

Convolutional Neural Network Accelerator Architecture Design for Ultimate Edge Computing Scenario
-
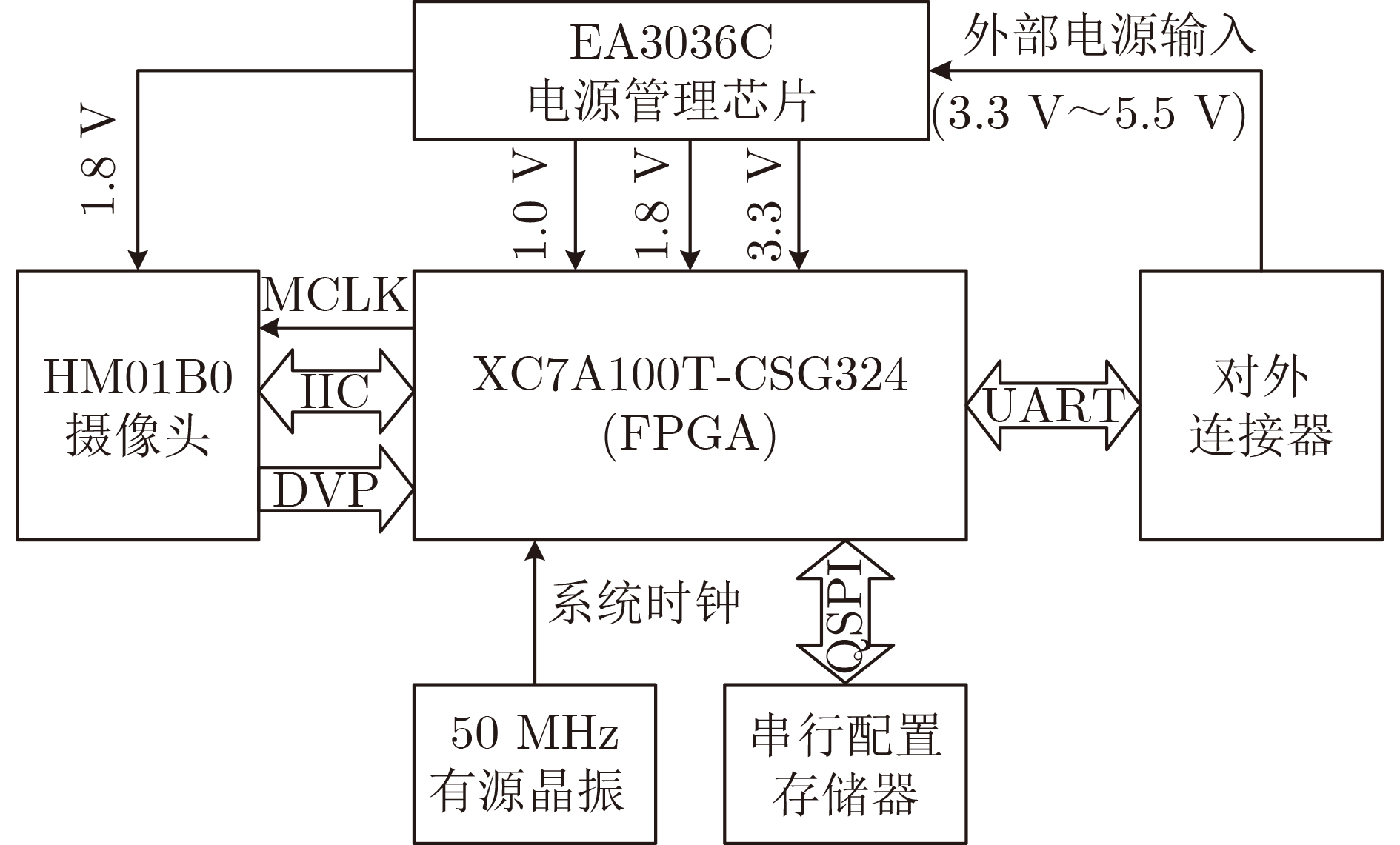
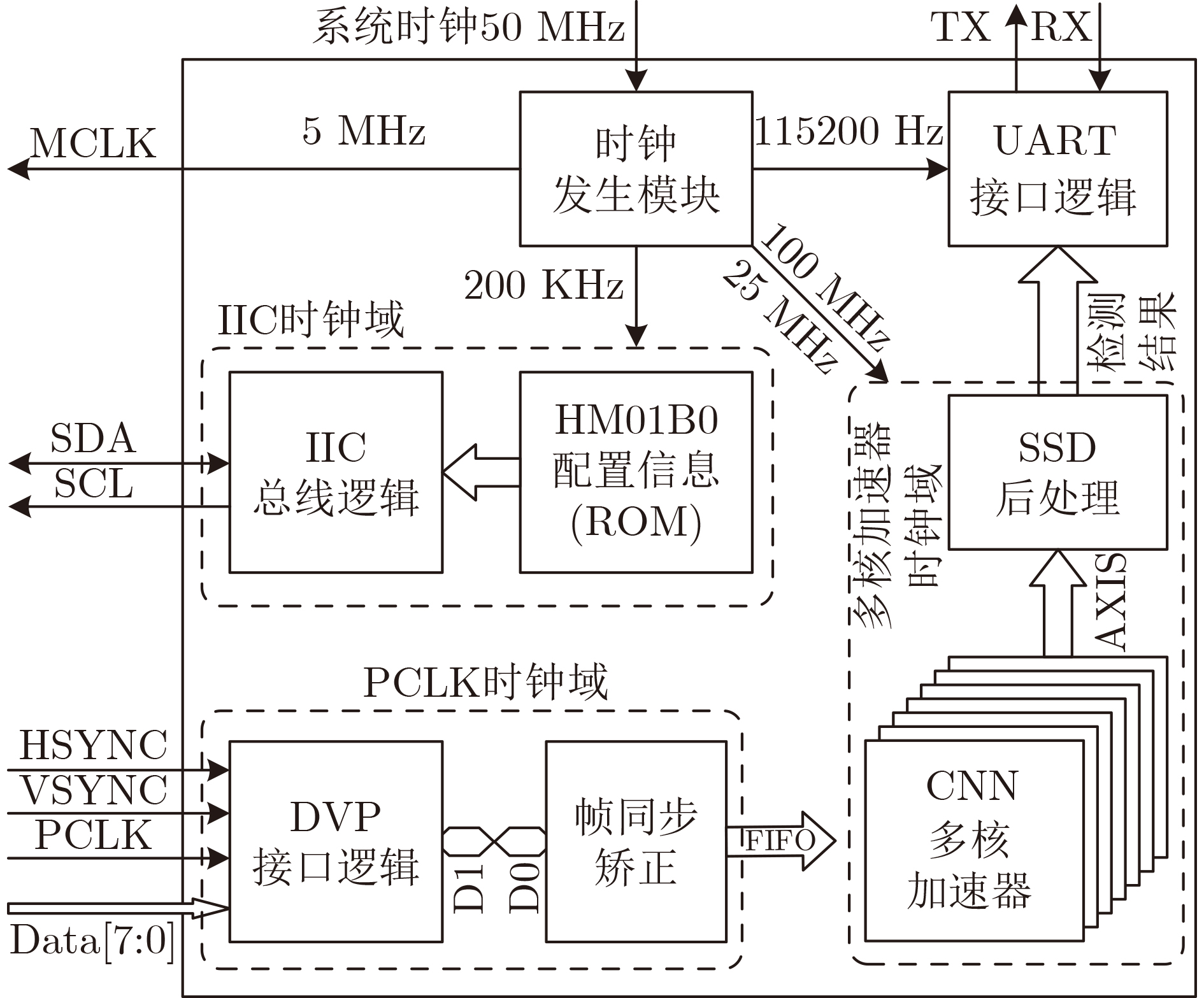
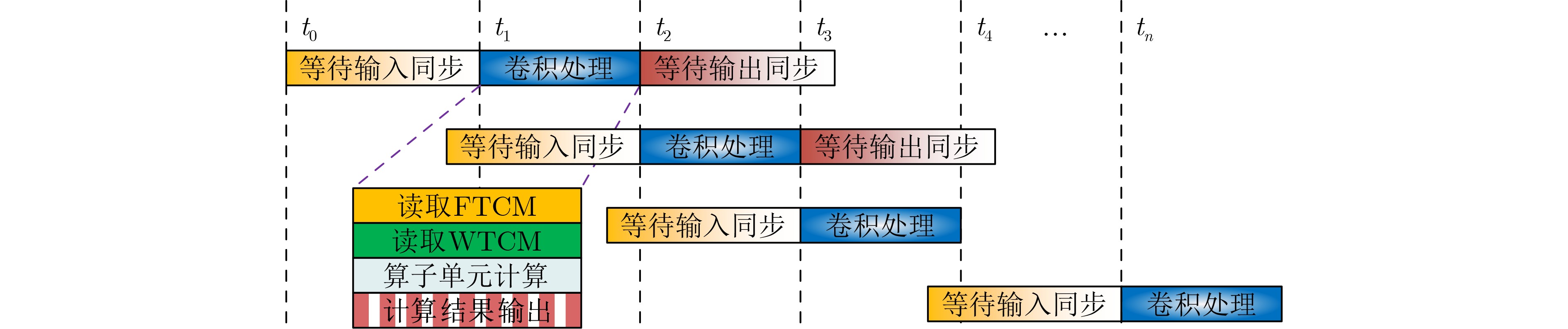
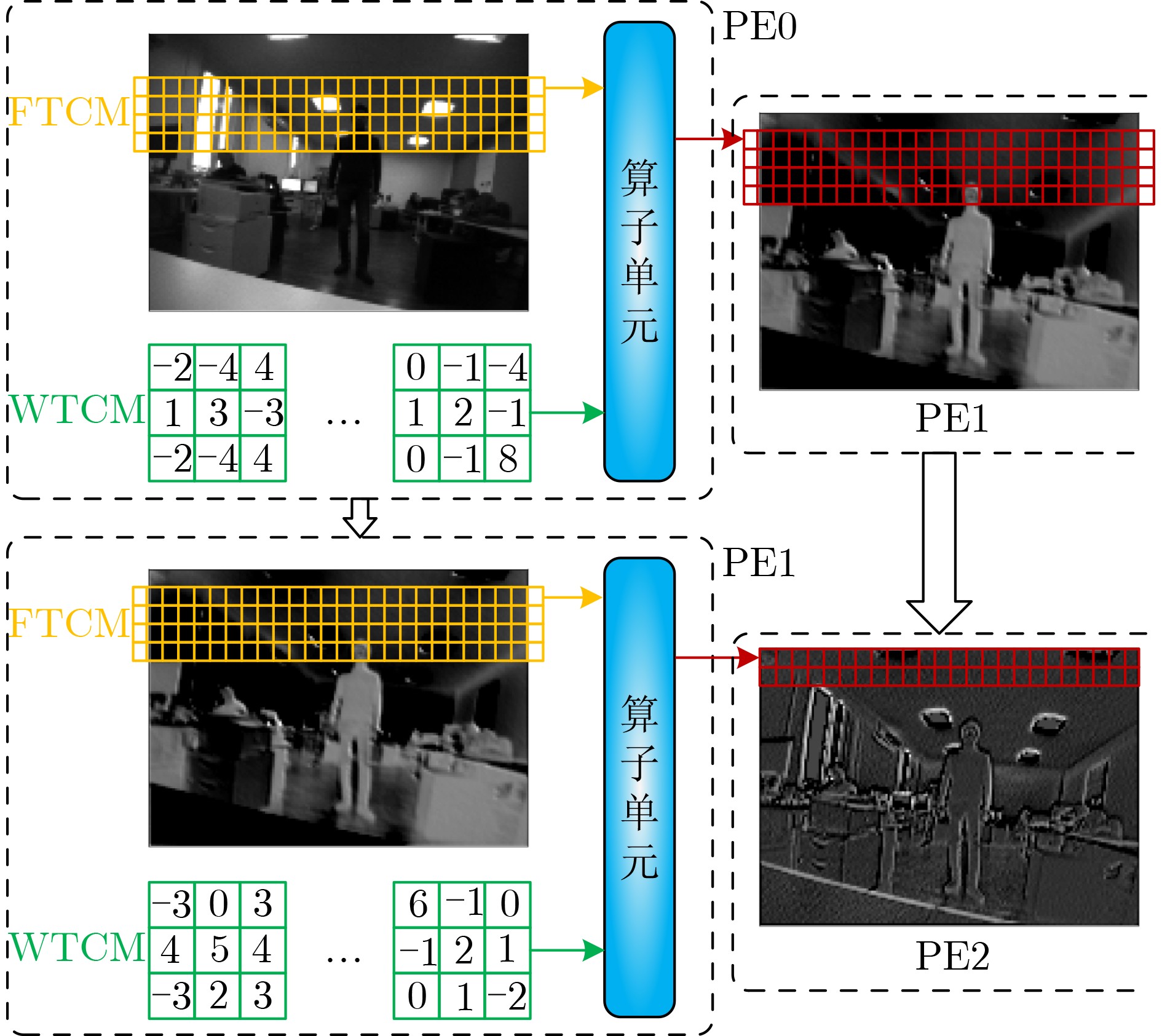
摘要: 针对卷积神经网络在极致边缘计算(UEC)场景应用中的性能和功耗需求,该文针对场景中16 Bit量化位宽的网络模型提出一种不依赖外部存储的卷积神经网络(CNN)加速器架构,该架构基本结构设计为基于现场可编程逻辑门阵列( FPGA)的多核CNN全流水加速器。在此基础上,实现了该加速器的层内映射与层间融合优化。然后,通过构建资源评估模型在理论上完成架构中的计算资源与存储资源评估,并在该理论模型指导下,通过设计空间探索来最大化资源使用率与计算效率,进而充分挖掘加速器在计算资源约束条件下的峰值算力。最后,以纳型无人机(UAV)自主快速人体检测UEC场景为例,通过实验完成了加速器架构性能验证与分析。结果表明,在实现基于单步多框目标检测(SSD)的人体检测神经网络推理中,加速器在100 MHz和25 MHz主频下分别实现了帧率为137和34的推理速度,对应功耗分别为0.514 W和0.263 W,满足纳型无人机自主计算这种典型UEC场景对图像实时处理的性能与功耗需求。
-
关键词:
- 极致边缘计算 /
- 卷积神经网络 /
- 现场可编程逻辑门阵列 /
- 加速器架构
Abstract: In order to meet the requirements of performance and power in Ultimate Edge Computing (UEC) scenario, a Convolutional Neural Network (CNN) accelerator architecture is proposed with 16 Bit quantization model that does not rely on external memory. The basic structure of proposed architecture is Field Programmable Gate Array (FPGA) with multi-core CNN full pipeline accelerator. On this basis, the optimization of intra-layer mapping and inter-layer fusion of accelerator is realized. Then, the evaluation of computing resource and memory resource are theoretically completed by building the corresponding model. Under the guidance of this model, the resource utilization and computing efficiency are maximized through design space exploration, and the peak computing power of accelerator is fully exploited with limited resource constraint. Finally, taking fast human detection of nano Unmanned Aerial Vehicle (UAV) as an example, the verification and analysis of architecture are completed through experiments. Experimental results show that in the inference of human body detection neural network based on Single Shot multibox Detector (SSD), the performance is achieved with the speed of frame rate 137 and 34 at 100 MHz and 25 MHz, and the corresponding power is 0.514 W and 0.263 W, respectively, which meets the performance and power requirements of real-time image processing in typical UEC scenarios such as autonomous computing of nano-UAV. -
表 1 网络结构参数与并行度探索结果
网络层 输入大小 卷积核大小 TM TN 周期 0 160×120×1 3×3×1×32 1 8 691200 1 160×120×32 1×1×32×32 32 1 614400 2 160×120×32 3×3×32 1 8 691200 3 160×120×32 1×1×32×32 32 1 614400 4 80×60×32 3×3×32×16 32 1 691200 5 80×60×16 1×1×16×16 2 1 614400 6 80×60×16 3×3×16 1 1 691200 7 80×60×16 1×1×16×16 2 1 614400 8 40×30×16 3×3×16×16 4 1 691200 9 40×30×16 1×1×16×16 1 1 307200 10 40×30×16 3×3×16 1 1 172800 11 40×30×16 1×1×16×16 1 1 307200 SSD0 40×30×16 – – – – 12 20×15×16 3×3×16×16 1 1 691200 13 20×15×16 1×1×16×16 1 1 196800 14 20×15×16 3×3×16 15 20×15×16 1×1×16×16 SSD1 20×15×16 – – – – 16 10×7×16 3×3×16×16 1 1 207200 17 10×7×16 1×1×16×16 18 10×7×16 3×3×16 19 10×7×16 1×1×16×16 SSD2 10×7×16 – – – –  下载: 导出CSV
下载: 导出CSV
表 2 加速器资源消耗理论值(个)
网络层 加速器 DSP BRAM36K 0 PE0 8 0.5 1 PE1 32 8 2 PE2 8 12 3 PE3 32 8 4 PE4 32 8 5 PE5 2 1.5 6 PE6 1 3 7 PE7 2 1.5 8 PE8 4 2 9 PE9 1 1 10 PE10 1 1.5 11 PE11 1 1 12 PE12 1 2.5 13~15 X0 1 10.5 16~19 X1 1 6 总计 15 127 67
下载: 导出CSV
表 3 部署资源消耗
资源类别 消耗(个) 片内总计(个) 占比(%) LUT 24814 63400 39.14 LUTRAM 1236 19000 6.51 FF 17516 126800 13.81 BRAM36K 106 135 78.52 DSP 156 240 65.00 IO 17 210 8.10
下载: 导出CSV
表 5 不同频率下功耗结果(W)
类别 100 MHz 功耗 25 MHz功耗 Clock 0.062 0.016 Logic 0.073 0.019 Signal 0.098 0.022 BRAM 0.040 0.010 DSP 0.050 0.012 IO <0.001 <0.001 Static 0.109 0.109 评估值 0.432 0.188 测量值 0.514 0.263
下载: 导出CSV
表 6 软硬件处理性能对比结果(ms)
ARM计算时间
1.2 GHzFPGA加速时间
100 MHzPE0~PE12 140.424 9.291 PE0~X1 141.179 13.280 SSD0 2.782 1.117 SSD1 1.952 0.939 SSD2 0.364 0.233 输入间隔 146.277 7.287 帧率 7 FPS 137 FPS
下载: 导出CSV
表 7 不同平台性能对比结果
类别 ARM GAP8 FPGA 1.2 GHz 200 MHz 25 MHz 100 MHz 每秒操作数 1.101 0.482 5.528 22.111 推理时间(ms) 146.277 334.625 29.148 7.287 功耗(W) 2.617 0.196 0.263 0.514 每瓦操作数 0.421 2.459 21.019 43.018
下载: 导出CSV
表 8 与相关工作比较结果
类别 文献[20] 文献[20] 文献[22] 文献[23] 本文 平台 GX1150 GX1150 10AS066N XC7Z045 XC7A100T 网络类型 卷积 深度分离卷积 MobileNetV2 Face Detector Body Detection 量化位宽(bit) 16 16 16 16 16 DSP 760 712 1278 – 128 频率(MHz) 150 180 133 150 25 100 算力(GOPS) 87.500 98.910 170.600 137 5.528 22.111 功耗(W) 8.69 8.52 – 9.63 0.263 0.514 计算效率 0.768 0.772 1.004 – 1.728 1.727 每瓦操作数 10.069 11.609 – 14.226 21.019 43.018
下载: 导出CSV
-
[1] BIANCHI V, BASSOLI M, LOMBARDO G, et al. IoT wearable sensor and deep learning: An integrated approach for personalized human activity recognition in a smart home environment[J]. IEEE Internet of Things Journal, 2019, 6(5): 8553–8562. doi: 10.1109/JIOT.2019.2920283 [2] 施巍松, 张星洲, 王一帆, 等. 边缘计算: 现状与展望[J]. 计算机研究与发展, 2019, 56(1): 69–89. doi: 10.7544/issn1000-1239.2019.20180760SHI Weisong, ZHANG Xingzhou, WANG Yifan, et al. Edge computing: State-of-the-art and future directions[J]. Journal of Computer Research and Development, 2019, 56(1): 69–89. doi: 10.7544/issn1000-1239.2019.20180760 [3] KRIZHEVSKY A, SUTSKEVER I, and HINTON G E. ImageNet classification with deep convolutional neural networks[C]. The 25th International Conference on Neural Information Processing Systems, Lake Tahoe, USA, 2012: 1097–1105. [4] ROY S K, KRISHNA G, DUBEY S R, et al. HybridSN: Exploring 3-D–2-D CNN feature hierarchy for hyperspectral image classification[J]. IEEE Geoscience and Remote Sensing Letters, 2020, 17(2): 277–281. doi: 10.1109/LGRS.2019.2918719 [5] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 318–327. doi: 10.1109/TPAMI.2018.2858826 [6] USAMA M, AHMAD B, SONG Enmin, et al. Attention-based sentiment analysis using convolutional and recurrent neural network[J]. Future Generation Computer Systems, 2020, 113: 571–578. doi: 10.1016/j.future.2020.07.022 [7] WAN Shaohua and GOUDOS S. Faster R-CNN for multi-class fruit detection using a robotic vision system[J]. Computer Networks, 2020, 168: 107036. doi: 10.1016/j.comnet.2019.107036 [8] ACHARYA J and BASU A. Deep neural network for respiratory sound classification in wearable devices enabled by patient specific model tuning[J]. IEEE Transactions on Biomedical Circuits and Systems, 2020, 14(3): 535–544. doi: 10.1109/TBCAS.2020.2981172 [9] WANG Yu, YANG Jie, LIU Miao, et al. LightAMC: Lightweight automatic modulation classification via deep learning and compressive sensing[J]. IEEE Transactions on Vehicular Technology, 2020, 69(3): 3491–3495. doi: 10.1109/TVT.2020.2971001 [10] WU Huaqiang, LYU Feng, ZHOU Conghao, et al. Optimal UAV caching and trajectory in aerial-assisted vehicular networks: A learning-based approach[J]. IEEE Journal on Selected Areas in Communications, 2020, 38(12): 2783–2797. doi: 10.1109/JSAC.2020.3005469 [11] Bitcraze. Crazyflie 2.1[EB/OL]. https://www.bitcraze.io/products/crazyflie-2-1/, 2022. [12] PALOSSI D, LOQUERCIO A, CONTI F, et al. A 64-mW DNN-based visual navigation engine for autonomous nano-drones[J]. IEEE Internet of Things Journal, 2019, 6(5): 8357–8371. doi: 10.1109/JIOT.2019.2917066 [13] NICULESCU V, LAMBERTI L, CONTI F, et al. Improving autonomous nano-drones performance via automated end-to-end optimization and deployment of DNNs[J]. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 2021, 11(4): 548–562. doi: 10.1109/JETCAS.2021.3126259 [14] PALOSSI D, ZIMMERMAN N, BURRELLO A, et al. Fully onboard AI-powered human-drone pose estimation on ultralow-power autonomous flying nano-UAVs[J]. IEEE Internet of Things Journal, 2022, 9(3): 1913–1929. doi: 10.1109/JIOT.2021.3091643 [15] 刘勤让, 刘崇阳. 利用参数稀疏性的卷积神经网络计算优化及其FPGA加速器设计[J]. 电子与信息学报, 2018, 40(6): 1368–1374. doi: 10.11999/JEIT170819LIU Qinrang and LIU Chongyang. Calculation optimization for convolutional neural networks and FPGA-based accelerator design using the parameters sparsity[J]. Journal of Electronics &Information Technology, 2018, 40(6): 1368–1374. doi: 10.11999/JEIT170819 [16] 秦华标, 曹钦平. 基于FPGA的卷积神经网络硬件加速器设计[J]. 电子与信息学报, 2019, 41(11): 2599–2605. doi: 10.11999/JEIT190058QIN Huabiao and CAO Qinping. Design of convolutional neural networks hardware acceleration based on FPGA[J]. Journal of Electronics &Information Technology, 2019, 41(11): 2599–2605. doi: 10.11999/JEIT190058 [17] YUAN Tian, LIU Weiqiang, HAN Jie, et al. High performance CNN accelerators based on hardware and algorithm co-optimization[J]. IEEE Transactions on Circuits and Systems I:Regular Papers, 2021, 68(1): 250–263. doi: 10.1109/TCSI.2020.3030663 [18] GONG Lei, WANG Chao, LI Xi, et al. MALOC: A fully pipelined FPGA accelerator for convolutional neural networks with all layers mapped on chip[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2018, 37(11): 2601–2612. doi: 10.1109/TCAD.2018.2857078 [19] WANG Chao, GONG Lei, YU Qi, et al. DLAU: A scalable deep learning accelerator unit on FPGA[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2017, 36(3): 513–517. doi: 10.1109/TCAD.2016.2587683 [20] DING Wei, HUANG Zeyu, HUANG Zunkai, et al. Designing efficient accelerator of depthwise separable convolutional neural network on FPGA[J]. Journal of Systems Architecture, 2019, 97: 278–286. doi: 10.1016/j.sysarc.2018.12.008 [21] BLOTT M, PREUßER T B, FRASER N J, et al. FINN-R: An end-to-end deep-learning framework for fast exploration of quantized neural networks[J]. ACM Transactions on Reconfigurable Technology and Systems, 2018, 11(3): 16. doi: 10.1145/3242897 [22] BAI Lin, ZHAO Yiming, and HUANG Xinming. A CNN accelerator on FPGA using depthwise separable convolution[J]. IEEE Transactions on Circuits and Systems II:Express Briefs, 2018, 65(10): 1415–1419. doi: 10.1109/TCSII.2018.2865896 [23] GUO Kaiyuan, SUI Lingzhi, QIU Jiantao, et al. Angel-eye: A complete design flow for mapping CNN onto embedded FPGA[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2018, 37(1): 35–47. doi: 10.1109/TCAD.2017.2705069 [24] ZHU Jiang, WANG Lizan, LIU Haolin, et al. An efficient task assignment framework to accelerate DPU-based convolutional neural network inference on FPGAs[J]. IEEE Access, 2020, 8: 83224–83237. doi: 10.1109/ACCESS.2020.2988311 -


 下载:
下载:



图(8) / 表(8)
计量
- 文章访问数: 2247
- HTML全文浏览量: 1114
- PDF下载量: 288
- 被引次数: 0
