wise perspective with transformer[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2022, 36(3): 2441–2249. doi: 10.1609/aaai.v36i3.20144 [20] CORNIA M, BARALDI L, SERRA G, et al. Predicting human eye fixations via an LSTM-based saliency attentive model[J]. IEEE Transactions on Image Processing, 2018, 27(10): 5142–5154. doi: 10.1109/tip.2018.2851672 [21] LOU Jianxun, LIN Hanhe, MARSHALL D, et al. TranSalNet: Towards perceptually relevant visual saliency prediction[J]. arXiv: 2110.03593, 2021. -

 下载:
下载:





图(9) / 表(7)
计量
- 文章访问数: 1553
- HTML全文浏览量: 869
- PDF下载量: 150
- 被引次数: 0
