

Communication-Efficient Federated Learning Algorithm Based on Event Triggering
-
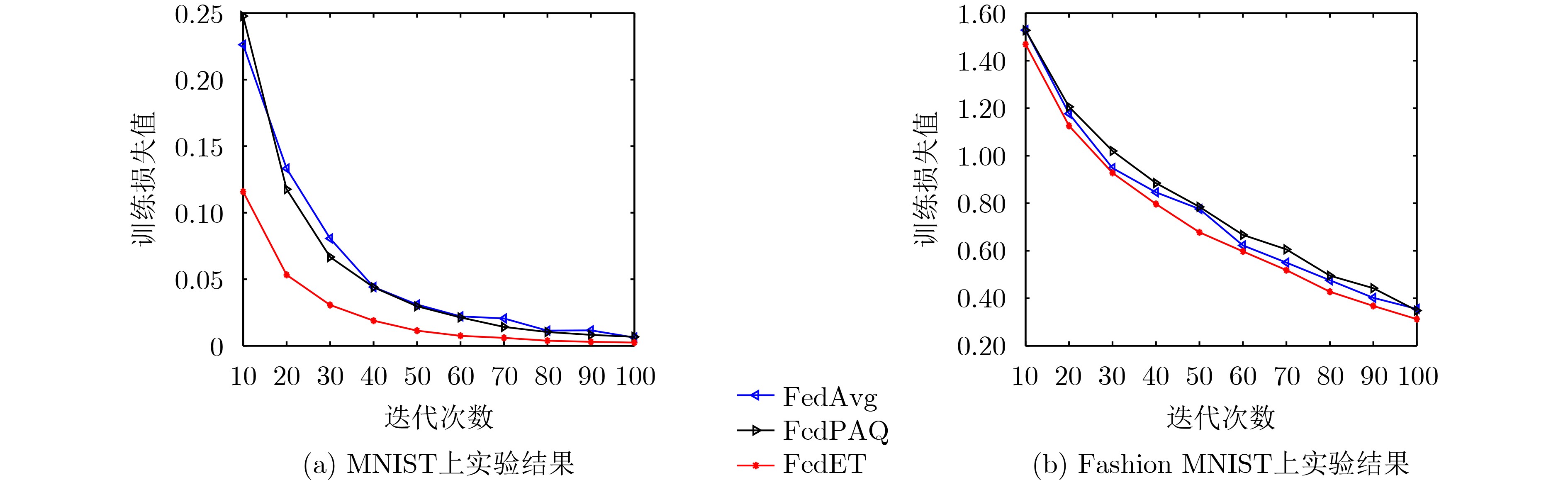
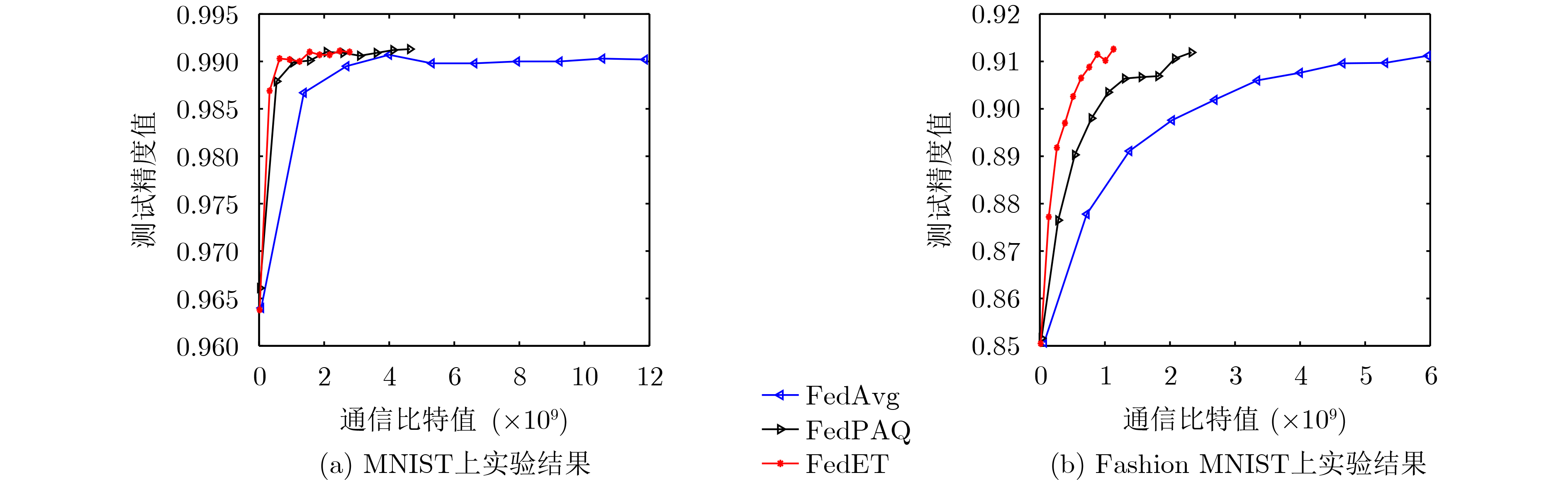
摘要: 由于实际网络的带宽是有限的,因此客户端和中心服务器之间的通信成为联邦学习的一个主要瓶颈。为了减小通信开销,该文引入事件触发机制,提出一个通信有效的联邦学习算法(FedET)。首先,客户端利用事件触发机制判断是否需要向中心服务器发送当前模型。然后,中心服务器基于收到的信息进行模型聚合。具体地,在每个通信轮次,客户端完成本地模型训练之后,将模型更新和触发阈值进行比较,若触发通信,则将信息进行压缩后发送给中心服务器。进一步地,分别对满足凸的、PL(Polyak-Łojasiewicz)条件的和非凸的光滑目标函数,该文分析了所提算法的收敛性并给出了证明。最后,在两个标准的数据集上进行仿真实验。实验结果验证了所提算法的可行性和有效性。Abstract: Due to the limited actual network bandwidth, the communication between clients and the central server is a main bottleneck of federated learning. To reduce the communication cost, a communication-efficient Federated learning algorithm is proposed by introducing the Event Triggered mechanism (FedET). Firstly, the clients determine whether to send the current model to the central server through using the event-triggered mechanism. Then, the central server aggregates models based on the information received. In particular, at each communication round, after finishing the local model training, the clients compare the model update with the trigger threshold, and if the communication is triggered, the transmitted information is compressed and sent to the central server. Furthermore, for smooth objective functions which satisfy convex, PL (Polyak-Łojasiewicz) condition and non-convex, respectively, this paper analyzes the convergence of the proposed algorithm and presents the proof. Finally, simulation experiments are implemented on two standard datasets. Simulation results verify the feasibility and effectiveness of the proposed algorithm.
-
Key words:
- Federated learning /
- Communication-efficient /
- Event triggering /
- Compression /
- Convergence
-
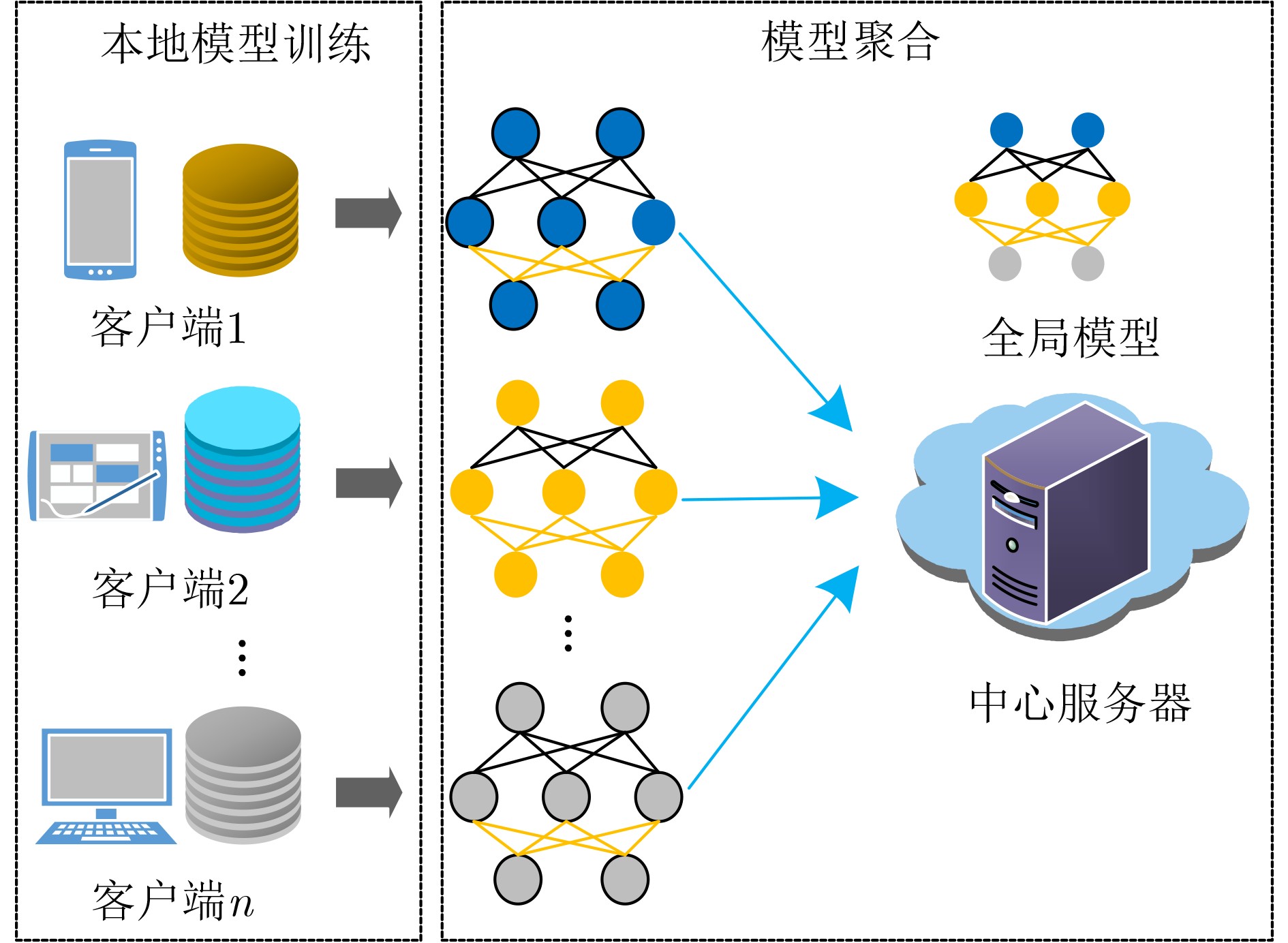
算法1 FedET算法 输入:全局模型迭代次数$K$,本地模型更新次数$\tau $,学习率$\gamma $和
$\eta $,全局模型初始值${x^0}$输出:模型参数${x^K}$ (1) for $k = 0,1, \cdots ,K - 1$ do (2) for 每一个客户端 $i \in \{ 0,1, \cdots ,n\} $ do (3) 设置${\boldsymbol{x}}_i^{k,0} = {{\boldsymbol{x}}^k}$; (4) for $h = 0,1, \cdots ,\tau - 1$ do (5) 采样最小批数据并计算随机梯度${\tilde g_i}({\boldsymbol{x}}_i^{k,h},\xi _i^{k,h})$; (6) ${\boldsymbol{x}}_i^{k,h + 1} = {\boldsymbol{x}}_i^{k,h} - \eta {\tilde g_i}({\boldsymbol{x}}_i^{k,h},\xi _i^{k,h})$; (7) end for (8) 根据式(2)计算${e_i}(k)$; (9) if $\parallel {e_i}(k){\parallel _1} \ge {\alpha _k}$ then (10) 发送$\mathcal{C}(\varDelta _i^k)$给服务器,并设置$\hat {\boldsymbol{x}}_i^{k + 1} = {\boldsymbol{x}}_i^{k,\tau }$; (11) end if (12) end for (13) 中心服务器根据式(3)更新全局模型${{\boldsymbol{x}}^{k + 1} }$,并将其广播给所
有客户端;(14) end for  下载: 导出CSV
下载: 导出CSV
-
[1] MCMAHAN B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data[C]. The 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, USA, 2017: 1273–1282. [2] WEN Guanghui, FU Junjie, DAI Pengcheng, et al. DTDE: A new cooperative multi-agent reinforcement learning framework[J]. The Innovation, 2021, 2(4): 100162. doi: 10.1016/j.xinn.2021.100162 [3] YANG Qiang, LIU Yang, CHENG Yong, et al. Federated Learning[M]. Cham, Germany: Springer, 2020: 82–85. [4] LIM W Y B, LUONG N C, HOANG D T, et al. Federated learning in mobile edge networks: A comprehensive survey[J]. IEEE Communications Surveys & Tutorials, 2020, 22(3): 2031–2063. doi: 10.1109/COMST.2020.2986024 [5] PFITZNER B, STECKHAN N, and ARNRICH B. Federated learning in a medical context: A systematic literature review[J]. ACM Transactions on Internet Technology, 2021, 21(2): 50. doi: 10.1145/3412357 [6] TAN Kang, BREMNER D, LE KERNEC J, et al. Federated machine learning in vehicular networks: A summary of recent applications[C]. 2020 International Conference on UK-China Emerging Technologies, Glasgow, United Kingdom, 2020: 1–4. [7] AJI A F and HEAFIELD K. Sparse communication for distributed gradient descent[C]. The 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 2017: 440–445. [8] REISIZADEH A, MOKHTARI A, HASSANI H, et al. FedPAQ: A communication-efficient federated learning method with periodic averaging and quantization[C]. The 23rd International Conference on Artificial Intelligence and Statistics, Palermo, Italy, 2020: 2021–2031. [9] 王长城, 戚国庆, 李银伢, 等. 量化状态信息下多智能体Gossip算法及分布式优化[J]. 电子与信息学报, 2014, 36(1): 128–134. doi: 10.3724/SP.J.1146.2013.00297WANG Changcheng, QI Guoqing, LI Yinya, et al. Multi-agent gossip consensus algorithm with quantized data and distributed optimizing[J]. Journal of Electronics &Information Technology, 2014, 36(1): 128–134. doi: 10.3724/SP.J.1146.2013.00297 [10] BASU D, DATA D, KARAKUS C, et al. Qsparse-local-SGD: Distributed SGD with quantization, sparsification, and local computations[J]. IEEE Journal on Selected Areas in Information Theory, 2020, 1(1): 217–226. doi: 10.1109/JSAIT.2020.2985917 [11] LI Zhize, KOVALEV D, QIAN Xun, et al. Acceleration for compressed gradient descent in distributed and federated optimization[C/OL]. The 37th International Conference on Machine Learning, 2020: 547. [12] HADDADPOUR F, KAMANI M M, MOKHTARI A, et al. Federated learning with compression: Unified analysis and sharp guarantees[C/OL]. Proceedings of the 24th International Conference on Artificial Intelligence and Statistics, 2021: 2350–2358. [13] GAO Huimin, WANG Lin, ZHU Junlong, et al. Federated optimization based on compression and event-triggered communication[C]. The 36th Youth Academic Annual Conference of Chinese Association of Automation, Nanchang, China, 2021: 517–522. [14] TGEORGE J and GURRAM P. Distributed stochastic gradient descent with event-triggered communication[C]. The 34th AAAI Conference on Artificial Intelligence, New York, USA, 2020: 7169–7178. [15] HSIEH K, HARLAP A, VIJAYKUMAR N, et al. Gaia: Geo-distributed machine learning approaching LAN speeds[C]. The 14th USENIX Conference on Networked Systems Design and Implementation, Boston, USA, 2017: 629–647. [16] SINGH N, DATA D, GEORGE J, et al. SQuARM-SGD: Communication-efficient momentum SGD for decentralized optimization[J]. IEEE Journal on Selected Areas in Information Theory, 2021, 2(3): 954–969. doi: 10.1109/JSAIT.2021.3103920 [17] BOTTOU L, CURTIS F E, and NOCEDAL J. Optimization methods for large-scale machine learning[J]. SIAM Review, 2018, 60(2): 223–311. doi: 10.1137/16M1080173 [18] KARIMI H, NUTINI J, and SCHMIDT M. Linear convergence of gradient and proximal-gradient methods under the polyak-łojasiewicz condition[C]. The Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Riva del Garda, Italy, 2016: 795–811. [19] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278–2324. doi: 10.1109/5.726791 [20] XIAO Han, RASUL K, and VOLLGRAF R. Fashion-MNIST: A novel image dataset for benchmarking machine learning algorithms[J]. arXiv: 1708.07747, 2017. [21] PASZKE A, GROSS S, MASSA F, et al. PyTorch: An imperative style, high-performance deep learning library[C]. The 32th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2019: 8024–8035. -

 下载:
下载:




图(5) / 表(1)
计量
- 文章访问数: 888
- HTML全文浏览量: 1022
- PDF下载量: 94
- 被引次数: 0
