

Objective Visual Attention Estimation Method via Progressive Learning and Multi-scale Enhancement
-
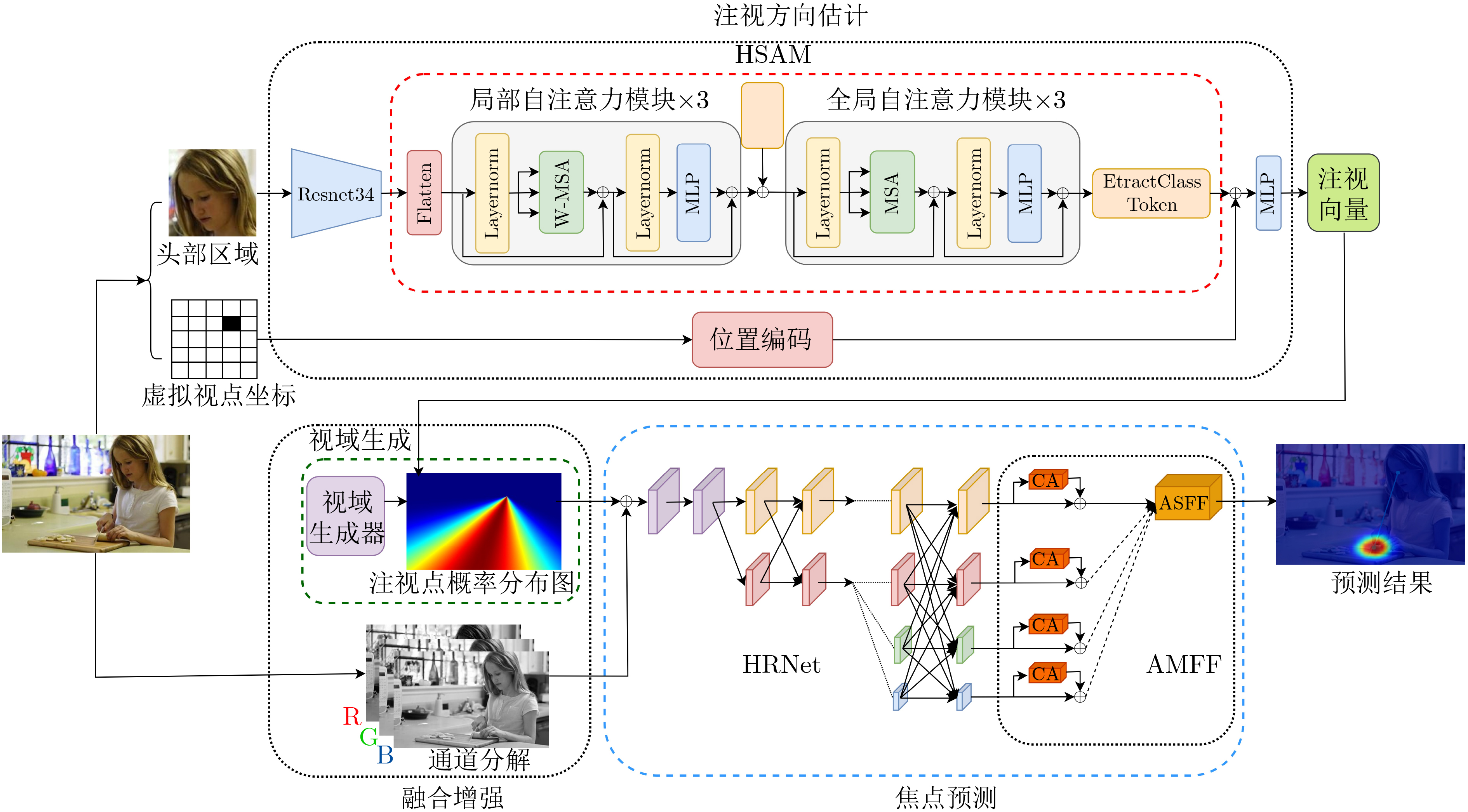
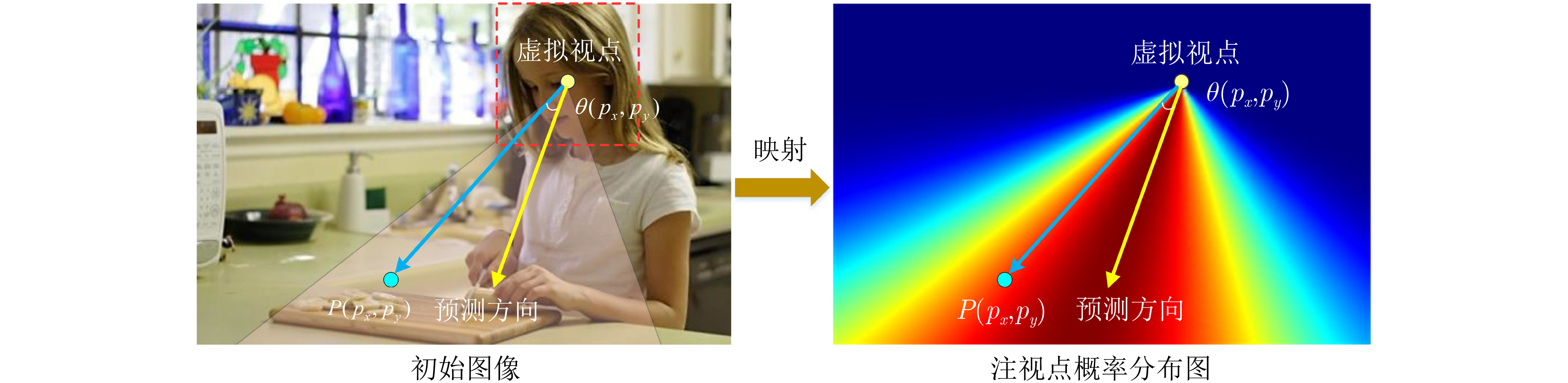
摘要: 视觉注意力机制已引起学界和产业界的广泛关注,但既有工作主要从场景观察者的视角进行注意力检测。然而,现实中不断涌现的智能应用场景需要从客体视角进行视觉注意力检测。例如,检测监控目标的视觉注意力有助于预测其后续行为,智能机器人需要理解交互对象的意图才能有效互动。该文结合客体视觉注意力的认知机制,提出一种基于渐进式学习与多尺度增强的客体视觉注意力估计方法。该方法把客体视域视为几何结构和几何细节的组合,构建层次自注意力模块(HSAM)获取深层特征之间的长距离依赖关系,适应几何特征的多样性;并利用方向向量和视域生成器得到注视点的概率分布,构建特征融合模块将多分辨率特征进行结构共享、融合与增强,更好地获取空间上下文特征;最后构建综合损失函数来估计注视方向、视域和焦点预测的相关性。实验结果表明,该文所提方法在公开数据集和自建数据集上对客体视觉注意力估计的不同精度评价指标都优于目前的主流方法。Abstract: Understanding the attention mechanism of the human visual system has attracted much research attention from researchers and industries. Recent studies of attention mechanisms focus mainly on observer patterns. However, more intelligent applications are presented in the real world and require objective visual attention detection. Automating tasks such as surveillance or human-robot collaboration require anticipating and predicting the behavior of objects. In such contexts, gaze and focus can be highly informative about participants' intentions, goals, and upcoming decisions. Here, a progressive mechanism of objective visual attention is developed by combining cognitive mechanisms. The field is first viewed as a combination of geometric structure and geometric details. A Hierarchical Self-Attention Module (HSAM) is constructed to capture the long-distance dependencies between deep features and adapt geometric feature diversity. With the identified generators, the field of view direction vectors are generated, and the probability distribution of gaze points is obtained. Furthermore, a feature fusion module is designed for structure sharing, fusion, and enhancement of multi-resolution features. Its output contains more detailed spatial and global information, better obtaining spatial context features. The experimental results are in excellent agreement with theoretical predictions by different evaluation metrics for objective attention estimation on publicly available and self-built datasets.
-
表 1 不同变种方法在GazeFollow和AutoGaze数据集上的结果对比
方法 GazeFollow AutoGaze AUC Dist Ang (°) AUC Dist Ang (°) M1 0.918 0.135 17.3 0.965 0.086 15.6 M2 0.914 0.139 17.3 0.960 0.093 16.0 M3 0.916 0.136 16.8 0.964 0.087 14.7 M4 0.915 0.137 17.0 0.961 0.091 15.4 M5 0.915 0.138 17.1 0.963 0.089 14.4 M6 0.906 0.143 17.6 0.960 0.092 16.6 本文方法(全模块) 0.922 0.133 16.7 0.969 0.083 13.9  下载: 导出CSV
下载: 导出CSV
表 2 不同模型在GazeFollow数据集上的结果对比
方法 AUC Dist MinDist Ang (°) MinAng (°) Random[7] 0.504 0.484 0.391 69.0 – Center[7] 0.633 0.313 0.230 49.0 – Fixed bias[7] 0.674 0.306 0.219 48.0 – Recasens等人[7] 0.878 0.190 0.113 24.0 – Chong等人[14] 0.896 0.187 0.112 – – Zhao等人[23] – 0.147 0.082 17.6 – Lian等人[8] 0.906 0.145 0.081 17.6 8.8 Chong等人[11] 0.921 0.137 0.077 – – 本文方法(FPN) 0.905 0.146 0.083 17.5 8.5 本文方法(ResNet50) 0.915 0.138 0.075 17.1 8.1 本文方法 0.922 0.133 0.072 16.7 7.6 人工辨识 0.924 0.096 0.040 11.0 –
下载: 导出CSV
-
[1] FATHI A, HODGINS J K, and REHG J M. Social interactions: A first-person perspective[C]. 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, USA, 2012: 1226–1233. [2] MARIN-JIMENEZ M J, ZISSERMAN A, EICHNER M, et al. Detecting people looking at each other in videos[J]. International Journal of Computer Vision, 2014, 106(3): 282–296. doi: 10.1007/s11263-013-0655-7 [3] PARKS D, BORJI A, and ITTI L. Augmented saliency model using automatic 3D head pose detection and learned gaze following in natural scenes[J]. Vision Research, 2015, 116: 113–126. doi: 10.1016/j.visres.2014.10.027 [4] SOO PARK H and SHI Jianbo. Social saliency prediction[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 4777–4785. [5] ZHANG Xucong, SUGANO Y, FRITZ M, et al. Appearance-based gaze estimation in the wild[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 4511–4520. [6] CHENG Yihua, LU Feng, and ZHANG Xucong. Appearance-based gaze estimation via evaluation-guided asymmetric regression[C]. The 15th European Conference on Computer Vision (ECCV), Munich, Germany, 2018: 105–121. [7] RECASENS A, KHOSLA A, VONDRICK C, et al. Where are they looking?[C]. The 28th International Conference on Neural Information Processing Systems, Montreal, Canada, 2015: 199–207. [8] LIAN Dongze, YU Zehao, and GAO Shenghua. Believe it or not, we know what you are looking at![C]. The 14th Asian Conference on Computer Vision, Perth, Australia, 2018: 35–50. [9] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. [10] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, USA, 2017: 936–944. [11] CHONG E, WANG Yongxin, RUIZ N, et al. Detecting attended visual targets in video[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 5395–5405. [12] SHI Xingjian, CHEN Zhourong, WANG Hao, et al. Convolutional LSTM network: A machine learning approach for precipitation nowcasting[C]. The 28th International Conference on Neural Information Processing Systems, Montreal, Canada, 2015: 802–810. [13] AUNG A M, RAMAKRISHNAN A, and WHITEHILL J R. Who are they looking at? Automatic eye gaze following for classroom observation video analysis[C]. The 11th International Conference on Educational Data Mining, Buffalo, USA, 2018: 252–258. [14] CHONG E, RUIZ N, WANG Yongxin, et al. Connecting gaze, scene, and attention: Generalized attention estimation via joint modeling of gaze and scene saliency[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 397–412. [15] WANG Jingdong, SUN Ke, CHENG Tianheng, et al. Deep high-resolution representation learning for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(10): 3349–3364. doi: 10.1109/TPAMI.2020.2983686 [16] LIU Ze, LIN Yutong, CAO Yue, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 9992–10002. [17] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C/OL]. The 9th International Conference on Learning Representations, 2021. [18] RAFFEL C, SHAZEER N, ROBERTS A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. The Journal of Machine Learning Research, 2020, 21(1): 140. [19] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Los Angeles, USA, 2017: 6000–6010. [20] QIN Zequn, ZHANG Pengyi, WU Fei, et al. FcaNet: Frequency channel attention networks[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 763–772. [21] LIU Songtao, HUANG Di, and WANG Yunhong. Learning spatial fusion for single-shot object detection[EB/OL]. https://arxiv.org/abs/1911.09516, 2019. [22] WANG Guangrun, WANG Keze, and LIN Liang. Adaptively connected neural networks[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 1781–1790. [23] ZHAO Hao, LU Ming, YAO Anbang, et al. Learning to draw sight lines[J]. International Journal of Computer Vision, 2020, 128(5): 1076–1100. doi: 10.1007/s11263-019-01263-4 -

 下载:
下载:





图(5) / 表(4)
计量
- 文章访问数: 993
- HTML全文浏览量: 724
- PDF下载量: 99
- 被引次数: 0
