

Caching and Update Strategy Based on Content Popularity and Information Freshness for Fog Radio Access Networks
-
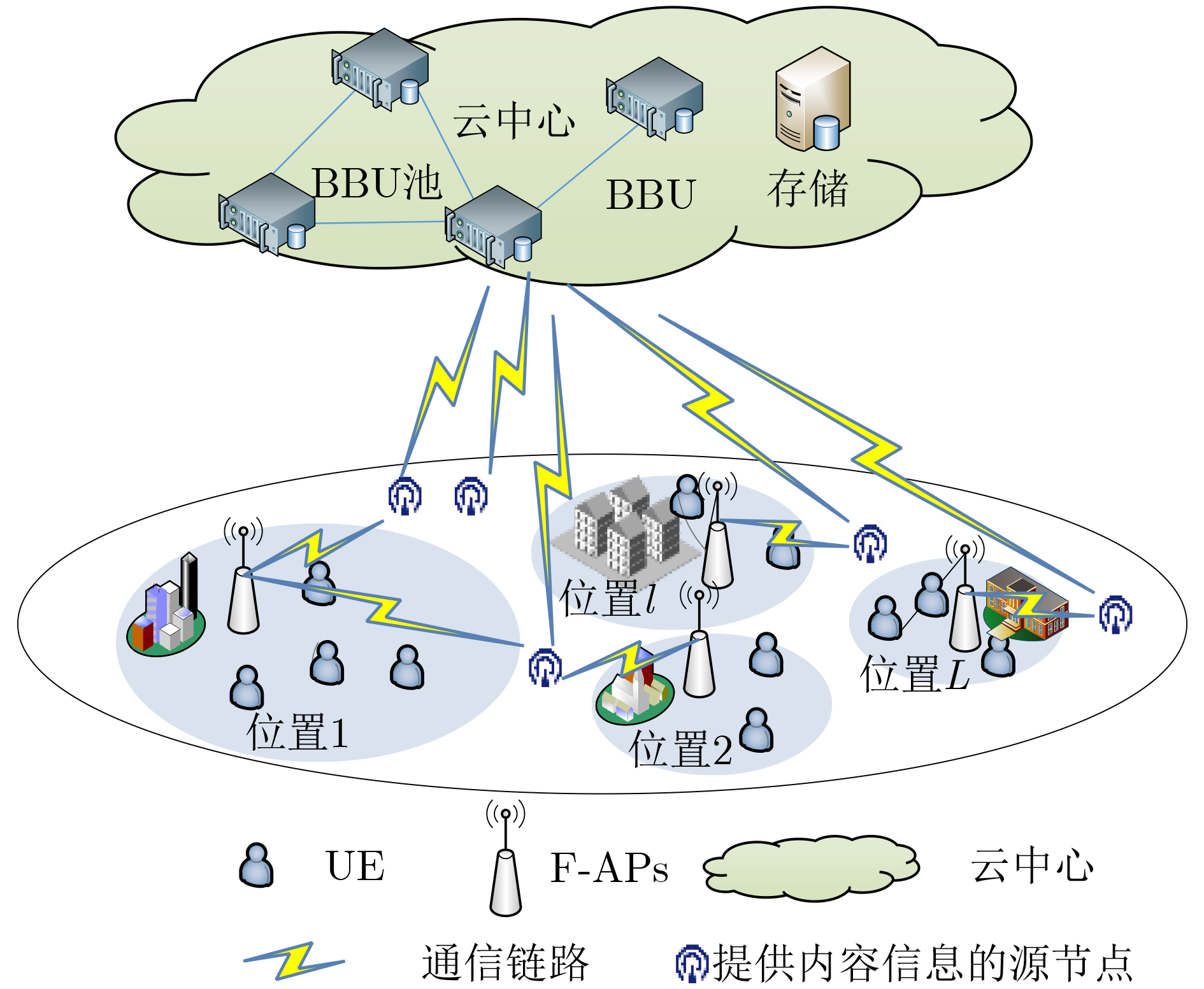
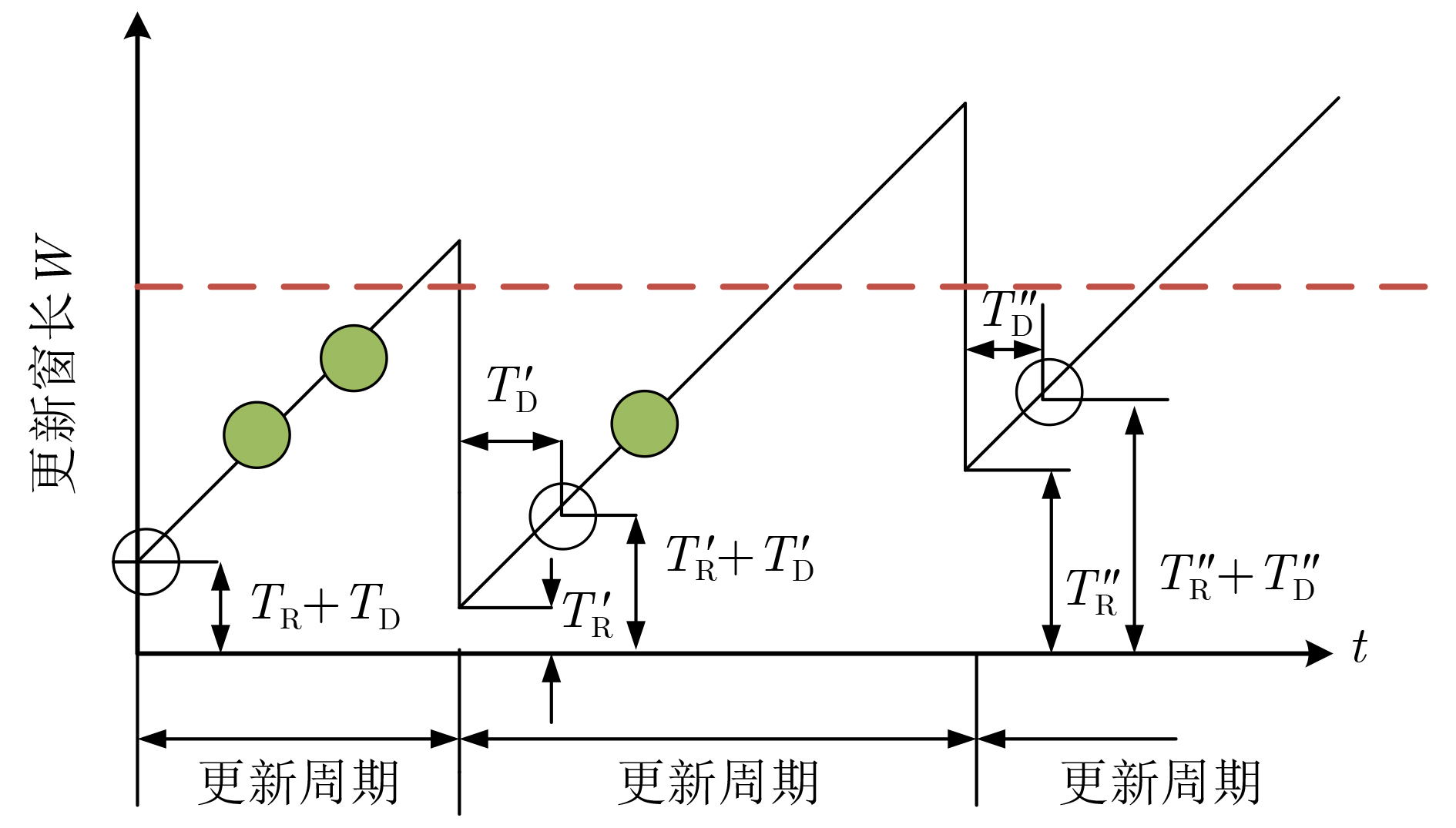
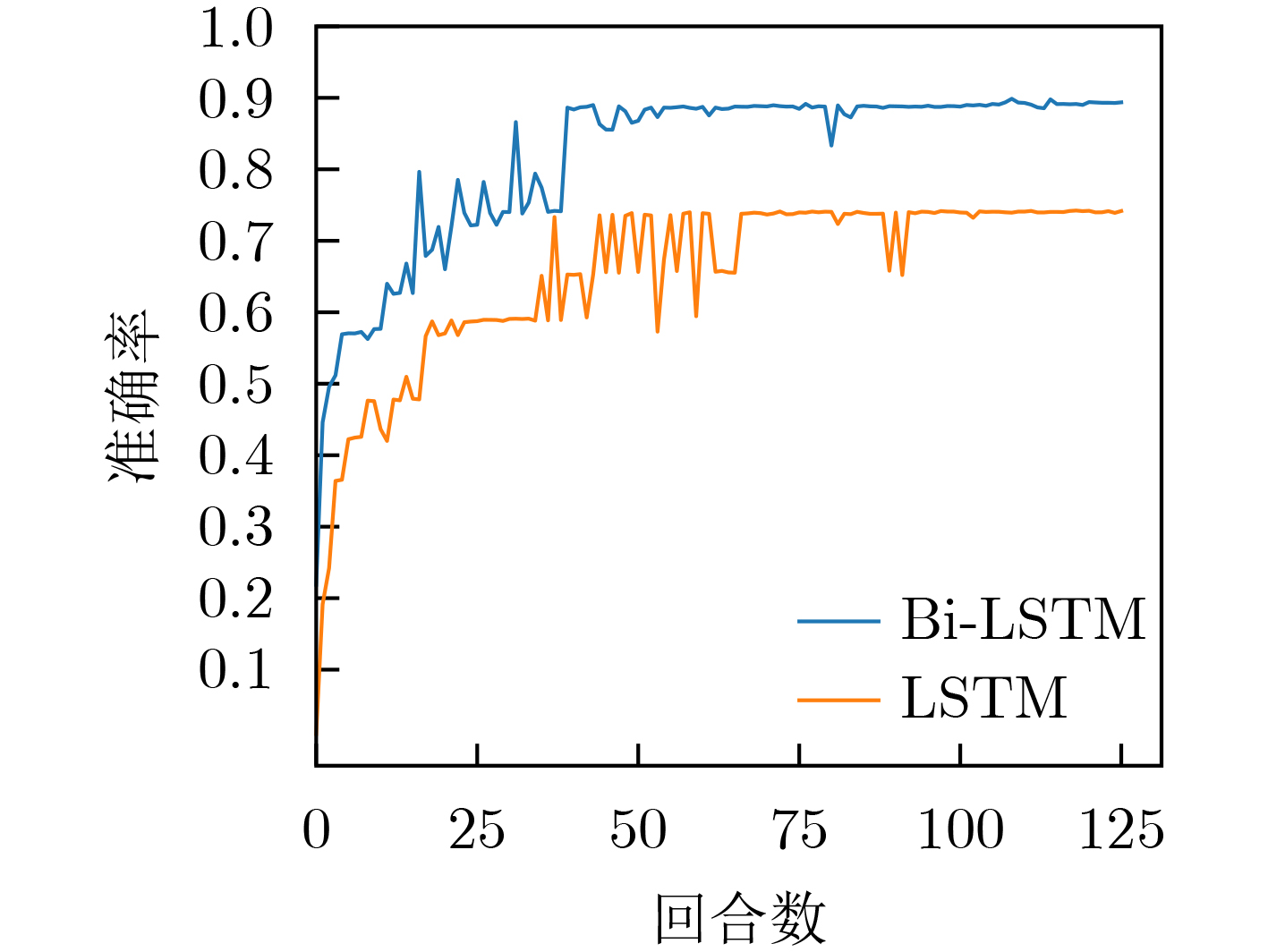
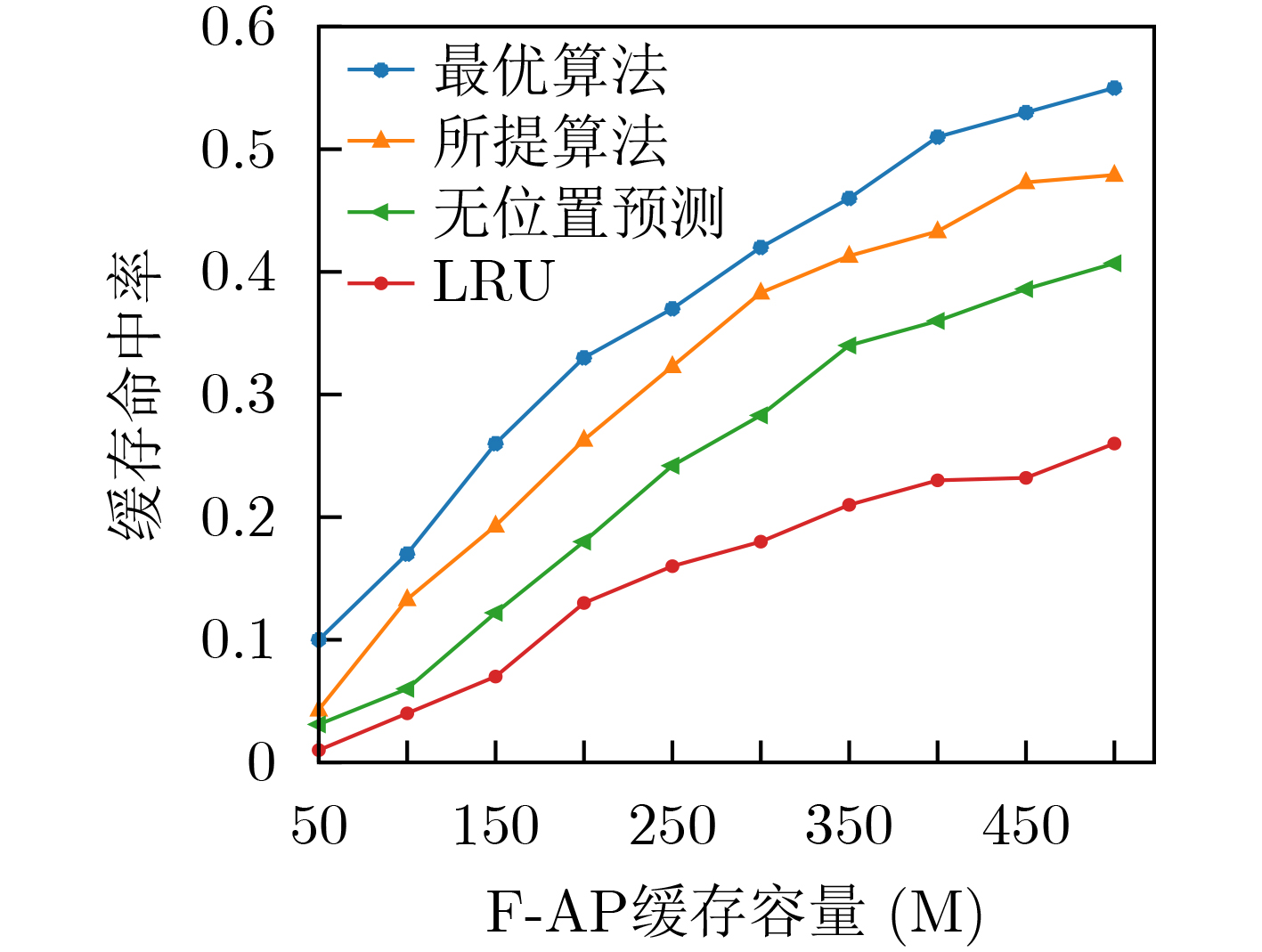
摘要: 将边缘缓存技术引入雾无线接入网,可以有效减少内容传输的冗余。然而,现有缓存策略很少考虑已缓存内容的动态特性。该文提出一种基于内容流行度和信息新鲜度的缓存更新算法,该算法充分考虑用户的移动性以及内容流行度的时空动态性,并引入信息年龄(AoI)实现内容的动态更新。首先,所提出算法根据用户的历史位置信息,使用双向长短期记忆网络(Bi-LSTM)预测下一时间段用户位置;其次,根据预测得到的用户位置,结合用户的偏好模型得到各位置区的内容流行度,进而在雾接入点进行内容缓存。然后,针对已缓存内容的信息年龄要求,结合内容流行度分布,通过动态设置缓存更新窗口以实现高时效、低时延的内容缓存。仿真结果表明,所提算法可以有效地提高内容缓存命中率,在保障信息的时效性的同时最大限度地减小缓存内容的平均服务时延。Abstract: Introducing edge caching into fog radio access networks can effectively reduce the redundancy of content transmission. However, the existing content caching strategies consider rarely the dynamic nature of already cached content. A caching update algorithm based on content popularity and information freshness is proposed. The proposed algorithm considers fully the mobility of users and the temporal and spatial dynamics of content popularity. Furthermore, the Age of Information (AoI) is introduced to achieve a dynamic content update procedure. More specifically, the proposed algorithm adopts initially a Bidirectional Long Short-Term Memory network (Bi-LSTM) to predict the user's location in the next period according to the user's historical location information. Secondly, according to the acquired user location, combined with the user's preference model, the content popularity of each location area is obtained accordingly, and the most popular content will be cached at the Fog Access Points(F-APs). Finally, concerning AoI requirements of the already cached content, the caching update window can be dynamically adjusted to achieve a high-efficient and low-latency caching process. Simulation results demonstrate that the proposed algorithm improves effectively the content cache hit rate, and also minimizes the average delay of content transmission while ensuring the timeliness of the information.
-
表 1 仿真参数
参数 值 覆盖半径$R$ 100 m 系统带宽$B$ 10 MHz 文件大小$\varphi $ 1 M 无线传输路径损耗指数$\alpha $ 4 加性高斯白噪声${\sigma ^2}$ –95 dBm F-APs发射功率${P_{{\rm{FAP}}} }$ 1 W 信源发射功率$P{\rm{s}}$ 0.1 W 请求到达率$\lambda $ 2000 请求/s  下载: 导出CSV
下载: 导出CSV
-
[1] ZENG Ming, LIN T H, CHEN Min, et al. Temporal-spatial mobile application usage understanding and popularity prediction for edge caching[J]. IEEE Wireless Communications, 2018, 25(3): 36–42. doi: 10.1109/MWC.2018.1700330 [2] 中华人民共和国工业和信息化部. 2021年通信业统计公报[R]. 2022.Ministry of Industry and Information Technology. 2021 communications industry statistical bulletin[R]. 2022. [3] ZEYDAN E, BASTUG E, BENNIS M, et al. Big data caching for networking: Moving from cloud to edge[J]. IEEE Communications Magazine, 2016, 54(9): 36–42. [4] YATES R D, SUN Yin, BROWN D R, et al. Age of information: An introduction and survey[J]. IEEE Journal on Selected Areas in Communications, 2021, 39(5): 1183–1210. doi: 10.1109/JSAC.2021.3065072 [5] BASTOPCU M and ULUKUS S. Information freshness in cache updating systems[J]. IEEE Transactions on Wireless Communications, 2021, 20(3): 1861–1874. doi: 10.1109/TWC.2020.3037144 [6] KAM C, KOMPELLA S, NGUYEN G D, et al. Information freshness and popularity in mobile caching[C]. 2017 IEEE International Symposium on Information Theory, Aachen, Germany, 2017: 136–140. doi: 10.1109/ISIT.2017.8006505. [7] WANG Xiaofei, CHEN Min, TALEB T, et al. Cache in the air: Exploiting content caching and delivery techniques for 5G systems[J]. IEEE Communications Magazine, 2014, 52(2): 131–139. doi: 10.1109/MCOM.2014.6736753 [8] ZHANG Min, JIANG Yanxiang, ZHENG Fuchun, et al. Cooperative edge caching via federated deep reinforcement learning in fog-RANs[C]. 2021 IEEE International Conference on Communications Workshops, Montreal, Canada, 2021: 1–6. doi: 10.1109/ICCWorkshops50388.2021.9473609. [9] ZHANG Yuming, FENG Bohao, Quan Wei, et al. Cooperative edge caching: A multi-agent deep learning based approach[J]. IEEE Access, 2020, 8: 133212–133224. doi: 10.1109/ACCESS.2020.3010329 [10] JIANG Yanxiang, FENG Haojie, ZHENG Fuchun, et al. Deep learning-based edge caching in fog radio access networks[J]. IEEE Transactions on Wireless Communications, 2020, 19(12): 8442–8454. doi: 10.1109/TWC.2020.3022907 [11] GOODFELLOW L, BENGIO Y, and COURVILLE A. Deep Learning[M]. Cambridge: The MIT Press, 2016. [12] BARTLETT P L, HAZAN E, and RAKHLIN A. Adaptive online gradient descent[C]. The 20th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2007: 65–72. [13] JIANG Yanxiang, MA Miaoli, BENNIS M, et al. User preference learning-based edge caching for fog radio access network[J]. IEEE Transactions on Communications, 2019, 67(2): 1268–1283. doi: 10.1109/TCOMM.2018.2880482 [14] JIANG Fan, ZHANG Xiaoli, and SUN Changyin. A D2D-enabled cooperative caching strategy for fog radio access networks[C]. The 2020 IEEE 31st Annual International Symposium on Personal, Indoor and Mobile Radio Communications, London, UK, 2020: 1–6. doi: 10.1109/PIMRC48278.2020.9217190. [15] ANDREWS J G, BACCELLI F, and GANTI R K. A tractable approach to coverage and rate in cellular networks[J]. IEEE Transactions on Communications, 2011, 59(11): 3122–3134. doi: 10.1109/TCOMM.2011.100411.100541 [16] ZHANG Shan, WANG Liudi, LUO Hongbin, et al. AoI-delay tradeoff in mobile edge caching with freshness-aware content refreshing[J]. IEEE Transactions on Wireless Communications, 2021, 20(8): 5329–5342. doi: 10.1109/TWC.2021.3067002 [17] Stanford University. Stanford university mobile activity TRAces (SUMATRA)[EB/OL]. http://infolab.stanford.edu/pleiades/SUMATRA.html, 2022. [18] TRZCIŃSKI T and ROKITA P. Predicting popularity of online videos using support vector regression[J]. IEEE Transactions on Multimedia, 2017, 19(11): 2561–2570. doi: 10.1109/TMM.2017.2695439 -

 下载:
下载:


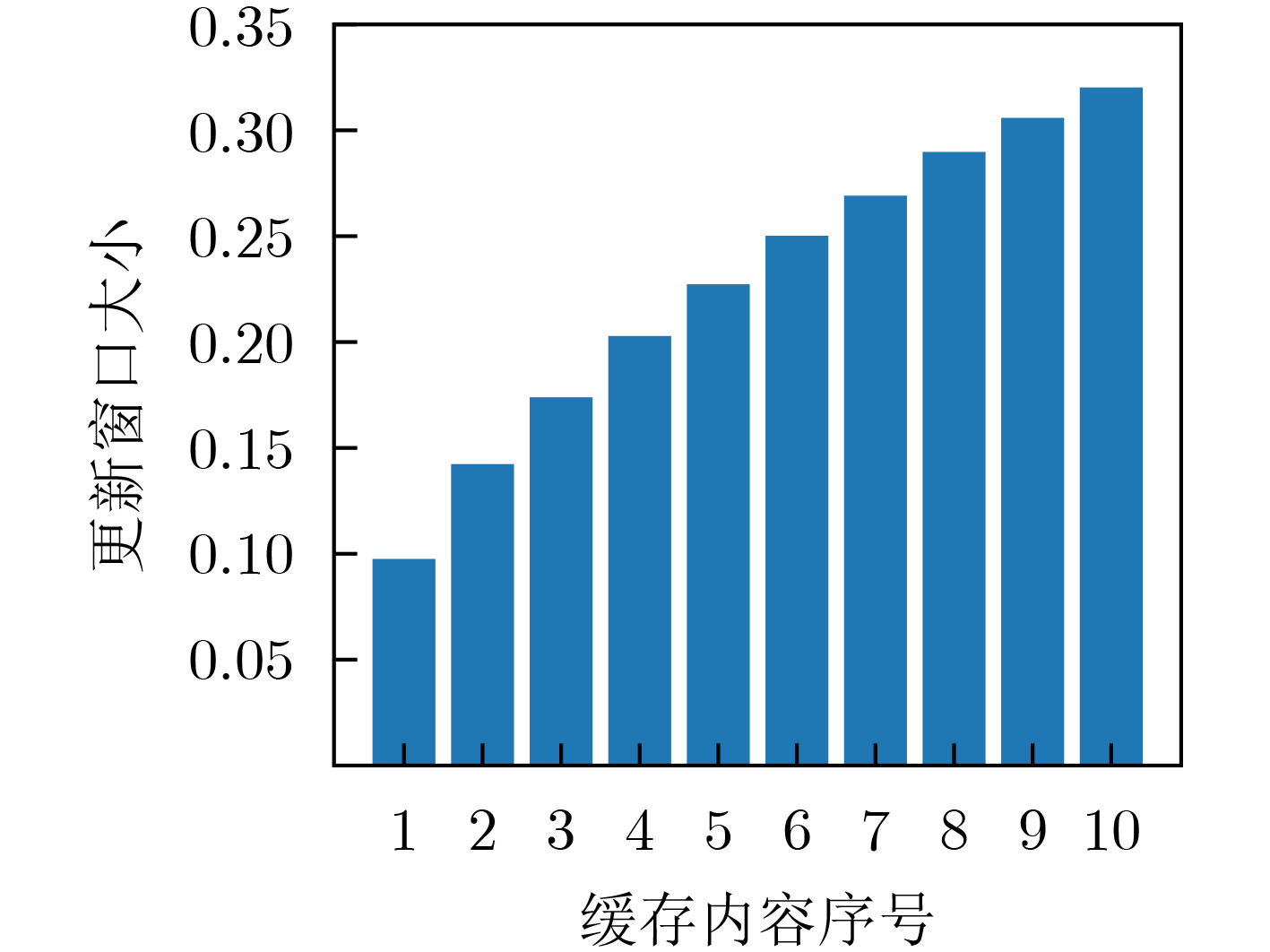
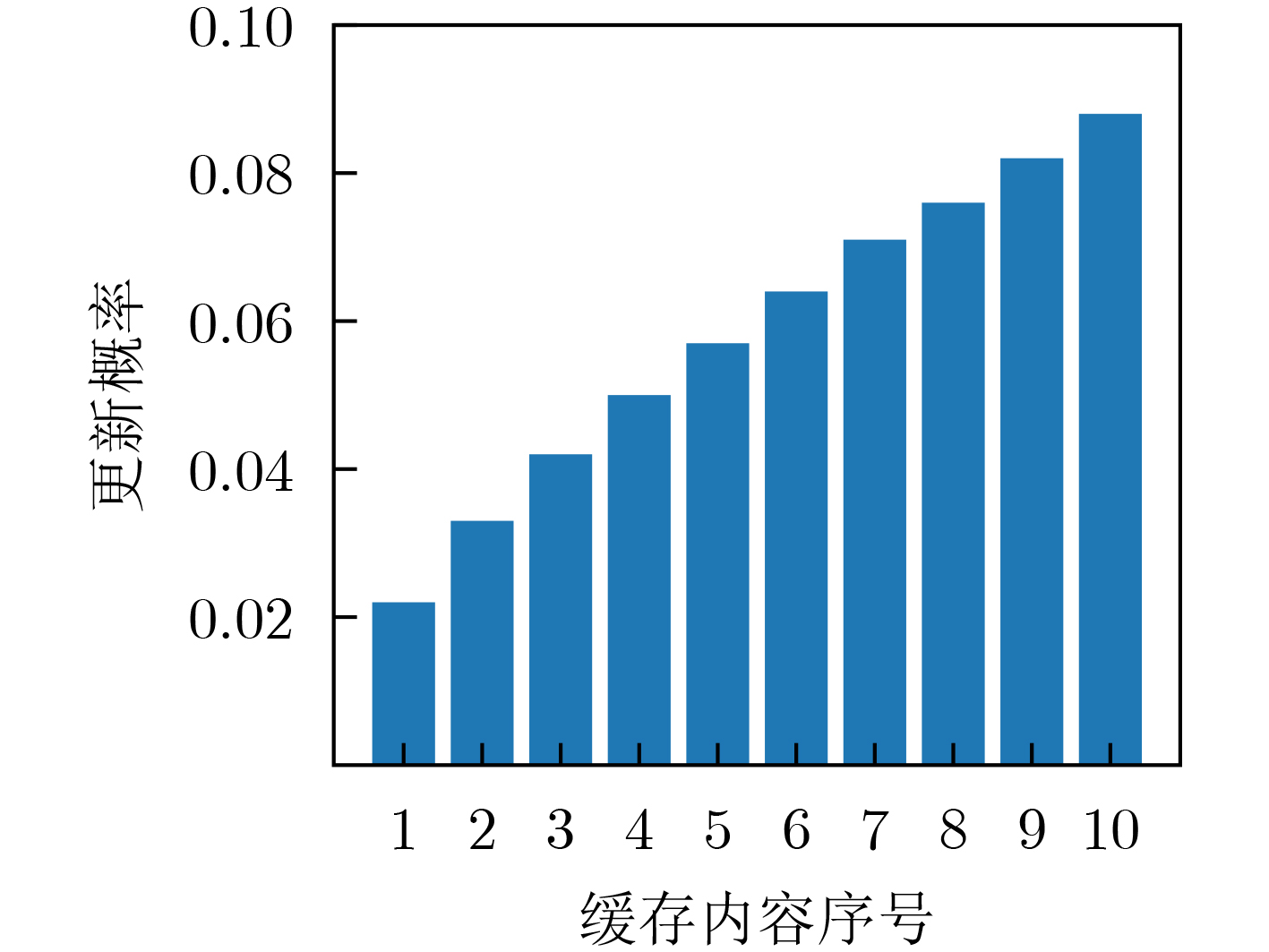



图(9) / 表(1)
计量
- 文章访问数: 1408
- HTML全文浏览量: 765
- PDF下载量: 113
- 被引次数: 0
