

High Performance YOLOv5: Research on High Performance Target Detection Algorithm for Embedded Platform
-
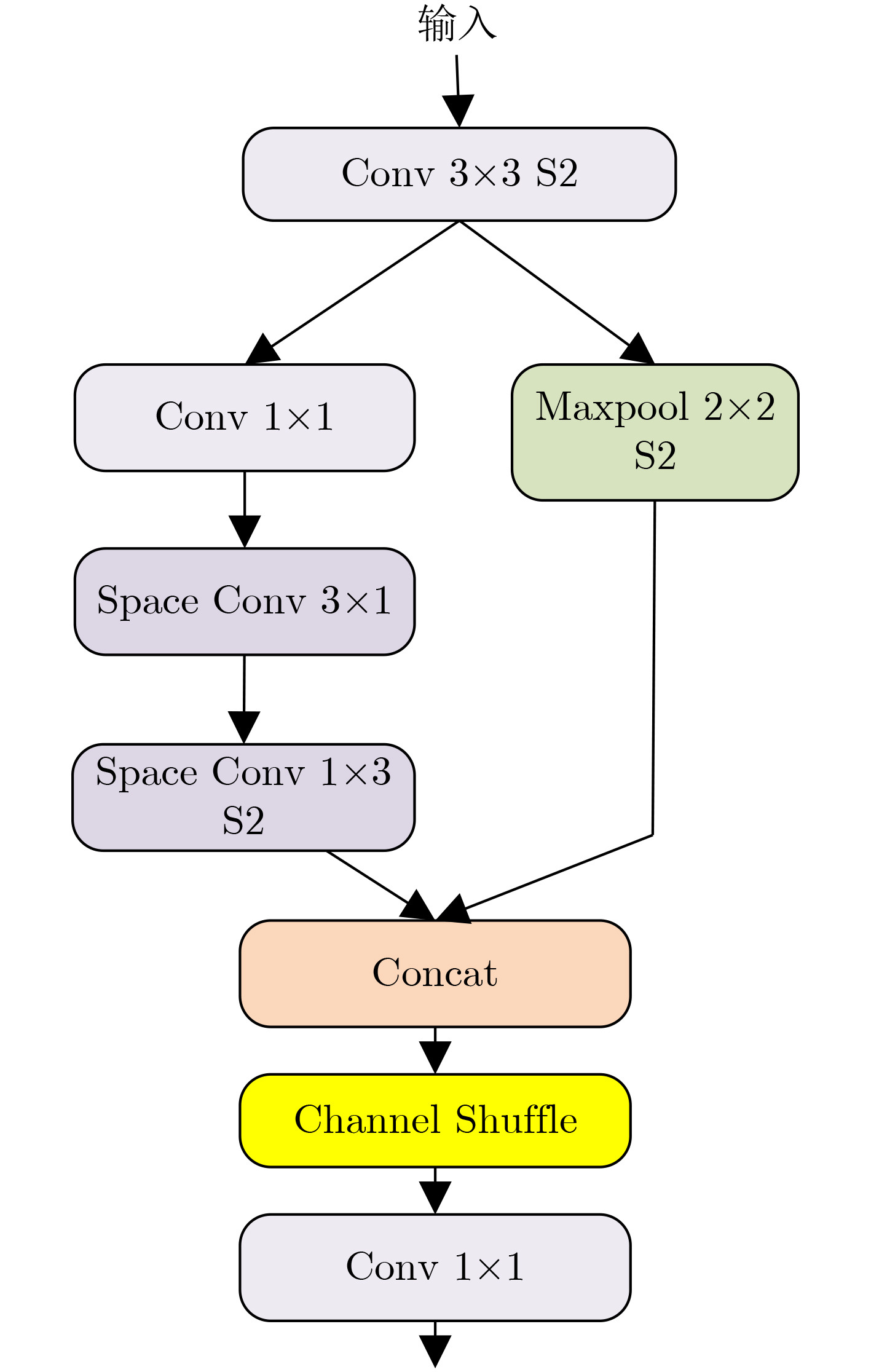
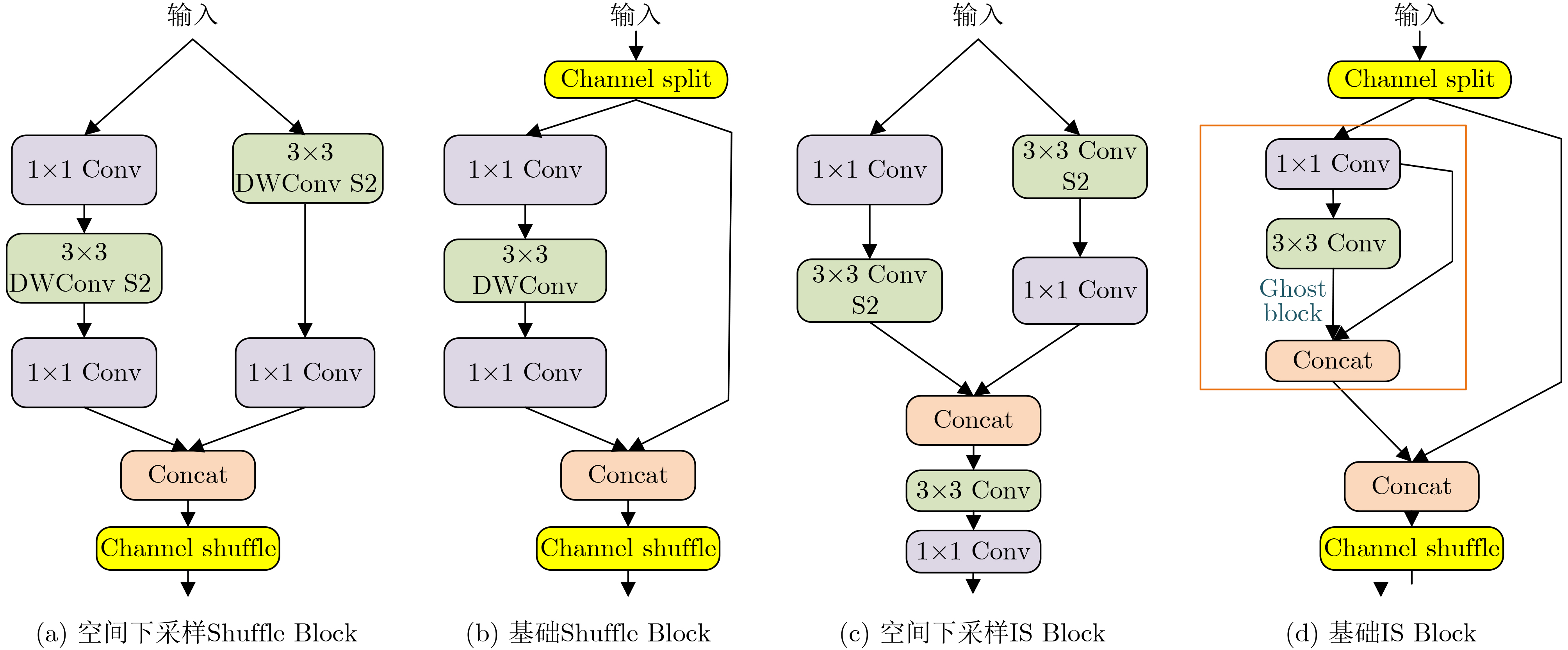
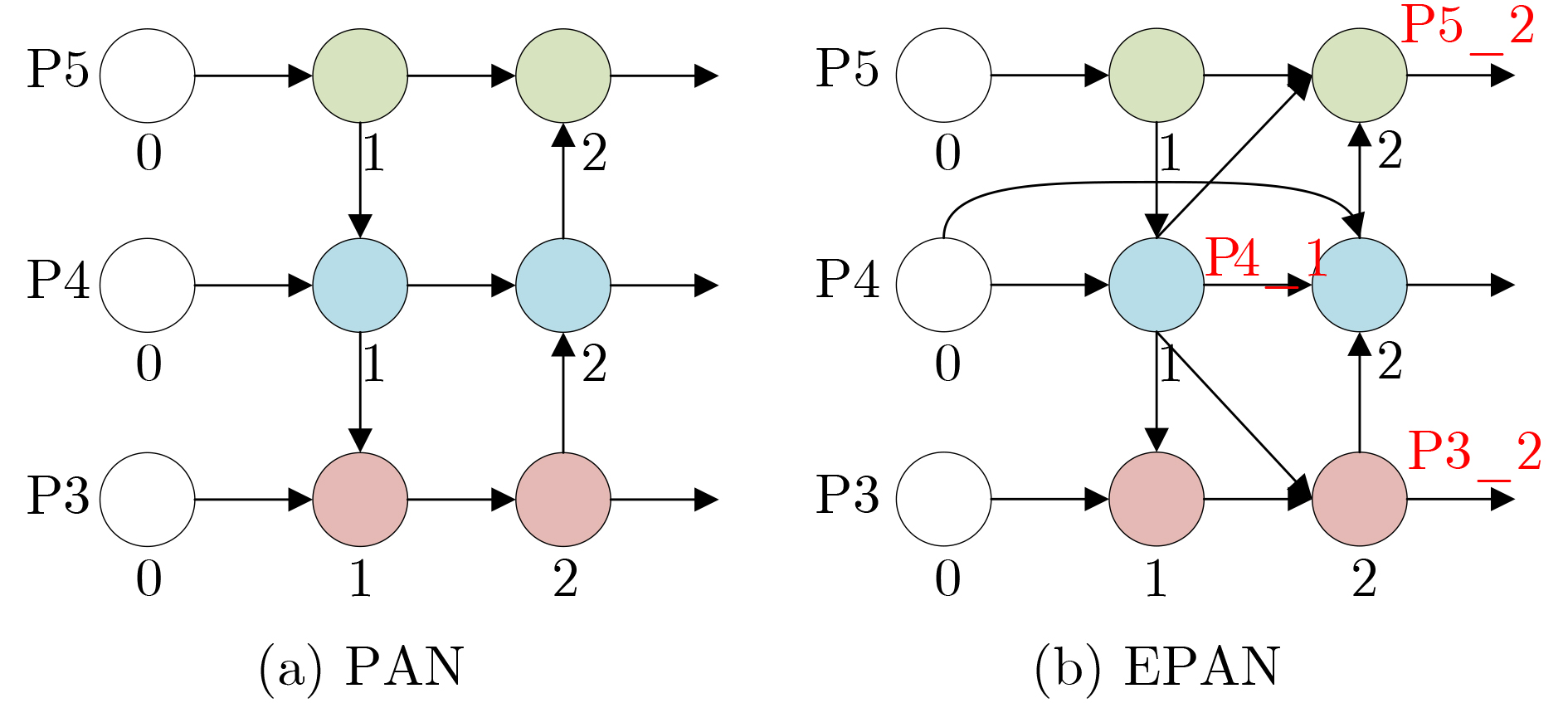
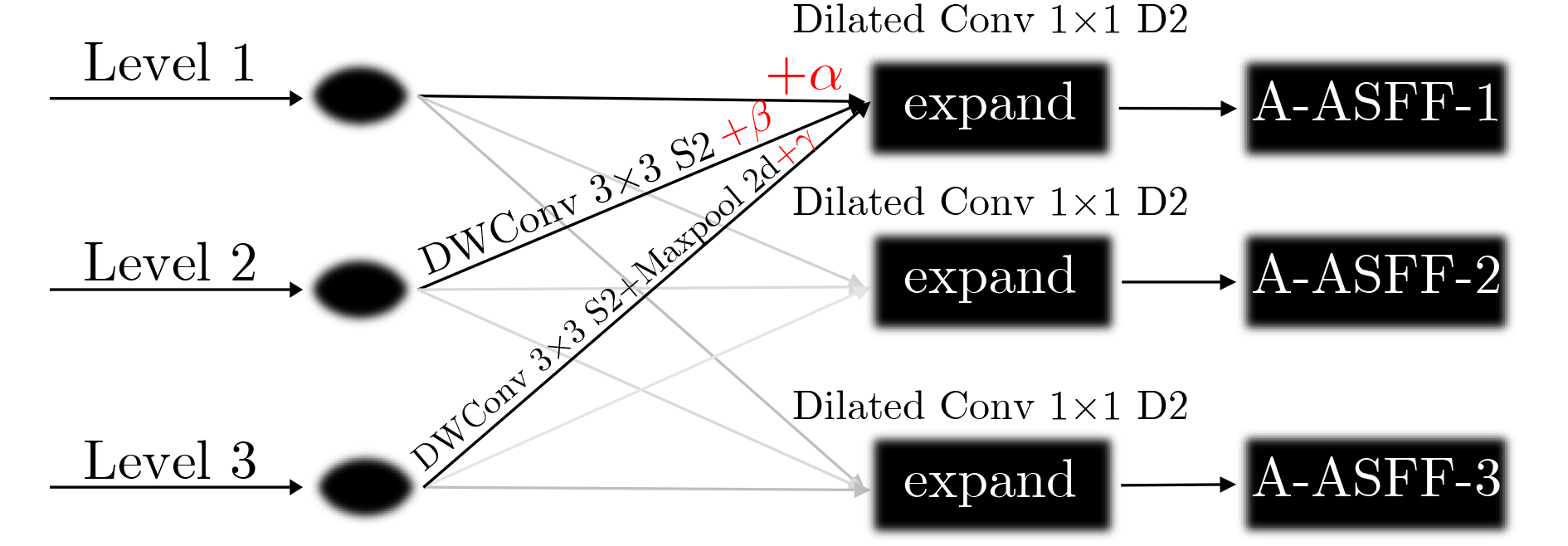
摘要: 针对目前深度学习单阶段检测算法综合性能不平衡以及在嵌入式设备难以部署等问题,该文提出一种面向嵌入式平台的高性能目标检测算法。基于只看1次5代 (YOLOv5)网络,改进算法首先在主干网络部分采用设计的空间颈块代替原有的焦点模块,结合改进的混洗网络2代替换原有的跨级局部暗网络,减小空间金字塔池化 (SPP)的内核尺寸,实现了主干网络的轻量化。其次,颈部采用了基于路径聚合网络 (PAN)设计的增强型路径聚合网络 (EPAN),增加了P6大目标输出层,提高了网络的特征提取能力。然后,检测头部分采用以自适应空间特征融合 (ASFF)为基础设计的自适应空洞空间特征融合 (A-ASFF)来替代原有的检测头,解决了物体尺度变化问题,在少量增加额外开销情况下大幅提升检测精度。最后,函数部分采用高效交并比 (EIoU)代替完整交并比 (CIoU)损失函数,采用S型加权线性单元 (SiLU)代替HardSwish激活函数,提升了模型的综合性能。实验结果表明,与YOLOv5-S相比,该文提出的同版本算法在mAP@.5,mAP@.5:.95上分别提高了4.6%和6.3%,参数量降低了43.5%,计算复杂度降低了12.0%,在Jetson Nano平台上使用原模型和TensorRT加速模型进行速度评估,分别减少了8.1%和9.8%的推理延迟。该文所提算法的综合指标超越了众多优秀的目标检测网络,对嵌入式平台更为友好,具有实际应用意义。Abstract: Considering the problems of imbalanced comprehensive performance of the current deep learning single-stage detection algorithms and difficult deployment in embedded devices, one High-Performance object detection algorithm for embedded platforms is proposed in this paper. Based on the You Only Look Once v5 (YOLOv5) network, in the backbone network part of the improved algorithm firstly, the original focus module and original Cross Stage Partial Darknet are replaced by a designed space stem block and an improved ShuffleNetv2, respectively. The kernel size of Space Pyramid Pooling (SPP) is reduced to lighten the backbone network. Secondly, in the neck, an Enhanced Path Aggregation Network (EPAN) based on Path Aggregation Network (PAN) design is adopted, a P6 large target output layer is added, and the feature extraction ability of the network is improved. And then, in the head, an Adaptive-Atrous Spatial Feature Fusion (A-ASFF) based on Adaptive Spatial Feature Fusion (ASFF) is used to replace the original detection head, the object scale change problem is solved, and the detection accuracy is greatly improved with a small amount of additional overhead. Finally, in the function section, a Complete Intersection over Union (CIoU) loss function is replaced by the Efficient Intersection over Union (EIoU), a HardSwish activation function is replaced by a Sigmoid weighted Linear Unit (SiLU), and model synthesis ability has been improved. The experimental results show that compared to YOLOv5-S, the mAP@.5 and mAP@.5:95 of the same version of the algorithm proposed in this paper are increased by 4.6% and 6.3% while the number of parameters and the computational complexity are reduced by 43.5% and 12.0%, respectively. Using the original model and the TensorRT accelerated model for speed evaluation on the Jetson Nano platform, the inference latency is reduced by 8.1% and 9.8%, respectively. The comprehensive indicators of many excellent object detection networks and their friendliness to embedded platforms are surpassed by the algorithm proposed in this paper and the practical meaning is generated.
-
表 1 网络叠加优化研究结果
方法 mAP@.5(%) mAP@.5:.95(%) Params(M) FLOPs(G) Latency (ms) YOLOv5 69.7 42.1 7.3 8.3 11.2 替换SiLU 70.2(+0.5) 42.4(+0.3) 7.3 8.3 10.8(–0.4) 修改SPP(3,5,9) 70.2 42.4 7.3 8.3 10.3(–0.5) 替换Space Stem 71.5(+1.3) 44.1(+1.7) 7.3 8.4 10.5(+0.2) 替换IS Block 70.8(–0.7) 43.2(–0.9) 3.8 7.0 8.3(–2.2) 替换EPAN 71.8(+1.0) 44.0(+0.8) 3.9 7.1 8.7(+0.4) 增添P6 Block 73.0(+1.2) 45.5(+1.5) 4.0 7.1 8.9(+0.2) 替换A-ASFF/ASFF 74.1/74.3(+1.1/+1.3) 47.6/47.7(+2.1/+2.2) 4.1/6.6 7.3/10.1 10.1/11.7(+1.2/2.8) 替换EIoU 74.3(+0.2) 48.4(+0.8) 4.1 7.3 10.1  下载: 导出CSV
下载: 导出CSV
表 2 本文方法与基线各模块的对比实验结果
原始方法/本文方法 Params(修改前/后) MFLOPs(修改前/后) mAP@.5(修改前/后)(%) SPP(5,9,13) / SPP(3,5,9) 656896.0/656896.0 257.8/257.8 69.7/69.7 Focus / Space Stem 44032.0/67968.0(+54.0%) 1643.0/2497.0(+51.9%) 69.7/71.3(+1.6) CSP Block / IS Block 986112.0/882432.0(–10.5%) 1549.0/71.3(–95.4%) 69.7/69.4(–0.3) PAN / EPAN 193654200.0/200566200.0(+3.6%) 5838.6/5841.4(+0.1%) 69.7/70.8(+1.1) Head / A-ASFF Head 158300900.0/175772300.0(+11.0%) 1442.7/1719.3(+19.2%) 69.7/71.6(+1.9)
下载: 导出CSV
表 3 本文方法与基线消融对比实验结果
SiLU Space Stem IS Block SPP
(3,5,9)EPAN P6 A-ASFF EIOU mAP@.5(%) mAP@.5:.95(%) Params(M) FLOPs(G) Latency (ms) 69.7 42.1 7.3 8.3 11.2 √ 70.2↑ 42.4↑ 7.3 8.3 10.8↑ √ 71.3↑ 43.9↑ 7.3 8.4↓ 11.5↓ √ 69.4↓ 41.3↓ 3.8↑ 6.9↑ 8.9↑ √ 69.7 42.1 7.3 8.3 10.7↑ √ 70.8↑ 43.3↑ 7.4↓ 8.4↓ 11.6↓ √ 71.6↑ 44.9↑ 7.5↓ 8.4↓ 11.4↓ √ 71.6↑ 45.3↑ 7.6↓ 8.7↓ 12.5↓ √ 70.0↑ 42.9↑ 7.3 8.3 11.2 √ √ 71.3↑ 43.9↑ 7.3 8.4↓ 11.1↑ √ √ 69.4↓ 41.3↓ 3.8↑ 6.9↑ 8.4↑ √ √ 70.8↑ 43.2↑ 3.8↑ 7.0↑ 9.1↑ √ √ √ 70.8↑ 43.2↑ 3.8↑ 7.0↑ 8.6↑ √ √ 72.5↑ 45.7↑ 7.6↓ 8.4↓ 11.7↓ √ √ √ √ √ √ √ √ 74.3↑ 48.4↑ 4.1↑ 7.3↑ 10.1↑
下载: 导出CSV
表 4 在PASCAL VOC 2012数据集上不同算法性能比较
算法 Params(M) FLOPs(G) mAP@.5(%) mAP@.5:.95(%) Latency/(ms) 模型大小 (MB) PC Nano TRT YOLOv3-Tiny 8.7 6.4 47.9 21.5 – – – 33.1 YOLOv4-Tiny 5.9 8.0 54.8 25.6 – – – 23.7 NanoDet 0.9 1.4 54.4 25.2 8.5 – – 1.7 NanoDet-Plus 1.2 1.8 57.1 29.3 9.0 – – 2.3 YOLOv5-N 1.9 2.2 61.9 34.2 9.2 115.2 25.8 4.0 YOLOv5-S 7.3 8.3 69.7 42.1 11.3 152.8 45.7 14.9 YOLOv5-M 21.6 25.3 75.1 49.8 13.2 315.6 97.4 43.5 HP-YOLOv5-N 1.1 1.9 67.2 39.6 8.9 108.4 23.9 3.1 HP-YOLOv5-S 4.1 7.3 74.3 48.4 10.1 140.4 41.2 11.4 HP-YOLOv5-M 11.0 19.1 76.7 52.7 12.5 284.5 86.1 35.6
下载: 导出CSV
-
[1] 罗会兰, 陈鸿坤. 基于深度学习的目标检测研究综述[J]. 电子学报, 2020, 48(6): 1230–1239. doi: 10.3969/j.issn.0372-2112.2020.06.026LUO Huilan and CHEN Hongkun. Survey of object detection based on deep learning[J]. Acta Electronica Sinica, 2020, 48(6): 1230–1239. doi: 10.3969/j.issn.0372-2112.2020.06.026 [2] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 580–587. [3] LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: Single shot MultiBox detector[C]. The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 21–37. [4] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA, 2016: 779–788. [5] REDMON J and FARHADI A. YOLO9000: Better, faster, stronger[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, USA, 2017: 6517–6525. [6] REDMON J and FARHADI A. YOLOv3: An incremental improvement[EB/OL]. http://arxiv.org/abs/1804.02767, 2018. [7] BOCHKOVSKIY A, WANG C Y, and LIAO H Y M. YOLOv4: Optimal speed and accuracy of object detection[EB/OL]. https://arxiv.org/abs/2004.10934v1, 2020. [8] ULTRALYTICS. YOLOv5[EB/OL]. https://github.com/ultralytics/YOLOv5, 2021. [9] 赖润平, 周鹏程, 张梓赫, 等. 基于Jetson Nano的目标跟踪小车的设计与实现[J]. 现代信息科技, 2021, 5(4): 183–187. doi: 10.19850/j.cnki.2096-4706.2021.04.046LAI Runping, ZHOU Pengcheng, ZHANG Zihe, et al. Design and implementation of object tracking car based on Jetson Nano[J]. Modern Information Technology, 2021, 5(4): 183–187. doi: 10.19850/j.cnki.2096-4706.2021.04.046 [10] 王文胜, 李继旺, 吴波, 等. 基于YOLOv5交通标志识别的智能车设计[J]. 国外电子测量技术, 2021, 40(10): 158–164. doi: 10.19652/j.cnki.femt.2102913WANG Wensheng, LI Jiwang, WU Bo, et al. Smart car design based on traffic sign recognition via YOLOv5[J]. Foreign Electronic Measurement Technology, 2021, 40(10): 158–164. doi: 10.19652/j.cnki.femt.2102913 [11] WANG Xiangheng, YUE Xuebin, LI Hengyi, et al. A high-efficiency dirty-egg detection system based on YOLOv4 and TensorRT[C]. 2021 International Conference on Advanced Mechatronic Systems (ICAMechS), Tokyo, Japan, 2021: 75–80. [12] WANG C Y, BOCHKOVSKIY A, and LIAO H Y M. Scaled-yolov4: Scaling cross stage partial network[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 13024–13033. [13] MA Ningning, ZHANG Xiangyu, ZHENG Haitao, et al. Shufflenet V2: Practical guidelines for efficient CNN architecture design[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 116–131. [14] RANGILYU. NanoDet[EB/OL]. https://github.com/RangiLyu/nanodet, 2021. [15] LIU Songtao, HUANG Dihuang, and WANG Yunhong. Learning spatial fusion for single-shot object detection[EB/OL]. https://arxiv.org/abs/1911.09516, 2019. [16] WANG R J, LI Xiang, and LING C X. Pelee: A real-time object detection system on mobile devices[EB/OL]. https://arxiv.org/abs/1804.06882, 2019. [17] HAN Kai, WANG Yunhe, TIAN Qi, et al. GhostNet: More features from cheap operations[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 1577–1586. [18] QI Delong, TAN Weijun, YAO Qi, et al. YOLO5Face: Why reinventing a face detector[EB/OL]. https://arxiv.org/abs/2105.12931, 2022. [19] ZHANG Yifan, REN Weiqiang, ZHANG Zhang, et al. Focal and efficient IOU loss for accurate bounding box regression[EB/OL]. https://arxiv.org/abs/2101.08158, 2021. [20] ELFWING S, UCHIBE E, and DOYA K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning[J]. Neural Networks, 2018, 107: 3–11. doi: 10.1016/j.neunet.2017.12.012 -


 下载:
下载:



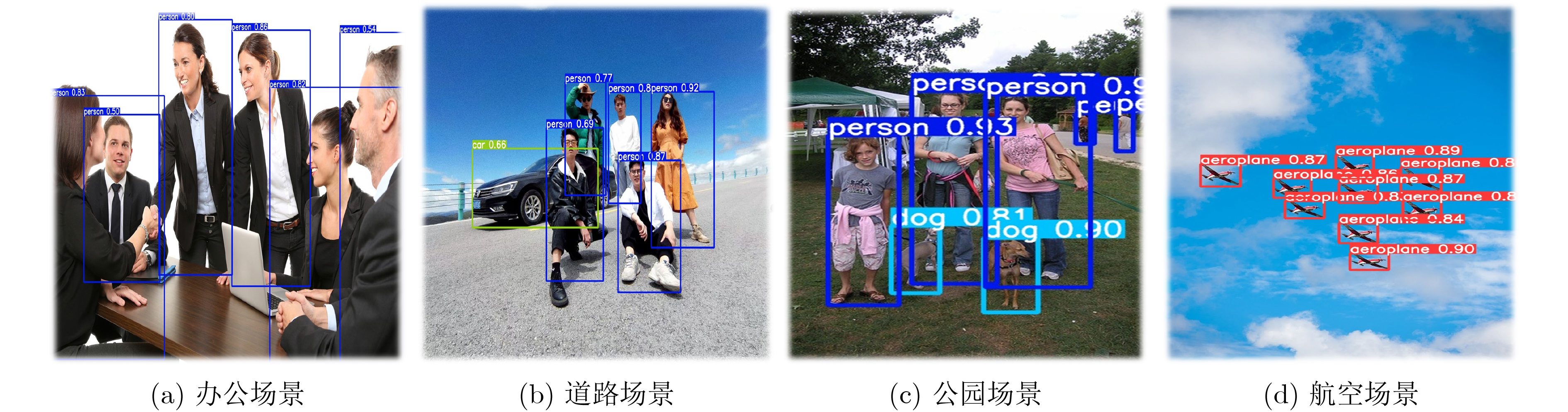


图(9) / 表(4)
计量
- 文章访问数: 3505
- HTML全文浏览量: 2911
- PDF下载量: 507
- 被引次数: 0
